pdf提取其中一页怎么操作?需要从一个PDF文件中提取特定页码的操作通常是在处理文档时常见的需求。这种操作允许用户选择性地获取所需的信息,而不必操作整个文档。通过选择性提取页面,你可以更高效地管理和利用PDF文件的内容,无论是为了特定的信息分享、打印需求或者其他工作流程。通过提取特定页面,你可以精确地获取所需的信息,而无需处理整个文档,这样可以节省时间和精力。如果文档包含敏感信息,单独提取一页可以帮助隔离和保护这些信息,避免整个文档被非授权人员访问。
通过提取特定页面可以帮助减少存储空间的使用,特别是在处理大型PDF文件时尤为重要。但是,提取单独的一页可能会导致内容的断裂,使得某些信息的上下文和连续性难以理解。如果频繁地提取单独的页面,可能会增加文档管理和组织的复杂性,特别是当涉及到大量文件或多个版本时。综上所述,提取PDF文件中的特定一页具有便利性和灵活性,但在使用时需谨慎考虑可能带来的信息管理和安全性挑战。

提取PDF其中一页的方法一:使用"星优PDF工具箱"软件
步骤1:首先,在你的电脑上启动"星优PDF工具箱"软件。一旦软件界面打开,点击首页上的"PDF文件处理"选项以进入主要功能区域。

步骤2:在软件界面的左侧列表中选择"PDF提取页面"功能。你可以直接将需要提取页面的PDF文件拖放到软件窗口中,或者点击"添加文件"按钮导入文件。这款软件支持同时提取多个文件。
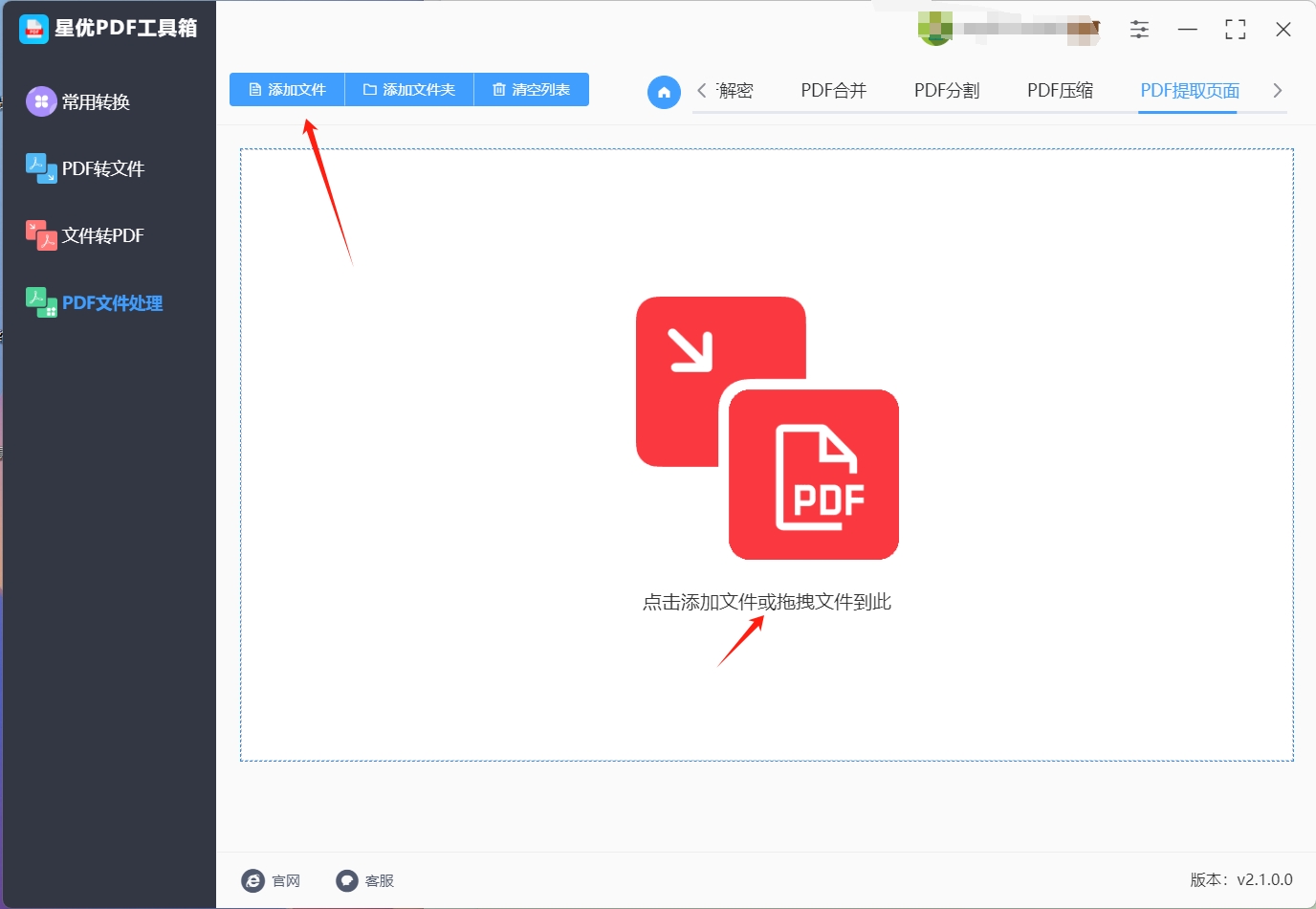
步骤3:文件成功导入后,点击界面中央的"全部页码"按钮。在弹出的页码设置框中,输入你希望提取的页面页码范围,可以单独设置单个页码或者多个页码。
