一、logging在接口自动化里的应用
1、设置日志的配置,并收集日志文件

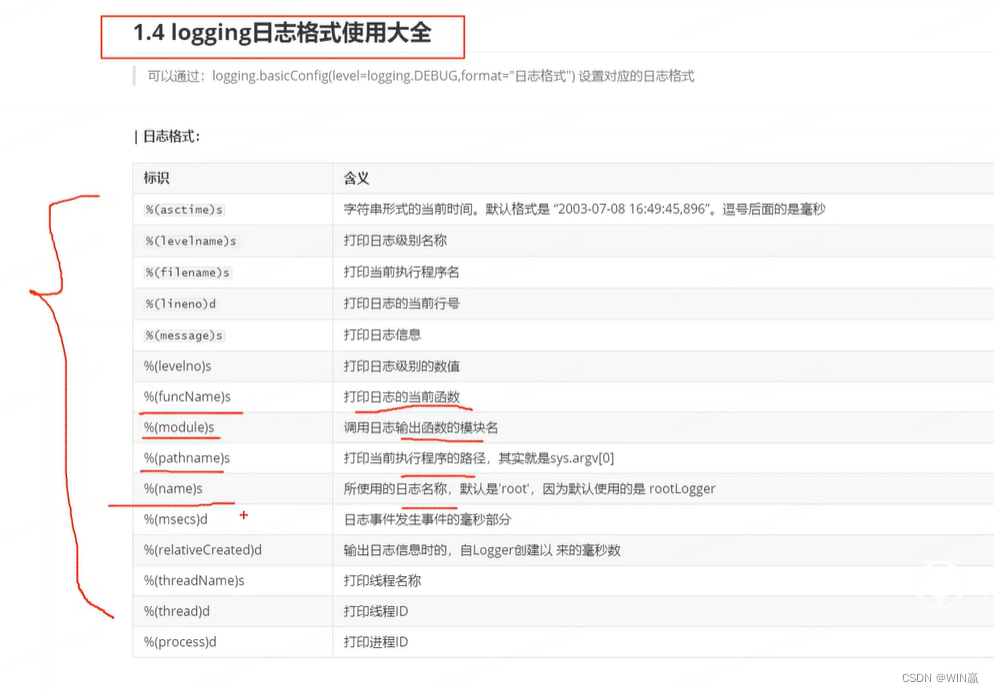
日志的设置需要在pytest.ini文件里设置。这个里面尽量不要有中文
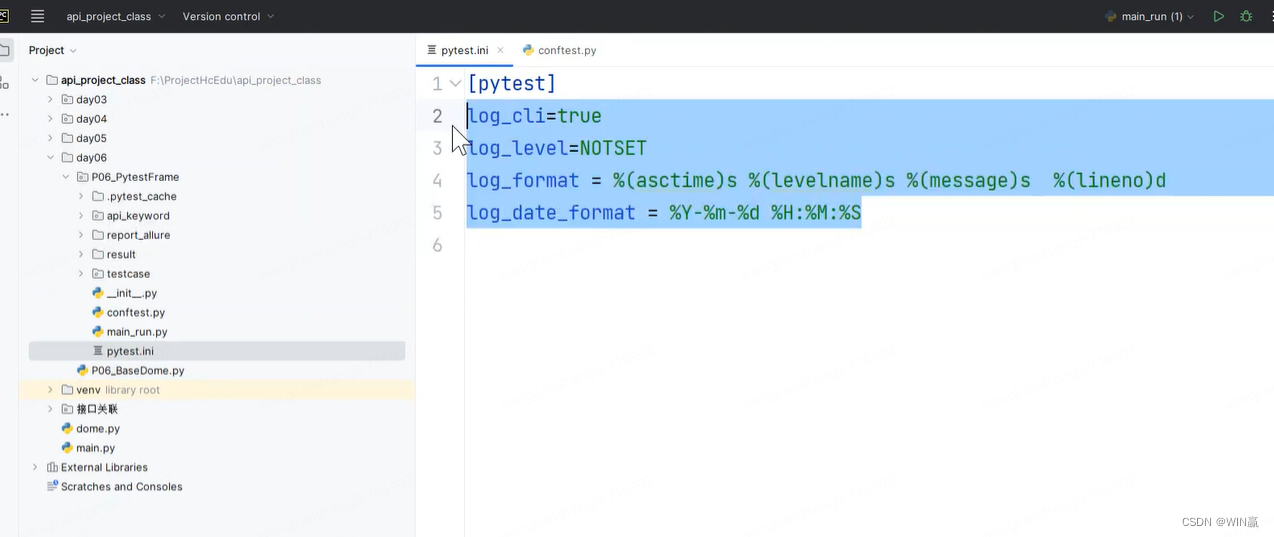
2、debug日志的打印
pytest.ini文件的开关一定得是true才能在控制台打印日志
import allure
import pytest
from P06_PytestFrame.api_keyword.api_key import ApiKey
import logging
@allure.title("DS01-通过用户名可以正确登录")
def test_login():
# 1. 最重要的日志打印
logging.basicConfig(level=logging.DEBUG)
logging.error("执行用例:DS01-通过用户名可以正确登录")
