|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 英文名称: FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs 中文名称: FunAudioLLM: 人与LLMs之间自然互动的语音理解和生成基础模型 论文地址: http://arxiv.org/abs/2407.04051v3 相关论文:https://fun-audio-llm.github.io/pdf/CosyVoice_v1.pdf 代码: https://github.com/FunAudioLLM 官网介绍:https://fun-audio-llm.github.io/ 作者: Tongyi SpeechTeam 机构: 阿里巴巴集团,通义Speech团队 日期: 2024-07-04 |
读后感
FunAudioLLM 工具集在 24 年 7 月初开源,核心包含两个语音模型:SenseVoice 和 CosyVoice。
模型(SenseVoice 和 CosyVoice)已在 Modelscope 和 Huggingface 上开源,并且 GitHub 上也发布了相应的训练、推理和微调代码。通过将这些模型与 LLMs 集成,FunAudioLLM 实现了多种应用,例如:语音到语音翻译、情感语音聊天、互动播客和富有表现力的有声书叙述。这些应用推动了语音交互技术的发展。
从算法角度来看,作者巧妙地结合了语音合成和语音识别。通过利用中间结果来优化 Speech Tokens,从而得到了效果更好的码表。
从训练数据来看,这些模型主要针对中文进行了优化。
摘要
目标:介绍 FunAudioLLM 模型家族,旨在增强人类与大型语言模型(LLMs)之间的自然语音交互。
方法:引入两个创新模型:SenseVoice 处理多语言语音识别、情感识别和音频事件检测;CosyVoice 促进多语言语音生成,具有对多种语言、音色、说话风格和说话人身份的控制。
结论:SenseVoice-Small 为 中文、英文、粤语、日文、韩文 5 种语言提供极低延迟的 ASR,性能比 Whisper-small 快 5 倍以上;SenseVoice-Large 支持 50 余种语言的高精度 ASR,在中文和粤语方面相较 Whisper 提升很大。CosyVoice 支持五种语言:中文、英文、日文、粤语和韩文,在零次学习上下文、跨语言语音克隆和遵循指令等方面表现出色。