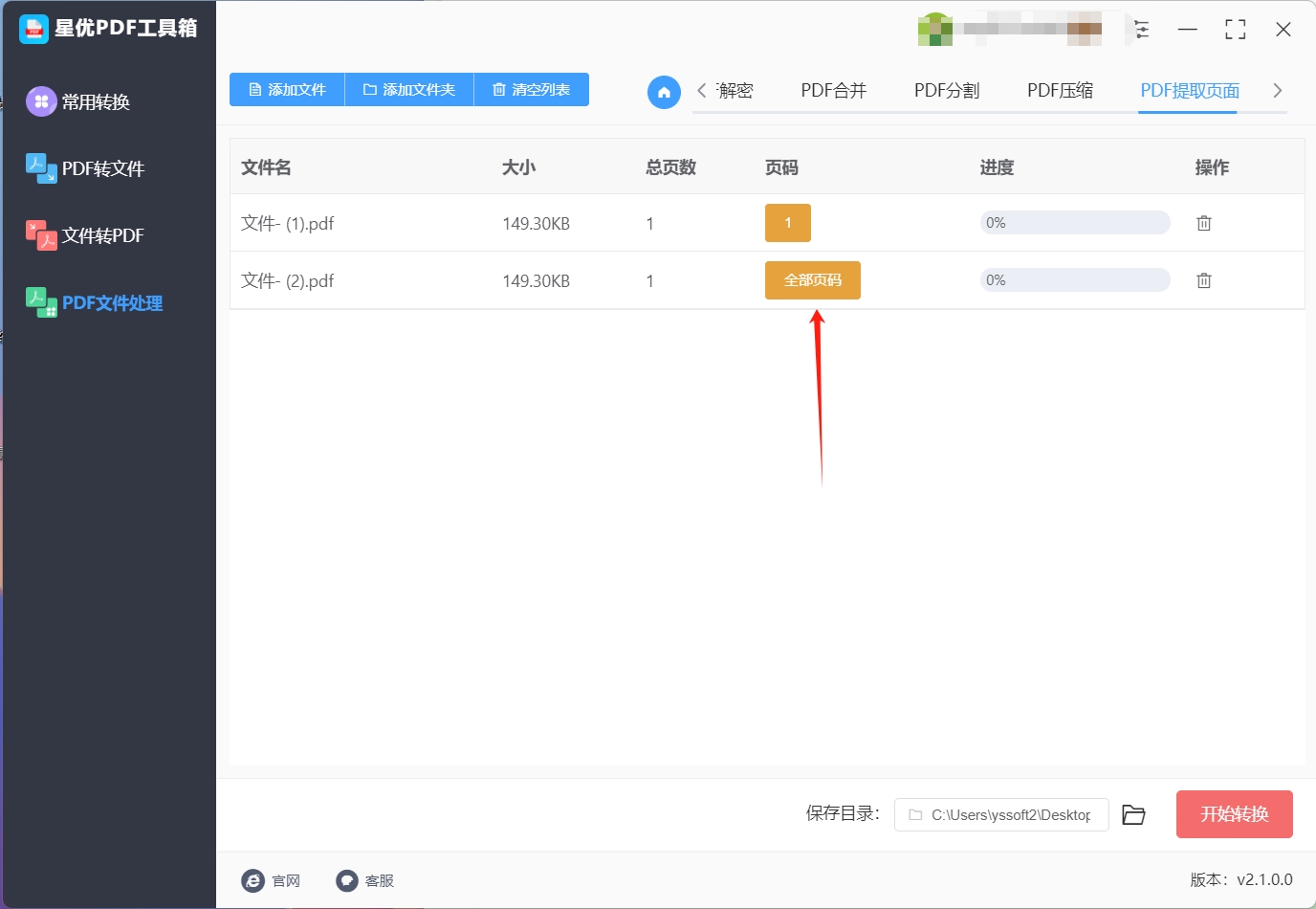
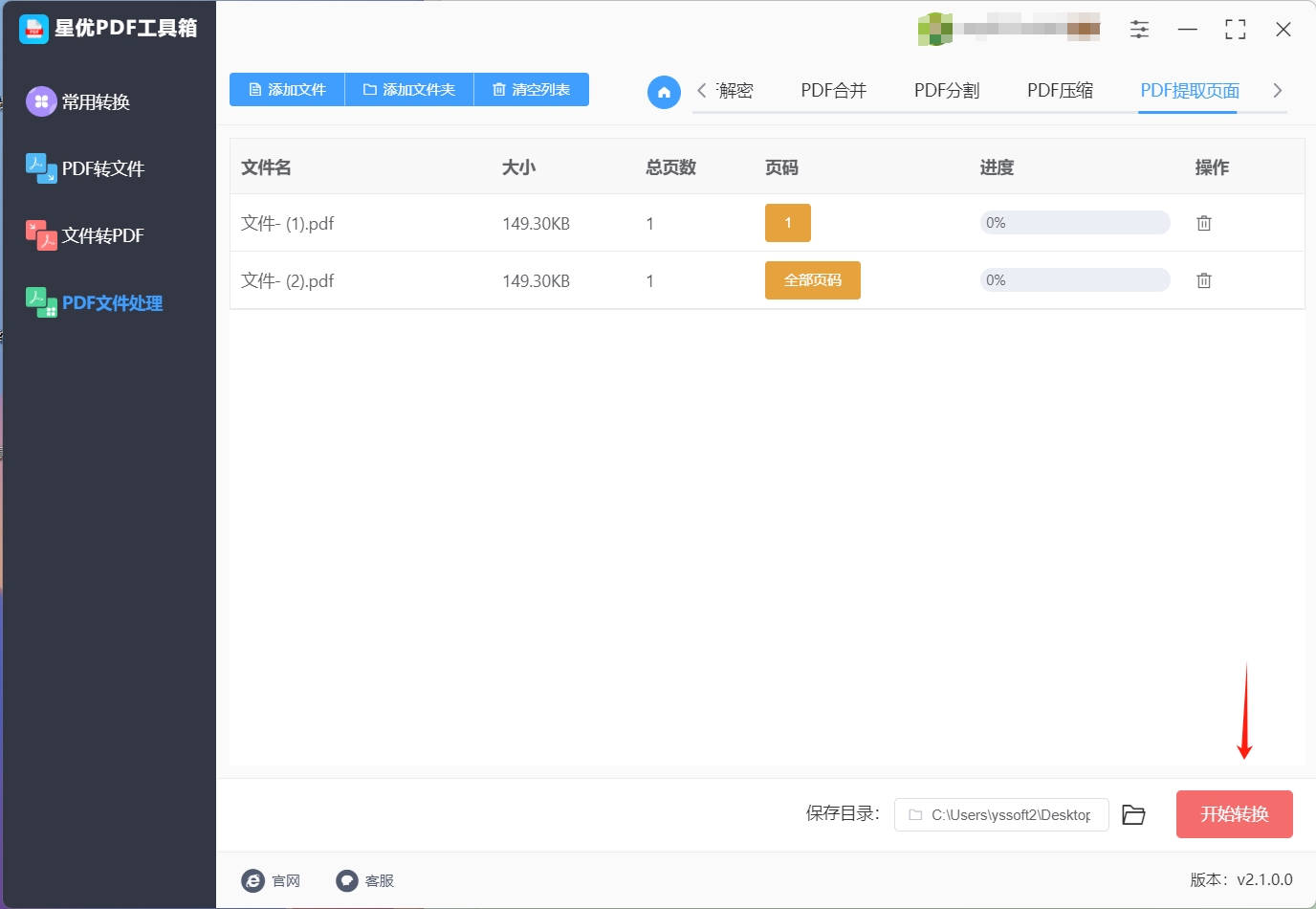
步骤4:确认设置后,点击软件界面右下角的"开始转换"按钮,启动页面提取程序。软件处理速度快,提取过程高效。
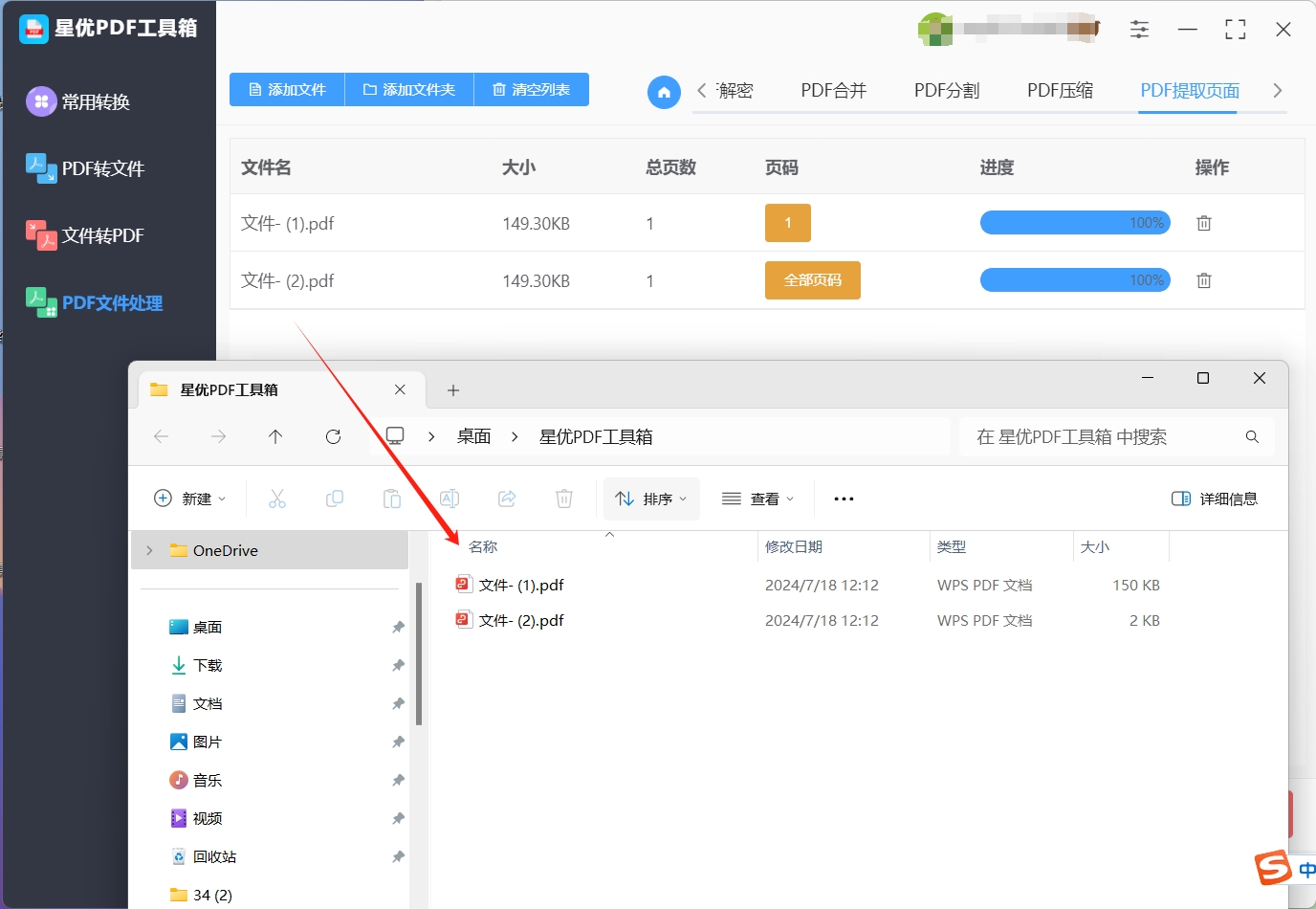
步骤5:当软件自动打开输出文件夹并显示提取完成的提示时,表明提取操作已成功完成。在输出文件夹中,你可以找到刚刚提取出的页面。
提取PDF其中一页的方法二:使用"Adobe Acrobat Reader DC"软件
- 启动Adobe Acrobat Reader DC并加载PDF文件
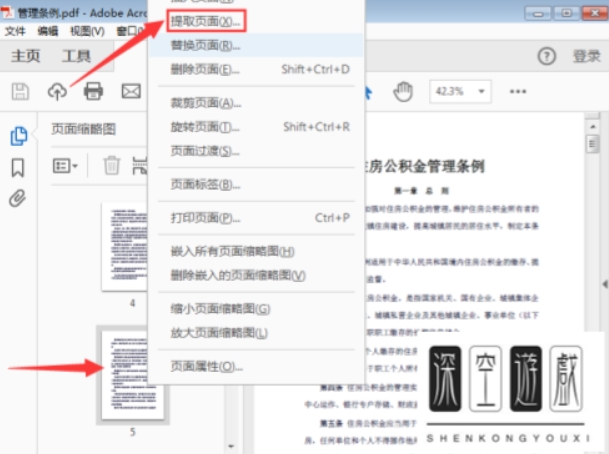
首先,确保您的计算机上已经安装了最新版本的Adobe Acrobat Reader DC。随后,双击桌面上的Adobe Acrobat Reader DC图标启动程序,或通过开始菜单中的快捷方式打开它。一旦程序启动,利用"文件"菜单中的"打开"选项,浏览并选择您希望处理的PDF文件。等待文件加载完成,您便可以在窗口中预览其全部内容。
- 导航至目标页面
使用滚动条或页面缩略图视图(如果可用),快速定位到您希望提取为JPEG图像的PDF页面。Adobe Acrobat Reader DC提供了直观的页面导航工具,让您能够轻松找到并查看文档的任何部分。
- 访问导出功能
