商品超卖的解决方案
1、加锁排队
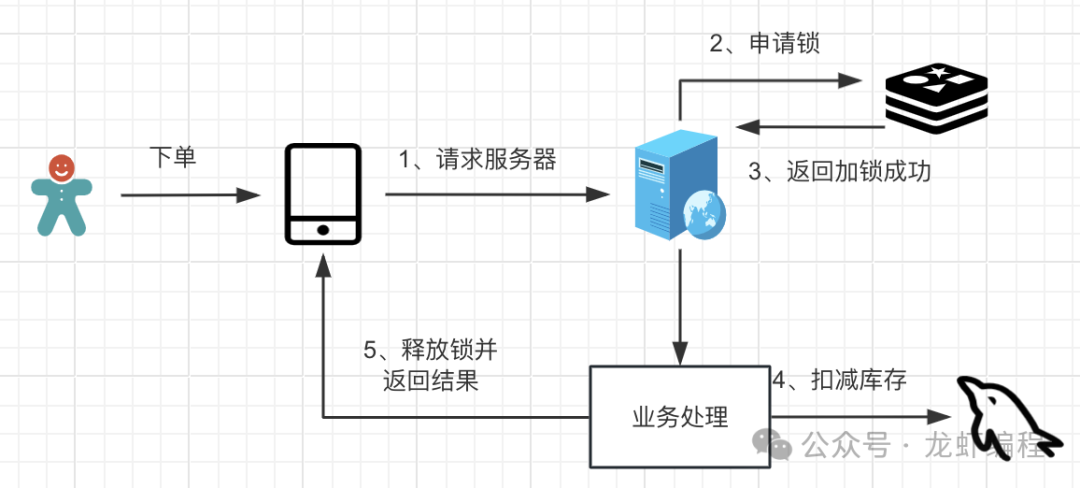
原理:通过加锁的方式让线程排队处理业务,这种方式实现简单,但是高高并发下效率不高。
2、update语句限制
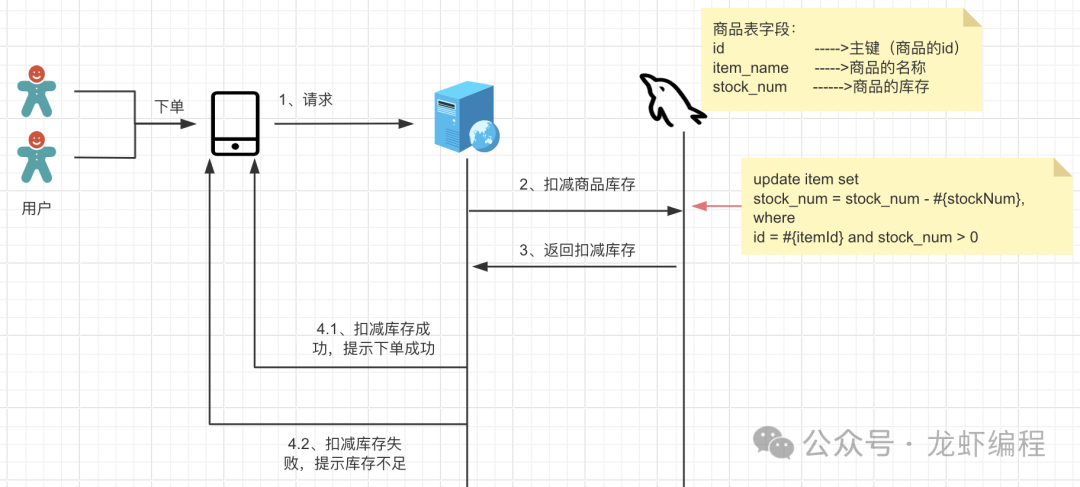
原理:在扣减库存的时候,sql更新上将库存大于0作为一个条件更新数据然后返回的影响行数:
(1)如果影响行数> 0,表示扣减库存成功
(2)如果影响行数<0,表示扣减库存失败
通过这种方式可以很好的防止超卖问题的出现,但是本方案不适用于在高并发场景下的使用,因为数据库将成为瓶颈。
3、数据库乐观锁方式
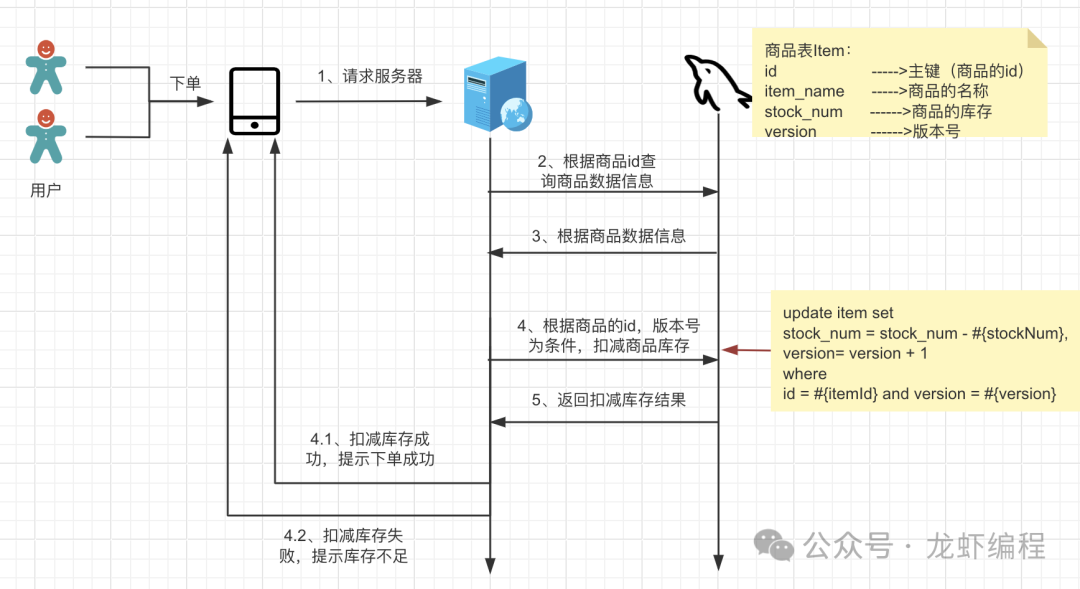
原理:在商品表中增加一个字段version,每次在更新的时候带上version字段作为更新的条件,然后返回的影响行数:
(1)如果影响行数> 0,表示扣减库存成功
(2)如果影响行数<0,表示扣减库存失败
4、临时表的方式
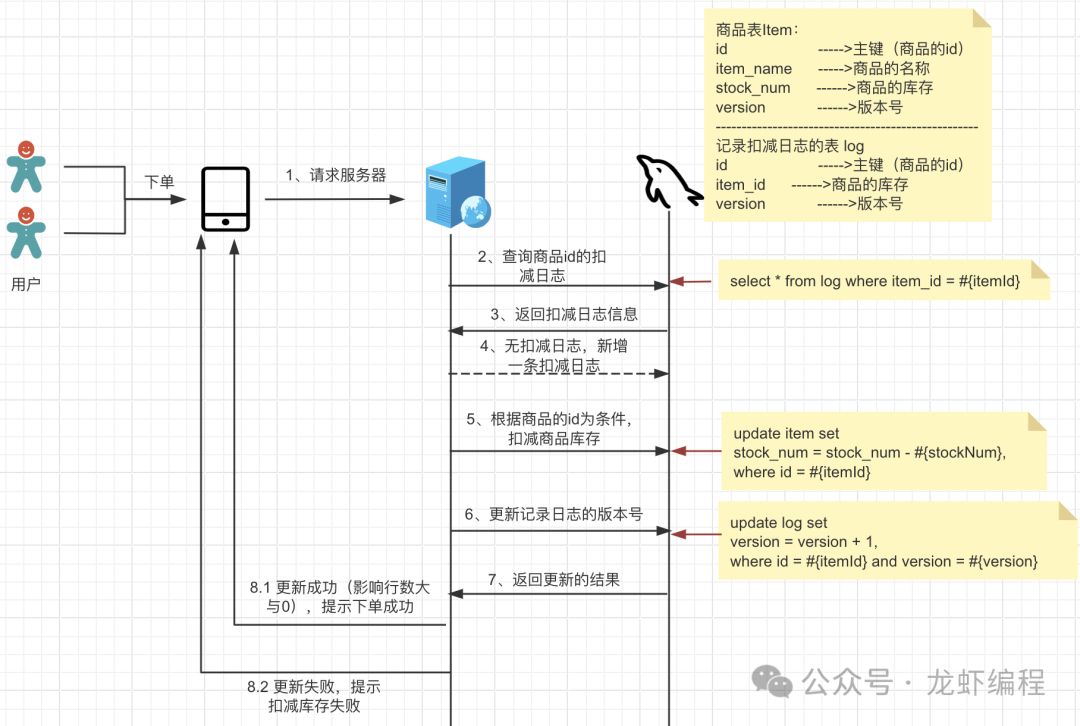
原理:扣减库存的时候,都要先查询日志表(第一次日志表没有的时候让线程创建一条数据插入的到数据库),然后执行扣减库存的操作,在扣减库存的时候可能会出现超卖的问题,但是在更新日志表的版本的是判断当前的版本是否被其他的线程操作过,如果被其他线程操作过就提示扣减库存失败,本次操作无效并会滚数据库数据。这样可以防止超卖的问题。
5、redis提前存入库存方式
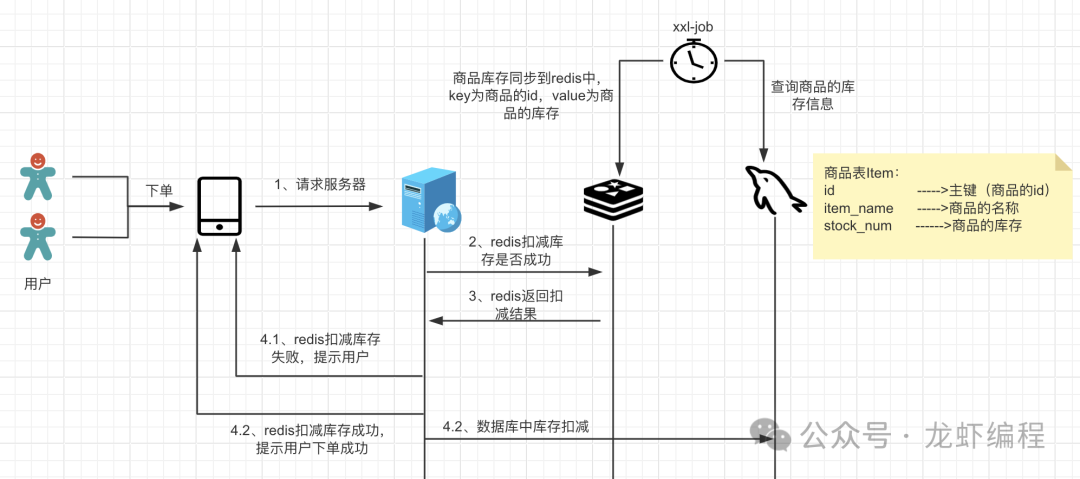
原理:使用定时任务(如xxl-job)在商品开售的之前将商品的库存信息存放到redis中(key是商品的id,value为商品的库存),用户下单的时候先在redis扣减(使用redis的decrby命令)库存,如果扣减后大于0,就允许用户下单,反之不可以让用户下单。这样也可以很好地防止超卖现象的问题发生。
总结:以上整理几种常见的防止库存超卖的解决方案,我们需要根据实际的业务场景选择合适的方案来解决。在高并发下建议采用redis提前存库存的方案,因为此方案的性能更好。针对业务并发量不高的场景建议使用锁方式、update语句限制方式、乐观锁锁来实现,因为实现起来简单、高效。
负载均衡原理
负载均衡
负载均衡,全称是Load Balancing,很多时候我们简称"LB",它可以在多个服务器、或其他资源之间,分配工作负载。
