MQ消息中间件
1)总览:
消息中间件

这里我们主要学习的是kafka的基础概念
具体参考黑马头条:https://www.bilibili.com/video/BV1Qs4y1v7x4/?spm_id_from=333.337.search-card.all.click
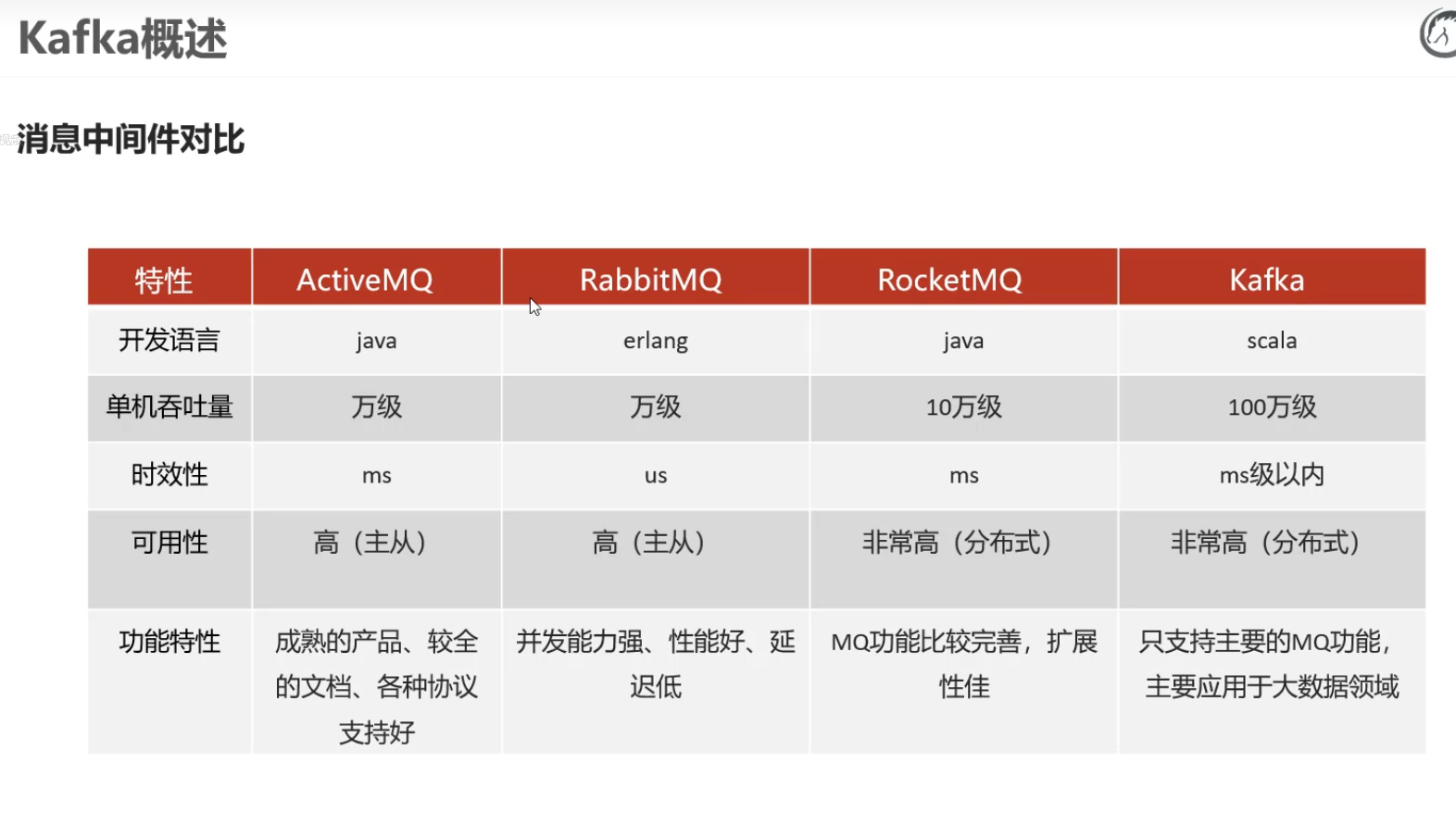
2)消息中间件对比

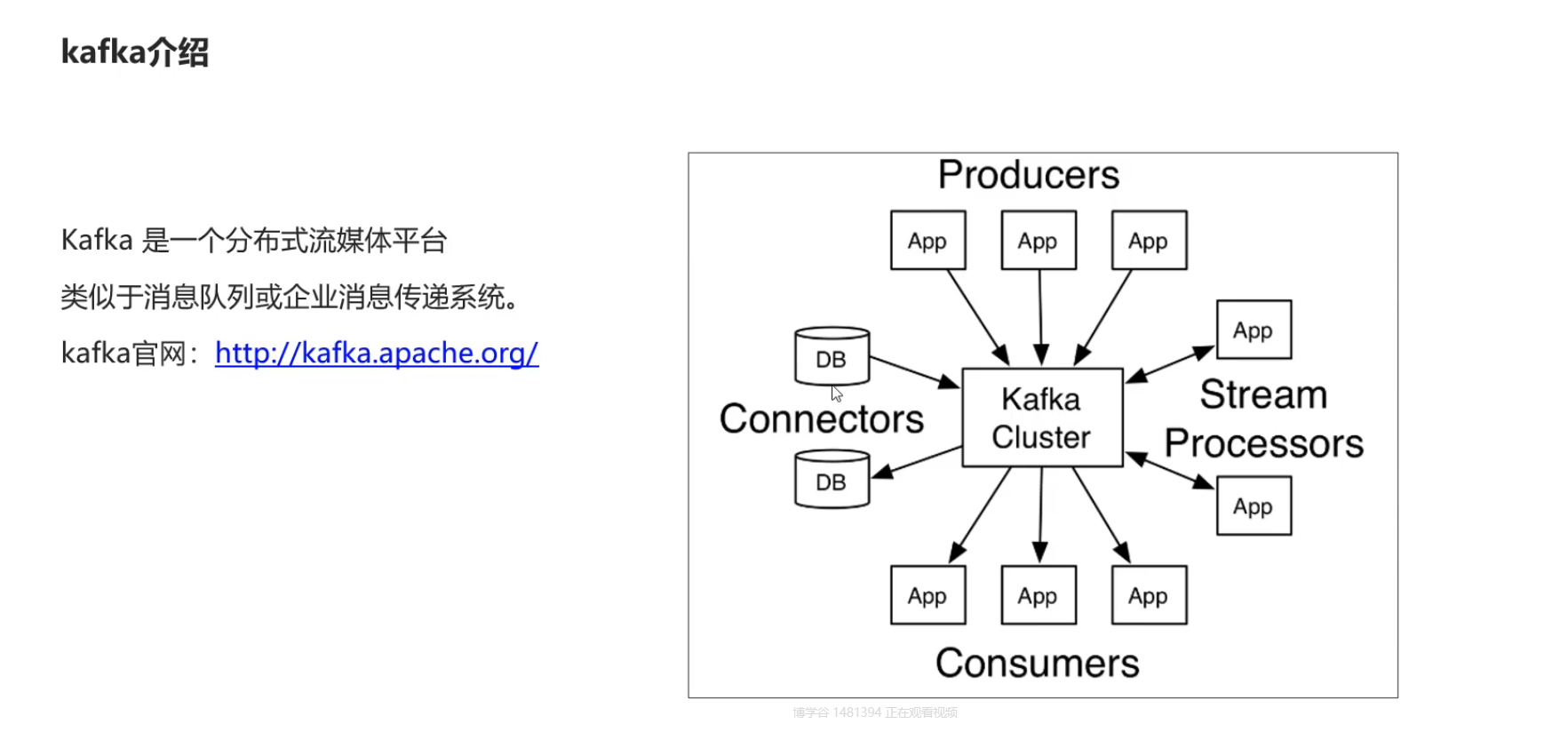
3)Kafka介绍
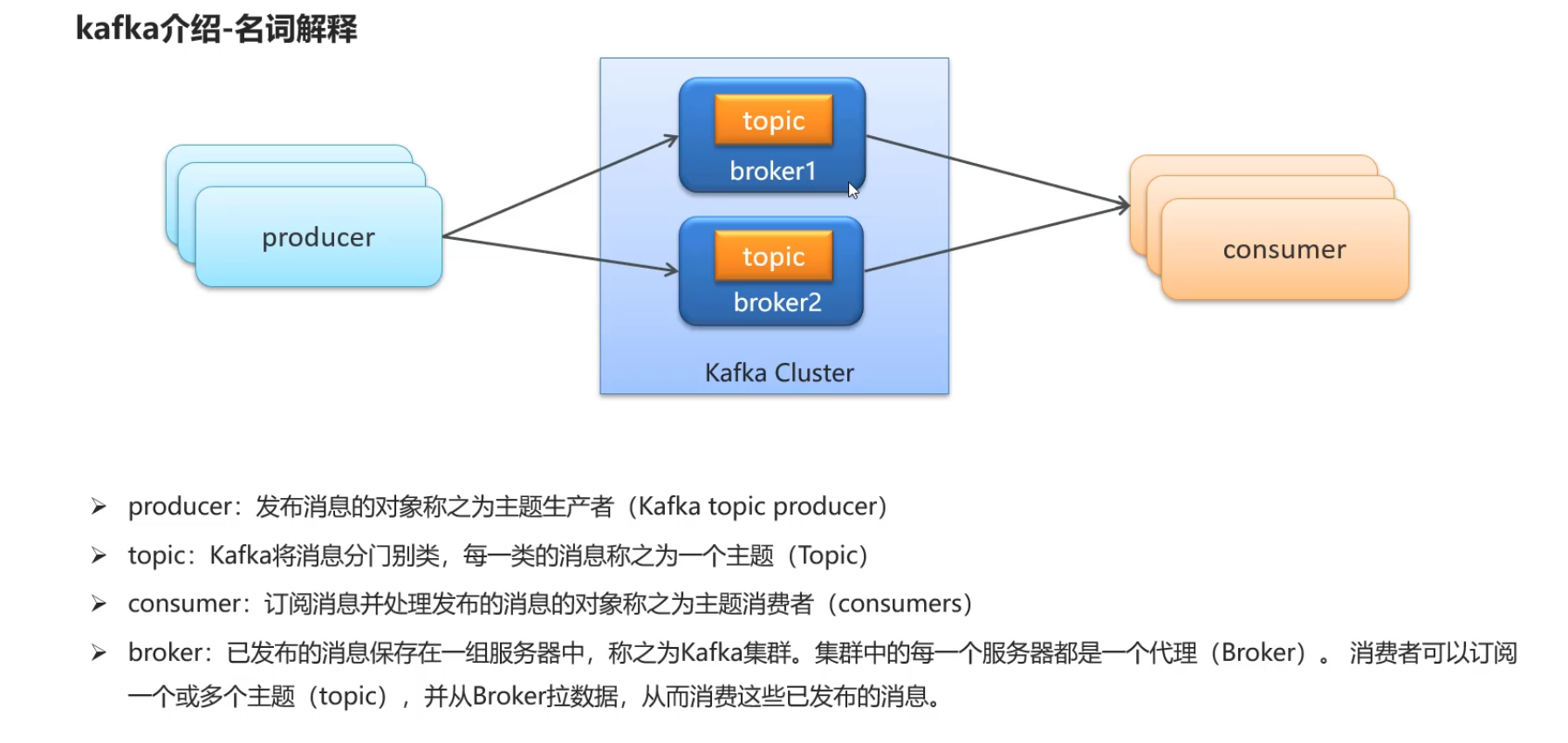
Kafka的安装和配置

安装Kafka之前必须先安装zookeeper
入门:
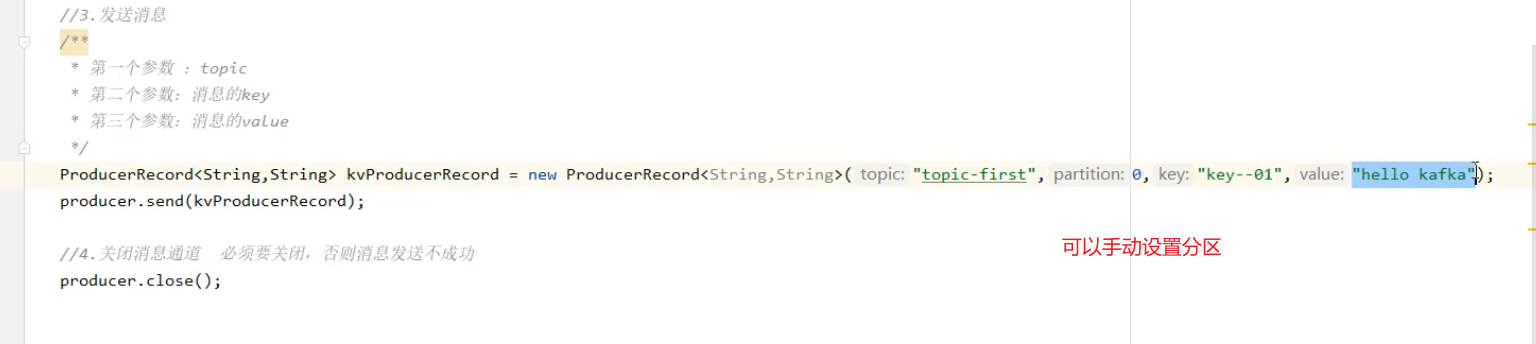