接下来,将注意力转移到程序界面的顶部工具栏。在这里,点击"文件"菜单,展开一个包含多种文档处理选项的下拉列表。为了将PDF页面转换为JPEG格式,您需要寻找与"导出"或"另存为"相关的选项。在Adobe Acrobat Reader DC中,这通常位于"文件"菜单下的"另存为其他"子菜单中。
- 选择JPEG格式并配置导出设置
在"另存为其他"下拉菜单中,选择"图像"类别,紧接着是"JPEG"选项。这一选择将触发一个导出向导或对话框,允许您进一步自定义转换过程。在此窗口中,确保您已勾选"当前页面"选项,这样只有当前选中的页面会被转换成JPEG图像。此外,您还可以根据需要调整图像质量、分辨率等参数,以获得最佳的视觉效果和文件大小平衡。
- 保存JPEG图像
完成所有必要的设置后,点击"保存"按钮。Adobe Acrobat Reader DC将开始处理您的请求,将选定的PDF页面转换为JPEG格式,并允许您选择一个位置来保存生成的图像文件。选择一个易于记忆和访问的文件夹,并为图像文件命名,以便将来能够轻松找到它。
提取PDF其中一页的方法三:使用在线PDF工具allpdf
第一步:访问Smallpdf的温馨家园
首先,启动您的浏览器,如同开启一扇通往数字世界的大门,输入Smallpdf的网址并访问其官方网站。Smallpdf以其简洁的界面和强大的功能,等待着为您的PDF处理需求提供解决方案。
第二步:在工具海洋中精准定位
抵达Smallpdf的首页后,您会发现一个琳琅满目的PDF工具集合。此时,请像探险家一样,用您的鼠标指针仔细搜寻,直到找到"Split PDF"(拆分PDF)这一宝藏工具。点击它,就像打开了通往特定功能的大门。
第三步:上传您的PDF文件
