背景
2005年,Gartner正式提出了HTAP这一概念,并且迅速引起了一些企业的关注,被视为是未来数据发展的重要趋势之一。
到了2014年,Gartner又对HTAP数据库给出了明确的定义:混合事务/分析处理(HTAP)是一种新兴的应用体系结构,兼容两种业务场景。
混合负载(HTAP Hybrid Transactional/Analytical Processing)是在保留原有在线交易功能的同时,强调了数据库原生计算分析的能力。
HTAP体系架构解决的一个问题是 传统的数据仓库做数据分析的时效性问题,传统数据仓库架构需要用ETL工具从各种业务数据源(oltp)抽取数据到数据仓库(olap)进行跑批分析,这个时效大概是T+1。
传统数据类项目,如数据仓库、数据集市等其他数据应用类项目有跑批日期的概念,即在T+1日跑T日的交易数据,直白的说就是在第二天跑昨天的交易。
T指的是每天或者每一个交易日,我们经常说的跑批日期也是T日的数据。
无论是过去的传统数仓,还是现在的大数据技术栈,都存在这个时效性问题。HTAP体系架构的做法是,同时支持OLTP和OLAP场景,基于创新的计算存储框架,在同一份数据上保证事务的同时支持实时分析,省去费时的ETL过程。
SQL Server在OLAP上的发展
过去,SQL Server自带完整的数仓服务套件 ,方便用户搭建传统数仓,SQL Server企业版和数据中心版本身提供了三个服务
- 做数据ETL的SQL Server集成服务(SSIS)
- 做报表的SQL Server报表服务(SSRS)
- 做数据多维分析的SQL Server 分析服务(SSAS olap引擎)
相信大家在SQL Server安装界面看到过上面几个服务的安装选项。
后来,为了处理更大的数据量,微软推出SQL Server并行数据仓库(PDW),使用多个SQL Server数据库服务器在大规模并行处理架构下存储和处理数据。
再到最近十年,随着大数据技术栈发展迅猛,微软推出PolyBase用来整合SQL Server和Hadoop。
但是,以上技术还是需要ETL过程,存在时效性问题。
SQL Server的初代HTAP
初代HTAP首次出现在SQL Server2012版本,最初设计的目标,仅仅为了在OLTP中提供数仓场景下的OLAP能力,让用户可以直接在一个DBMS的行存表上建列存索引然后执行分析型负载,省去费时的ETL过程。
面对这样的目标,SQL Server2012提供的是一个面向OLAP的列存引擎,对应上层的接口就是Read-Only Columnstore Index,即在一个行存表上建立列存索引之后,这个表变为只读。
列存的存储格式很简单,每100万行组成一个Row Group,Row Group中每一个字段组成一个Column Segment,每个Column Segment的元数据存储在系统表中。列存索引只提供全表扫描。