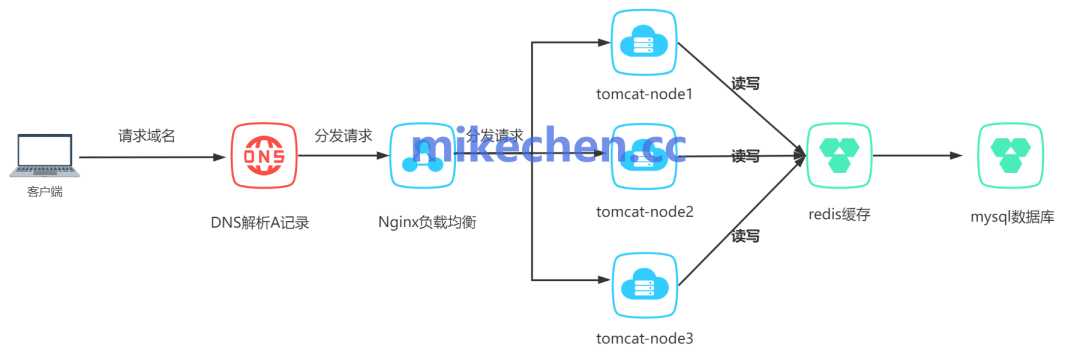
通过增加服务器数量,比如:上图的tomcat-node1、tomcat-node2、tomcat-node3...等服务器。
然后通过Nginx负载均衡技术,来有提高系统的处理能力、和可靠性,这就是典型的负载均衡。
原 理
客户端的请求,首先到达负载均衡器,然后负载均衡器根据**:调度算法,**将请求分发到不同的服务器上。
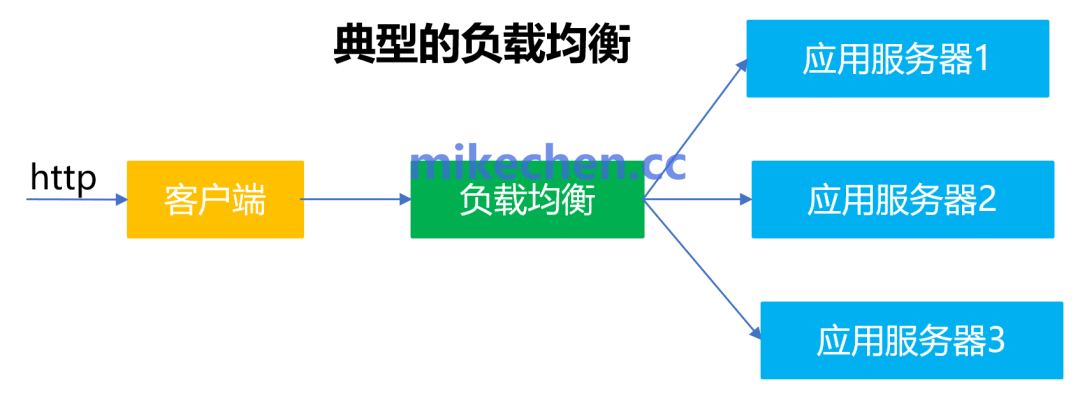
这里的"调度算法",典型的有:轮询 (Round Robin)、加权轮询 (Weighted Round Robin)、最小连接数 (Least Connections)...等等。
轮询 (Round Robin)
轮询算法:是最简单的一种负载均衡算法,它将请求按顺序分配给每一个服务器,循环进行。
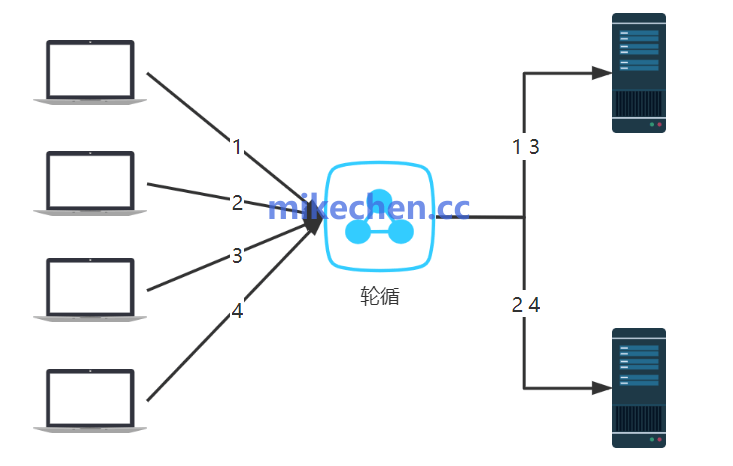
优点:
实现简单;适用于服务器性能相近的情况。
缺点:
未考虑服务器当前的负载和处理能力,不适用于服务器性能差异较大的场景。
应用:
适用于性能相近的服务器。
加权轮询 (Weighted Round Robin)
加权轮询算法:在轮询的基础上,为每个服务器分配一个权重,权重越高的服务器接收的请求越多。
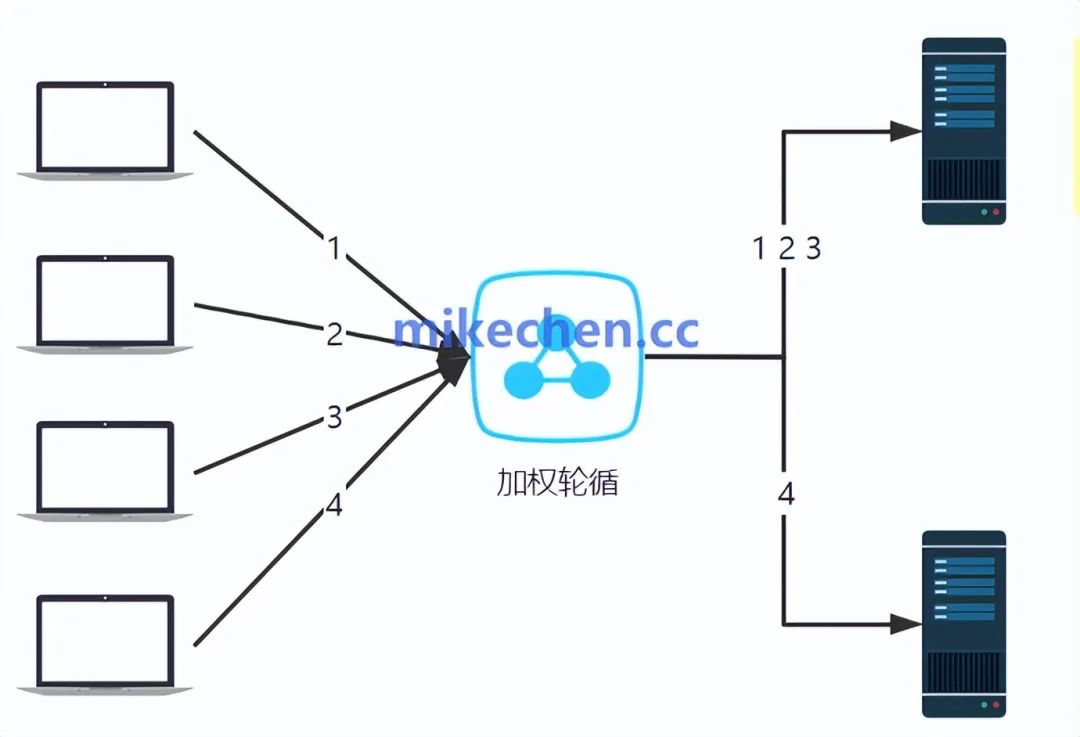
负载均衡器按照设定的权重值,将客户端的请求依次分发给后端服务器,权重大的服务器在每轮轮询中接收的请求更多。
还是,还是举一个例子:
-
服务器A的权重为5
-
服务器B的权重为3
-
服务器C的权重为2
在这种情况下,负载均衡器会按照以下顺序分发10个请求:A, A, A, A, A, B, B, B, C, C。
加权轮询,适用于以下场景:
系统中包含不同性能的服务器,需要根据其处理能力分配不同数量的请求。
最小连接数 (Least Connections)
优先将请求分配给当前连接数最少的服务器,适用于长连接应用。
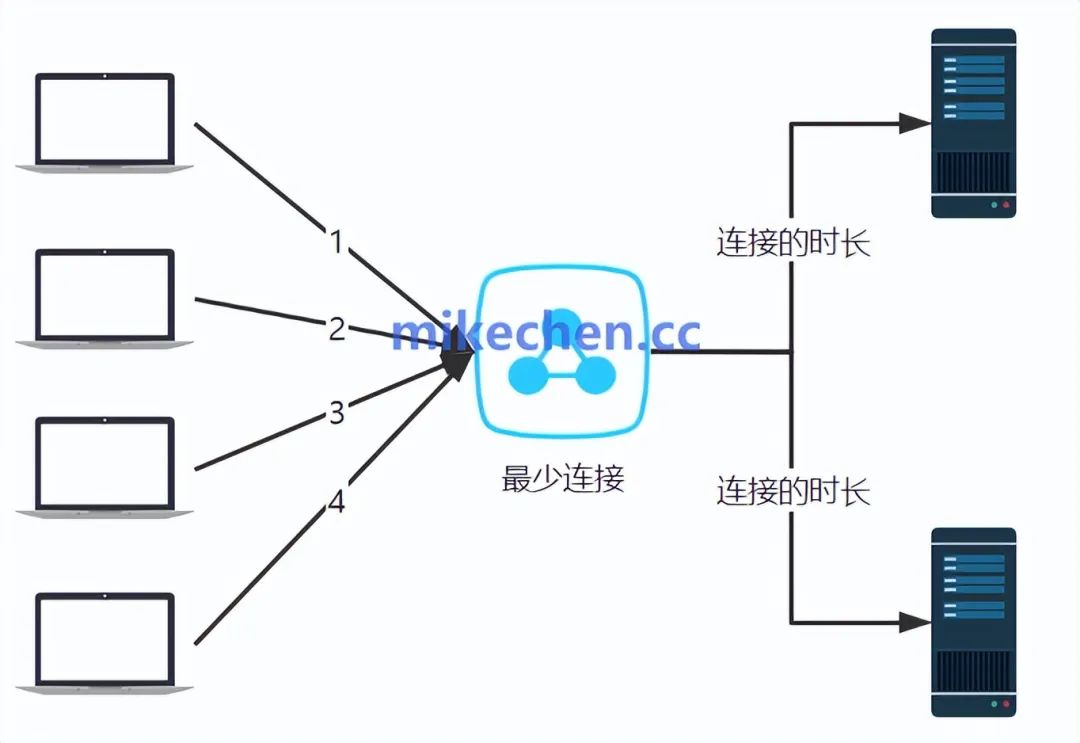
例如,假设有三台服务器A、B、C,当前连接数分别为3、5、2。
当一个新请求到达时,该请求将被分配给服务器C,因为它的活动连接数最少。
最少连接算法,适用于以下场景:
-
长连接应用:如数据库连接、视频流媒体、聊天服务...等需要长时间保持连接的应用,在这些场景中,最少连接算法能较好地平衡负载;