接下来,您需要上传那个包含您心仪页面的PDF文件。点击页面上醒目的"选择文件"按钮,从您的电脑文件夹中挑选出那个文件。或者,您也可以直接将文件拖放到页面指定的上传区域,享受即刻上传的便捷。
第四步:耐心等待,见证奇迹
文件上传后,Smallpdf将迅速接管任务,开始处理您的PDF文件。请耐心等待片刻,让Smallpdf的魔法在后台悄然施展。不久,您就会看到PDF文件的缩略图列表,这标志着文件已加载完成,准备接受您的进一步操作。
第五步:精准定位,选定页面
在缩略图列表中,使用鼠标滚轮或页面下方的滑动条,轻松浏览至您想要提取的那一页。就像翻阅实体书籍一样,但更加迅速和精准。
第六步:确认并提取页面
当您找到目标页面后,只需轻轻一点,Smallpdf就会在页面右侧即时展示该页的预览图。这不仅是对选择的确认,也是对您即将获得成果的预览。确认无误后,点击"Extract Page"(提取页面)按钮,Smallpdf就会开始执行提取操作。
第七步:保存为图像,轻松下载
提取完成后,Smallpdf会将选定的页面转换为图像文件(默认为JPEG格式),并为您提供下载选项。点击"下载"按钮,就像收获辛勤劳动的成果一样,将这份珍贵的图像文件保存到您的计算机中。
第八步:享受成果,开启新篇章
下载完成后,您就可以在自己的计算机上找到并使用这个提取的图像文件了。无论是用于报告、演示还是个人收藏,这份文件都将以其清晰度和便利性,为您的工作或生活增添一份色彩。至此,您已经成功掌握了使用Smallpdf提取PDF文件中单页的方法,未来处理PDF文件时,将更加得心应手。
提取PDF其中一页的方法四:使用"Adobe Photoshop"软件
