日期
心得
昇思MindSpore 应用学习-DCGAN生成漫画头像(AI代码学习)
DCGAN生成漫画头像
在下面的教程中,我们将通过示例代码说明DCGAN网络如何设置网络、优化器、如何计算损失函数以及如何初始化模型权重。在本教程中,使用的动漫头像数据集共有70,171张动漫头像图片,图片大小均为96*96。
GAN基础原理
这部分原理介绍参考GAN图像生成。
DCGAN原理
DCGAN(深度卷积对抗生成网络,Deep Convolutional Generative Adversarial Networks)是GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和转置卷积层。
它最早由Radford等人在论文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。生成器则是由转置卷积层、BatchNorm层和ReLU激活层组成。输入是标准正态分布中提取出的隐向量z𝑧,输出是3x64x64的RGB图像。
本教程将使用动漫头像数据集来训练一个生成式对抗网络,接着使用该网络生成动漫头像图片。
数据准备与处理
首先我们将数据集下载到指定目录下并解压。示例代码如下:
python
from download import download # 导入download模块中的download方法
url = "https://download.mindspore.cn/dataset/Faces/faces.zip" # 指定要下载的文件的URL
path = download(url, "./faces", kind="zip", replace=True) # 下载指定URL的文件,解压到"./faces"目录,若存在则替换解析:
from download import download:导入download模块中的download函数,用于网络文件下载。- API :
download是一个用于下载文件的函数,通常支持多种下载选项。
- API :
url = "https://download.mindspore.cn/dataset/Faces/faces.zip":定义要下载的文件的URL地址。- 这是一个指向ZIP格式数据集的链接。
path = download(url, "./faces", kind="zip", replace=True):调用download函数,下载指定的ZIP文件,并将其解压到指定的路径"./faces"。url:要下载的文件的网络地址。"./faces":文件下载后要保存的本地目录。kind="zip":指定下载文件的类型为ZIP格式。replace=True:如果目标路径已经存在同名文件,则替换它。
下载后的数据集目录结构如下:
./faces/faces
├── 0.jpg
├── 1.jpg
├── 2.jpg
├── 3.jpg
├── 4.jpg
...
├── 70169.jpg
└── 70170.jpg数据处理
首先为执行过程定义一些输入:
batch_size = 128 # 批量大小
image_size = 64 # 训练图像空间大小
nc = 3 # 图像彩色通道数
nz = 100 # 隐向量的长度
ngf = 64 # 特征图在生成器中的大小
ndf = 64 # 特征图在判别器中的大小
num_epochs = 10 # 训练周期数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的beta1超参数定义create_dataset_imagenet函数对数据进行处理和增强操作。
python
import numpy as np # 导入NumPy库,通常用于数组和矩阵操作
import mindspore.dataset as ds # 导入MindSpore的数据集模块
import mindspore.dataset.vision as vision # 导入MindSpore的视觉数据处理模块
def create_dataset_imagenet(dataset_path):
"""数据加载"""
dataset = ds.ImageFolderDataset(dataset_path, # 创建一个ImageFolderDataset实例,指定数据集路径
num_parallel_workers=4, # 设置并行工作线程数为4
shuffle=True, # 数据打乱
decode=True) # 解码图像数据
# 数据增强操作
transforms = [
vision.Resize(image_size), # 调整图像大小
vision.CenterCrop(image_size), # 中心裁剪图像
vision.HWC2CHW(), # 将图像格式从HWC转为CHW
lambda x: ((x / 255).astype("float32")) # 将图像数据归一化到[0, 1]范围并转换为float32类型
]
# 数据映射操作
dataset = dataset.project('image') # 仅选择图像数据
dataset = dataset.map(transforms, 'image') # 对图像数据应用转换操作
# 批量操作
dataset = dataset.batch(batch_size) # 将数据集分批处理
return dataset # 返回处理后的数据集
dataset = create_dataset_imagenet('./faces') # 调用函数创建数据集,路径为'./faces'解析:
import numpy as np:导入NumPy库,通常用于处理数组和矩阵运算,尽管在此段代码中未直接使用。import mindspore.dataset as ds和import mindspore.dataset.vision as vision:导入MindSpore的dataset模块和视觉处理模块,用于处理和增强数据集。def create_dataset_imagenet(dataset_path)::定义一个函数用于创建ImageNet数据集,并传入数据集的路径。dataset = ds.ImageFolderDataset(dataset_path, ...):- API :
ImageFolderDataset用于从指定路径加载图像数据集,支持数据的并行处理和打乱。 num_parallel_workers=4:设置4个并行工作者以提高数据加载速度。shuffle=True:每次迭代前打乱数据,增强模型的鲁棒性。decode=True:对图像进行解码处理,以便后续处理。
- API :
transforms:定义数据增强的操作列表,具体包括:vision.Resize(image_size):调整图像到指定的尺寸。vision.CenterCrop(image_size):对图像进行中心裁剪。vision.HWC2CHW():将图像维度从HWC(高度、宽度、通道)转换为CHW(通道、高度、宽度)。lambda x: ((x / 255).astype("float32")):将像素值归一化到0, 1之间,并转换为浮点型。
dataset = dataset.project('image'):从数据集中选择图像数据进行后续处理。dataset = dataset.map(transforms, 'image'):对选择的图像数据应用前面定义的变换操作。dataset = dataset.batch(batch_size):将数据集分成批次,以便于模型训练时一次处理多个样本。return dataset:返回处理后的数据集供后续使用。dataset = create_dataset_imagenet('./faces'):调用定义的函数,传入数据集路径,得到经过处理的图像数据集。
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
python
import matplotlib.pyplot as plt # 导入matplotlib.pyplot库,用于绘制图形和可视化
def plot_data(data):
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140) # 创建一个图形,设置其大小和分辨率