1 FunAudioLLM 模型
1.1 FunAudioLLM 概述
SenseVoice 支持多语言语音识别,经过超过 300k 小时的训练。
CosyVoice 可以生成多语言语音,经过超过 170k 小时的训练,支持五种语言,包括中文(ZH)、英文(EN)、日语(JP)、粤语(Yue)和韩语(KO)。
1.2 语音理解模型:SenseVoice

图 2:SenseVoice 旨在执行各种语音理解任务,包括自动语音识别(ASR)、语言识别(LID)、语音情感识别(SER)和音频事件检测(AED)。SenseVoice-Small(上):这是一款专为快速语音理解而优化的仅编码器模型。它提供高速处理,同时支持五种语言。SenseVoice-Large(下):这是一种编码器 - 解码器模型,旨在实现更广泛语言范围内更精确的语音理解。
SenseVoice-Small 是一个非自回归的编码器模型,适用于多语言、多风格的语音识别以及多个语音理解任务。对于给定输入的音频波形,首先计算 80 维的对数梅尔滤波器组特征,然后将连续帧堆叠并下采样 6 倍。这些提取特征被映射到编码器的维度,记为𝑋speech∈ℝ𝑇×𝐷,其中𝑇是下采样特征的长度。编码器是一个带有记忆功能的自注意力网络。为了指定任务,在语音特征前添加四个嵌入,作为编码器的输入。

𝑉′ 是词汇表,包括用于 ASR 和其他任务的令牌,e 是四个任务嵌入:
- LID:语音对应的语言,如:中/英文。
- SER:语音情感标签,如:高兴、悲伤、生气、害怕等。
- AEC:音频事件标签,如:音乐、掌声和笑声等。
- ITN/NoITN:将语音转换成带有或不带正确标点和格式的文字。
在训练阶段,LID、SER 和 AEC 任务使用交叉熵损失进行优化。ASR 任务使用 CTC 损失进行优化,它的输入输出均为序列数据,CTC 损失的最大优点是能够处理输入和输出序列长度不一致的情况,并允许网络在输出序列中插入空白符号。
SenseVoice-Large 是一种自回归编码器 - 解码器模型,专用于多语言语音识别(ASR)和多种语音理解任务。类似于 Whisper,SenseVoice-Large 通过一系列输入令牌到解码器来指定任务。
SenseVoice 具有强大的富文本识别能力,不仅能识别情感,还支持声音事件检测功能。它可以检测到音乐、掌声、笑声、哭声、咳嗽和喷嚏等多种常见的人机交互事件。从表 1 中可以看到,SenseVoice 识别到的情绪符号如下:

1.3 语义语音分词器