启动Adobe Photoshop:双击桌面上的Photoshop图标或通过开始菜单找到并启动它。随着软件的加载,您会看到一个充满创意可能性的工作界面。
导入PDF文件:在Photoshop的菜单栏中,仔细寻找并点击"文件"(File)选项。这将展开一个下拉菜单,其中包含了一系列与文件操作相关的命令。接下来,将鼠标悬停在"导入"(Import)上,当子菜单展开时,选择"PDF"(有时也可能是"从文件导入"并手动选择PDF格式)。
选择PDF文件:此时,一个文件浏览窗口会出现在屏幕上,允许您浏览计算机上的文件夹以找到目标PDF文件。利用窗口顶部的搜索框可以快速定位文件,或者通过左侧的文件夹树状结构逐级浏览。找到文件后,单击它以选中,然后点击窗口底部的"打开"(Open)按钮。
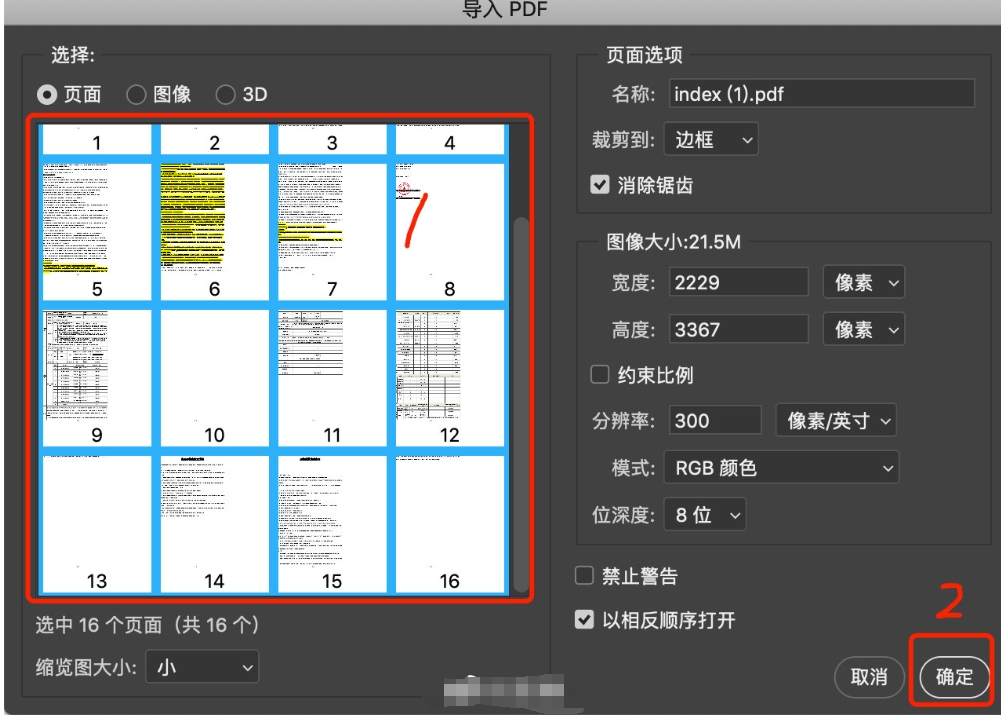
配置导入设置:一旦PDF文件被选中并打开,Photoshop会显示一个"导入PDF"对话框,该对话框提供了丰富的选项来定制您的导入过程。在"页面"(Pages)选项卡中,您可以通过勾选对应的复选框来选择想要导入的特定页面,或者选择"全部"(All)来导入整个PDF文档。此外,还可以调整页面尺寸、分辨率等参数,以满足您的具体需求。
完成导入:完成所有必要的设置后,点击对话框底部的"确定"(OK)按钮。Photoshop将开始处理选定的PDF页面,并将它们作为独立的图层或合并的图层(取决于您的设置)导入到一个新的PSD文件中。PSD是Photoshop的专有文件格式,支持丰富的图层、蒙版和效果,非常适合进行进一步编辑。