url = "http://shop-xo.hctestedu.com/index.php?s=/api/user/login"
params = {"application": "app", "application_client_type": "weixin"}
data = {"accounts": "hami", "pwd": "123456", "type": "username"}
ak = ApiKey()
# 2. 发送请求
res = ak.post(url=url, params=params, data=data)
print(f"响应结果是:{res.json()}")
# 3.断言
sj_res = ak.get_text(res.json(), "$.msg")
qw_res = "登录成功1"
assert sj_res == qw_res, "结果不一致"控制台运行结果
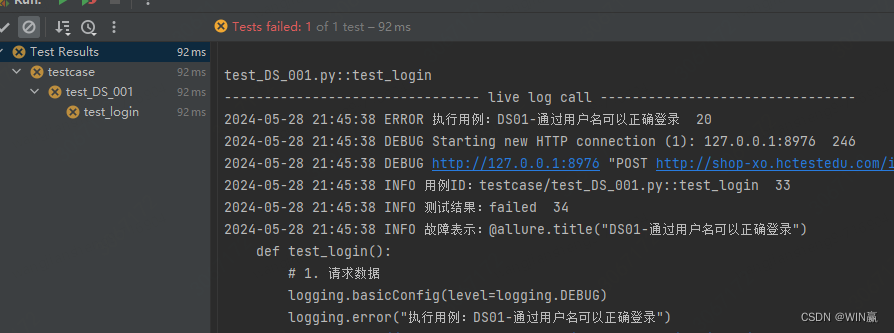
日志收集文件里的存储结果

3、钩子函数
钩子函数放在conftest.py文件里
pytest官网:pytest: helps you write better programs - pytest documentation
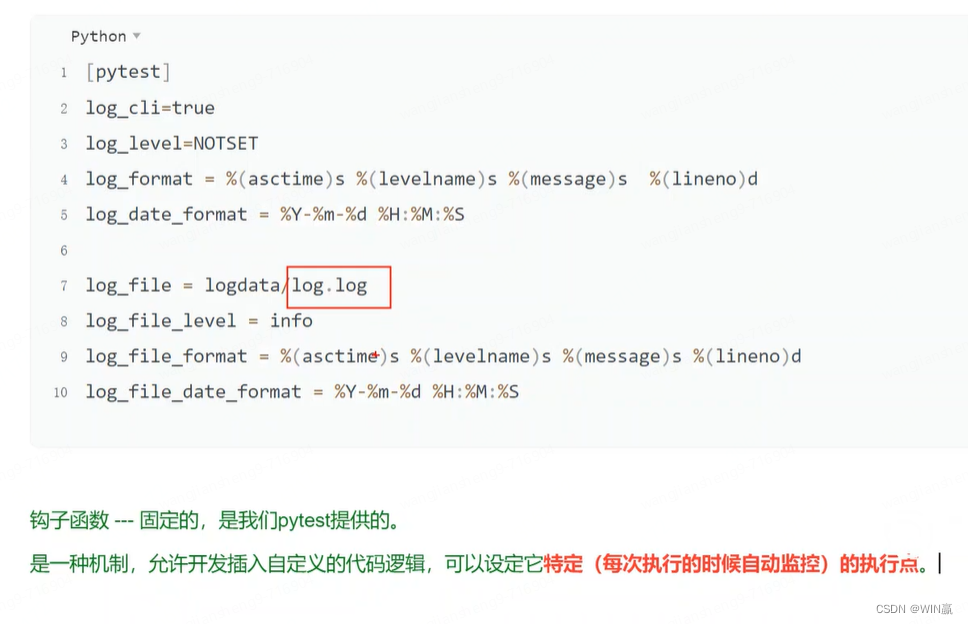
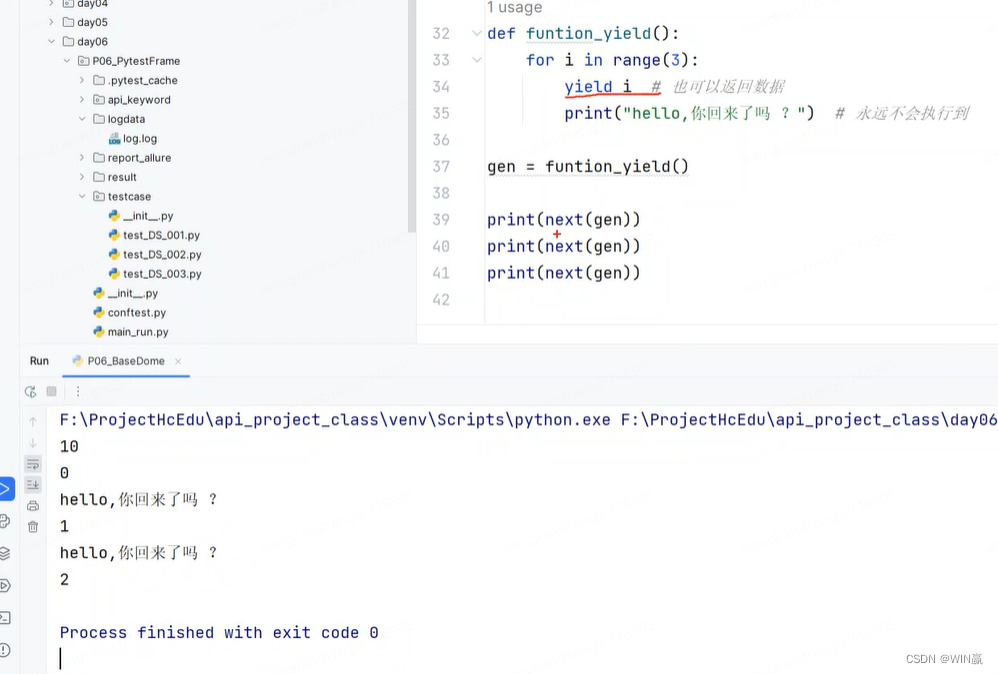
return永远不执行后面的

迭代器会往复执行
二、所有接口的区别
接口四要素不同--数据提取出来--就是数据驱动(DDT)
"数据驱动测试"(Data-Driven Testing,简称DDT)是一种软件测试方法,使用不同的数据集来驱动测试用例的执行。通过将测试数据与测试逻辑分离,DDT可以提高测试覆盖率、增强测试代码的可维护性,并减少重复代码。1、数据格式
把所有的数据进行提取 - DDT(数据驱动)
格式:
单元素:每次拿一个数据(有多少个就多少次)
()--元组,无序
[] --列表 ,有序
{}--字典 , 有序(python3.7开始字典有序,之前的无序)
嵌套元素:每次拿一组数据,要取其中的值(可以通过下标去获取)
([],[])--元组里套列表
[(),()] --列表里套元组,因为元组无序,所以这个不能通过下标获取
[{},{}] --列表套字典- 用的最多的一种格式
方法:--装饰器
@pytest.mark.parametrize("变量名",数据源)
在运行过程当中,数据源有多少个就会执行多少次1)单元素数据驱动
data1 = ("hami", "xiaomi", "sanfeng") 元组类型
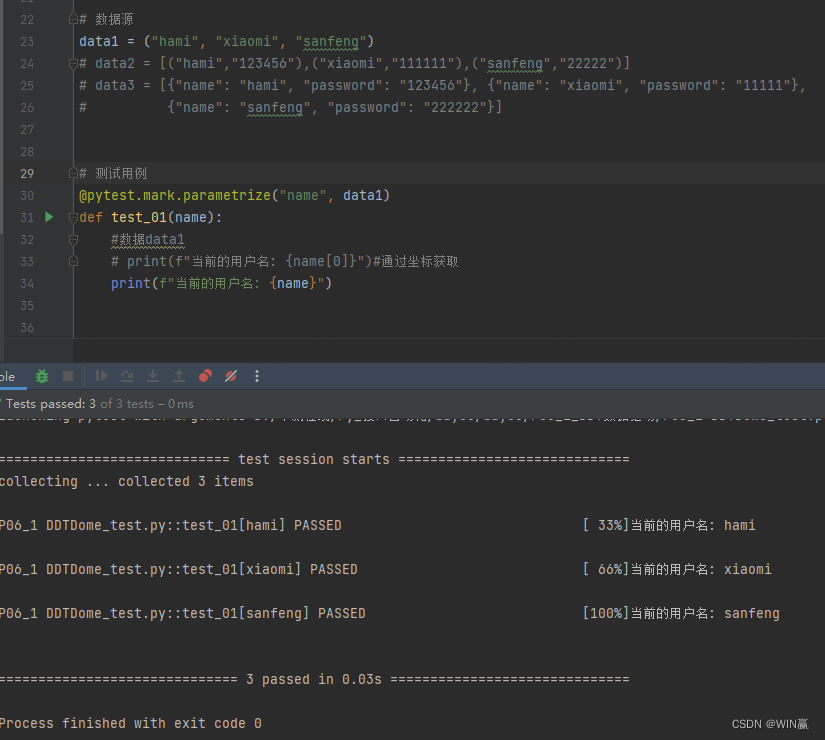
获取元素的坐标结果
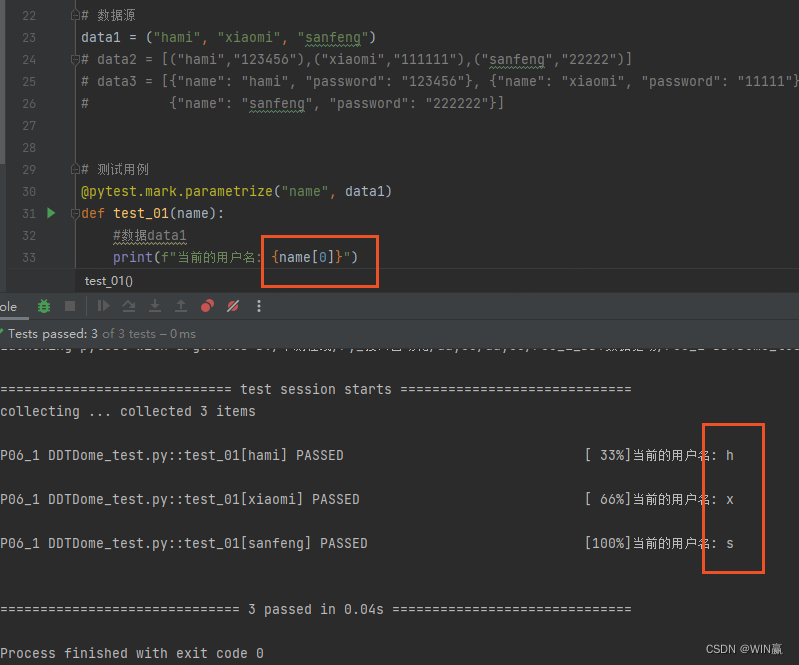
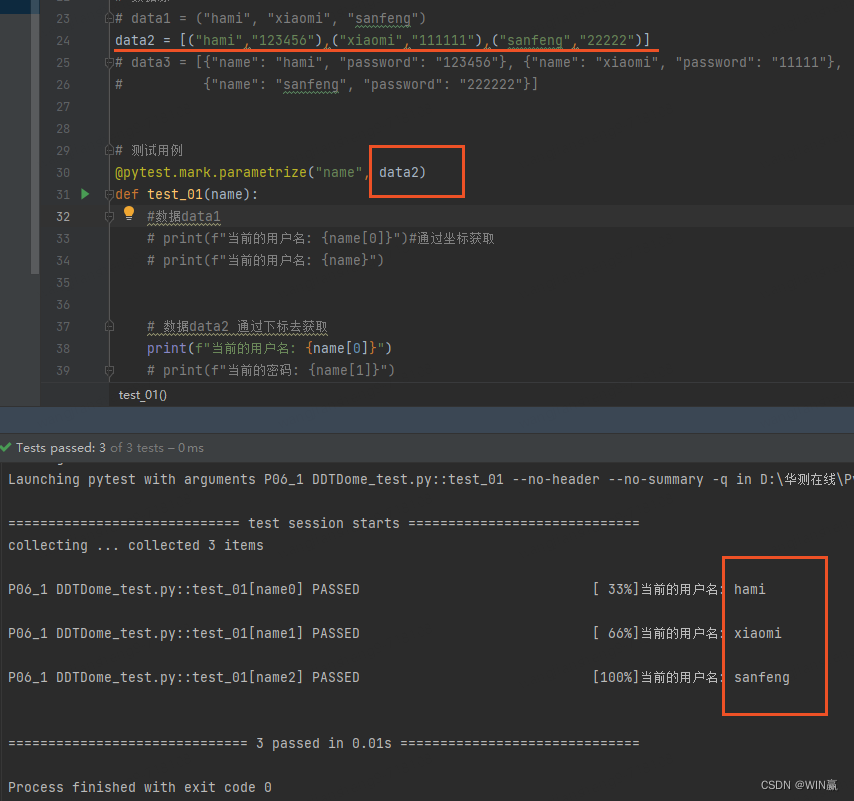
