概述
近期在研究基于Godot的XML和SVG解析,并且在昨天(2024年7月20日)编写了一个简易的SVG文件解析器。
在群友的提示下,知道早就存在GodotXML这样的解析器。所以今天就来测试使用并准备研究学习源代码了。和以往一样,看源码里一堆英文注释就手痒,机翻之。并且想要分享出来,供大家一起学习,于是就有了这篇笔记。
GodotXML简介
GodotXML是一个为Godot4引擎提供高级XML支持的插件,项目代码在Github上开源,项目地址:https://github.com/elenakrittik/GodotXML。
GodotXML支持Godot 4.0-4.2,以及可能的未来版本。
功能
- 纯GDSCript实现:基于GDSCript内置的
XMLParser编写 - 将XML数据加载和转储到基于类格式的便捷方式。
- 美化XML(类似于VSCode中的"文档格式化"功能)
- 可以将XML转换成字典。
- 将具有唯一名称的子节点访问为常规属性(在编辑器中也可用)。
- 当输入格式不正确时提供合理的错误消息。
安装
- 在Godot4资产库中搜索 "GodotXML" 插件安装
- 或者在Github项目主页下载ZIP压缩包到本地,将
addons/文件夹复制到项目的根目录。
下载下来后核心只有3个.gd文件,说是插件其实就是2个静态函数库+2个类。

源码翻译+重排
XML

xml.gd内部是一个class_name为XML的静态函数库- 使用
XML.parse_file()可以解析XML文件为XMLDocument实例 - 使用
XML.parse_string()可以解析XML字符串为XMLDocument实例 - 使用
XML.parse_buffer()可以解析PackedByteArray类型的XML内容为XMLDocument实例
下面是汉化注释和进行一定的内容重排的源代码:
swift
# ==================================================================
# 名称:XML
# 描述:GodotXML - Godot4的高级XML支持。此类允许从文件解析XML数据并将其转储到各种源。
# 原作者:elenakrittik(https://github.com/elenakrittik)
# 翻译+重排:巽星石 最后修改:2024年7月21日15:56:39
# ==================================================================
class_name XML extends RefCounted
# =============================== 表层解析函数(直接调用) ===============================
# 将文件内容作为XML解析为 XMLDocument 实例
# 指定路径处的文件必须可读,文件内容必须是语法有效的XML文档。
static func parse_file(path: String) -> XMLDocument:
var file = FileAccess.open(path, FileAccess.READ)
var xml: PackedByteArray = file.get_as_text().to_utf8_buffer()
file = null
return XML._parse(xml)
# 将字符串作为XML解析为 XMLDocument 实例
# 字符串内容必须是语法有效的XML文档
static func parse_str(xml: String) -> XMLDocument:
return XML._parse(xml.to_utf8_buffer())
# 将字 PackedByteArray 作为XML解析为 XMLDocument 实例
# PackedByteArray 内容必须是语法有效的XML文档。
static func parse_buffer(xml: PackedByteArray) -> XMLDocument:
return XML._parse(xml)
# =============================== 核心解析函数(底层、被调用) ===============================
# 被parse_file()、parse_str()、parse_buffer()调用
static func _parse(xml: PackedByteArray) -> XMLDocument:
xml = _cleanup_double_blankets(xml) # 见函数体中的注释
var doc := XMLDocument.new()
var queue: Array[XMLNode] = [] # 未关闭的标签队列
var parser := XMLParser.new()
parser.open_buffer(xml)
while parser.read() != ERR_FILE_EOF:
var node: XMLNode = _make_node(queue, parser)
# 如果节点类型为NODE_TEXT,则没有节点,因此我们跳过
if node == null:
continue
# 如果我们刚刚开始,我们将第一个节点设置为根节点并初始化队列
if len(queue) == 0:
doc.root = node
queue.append(node)
else:
var node_type := parser.get_node_type()
# 下面,`queue.back().childs.append(...)`表示:
# - 获取最后一个节点
# - 因为我们在那个未闭合的节点内,所以我们得到的所有非闭合节点都是它的子节点
# - 因此,我们访问.childs并将我们的非闭合节点附加到它们上
# 希望这能说明一切
if node.standalone:
queue.back().children.append(node)
# 这里一样
elif node_type == XMLParser.NODE_ELEMENT_END:
var last := queue.pop_back() # 获取删除最后一个未关闭的节点
# 如果我们有一个关闭节点,但它的名称与打开节点的名称不同,这是一个错误
if node.name != last.name:
push_error(
"Invalid closing tag: started with %s but ended with %s. Ignoring (output may be incorrect)." % [last.name, node.name]
)