语音标记器将语音信号转换为离散标记 (原理见 论文阅读_语音表示_HuBERT),从而可以通过自回归转换器进行建模和预测以生成语音。无监督或自监督训练的分词器通常与语义内容的关联较弱,导致合成过程不稳定,并且对干净的训练数据需求量大。
在 SenseVoice 模型成功的基础上,作者引入了一种监督语义语音标记器,称为 S3。
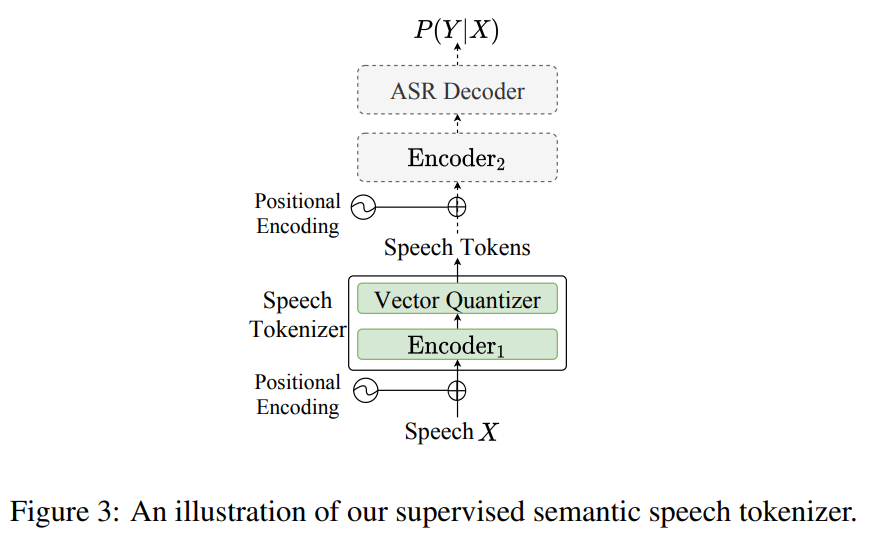
基于预训练的 SenseVoice-Large 模型,在编码器的前六层后加入了一个向量量化器,如图 -3 所示。量化后加入了额外的位置嵌入以增强时间信息。Encoder1 和向量量化器组合后作为语音分词器 ,使用最接近码向量的索引作为语音标记。此向量量化器使用一个包含 4,096 个条目的大词典。得到的标记序列频率为 50 Hz,从而减少了语言模型中从文本到标记生成的计算负担。
由于语音分词器经过端到端训练以减少文本识别错误,提取的标记与文本和副语言信息有很强的语义关系。此外,S3 分词器通过监督训练,提高了对数据噪声的鲁棒性,减少了对高质量数据收集的依赖,因此可以使用更广泛的数据来训练模型。这优化了后续的语音合成模型。
|500
1.4 语音合成模型:CosyVoice
CosyVoice 是一种语音生成模型,能够生成自然的语音,适用于多种应用场景。它可以处理多语言语音生成,在没有训练的情况下适应新说话者,跨语言复制声音,创建带有情感的语音,并通过指令文本对语音输出进行精细调整。CosyVoice 支持五种语言,包括中文、英语、日语、粤语和韩语。
我们推出了三个开源模型:第一个是 CosyVoice-base-300M,它擅长准确代表说话者身份,无需微调即可适应不同上下文,还可以跨语言克隆声音 。第二个是 CosyVoice-instruct-300M,它擅长生成带有情感的语音,并允许通过指令文本进行精细调整。最后一个是 CosyVoice-sft-300M,该模型在七个多语言说话者上进行了微调,可以立即使用。这些模型共享相同的架构和学习框架。
1.4.1 CosyVoice 原理
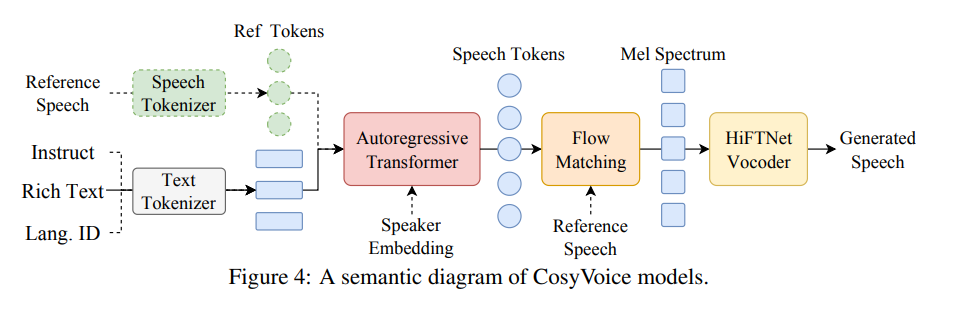
CosyVoice 结合了基于 Transformer 的自回归语言模型(LM),为输入文本生成语音标记。出下内容来自 CosyVoice 论文。
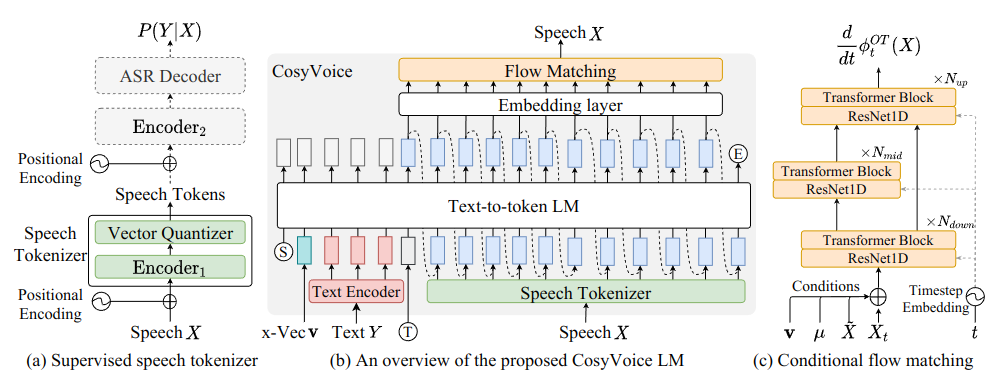