2)嵌套元素数据--列表里套元组
data2 = ("hami","123456"),("xiaomi","111111"),("sanfeng","22222")
通过下标获取其一数据
3)嵌套元素数据--列表里套字典
data3 = [{"name": "hami", "password": "123456"}, {"name": "xiaomi", "password":"11111"},{"name": "sanfeng", "password": "222222"}]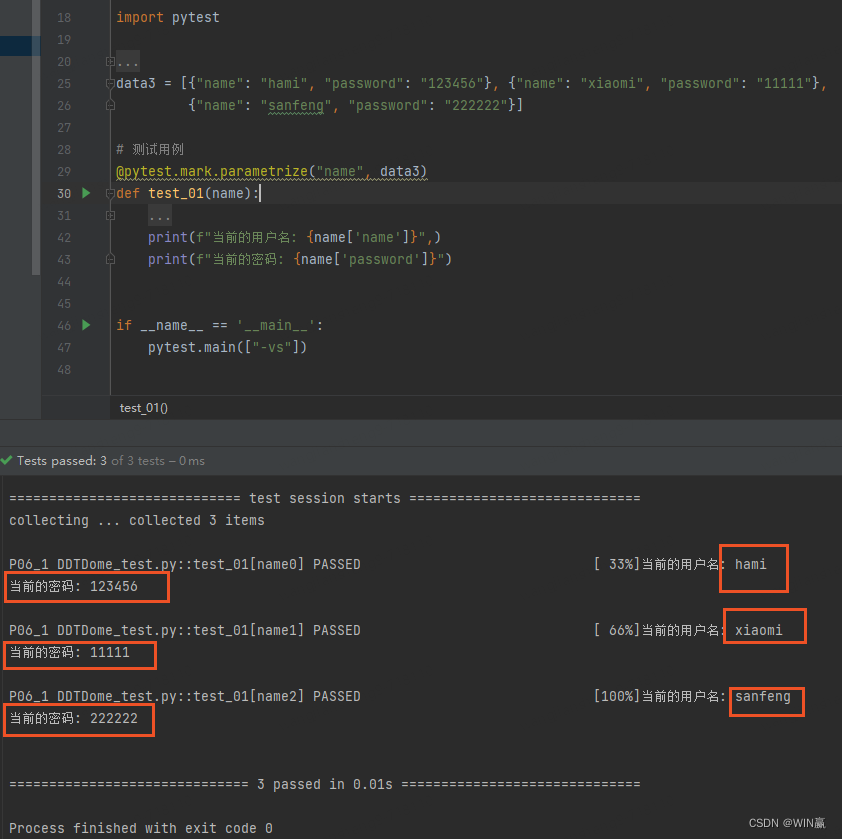
三、接口自动化用例模板的编写
要求:
1、编号和行号一致
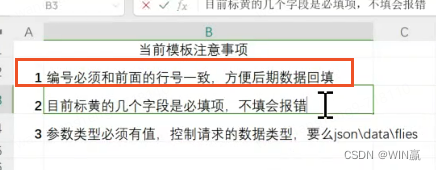
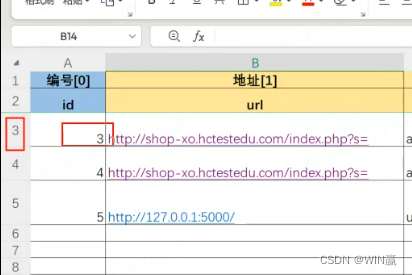
2、 标黄色都是必填
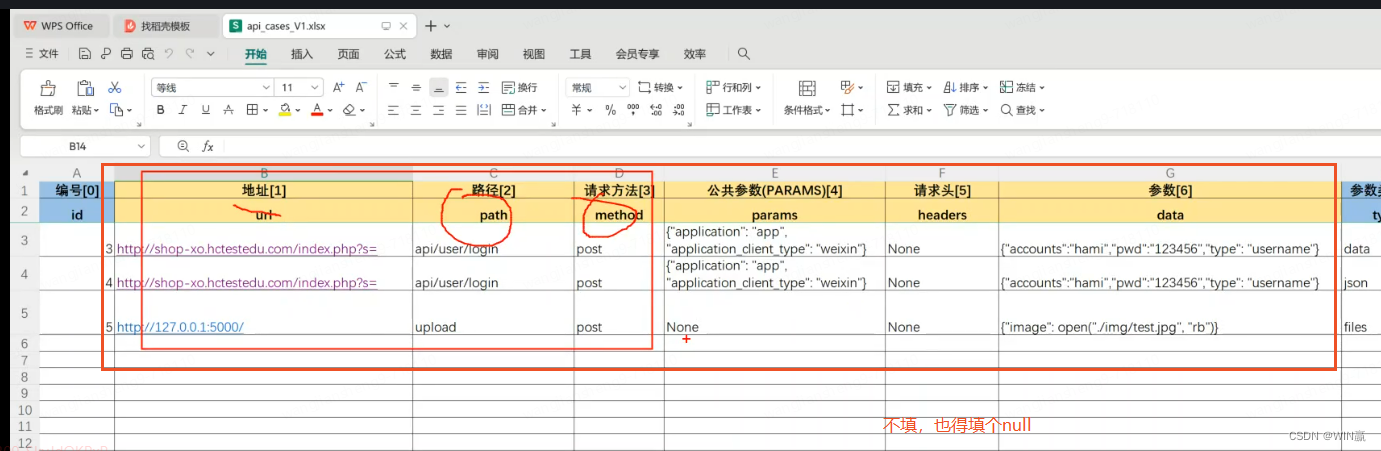