for i, image in enumerate(data[0][:30], 1): # 遍历数据中的前30张图像
plt.subplot(3, 10, i) # 创建一个3行10列的子图,指定当前图像位置
plt.axis("off") # 关闭坐标轴显示
plt.imshow(image.transpose(1, 2, 0)) # 显示图像,将图像从CHW格式转换为HWC格式
plt.show() # 展示绘制的图形
sample_data = next(dataset.create_tuple_iterator(output_numpy=True)) # 从数据集中获取一个样本数据,输出为NumPy格式
plot_data(sample_data) # 调用plot_data函数可视化获取的样本数据解析:
import matplotlib.pyplot as plt:导入matplotlib库中的pyplot模块,用于绘图和数据可视化。def plot_data(data)::定义一个函数用于可视化传入的数据。plt.figure(figsize=(10, 3), dpi=140):创建一个新的图形窗口,设置图形的大小为10x3英寸,分辨率为140 DPI(每英寸点数)。- API :
figure()用于初始化一个新图形。
- API :
for i, image in enumerate(data[0][:30], 1)::enumerate(data[0][:30], 1):遍历传入数据的前30张图像,data[0]通常是一个包含图像的数组,1表示索引从1开始。i是当前图像的索引,image是当前图像数据。
plt.subplot(3, 10, i):在当前图形中创建一个3行10列的子图,定位到第i个子图中。- API :
subplot()用于在图形中添加子图。
- API :
plt.axis("off"):关闭当前子图的坐标轴显示,以便只显示图像。- API :
axis()用于控制坐标轴的显示。
- API :
plt.imshow(image.transpose(1, 2, 0)):将图像从CHW格式(通道、高度、宽度)转换为HWC格式(高度、宽度、通道),并显示图像。- API :
imshow()用于显示图像。
- API :
plt.show():展示所有绘制的图形。- API :
show()用于显示当前图形。
- API :
sample_data = next(dataset.create_tuple_iterator(output_numpy=True)):- API :
create_tuple_iterator()用于生成一个迭代器,以便逐批访问数据集中的样本,output_numpy=True表示将数据输出为NumPy数组。 next(...)获取迭代器的下一个样本数据。
- API :
plot_data(sample_data):调用之前定义的函数,传入获取到的样本数据进行可视化。

构造网络
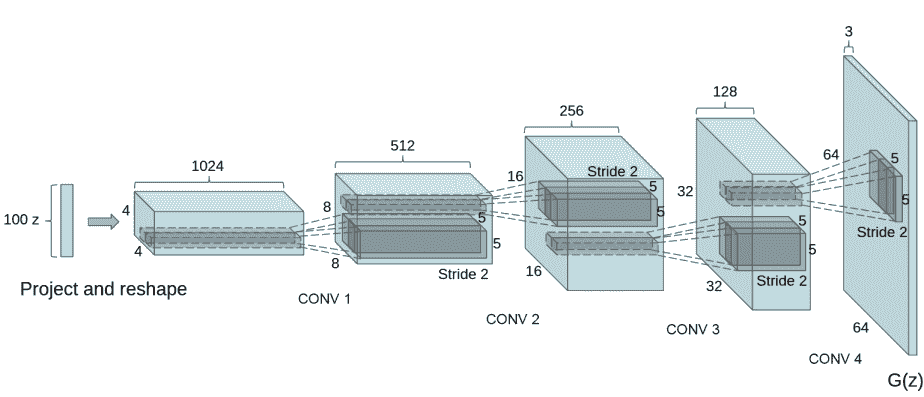
当处理完数据后,就可以来进行网络的搭建了。按照DCGAN论文中的描述,所有模型权重均应从mean为0,sigma为0.02的正态分布中随机初始化。
生成器
生成器G的功能是将隐向量z映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的 RGB 图像。在实践场景中,该功能是通过一系列Conv2dTranspose转置卷积层来完成的,每个层都与BatchNorm2d层和ReLu激活层配对,输出数据会经过tanh函数,使其返回[-1,1]的数据范围内。
DCGAN论文生成图像如下所示:
图片来源:Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks.
我们通过输入部分中设置的nz、ngf和nc来影响代码中的生成器结构。nz是隐向量z的长度,ngf与通过生成器传播的特征图的大小有关,nc是输出图像中的通道数。
以下是生成器的代码实现:
python
import mindspore as ms # 导入MindSpore库
from mindspore import nn, ops # 从MindSpore中导入神经网络模块nn和操作模块ops
from mindspore.common.initializer import Normal # 从MindSpore中导入正态分布初始化器
# 定义权重和伽马的初始化方式
weight_init = Normal(mean=0, sigma=0.02) # 权重初始化为均值为0,标准差为0.02的正态分布
gamma_init = Normal(mean=1, sigma=0.02) # 伽马初始化为均值为1,标准差为0.02的正态分布
class Generator(nn.Cell):
"""DCGAN网络生成器"""
def __init__(self):
super(Generator, self).__init__() # 调用父类构造函数
self.generator = nn.SequentialCell( # 定义生成器为一个顺序的神经网络
nn.Conv2dTranspose(nz, ngf * 8, 4, 1, 'valid', weight_init=weight_init), # 转置卷积层,输出通道为ngf*8
nn.BatchNorm2d(ngf * 8, gamma_init=gamma_init), # 批归一化层
nn.ReLU(), # ReLU激活函数
nn.Conv2dTranspose(ngf * 8, ngf * 4, 4, 2, 'pad', 1, weight_init=weight_init), # 转置卷积层,输出通道为ngf*4
nn.BatchNorm2d(ngf * 4, gamma_init=gamma_init), # 批归一化层
nn.ReLU(), # ReLU激活函数
nn.Conv2dTranspose(ngf * 4, ngf * 2, 4, 2, 'pad', 1, weight_init=weight_init), # 转置卷积层,输出通道为ngf*2
nn.BatchNorm2d(ngf * 2, gamma_init=gamma_init), # 批归一化层
nn.ReLU(), # ReLU激活函数
nn.Conv2dTranspose(ngf * 2, ngf, 4, 2, 'pad', 1, weight_init=weight_init), # 转置卷积层,输出通道为ngf
nn.BatchNorm2d(ngf, gamma_init=gamma_init), # 批归一化层
nn.ReLU(), # ReLU激活函数
nn.Conv2dTranspose(ngf, nc, 4, 2, 'pad', 1, weight_init=weight_init), # 转置卷积层,输出通道为nc
nn.Tanh() # 使用Tanh激活函数以获得输出范围[-1, 1]
)
def construct(self, x): # 定义前向传播过程
return self.generator(x) # 返回生成器的输出
generator = Generator() # 实例化生成器解析:
import mindspore as ms:导入MindSpore库,用于构建和训练深度学习模型。from mindspore import nn, ops:从MindSpore中导入nn(神经网络模块)和ops(操作模块)。from mindspore.common.initializer import Normal:导入正态分布初始化器,用于初始化神经网络参数。weight_init = Normal(mean=0, sigma=0.02):定义权重的初始化方式,使用均值为0,标准差为0.02的正态分布。gamma_init = Normal(mean=1, sigma=0.02):定义伽马的初始化方式,与权重初始化类似。class Generator(nn.Cell)::定义一个生成器类,继承自nn.Cell,用于构建DCGAN的生成器网络。def __init__(self)::构造函数,初始化生成器的网络结构。super(Generator, self).__init__():调用父类的构造函数。self.generator = nn.SequentialCell(...):使用SequentialCell构建网络,包含多个层次。nn.Conv2dTranspose(...):转置卷积层,逐层增大特征图的尺寸。
