目录
[MySQL事务和Redis 事务有什么区别?](#MySQL事务和Redis 事务有什么区别?)
MySQL事务隔离级别有哪些?分别解决哪些问题?(先说问题再说隔离级别)
[如果两个 A B 事务并发修改一个变量,那么 A 读到的值是什么,怎么分析。(根据隔离级别进行分析)](#如果两个 A B 事务并发修改一个变量,那么 A 读到的值是什么,怎么分析。(根据隔离级别进行分析))
[读已提交和可重复读隔离级别实现 MVCC的区别?](#读已提交和可重复读隔离级别实现 MVCC的区别?)
可重复读隔离级别为什么不能完全避免幻读?什么情况下出现幻读?
事务有什么特性?
MySQL事务有 ACID 四大特性,分别是原子性、一致性、隔离性、持久性。
- 原子性的意思是事务中的所有操作要么全部完成,要么全部不完成,不会结束在中间某个环节,原子性是由 undo log 日志保证的;
- 一致性的意思是事务执行前后,数据库的状态必须保持一致性,一致性是由通过持久性+原子性+隔离性这三个共同保证的:
- 隔离性的意思是多个并发事务之间需要相互隔离,即一个事务的执行不能被其他事务干扰 。隔离性是由MVCC 和锁机制保证的
- 持久性的意思是保证事务完成后对数据的修改就是永久的。即使发生系统崩溃,修改的数据也不会丢失。持久性是由 redo log 日志保证的;
事务的隔离性如何保证?
事务的隔离性是由MVCC 和锁保证的
可重复读隔离级别下的快照读(普通select),通过 MVCC 来保证事务隔离
当前读 (update、select ... for update) 是通过行级锁来保证事务隔离性的。
事务的持久性如何保证?
事务的持久性是由 redo log保证的,因为 MySQL通过 WAL (先写日志再写数据)机制,在修改数据的时候,会将本次对数据页的修改以 redo log 的形式记录下来,这个时候更新就算完成了。
Buffer Pool 的脏页会通过后台线程刷盘,即使在脏页还没刷盘的时候发生了数据库重启,由于修改操作都记录到了 redo log ,之前已提交的记录都不会丢失 **,**重启后就通过 redo log,恢复脏页数据,从而保证了事务的持久性。
事务的原子性如何保证?
事务的原子性是通过 undo log 实现的,在事务还没提交前,历史数据会记录在 undo log中,如果事务执行过程中,出现了错误或者用户执行ROLLBACK 语句,MySQL可以利用undo log 中的历史数据,将数据恢复到事务开始之前的状态,从而保证了事务的原子性。
MySQL 事务和Redis 事务有什么区别?
Redis事务没保证原子性和持久性
- MySQL事务能够实现ACID四大特性,而Redis事务没保证原子性和持久性
- Redis 事务没有回滚功能,没办法实现跟MySQL事务一样的原子性,就是没办法保证事务执行期间,要不全部失败,要不全部成功。Redis 事务执行过程中,如果中途有命令执行出错了,不会停止和回滚,而是继续执行,那么就可能出现半成功的状态
- Redis 不管是 AOF 模式,还是 RDB 快照,都没办法保证数据不丢失,所以 Redis 事务不具有持久性。
MySQL 事务隔离级别 有哪些?分别解决哪些问题? (先说问题再说隔离级别)