生产者发送消息
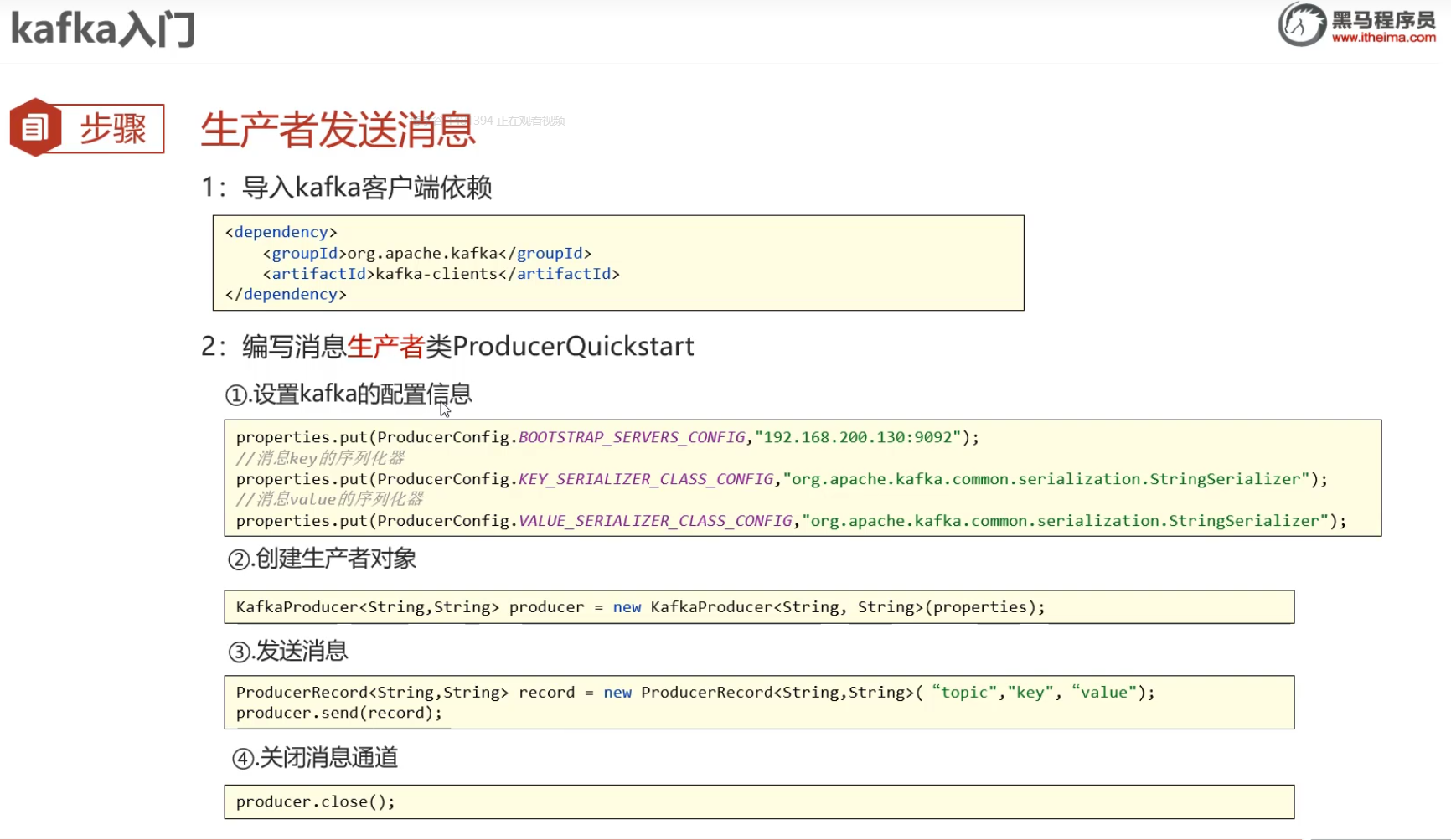
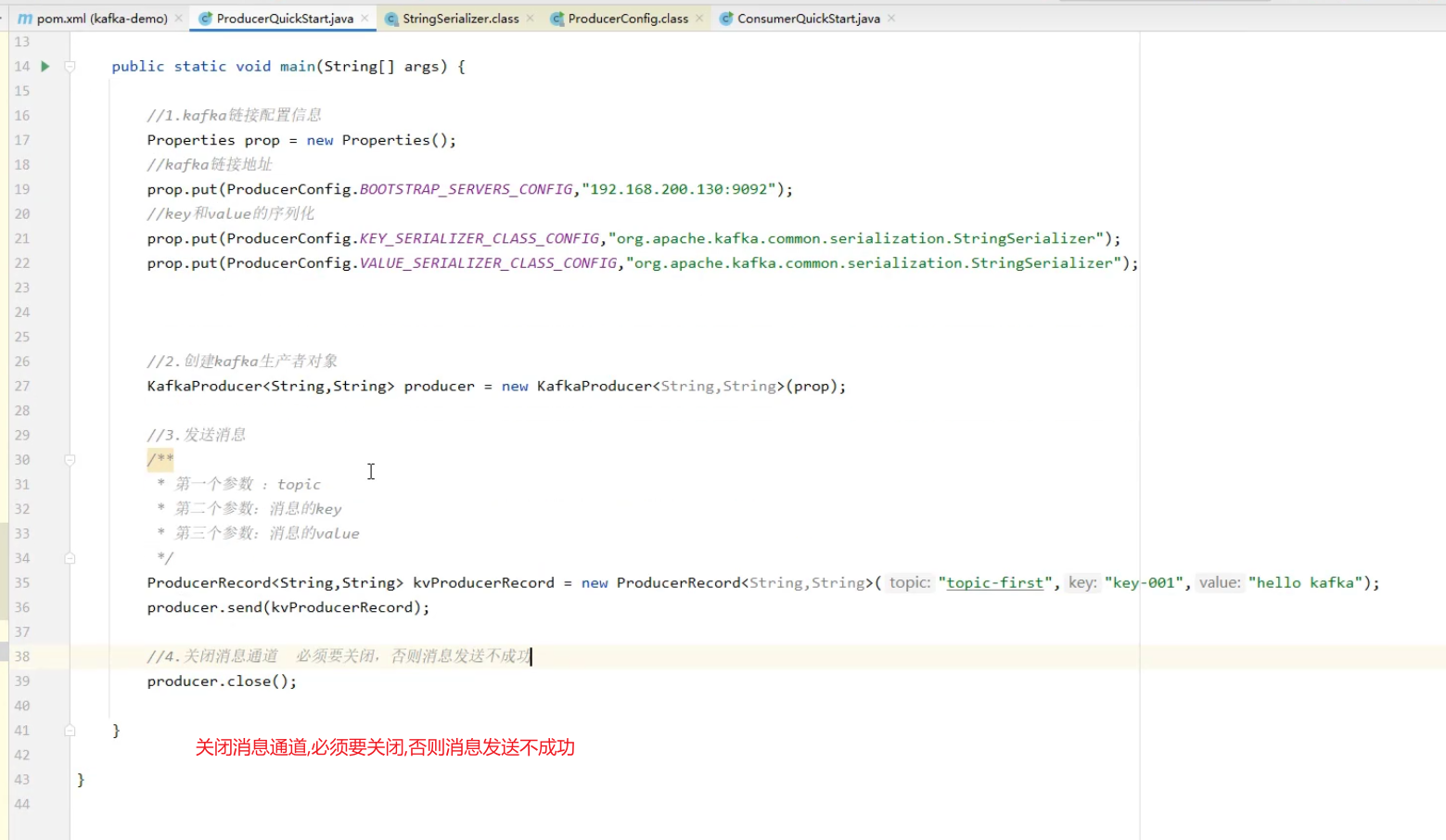
- 引入依赖,之后开始编写生成者类ProducerQuickstart
- 设置kafka的配置信息
- 创建生产者对象
- 发送消息
- 关闭消息通道
消费者接受消息
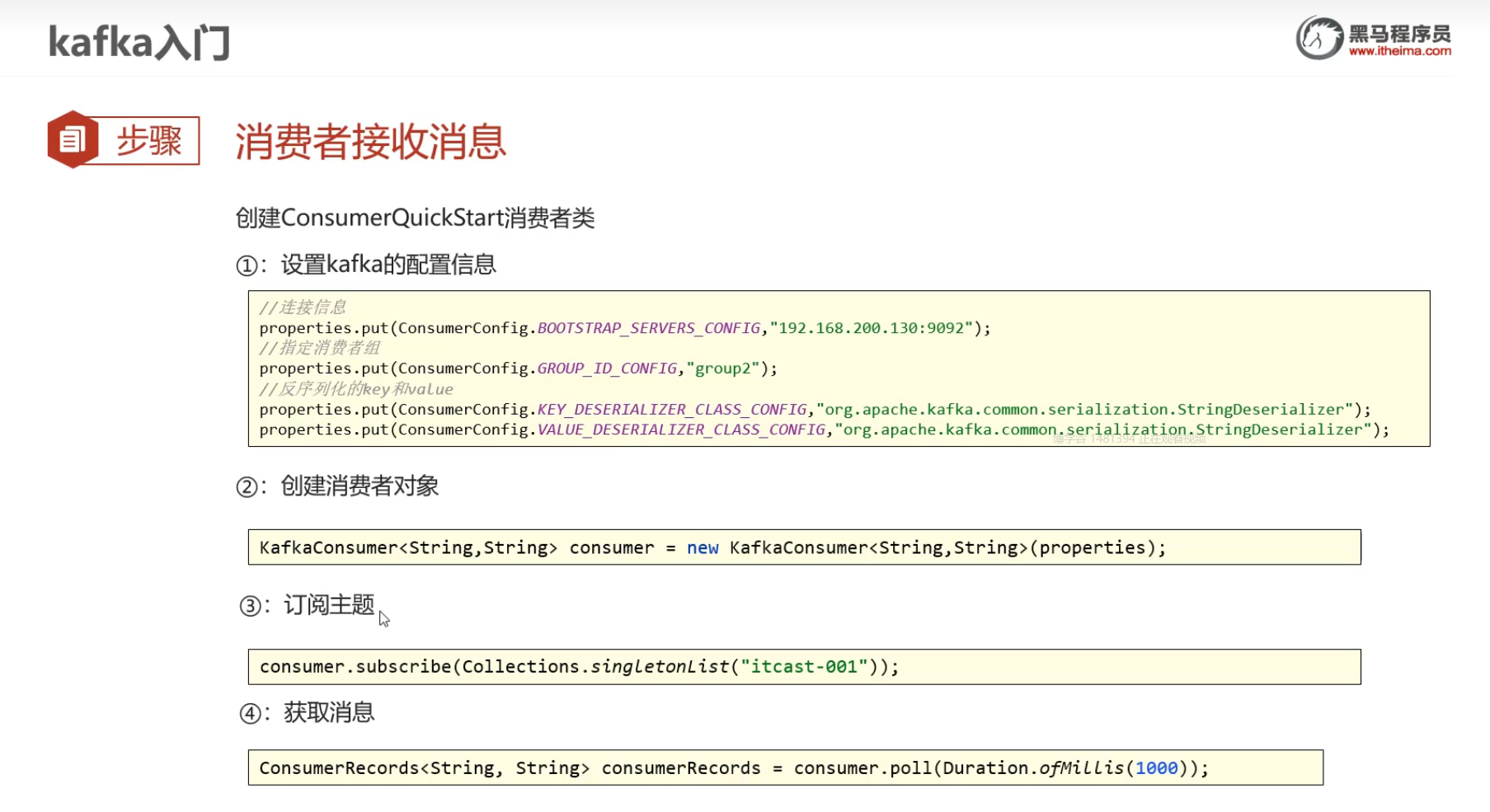
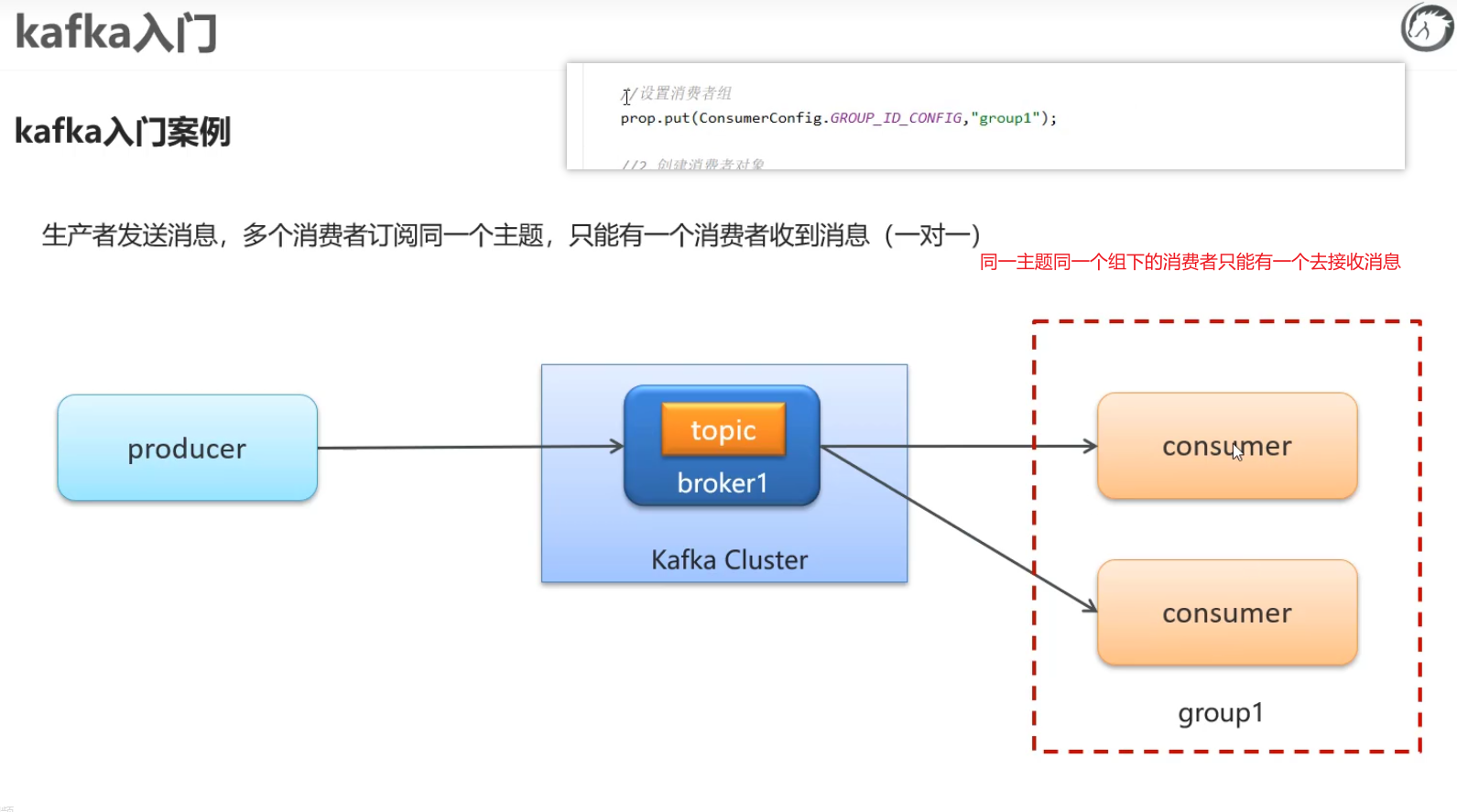
**注意:**要制定消费者组 比如这里的group2
- 配置kafka的配置信息
- 创建消费者对象
- 订阅主题
- 获取消息
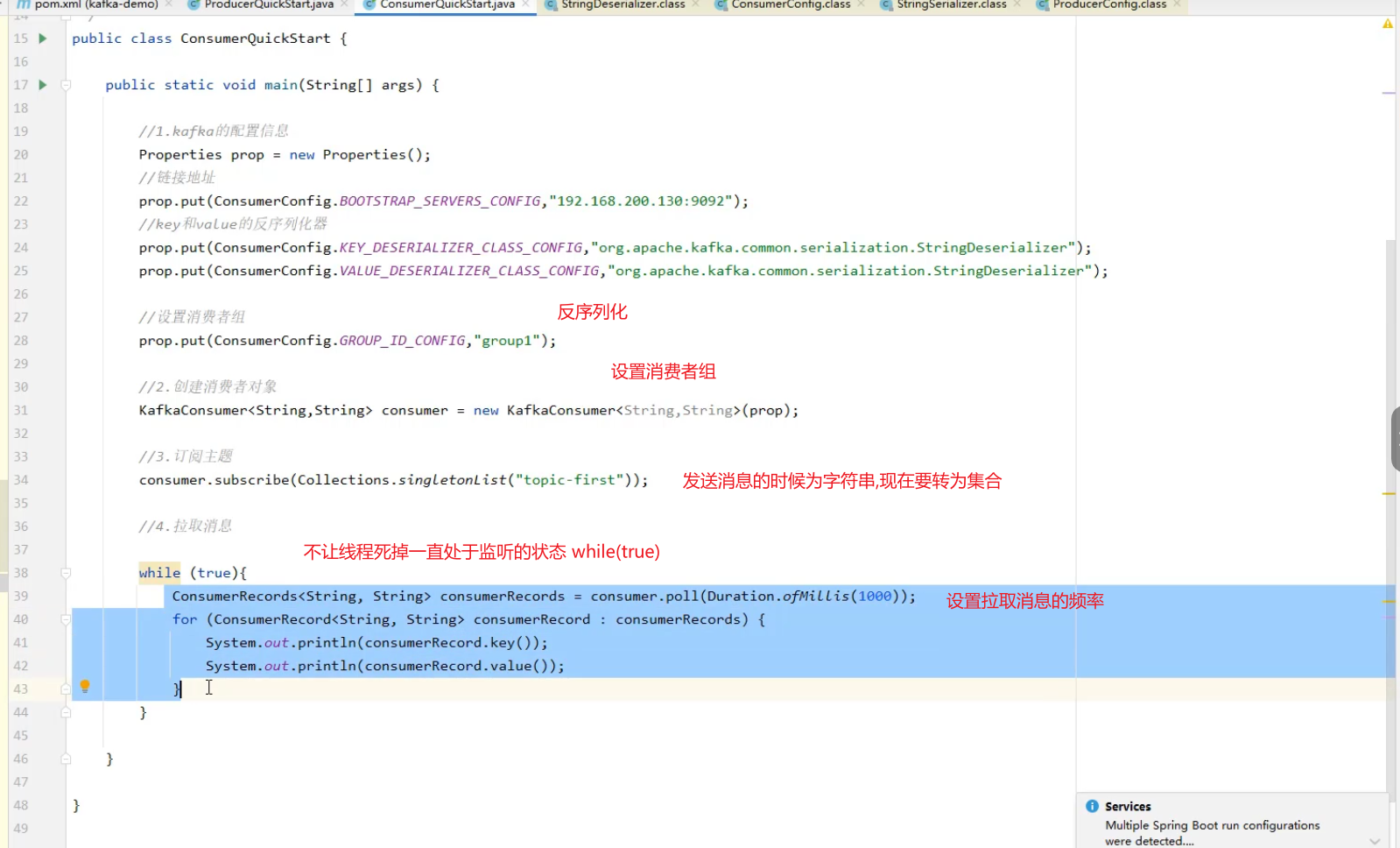