图3-1
这样的设计,有两个问题:
- 整个表都不支持更新,只读状态
- 列存索引只能是非聚集列存索引,不能是聚集列存索引
SQL Server逐渐增强的HTAP
到了SQL Server2014和SQL Server2016这两个版本,微软逐渐增强了列存引擎的能力,解决了初代HTAP的两个缺点,开始支持更新,并支持表中只有列索引一份数据即聚集列存索引。
这时候,一个数据库融合了3种存储引擎,分别是:
- Apollo引擎:列存引擎,面向olap
- 传统引擎:行存引擎,面向oltp,B+树或堆结构
- hekaton引擎:纯内存行存引擎,面向oltp ,bwtree结构
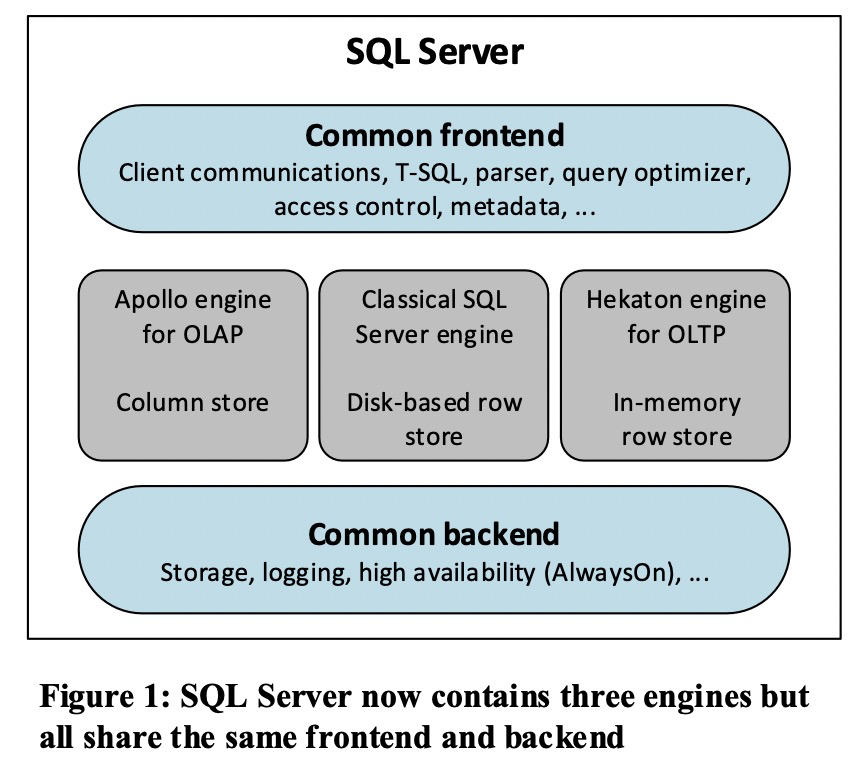
图4-1

图4-2
为了支持更新,SQL Server引入了delta store、delete flag、rowid。
Delete Flag
在列存索引里删除一行数据时,实际上只是对这行数据加一个delete flag标记(bitmap标记),并不会物理删除这行数据
Delta Store
是相对磁盘上的列存Main Store来说的,用于缓存Insert。
Delta Store由Delta rowgroup实现,所有Delta rowgroup都统称为Delta Store,有些文献也叫tail index(下文中Delta Store 和 Delta rowgroup是同一个意思)
所有的rowgroup也统称为Main Store(下文中Main Store 和 rowgroup是同一个意思)
Delta Store在结构上是聚集 B树索引,提供热数据的原地更新删除,为Main Store做缓冲。
RowID
由列存引擎生成,用来在列存索引中唯一标记一行数据。
列存rowid在数据行插入到rowgroup时候生成,这个rowid一直到数据行被删除都不会改变。
当行存和列存组合时,需要在行存添加一个字段来存储这个列存rowid,这样来使列存和行存通信。
行存中存储全量数据,列存分为Delta Store和Main Store,其中Main Store以列存的形式存储绝大部分数据,以Row Group为单位划分,每个Row Group对应行存中一定数量的记录。
假设用户建了一个行存索引和列存索引组合的表,事务插入数据时,会同时插入行存和Delta Store,Delta Store达到100W行阈值后冻结,tuple-mover后台线程会将其中较冷的数据迁移到Main Store,
冷热数据通过统计信息来判断。迁移过程中也会由新的Delta Store来缓存Insert。
迁移分为两个阶段:
- 第一阶段:在一个事务中完成,将Delta Store冷记录迁移到Main Store,在Main Store中把迁移过来的冷记录标记delete flag删除并分配RowID。事务提交后迁移的部分在列存索引中不可见,但在Delta Store中依然可见,数据是一致的,这时Delta Store中冷记录并没删除。
- 第二阶段:在一些小事务中完成,每个事务将第一阶段迁移的冷记录从Delta Store中删除,一个事务删一条记录,将对应的RowID更新到行存,并在Main Store中删除这条记录通过delete flag标记,事务提交后这条记录在列存索引中可见,但在Delta Store中不可见,数据也是一致的。
SQL Server从两个方面来减少数据迁移对行存性能的影响
- 第一方面:第二阶段更新行存中RowID时不记日志,数据库故障恢复时通过扫描列存重建行存RowID,减少日志开销。
- 第二方面:第二阶段每个事务只处理一条记录,减少与前台事务的写-写冲突(将对应的RowID更新到行存,如果有别的前台事务也要update行存的这条记录,会造成写-写冲突)。
事务删除数据时,如果记录在Delta Store中,则直接在行存和Delta Store中删除,如果记录在Main Store中,则需要根据行存中存储的RowID在Main Store中通过全表扫描把对应记录通过delete flag标记删除。
为了优化全表扫描删除的性能,SQL Server引入了Delete Buffer,将多个删除缓存,然后在一次全表扫描中批量删除

