Prometheus+Grafana+Alertmanager告警
Alertmanager开源地址:github.com/prometheus
Prometheus是一款基于时序数据库的开源监控告警系统,它是SoundCloud公司开源的,SoundCloud的服务架构是微服务架构,他们开发了很多微服务,由于服务太多,传统的监控已经无法满足它的监控需求,于是他们在2012就着手开发新的监控系统。
本篇使用的组件:
- Prometheus
- Grafana
- Node-exporter
- Alertmanager
本篇忽略前三个组件的安装步骤
| IP | 部署组件 | |
|---|---|---|
| 10.22.51.65 | Prometheus服务端、Grafana、Alertmanager报警 | |
| 10.22.51.66 | Node-exporter | |
| 120.78.156.217 | Node-exporter | |
| 10.22.51.64 | Node-exporter |
1、Prometheus架构原理
1.架构图
来自官方的架构图
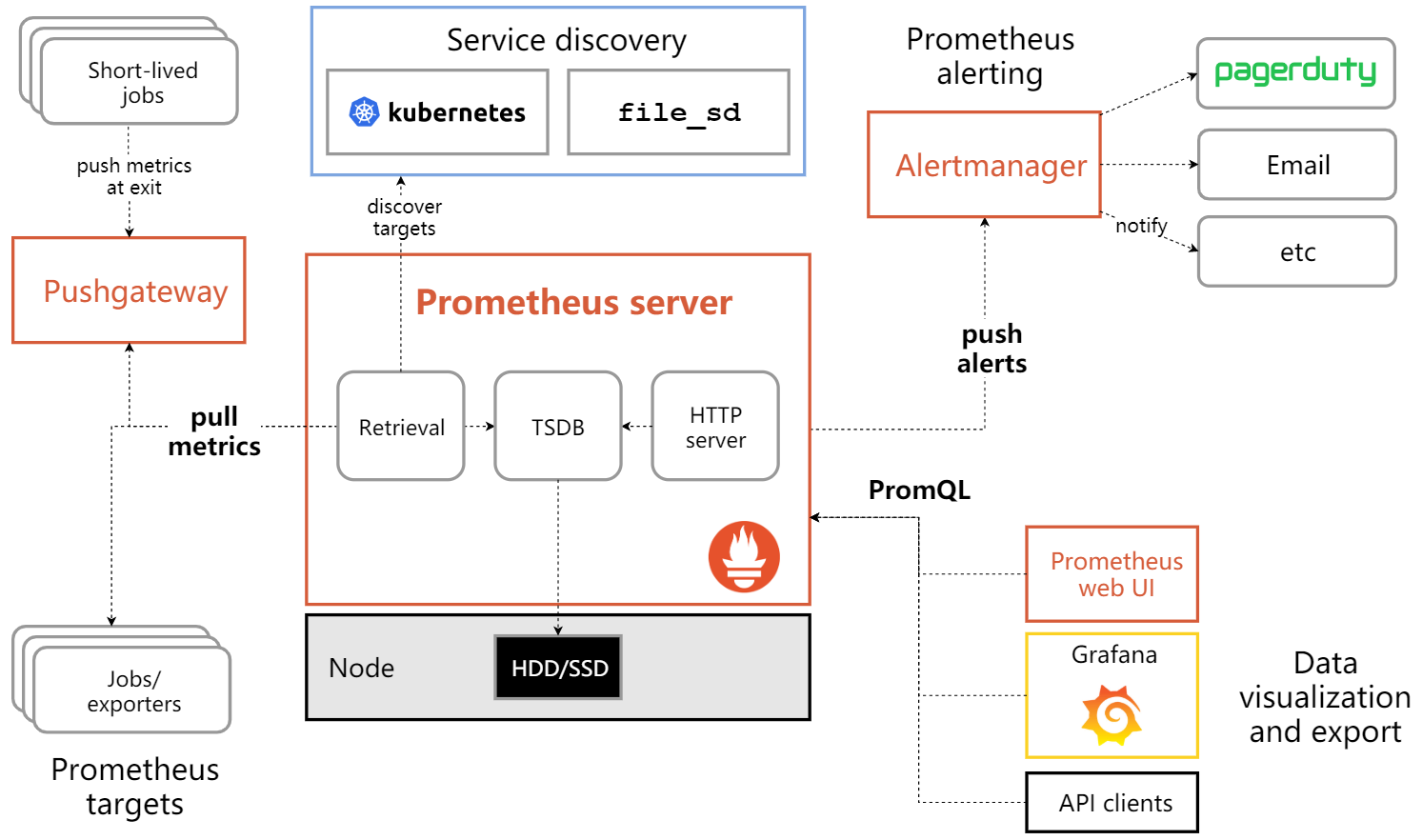
2.怎么采集监控数据
要采集目标的监控数据,首先就要在被采集目标地方安装采集组件(如node-exporter),这种采集组件被称为Exporter。prometheus.io官网上有很多这种exporter,官方 exporter列表。
采集完了怎么传输到Prometheus?