如图 1 所示,其中 b 为主图,a 和 c 分别与绿色和黄色模块相关。CosyVoice 由四个组件组成:文本编码器(红)、语音标记器(绿)、大型语言模型(白)和条件流匹配模型(黄)。
1.4.1.1 有监督语音的语义标记
在 CosyVoice 中,使用了一个有监督的自动语音识别(ASR)模型来生成语音的语义标记,如图 1(a) 所示。这个模型是阿里自有的 SenseVoice ASR 模型的微调版本。不同于原始的 ASR 模型,这里将编码器分成两部分,并在中间插入一个矢量量化层。输入一个 Mel 频谱图后,它会经过位置编码和第一个编码器,以获得上下文感知的表示:
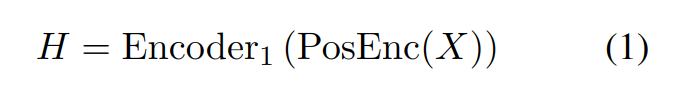
|350
接下来,使用向量量化器(VQ)来获得离散的语音标记。在每个时间点,最近的嵌入索引作为语音标记。计算公式为:
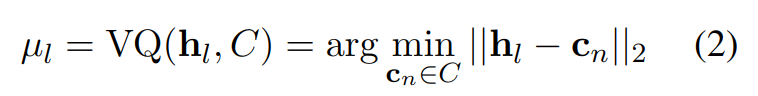
|400
训练阶段,通过指数移动平均(EMA)更新码表嵌入:
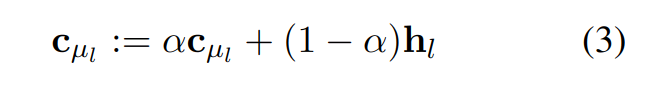
|300
其中α是预设的衰减系数。这些更新后的代表嵌入作为量化后的隐藏表示,传递给剩余的编码器层进行处理:
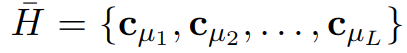
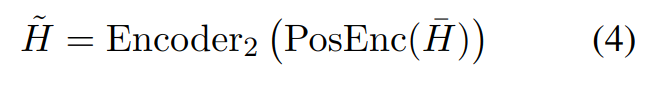
300
在后面的编码层之前,我们添加了一个额外的位置编码来增强时间信息。在 Encoder2 之后,跟随一个基于 transformer 的 ASR 解码器,预测文本标签的后验概率。
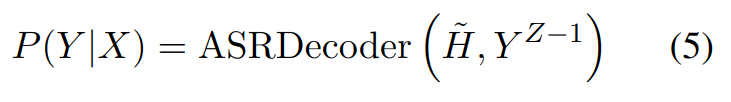
|300
小编说:与其它工具相比,在 ASR 过程中产出的 speech tokens,可将它看作是码表的调优。
1.4.1.2 TTS 的大型语言模型
将 TTS 任务表示为使用大语言模型(LLM)的自回归语音生成问题。对于 LLM,序列构建是最重要的,如下所示:
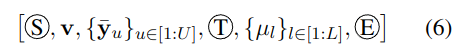
|300
开始 S 和结束 E 表示序列的起始和结束。v 是从语音 X 中提取的说话人嵌入向量,通过预训练声纹模型获得。文本编码是通过将文本传递给字节对编码(BPE)分词器和文本编码器得到的:
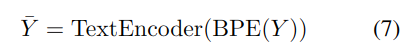
|300