-
性能异构的服务器:当服务器性能差异不大,但负载波动较大时,最少连接算法能动态调整负载分配,避免某些服务器过载;
-
需要高实时性负载均衡的应用:如实时游戏、在线交易......等需要快速响应的应用,通过最少连接算法能减少响应时间,提高用户体验。
IP哈希 (IP Hash)
IP哈希(IP Hash)是一种负载均衡算法,通过对客户端IP地址进行哈希运算,将请求分配到特定的服务器。
负载均衡器使用一个哈希函数,将客户端的IP地址转换为一个整数值,根据哈希值对服务器数量取模,将客户端请求分配给计算得到的服务器。
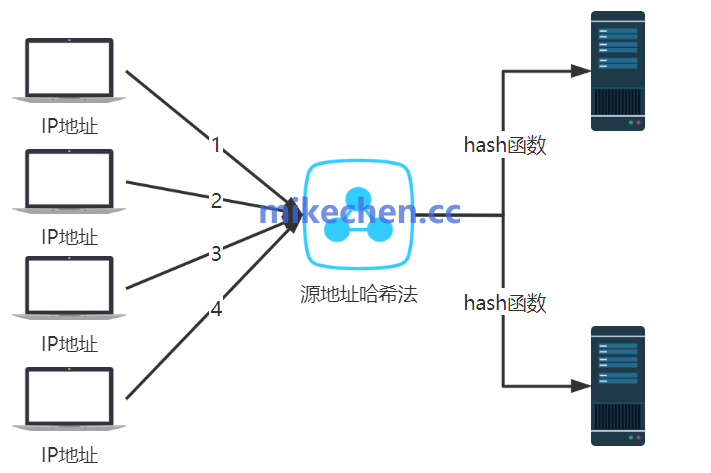
假设有:三台服务器:Server A、Server B、Server C,客户端IP地址是:192.168.0.1。
假如,哈希函数计算结果是:12345。
取模运算:12345 % 3 = 0,故请求分配给Server A。
同一客户端IP地址的请求总是分配给相同的服务器,非常适合需要保持会话状态的应用。
负载均衡分类
负载均衡根据工作在网络协议栈中的不同层次,可以分为:二层(数据链路层)、三层(网络层)、四层(传输层),以及七层(应用层)负载均衡。
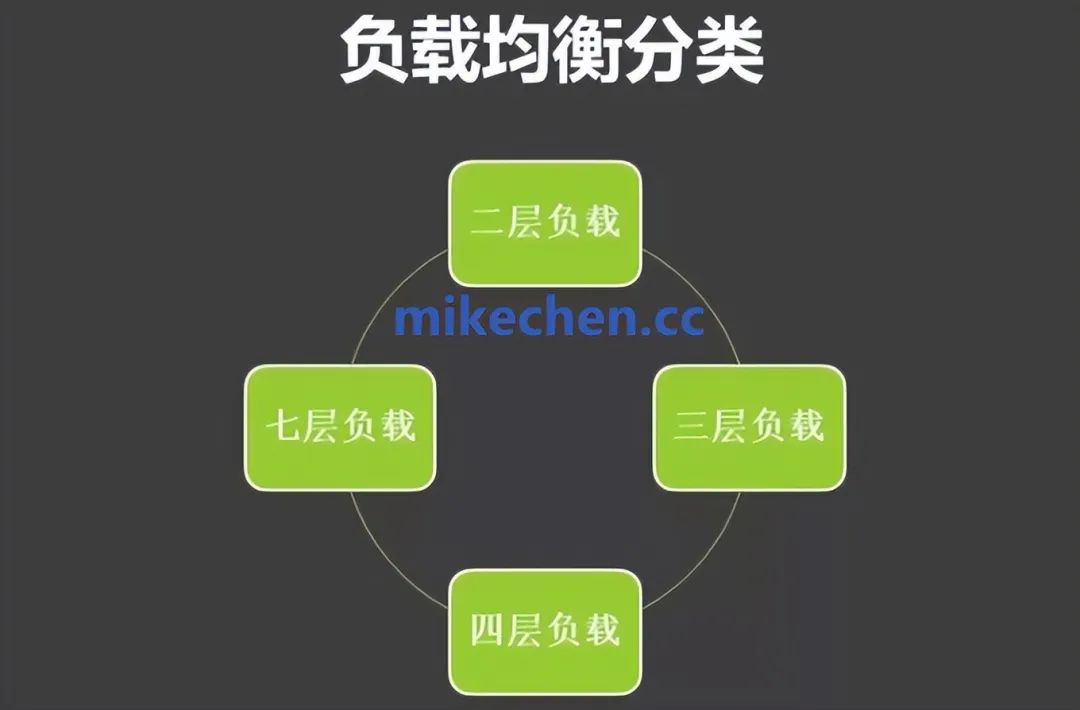
1)二层负载均衡(数据链路层)
二层负载均衡工作在OSI模型的第二层,即数据链路层。
它通常基于MAC地址进行流量分发,利用交换机、或桥接器将数据包分发到不同的服务器。
主要用于小型局域网(LAN),在广域网(WAN)环境...中应用受限。
2)三层负载均衡(网络层)
三层负载均衡工作在OSI模型的第三层,即网络层,它基于IP地址进行流量分发。
3)四层负载均衡(传输层)
四层负载均衡工作在OSI模型的第四层,即传输层,它基于TCP/UDP协议,通过分析IP地址、和端口号进行流量分发。
常见的四层负载均衡器有:硬件设备(如F5)、和软件实现(如HAProxy)。
4)七层负载均衡(应用层)
七层负载均衡工作在OSI模型的第七层,即应用层,它基于HTTP/HTTPS等应用层协议,通过分析URL、Cookie、HTTP头信息等进行流量分发。
常见的七层负载均衡器有:Nginx、Apache、HAProxy......等。
每种负载均衡技术都有其特定的优势和局限性,选择适合的负载均衡方案需要根据具体的应用需求、网络环境和系统架构进行综合考虑。
Innodb加索引,会锁表吗?