MySQL共有四个隔离级别如下:
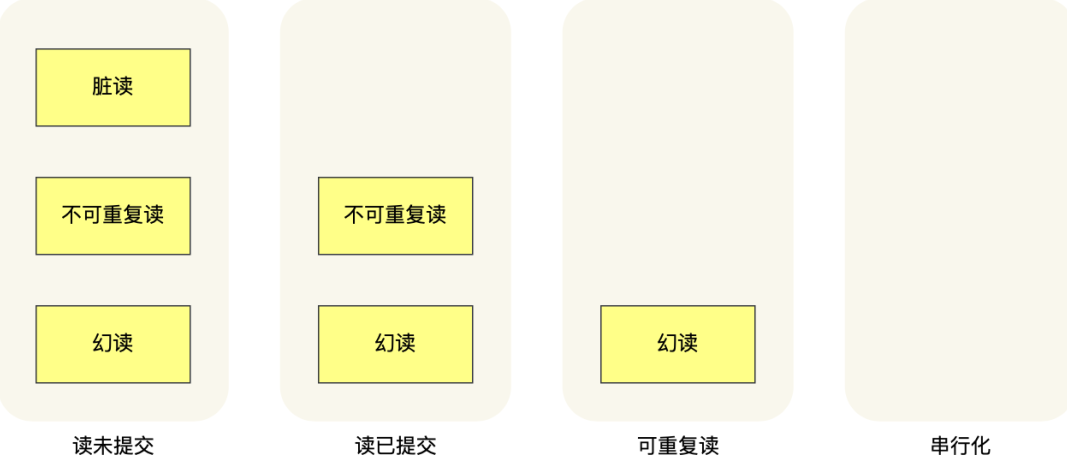
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到; 出现" 脏读 "、" 不可重复读 "和" 幻读 "的问题 。
- 读已提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到; 可以避免" 脏读 "现象。但 不可重复读 和 幻读 问题仍然存在。
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别 ; 避免了" 脏读 "和" 不可重复读 ",但可能会出现 幻读 。
- 串行化(serializable ),会对记录加上读写锁,通过强制事务串行执行来避免并发问题,可以解决" 脏读 "、" 不可重复读 "和" 幻读 "问题。但会导致大量的超时和锁竞争问题。
隔离水平由低到高 1-4
脏读 、 不可重复读 、 幻读 的意思:
- 脏读是指一个事务读取了另一个事务还未提交的数据,如果另一个事务回滚,则读取的数据是无效的。
- 不可重复读是指在同一事务中执行相同的查询时,返回的结果集不同。这是由于在事务过程中,另一个事务修改了数据并提交。
- 幻读是指在同一事务中执行相同的查询时,返回的结果集中出现了之前没有的数据行。这是因为在事务过程中,另一个事务插入了新的数据并提交。
MySQL默认隔离级别是可重复读,除此之外,我还知道 MySQL还支持读未提交、读已提交、串行化 这三个隔离级别。
我了解到事务并发问题有 脏读 、 不可重复读 、 幻读,不同的隔离级别,解决的问题也各不同的。
- 读未提交一个问题都没有解决
- 读已提交避免了脏读问题,但是还存在不可重复读和幻读这两个问题
- 可重复读避免了脏读和不可重复读的问题,不过对于幻读问题是很大程度上避免了,没有完全避免。
- 串行化是所有问题都可以避免,但是事务的并发性能是最差的。
MySQL 默认的隔离级别是什么?怎么实现的?
MySQL默认的隔离级别是可重复读
select 查询是通过 MVCC 实现的,在 MVCC 实现中,每条记录都会保存多个版本,每个版本都有一个版本号,事务在读取数据时,会根据事务开始时的版本号来读取数据,从而保证了事务的隔离性。
可重复读隔离级别是在开启事务后,执行一条 select 语句的时候,会生成一个Read View,后续事务查询数据的时候都在复用 Read View,所以保证了事务期间多次读到的数据都是一致的。
事务的各个隔离级别都是如何实现的?
读未提交是如何实现的?
不提供任何锁机制来保护读取的数据,允许读取未提交的数据(即脏读)。
读已提交&可重复读是如何实现的?
读已提交和可重复读通过 MVCC 机制中的 ReadView 来实现。
- READ COMMITTED:每次读取数据前都生成一个 ReadView,保证每次读操作都是最新的数据。
- REPEATABLE READ:只在第一次读操作时生成一个 ReadView,后续读操作都使用这个 ReadView,保证事务内读取的数据是一致的。
串行化是如何实现的?