由于文本和语音标记在不同的语义层次上,因此使用文本编码器进行对齐。
在训练阶段,使用教师强迫机制,即用左移的序列作为模型输入,原始序列作为期望输出。
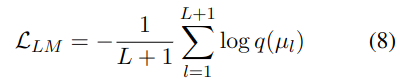
|300
1.4.1.3 最优传输条件流匹配
CosyVoice 使用了一种称为最优传输条件流匹配模型(OT-CFM)的方法,来学习 Mel 频谱图的分布,并根据生成的语音标记来生成样本。在连续时间规范化流(CNFs)中,它从一个初始分布到 Mel 频谱图的数据分布之间构建了一条概率路径。如图 1(c) 所示。
该方法通过一个随时间变化的矢量场来描述语音信号的变化,这个矢量场由一个神经网络来学习。通过解决一个特定的数学问题,即常微分方程,我们可以近似生成语音的分布,并从中采样生成语音。
在训练阶段,自回归语言模型(LM)使用教师强制范式进行训练。此过程中,提供标记化文本和左移版本的语音令牌作为输入,以预测后续的语音令牌(Speech tokens)。
1.4.2 模型训练
在训练阶段,自回归语言模型(LM)采用教师强制范式进行训练。在此过程中,输入的是左移版本的标记化文本和语音令牌,以预测后续的语音令牌(Speech tokens)。
流匹配模型(The flow matching model)用于估计条件概率 P(S|X, v, Sref)。其中,X 和 v 分别表示语音片段和说话人嵌入,S 和 Sref 分别表示目标和参考语音的梅尔频谱。该模型使用卷积 Transformer U-Net 来确定最优传输 ODE 中先验分布与目标分布之间的矢量场。在推理阶段,只需五到十次迭代即可生成令人满意的梅尔频谱图。此外,还采用无分类器指导技术,通过屏蔽 70% 到 100% 的前置特征条件来增强上下文学习能力。
在从预测的梅尔频谱图合成波形时,我们使用改进的 HiFTNet 声码器,以支持流式生成。详细调整请参见代码发布。
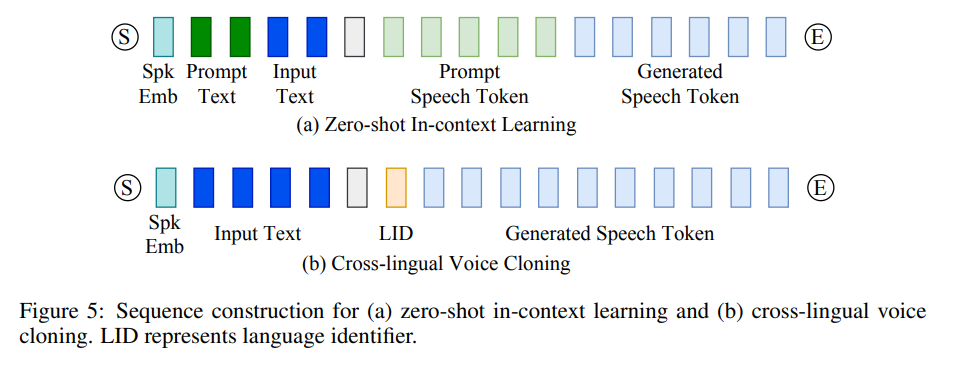
1.4.3 零样本上下文学习
CosyVoice 模型具有零样本上下文学习能力,只需一个简短的语音样本就能复刻任意声音。在过程中,需要构建输入序列,如图 5 所示。对于同一语言的提示语音和输入文本,将它们合并成一个统一的输入,并将提示语音标记视为预生成内容。使用这个输入序列,自回归 LM 会逐步预测下一个标记,直到遇到"序列结束"标记 E。如果提示语音和输入文本是不同语言,会忽略与提示相关的文本和标记,以防止原语言韵律特征影响目标语言。提示文本(Prompt Text)可以通过人工注释或 ASR 模型(如 SenseVoice)进行转录,而提示标记(Prompt Speech Token)是通过 S3 分词器从提示语音中提取出来的。