1000ms 等于 每秒去拉取
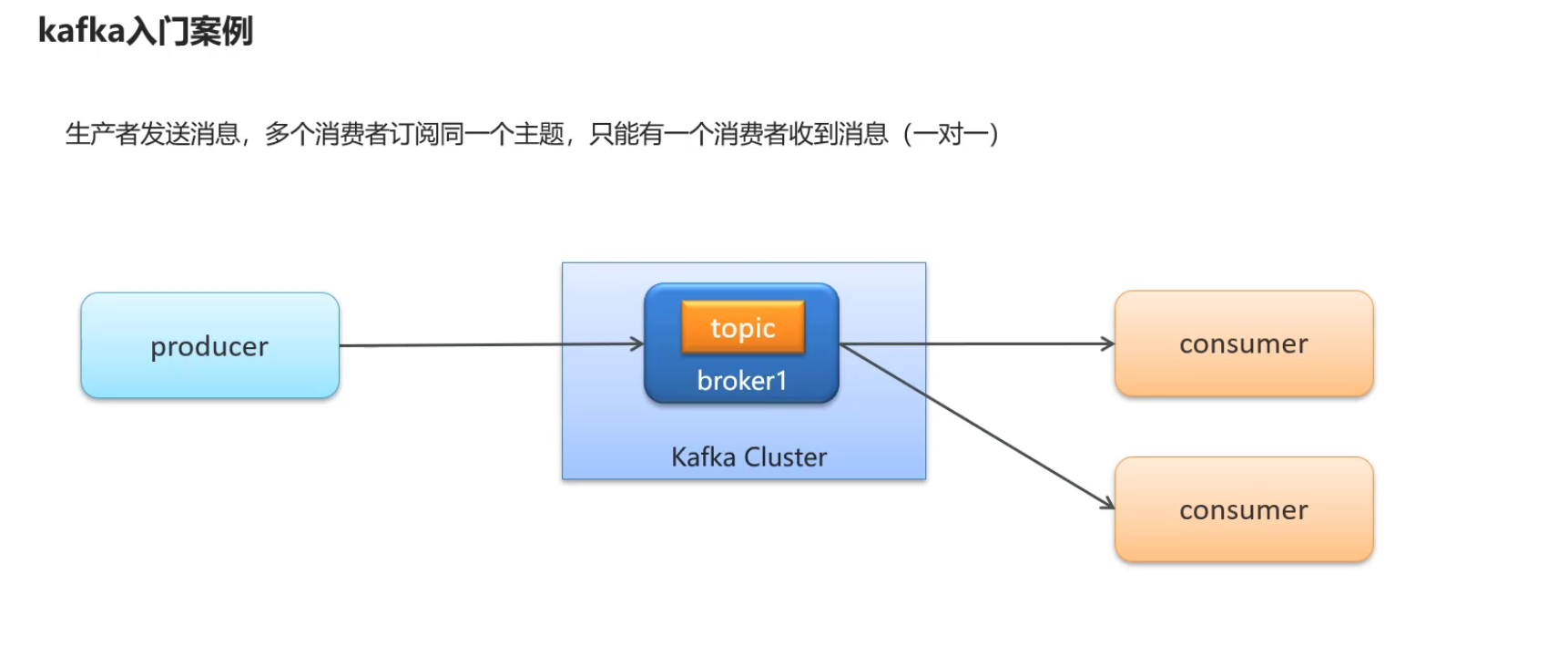
案例:要求一对一
多个消费者订阅同一个主题,只能有一个消费者收到消息
案例:要求一对多
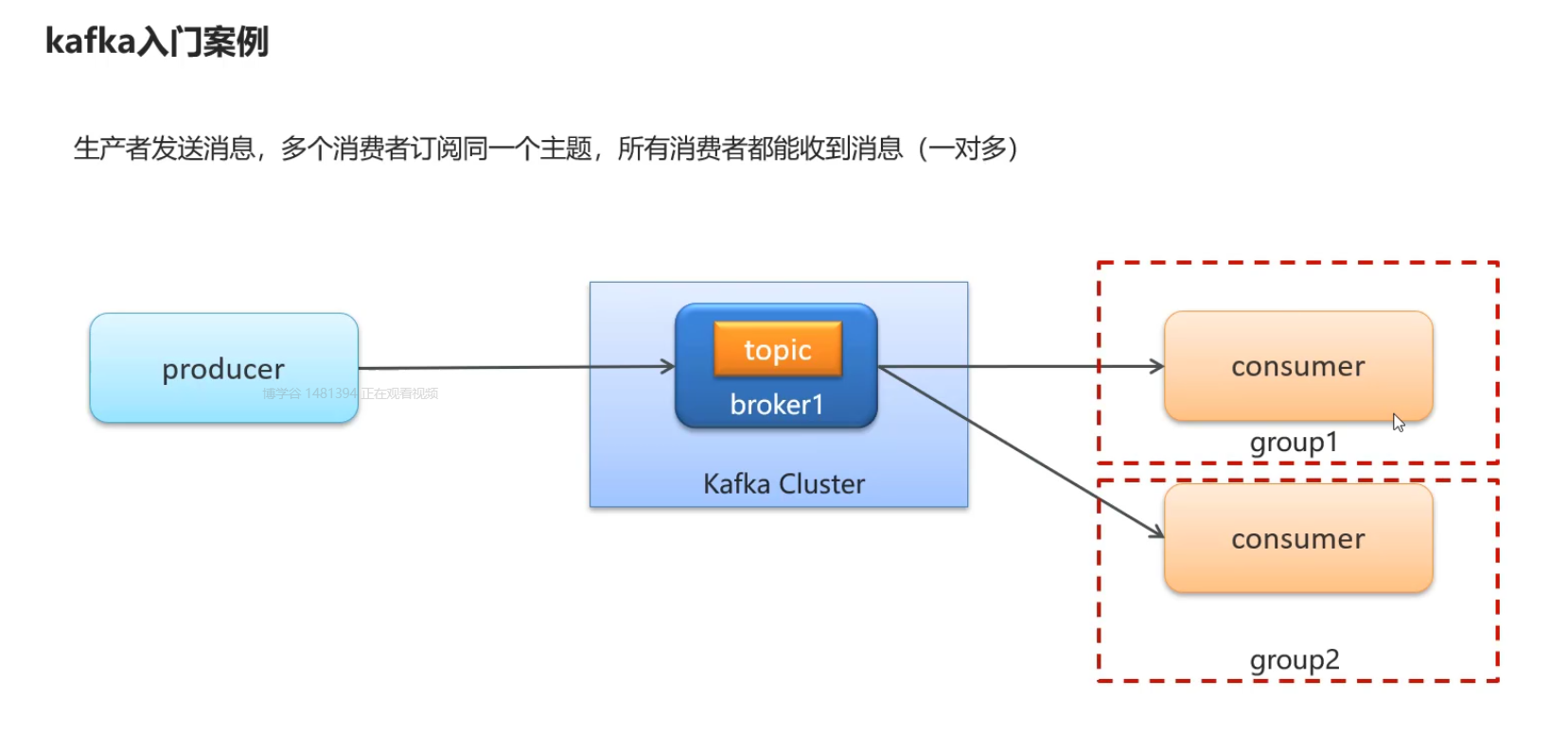
消费者在不同的组下 并且订阅的是同一个主题即可
分区机制
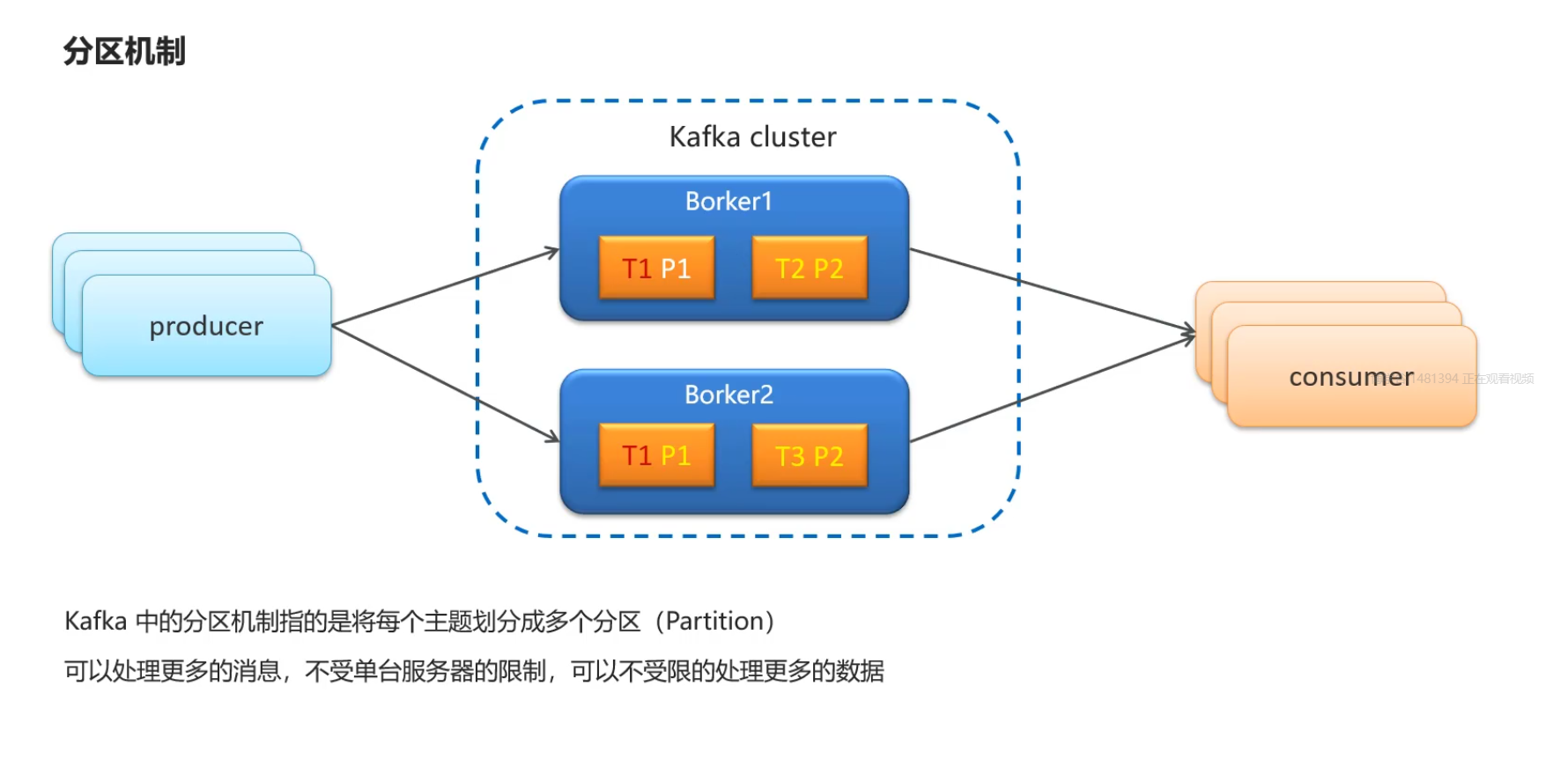
分区可以理解为存储topic文件的文件夹,发送消息的时候可以给topic制定不同的分区,然topic数据存储在不同的分区下,并且是不同的机器下.
为什么要这样设计?
假如数据量大都存储在一个台服务器上容易崩.这样可以处理更多的数据,不受单台服务器的限制,可以不受限的处理更多的数据
- 分区策略