事务在读操作 时,必须先加表级 共享锁 ,直到事务结束才释放;事务在写操作 时,必须先加表级排他锁,直到事务结束才释放。
串行化隔离级别的特点是:
- 所有读操作都需要加锁:在串行化隔离级别下,读操作不仅仅是简单的读取数据,还会使用锁来防止其他事务同时修改或插入数据。这种锁通常是表级共享锁(S lock)。
- 所有写操作都需要加锁:写操作在串行化隔离级别下,需要使用表级排他锁(X lock)。这意味着当一个事务在写数据时,其他事务无法对该表进行读或写操作。
介绍一下MVCC
- MVCC 是多版本并发控制 ,是通过记录历史版本数据,解决读写并发冲突问题,避免了读数据时加锁,提高了事务的并发性能。
- 在传统的锁机制中,如果一个事务正在写数据,那么其他事务必须等待写事务完成才能读数据,MVCC 允许读操作访问数据的一个旧版本快照,同时写操作创建一个新的版本,这样读写操作就可以并行进行,不必等待对方完成。
- MySQL将历史数据存储在 undo log 中,结构逻辑上类似一个链表,MySQL数据行上有两个隐藏列,一个是事务trx_ID,一个就是指向 undo log 的指针。
- 事务开启后,执行第一条select(读)语句的时候会创建 ReadView ,ReadView 记录了当前未提交的事务,通过与历史数据的事务ID比较,就可以根据可见性规则进行判断,判断这条记录是否可见,如果可见就直接将这个数据返回给客户端,如果不可见就继续往undo log 版本链查找第一个可见的数据。
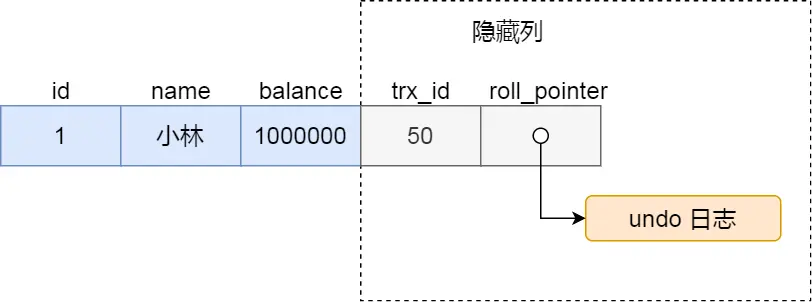
trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
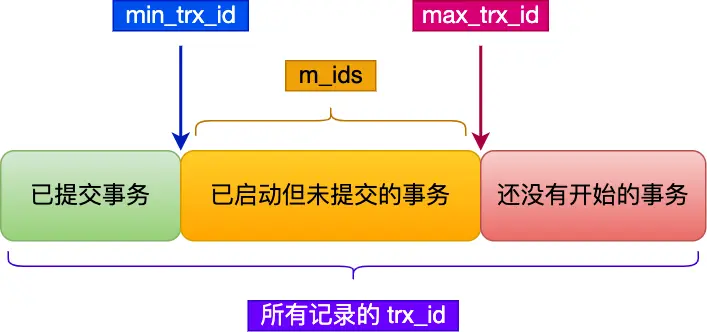
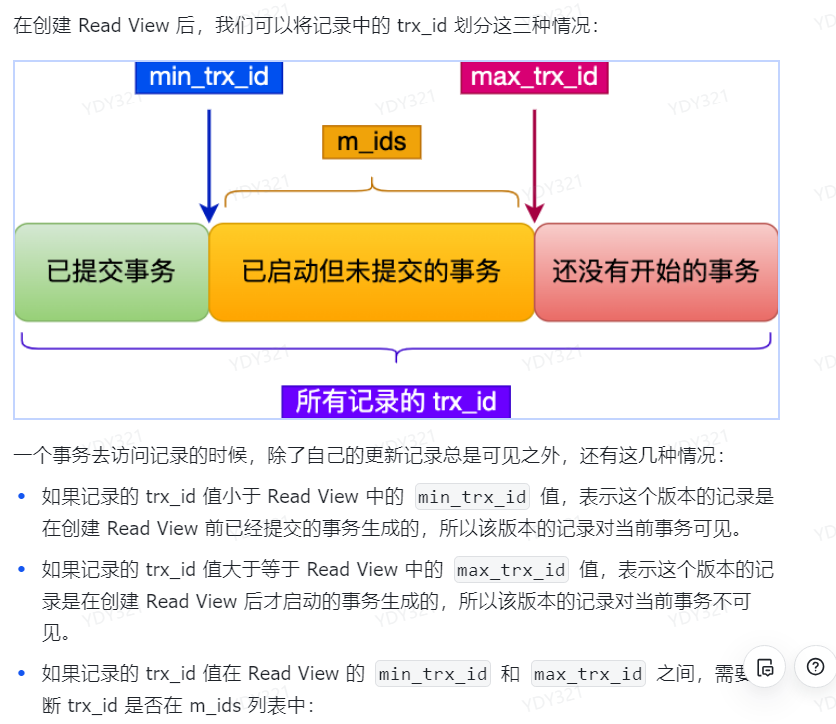
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
MVCC的如何判断行记录对某一个事务是否可见?