- 参数解释:
- 输入通道数和输出通道数。
- 卷积核的大小(例如4)。
- 步幅(stride)。
- 填充方式(padding)。
nn.BatchNorm2d(...):批归一化层,优化训练过程,加速收敛。nn.ReLU():ReLU激活函数,非线性激活。nn.Tanh():最后一层使用Tanh激活函数,使输出在-1, 1范围内。def construct(self, x)::定义前向传播方法。return self.generator(x):将输入x传入生成器,返回生成结果。generator = Generator():实例化生成器对象。
判别器
如前所述,判别器D是一个二分类网络模型,输出判定该图像为真实图的概率。通过一系列的Conv2d、BatchNorm2d和LeakyReLU层对其进行处理,最后通过Sigmoid激活函数得到最终概率。
DCGAN论文提到,使用卷积而不是通过池化来进行下采样是一个好方法,因为它可以让网络学习自己的池化特征。
判别器的代码实现如下:
python
class Discriminator(nn.Cell):
"""DCGAN网络判别器"""
def __init__(self):
super(Discriminator, self).__init__() # 调用父类构造函数
self.discriminator = nn.SequentialCell( # 定义判别器为一个顺序的神经网络
nn.Conv2d(nc, ndf, 4, 2, 'pad', 1, weight_init=weight_init), # 卷积层,输入通道为nc,输出通道为ndf
nn.LeakyReLU(0.2), # Leaky ReLU激活函数,负半轴有小的斜率
nn.Conv2d(ndf, ndf * 2, 4, 2, 'pad', 1, weight_init=weight_init), # 卷积层,输出通道为ndf*2
nn.BatchNorm2d(ndf * 2, gamma_init=gamma_init), # 批归一化层
nn.LeakyReLU(0.2), # Leaky ReLU激活函数
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 'pad', 1, weight_init=weight_init), # 卷积层,输出通道为ndf*4
nn.BatchNorm2d(ndf * 4, gamma_init=gamma_init), # 批归一化层
nn.LeakyReLU(0.2), # Leaky ReLU激活函数
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 'pad', 1, weight_init=weight_init), # 卷积层,输出通道为ndf*8
nn.BatchNorm2d(ndf * 8, gamma_init=gamma_init), # 批归一化层
nn.LeakyReLU(0.2), # Leaky ReLU激活函数
nn.Conv2d(ndf * 8, 1, 4, 1, 'valid', weight_init=weight_init), # 最后一个卷积层,输出通道为1
)
self.adv_layer = nn.Sigmoid() # 使用Sigmoid激活函数将输出限制在[0, 1]区间
def construct(self, x):
out = self.discriminator(x) # 通过判别器进行前向传播
out = out.reshape(out.shape[0], -1) # 将输出展平为二维数组
return self.adv_layer(out) # 返回经过Sigmoid激活后的结果
discriminator = Discriminator() # 实例化判别器解析:
class Discriminator(nn.Cell)::定义一个判别器类,继承自nn.Cell,用于构建DCGAN的判别器网络。def __init__(self)::构造函数,初始化判别器的网络结构。super(Discriminator, self).__init__():调用父类的构造函数。self.discriminator = nn.SequentialCell(...):使用SequentialCell构建判别器,由多个层次组成。nn.Conv2d(...):普通卷积层。- 参数解释:
- 输入通道数(如
nc)和输出通道数(如ndf)。 - 卷积核的大小(如4)。
- 步幅(如2)。
- 填充方式(如
'pad')。 - 填充数量(如1)。
- 输入通道数(如
- 参数解释:
nn.LeakyReLU(0.2):Leaky ReLU激活函数,避免神经元完全失活,负侧有0.2的斜率。nn.BatchNorm2d(...):批归一化层,优化训练过程,加速收敛。self.adv_layer = nn.Sigmoid():定义一个Sigmoid层,将最终的输出压缩到0, 1区间。def construct(self, x)::定义前向传播方法。out = self.discriminator(x):通过判别器进行前向传播,得到输出。out = out.reshape(out.shape[0], -1):将输出展平为二维数组,第一维为批量大小,第二维为特征数量。return self.adv_layer(out):将展平后的输出通过Sigmoid激活,返回最终结果。discriminator = Discriminator():实例化判别器对象。
模型训练
损失函数
当定义了D和G后,接下来将使用MindSpore中定义的二进制交叉熵损失函数BCELoss。
python
# 定义损失函数
adversarial_loss = nn.BCELoss(reduction='mean') # 使用二元交叉熵损失函数,计算生成器和判别器的对抗损失解析:
adversarial_loss = nn.BCELoss(reduction='mean'):定义对抗损失函数,使用二元交叉熵损失(Binary Cross Entropy Loss,BCELoss)来衡量生成器和判别器的性能。- BCELoss:适用于二分类问题,计算预测值和真实值之间的差异。
- reduction='mean':表示对损失值进行平均处理,即将所有样本的损失求平均值。这种方式能够避免因为不同批次的样本数量不同而导致的损失不一致。
在DCGAN中,生成器试图生成能够以假乱真的图像,而判别器则试图区分真实图像和生成图像。使用BCELoss作为损失函数,可以有效地衡量生成图像的真实度,从而指导生成器和判别器进行优化。
优化器
这里设置了两个单独的优化器,一个用于D,另一个用于G。这两个都是lr = 0.0002和beta1 = 0.5的Adam优化器。
python
# 为生成器和判别器设置优化器
optimizer_D = nn.Adam(discriminator.trainable_params(), learning_rate=lr, beta1=beta1) # 设置判别器的Adam优化器
optimizer_G = nn.Adam(generator.trainable_params(), learning_rate=lr, beta1=beta1) # 设置生成器的Adam优化器
optimizer_G.update_parameters_name('optim_g.') # 更新生成器优化器的参数名称前缀
optimizer_D.update_parameters_name('optim_d.') # 更新判别器优化器的参数名称前缀解析:
optimizer_D = nn.Adam(discriminator.trainable_params(), learning_rate=lr, beta1=beta1):为判别器创建Adam优化器。discriminator.trainable_params():获取判别器模型中可训练的参数。learning_rate=lr:设置学习率,lr为预先定义的学习率值。beta1=beta1:设置Adam优化器的β1参数,用于控制一阶矩估计的衰减。