保存为其他格式:如果您需要将处理后的图像保存为JPEG、PNG或其他常用的图像格式,可以点击菜单栏中的"文件"(File),然后选择"另存为"(Save As)。在弹出的保存对话框中,选择您想要的格式,并指定文件名和保存位置。点击"保存"(Save)后,可能还需要根据所选格式调整一些输出选项,如图像质量、颜色模式等。
提取PDF其中一页的方法五:使用命令行工具(pdftoppm)
对于偏好在命令行环境中高效处理文件的专业用户而言,pdftoppm 是一个非常实用的工具,它隶属于强大的 poppler-utils 软件包,专为处理PDF文档而设计。此工具允许用户通过简洁的命令行指令,将PDF页面转换为各种图像格式,包括但不限于PPM、PNM和JPEG等,极大地增强了文档内容的可访问性和灵活性。
以下是使用 pdftoppm 工具进行PDF到JPEG转换的一个详细且丰富的示例:
引入 pdftoppm
首先,确保您的系统上已安装了 poppler-utils,因为 pdftoppm 是该软件包中的一员。在大多数Linux发行版中,您可以通过包管理器(如apt-get、yum、dnf等)轻松安装它。安装完成后,您就可以在命令行中调用 pdftoppm 了。
使用示例命令
为了将PDF文档中的页面转换为JPEG图像,您可以使用以下命令格式:
bash
pdftoppm -jpeg -f 1 -l <最后一页的页码> -singlefile input.pdf output