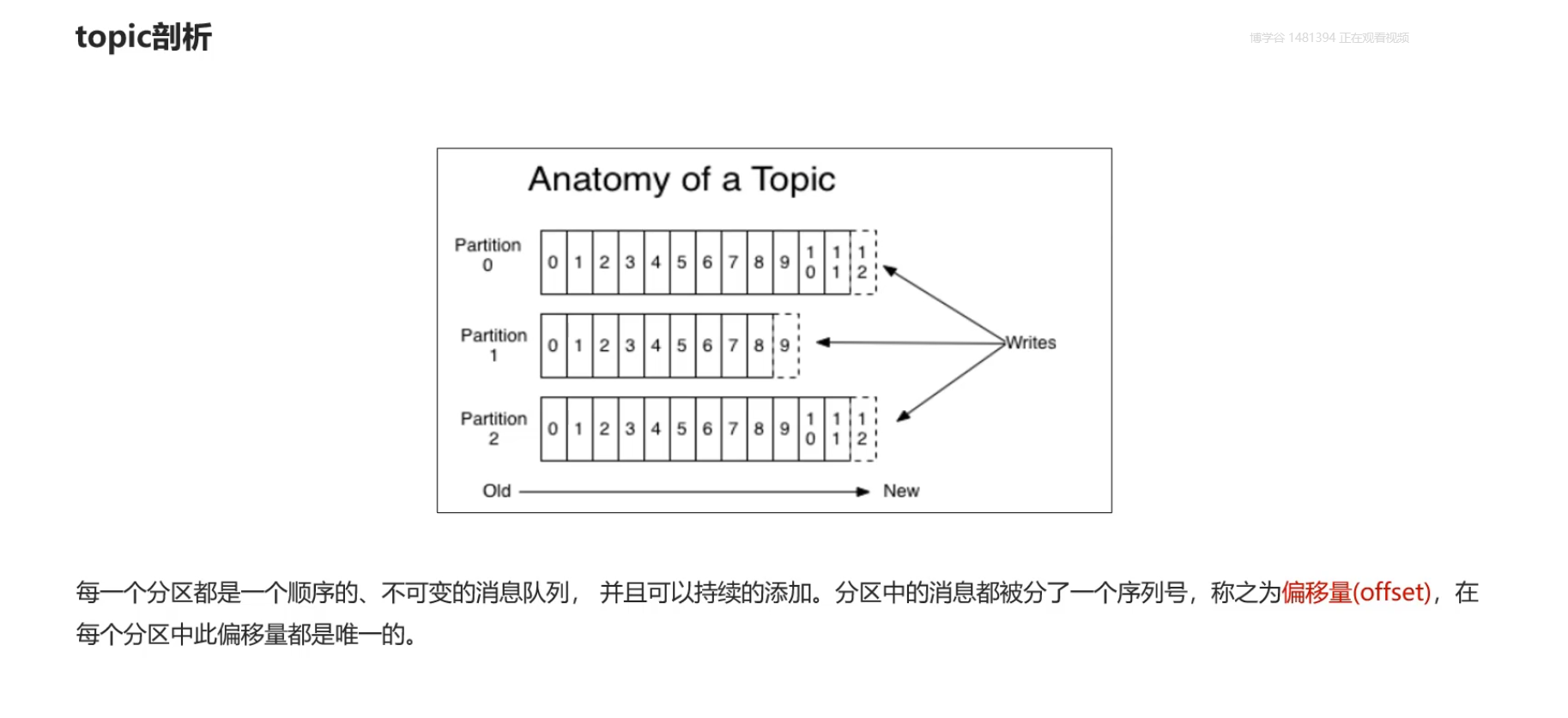
- 偏移量
每一个分区下面都有一个连续自增的数值,去标记消息存储的位置
高可用设计方案
1.集群
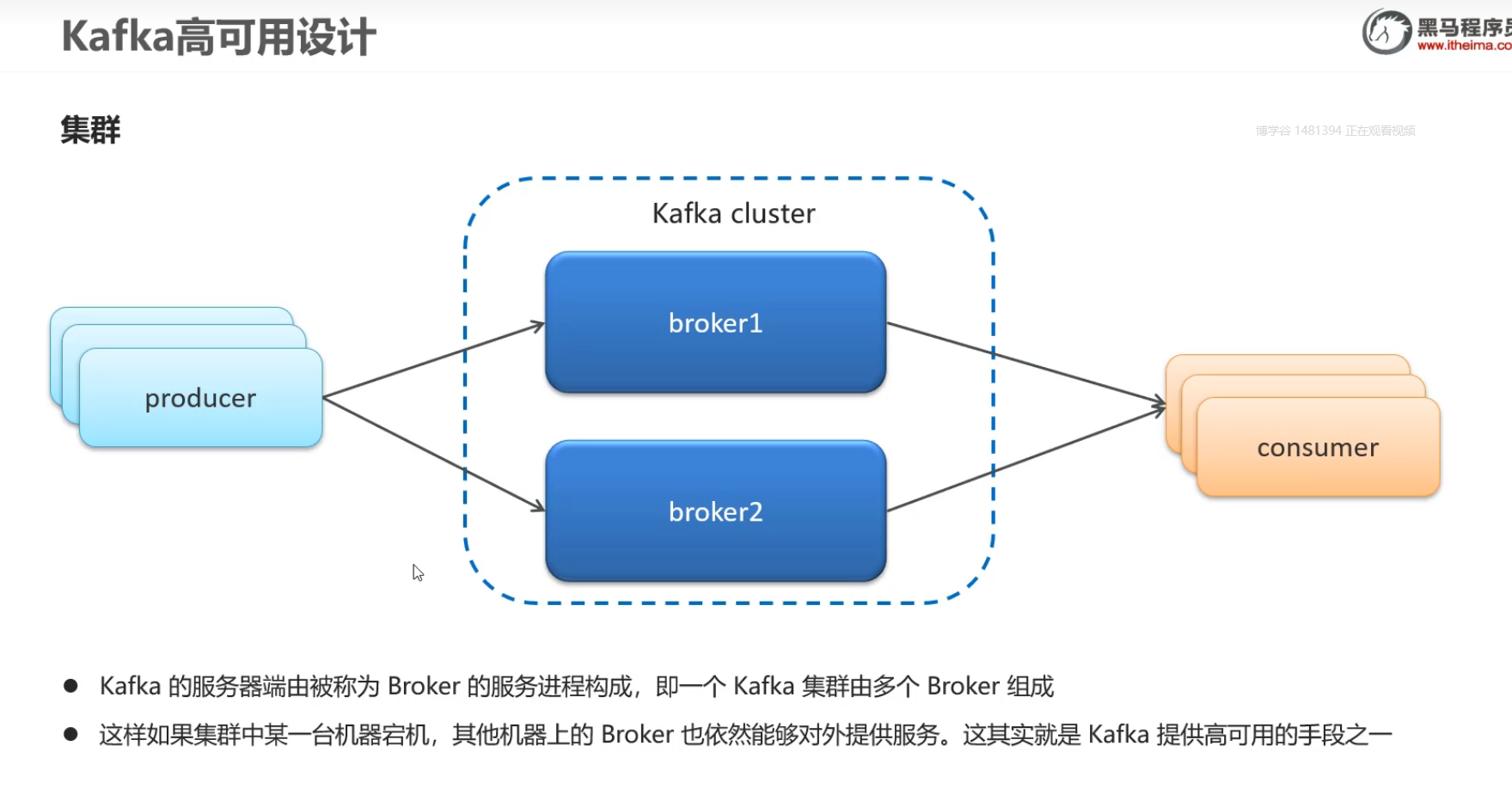
kafka集群都是由多个Broker去组成,集群中有一台服务器挂了,其他broker可以对外提供服务的,一个kafka集群是由多个Broker组成
2.备份机制
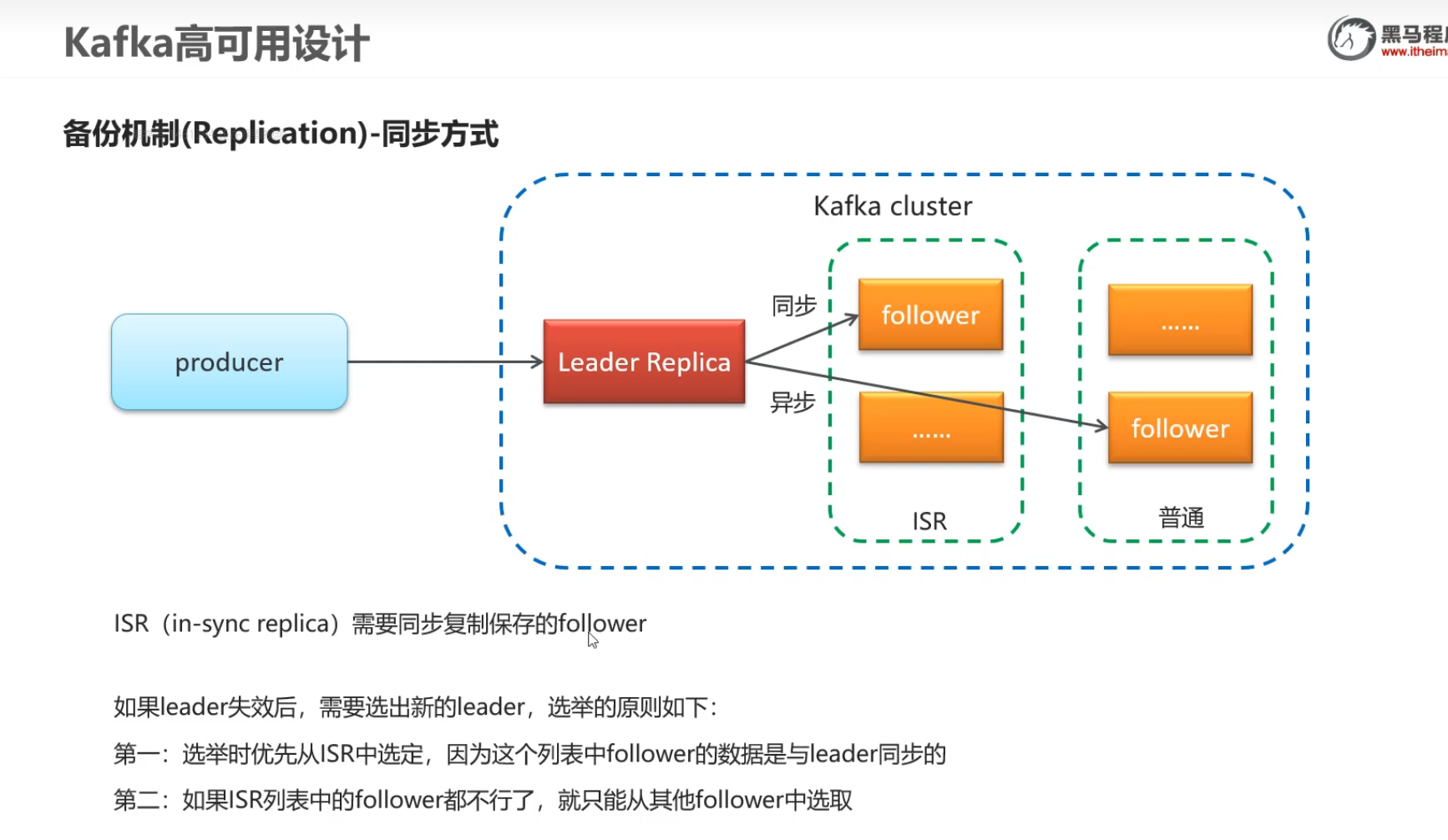
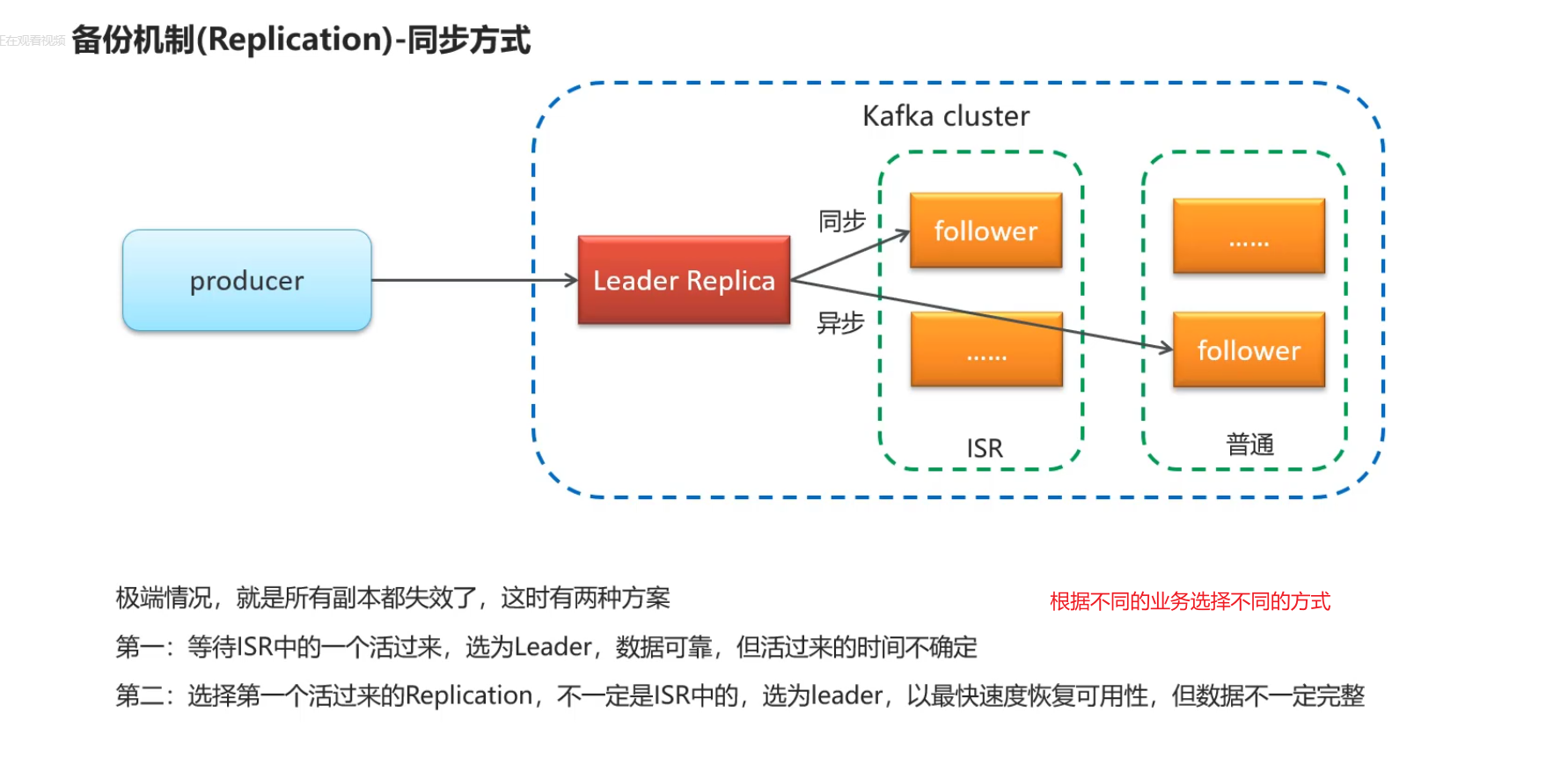
不同业务选择保证一致性还是可用性
4)生产者-消息发送类型
同步
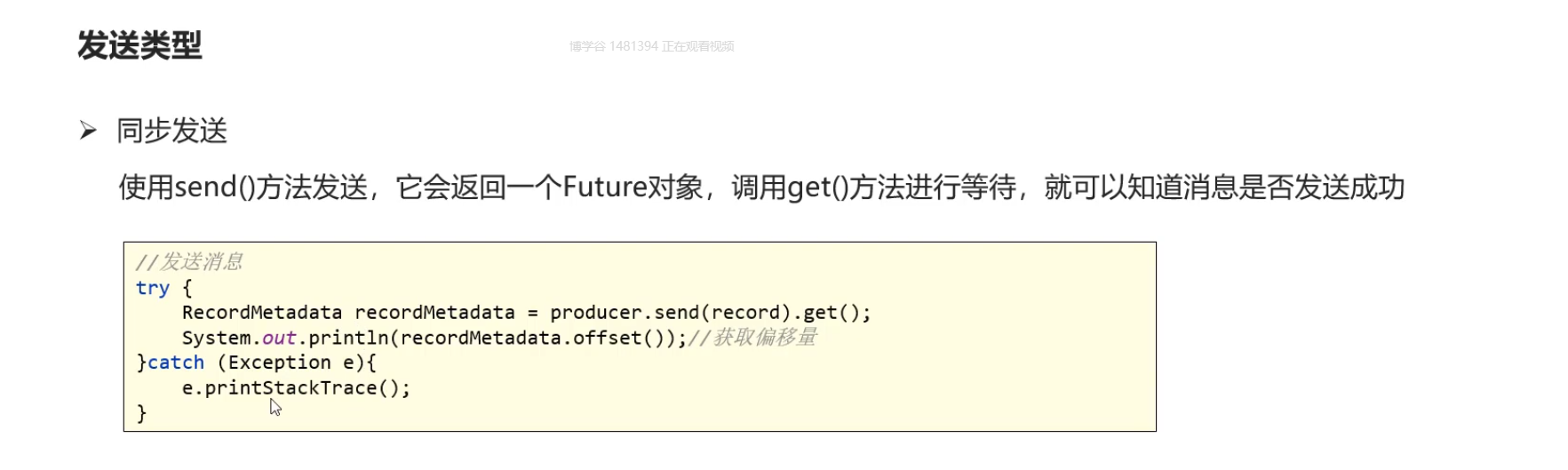
同步发送消息回存在什么问题?
