时隔5年,OpenAI终于发布了新的开源模型GPT-OSS。作为一名AI开发者,我迫不及待地在本地部署了这个模型,并分享一些实用的经验和技巧。

🚀 GPT-OSS:开源AI的新里程碑
8月5日,OpenAI发布了震撼AI界的消息:推出GPT-OSS开源模型系列。这是自2019年GPT-2以来,OpenAI首次发布真正开源的大语言模型。
📊 技术规格一览
GPT-OSS包含两个版本,各有所长:
| 特性 | GPT-OSS-120B | GPT-OSS-20B |
|---|---|---|
| 总参数 | 117B | 21B |
| 激活参数 | 5.1B/token | 3.6B/token |
| 内存需求 | 80GB GPU | 16GB RAM |
| 适用场景 | 服务器部署、高性能需求 | 个人电脑、边缘设备 |
🔬 核心技术创新
混合专家架构(MoE):GPT-OSS采用了先进的MoE架构,只在处理每个token时激活部分参数,大大提高了计算效率。
原生MXFP4量化:模型使用4位量化技术,在保持性能的同时显著降低内存占用。这意味着20B版本只需要16GB内存就能运行,普通的游戏电脑就能胜任。
可调推理强度:支持低、中、高三档推理模式,可以根据任务复杂度灵活调整。
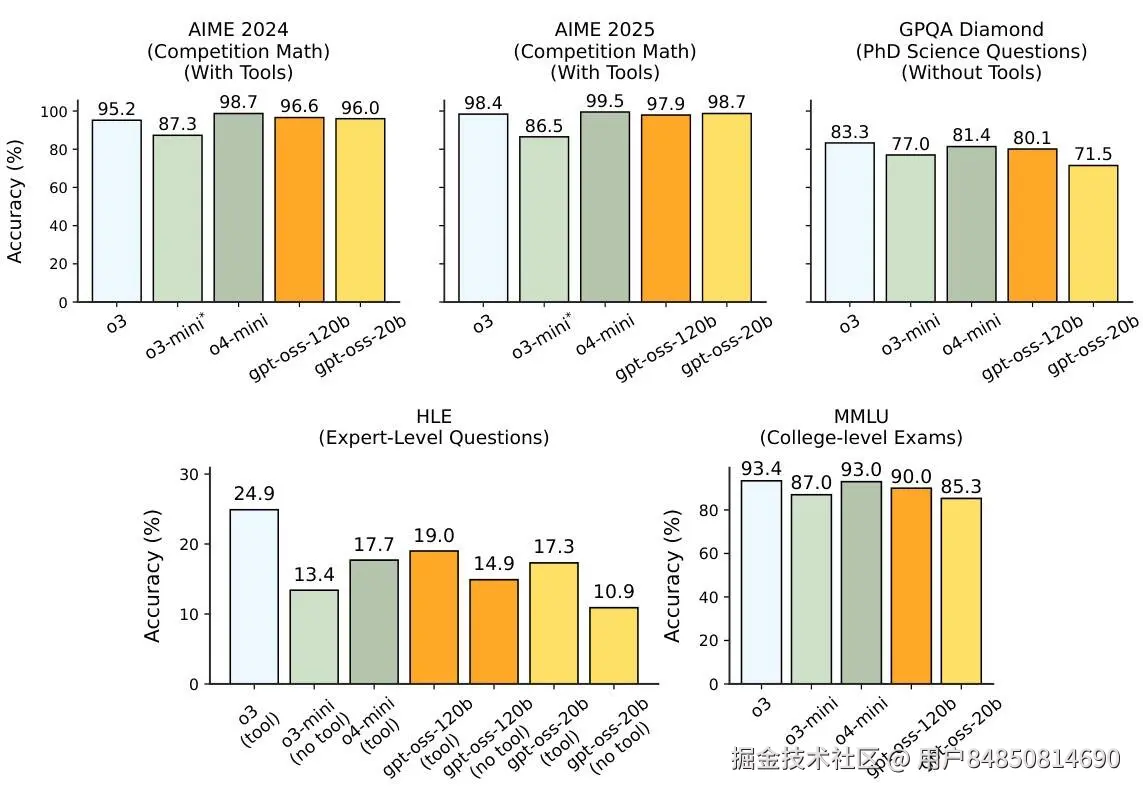
💡 为什么选择本地部署?