optimizer_G = nn.Adam(generator.trainable_params(), learning_rate=lr, beta1=beta1):为生成器创建Adam优化器。generator.trainable_params():获取生成器模型中可训练的参数。
optimizer_G.update_parameters_name('optim_g.'):更新生成器优化器的参数名称前缀为optim_g.,有助于在训练过程中清晰区分不同模型的参数。optimizer_D.update_parameters_name('optim_d.'):更新判别器优化器的参数名称前缀为optim_d.,同样是为了在训练中便于管理和识别不同模型的参数。
使用Adam优化器是因为其自适应学习率能够在训练过程中提供更好的收敛性,适合用于生成对抗网络(GAN)的训练。
训练模型
训练分为两个主要部分:训练判别器和训练生成器。
- 训练判别器
训练判别器的目的是最大程度地提高判别图像真伪的概率。按照Goodfellow的方法,是希望通过提高其随机梯度来更新判别器,所以我们要最大化logD(x)+log(1−D(G(z))的值。
- 训练生成器
如DCGAN论文所述,我们希望通过最小化log(1−D(G(z)))来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计,将fixed_noise批量推送到生成器中,以直观地跟踪G的训练进度。
下面实现模型训练正向逻辑:
python
def generator_forward(real_imgs, valid):
# 将噪声采样为发生器的输入
z = ops.standard_normal((real_imgs.shape[0], nz, 1, 1)) # 生成随机噪声,形状为(batch_size, nz, 1, 1)
# 生成一批图像
gen_imgs = generator(z) # 使用生成器生成图像
# 损失衡量发生器绕过判别器的能力
g_loss = adversarial_loss(discriminator(gen_imgs), valid) # 计算生成器的损失
return g_loss, gen_imgs # 返回生成器损失和生成的图像
def discriminator_forward(real_imgs, gen_imgs, valid, fake):
# 衡量鉴别器从生成的样本中对真实样本进行分类的能力
real_loss = adversarial_loss(discriminator(real_imgs), valid) # 计算真实图像的损失
fake_loss = adversarial_loss(discriminator(gen_imgs), fake) # 计算生成图像的损失
d_loss = (real_loss + fake_loss) / 2 # 计算判别器的平均损失
return d_loss # 返回判别器损失
grad_generator_fn = ms.value_and_grad(generator_forward, None,
optimizer_G.parameters, # 计算生成器的梯度
has_aux=True) # 指定返回辅助信息
grad_discriminator_fn = ms.value_and_grad(discriminator_forward, None,
optimizer_D.parameters) # 计算判别器的梯度
@ms.jit
def train_step(imgs):
valid = ops.ones((imgs.shape[0], 1), mindspore.float32) # 创建一个全为1的张量,作为真实样本的标签
fake = ops.zeros((imgs.shape[0], 1), mindspore.float32) # 创建一个全为0的张量,作为生成样本的标签
(g_loss, gen_imgs), g_grads = grad_generator_fn(imgs, valid) # 计算生成器损失和梯度
optimizer_G(g_grads) # 更新生成器参数
d_loss, d_grads = grad_discriminator_fn(imgs, gen_imgs, valid, fake) # 计算判别器损失和梯度
optimizer_D(d_grads) # 更新判别器参数
return g_loss, d_loss, gen_imgs # 返回生成器损失、判别器损失和生成的图像解析:
def generator_forward(real_imgs, valid)::定义生成器的前向传播函数。z = ops.standard_normal((real_imgs.shape[0], nz, 1, 1)):生成一个服从标准正态分布的随机噪声,作为生成器的输入。gen_imgs = generator(z):将随机噪声输入生成器,生成图像。g_loss = adversarial_loss(discriminator(gen_imgs), valid):通过判别器计算生成器生成的图像的损失。return g_loss, gen_imgs:返回生成器损失和生成的图像。
def discriminator_forward(real_imgs, gen_imgs, valid, fake)::定义判别器的前向传播函数。real_loss = adversarial_loss(discriminator(real_imgs), valid):计算真实图像的损失。fake_loss = adversarial_loss(discriminator(gen_imgs), fake):计算生成图像的损失。d_loss = (real_loss + fake_loss) / 2:求取真实与生成图像损失的平均值,得到判别器的损失。return d_loss:返回判别器损失。
grad_generator_fn = ms.value_and_grad(...):使用value_and_grad函数为生成器前向传播定义一个函数,计算生成器的损失和梯度,has_aux=True表示还需返回辅助信息。grad_discriminator_fn = ms.value_and_grad(...):同样为判别器前向传播定义一个函数,计算判别器的损失和梯度。@ms.jit:使用JIT编译器加速train_step函数的执行。def train_step(imgs)::定义训练步长函数。valid = ops.ones((imgs.shape[0], 1), mindspore.float32):创建一个全为1的张量,表示真实样本的标签。fake = ops.zeros((imgs.shape[0], 1), mindspore.float32):创建一个全为0的张量,表示生成样本的标签。(g_loss, gen_imgs), g_grads = grad_generator_fn(imgs, valid):计算生成器损失和梯度。optimizer_G(g_grads):更新生成器参数。d_loss, d_grads = grad_discriminator_fn(imgs, gen_imgs, valid, fake):计算判别器损失和梯度。optimizer_D(d_grads):更新判别器参数。return g_loss, d_loss, gen_imgs:返回生成器损失、判别器损失和生成的图像。
这个训练过程通过不断优化生成器和判别器,使得生成器生成的图像越来越真实,同时使得判别器的分类性能得到提升。
循环训练网络,每经过50次迭代,就收集生成器和判别器的损失,以便于后面绘制训练过程中损失函数的图像。
python
import mindspore
G_losses = [] # 用于存储生成器损失
D_losses = [] # 用于存储判别器损失
image_list = [] # 用于存储生成的图像
total = dataset.get_dataset_size() # 获取训练数据集的总大小
for epoch in range(num_epochs): # 开始训练的循环
generator.set_train() # 设置生成器为训练模式
discriminator.set_train() # 设置判别器为训练模式
# 为每轮训练读入数据
for i, (imgs, ) in enumerate(dataset.create_tuple_iterator()): # 遍历数据集