数据量大的时候消耗时间比较长
异步

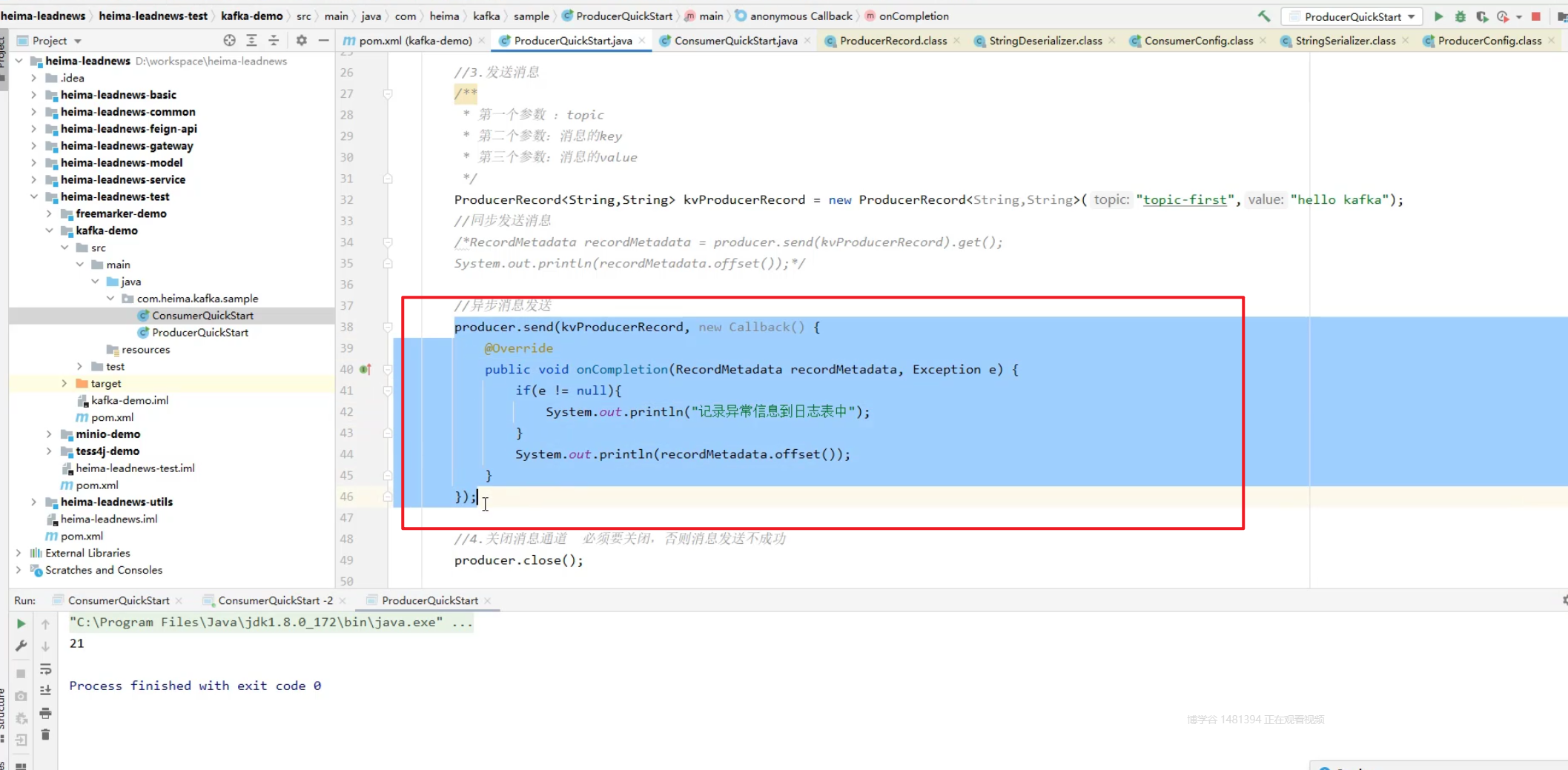
5)生产者-参数配置
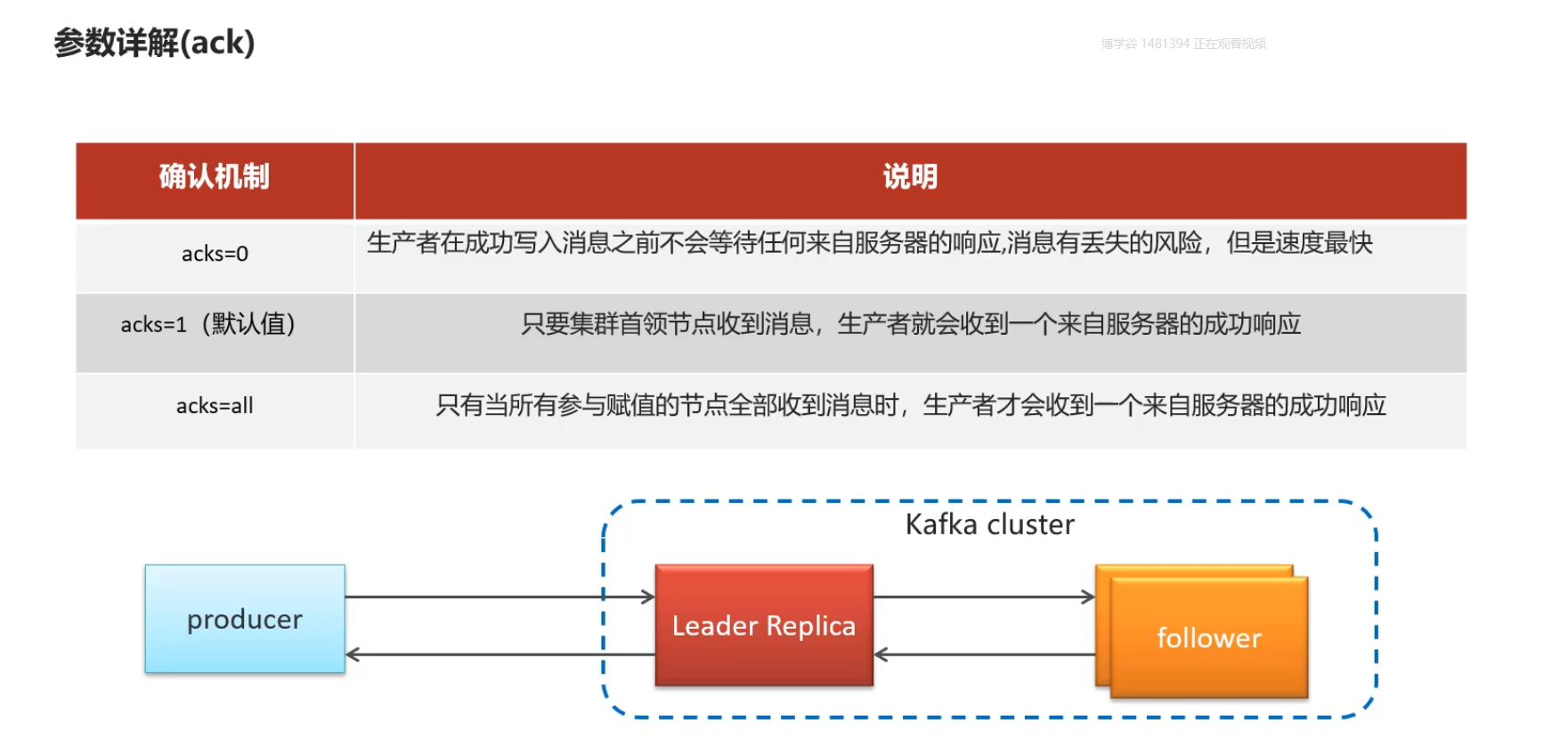
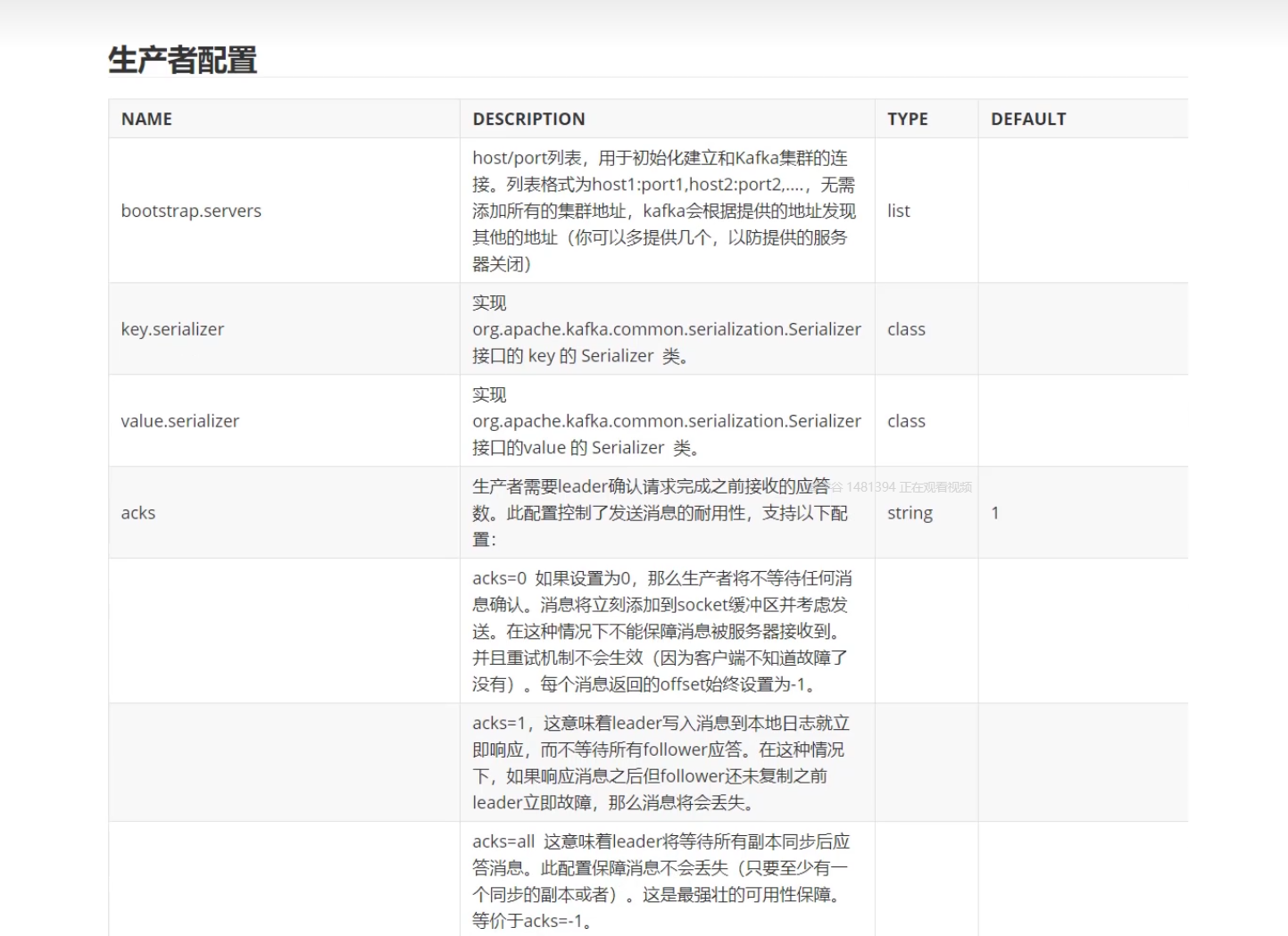
ack确认者机制
ack配置,消息确认机制
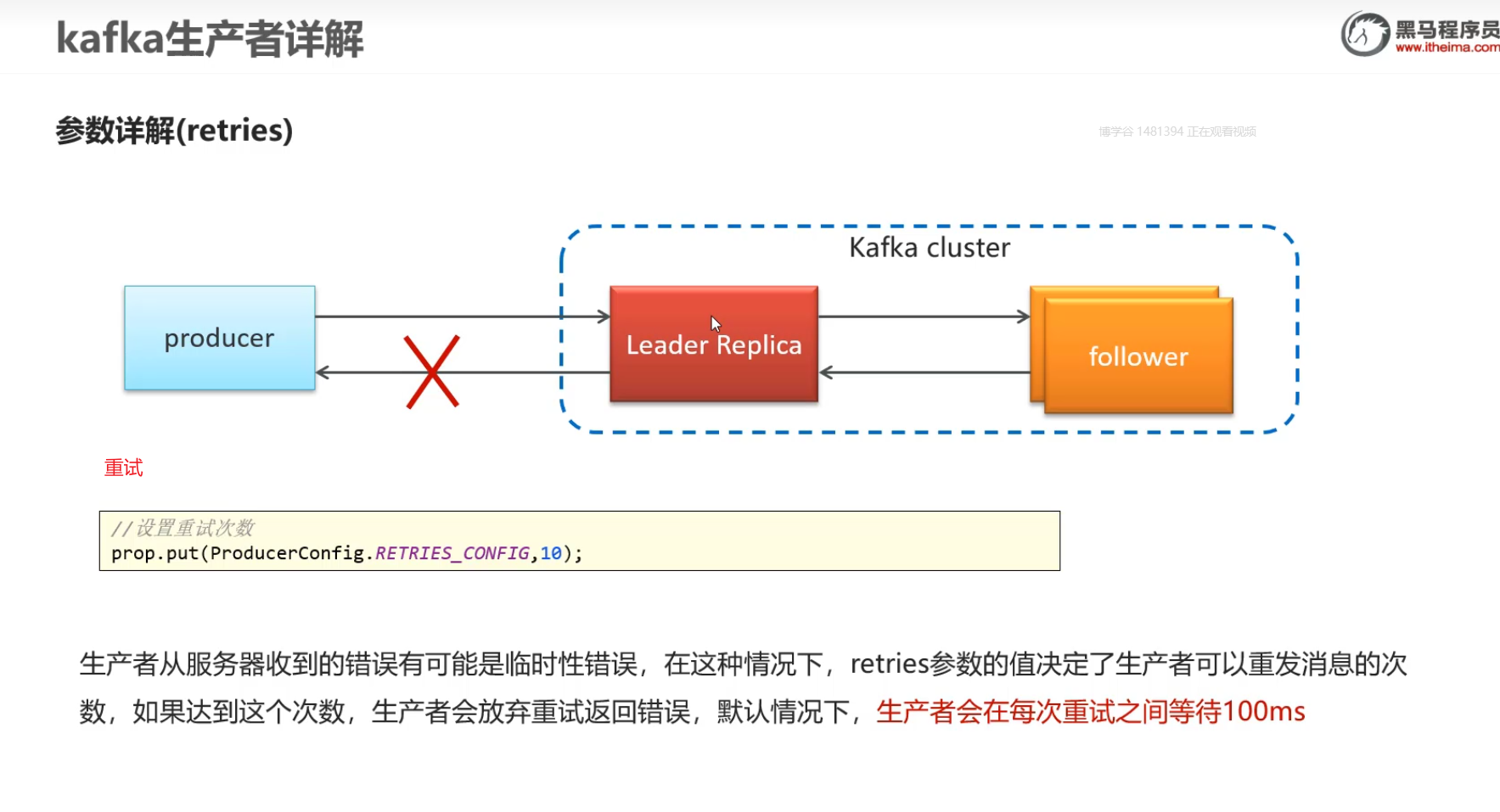
重试机制
消息压缩
默认情况下,消息发送时不会被压缩

6)消费者-消息有序性
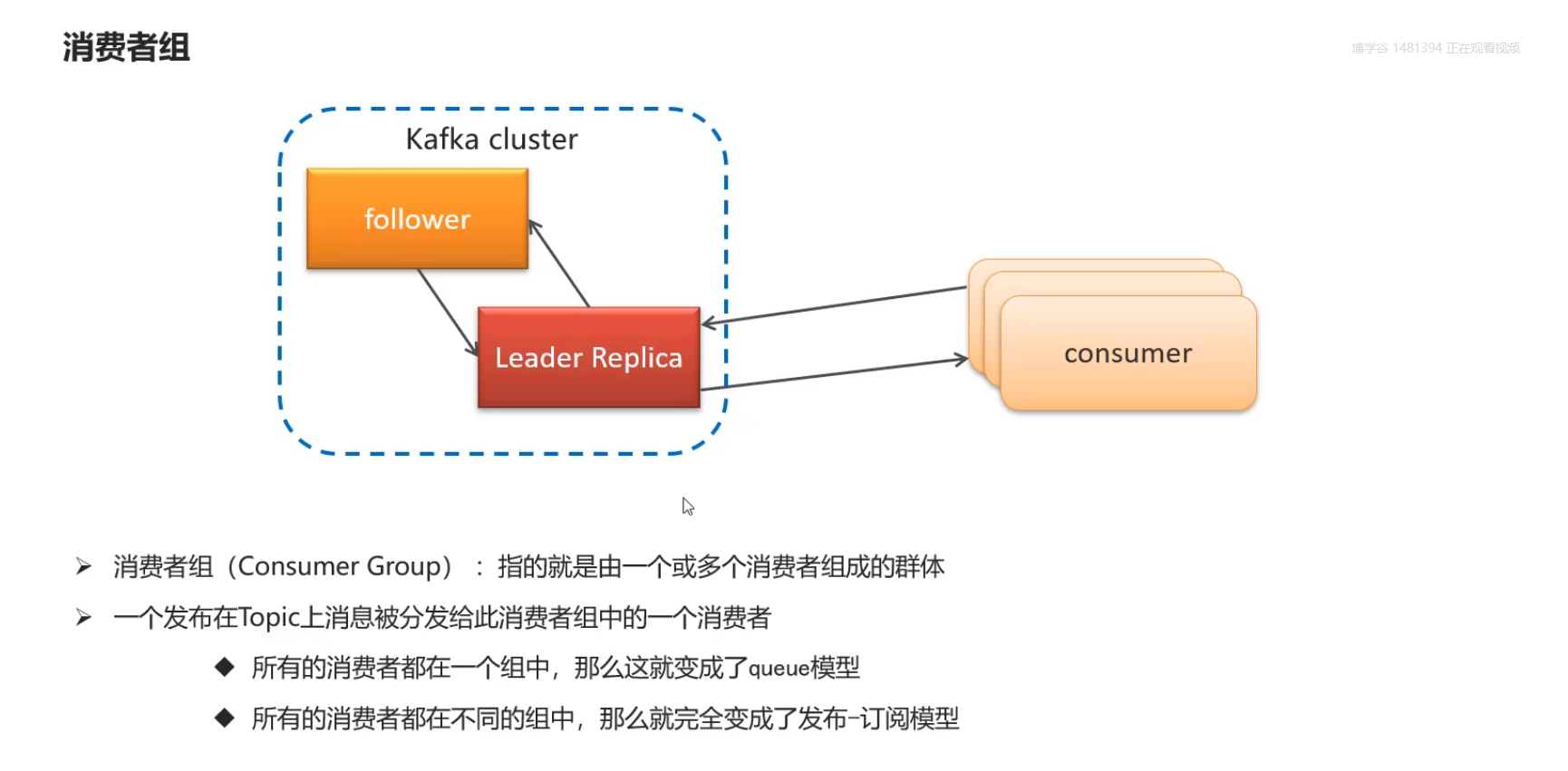
消息有序性