在生成语音标记后,将其附加在提示标记之后,形成一个复合条件以供流匹配模型使用。此外,还会结合说话人的嵌入(Spk Emb)和 Mel 频谱图,以进一步增强音色和环境的一致性。
1.4.4 指令微调
为了提升 CosyVoice 的可控性,我们进行了额外的指令微调实验。CosyVoice-instruct 在 CosyVoice-base 的基础上增强了指令跟随能力,支持对说话人身份(即说话者的特征)、说话风格(包括情感、性别、语速和音高)以及细粒度副语言特征的控制。这些特征包括插入笑声、呼吸声、边笑边说以及强调某些词。表 3 展示了说话人身份、说话风格和细粒度副语言特征的一些例子。

2 数据集
2.1 SenseVoice 的训练集
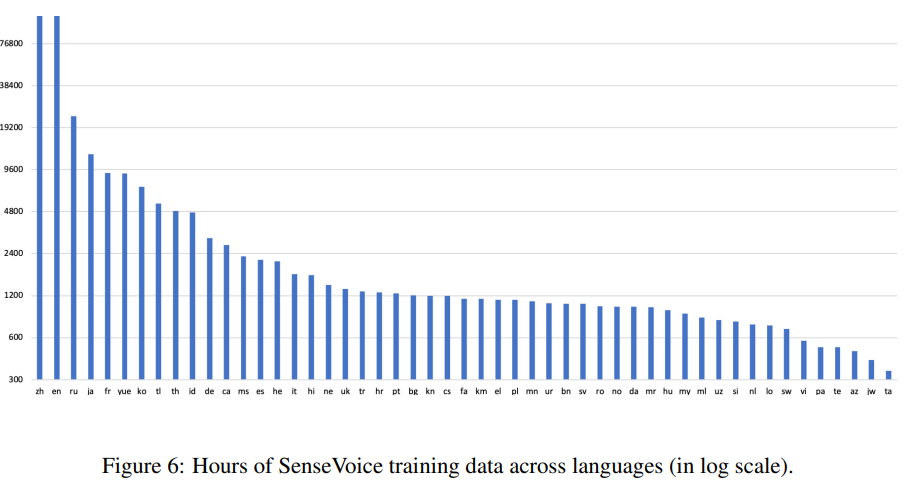
SenseVoice-Small 模型在大约 30 万小时的广泛音频数据语料上进行了训练,涵盖中文、粤语、英语、日语和韩语等五种语言。为进一步提升 SenseVoice-Large 的多语种能力,训练语料库中额外整合了 10 万小时的多语种数据。
为了从语音数据中获得丰富的转录标签,我们利用开源的音频事件检测(AED)和语音情感识别(SER)模型来生成伪标签,从而产生广泛而丰富的转录数据集。具体来说,AED 数据为 1.5 亿个条目,而 SER 数据为 3000 万个条目。
2.2 CosyVoice 的训练集
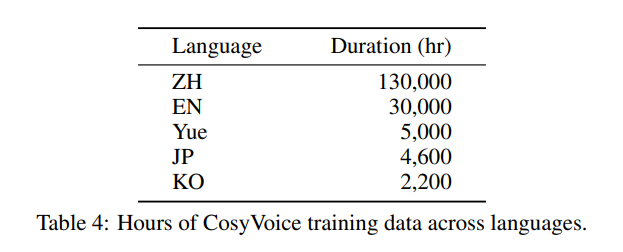
我们使用专门的内部工具进行语音检测、信噪比(SNR)估计、说话人分类和分离。随后,利用 SenseVoice-Large 和 Paraformer 生成伪文本标签。通过力对齐(FA)模型,这些标签得到了细化。这有助于消除低质量数据并提高标点符号的准确性。表 4 提供了各种语言的训练数据持续时间的全面细分。
|400
3 实验
3.1 语音识别
使用字符错误率(CER)评估五种语言的模型:中文、粤语、日语、韩语和泰语。使用单词错误率(WER)评估所有其他语言的模型。
表 6 中的结果展示了 Whisper、SenseVoice 和 Paraformer 的比较。