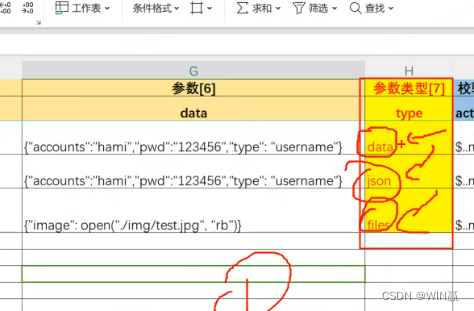
3、请求数据的参数类型
data是表单形式提交,Json是请求头是json的去提交,files是上传文件的接口需要使用
4、断言的字段
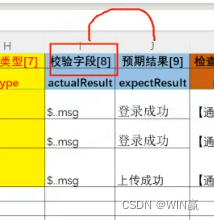
5、程序执行完,自动回写的数据

四、读取文件的程序-FileDataDriver.py
用来读取和写入excel \ yaml文件。
利用数据驱动,把excel文件读取成功
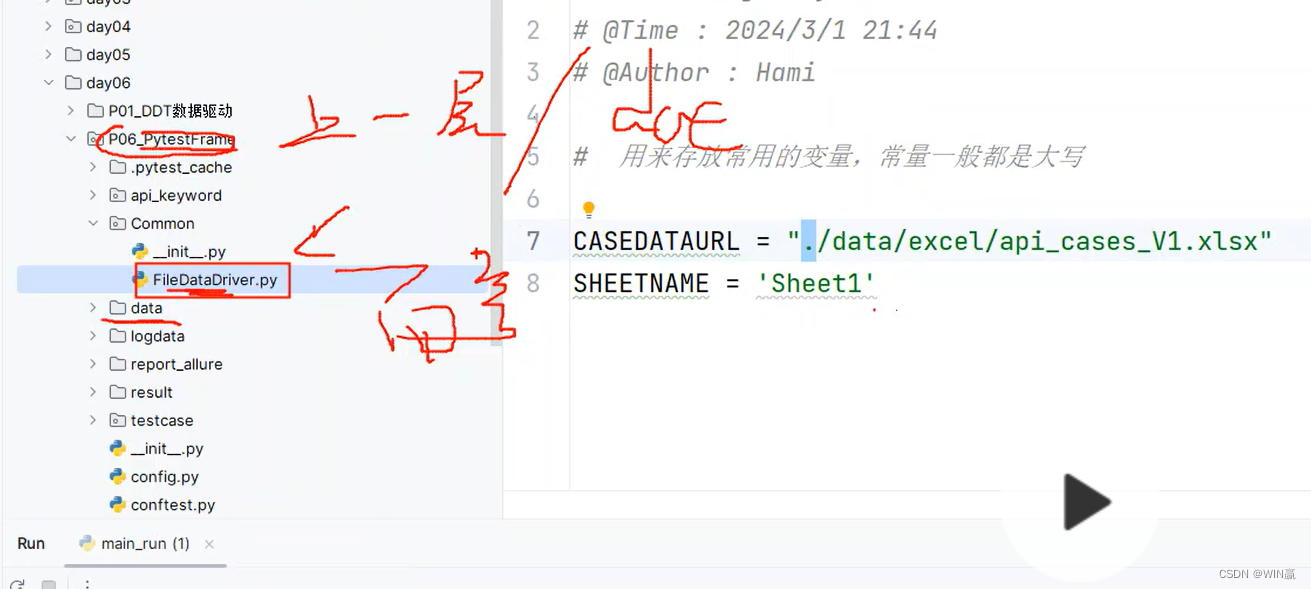
五、config.py
用来存放常用的变量(文件路径、读取的sheet页),其中,常量要大写
要从文件的根目录的下一级开始读取文件,所以,config.py文件要在文件的根目录的下一级
如图,是day06.P06_PytestFrame

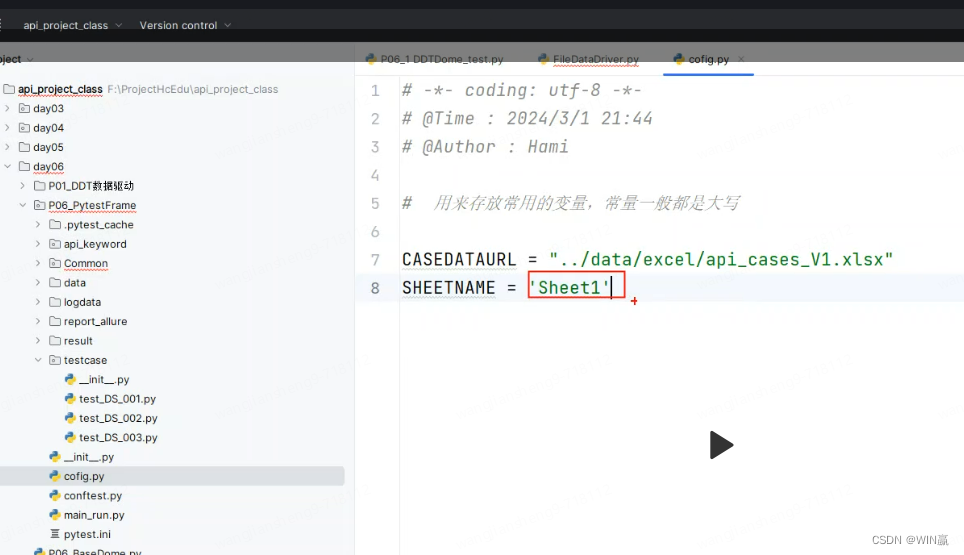