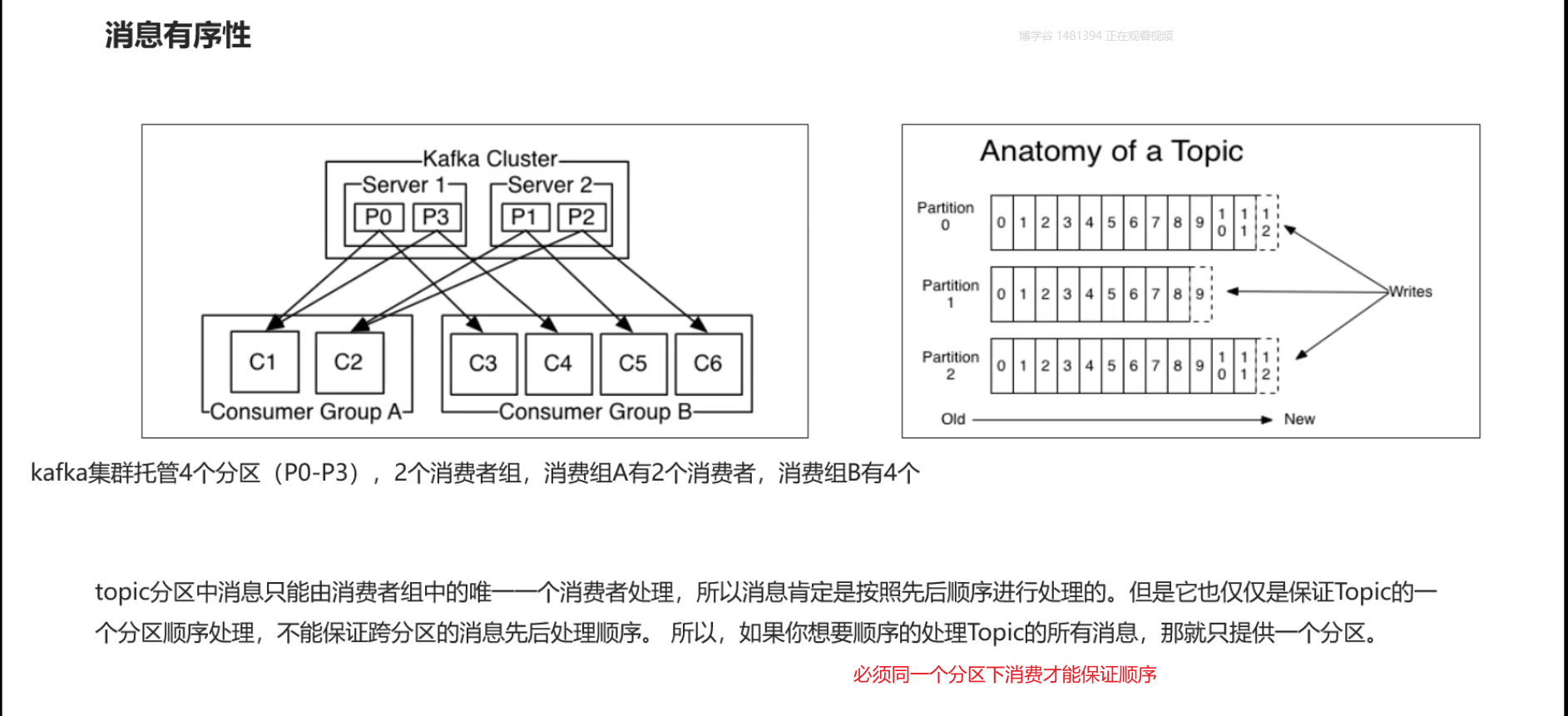
如果想要顺序的去处理那么就要在创建topic 的时候只提供一个分区就行.同一个分区下是可以保证顺序的
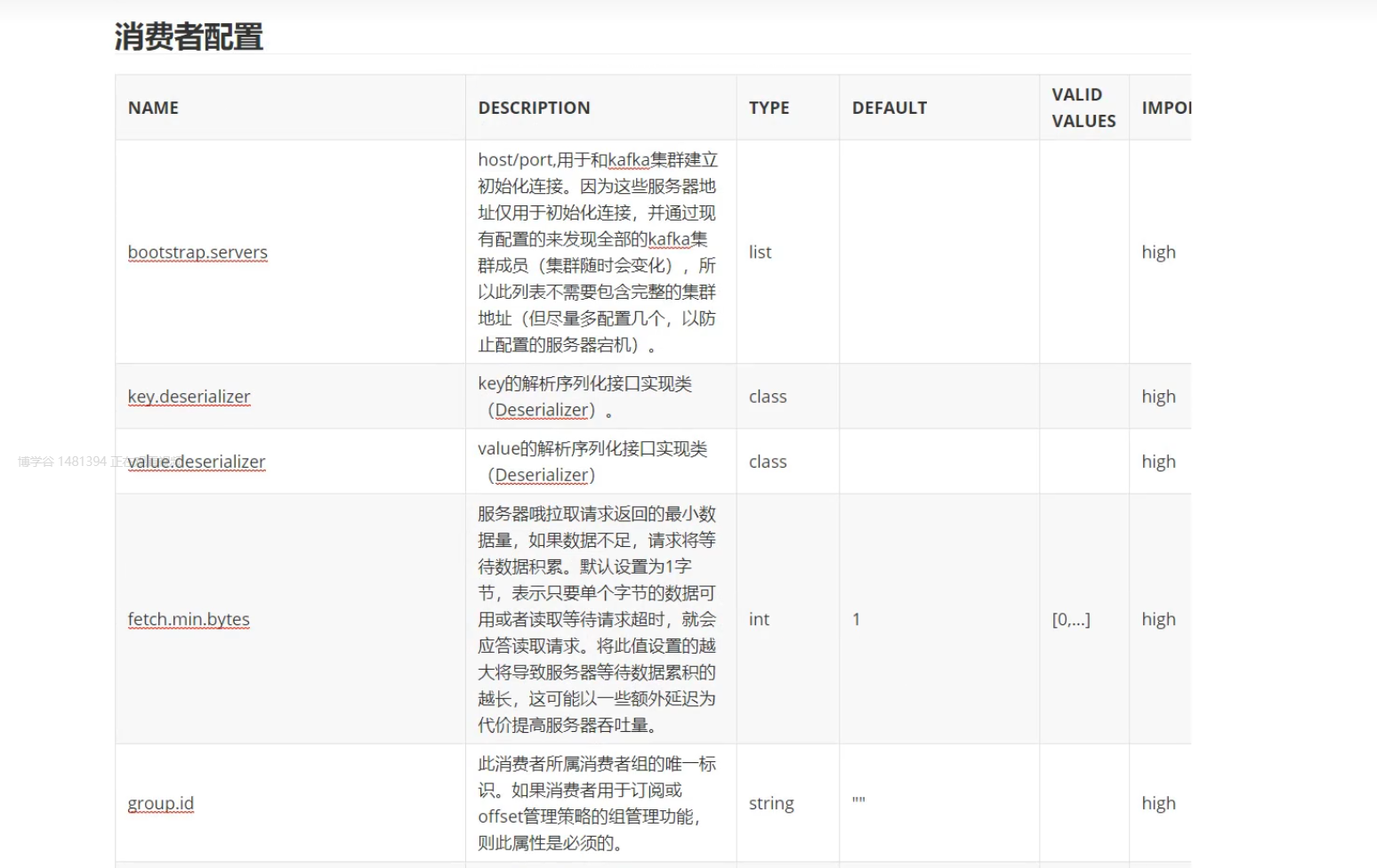
7)消费者-提交和偏移量
偏移量会记录消息的位置:每一个分区下面都有一个连续自增的数值,去标记消息存储的位置

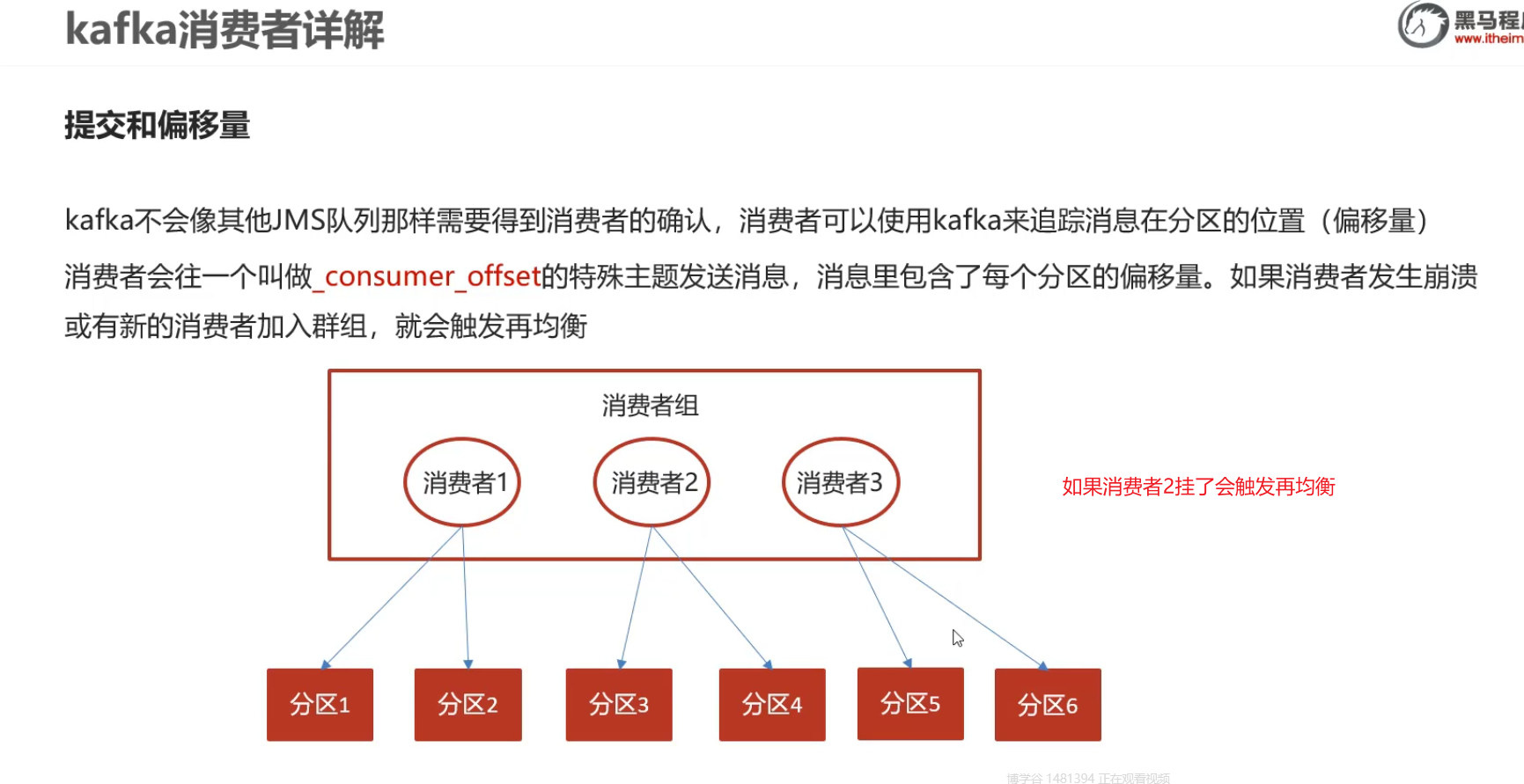
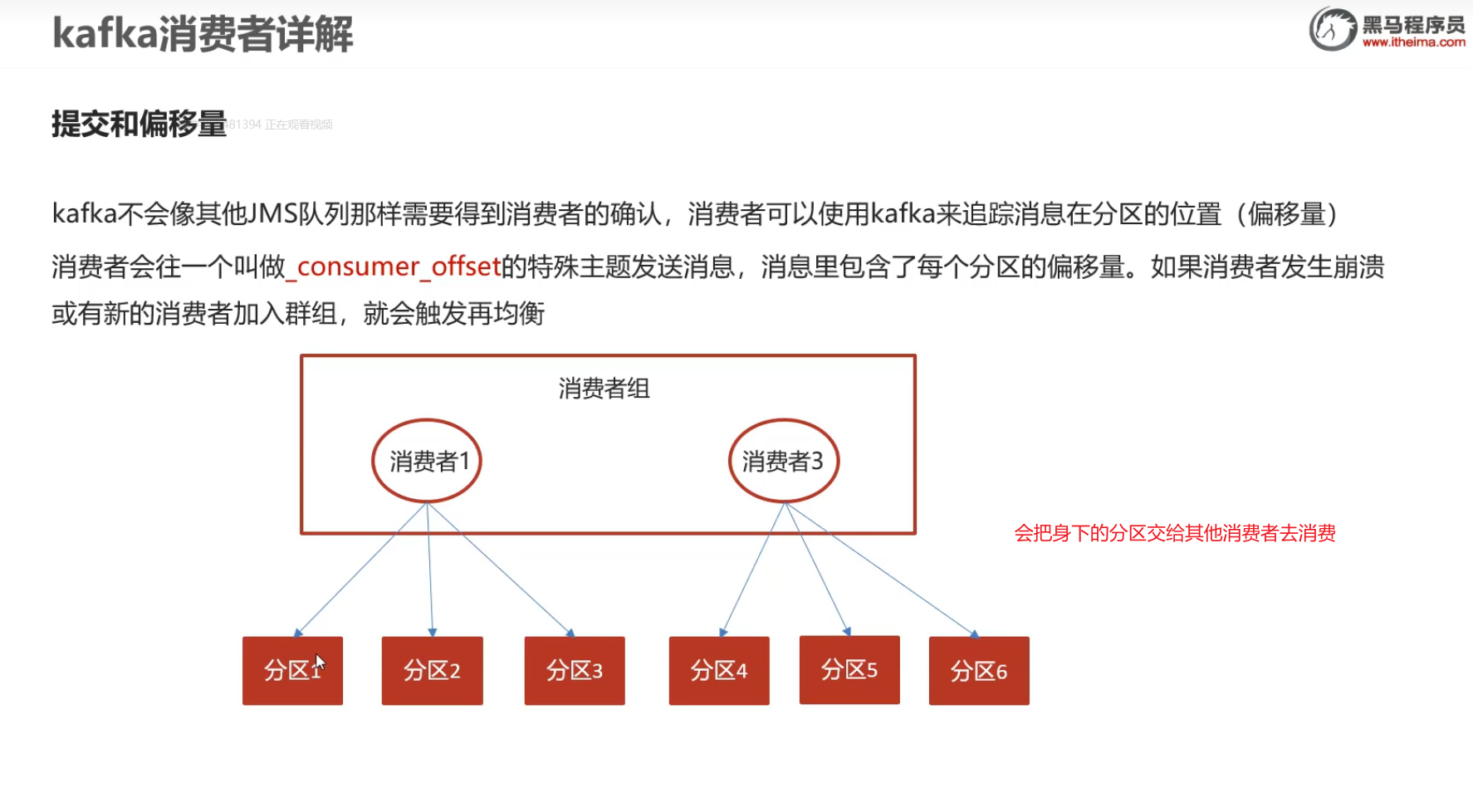
及时再均衡也可能会出现问题
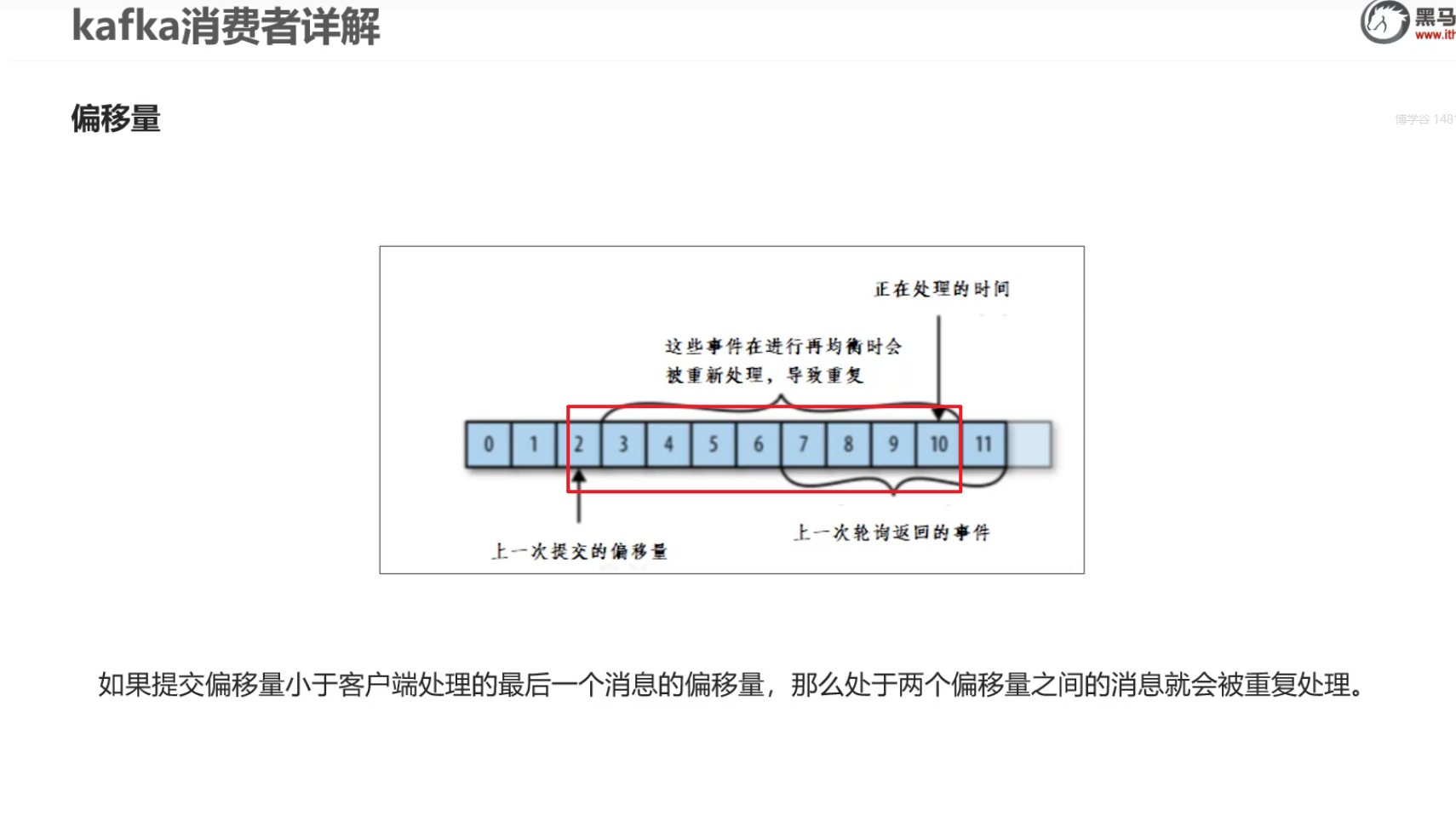