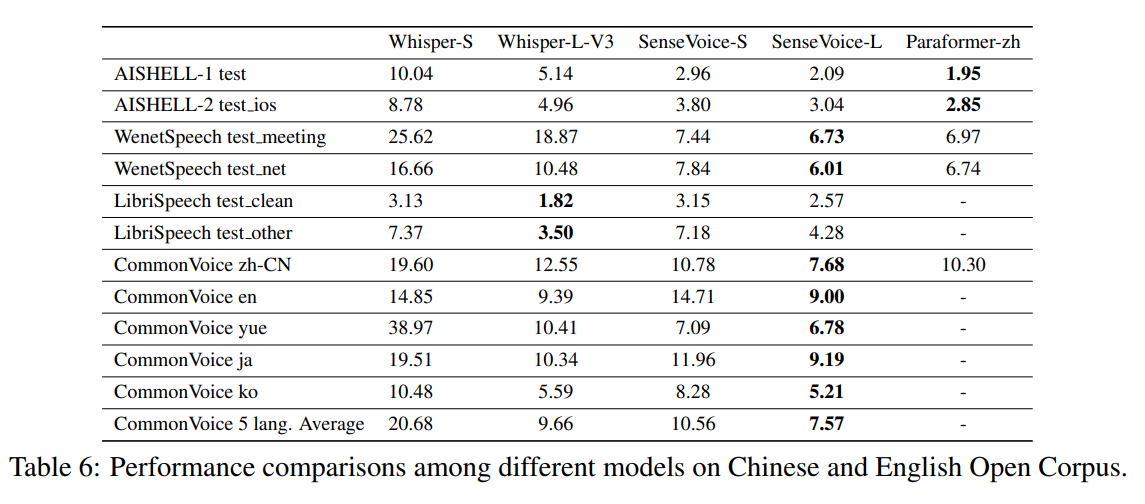
(小编说,之前使用阿里 FunASR 工具集语音识别,在主观体验上,中文方面就已经优于 Whisper)
模型参数比较如表 -7 所示。其中,实时因子(RTF,即转录时间与音频长度的比率)和 10 秒音频延迟(转录 10 秒音频时的平均时间成本)在 A800 机器上进行了基准测试。
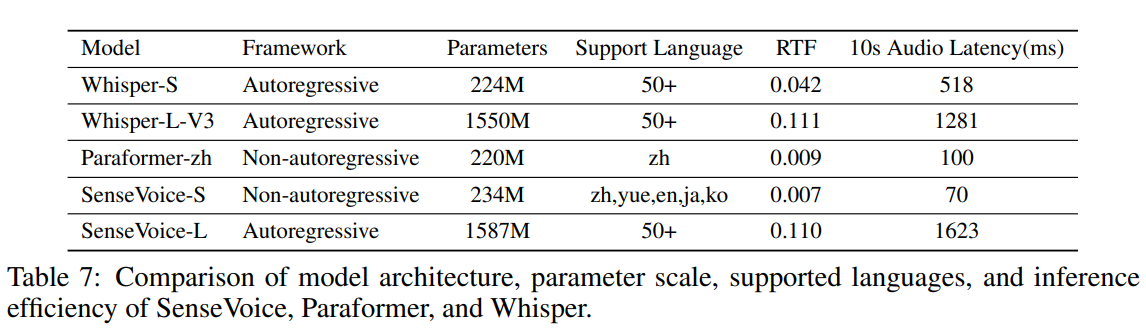
其它实验的几个指标比较小众,就不在这里贴了。
3.2 语音合成
3.2.1 语音合成质量
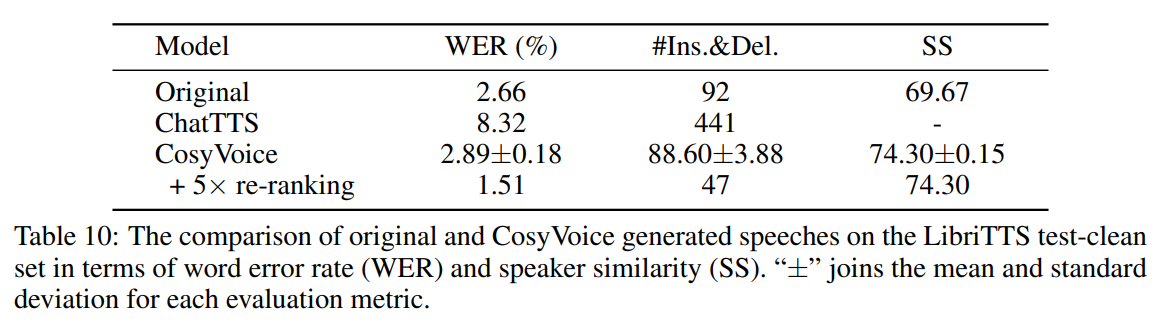
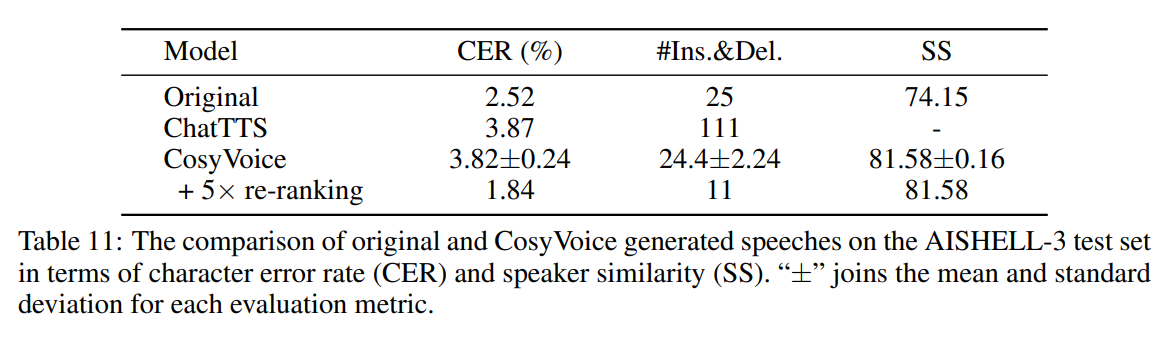
通过检查内容一致性和说话人相似性来评估 CosyVoice 语音合成的质量。
表 10 和表 11 分别列出了英文和中文的结果,对单词错误率(WER)和说话人相似度(SS)的比较。"±"连接每个评估指标的均值和标准差。
3.2.2 语音合成情感
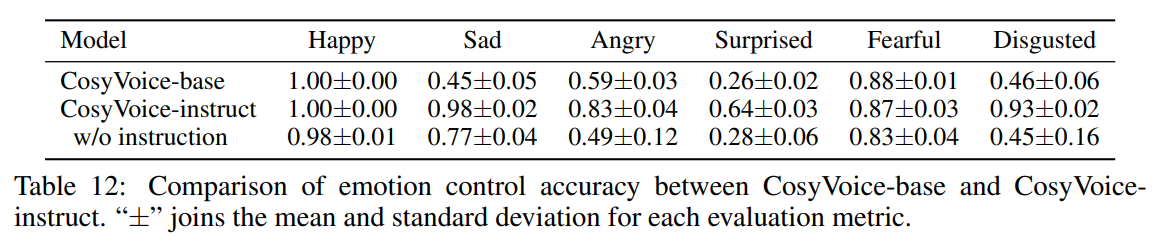
为六种情绪中的每一种生成并评估 100 个英语话语:快乐、愤怒、悲伤、惊讶、恐惧和厌恶。合成文本的内容旨在匹配目标情感。对 CosyVoice-base 和 CosyVoice-instruct 的情绪控制准确率比较。
4 应用
通过集成 SenseVoice、CosyVoice 和 LLMs,FunAudioLLM 提供了多种丰富的应用演示,包括语音到语音翻译、情感语音聊天、交互式播客和富有表现力的有声读物旁白。演示版本为 https://fun-audio-llm.github.io。
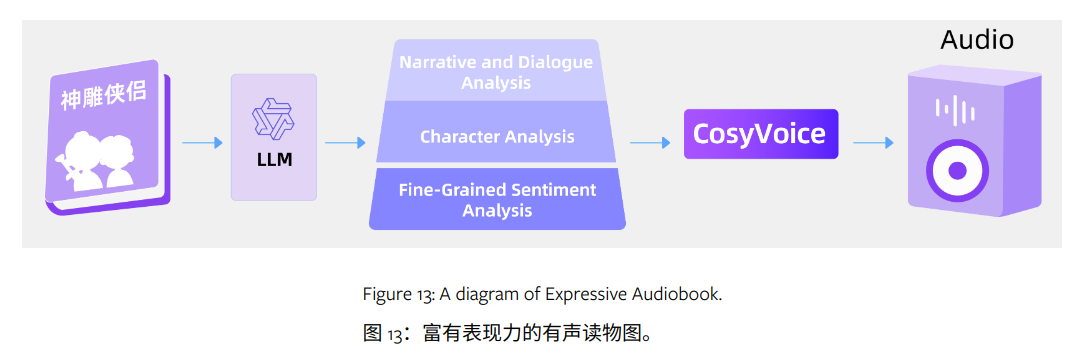
例如:通过利用 LLMs 的分析能力来识别书中的情感,并将其与 CosyVoice 结合,我们实现了具有增强表现力的有声读物,如图 13 所示。LLMs 用于叙述和对话分析、角色分析及细粒度情感分析,而 CosyVoice 则以增强的表现力合成语音。
5 试用
如果机器本身已经有了 PyTorch 2.0+ 的深度学习环境,那么配置环境会非常快。