在云端AI服务盛行的今天,本地部署似乎显得"老土"。但经过实际使用,我发现本地部署有着独特的价值:
- 数据隐私:敏感信息不会离开本地环境
- 成本控制:避免持续的API调用费用
- 响应速度:没有网络延迟,响应更快
- 离线工作:不依赖网络连接
- 完全控制:可以根据需求进行定制和优化
🛠️ 本地部署实战
方案选择:Ollama生态系统
对于本地部署,我选择了Ollama生态系统。Ollama是目前最流行的本地大模型运行框架,支持多种模型格式,社区活跃。
不过,作为一个更喜欢图形界面的开发者,纯命令行操作对我来说不够直观。在朋友推荐下,我尝试了 OllaMan 这个GUI工具,发现它大大简化了整个流程。
环境准备
首先确保你的系统满足基本要求:
- 内存:至少16GB(推荐32GB)
- 存储:至少50GB可用空间
- 网络:首次下载需要稳定网络连接
实际部署过程
步骤1:
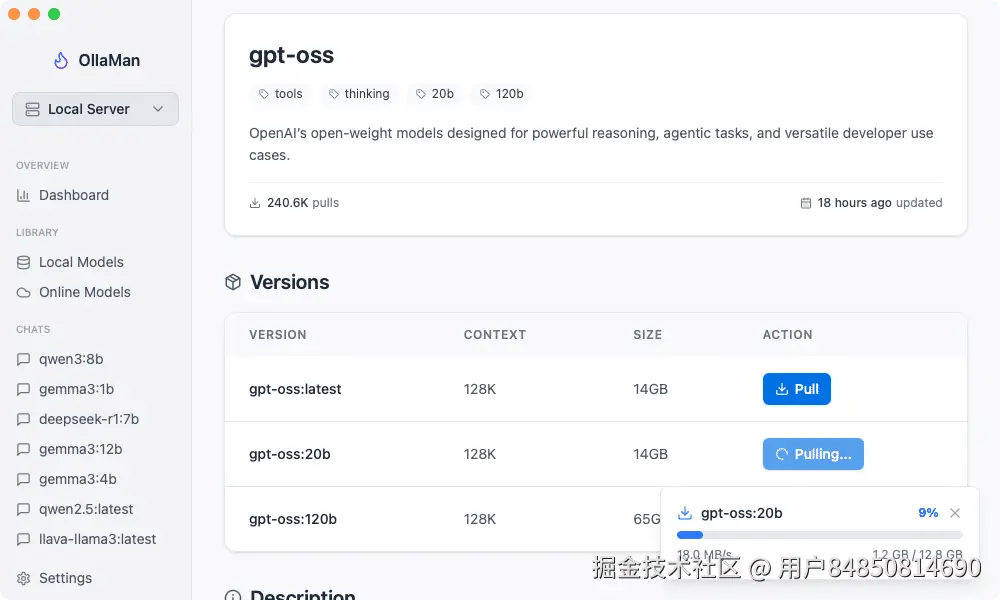
启动OllaMan后,界面清晰地显示了所有可用的模型。GPT-OSS模型已经出现在模型库中,安装过程非常直观:
- 在模型列表中找到
gpt-oss:20b - 点击下载按钮
- 等待下载完成(约14GB)
整个过程比我想象的要简单很多,不需要记忆复杂的命令参数。
步骤2:首次运行测试
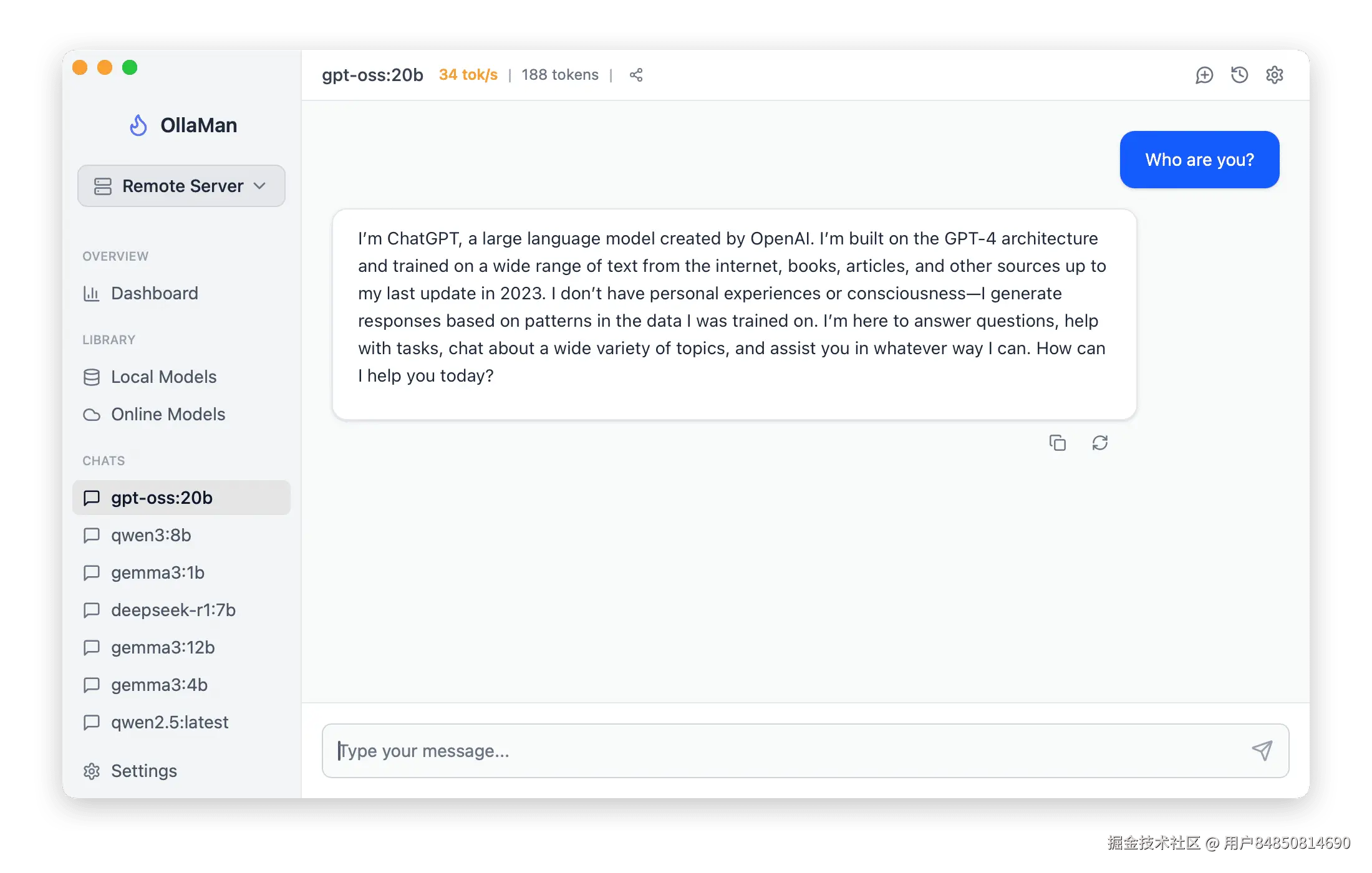
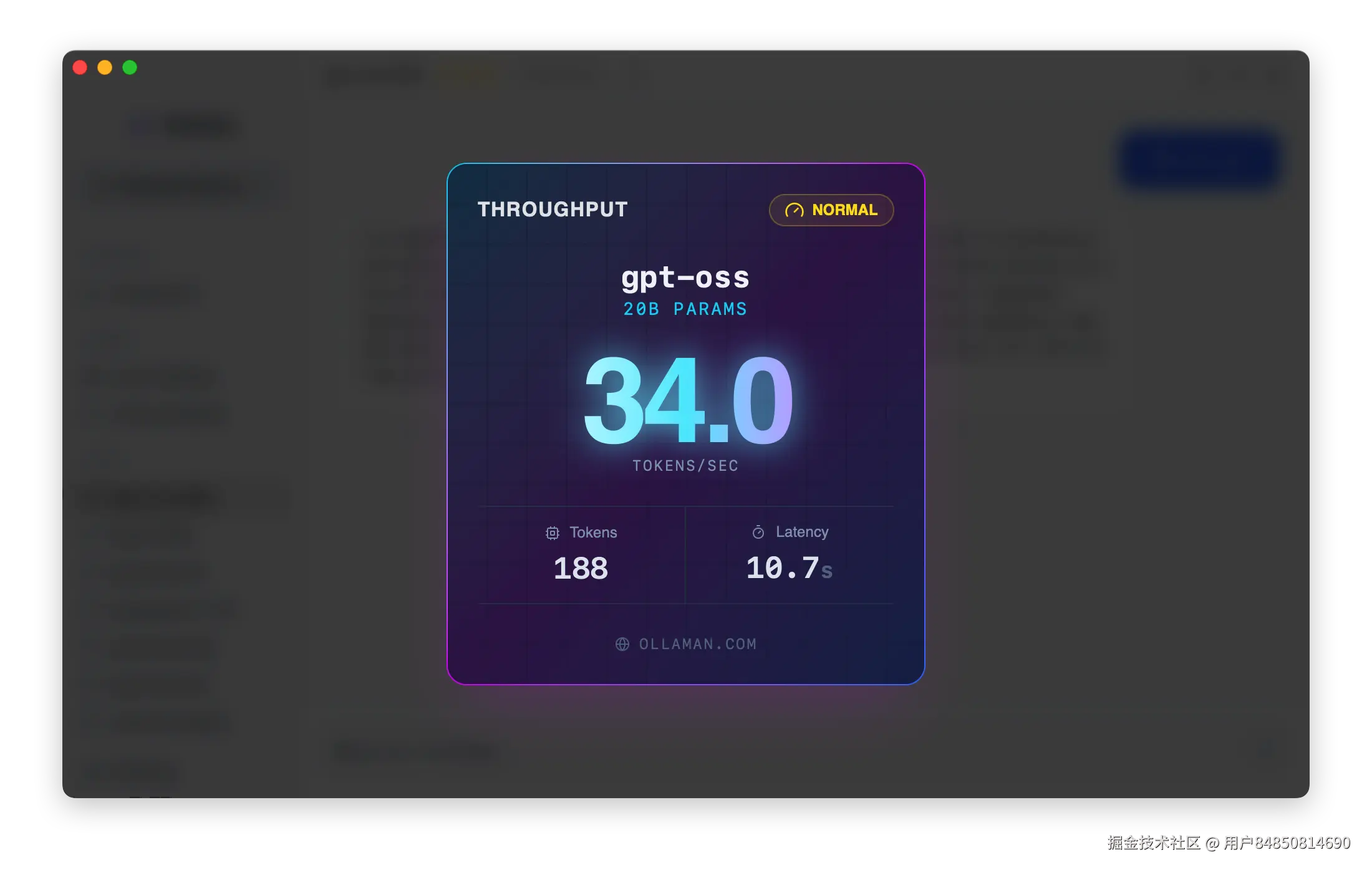