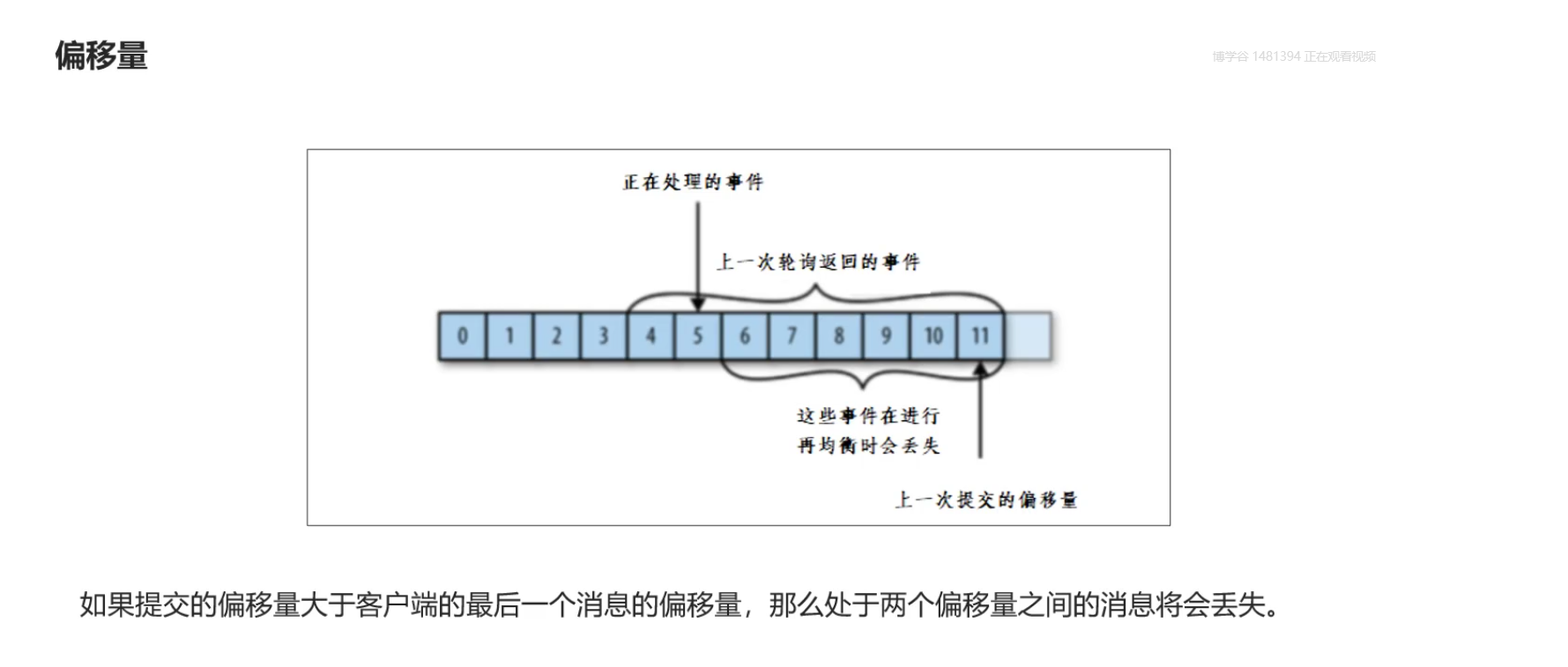
这都是自动提交偏移量造成的
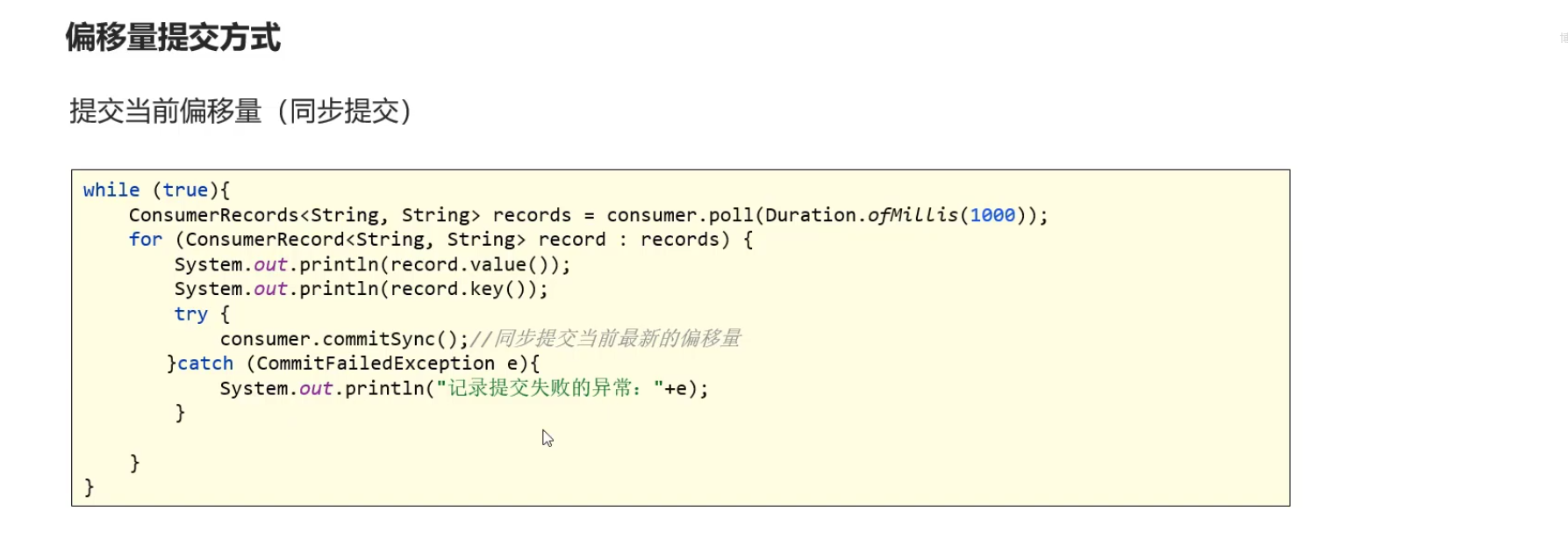
- 偏移量提交方式
自动提交,手动提交

同步提交:缺点产生方法的阻塞
异步提交:缺点 没有重试 ,如果同时存在多个异步提交进行重试可能会导致位移的覆盖
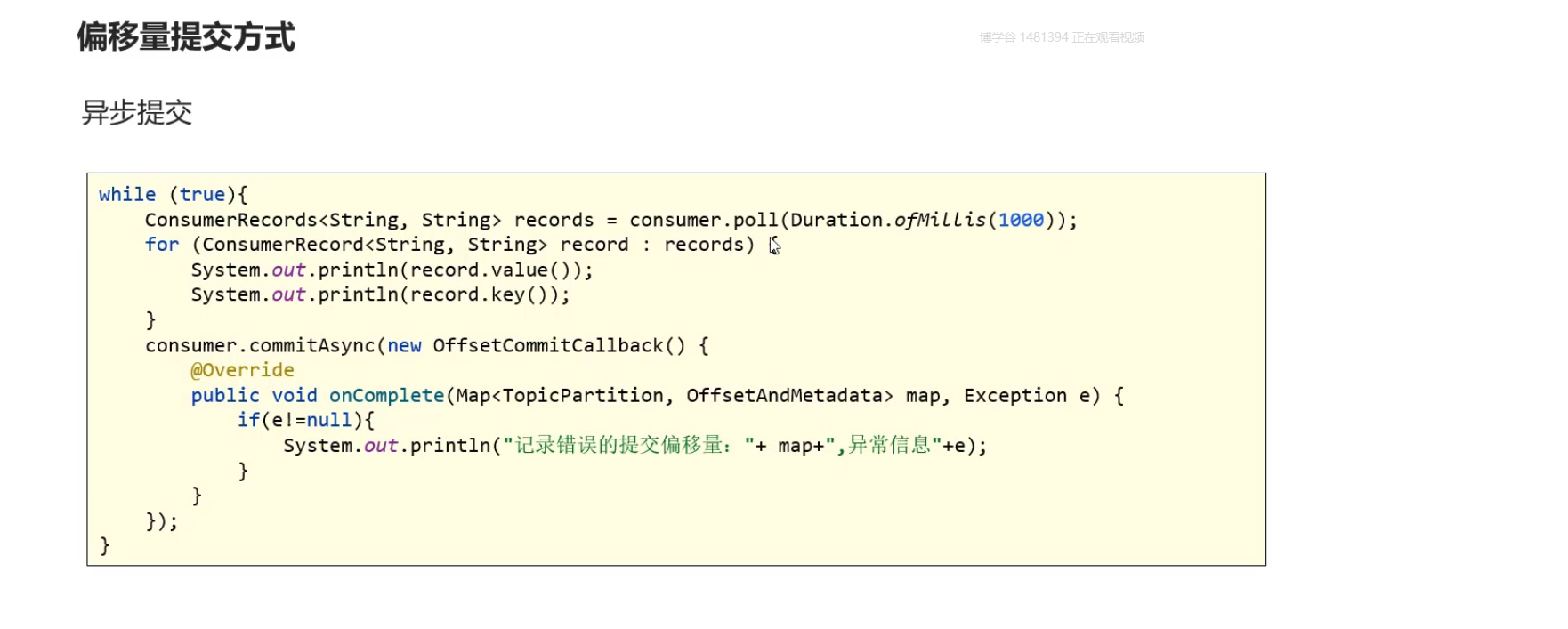
同步异步组合提交
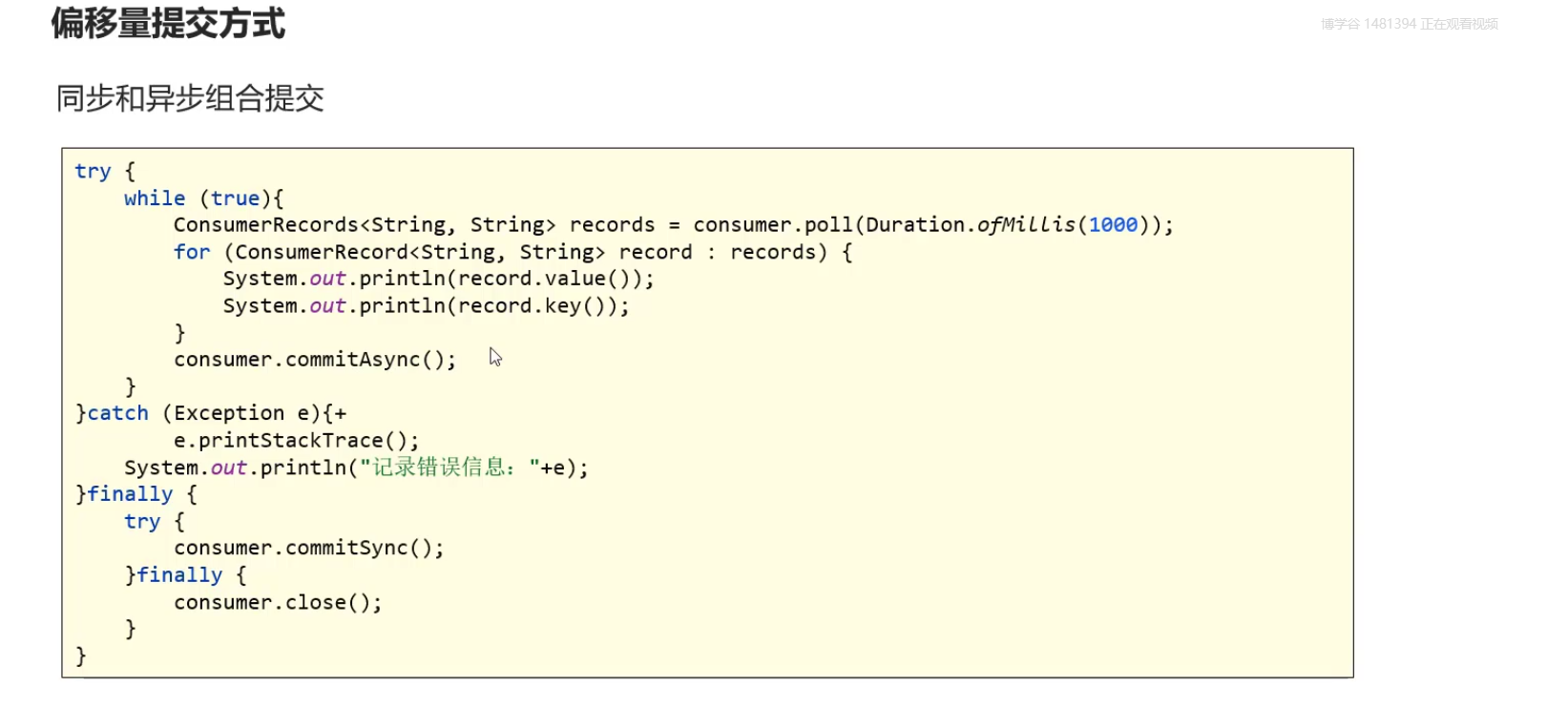
如果异步提交产生错误之后我们再用同步的方式去提交偏移量