g_loss, d_loss, gen_imgs = train_step(imgs) # 执行一次训练步骤
if i % 100 == 0 or i == total - 1: # 每100个批次或最后一个批次输出训练记录
print('[%2d/%d][%3d/%d] Loss_D:%7.4f Loss_G:%7.4f' % (
epoch + 1, num_epochs, i + 1, total, d_loss.asnumpy(), g_loss.asnumpy())) # 打印当前损失
D_losses.append(d_loss.asnumpy()) # 存储判别器损失
G_losses.append(g_loss.asnumpy()) # 存储生成器损失
# 每个epoch结束后,使用生成器生成一组图片
generator.set_train(False) # 将生成器设置为评估模式
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)) # 生成固定的随机噪声
img = generator(fixed_noise) # 使用生成器生成图像
image_list.append(img.transpose(0, 2, 3, 1).asnumpy()) # 将图像维度调整并存储为numpy数组
# 保存网络模型参数为ckpt文件
mindspore.save_checkpoint(generator, "./generator.ckpt") # 保存生成器参数
mindspore.save_checkpoint(discriminator, "./discriminator.ckpt") # 保存判别器参数解析:
G_losses = []和D_losses = []:初始化用于存储生成器和判别器损失的列表。image_list = []:初始化用于存储生成的图像的列表。total = dataset.get_dataset_size():获取训练数据集的大小,便于在训练过程中跟踪进度。for epoch in range(num_epochs)::遍历每个训练轮次(epoch)。generator.set_train()和discriminator.set_train():将生成器和判别器设置为训练模式,启用 dropout 和 batch normalization 等训练特性。for i, (imgs, ) in enumerate(dataset.create_tuple_iterator())::通过创建一个元组迭代器遍历数据集,获取每个批次的图像数据。g_loss, d_loss, gen_imgs = train_step(imgs):执行训练步骤,计算生成器和判别器的损失,并生成图像。if i % 100 == 0 or i == total - 1::每100个批次或最后一个批次时输出训练损失。- 使用
print语句格式化输出当前的轮次、批次和损失值。
- 使用
D_losses.append(d_loss.asnumpy())和G_losses.append(g_loss.asnumpy()):将当前损失值转换为numpy数组并添加到相应的列表中,以便后续分析和可视化。generator.set_train(False):在每个epoch结束后,将生成器设置为评估模式,以便生成图像时不使用 dropout 等训练特性。fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)):生成一个固定的随机噪声,用于生成图像,以便在不同的epoch中进行比较。img = generator(fixed_noise):使用生成器生成图像。image_list.append(img.transpose(0, 2, 3, 1).asnumpy()):调整生成的图像张量的维度,将其转换为numpy数组并存储。mindspore.save_checkpoint(generator, "./generator.ckpt")和mindspore.save_checkpoint(discriminator, "./discriminator.ckpt"):将生成器和判别器的模型参数保存为ckpt文件,以便后续恢复或分析。
这一段代码实现了一个生成对抗网络的训练过程,通过不断优化生成器和判别器,使生成器能够生成越来越真实的图像。训练过程中的损失被记录并可用于后续分析,同时每个epoch结束后保存模型参数以防止训练丢失。
结果展示
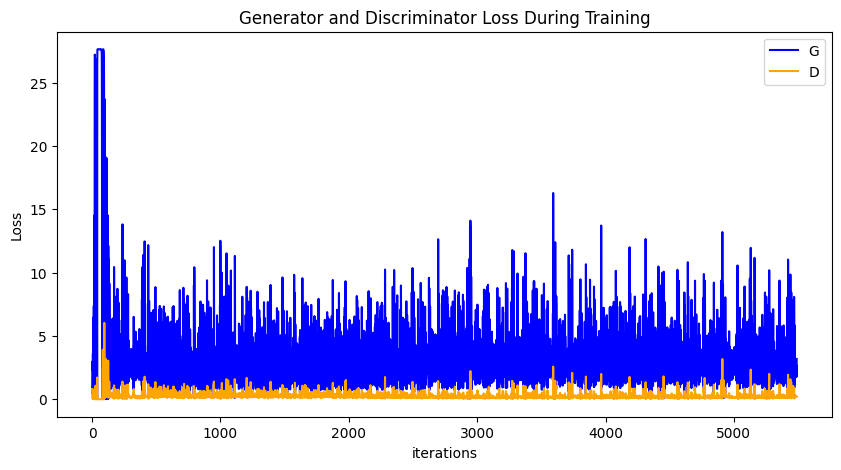
运行下面代码,描绘D和G损失与训练迭代的关系图:
python
plt.figure(figsize=(10, 5)) # 创建一个图形,设定大小为10x5英寸
plt.title("Generator and Discriminator Loss During Training") # 设置图形的标题
plt.plot(G_losses, label="G", color='blue') # 绘制生成器损失曲线,标签为"G",颜色为蓝色
plt.plot(D_losses, label="D", color='orange') # 绘制判别器损失曲线,标签为"D",颜色为橙色
plt.xlabel("iterations") # 设置x轴标签为"iterations"
plt.ylabel("Loss") # 设置y轴标签为"Loss"
plt.legend() # 显示图例
plt.show() # 显示图形解析:
plt.figure(figsize=(10, 5)):创建一个新的图形对象,并设置其大小为10x5英寸。plt.title("Generator and Discriminator Loss During Training"):为图形设置标题,描述图形的内容。plt.plot(G_losses, label="G", color='blue'):绘制生成器损失的曲线,使用蓝色作为曲线颜色,并设置标签为"G"。plt.plot(D_losses, label="D", color='orange'):绘制判别器损失的曲线,使用橙色作为曲线颜色,并设置标签为"D"。plt.xlabel("iterations"):设置x轴的标签,表示训练的迭代次数。plt.ylabel("Loss"):设置y轴的标签,表示损失值。plt.legend():显示图例,以便通过标签识别不同的曲线。plt.show():显示创建的图形。
这段代码用于可视化训练过程中生成器和判别器的损失变化。通过观察损失曲线,可以了解模型的训练状态以及生成器和判别器的表现。这对于调试和优化GAN(生成对抗网络)模型非常重要。
可视化训练过程中通过隐向量fixed_noise生成的图像。
python
import matplotlib.pyplot as plt # 导入matplotlib.pyplot用于绘图
import matplotlib.animation as animation # 导入matplotlib.animation用于动画创建
import numpy as np # 导入numpy用于数值计算(确保代码运行)
def showGif(image_list):
show_list = [] # 初始化一个列表,用于存储每个epoch的图像
fig = plt.figure(figsize=(8, 3), dpi=120) # 创建一个图形,设置大小和分辨率
for epoch in range(len(image_list)): # 遍历每个epoch
images = [] # 初始化当前epoch的图像列表
for i in range(3): # 假设每个epoch生成3行图像
# 将当前epoch的每一行图像拼接在一起
row = np.concatenate((image_list[epoch][i * 8:(i + 1) * 8]), axis=1) # 将每8张图像在水平方向上拼接
images.append(row) # 将拼接后的行图像添加到images中
# 将所有行图像在垂直方向上拼接,并限制像素值在0到1之间
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1)
plt.axis("off") # 关闭坐标轴