# 我们没有在这里打断,而是继续,因为无效的名字往往只是一个拼写错误
continue
# we just closed a node, so if the queue is empty we stop parsing (effectively ignoring
# anything past the first root). this is done to prevent latter roots overwriting former
# ones in case when there's more than one root (invalid per standard, but still used in
# some documents). we do not natively support multiple roots (and will not, please do not
# open PRs for that), but if the user really needs to, it is trivial to wrap the input with
# another "housing" node.
# 我们刚刚关闭了一个节点,因此如果队列为空,我们将停止解析(实际上忽略了
# 任何超过第一根的东西)。这样做是为了防止后根覆盖前根
# 如果有多个根(根据标准无效,但仍在使用
# 一些文件)。我们本身不支持多个根(也不会,请不要
# 为此打开PR),但如果用户真的需要,用以下内容包装输入是很简单的
# 另一个"住房"节点。
if queue.is_empty():
break
# opening node
else:
queue.back().children.append(node)
queue.append(node) # 移动到节点体内
# 如果解析已结束,但仍有未关闭的节点,我们会报告它
if not queue.is_empty():
queue.reverse()
var names: Array[String] = []
for node in queue:
names.append(node.name)
push_error("The following nodes were not closed: %s" % ", ".join(names))
return doc
# =============================== 转换函数 ===============================
# 将 XMLDocument 实例转为纯文本存储到指定文件
static func dump_file(
path: String,
document: XMLDocument,
pretty: bool = false,
indent_level: int = 0,
indent_length: int = 2
) -> void:
return document.root.dump_file(path, pretty, indent_level, indent_length)
# 将 XMLDocument 实例转为 PackedByteArray形式
static func dump_buffer(
document: XMLDocument,
pretty: bool = false,
indent_level: int = 0,
indent_length: int = 2,
) -> PackedByteArray:
return document.root.dump_buffer(pretty, indent_level, indent_length)
## 将 XMLDocument 实例转为 String 形式
static func dump_str(
document: XMLDocument,
pretty: bool = false,
indent_level: int = 0,
indent_length: int = 2,
) -> String:
return document.root.dump_str(pretty, indent_level, indent_length)
# 创建节点
static func _make_node(queue: Array[XMLNode], parser: XMLParser) -> Variant:
var node_type := parser.get_node_type()
match node_type:
XMLParser.NODE_ELEMENT:
return XML._make_node_element(parser)
XMLParser.NODE_ELEMENT_END:
return XML._make_node_element_end(parser)
XMLParser.NODE_TEXT:
# 忽略根节点前的空白文本;这样更容易,相信我
if queue.is_empty():
return
XML._attach_node_data(queue.back(), parser)
return
XMLParser.NODE_CDATA:
if queue.is_empty():
return
_attach_node_cdata(queue.back(), parser)
return
return
# 创建节点元素
static func _make_node_element(parser: XMLParser) -> XMLNode:
var node := XMLNode.new()
node.name = parser.get_node_name()
node.attributes = XML._get_attributes(parser)
node.content = ""
node.standalone = parser.is_empty() # see .is_empty() docs
node.children = []
return node
# 创建结束标签
static func _make_node_element_end(parser: XMLParser) -> XMLNode:
var node := XMLNode.new()
node.name = parser.get_node_name()
node.attributes = {}
node.content = ""
node.standalone = false # 独立节点始终为NODE_ELEMENT
node.children = []
return node