但请注意,原始命令中 -singlefile 的用法实际上是不正确的,因为 pdftoppm 的 -singlefile 选项并不是用来将所有页面合并成一个文件的,而是用于控制输出文件的命名方式,使得每一页的输出文件都包含相同的前缀,而不是每个文件都有独立的名称。不过,由于我们想要的是将所有页面"看似合并"为一个文件(实际上是以多个文件形式存在,但具有统一的命名前缀),我们可以忽略 -l 参数(如果不需要指定结束页码)或使用它来精确控制转换的页面范围,同时保留 -singlefile 以获得统一的文件名前缀。
正确的用法示例(假设我们想从第一页开始转换整个文档):
bash
pdftoppm -jpeg -f 1 -singlefile output input.pdf
这里:
-jpeg 指定了输出格式为JPEG。
-f 1 表示从PDF文档的第一页开始转换。
-singlefile output 告诉 pdftoppm 使用"output"作为所有输出JPEG文件的前缀,并自动为每页添加数字后缀以区分(例如,output-1.jpg, output-2.jpg 等)。
input.pdf 是您希望转换的输入PDF文件名。
通过这种方式,您不仅可以在命令行中高效地处理PDF到JPEG的转换,还能保持输出的有序性和可管理性。
这不仅使我们能够高效地管理文档,还能确保我们能够精确地选择和利用需要的信息。通过使用类似"星优PDF工具箱"这样的工具,你不仅可以轻松地提取单页或多页,还能够在操作中享受到快速和便捷的体验。这种技能不仅适用于日常办公和学术研究,也在处理报告、项目文件或文档整理时极具实用性。因此,掌握PDF提取功能不仅仅是提高工作效率的关键,也是适应数字化工作环境不可或缺的一部分。