show_list.append([plt.imshow(img)]) # 将当前图像添加到动画列表中
# 创建动画,设置每个图像的显示间隔和循环延迟
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save('./dcgan.gif', writer='pillow', fps=1) # 保存动画为GIF文件
showGif(image_list) # 调用函数,生成并保存GIF解析:
import matplotlib.pyplot as plt和import matplotlib.animation as animation:导入绘图和动画所需的库。import numpy as np:导入NumPy库以进行数值处理。def showGif(image_list)::定义一个函数,用于显示生成的图像并保存为GIF。show_list = []:初始化一个空列表,用于存储每个epoch的图像信息。fig = plt.figure(figsize=(8, 3), dpi=120):创建一个图形对象,设置其大小为8x3英寸,分辨率为120 DPI。for epoch in range(len(image_list))::遍历图像列表中的每个epoch。images = []:初始化一个空列表,用于存储当前epoch的行图像。for i in range(3)::假设每个epoch生成3行图像。row = np.concatenate((image_list[epoch][i * 8:(i + 1) * 8]), axis=1):将当前epoch中的8张图像在水平方向拼接成一行图像。images.append(row):将拼接好的行图像添加到images列表中。
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1):将所有行图像在垂直方向拼接,并限制像素值在0到1之间,以确保图像的显示范围。plt.axis("off"):关闭坐标轴,以便只显示图像。show_list.append([plt.imshow(img)]):将当前图像的显示信息添加到动画列表中。ani = animation.ArtistAnimation(...):创建图像动画,设置每帧的显示间隔为1000毫秒(1秒),并设置重复延迟为1000毫秒。ani.save('./dcgan.gif', writer='pillow', fps=1):以1帧每秒的速度保存动画为GIF文件。showGif(image_list):调用函数,生成并保存GIF动画。
这段代码用于创建一个GIF动画,展示生成对抗网络(GAN)训练过程中生成器生成的图像变化。通过查看GIF,可以直观地观察到生成器在不同epoch中生成的图像质量如何变化。

从上面的图像可以看出,随着训练次数的增多,图像质量也越来越好。如果增大训练周期数,当num_epochs达到50以上时,生成的动漫头像图片与数据集中的较为相似,下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
python
# 从文件中获取模型参数并加载到网络中
mindspore.load_checkpoint("./generator.ckpt", generator) # 加载生成器的训练好的模型参数
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)) # 生成固定的随机噪声,用于生成图像
img64 = generator(fixed_noise).transpose(0, 2, 3, 1).asnumpy() # 使用生成器生成图像并调整维度为(H, W, C)
fig = plt.figure(figsize=(8, 3), dpi=120) # 创建一个图形,设置大小和分辨率
images = [] # 初始化一个列表,用于存储拼接后的图像
for i in range(3): # 假设我们希望展示3行图像
images.append(np.concatenate((img64[i * 8:(i + 1) * 8]), axis=1)) # 将生成的每8张图像在水平方向拼接成一行
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1) # 将所有行图像在垂直方向拼接,并限制像素值在0到1之间
plt.axis("off") # 关闭坐标轴
plt.imshow(img) # 显示拼接好的图像
plt.show() # 显示图形解析:
mindspore.load_checkpoint("./generator.ckpt", generator):从指定的文件中加载生成器的模型参数到生成器网络中。fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)):生成固定的标准正态分布随机噪声,用于生成图像。batch_size是每个批次的图像数量,nz是噪声的维度。img64 = generator(fixed_noise).transpose(0, 2, 3, 1).asnumpy():使用生成器生成图像,并将输出的维度从 (N, C, H, W) 转换为 (N, H, W, C) 格式,以便进行可视化。fig = plt.figure(figsize=(8, 3), dpi=120):创建一个新的图形窗口,设置其大小为8x3英寸,分辨率为120 DPI。images = []:初始化一个空列表,用于存储生成图像的拼接结果。for i in range(3)::循环3次,每次处理一行图像。images.append(np.concatenate((img64[i * 8:(i + 1) * 8]), axis=1)):将当前行的8张图像在水平方向上拼接,并添加到images列表中。
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1):将所有行图像在垂直方向拼接,并使用np.clip确保像素值限制在0到1之间,以便于显示。plt.axis("off"):关闭坐标轴,以便仅显示生成的图像。plt.imshow(img):将拼接后的图像显示在图形中。plt.show():最终显示图形。
这一段代码实现了加载训练好的生成器模型,并使用该模型生成固定噪声的图像,然后将生成的图像进行拼接,最后展示生成的图像。通过这种方式,用户可以直观地看到生成器生成的图像效果。

整体代码
python
#!/usr/bin/env python
# coding: utf-8
# # DCGAN生成漫画头像
# 导入下载库并定义数据集下载链接
from download import download
url = "https://download.mindspore.cn/dataset/Faces/faces.zip"
path = download(url, "./faces", kind="zip", replace=True) # 下载数据集
# 定义一些超参数
batch_size = 128 # 批量大小
image_size = 64 # 训练图像空间大小
nc = 3 # 图像彩色通道数
nz = 100 # 隐向量的长度
ngf = 64 # 特征图在生成器中的大小
ndf = 64 # 特征图在判别器中的大小
num_epochs = 10 # 训练周期数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的beta1超参数
import numpy as np
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
def create_dataset_imagenet(dataset_path):
"""数据加载"""
dataset = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=4,
shuffle=True,
decode=True)
# 数据增强操作
transforms = [
vision.Resize(image_size), # 调整图像大小
vision.CenterCrop(image_size), # 中心裁剪图像
vision.HWC2CHW(), # 调整图像通道顺序