自己的代码-根目录是day06,下一级是P06_PytestFrame
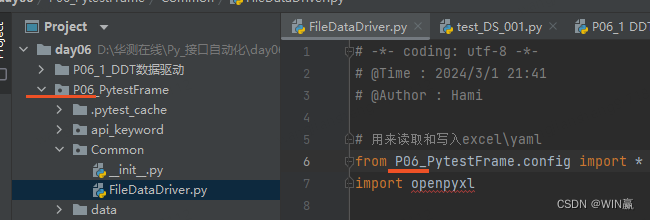
下载指令:pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple六、data的路径
下面这些文件是在同一级目录里
如果是基于上一层目录下的一层(在二级目录里),则是../
如果只是处于同级目录,是./
七、核心执行器--testcase
拿到数据,进行解析,发送请求

1、反射
class ApiKey:
name = "hami"
def get(self):
print("这是get方法")
def post(self, url, data):
print("这是post方法")
print("url", url)
print("data", data)
return "ok"
# 反射:通过[类(实例化对象)和方法名]找到对应的方法
# 反射的语法:getattr(实例化对象, 方法名/属性名)**参数 ,返回值:方法本体
ak = ApiKey()
method = "post"
method_fun = getattr(ak, method)#(类,方法)
method_fun(url="1111",data="2222")tips:
# eval() # 把字符串 转成[有效的表达式]
#
# a = "1+2"
# print(eval(a)) #3
# data = "{'name':'hami'}"
# print(type(eval(data))) #dict2、断言

拿到响应数据,和预期数据,断言比较
3、动态生成标题:

使用固定的方法,动态生成标题

然后生成的标题

八、离大谱
数据驱动去执行读取excel文件,是通过main方法,不是单独去执行这个用例
 而是,通过main文件,执行用例
而是,通过main文件,执行用例

就可以读取到excel文件的数据了