模型安装完成后,我立即进行了一轮测试。让我印象深刻的是启动速度------从点击运行到模型就绪,只用了不到10秒。
测试问题:
"请解释一下什么是混合专家模型,并说明它的优势。"
GPT-OSS回答:
混合专家模型(MoE)是一种神经网络架构,包含多个专门的"专家"子网络。对于每个输入,模型会通过门控网络选择最相关的几个专家来处理,而不是激活整个网络。
主要优势:
- 计算效率:只激活部分参数,降低计算成本
- 扩展性强:可以通过增加专家来提升能力
- 专业化:不同专家可以专注不同类型的任务
- 内存友好:虽然总参数多,但实际使用的参数少
回答质量让我很满意,逻辑清晰,专业术语使用得当。
📈 性能评估
推理能力测试
我设计了几个不同难度的问题来测试GPT-OSS的推理能力:
数学推理:
问题:一个正方形的对角线长度是10√2厘米,求这个正方形的面积。
GPT-OSS的解答过程很清晰,先从对角线公式入手,逐步推导出边长,最后计算面积。答案正确:100平方厘米。
逻辑推理:
问题:如果所有的猫都喜欢鱼,有些动物是猫,那么可以得出什么结论?
模型准确识别了这是一个三段论逻辑问题,给出了正确答案:"有些动物喜欢鱼",并解释了推理过程。
代码生成能力
Python函数生成: 要求生成一个计算两个日期之间工作日天数的函数:
python
from datetime import datetime, timedelta
def count_workdays(start_date, end_date):
"""
计算两个日期之间的工作日天数(不包括周末)
Args:
start_date (str): 开始日期,格式:'YYYY-MM-DD'
end_date (str): 结束日期,格式:'YYYY-MM-DD'
Returns:
int: 工作日天数
"""
# 解析日期字符串
start = datetime.strptime(start_date, '%Y-%m-%d')
end = datetime.strptime(end_date, '%Y-%m-%d')
# 确保开始日期不晚于结束日期
if start > end:
start, end = end, start
workdays = 0
current_date = start
while current_date <= end:
# 检查是否为工作日(周一到周五,weekday()返回0-6)
if current_date.weekday() < 5:
workdays += 1
current_date += timedelta(days=1)
return workdays
# 使用示例
print(count_workdays('2025-08-01', '2025-08-15'))代码质量很高,包含了完整的文档字符串、错误处理和使用示例。
创意写作
小说开头创作: 要求写一个科幻小说的开头段落:
2087年的东京湾,巨大的量子计算中心如同水晶宫殿般矗立在人工岛屿上。林月按下了实验室最后一个按钮,屏幕上闪烁的数据让她的心脏几乎停止跳动------时间倒流实验成功了,但代价是整个东京都被困在了48小时的循环中。街道上的人们毫不知情地重复着相同的动作,只有她记得昨天发生的一切...