#
static func _attach_node_data(node: XMLNode, parser: XMLParser) -> void:
# XMLParser将节点之间的空白内容视为NODE_TEXT,这是不需要的
# 因此,我们去除了"空格",导致只有实际的内容滑入到内容中
node.content += parser.get_node_data().strip_edges()
static func _attach_node_cdata(node: XMLNode, parser: XMLParser) -> void:
node.cdata.append(parser.get_node_name().strip_edges())
# 获取属性
static func _get_attributes(parser: XMLParser) -> Dictionary:
var attrs: Dictionary = {}
var attr_count: int = parser.get_attribute_count()
for attr_idx in range(attr_count):
attrs[parser.get_attribute_name(attr_idx)] = parser.get_attribute_value(attr_idx)
return attrs
static func _cleanup_double_blankets(xml: PackedByteArray) -> PackedByteArray:
# #XMLParser再次"不正确",并且由于双空格转义而重复节点
# https://github.com/godotengine/godot/issues/81896#issuecomment-1731320027
var rm_count := 0 # How much elements (blankets) to remove from the source
var idx := xml.size() - 1
# 以相反的顺序迭代。这对perf很重要,否则我们
# 需要执行double.reverse()并从一开始就删除元素
# 这两种阵列都相当昂贵
while idx >= 0:
if xml[idx] in [9, 10, 13]: # [\t, \n, \r]
rm_count += 1
idx -= 1
else:
break
# 移除空格
while rm_count > 0:
xml.remove_at(xml.size() - 1)
rm_count -= 1
return xmlXMLDocument

xml_document.gd中申明了一个XMLDocument类,用于表示XML文档,只提供一个root属性表示XML文档的根节点。
swift
# ==================================================================
# 名称:XMLDocument
# 描述:表示XML文档
# 原作者:elenakrittik(https://github.com/elenakrittik)
# 翻译+重排:巽星石 最后修改:2024年7月21日15:38:23
# ==================================================================
class_name XMLDocument extends RefCounted
# ========================================== 属性 ==========================================
var root: XMLNode
# ========================================== 虚函数 ==========================================
func _to_string():
return "<XMLDocument root=%s>" % self.rootXMLNode
可以看到比较核心和重要的内容放到了XMLNode类上。

swift
# ==================================================================
# 名称:XMLNode
# 描述:表示XML元素(又名XML节点)。
# 提示:如果只有一个同名的子节点,您可以通过 this_node.my_child_name 访问它!
# 原作者:elenakrittik(https://github.com/elenakrittik)
# 翻译+重排:巽星石 最后修改:2024年7月21日15:38:23
# ==================================================================
class_name XMLNode extends RefCounted
# ========================================== 属性 ==========================================
var name: String = "" # 节点名称
var attributes: Dictionary = {} # 节点属性字典
var content: String = "" # 节点内容
var cdata: Array[String] = [] # CDATA
var standalone: bool = false # 是否为空节点(也就是自闭合标签)
var children: Array[XMLNode] = [] # 子节点
var _node_props: Array
var _node_props_initialized: bool = false
const KNOWN_PROPERTIES: Array[String] = ["name", "attributes", "content", "cdata", "standalone", "children"]
# ========================================== 虚函数 ==========================================
# print()或调用to_string()时返回的文本
func _to_string():
return "<XMLNode name=%s attributes=%s content=%s cdata=%s standalone=%s children=%s>" % [