ReadView 有四个重要的字段:
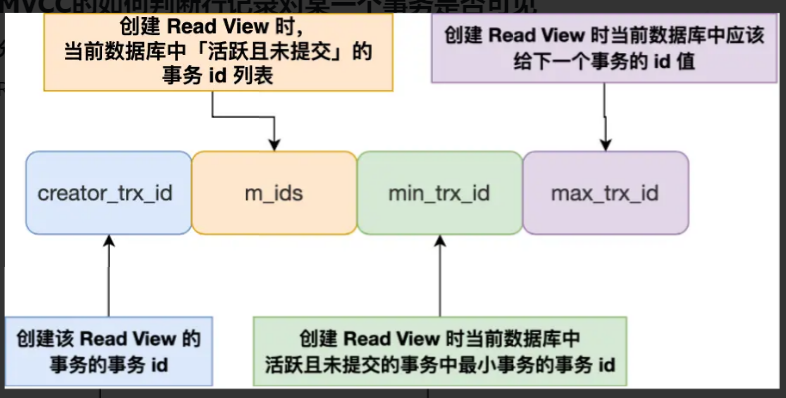
m_ids:指的是在创建 Read View 时,当前数据库中活跃事务的事务id 列表,注意是一个列表,"活跃事务"指的就是,启动了但还没提交的事务
min_trx_id:指的是在创建 Read View 时,当前数据库中 活跃事务中事务id 最小的事务,也就是 m_ids的最小值。
max_trx_id:这个并不是m_ids 的最大值,而是创建Read View 时当前数据库中应该给下一个事务的id 值,也就是全局事务中最大的事务id 值 +1
creator_trx id:指的是创建该 Read View 的事务的事务id。
我们每一条记录都有两个隐藏列,一个是事务 id,一个是指向历史数据 undo log 的指针,然后 Read View 有四个字段,分别是创建 Read View 的事务 id、活跃事务 id 列表、活跃事务 id 列表中最小的 id、下一个事务的 id。
主要有这几种判断规则:
- 如果记录的事务 id 小于活跃事务 id 列表中最小的 id,就说明该记录是在创建Read View 前就生成好了,所以该记录是当前事务是可见的。
- 如果记录的事务id 大于下一个事务的 id,就说明该记录是在创建 Read View 后才生成的,所以该记录是当前事务是不可见的。
- 如果记录隐藏列的事务 id 在最小的 id 和下一个事务的id之间,这时候就需要看记录的事务id是否在活跃事务id列表中:
-
- 如果记录的事务id 在活跃事务 id 列表中,说明修改该记录的事务还没提交,所以该记录是不可见的。
- 如果记录的事务id不在活跃事务id 列表中,说明修改该记录的事务已经提交了那么该记录就是可见。
活跃id事务是启动未提交的列表,事务提交就不在该列表内了
如果两个 A B 事务并发修改一个变量,那么 A 读到的值是什么,怎么分析。(根据隔离级别进行分析)
当两个事务 A 和 B 并发修改同一个变量时,A 事务读取到的值取决于多个因素,包括事务的隔离级别、事务的开始时间和提交时间等。
- 读未提交:在这个级别下,事务可以看到其他事务尚未提交的更改。如果 B 更改了一个变量但尚未提交,A 可以读到这个更改的值。
- 读提交:A 只能看到 B 提交后的更改。如果 B 还没提交,A 将看到更改前的值。
- 可重复读:在事务开始后,A 总是读取到变量的相同值,即使 B 在这期间提交了更改。这是通过 MVCC 机制实现的。
- 可串行化:A 和 B 的操作是串行执行的,如果 A 先执行,那么 A 读到的值就是 B 提交前的值;如果 B 先执行,那么 A 读到的值就是 B 提交后的值。
读已提交和可重复读隔离级别实现 MVCC的区别?