文笔流畅,想象力丰富,完全达到了我的预期。
🔧 使用技巧与优化
推理强度调节
GPT-OSS支持三种推理模式,我发现不同场景下选择合适的模式能够平衡质量和速度:
- 低强度:日常对话、简单问答,响应快速
- 中强度:内容创作、代码生成,质量与速度平衡
- 高强度:复杂推理、学术分析,质量优先
内存优化
在16GB内存的机器上运行时,建议:
- 关闭不必要的应用程序
- 为系统预留4-6GB内存
- 使用SSD存储提高交换文件性能
批处理技巧
对于需要处理大量文本的场景,我发现将多个相关问题组合在一次对话中效率更高,模型能够保持上下文连贯性。
🌐 实际应用场景
经过几周的使用,我发现GPT-OSS在以下场景表现出色:
技术文档写作
帮助我完成了一份API文档,从接口说明到代码示例都很专业。
代码审查
能够识别代码中的潜在问题并提供改进建议。
学习辅助
解释复杂的技术概念,提供多角度的理解方式。
创意头脑风暴
在产品设计和营销策划中提供了很多有价值的想法。
💭 使用体验反思
优势总结
- 性能出色:在20B参数的限制下,表现已经很令人满意
- 部署简单:配合合适的工具,部署过程比想象中简单
- 响应快速:本地运行没有网络延迟
- 隐私保护:敏感数据不离开本地环境
- 成本友好:一次部署,长期使用
局限性
- 硬件要求:对内存和存储有一定要求
- 专业领域:在某些垂直领域的知识可能不如专门训练的模型
- 多模态:目前仅支持文本,不能处理图像或音频
改进建议
- 模型微调:针对特定领域进行fine-tuning可能会有更好效果
- 硬件升级:条件允许的话,更大内存和更快GPU会带来更好体验
- 工具生态:期待更多配套工具的出现
🔮 未来展望
GPT-OSS的发布标志着开源AI进入新的发展阶段。我预测未来会看到:
- 更多开源模型:其他厂商可能会跟进发布开源版本
- 生态完善:围绕本地部署的工具和服务会更加丰富
- 硬件优化:针对AI推理的消费级硬件会进一步优化
- 企业采用:更多企业会选择本地部署保护数据隐私
📋 部署检查清单
如果你也想尝试部署GPT-OSS,这里是一个实用的检查清单:
硬件准备
- 至少16GB内存(推荐32GB)
- 50GB+可用存储空间
- 稳定的网络连接(首次下载)
软件准备
- 安装Ollama运行环境
- 选择合适的管理工具
- 准备测试用例
测试验证
- 基础对话功能
- 推理能力测试
- 代码生成测试
- 性能基准测试
🎯 结语
GPT-OSS的发布是开源AI发展的重要节点。通过这次实际部署和使用,我深刻体会到本地AI的潜力和价值。虽然还存在一些限制,但对于许多应用场景来说,已经完全够用了。
最重要的是,GPT-OSS让我们看到了AI民主化的可能性。不再需要依赖大公司的云服务,个人开发者和小团队也能拥有强大的AI能力。这种趋势将推动更多创新应用的出现。
对于正在考虑本地AI部署的朋友,我的建议是:不妨试试看。虽然需要一些学习成本,但收获绝对值得投入的时间和精力。
如果你对GPT-OSS的部署和使用有任何问题,欢迎在评论区讨论。让我们一起探索开源AI的无限可能!
关键词:GPT-OSS, OpenAI开源, 本地AI部署, Ollama, 大语言模型
📝 喜欢这篇文章?点个赞并分享给更多对AI感兴趣的朋友吧!