self.name,
"{...}" if len(self.attributes) > 0 else "{}",
'"..."' if len(self.content) > 0 else '""',
"[...]" if len(self.cdata) > 0 else "[]",
self.standalone,
"[...]" if len(self.children) > 0 else "[]"
]
# 通过GDScript进行点访问
func _get(property: StringName):
if not self._node_props_initialized:
self._initialize_node_properties()
if (
property not in KNOWN_PROPERTIES
and property in self._node_props
):
for child in self.children:
if child.name == property:
return child
# 通过编辑器进行点式访问
func _get_property_list() -> Array[Dictionary]:
var props: Array[Dictionary] = []
if not self._node_props_initialized:
self._initialize_node_properties()
for child_name in self._node_props:
props.append({
"name": child_name,
"type": TYPE_OBJECT,
"class_name": "XMLNode",
"usage": PROPERTY_USAGE_DEFAULT,
"hint": PROPERTY_HINT_NONE,
"hint_string": "",
})
return props
# 初始化节点属性
func _initialize_node_properties() -> void:
var names_to_nodes := {}
for child: XMLNode in self.children:
if not child.name in names_to_nodes.keys():
names_to_nodes[child.name] = child
else:
names_to_nodes.erase(child.name)
self._node_props = names_to_nodes.keys()
self._node_props_initialized = true
# ========================================== 方法 ==========================================
# 将当前节点(及其所有子节点)转换为字典形式
func to_dict() -> Dictionary:
var output := {}
output["__name__"] = self.name # 节点名称
output["__content__"] = self.content # 节点内容
output["__cdata__"] = self.cdata # CDATA
output["attrs"] = self.attributes # 节点属性
# 遍历+递归获取子节点的字典形式
var children_dict := {}
for child in self.children:
children_dict[child.name] = child.to_dict()
output["children"] = children_dict
return output
# -------------------- 类型转化 --------------------
# 将当前节点转储到指定文件
func dump_file(path: String,pretty: bool = false,indent_level: int = 0,indent_length: int = 2) -> void:
var file = FileAccess.open(path, FileAccess.WRITE)
var xml: String = self.dump_str(pretty, indent_level, indent_length)
file.store_string(xml)
file = null
# 将当前节点转化为 PackedByteArray 形式
func dump_buffer(pretty: bool = false,indent_level: int = 0,indent_length: int = 2) -> PackedByteArray:
return self.dump_str(pretty, indent_level, indent_length).to_utf8_buffer()
# 将当前节点转化为 String 形式。
func dump_str(pretty: bool = false,indent_level: int = 0,indent_length: int = 2) -> String:
if indent_level < 0:
push_warning("indent_level必须>= 0")
indent_level = 0
if indent_length < 0:
push_warning("indent_length必须>= 0")
indent_length = 0
return self._dump() if not pretty else self._dump_pretty(indent_level, indent_length)
# -------------------- 类型转化核心函数(底层、被调用) --------------------
# 转化核心函数
func _dump() -> String:
var attribute_string := ""
var children_string := ""
var cdata_string = ""
if not self.attributes.is_empty():
attribute_string += " "
for attribute_key in self.attributes:
var attribute_value := self.attributes.get(attribute_key)