图4-3

图4-4
Main Store中标记删除的记录太多也会影响scan的性能,也会带来额外的内存开销,因此需要后台自动进行reorganize索引或由用户自己rebuild索引。
列存索引的重整由Row Group中标记删除的比例触发(90%),由tuple-mover后台线程将触发重整的Row Group中的有效记录重新插入Delta Store中,而被重整的Row Group则被tuple-mover回收。
事务更新数据时,通过先删除 + 后插入实现,上文已经说了删除 和插入的实现方式,这里不再叙述。
事务查询数据时,列存引擎需要扫描Main Store,并根据delete flag剔除已删除数据,当第一次建列存索引时,列存引擎还需要通过Delta Store从行存表中获取未迁移到Main Store的数据,
然后利用bulk load,把未迁移到Main Store的行存数据(满足100w行的条件)直接迁移到Main Store,如果数据不足100w行,那么就把行存数据迁移到Delta Store中
因此,query数据时,要查询Delta Store和Main Store,把两者的结果Union才是最后的结果。

图4-5
SQL Server列存总结
在概括SQL Server列存设计的优缺点之前,首先要看下数仓场景下更新的特点,这会影响到整个存储设计。
数仓场景下更新的特点,更新中绝大部分的是Insert,只包含极少数的Update和Delete。
并且列存中in-place update的成本很高,所以Update的实现一般是一次Delete加上一次Insert 这种out-of-place update。因此支持更新实际上只需要考虑Insert的性能,Delete的性能并不是很重要。
现在大部分的列存引擎普遍都会选择Delta-Main架构,因为本身按列存储就不利于更新,因此需要使用Delta缓存架构来解决更新的问题。
SQL Server列存的优缺点
优点:
- 通过引入delta store、delete flag、rowid,让列存索引以append-only的方式更新,保证跨行存和列存索引上事务的ACID。
缺点:
- 插入数据到列存、Row Group重整、更新列存数据带来一定开销,这个开销就是都需要更新行存中的RowID,因此都会和行存的OLTP事务产生竞争,影响系统整体性能,这个是SQL Server行存和列存紧耦合导致的。
根据数仓场景的特点,SQL Server列存的开销其实可以接受,然后使用类Delta-Main架构也是比较主流的做法,但是到了HTAP的场景,整个数据库需要支撑高并发的查询和更新,列存的开销就会被放大。
在这方面,SQL Server也提供了很多优化方案,比如使用Mapping Index来减轻更新行存中的RowID的开销问题。
有同学会问SQL Server2014开始支持聚集列存索引,整个表只有一个列存索引作为primary index,就不会有更新行存RowID这个开销,但是数据库一般也需要唯一约束、外键约束等,要维护这些约束就需要行存B树索引来辅助。
所以,最后还是要行存和列存组合来使用。
HTAP发展
最后,从SQL Server的发展来看,一份表数据两种存储格式,两种存储引擎处理,查询时优化器自动选择存储引擎执行,对用户透明,这些特性让SQL Server走在了前列
当然,其他商业数据库和开源数据库也在向HTAP方向发展,例如Oracle、GreenPlum、SAP HANA等等
还有,两大开源国产数据库代表PingCAP、OceanBase,在成立之初就定位为新一代分布式的HTAP数据库,通过行存和列存松耦合来解决性能问题,新型的分布式架构确实比传统数据库更胜一筹。