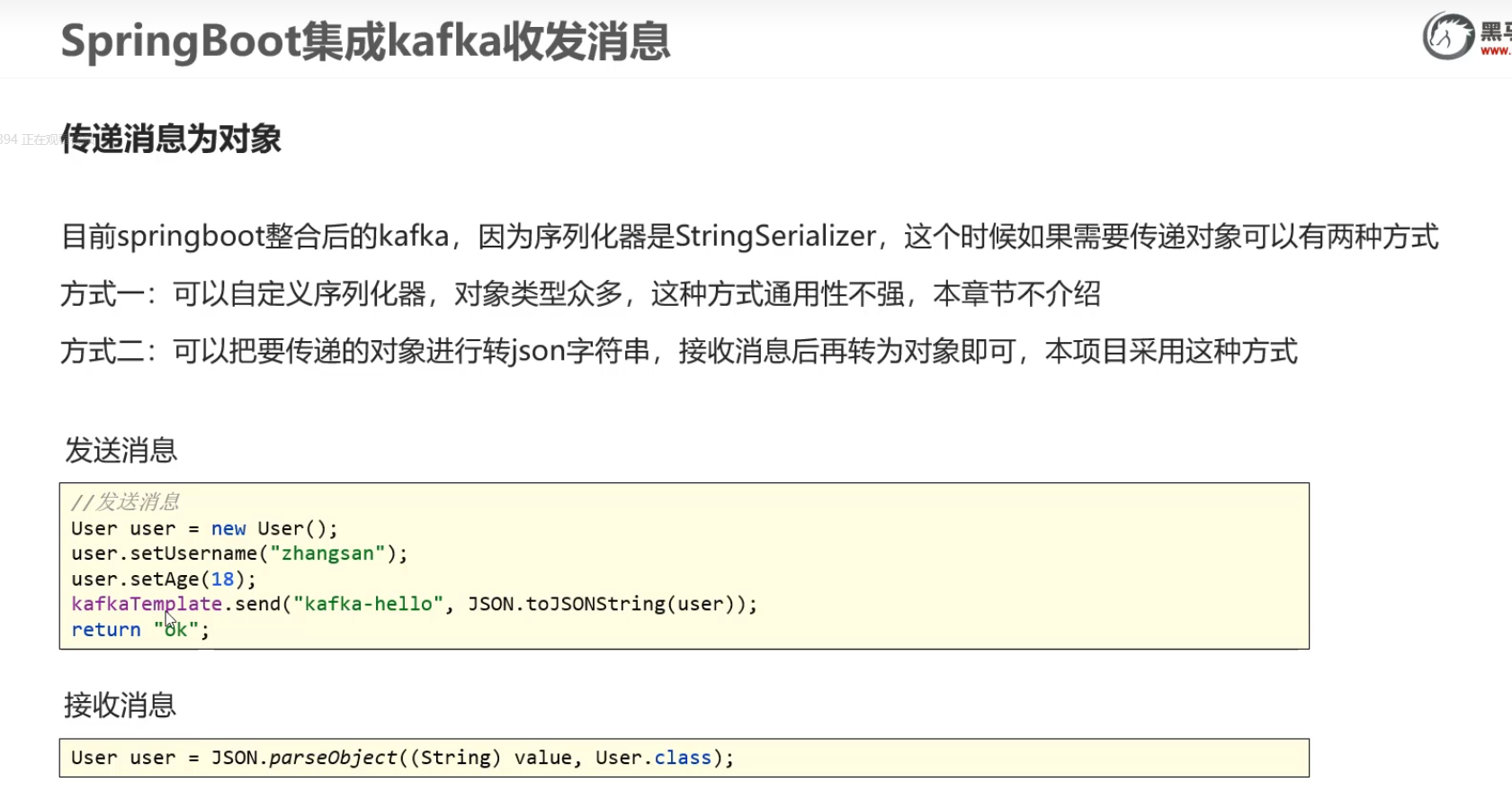
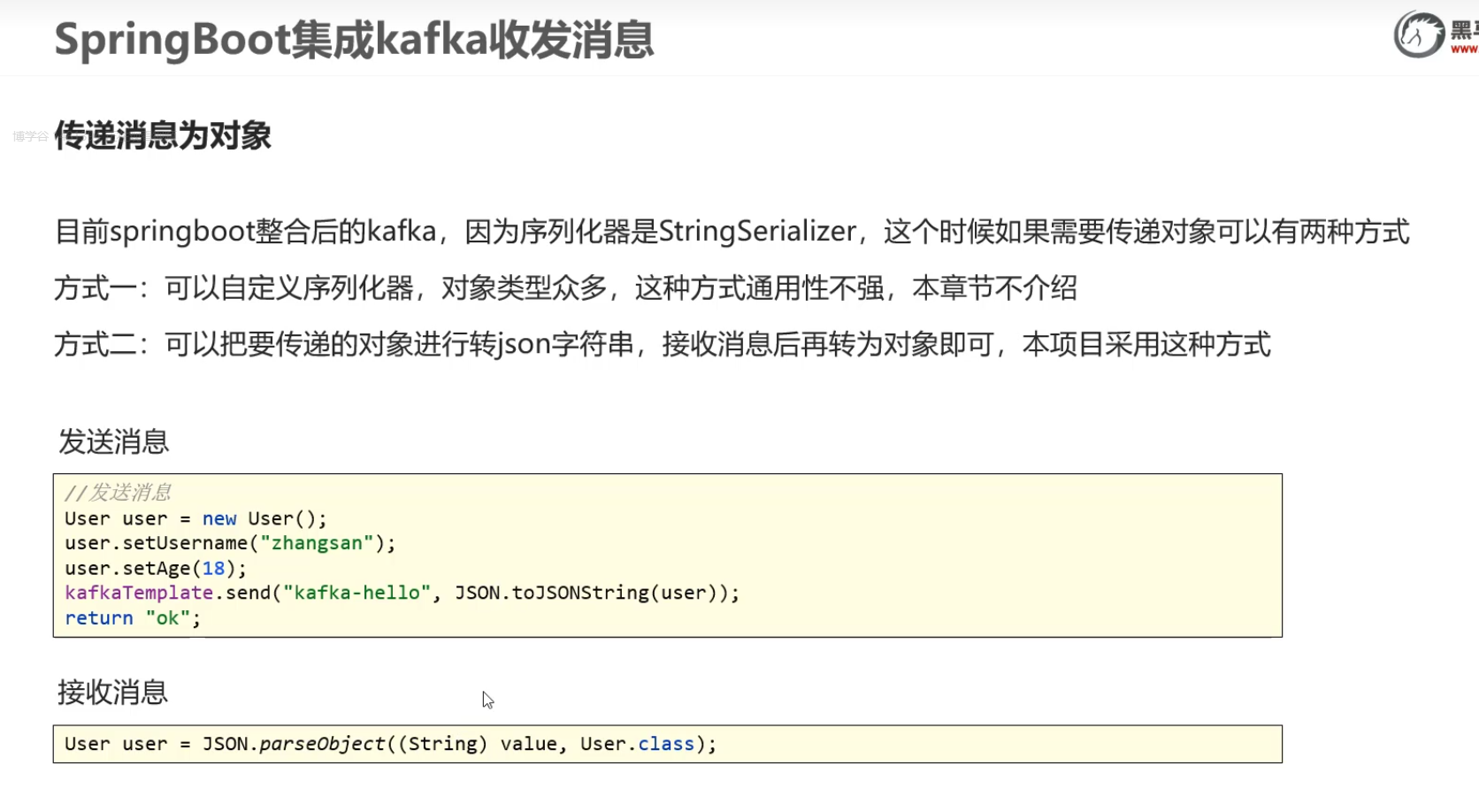
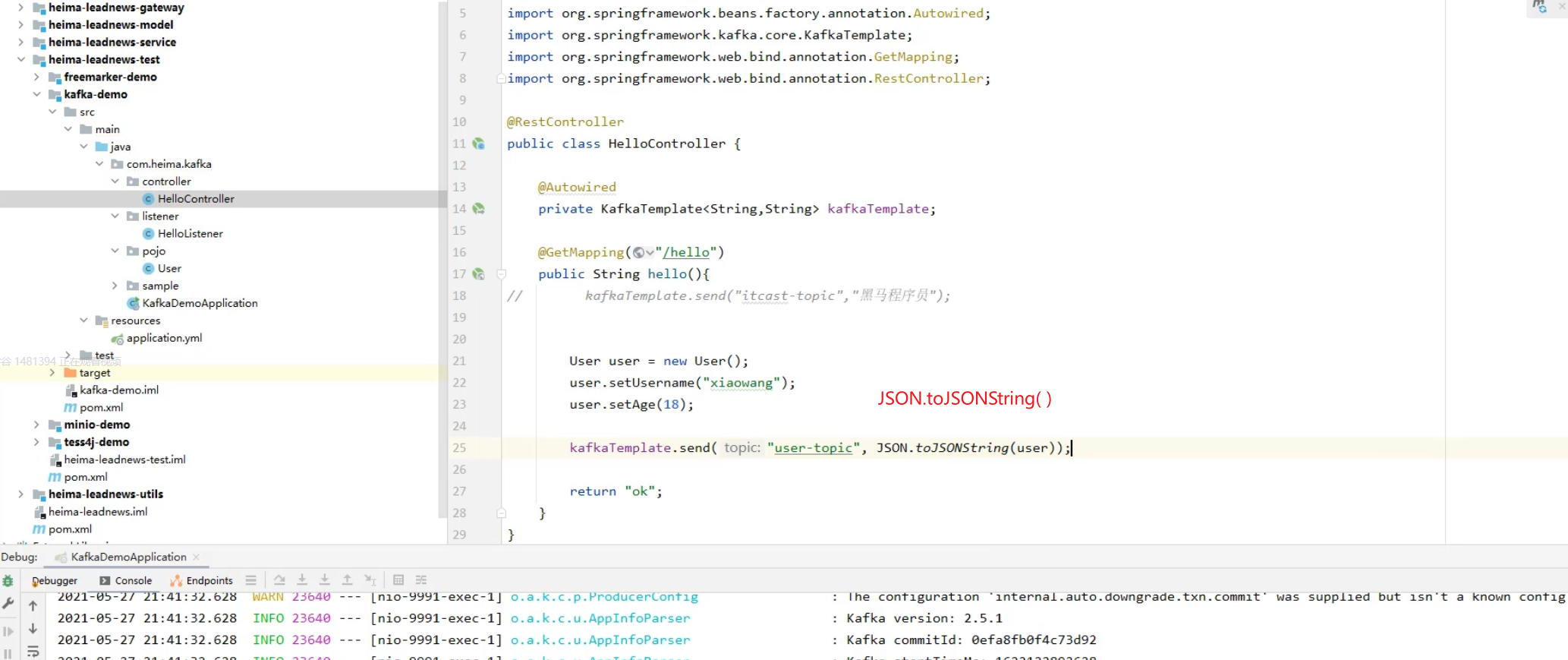
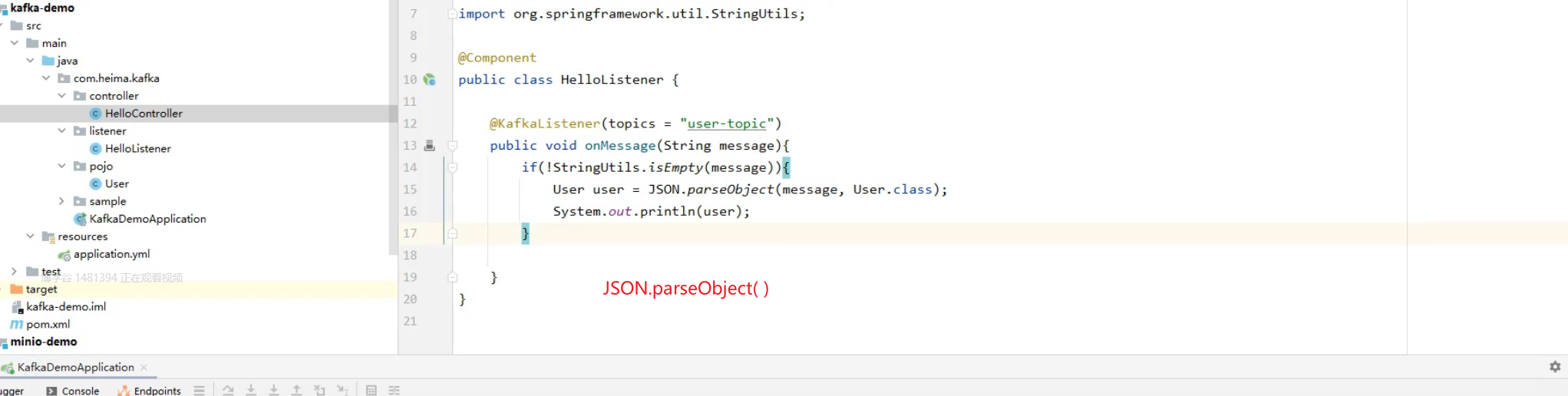
8)SpringBoot集成kafka收发消息
- 引入依赖修改配置
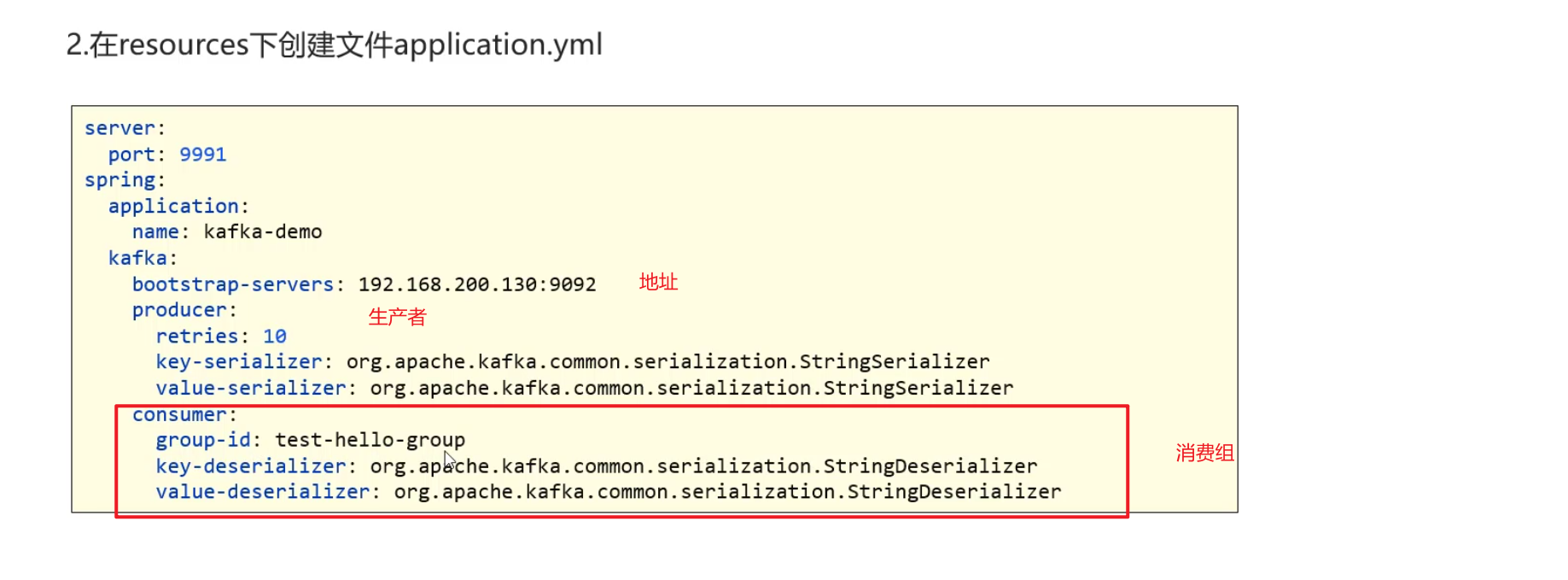
重试次数 序列化器

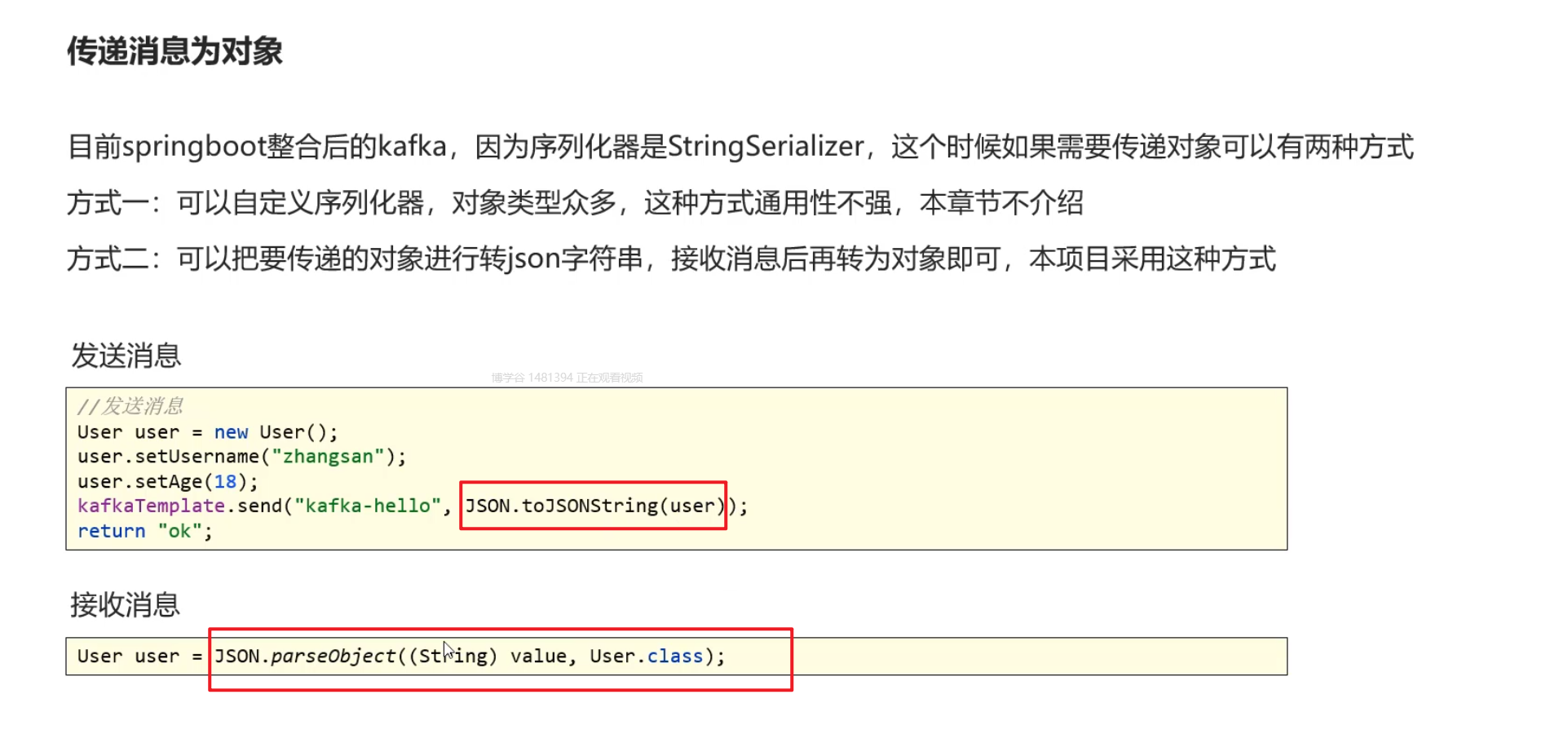
传递消息为对象