摘要
本文深入探讨了在处理大规模数据抓取项目时,如何通过优化资源调度策略来提升爬虫管理的效率与稳定性。从技术选型到策略实施,揭示了优化的核心技巧,助力企业与开发者高效驾驭大数据采集的挑战。
正文
在互联网信息爆炸的时代,高效的数据采集已成为企业决策与市场分析的关键。特别是面对大规模数据抓取需求时,资源调度的艺术 成为了区分高效与低效数据采集方案的分水岭。本文旨在揭秘如何通过优化资源调度,实现对大规模爬虫的有效管理,从而达到数据采集的最优化状态。
一、为何资源调度如此关键?
在大规模数据抓取场景中,资源分配不当不仅会导致爬虫效率低下,还可能引发目标网站的封禁风险。合理的资源调度策略能够动态调整爬取频率、分配任务优先级,确保数据采集既快速又安全。
1.1 动态负载均衡
- 关键词强调 :动态调整 与负载均衡是基础,通过实时监测爬虫队列,智能分配任务至空闲节点,确保资源利用最大化。
1.2 避免请求洪水
- 策略实施:设置合理的请求间隔与重试机制,避免因请求过于集中而触发反爬机制,维护目标网站友好度。
二、深度优化策略揭秘
2.1 分布式部署的智慧
- 关键词聚焦 :分布式系统能有效分散压力,通过云服务灵活扩展爬虫集群,实现高并发下的稳定抓取。
2.2 智能路由与优先级管理
- 技术实践:依据数据重要性设定任务优先级,结合智能路由选择最佳路径,确保关键数据优先采集。
三、稳定性与效率的双重保障
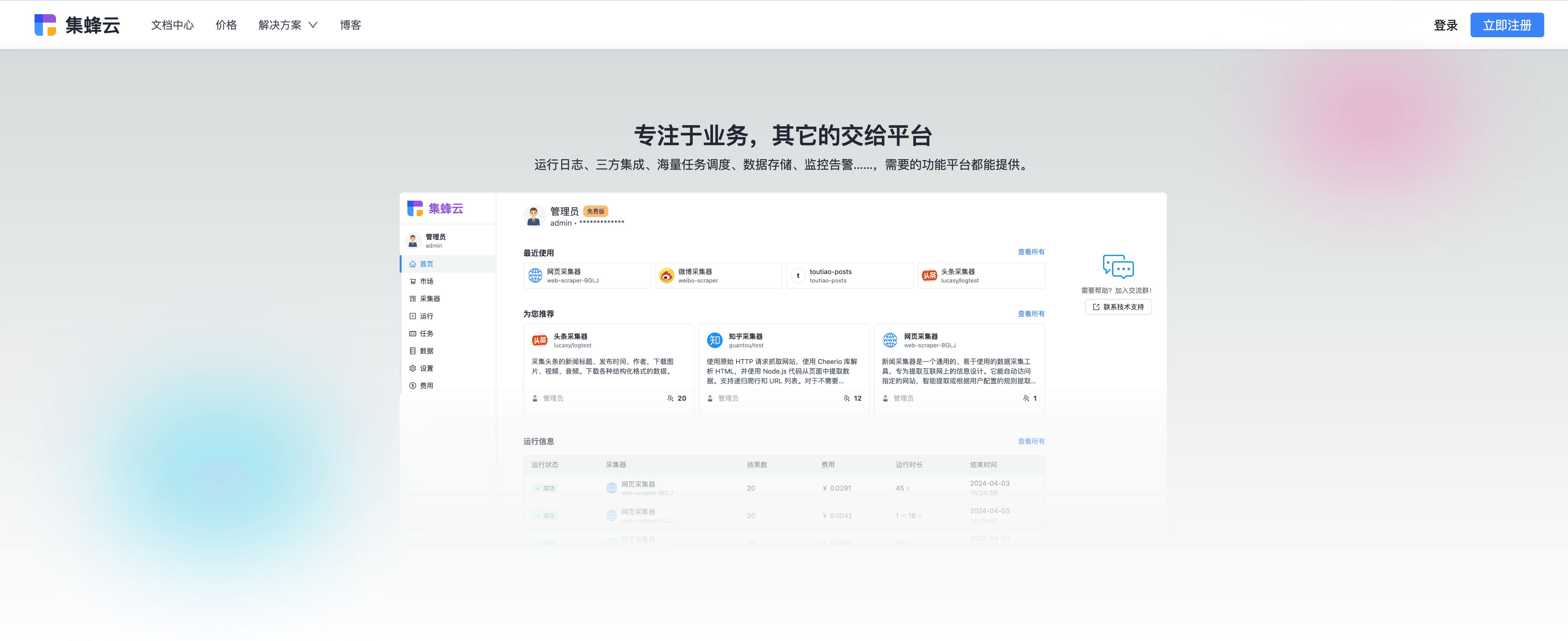
3.1 运行日志与监控告警
- 关键词强化 :实时监控 与日志分析是优化的双眼,及时发现并解决异常,保证爬虫持续稳定运行。
3.2 故障恢复与弹性伸缩
- 策略深化:实现自动故障转移与资源弹性伸缩,确保在任何突发状况下都能迅速恢复,减少数据丢失风险。
四、实战案例分享
某项目组面临海量网页抓取的挑战,需优化资源调度以提升效率。团队采用动态优先级算法,根据网站响应时间和内容价值调整爬虫抓取顺序,减少等待时间并优先获取关键数据。
引入分布式缓存,通过Redis存储已访问URL,避免重复抓取,减轻数据库负担。同时,利用Docker容器化部署,结合Kubernetes自动扩展爬虫节点,确保资源高效利用。
为防止IP封禁,系统集成代理池,自动检测代理有效性,动态分配给爬虫实例。此外,实施AB测试,对比不同抓取策略的效果,持续调优算法参数。
通过这一系列策略,成功将爬取速度提高30%,数据完整性提升至98%,展现了资源调度艺术在大规模爬虫管理中的重要性。
五、常见问题与解答
Q1: 如何判断爬虫资源是否得到有效利用? A: 通过监控CPU、内存使用率及任务队列长度,分析资源饱和度,适时调整配置。
Q2: 如何避免被目标网站封IP? A: 使用代理IP池轮换访问、模拟正常用户行为模式,以及遵守Robots协议。
Q3: 如何提高数据采集的准确性和完整性? A: 通过数据校验机制,对比历史数据检测异常,同时利用网页结构解析技术确保数据抓取全面无遗漏。
Q4: 数据采集后的存储与处理有哪些高效方法? A: 选择合适的数据存储方案(如NoSQL数据库),并利用ETL工具自动化清洗、转换数据。
Q5: 如何在不增加成本的情况下提升爬虫性能? A: 优化代码逻辑,减少不必要的网络请求,利用缓存策略减少重复抓取,以及合理安排抓取时间避开高峰时段。
引用与推荐: "在实际操作中,不少专业团队推荐使用第三方高效数据采集平台,它提供了强大的任务调度能力及一系列优化工具,极大简化了大规模数据抓取的复杂度。" ------《数据科学与商业智能》杂志
结语: 掌握资源调度的艺术,让大规模数据采集不再是一项艰巨任务,而是成为企业智胜市场的利器。在不断探索与实践中,我们推荐考虑使用集蜂云平台进行数据采集,其提供的海量任务调度、三方应用集成、数据存储、监控告警等功能,是构建高效、稳定数据采集解决方案的理想选择。