在 MySQL 5.6 之前,InnoDB 在索引构建期间会对表进行排它锁定,这意味着其他会话无法读取或修改表中的数据,从而导致长时间阻塞和性能问题。
自 MySQL 5.6 起,InnoDB 开始采用一种名为"Online DDL"的技术,允许在不阻塞其他会话的情况下创建或删除索引。Online DDL 针对不同的操作提供了多种实现方式,包括 COPY、INSTANT 和 INPLACE。
由于 DDL 涉及多种操作,如索引创建、字段增加和外键添加等,因此不同操作的支持方式也各不相同。具体支持方式可参考 MySQL 官方文档(https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html)。
以索引创建为例:
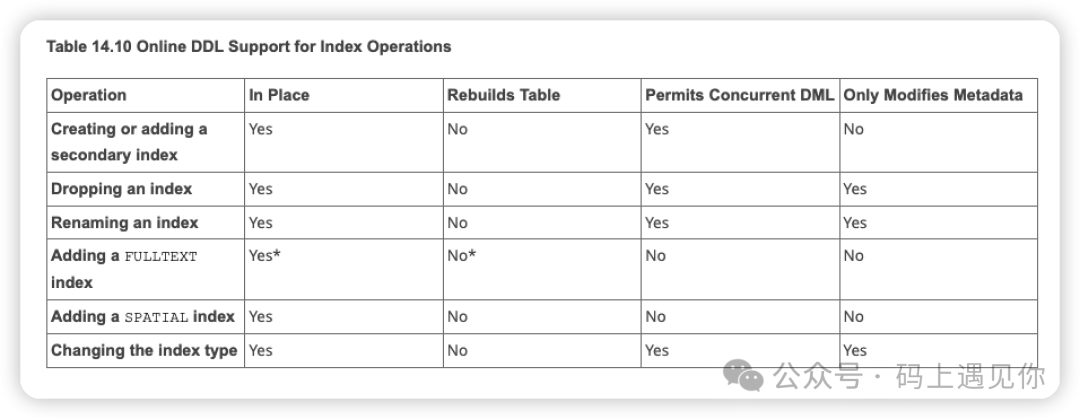
从上文可见,当我们创建、删除或重命名索引时,会采用"in place"的模式。
需要注意的是,尽管 Online DDL 能够减少锁定时间和对性能的影响,但在索引构建期间仍可能出现锁定和阻塞情况。例如,在添加索引时,如果表中存在大量未提交的事务,则需要等待这些事务提交后才能开始索引构建。因此,建议在非高峰时段进行此类操作,以避免影响用户的正常使用。在执行任何 DDL 操作之前,最好进行充分的测试和规划,并确保有备份和回滚计划,以应对意外情况。
扩展知识
什么是 Online DDL
DDL,即数据定义语言(Data Definition Language),用于定义数据库结构的操作。DDL 操作包括创建、修改和删除数据库中的表、索引、视图、约束等数据库对象,而不涉及实际数据的操作。以下是一些常见的 DDL 操作:
-
CREATE(创建)
-
ALTER(修改)
-
DROP(删除)
-
TRUNCATE(截断)
相对应的是 DML,即数据操作语言(Data Manipulation Language),用于操作数据。包括我们常用的 INSERT、DELETE 和 UPDATE 等操作。
在 MySQL 5.6 之前,所有的 ALTER 操作实际上都会阻塞 DML 操作,例如添加或删除字段、添加或删除索引等,都会导致表被锁定。
然而,在 MySQL 5.6 中引入了 Online DDL,它是 MySQL 5.6 提出的一种加速 DDL 的方案,旨在尽可能保证 DDL 期间不会阻塞 DML 操作。但需要注意的是,并非所有的 DDL 语句都会利用 Online DDL 进行加速。
Online DDL 的优点在于可以减少阻塞,它是 MySQL 内置的一种优化手段。但需注意的是,在 DDL 开始和结束阶段,都需要获取 MDL 锁,如果在获取锁时存在未提交的事务,则 DDL 可能因为锁定失败而被阻塞,从而影响性能。
此外,如果 Online DDL 操作失败,其回滚操作可能会造成较高的成本。长时间运行的 Online DDL 操作也可能导致主从同步的延迟。
DDL 算法
在 MySQL 5.6 支持 Online DDL 之前,存在两种 DDL 算法,分别是 COPY 和 INPLACE。
我们可以使用以下 SQL 来指定 DDL 算法:
ALTER TABLE paidaxing_ddl_test ADD PRIMARY KEY (id) ,ALGORITHM=INPLACE,LOCK=NONECOPY 算法原理
-
创建一张临时表。
-
对原表加共享 MDL 锁,阻止对原表的写操作,仅允许查询操作。
-
逐行将原表数据拷贝到临时表中,且无需进行排序。
-
数据拷贝完成后,将原表锁升级为排他 MDL 锁,阻止对原表的读写操作。
-
对临时表进行重命名操作,并创建索引,完成 DDL 操作。
INPLACE 算法原理
INPLACE 算法是在 MySQL 5.5 中引入的,旨在优化索引的创建和删除过程的效率。其原理是尽可能地使用原地算法进行 DDL 操作,而不是重新创建或复制表。
-
创建索引数据字典。
-
对原表加共享 MDL 锁,阻止对原表的写操作,只允许查询操作。
-
根据聚集索引的顺序,查询表中的数据,并提取所需的索引列数据。将提取的索引数据进行排序,并插入到新的索引页中。
-
等待当前表的所有只读事务提交。
-
索引创建完成。
MySQL 中的 INPLACE 算法实际上分为两种:
-
inplace-no-rebuild:对二级索引的增删改查、修改变长字段长度(例如:varchar)、重命名列名等操作都不需要重建原表。
-
inplace-rebuild:修改主键索引、增加或删除列、修改字符集、创建全文索引等操作需要重建原表。
OnlineDDL 算法
前面提到,ALGORITHM 可以指定 DDL 操作的算法,目前主要支持以下几种:
-
COPY 算法
-
INPLACE 算法
-
INSTANT 算法:MySQL 8.0.12 引入的新算法,目前只支持添加列等少量操作。它利用了 8.0 新的表结构设计,可以直接修改表的元数据,省去了重建原表的过程,从而极大地缩短了 DDL 语句的执行时间。对于其他类型的改表语句,默认使用 inplace 算法。关于 INSTANT 支持的场景可参考官方文档 Online DDL Operations:https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html。
-
DEFAULT:如果不指定 ALGORITHM,MySQL 会自行选择默认算法。它优先考虑 INSTANT,其次是 INPLACE,然后是 COPY。
以下是 MySQL 官网上给出的 Online DDL 对索引操作的支持情况:
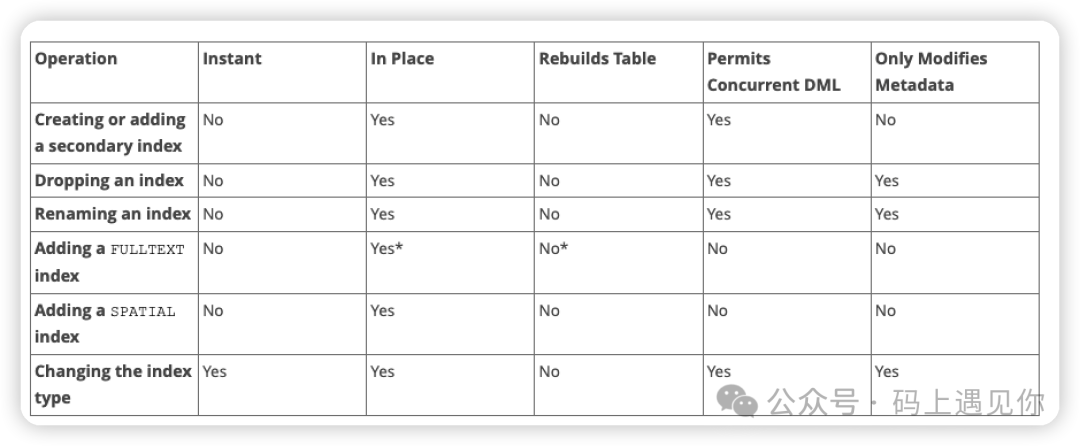
OnlineDDL 的原理
以下是 Online DDL 的整体步骤,主要分为 Prepare 阶段、DDL 执行阶段以及 Commit 阶段。
Prepare 阶段:
-
创建临时 frm 文件。
-
加 EXCLUSIVE-MDL 锁,阻止读写操作。
-
根据 ALTER 类型,确定执行方式(copy/online-rebuild/online-norebuild)。需要注意,如果使用 copy 算法,则不是 Online DDL。
-
更新数据字典的内存对象。
-
分配 row_log 对象,记录 Online DDL 过程中增量的 DML。
-
生成新的临时 idb 文件。
Execute 阶段:
-
降级 EXCLUSIVE-MDL 锁为 SHARED-MDL 锁,允许读写操作。
-
扫描原表聚集索引的每一条记录。
-
遍历新表的聚集索引和二级索引,逐一处理。
-
根据原表中的记录构造对应的索引项。
-
将构造的索引项插入 sort_buffer 块排序。
-
将 sort_buffer 块更新到新表的索引上。
-
记录 Online DDL 执行过程中产生的增量(online-rebuild)。
-
重放 row_log 中的操作到新表的索引上(online-not-rebuild 数据是在原表上更新)。
-
重放 row_log 中的 DML 操作到新表的数据行上。
Commit 阶段:
-
升级到 EXCLUSIVE-MDL 锁,阻止读写操作。
-
重做 row_log 中最后一部分增量。
-
更新 InnoDB 的数据字典表。
-
提交事务,写 redo log。
-
修改统计信息。
-
重命名临时 ibd 文件,frm 文件。
-
变更完成,释放 EXCLUSIVE-MDL 锁。
尽管 Prepare 阶段和 Commit 阶段也加了 EXCLUSIVE-MDL 锁,但操作非常轻量,因此耗时较低。Execute 阶段允许读写操作,并通过 row_log 记录期间的变更数据记录,最终应用这些变更到新表中,从而实现 Online DDL 的效果。
13个分布式事务处理机制
分布式事务是指在分布式系统中,为了保证多个节点上的操作能够满足事务的ACID(原子性、一致性、隔离性、持久性)特性而设计的一种机制。在分布式系统中,事务的参与者可能分布在不同的服务器、数据库或服务中。/
1. 两阶段提交(2PC)
两阶段提交(2PC)是分布式事务中一种非常重要的协议,它确保了事务在分布式系统中的原子性和一致性。两阶段提交分为两个阶段:
-
准备阶段(Prepare Phase)
-
提交阶段(Commit Phase)
准备阶段(Prepare Phase)
在这个阶段,事务协调者(Coordinator)向所有参与者(Participants)发送准备请求,询问它们是否准备好提交事务。参与者在收到请求后,会执行所有事务操作,并将结果写入到持久化日志中。如果参与者能够提交事务,它会向协调者发送一个"准备就绪"的响应;如果无法提交事务,它会发送一个"准备失败"的响应。
提交阶段(Commit Phase)
协调者在收到所有参与者的响应后,会根据响应来决定事务的最终提交状态:
-
如果所有参与者都发送了"准备就绪"的响应,协调者会进入提交阶段,向所有参与者发送提交请求,参与者在收到提交请求后,会正式提交事务。
-
如果任何一个参与者发送了"准备失败"的响应,协调者会向所有参与者发送回滚请求,参与者在收到回滚请求后,会撤销之前执行的所有操作。
业务示例代码演示
下面是一个简化版的两阶段提交的伪代码示例,用于说明其工作原理:
// 事务协调者(Coordinator)
class Coordinator {
void prepare() {
for (Participant participant : participants) {
boolean ready = participant.prepare();
if (!ready) {
// 如果任何参与者准备失败,向所有参与者发送回滚请求
rollback();
return;
}
}
// 所有参与者都准备就绪,可以提交事务
commit();
}
void commit() {
for (Participant participant : participants) {
participant.commit();
}
}
void rollback() {
for (Participant participant : participants) {
participant.rollback();
}
}
}
// 参与者(Participant)
class Participant {
// 准备阶段,执行事务操作并持久化日志
boolean prepare() {
// 执行事务操作
boolean success = executeTransaction();
// 将操作结果写入持久化日志
logTransaction(success);
return success;
}
// 提交阶段,正式提交事务
void commit() {
// 提交事务操作
finalizeTransaction();
}
// 回滚阶段,撤销事务操作
void rollback() {
// 撤销事务操作
revertTransaction();
}
private boolean executeTransaction() {
// 执行具体的事务操作
// 返回操作是否成功
}
private void logTransaction(boolean success) {
// 将事务操作结果写入日志
}
private void finalizeTransaction() {
// 将事务操作应用到数据库
}
private void revertTransaction() {
// 撤销事务操作
}
}在这个示例中,Coordinator类代表事务协调者,负责协调整个事务的提交过程。Participant类代表参与者,负责执行具体的事务操作。在prepare()方法中,协调者会询问所有参与者是否准备好提交事务。如果所有参与者都准备好了,协调者会调用commit()方法来提交事务;否则,它会调用rollback()方法来回滚事务。
说明和解释
-
原子性:通过两阶段提交,可以确保事务要么完全执行,要么完全不执行,满足原子性要求。
-
一致性:在准备阶段,所有参与者都执行了事务操作,并将结果持久化,保证了事务的一致性。
-
隔离性:虽然两阶段提交本身不直接处理隔离性,但通过事务日志和回滚机制,可以在失败时恢复到一致状态。
-
持久性:在准备阶段,参与者将事务操作结果写入持久化日志,确保了事务的持久性。
两阶段提交是一种强一致性的事务处理机制,但它也有一些缺点,如可能产生阻塞、性能开销较大等。在实际应用中,需要根据具体场景权衡使用。
2. 三阶段提交(3PC)
三阶段提交(3PC)是两阶段提交(2PC)的一个改进版本,旨在解决2PC在某些情况下的阻塞问题。3PC通过引入一个额外的阶段------预提交阶段(Pre-prepare),来减少阻塞并提高系统的响应性。3PC的三个阶段如下:
-
询问阶段(Ask Phase):协调者询问参与者是否可以提交事务。
-
预提交阶段(Pre-prepare Phase):如果参与者都同意提交,协调者会通知它们预提交事务。
-
提交阶段(Do-prepare Phase):在预提交成功后,协调者会通知参与者正式提交事务。
询问阶段(Ask Phase)
在这个阶段,协调者向所有参与者发送询问消息,询问它们是否准备好提交事务。参与者在收到询问后,会锁定必要的资源,并准备进行事务的提交。
预提交阶段(Pre-prepare Phase)
如果所有参与者都响应说它们准备好了,协调者会进入预提交阶段。在这个阶段,协调者向所有参与者发送预提交请求,并要求它们执行事务操作,但不会立即提交。参与者在执行事务操作后,会将操作结果持久化到日志中。
提交阶段(Do-prepare Phase)
在预提交阶段完成后,如果所有参与者都成功执行了事务操作,协调者会进入提交阶段,向所有参与者发送提交请求。参与者在收到提交请求后,会正式提交事务。
业务示例代码演示
由于3PC的实现相对复杂,下面是一个简化版的伪代码示例,用于说明其工作原理:
// 事务协调者(Coordinator)
class Coordinator {
void ask() {
for (Participant participant : participants) {
participant.lockResources();
participant.prepare();
}
}
void prePrepare() {
for (Participant participant : participants) {
participant.preCommit();
}
}
void doPrepare() {
for (Participant participant : participants) {
participant.commit();
}
}
void abort() {
for (Participant participant : participants) {
participant.abort();
}
}
}
// 参与者(Participant)
class Participant {
void lockResources() {
// 锁定必要的资源
}
void prepare() {
// 准备事务,但不提交
}
void preCommit() {
// 执行事务操作,但不提交
// 持久化操作结果
}
void commit() {
// 正式提交事务
}
void abort() {
// 回滚事务,释放资源
}
}在这个示例中,Coordinator类代表事务协调者,负责协调整个事务的提交过程。Participant类代表参与者,负责执行具体的事务操作。
说明和解释
-
减少阻塞:3PC通过引入预提交阶段,允许参与者在正式提交之前执行事务操作,减少了在等待其他参与者响应时的阻塞时间。
-
提高响应性:在预提交阶段,参与者可以提前执行事务操作,提高了系统的响应性。
-
容错性:如果协调者在预提交阶段失败,参与者可以根据持久化的日志信息决定是否继续提交事务,提高了系统的容错性。
然而,3PC也有其缺点,如实现复杂、可能产生更多的消息开销等。在实际应用中,需要根据具体场景权衡使用。此外,3PC并不是一个广泛采用的标准协议,它更多的是作为理解分布式事务处理中更复杂问题的一个概念模型。
3. 补偿事务(Compensation Transactions)
补偿事务(Compensating Transaction)是一种处理分布式系统中事务失败的方法。它的核心思想是为每个事务操作提供一个对应的补偿操作(也称为回滚操作),以便在事务失败时能够撤销之前的操作,从而保证系统的一致性。
补偿事务的工作原理:
-
执行操作:在事务开始时,首先执行正常的业务操作。
-
记录日志:操作执行的同时,记录操作的日志信息,以便后续可以重放或补偿。
-
提交事务:如果所有操作都成功执行,提交事务。
-
补偿操作:如果事务中的某个操作失败,执行相应的补偿操作来撤销之前的操作,恢复系统到事务开始前的状态。
业务示例代码演示:
假设我们有一个电子商务平台,用户下单后需要扣减库存并创建订单。我们可以使用补偿事务来确保这两个操作要么都成功,要么都失败。
class OrderService {
// 执行业务操作
public void placeOrder(String productId, int quantity) {
// 尝试扣减库存
boolean isStockSufficient = inventoryService.decrementStock(productId, quantity);
if (!isStockSufficient) {
// 如果库存不足,直接返回,不执行后续操作
return;
}
// 扣减库存成功,记录日志
logService.log("库存扣减成功,产品ID:" + productId + ",数量:" + quantity);
// 创建订单
boolean isOrderCreated = orderRepository.createOrder(productId, quantity);
if (!isOrderCreated) {
// 创建订单失败,执行补偿操作
compensateOrderCreation(productId, quantity);
} else {
// 创建订单成功,记录日志
logService.log("订单创建成功,产品ID:" + productId);
}
}
// 补偿操作:撤销订单创建
private void compensateOrderCreation(String productId, int quantity) {
// 回滚库存扣减
inventoryService.incrementStock(productId, quantity);
// 记录补偿操作日志
logService.log("订单创建失败,库存回滚,产品ID:" + productId + ",数量:" + quantity);
}
}
class InventoryService {
// 扣减库存
public boolean decrementStock(String productId, int quantity) {
// 模拟库存扣减逻辑
// 返回操作是否成功
}
// 回滚库存扣减
public void incrementStock(String productId, int quantity) {
// 模拟库存回滚逻辑
}
}
class OrderRepository {
// 创建订单
public boolean createOrder(String productId, int quantity) {
// 模拟订单创建逻辑
// 返回操作是否成功
}
}
class LogService {
// 记录日志
public void log(String message) {
// 实现日志记录逻辑
}
}说明和解释:
-
幂等性:补偿操作应该是幂等的,即使多次执行补偿操作,也不会对系统状态产生不良影响。
-
日志记录:为了能够执行补偿操作,需要在执行业务操作的同时记录详细的日志信息。
-
事务一致性:通过补偿操作,可以确保即使在分布式系统中,事务也能够保持一致性。
补偿事务是一种非常灵活的处理分布式事务的方法,尤其适用于那些操作可以很容易地被补偿的场景。然而,它也有局限性,比如补偿操作可能比原始操作更复杂,或者在某些情况下难以实现补偿操作。因此,在设计补偿事务时,需要仔细考虑业务逻辑和系统架构。
4. 基于Saga的事务
基于Saga的事务是一种处理分布式事务的方法,它适用于复杂的业务场景,其中事务被拆分成一系列本地事务(每个本地事务都是一个独立的操作,如数据库操作)。Saga通过将一个长事务拆分成多个短事务,并且为每个本地事务定义相应的补偿操作来保证数据的最终一致性。
Saga模型的核心概念包括:
-
Saga:一系列本地事务的集合,它们作为一个整体执行。
-
Saga事务:Saga中的单个本地事务。
-
Compensation:补偿操作,用于撤销Saga中的某个Saga事务,恢复数据到原始状态。
Saga事务的工作原理:
-
执行Saga事务:按顺序执行一系列本地事务。
-
提交或补偿:如果所有事务都成功提交,Saga成功结束。如果某个事务失败,则执行该事务对应的补偿操作,然后继续尝试提交后续事务。
-
终止Saga:如果在执行补偿操作后,Saga无法继续执行,则Saga终止。
业务示例代码演示:
假设在一个在线购物平台中,用户下单操作可以拆分为两个本地事务:创建订单和扣减库存。以下是使用Saga模型实现的示例:
class SagaManager {
// 执行整个Saga事务
public boolean executeOrderSaga(String productId, int quantity) {
try {
// Saga事务1:创建订单
boolean orderCreated = orderService.createOrder(productId, quantity);
if (!orderCreated) {
return false;
}
// Saga事务2:扣减库存
boolean stockDeducted = inventoryService.decrementStock(productId, quantity);
if (!stockDeducted) {
// 如果扣减库存失败,执行补偿操作:撤销订单
orderService.cancelOrder(productId, quantity);
return false;
}
// 如果所有事务都成功,Saga成功结束
return true;
} catch (Exception e) {
// 如果发生异常,执行所有事务的补偿操作
inventoryService.revertStock(productId, quantity);
orderService.cancelOrder(productId, quantity);
return false;
}
}
}
class OrderService {
// 创建订单
public boolean createOrder(String productId, int quantity) {
// 订单创建逻辑
// 返回操作是否成功
}
// 撤销订单
public void cancelOrder(String productId, int quantity) {
// 订单撤销逻辑,补偿操作
}
}
class InventoryService {
// 扣减库存
public boolean decrementStock(String productId, int quantity) {
// 库存扣减逻辑
// 返回操作是否成功
}
// 回滚库存扣减,补偿操作
public void revertStock(String productId, int quantity) {
// 库存回滚逻辑,补偿操作
}
}说明和解释:
-
最终一致性:Saga模式不保证事务的即时一致性,而是保证事务的最终一致性。这意味着在某些情况下,系统可能会短暂处于不一致状态,但最终会通过补偿操作达到一致状态。
-
补偿操作:Saga模式要求为每个本地事务定义一个补偿操作。补偿操作应该能够撤销本地事务的影响,使得整个系统恢复到事务执行前的状态。
-
可逆操作:Saga模式要求本地事务应该是可逆的,即每个操作都有一个对应的反向操作。
-
Saga协调器:Saga协调器负责管理Saga的执行流程,包括事务的提交和补偿操作的执行。在复杂的系统中,可能需要一个中央协调器来管理Saga的执行和状态。
Saga模式非常适合于微服务架构,因为它允许每个服务独立地管理自己的事务,并且可以灵活地处理分布式事务中的错误。然而,设计Saga事务和补偿操作可能比较复杂,需要仔细规划和测试以确保系统的可靠性。
5. 分布式锁
分布式锁是分布式系统中用于确保跨多个节点或服务的原子性和一致性的机制。它是一种同步机制,用于防止多个进程或线程同时执行某些操作,这些操作如果并发执行可能会导致数据不一致或竞态条件。
分布式锁的核心特性:
-
互斥性:在任何时候,只有一个进程可以持有锁。
-
安全性:持有锁的进程可以安全地执行操作,而不必担心其他进程会干扰。
-
性能:锁的获取和释放应该尽可能快,以避免不必要的延迟。
-
可重入性:同一个进程可以多次获取同一把锁。
-
死锁预防:系统应该能够处理锁的持有者异常退出的情况,避免死锁。
分布式锁的实现方式:
-
基于数据库:使用数据库的排它锁(例如,通过行级锁)。