读已提交和可重复读隔离级别都是由MVCC实现的,它们的区别在于创建 Read View 的时机不同。
- 读已提交隔离级别在事务开启后, 每次执行 select 都会生成一个新的 Read View,所以每次 select 都能看到其他事务最近提交的数据
- 可重复读隔离级别在事务开启后,执行第一条 select 时生成一个 Read View,然后整个事务期间都在复用这个 Read View,所以一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的。
为什么互联网公司用读已提交隔离级别?
- 读已提交的并发性能更好,因为读已提交没有间隙锁,只有记录锁,发生死锁的概率比较低。而可重复读是会有记录锁和间隙锁,所以读已提交隔离级别发生死锁的概率比较小
- 然后互联网业务对于幻读和不可重复读的问题都是能接受的,所以为了降低死锁的概率,提高事务的并发性能,都会选择使用读已提交隔离级别。
可重复读 隔离级别是如何解决 不可重复读 的?
分两种查询来回答
- 快照读,靠MVCC解决不可重复读
- 当前读,靠行级锁中的记录锁解决不可重复读
针对快照读的话,是通过 MVCC 机制来解决的,在可重复读隔离级别下,第一次select查询的时候,会生成 readview,在第二次执行select查询的时候,会复用这个readview,这样前后两次查询的记录都是一样的,不会读到其他事务更新的操作,这样就不会发生不可重复读的问题了。
针对当前读的话,是靠行级锁中的记录锁来实现的 ,在可重复读隔离级别下,第一次select for update 语句查询的时候,会对记录加next-key 锁,这个锁包含记录锁,这时候如果其他事务更新了加了锁的记录,都会被阻塞住,这样就不会发生不可重复读的问题
可重复读 隔离级别是怎么解决 幻读 的?
分两种查询来回答
快照读,靠MVCC解决幻读
当前读,靠行级锁中的间隙锁解决幻读
回答
针对快照读的话,是通过 MVCC 机制来解决的,在可重复读隔离级别下,第一次select查询的时候,会生成 readview,在第二次执行select查询的时候,会复用这个readview,这样前后两次查询的结果集都是一样的,不会读到其他事务新插入的记录,这样就不会发生幻读的问题了。
针对当前读的话,是靠行级锁中的间隙锁 来实现的,在可重复读隔离级别下,第一次select for update 语句查询的时候,会对记录加next-key 锁,这个锁包含间隙锁,这时候如果其他事务往这个间隙插入新记录的话,都会被阻塞住,这样就不会发生幻读的问题了。
可重复读隔离级别解决了什么问题?有没有完全解决幻读?
可重复读隔离级别解决了脏读、不可重复读问题,幻读也很大程度上避免了,但是我觉得并没有完全解决幻读,在一些特殊的场景,还是会发生幻读的问题。
可重复读隔离级别为什么不能完全避免幻读?什么情况下出现幻读?
在可重复读隔离级别场景下,当先快照读再当前读的场景下可能会出现幻读的问题。
比如说这个场景:
事务A 通过快照读的方式查询id =5的记录,此时数据库没有这条记录,然后事务 B 向这张表中新插入了一条 id =5的记录并提交了事务。
接着,事务A对id = 5这条记录进行了更新(当前读)操作,在这个时刻,这条新记录隐藏列中的事务id就变成了事务A 的事务 id,这时候事务 A 再使用 select 语去查询这条记录时就可以看到这条记录了,这里事务 A前后两次查询的结果集合数不一样了,于是就发生了幻读
我还知道另外一个场景,事务A 通过快照读的方式查询d 大于 100的记录,假设这时候有1条记录,然后事务B 插入了 id = 200的记录并提交了事务,接着事务A 通过当前读的方式查询 id 大于 100的记录,这时候就会得到 2条记录,事务 A 前后两次查询的结果集合数不一样了,就发生了幻读
我觉得上面这两种发生幻读的场景,也是可以避免的,就是尽量在开启事务之后,马上执行 select ... for update 语句,因为它会对记录加临键锁 (next-key 锁),这样就可以避免其他事务插入一条新记录,就避免了幻读的问题。
可重复读隔离级别,MVCC完全解决了不可重复读问题吗?
如果前后两次查询都是快照读 ,就是普通的 select 的话,那就不会产生不可重复读的问题的。但是如果第一次查询是快照读,第二次查询是当前读,那么就可能会发生不可重复读的问题。
修改隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL 隔离级别;
自己整理,借鉴很多博主,感谢他们