采集了数据,要传输给prometheus。怎么做?
Exporter 会暴露一个HTTP接口,prometheus通过Pull模式的方式来拉取数据,会通过HTTP协议周期性抓取被监控的组件数据。
不过prometheus也提供了一种方式来支持Push模式,你可以将数据推送到Push Gateway,prometheus通过pull的方式从Push Gateway获取数据。
3.主要流程
- Prometheus server定期从静态配置的 targets 或者服务发现的 targets 拉取数据(zookeeper,consul,DNS SRV Lookup等方式)
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus会将数据持久化到磁盘,也可以远程持久化到云端。
- Prometheus通过PromQL、API、Console和其他可视化组件展示数据。Prometheus支持很多方式图表可视化,比如Grafana,自带的Promdash。它还提供HTTP API的查询方式,自定义输出。
- Prometheus 可以配置rules,然后定时查询数据,当条件触发的时候,会将alert推送到配置的Alertmanager。
- Alertmanager收到告警的时候,会根据配置,聚合,去重,降噪,最后发出警告。
2、Centos7部署Alertmanager
1.Alertmanager下载安装
cd /usr/local/src
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-386.tar.gz
tar -zxvf alertmanager-0.27.0.linux-386.tar.gz -C /data
mv /data/alertmanager-0.27.0.linux-386 /data/alertmanager2.加入systemd管理
[root@zhongjl-test-02 /data/alertmanager]# cat /etc/systemd/system/alertmanager.service
[Unit]
Description=AlertManager Service
After=network.target
After=syslog.target
[Service]
Restart=always
ExecStart=/data/alertmanager/alertmanager --config.file=/data/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target3.启动alertmanager
systemctl start alertmanager.service
[root@zhongjl-test-02 /data/alertmanager]# netstat -tnlp | grep aler
tcp6 0 0 :::9093 :::* LISTEN 663/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 663/alertmanager3、prometheus文件配置
修改prometheus主配置文件data/prometheus/prometheus.yml,
[root@zhongjl-test-02 /data/prometheus]# cat /data/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.22.51.65:9093
rule_files:
- "rules/*.yml"
- "rules/target_down.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["10.22.51.65:9090"]
- job_name: 'node'
static_configs:
- targets: ['10.22.51.63:9100', '10.22.51.65:9100', '10.22.51.66:9100', '120.78.156.217:9100', '120.78.156.217:8181']
- job_name: 'test_cluster'
file_sd_configs:
- files: ['/data/prometheus/sd_config/*.yml']1.配置说明:
alerting:配置Alertmanager与prometheus通讯
sed -i '
/alerting:/, /static_configs:/c\
alerting:\
alertmanagers:\