if attribute_value is String:
attribute_value = attribute_value.xml_escape(true)
attribute_string += '{key}="{value}"'.format({"key": attribute_key, "value": attribute_value})
for child: XMLNode in self.children:
children_string += child._dump()
for cdata_content in self.cdata:
cdata_string += "<![CDATA[%s]]>" % cdata_content.replace("]]>", "]]]]><![CDATA[>")
if self.standalone:
return "<" + self.name + attribute_string + "/>"
else:
return (
"<" + self.name + attribute_string + ">" +
self.content.xml_escape() + cdata_string + children_string +
"</" + self.name + ">"
)
# -------------------- 格式化 --------------------
# 格式化XML文档
# 让杂乱的内容变的清晰美观
func _dump_pretty(indent_level: int, indent_length: int) -> String:
var indent_string := " ".repeat(indent_level * indent_length)
var indent_next_string := indent_string + " ".repeat(indent_length)
var attribute_string := ""
var content_string := "\n" + indent_next_string + self.content.xml_escape() if not self.content.is_empty() else ""
var children_string := ""
var cdata_string := ""
if not self.attributes.is_empty():
for attribute_key in self.attributes:
var attribute_value := self.attributes.get(attribute_key)
if attribute_value is String:
attribute_value = attribute_value.xml_escape(true)
attribute_string += ' {key}="{value}"'.format({"key": attribute_key, "value": attribute_value})
for child: XMLNode in self.children:
children_string += "\n" + child.dump_str(true, indent_level + 1, indent_length)
for cdata_content in self.cdata:
cdata_string += "\n" + indent_next_string + (
"<![CDATA[%s]]>" % cdata_content.replace("]]>", "]]]]>\n%s<![CDATA[>" % indent_next_string)
)
if self.standalone:
return indent_string + "<" + self.name + attribute_string + "/>"
else:
return (
indent_string + "<" + self.name + attribute_string + ">" +
content_string + cdata_string + children_string +
"\n" + indent_string + "</" + self.name + ">"
)使用
解析XML文件
swift
@tool
extends EditorScript
func _run() -> void:
var xml_doc:XMLDocument = XML.parse_file("icon.svg") # 解析SVG文件为XMLDocument实例
print(xml_doc)
pass上面代码中:
- 我们使用XML静态函数库的
parse_file()静态方法,将Godot项目根目录的icon.svg解析为XMLDocument实例 print(xml_doc)会自动调用XMLDocument内部的_to_string()并打印其返回值
输出:
swift
<XMLDocument root=<XMLNode name=svg attributes={...} content="" cdata=[] standalone=false children=[...]>>转化为字典形式
swift
@tool
extends EditorScript
func _run() -> void:
var xml_doc:XMLDocument = XML.parse_file("icon.svg") # 解析SVG文件为XMLDocument实例
var root:XMLNode = xml_doc.root # 获取根节点
var dict:Dictionary = root.to_dict() # 转化为字典形式
print(JSON.stringify(dict,"\t") ) # 以格式化的JSON形式打印上面代码中:
- 使用
XMLNode的to_dict()方法会讲当前节点转化为字典,并采用递归形式将其所有子孙节点转化为字典放入对应父节点的children属性中。 XMLDocument用root属性记录了解析后的XML文档根节点,我们只需要对这个根节点调用to_dict()方法,就可以获得整个XML文档的字典形式
上面代码输出:
json
{
"__cdata__": [],
"__content__": "",
"__name__": "svg",
"attrs": {
"height": "128",
"width": "128",
"xmlns": "http://www.w3.org/2000/svg"