-
基于缓存系统:使用Redis、Memcached等缓存系统提供的原子操作来实现锁。
-
基于一致性协议:如ZooKeeper的临时顺序节点。
-
基于分布式键值存储:如etcd,提供分布式锁服务。
业务示例代码演示:
以下是一个使用Redis作为分布式锁的简单示例。我们将使用Redis的SETNX命令来设置一个键,如果该键不存在,则操作成功,我们可以认为获取了锁;如果键已存在,则操作失败,表示锁被其他进程持有。
import redis.clients.jedis.Jedis;
public class DistributedLock {
private Jedis jedis;
private static final String LOCK_SCRIPT = "if redis.call('set', KEYS[1], ARGV[1]) == 1 then return 1 else return 0 end";
public DistributedLock(Jedis jedis) {
this.jedis = jedis;
}
// 尝试获取锁
public boolean tryLock(String lockKey, String requestId, int timeout) {
Long result = (Long) jedis.eval(LOCK_SCRIPT, 1, lockKey, requestId);
if (result == 1) {
// 获取锁成功,设置超时时间
jedis.expire(lockKey, timeout);
return true;
}
return false;
}
// 释放锁
public void unlock(String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
jedis.eval(script, 1, lockKey, requestId);
}
}在这个示例中,DistributedLock类提供了获取和释放分布式锁的方法。tryLock方法尝试获取锁,如果成功,则通过requestId作为值设置锁,并使用expire命令设置超时时间,以避免锁持有者未释放锁的情况。unlock方法通过Lua脚本来安全地释放锁,只有当当前持有锁的requestId与传入的requestId相匹配时,锁才会被释放。
说明和解释:
-
锁的超时:为了防止死锁,分布式锁应该有超时机制。在上面的示例中,我们使用expire命令为锁设置了一个超时时间。
-
锁的安全性:Lua脚本用于保证解锁操作的原子性,防止在解锁过程中发生竞态条件。
-
重试机制:在实际应用中,如果尝试获取锁失败,通常会实现重试机制,直到成功获取锁或达到最大重试次数。
分布式锁是确保分布式系统中数据一致性的关键技术之一,正确地实现和使用分布式锁对于构建可靠的分布式系统至关重要。
6. 消息队列
消息队列(Message Queue,简称MQ)是一种应用程序之间的通信方法,用于在分布式系统中存储和转发消息。消息队列可以解耦服务之间的直接调用,提高系统的可用性和伸缩性,并作为分布式事务中保证最终一致性的一种手段。
消息队列的核心特性:
-
解耦:生产者和消费者不需要直接交互,它们通过消息队列进行通信。
-
异步通信:生产者发送消息后不需要等待消费者的响应即可继续执行。
-
持久化:消息可以存储在队列中,直到被消费者处理。
-
缓冲:消息队列可以作为缓冲区,平衡生产者和消费者的处理速度。
-
可扩展性:通过增加消费者的数量来提高处理能力。
-
容错性:即使某个消费者失败,消息队列也可以保证消息不会丢失。
常见的消息队列实现:
-
RabbitMQ:一个开源的消息代理,支持多种消息协议。
-
Apache Kafka:一个分布式流处理平台,用于构建实时数据管道和流处理应用程序。
-
Amazon SQS:一个托管的消息队列服务,提供可扩展和完全管理的队列。
-
Redis:除了作为缓存和数据库使用外,Redis也支持发布/订阅模式。
业务示例代码演示:
以下是一个使用RabbitMQ作为消息队列的Java示例。我们将创建一个简单的生产者和消费者,生产者发送消息,消费者接收并处理消息。
生产者代码示例:
import com.rabbitmq.client.*;
public class MessageProducer {
private final static String EXCHANGE_NAME = "test_exchange";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
String message = "Hello World!";
String routingKey = "test_routing_key";
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
channel.close();
connection.close();
}
}消费者代码示例:
import com.rabbitmq.client.*;
import java.io.IOException;
public class MessageConsumer {
private final static String EXCHANGE_NAME = "test_exchange";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind(queueName, EXCHANGE_NAME, "test_routing_key");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
};
channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });
}
}
}说明和解释:
-
消息交换:在RabbitMQ中,消息通过交换机(exchange)路由到队列。生产者发送消息到交换机,交换机根据路由键(routing key)将消息路由到一个或多个队列。
-
队列绑定:消费者监听特定的队列,并将队列绑定到交换机和路由键上。
-
消息持久化:在RabbitMQ中,可以通过设置消息和队列的持久性属性来确保消息不会在系统崩溃时丢失。
-
消费者确认:消费者在处理完消息后,需要发送确认回执给RabbitMQ,这样RabbitMQ才会从队列中移除消息。如果消费者在处理消息时失败,RabbitMQ会将消息重新放入队列。
消息队列在分布式系统中扮演着重要的角色,不仅可以提高系统的解耦和可扩展性,还可以在分布式事务中作为确保最终一致性的关键组件。通过使用消息队列,系统的不同部分可以独立地扩展和维护,同时保持高效的通信和数据一致性。
7. TCC(Try-Confirm-Cancel)模式
TCC(Try-Confirm-Cancel)是一种用于分布式事务管理的模式,它通过将一个分布式事务分解为三个阶段来确保事务的一致性:尝试(Try)、确认(Confirm)和取消(Cancel)。
TCC的三个阶段:
-
Try阶段:在这个阶段,每个服务尝试执行本地事务,并预留必要的资源。如果所有服务都成功预留资源,事务可以继续到确认阶段;如果有任何一个服务无法预留资源,事务将进入取消阶段。
-
Confirm阶段:如果所有服务在Try阶段都成功,协调者会向所有服务发送确认消息,服务收到确认消息后,会提交本地事务。
-
Cancel阶段:如果任何一个服务在Try阶段失败,协调者会向所有服务发送取消消息,服务收到取消消息后,会释放在Try阶段预留的资源。
TCC的核心特性:
-
可恢复性:TCC模式允许事务在失败时恢复到原始状态。
-
幂等性:Confirm和Cancel操作需要是幂等的,即无论执行多少次,结果都是一致的。
-
协调者:需要一个协调者来管理Try、Confirm和Cancel三个阶段的流程。
业务示例代码演示:
假设我们有一个在线支付系统,用户支付操作需要扣减账户余额和记录支付日志。以下是使用TCC模式实现的示例:
class PaymentService {
private AccountService accountService;
private PaymentLogService paymentLogService;
// 尝试阶段:预留资源
public boolean preparePayment(String userId, double amount) {
// 尝试扣减账户余额
boolean accountDeducted = accountService.tryDeduct(userId, amount);
if (!accountDeducted) {
return false; // 资源预留失败,返回false
}
// 记录支付日志
boolean logRecorded = paymentLogService.recordPaymentLog(userId, amount);
if (!logRecorded) {
accountService.cancelDeduct(userId, amount); // 释放资源
return false; // 资源预留失败,返回false
}
return true; // 资源预留成功,返回true
}
// 确认阶段:提交事务
public void confirmPayment(String userId, double amount) {
accountService.confirmDeduct(userId, amount); // 提交扣减账户余额
paymentLogService.confirmPaymentLog(userId, amount); // 提交支付日志
}
// 取消阶段:释放资源
public void cancelPayment(String userId, double amount) {
accountService.cancelDeduct(userId, amount); // 释放账户余额
paymentLogService.cancelPaymentLog(userId, amount); // 取消支付日志记录
}
}
class AccountService {
// 尝试扣减账户余额
public boolean tryDeduct(String userId, double amount) {
// 预留资源逻辑
// 返回操作是否成功
}
// 提交扣减账户余额
public void confirmDeduct(String userId, double amount) {
// 提交事务逻辑
}
// 取消扣减账户余额
public void cancelDeduct(String userId, double amount) {
// 释放资源逻辑
}
}
class PaymentLogService {
// 记录支付日志
public boolean recordPaymentLog(String userId, double amount) {
// 记录日志逻辑
// 返回操作是否成功
}
// 提交支付日志
public void confirmPaymentLog(String userId, double amount) {
// 提交日志逻辑
}
// 取消支付日志记录
public void cancelPaymentLog(String userId, double amount) {
// 取消记录逻辑
}
}说明和解释:
-
资源预留:在Try阶段,需要预留必要的资源,如扣减账户余额和记录支付日志。
-
幂等性:Confirm和Cancel操作需要设计为幂等的,确保多次执行不会对系统产生不良影响。
-
事务一致性:通过TCC模式,可以确保分布式事务的一致性,要么所有操作都成功,要么所有操作都失败。
-
错误处理:在Try阶段,如果任何一个操作失败,需要回滚所有已执行的操作,并释放资源。
TCC模式是一种有效的分布式事务解决方案,适用于需要强一致性保证的场景。然而,它也带来了一定的复杂性,需要为每个操作设计Try、Confirm和Cancel三个阶段的逻辑。此外,TCC模式需要一个可靠的协调者来管理整个事务流程。
8. CAP定理
CAP定理(也称为布鲁尔定理)是分布式计算中的一个概念,由计算机科学家埃里克·布鲁尔(Eric Brewer)提出,并由汤姆·林(T.H. Lin)在2000年的分布式计算原理研讨会上正式命名。CAP定理指出,一个分布式系统不可能同时提供以下三个特性:
-
一致性(Consistency):在分布式系统中的所有数据副本上,对于任何给定的事务,系统都能保证在任何时刻提供最新的数据。
-