|-------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 | $ git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git $ cd CosyVoice $ pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com $ mkdir pretrained_models -p $ git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M $ git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT $ git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct $ python webui.py |
注意:
- 如果在 Docker 内部启动,请修改 webui.py 中的 server_name 为 '0.0.0.0',并且不要忘记映射端口号。
- 如果需要使用 instruct 模型,请在运行时指定:--model_dir pretrained_models/CosyVoice-300M-Instruct/
- instruct 的提示词请参考其论文表 3 中的示例,很多自己想到的内容可能不起作用。
6 参考
7 使用体验
(仅代表我个人观点)
- 资源和效能
- 模型非常小,仅 300M,资源占用方面非常友好。
- 使用 1080ti GPU 的机器上,每秒处理 8 个字,对话基本够用。
- 依赖 torch 代码,所以 image 并不小,最好与其他深度学习模型共用库。
- 使用体验
- 整体体验不错,但没有特别惊艳。官方示例效果很好,建议自己亲自试试。
- 声音清晰度没问题,可以感觉到训练数据是高品质的。
- 合成后的声效虽然不是标准播音腔,但相对自然。
- 音色克隆效果尚可,不能期望录 3-6 秒就能完全复刻韵律,韵律还通过文本设定。
- gradio 界面设计良好,一键启动自动下载,关键元素清晰明了,学习成本低。还在 gradio 中增加了录制功能,方便复刻自己的声音。
- 论文中列出的提示词效果很好,用他示例的提示词唤出了我想要的声优效果;但其它自己写的不太行。不确定模型对哪些提示词更敏感。
- 测试 sft 中七个声音的精调(设置 seed 无效),达不到声优效果。
- 需要提示工程:找到合适的提示词和好的声音 seed 组合可能会有很好的效果,但必须一个一个去尝试。
- 可控度没有想象中那么好,用不同的 seed 也没有 ChatTTS 生成的个性化程度高。