lambda x: ((x / 255).astype("float32")) # 归一化到[0,1]范围
]
# 数据映射操作
dataset = dataset.project('image')
dataset = dataset.map(transforms, 'image')
# 批量操作
dataset = dataset.batch(batch_size)
return dataset
dataset = create_dataset_imagenet('./faces') # 创建数据集
import matplotlib.pyplot as plt
def plot_data(data):
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data[0][:30], 1):
plt.subplot(3, 10, i)
plt.axis("off")
plt.imshow(image.transpose(1, 2, 0)) # 转置以匹配matplotlib的格式
plt.show()
sample_data = next(dataset.create_tuple_iterator(output_numpy=True))
plot_data(sample_data) # 显示样本数据
# DCGAN网络生成器实现
import mindspore as ms
from mindspore import nn, ops
from mindspore.common.initializer import Normal
weight_init = Normal(mean=0, sigma=0.02) # 权重初始化
gamma_init = Normal(mean=1, sigma=0.02) # γ的初始化
class Generator(nn.Cell):
"""DCGAN网络生成器"""
def __init__(self):
super(Generator, self).__init__()
self.generator = nn.SequentialCell(
nn.Conv2dTranspose(nz, ngf * 8, 4, 1, 'valid', weight_init=weight_init),
nn.BatchNorm2d(ngf * 8, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 8, ngf * 4, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 4, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 4, ngf * 2, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 2, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 2, ngf, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf, nc, 4, 2, 'pad', 1, weight_init=weight_init),
nn.Tanh() # 输出范围[-1, 1]
)
def construct(self, x):
return self.generator(x)
generator = Generator() # 实例化生成器
# DCGAN网络判别器实现
class Discriminator(nn.Cell):
"""DCGAN网络判别器"""
def __init__(self):
super(Discriminator, self).__init__()
self.discriminator = nn.SequentialCell(
nn.Conv2d(nc, ndf, 4, 2, 'pad', 1, weight_init=weight_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf, ndf * 2, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 2, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 4, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 8, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 8, 1, 4, 1, 'valid', weight_init=weight_init)
)
self.adv_layer = nn.Sigmoid() # Sigmoid激活函数
def construct(self, x):
out = self.discriminator(x)
out = out.reshape(out.shape[0], -1) # 重塑输出形状
return self.adv_layer(out)
discriminator = Discriminator() # 实例化判别器
# 定义损失函数
adversarial_loss = nn.BCELoss(reduction='mean')
# 为生成器和判别器设置优化器
optimizer_D = nn.Adam(discriminator.trainable_params(), learning_rate=lr, beta1=beta1)
optimizer_G = nn.Adam(generator.trainable_params(), learning_rate=lr, beta1=beta1)
# 定义训练步骤
def generator_forward(real_imgs, valid):
z = ops.standard_normal((real_imgs.shape[0], nz, 1, 1)) # 生成随机噪声
gen_imgs = generator(z) # 生成图像
g_loss = adversarial_loss(discriminator(gen_imgs), valid) # 计算生成器损失
return g_loss, gen_imgs
def discriminator_forward(real_imgs, gen_imgs, valid, fake):
real_loss = adversarial_loss(discriminator(real_imgs), valid) # 真实图像损失
fake_loss = adversarial_loss(discriminator(gen_imgs), fake) # 生成图像损失
d_loss = (real_loss + fake_loss) / 2 # 判别器损失
return d_loss
grad_generator_fn = ms.value_and_grad(generator_forward, None, optimizer_G.parameters, has_aux=True)
grad_discriminator_fn = ms.value_and_grad(discriminator_forward, None, optimizer_D.parameters)
@ms.jit
def train_step(imgs):
valid = ops.ones((imgs.shape[0], 1), mindspore.float32) # 真实标签
fake = ops.zeros((imgs.shape[0], 1), mindspore.float32) # 生成标签
(g_loss, gen_imgs), g_grads = grad_generator_fn(imgs, valid) # 计算生成器损失
optimizer_G(g_grads) # 更新生成器
d_loss, d_grads = grad_discriminator_fn(imgs, gen_imgs, valid, fake) # 计算判别器损失
optimizer_D(d_grads) # 更新判别器
return g_loss, d_loss, gen_imgs
# 训练模型
G_losses = []
D_losses = []