可用性(Availability):系统在任何时刻都能够响应用户的请求。
-
分区容错性(Partition Tolerance):系统在遇到网络分区(即网络中的节点因为网络问题无法互相通信)的情况下,仍然能够继续运作。
CAP定理的核心要点:
-
网络分区:在分布式系统中,由于网络问题导致系统的不同部分无法互相通信,这是不可避免的。
-
三选二:在网络分区发生时,系统只能在一致性和可用性之间选择一个。如果系统追求一致性,则可能无法响应用户的请求;如果追求可用性,则可能提供不是最新数据的响应。
业务示例代码演示:
假设我们有一个在线电子商务平台,该平台需要处理商品的查询和购买操作。我们可以从CAP定理的角度来考虑如何设计这个系统。
一致性优先的设计:
class ProductService {
public synchronized boolean purchaseProduct(String productId, int quantity) {
// 假设这里有一个方法来检查库存是否充足
boolean hasStock = checkStock(productId, quantity);
if (!hasStock) {
return false; // 库存不足,无法购买
}
// 执行购买操作,更新库存
updateStock(productId, -quantity);
return true;
}
private boolean checkStock(String productId, int quantity) {
// 检查库存逻辑
// 返回库存是否充足
}
private void updateStock(String productId, int quantity) {
// 更新库存逻辑
}
}在这个示例中,我们使用synchronized关键字来保证在任何时刻只有一个线程可以执行购买操作,从而保证了一致性。但这也意味着在高并发的情况下,系统的可用性会受到影响,因为其他请求必须等待当前操作完成。
可用性优先的设计:
class ProductService {
public boolean purchaseProduct(String productId, int quantity) {
// 假设这里有一个方法来检查库存是否充足,但允许一定程度的过时
boolean hasStock = checkStock(productId, quantity);
if (!hasStock) {
return false; // 库存不足,无法购买
}
// 执行购买操作,更新库存
updateStock(productId, -quantity);
return true;
}
private boolean checkStock(String productId, int quantity) {
// 快速检查库存逻辑,可能返回过时的数据
// 返回库存是否充足
}
private void updateStock(String productId, int quantity) {
// 更新库存逻辑,允许短暂的不一致
}
}在这个示例中,我们允许系统在某些情况下提供过时的数据(例如,库存数据可能不是最新的),以提高系统的响应速度和可用性。这种设计在网络分区或高负载情况下仍然能够处理请求,但可能会牺牲一定的一致性。
说明和解释:
-
CAP权衡:在设计分布式系统时,开发者需要根据业务需求在一致性、可用性和分区容错性之间做出权衡。
-
业务场景:不同的业务场景可能对CAP的不同方面有不同的需求。例如,金融交易系统可能更注重一致性,而社交媒体平台可能更注重可用性。
-
系统设计:在实际的系统设计中,可以通过各种策略和技术(如缓存、数据副本、分布式锁等)来优化CAP的权衡。
CAP定理为理解和设计分布式系统提供了一个重要的理论基础,帮助开发者根据具体的业务需求做出合理的架构选择。
9. BASE理论
BASE理论是为分布式系统提供一种不同于传统ACID事务的新事务处理方法。它由eBay的架构师提出,主要用于大型高可用可扩展的分布式系统。BASE是以下四个概念的缩写:
-
Basically Available(基本可用):分布式系统在出现故障时,仍然能够保证核心功能可用,但可能会损失部分功能或性能。
-
Soft State(软状态):系统的状态允许有一定的灵活性,不必一直保持一致,可以在有限时间内不同步。
-
Eventual Consistency(最终一致性):系统保证在没有新的更新的情况下,所有数据副本最终会达到一个一致的状态。
BASE理论的核心要点:
-
不保证立即一致性:与传统的ACID事务不同,BASE理论允许系统在事务过程中出现不一致,但最终会达到一致性。
-
优先考虑可用性:在设计分布式系统时,BASE理论更倾向于保证系统的可用性而不是一致性。
-
依赖时间来解决一致性问题:BASE理论认为,通过时间的积累,系统最终会达到一致性。
业务示例代码演示:
有一个电子商务平台的购物车系统,该系统需要处理商品的添加和删除操作。我们可以从BASE理论的角度来考虑如何设计这个系统。
商品添加操作:
class ShoppingCartService {
private Map<String, Integer> cart = new ConcurrentHashMap<>();
public void addToCart(String productId, int quantity) {
// 基本可用:立即添加商品到购物车,不保证立即的数据一致性
cart.merge(productId, quantity, Integer::sum);
}
public Map<String, Integer> getCart() {
// 软状态:返回当前购物车状态,可能不是最新的
return new HashMap<>(cart);
}
}在这个示例中,addToCart方法通过ConcurrentHashMap的merge操作立即将商品添加到购物车中,这个过程是基本可用的,但可能存在短暂的数据不一致问题。getCart方法返回当前购物车的状态,但这个状态可能不是最新的,体现了软状态的概念。
商品删除操作:
public void removeFromCart(String productId) {
// 基本可用:立即从购物车中删除商品
cart.remove(productId);
}
// 异步更新操作,用于保证最终一致性
public void asyncUpdateInventory(String productId, int quantity) {
// 异步减少库存
// 这个过程不立即影响购物车操作,但最终会达到一致性
}在这个示例中,removeFromCart方法立即从购物车中删除商品,保证了基本可用性。asyncUpdateInventory是一个异步操作,用于在后台减少库存数量,这个过程体现了最终一致性的概念。
说明和解释:
-
设计权衡:BASE理论下的设计需要在立即一致性和可用性之间做出权衡,通常更倾向于后者。
-
适用场景:BASE理论适用于那些可以容忍短期数据不一致,但需要高可用性和可扩展性的系统。
-
数据一致性策略:在BASE理论下,可以通过各种策略(如异步处理、数据副本同步、缓存策略等)来实现最终一致性。
BASE理论为构建大规模分布式系统提供了一种灵活的事务处理方法,允许系统在保证核心功能可用的前提下,通过时间的积累逐步达到数据的一致性。这对于需要处理大量数据和高并发请求的现代互联网应用尤其重要。
10. 事务协调者(Coordinator)
事务协调者(Transaction Coordinator)是分布式事务中的一个关键组件,它负责协调和管理分布式系统中多个参与者(Participants)的事务操作,确保事务的原子性和一致性。在分布式事务处理中,事务协调者通常采用两阶段提交(2PC)或三阶段提交(3PC)等协议来执行事务。
事务协调者的核心职责:
-
协调事务:事务协调者负责协调所有参与者的事务操作,确保它们要么全部提交,要么全部回滚。
-
管理超时:协调者需要管理事务的超时时间,以避免事务长时间处于不确定状态。
-
处理失败:在参与者失败时,协调者需要决定是继续执行事务还是回滚事务,并通知所有参与者。
-
日志记录:协调者可能会记录事务的所有操作,以便于故障恢复和调试。
业务示例代码演示:
假设我们有一个微服务架构的电子商务平台,其中包括订单服务、库存服务和支付服务。以下是一个简化的事务协调者的示例,它使用两阶段提交协议来管理一个购买操作。
事务协调者接口:
interface TransactionCoordinator {
void beginTransaction();
boolean prepareCommit();
void commitTransaction();
void rollbackTransaction();
}具体的事务协调者实现:
class OrderTransactionCoordinator implements TransactionCoordinator {
private boolean isPrepared = false;
private OrderService orderService;
private InventoryService inventoryService;
private PaymentService paymentService;
public OrderTransactionCoordinator(OrderService orderService, InventoryService inventoryService, PaymentService paymentService) {
this.orderService = orderService;
this.inventoryService = inventoryService;
this.paymentService = paymentService;
}
@Override
public void beginTransaction() {
// 开始事务
}
@Override
public boolean prepareCommit() {
// 准备提交阶段
boolean orderSuccess = orderService.prepareOrder();
boolean inventorySuccess = inventoryService.prepareInventory();
boolean paymentSuccess = paymentService.preparePayment();
// 如果所有服务都准备成功,则标记为已准备
isPrepared = orderSuccess && inventorySuccess && paymentSuccess;
return isPrepared;
}
@Override
public void commitTransaction() {
// 提交事务阶段
if (isPrepared) {
orderService.commitOrder();
inventoryService.commitInventory();
paymentService.commitPayment();
} else {
// 如果未准备好,则回滚事务
rollbackTransaction();
}
}
@Override
public void rollbackTransaction() {
// 回滚事务阶段
orderService.rollbackOrder();
inventoryService.rollbackInventory();
paymentService.rollbackPayment();
}
}在这个示例中,OrderTransactionCoordinator类实现了TransactionCoordinator接口,并负责协调订单服务、库存服务和支付服务的事务操作。prepareCommit方法尝试准备提交事务,如果所有服务都准备成功,则标记为已准备。commitTransaction方法根据准备阶段的结果来提交或回滚事务。
服务类示例:
class OrderService {
public boolean prepareOrder() {
// 订单服务的准备逻辑
}
public void commitOrder() {
// 订单服务的提交逻辑
}
public void rollbackOrder() {
// 订单服务的回滚逻辑
}
// 其他服务类以类似方式实现
}说明和解释:
-
事务的开始和结束:事务协调者控制事务的开始、提交和回滚。
-
两阶段提交:示例中的prepareCommit和commitTransaction方法体现了两阶段提交的过程。
-