},
"children": {
"g": {
"__cdata__": [],
"__content__": "",
"__name__": "g",
"attrs": {
"transform": "scale(.101) translate(122 122)"
},
"children": {
"g": {
"__cdata__": [],
"__content__": "",
"__name__": "g",
"attrs": {
"fill": "#414042"
},
"children": {
"circle": {
"__cdata__": [],
"__content__": "",
"__name__": "circle",
"attrs": {
"cx": "717",
"cy": "532",
"r": "60"
},
"children": {
}
}
}
}
}
},
"rect": {
"__cdata__": [],
"__content__": "",
"__name__": "rect",
"attrs": {
"fill": "#363d52",
"height": "124",
"rx": "14",
"stroke": "#212532",
"stroke-width": "4",
"width": "124",
"x": "2",
"y": "2"
},
"children": {
}
}
}
}可以看到,每个节点主要结构:
__name__:存储XML节点名称__content__:存储XML节点内部的文本__cdata__:存储CDATDattrs:以字典和键值对形式存储XML节点的属性和值children以字典形式存储XML节点的子节点
构造XML文件
能够解析XML文件,本质上已经意味着可以用代码形式生成XML文件。
swift
@tool
extends EditorScript
func _run() -> void:
var xml_doc:= XMLDocument.new()
# 根节点svg
var root = XMLNode.new()
root.name = "svg"
root.attributes = {
"width":200,
"height":200
}
# 子节点rect
var rect = XMLNode.new()
rect.name = "rect"
rect.attributes = {
"width":200,
"height":200,
"fill":"red"
}
root.children.append(rect) # 添加为根节点的子节点
xml_doc.root = root # 设为文档根节点
print(XML.dump_str(xml_doc)) # 转为文本形式输出:
swift
<svg width="200"height="200"><rect width="200"height="200"fill="red"></rect></svg>pretty参数设为true:
swift
print(XML.dump_str(xml_doc,true)) # 转为文本形式输出:
swift
<svg width="200" height="200">
<rect width="200" height="200" fill="red">
</rect>
</svg>可以看到这里默认把<rect>设定为双标签了。
我们只需要设定rect的standalone属性等于true就可以了,输出:
swift
<svg width="200" height="200">
<rect width="200" height="200" fill="red"/>
</svg>存储文件
要将生成的XML或SVG内容存储为文件,只需要调用XML静态函数库的dump_file()方法就可以了。
swift
XML.dump_file("test.svg",xml_doc,true) # 转为文本形式打开后:

我们只需要给根节点<svg>标签加上xmlns属性和其固定值http://www.w3.org/2000/svg就可以了。
swift
# 根节点svg
var root = XMLNode.new()
root.name = "svg"
root.attributes = {
"width":200,
"height":200,
"xmlns":"http://www.w3.org/2000/svg"
}此时生成的SVG文件就可以正常查看了。

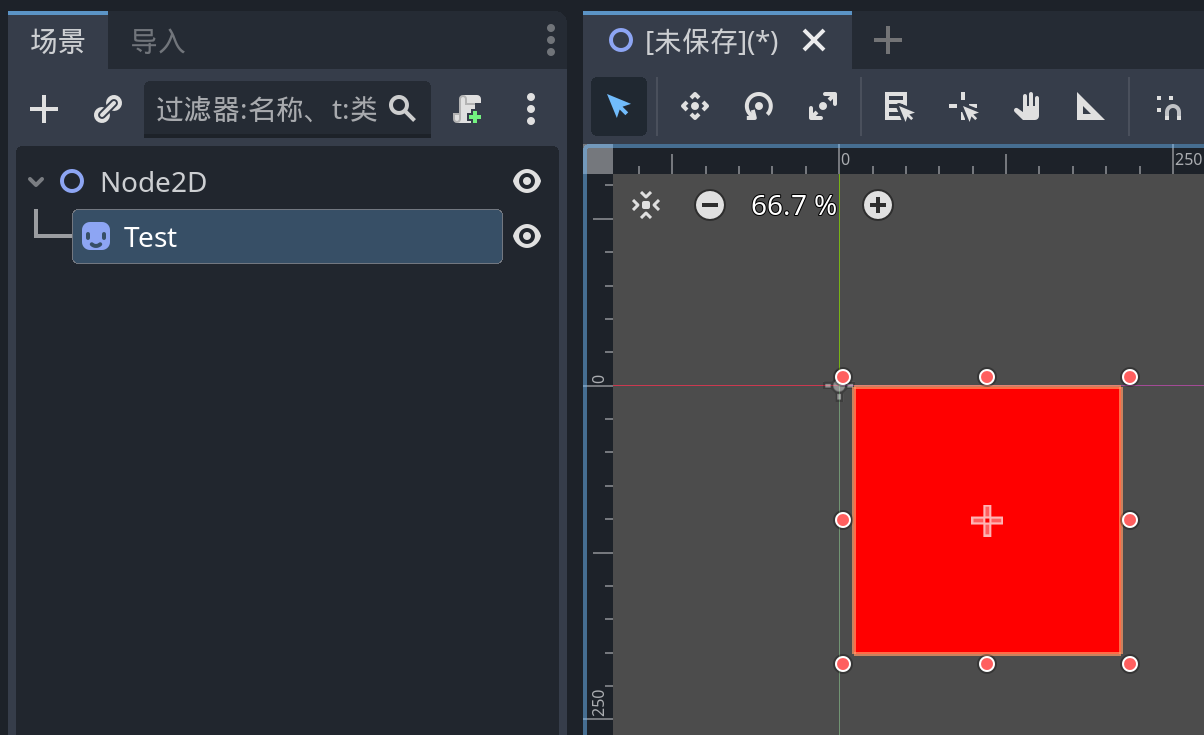
也可以直接在Godot中使用了:
个人心声
- 之所以研究SVG,是因为它的确是可以在Godot作为素材使用的,而且它在本质上是纯文本,而且参数化和矢量化的(在Godot使用时不纯矢量形式)。
- 在研究完Godot内置绘图函数后,我发现SVG与绘图函数参数化的形式最为接近,所以SVG甚至可以与绘图函数互转,也是就SVG作为绘图函数的文件存储形式,而绘图函数渲染SVG图形
- 虽然好似没什么用,但是:如果你可以设计一个分层的图形编辑器,你便可以在Godot中制作一个属于自己的InkScape了(同样已经有类似项目)
- 还有一点,可以用GDSCript以函数或代码形式动态生成SVG图形,并赋值给节点。这对于编写相关的插件非常有用。
- 对于
TextureButton或TextureProgress节点,可以参数化可视化的生成其所需的图片元素 - 可以将碰撞图形、Polygon2D、Line2D、Path2D等的形状和路径信息转为SVG形式存储和修改
- ...
总结
- Godot中的
XMLParser类只提供了基础的API来解析XML文件,如果需要像Config或JSON一样容易使用,你就需要自己动手编写一个解析器,诚如前文笔者(Bilibili@巽星石)确实也自己编写了一个名为SVGParser的简易解析器类 - 而开源项目GodotXML,其实算是国外大佬的先行之作,低级别的可以直接"拿来主义",用就完事儿,但是我想也有对源代码和设计思路感兴趣的,所以对整个源代码注释内容进行了机翻辅助人工汉化。并做了一些符合我个人代码注释风格的补充和重排。希望可以让自己和小伙伴们研究学习源码时更容易读懂
- 在源码汉化重排的基础上,我适当绘制了一些类图,将比较重要的属性和方法摘出来,让大家对类的设计和结构有个更直观的了解
- 在实际上手使用和测试的基础上,我简单补充了一些用法实例,实际测试表明GodotXML可以比较稳定的发挥XML包括SVG文件的解析、转换以程序化生成和存储文件的作用。
- 希望对你的学习有用,手闲可以点赞鼓励一下