image_list = []
total = dataset.get_dataset_size()
for epoch in range(num_epochs):
generator.set_train()
discriminator.set_train()
for i, (imgs, ) in enumerate(dataset.create_tuple_iterator()):
g_loss, d_loss, gen_imgs = train_step(imgs)
if i % 100 == 0 or i == total - 1:
print('[%2d/%d][%3d/%d] Loss_D:%7.4f Loss_G:%7.4f' % (
epoch + 1, num_epochs, i + 1, total, d_loss.asnumpy(), g_loss.asnumpy()))
D_losses.append(d_loss.asnumpy())
G_losses.append(g_loss.asnumpy())
generator.set_train(False)
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)) # 生成固定噪声
img = generator(fixed_noise) # 生成图像
image_list.append(img.transpose(0, 2, 3, 1).asnumpy()) # 保存生成图像
# 保存网络模型参数为ckpt文件
mindspore.save_checkpoint(generator, "./generator.ckpt")
mindspore.save_checkpoint(discriminator, "./discriminator.ckpt")
# 绘制损失图
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G", color='blue')
plt.plot(D_losses, label="D", color='orange')
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 可视化生成的图像
import matplotlib.animation as animation
def showGif(image_list):
show_list = []
fig = plt.figure(figsize=(8, 3), dpi=120)
for epoch in range(len(image_list)):
images = []
for i in range(3):
row = np.concatenate((image_list[epoch][i * 8:(i + 1) * 8]), axis=1) # 拼接图像
images.append(row)
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1) # 限制像素值
plt.axis("off")
show_list.append([plt.imshow(img)])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save('./dcgan.gif', writer='pillow', fps=1)
showGif(image_list)
# 加载生成器模型参数并生成图像
mindspore.load_checkpoint("./generator.ckpt", generator)
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1))
img64 = generator(fixed_noise).transpose(0, 2, 3, 1).asnumpy()
fig = plt.figure(figsize=(8, 3), dpi=120)
images = []
for i in range(3):
images.append(np.concatenate((img64[i * 8:(i + 1) * 8]), axis=1)) # 拼接生成的图像
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1)
plt.axis("off")
plt.imshow(img)
plt.show()解析:
- 数据下载与处理 :
download(url, "./faces", kind="zip", replace=True):下载动漫头像数据集并解压到指定路径。create_dataset_imagenet函数:用于加载和预处理数据,包括图像缩放、裁剪和归一化。
- 网络构建 :
Generator类:定义DCGAN生成器,包含一系列转置卷积层和激活函数,生成RGB图像。Discriminator类:定义DCGAN判别器,包含卷积层和激活函数,输出图像为真实图像的概率。
- 训练过程 :
- 使用二进制交叉熵损失函数(
BCELoss)来评估生成器和判别器的性能。 - 优化器使用Adam优化算法,分别为生成器和判别器设置。
- 使用二进制交叉熵损失函数(
- 生成与展示 :
train_step函数:实现了生成器和判别器的训练步骤。- 训练后,生成图像并保存模型参数。
- 最后,通过加载生成器参数生成新图像并可视化。
通过本教程,可以了解如何使用DCGAN生成动漫头像,并掌握基本的模型构建与训练过程。
python
# 加载生成器模型参数并生成图像
mindspore.load_checkpoint("./generator.ckpt", generator)
# 使用标准正态分布生成固定的随机噪声
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1))
# 通过生成器生成图像
img64 = generator(fixed_noise).transpose(0, 2, 3, 1).asnumpy()
# 创建一个图形用于显示生成的图像
fig = plt.figure(figsize=(8, 3), dpi=120)
images = []
# 将生成的图像按行进行拼接
for i in range(3):
images.append(np.concatenate((img64[i * 8:(i + 1) * 8]), axis=1)) # 每行拼接8张图像
# 合并所有行并限制像素值在0到1之间
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1)
# 关闭坐标轴并显示生成的图像
plt.axis("off")
plt.imshow(img)
plt.show()解析:
- 加载生成器模型 :
mindspore.load_checkpoint("./generator.ckpt", generator):加载之前训练好的生成器模型参数,这样我们可以使用训练好的模型生成图像。
- 生成固定噪声 :
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1)):生成一个固定的标准正态分布随机噪声,作为生成器的输入。这里的batch_size表示生成多少张图像,nz是隐向量的维度。
- 生成图像 :
img64 = generator(fixed_noise).transpose(0, 2, 3, 1).asnumpy():通过生成器生成图像,并将输出的维度从(N, C, H, W)转换为(N, H, W, C)格式,以便使用matplotlib进行可视化。
- 创建图形并拼接图像 :
fig = plt.figure(figsize=(8, 3), dpi=120):创建一个新的图形窗口,设置其大小和分辨率。- 使用
np.concatenate将生成的图像按行拼接,每行展示8张图像。
- 显示生成的图像 :
plt.axis("off"):关闭坐标轴,以便仅显示生成的图像。plt.imshow(img):将拼接后的图像显示在图形中。plt.show():最终显示图形。
通过这一段代码,我们可以使用训练好的DCGAN生成新的动漫头像,并直观地查看生成结果。随着训练次数的增加,生成的图像质量会逐渐提升。当训练周期达到50个以上时,生成的头像与真实的动漫头像会更加相似。