服务的解耦:事务协调者允许各个服务保持独立,同时确保整个事务的一致性。
-
容错性:如果某个服务失败,协调者需要能够处理这种情况,可能通过回滚事务来保证系统的一致性。
事务协调者在分布式系统中扮演着至关重要的角色,它通过协调各个服务的事务操作,确保整个分布式事务能够正确地提交或回滚。在实际应用中,事务协调者可以是一个独立的服务或组件,负责管理复杂的事务流程。
11. 参与者(Participants)
在分布式事务中,参与者(Participant)是指那些实际执行事务操作的服务或组件。每个参与者都负责执行一部分事务,并与事务协调者(Transaction Coordinator)进行通信,以确保整个分布式事务的一致性和完整性。
参与者的核心职责:
-
执行本地事务:参与者负责执行其本地资源上的事务操作,如数据库更新、消息发送等。
-
与协调者通信:参与者需要响应协调者的请求,并报告其事务状态。
-
准备提交:在两阶段提交协议中,参与者在准备阶段需要决定是否能够提交本地事务。
-
提交或回滚事务:根据协调者的指令,参与者需要提交本地事务或执行回滚操作。
业务示例代码演示:
一个电子商务平台,其中包括订单服务、库存服务和支付服务。每个服务都是一个参与者,它们将协同工作以完成一个购买操作的分布式事务。
参与者接口:
interface Participant {
void prepare();
void commit();
void rollback();
}订单服务参与者实现:
class OrderParticipant implements Participant {
private OrderService orderService;
private boolean prepared;
public OrderParticipant(OrderService orderService) {
this.orderService = orderService;
}
@Override
public void prepare() {
// 执行订单服务的本地事务操作
prepared = orderService.createOrder();
}
@Override
public void commit() {
if (prepared) {
orderService.confirmOrder();
}
}
@Override
public void rollback() {
if (prepared) {
orderService.cancelOrder();
}
}
}在这个示例中,OrderParticipant类实现了Participant接口,并负责协调订单服务的本地事务操作。prepare方法尝试创建订单,commit方法在准备成功后确认订单,rollback方法在需要时取消订单。
库存服务和支付服务参与者实现:
class InventoryParticipant implements Participant {
private InventoryService inventoryService;
public InventoryParticipant(InventoryService inventoryService) {
this.inventoryService = inventoryService;
}
// 实现 prepare, commit, rollback 方法
// 与订单服务类似,但涉及库存的本地事务操作
}
class PaymentParticipant implements Participant {
private PaymentService paymentService;
public PaymentParticipant(PaymentService paymentService) {
this.paymentService = paymentService;
}
// 实现 prepare, commit, rollback 方法
// 与订单服务类似,但涉及支付的本地事务操作
}说明和解释:
-
本地事务操作:每个参与者都负责执行与其服务相关的本地事务操作。
-
准备状态:在两阶段提交的准备阶段,参与者需要决定是否能够提交本地事务,并进入准备状态。
-
响应协调者:参与者需要根据协调者的指令来提交或回滚本地事务。
-
事务一致性:通过所有参与者的协作,整个分布式事务能够保持一致性。
参与者在分布式事务中扮演着执行具体操作的角色,它们与事务协调者紧密合作,共同确保分布式事务的正确性和完整性。在实际应用中,每个服务或组件都可以作为一个参与者,负责管理其本地资源的事务状态。
12. 超时机制
超时机制是分布式系统中用于处理事务或操作的一种重要策略,特别是在涉及网络通信和多个服务交互的场景中。超时机制确保了在预定时间内没有收到响应或完成操作时,系统能够采取相应的措施,比如重试、回滚或补偿操作,以避免系统资源被无限期占用或出现死锁。
超时机制的核心要点:
-
避免死锁:通过设置超时,可以避免因为等待某个操作完成而导致的系统死锁。
-
资源释放:超时后,系统可以释放在等待期间占用的资源,如数据库连接、内存等。
-
用户体验:合理的超时设置可以改善用户体验,避免用户长时间等待无响应的操作。
-
系统健壮性:超时机制增加了系统的健壮性,使其能够在部分组件失败时继续运行。
-
重试策略:超时后,系统可能会根据业务需求实施重试策略,以提高操作成功率。
业务示例代码演示:
假设我们有一个需要调用远程服务的业务操作,如下单操作,我们需要为这个操作设置超时机制。
使用伪代码的示例:
class OrderService {
Future<Boolean> submitOrder(String orderId) {
try {
// 调用远程服务提交订单,返回一个Future对象
Future<Boolean> result = remoteService.submitOrderAsync(orderId);
// 设置超时时间,单位为毫秒
boolean success = result.get(5000, TimeUnit.MILLISECONDS);
return success ? CompletableFuture.completedFuture(true) : CompletableFuture.failedFuture(new TimeoutException("Order submission timed out"));
} catch (InterruptedException | ExecutionException e) {
// 处理异常情况
return CompletableFuture.failedFuture(e);
}
}
}在这个示例中,submitOrder方法尝试异步提交一个订单,并使用Future.get方法设置超时时间。如果在5秒内没有得到响应,就会抛出TimeoutException异常,表示订单提交操作超时。
处理超时的策略:
class OrderManager {
OrderService orderService;
void processOrderWithTimeout(String orderId) {
CompletableFuture<Boolean> orderFuture = orderService.submitOrder(orderId);
orderFuture.handle(( success, throwable ) -> {
if (throwable instanceof TimeoutException) {
// 执行超时后的补偿操作,如重试、回滚等
logger.error("Order processing timed out, initiating compensation", throwable);
compensateForTimeout(orderId);
} else if (success) {
// 订单提交成功
logger.info("Order processed successfully");
} else {
// 处理其他失败情况
logger.error("Order processing failed", throwable);
}
return null;
});
}
private void compensateForTimeout(String orderId) {
// 实现超时补偿逻辑,例如取消订单、通知用户等
}
}在这个示例中,OrderManager类中的processOrderWithTimeout方法处理订单提交的异步结果。如果出现超时异常,它将调用compensateForTimeout方法来执行补偿操作。
说明和解释:
-
Future对象:在Java中,Future对象用于表示异步操作的结果。通过Future.get方法,我们可以设置超时时间。
-
异常处理:在超时或其他异常发生时,合理的异常处理策略是必要的,以保证系统的稳定性。
-
补偿操作:超时后,可能需要执行一些补偿操作来恢复系统状态或通知用户。
-
业务需求:超时时间的设置应根据具体的业务需求和网络状况来确定。
超时机制是分布式系统中保证操作可控性和系统稳定性的关键技术之一。通过合理设置超时时间并实施相应的异常处理和补偿策略,可以显著提高分布式系统的健壮性和用户体验。
13. 幂等性
幂等性(Idempotence)是分布式系统中的一个重要概念,它指的是一个操作无论执行多少次,其结果都相同。在分布式事务和网络通信中,幂等性用于确保即使在重复请求或网络重试的情况下,系统状态也不会发生变化,从而保证了系统的一致性和可靠性。(这个问题V哥听好多同学说在面试中被问到。)
幂等性的核心要点:
-
重复执行相同:一个幂等的操作,重复执行多次和执行一次的效果是一样的。
-
状态不变:幂等操作不会改变系统的状态。
-
无副作用:幂等操作不会产生副作用。
-
可预测性:幂等操作的结果是可以预测的。
幂等性在分布式系统中的作用:
-
防止数据不一致:在分布式系统中,由于网络问题或服务故障,一个操作可能被执行多次。幂等性可以防止这种情况导致的数据不一致。
-
简化重试逻辑:在网络请求失败时,可以安全地重试幂等操作,而不必担心产生错误结果。
-
提高系统健壮性:幂等性提高了系统的健壮性,因为即使在失败和重试的情况下,系统状态也能保持一致。
业务示例代码演示:
假设我们有一个在线购物平台,用户可以发起支付请求。为了确保即使在网络波动或系统故障时支付也不会被重复扣款,我们需要设计支付操作为幂等的。
支付服务接口:
interface PaymentService {
boolean makePayment(String paymentId, double amount);
}支付服务实现:
class PaymentServiceImpl implements PaymentService {
private Map<String, Double> payments = new ConcurrentHashMap<>();
@Override
public boolean makePayment(String paymentId, double amount) {
// 检查是否已经支付过
if (payments.containsKey(paymentId)) {
// 如果已经支付过,返回false,表示支付失败(重复支付)
return false;
} else {
// 如果没有支付过,记录支付信息
payments.put(paymentId, amount);
// 执行支付逻辑,如调用第三方支付平台
// ...
return true; // 表示支付成功
}
}
}在这个示例中,PaymentServiceImpl类实现了PaymentService接口。makePayment方法首先检查支付ID是否已经存在于支付记录中,如果存在,则表示这是一个重复的支付请求,方法返回false。如果不存在,方法将记录支付信息并执行支付逻辑,然后返回true。
幂等性的关键实现点:
-
唯一标识:使用支付ID作为唯一标识,确保每次支付请求都可以被识别和验证。
-
状态检查:在执行操作前,先检查系统状态,以确定操作是否已经执行过。
-
状态更新:只有当操作未被执行时,才更新系统状态。
说明和解释:
-
幂等性与业务逻辑:幂等性需要与业务逻辑紧密结合,不同的业务操作可能有不同的幂等性实现方式。
-
幂等性与数据库操作:数据库操作(如插入、更新)通常可以通过唯一约束、事务等机制来实现幂等性。
-
幂等性与分布式事务:在分布式事务中,幂等性是实现补偿事务(Compensating Transaction)的基础。
幂等性是设计分布式系统时必须考虑的一个重要特性,它有助于提高系统的健壮性、简化错误处理逻辑,并确保数据的一致性。