- static_configs:\
- targets:\
- 10.22.51.65:9093
' /data/prometheus/prometheus.yml引入告警规则文件
在prometheus配置文件中创建告警规则,编辑文件vim /data/prometheus/prometheus.yml,新增内容:
rule_files:
- "rules/*.yml"
- "rules/target_down.yml"创建一个job
- job_name: 'test_cluster' # 创建一个job
file_sd_configs: # 此job基于文件动态添加node
- files: ['/usr/local/prometheus/sd_config/*.yml'] # 动态添加node的文件路径
refresh_interval: 5s # 隔 5s检查一次文件是否有新增或删除4、Job节点配置与测试
1.job节点配置
[root@zhongjl-test-02 /data/prometheus]# cat sd_config/node.yml
- targets: ['10.22.51.66:9100']
#labels: # 可以设置标签
# name: docker
- targets: ['10.22.51.63:9100']
- targets: ['10.22.51.65:9090']
#labels:
# name: prometheus2.prometheus界面说明
可以在这个界面使用promeSQL查看监控的数据,后面再说。
Status------->Service Discovery 查看发现的被监控端的机器
Status------->Targets 查看被监控的机器的状态
Status------->Rules 查看配置的告警规则
Status------->Configuration 查看prometheus的配置文件
Graph 可以编辑promeSQL,查看收集到的数据,可以做sql调试,也可以用图形化展示;不过图形化展示建议配合grafna做。
Alerts 可以查看告警的状态
3.查看节点
在prometheus的web页面Status----->Service Discovery查看是否发现了配置的node

在Status----->Targets可以查看当前发现的node状态是否是正常的,up为正常

4.查看收集的数据
根据上面Endpoint的连接,在Prometheus上利用sql查看node的CPU的数据node_cpu_seconds_total
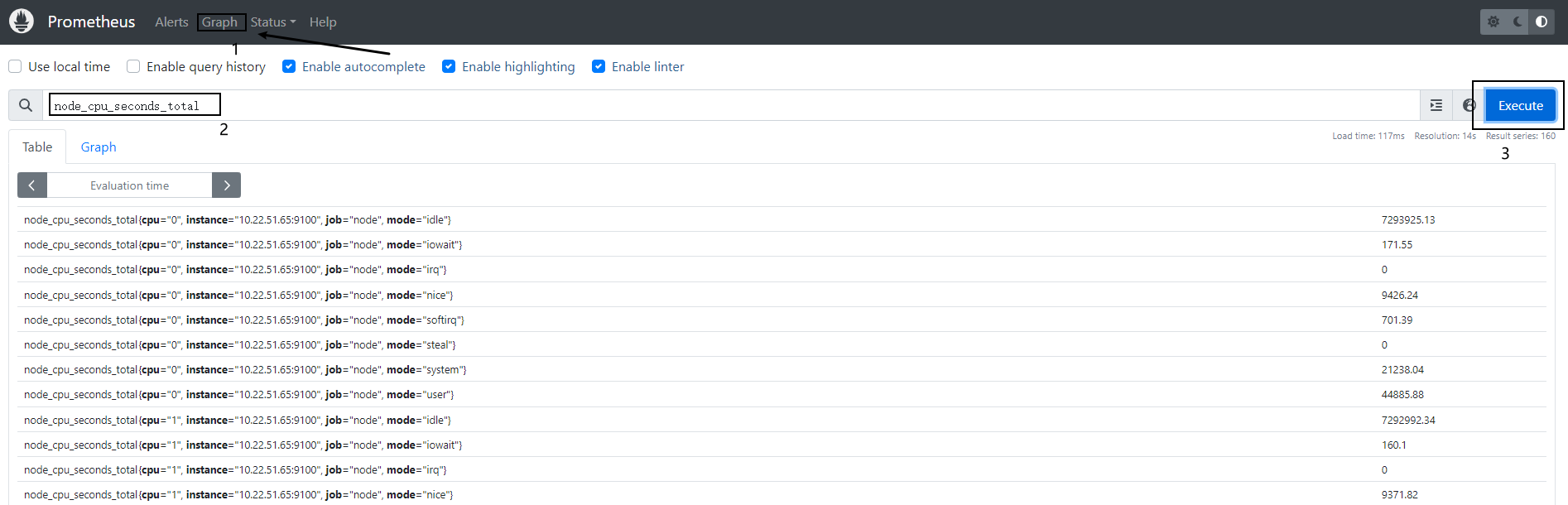
5、告警测试
1.创建告警规则存放文件
mkdir -p /data/prometheus/rules
#创建规则文件,名称自定义
vim /data/prometheus/rules/systemd.ymlsystemd.yml配置内容:
groups:
- name: docker
rules:
- alert: docker_systemd_down # 告警聚合的名称依据
expr: node_systemd_unit_state{name="docker.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难 # 告警级别
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"
- alert: sshd_systemd_down
expr: node_systemd_unit_state{name="sshd.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"
- alert: nginx_systemd_down
expr: node_systemd_unit_state{name="nginx.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"2.告警规则配置说明
docker服务停止告警
groups:
- name: docker
rules:
- alert: docker_systemd_down # 告警聚合的名称依据
expr: node_systemd_unit_state{name="docker.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难 # 告警级别
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"ssh服务停止告警
- alert: sshd_systemd_down
expr: node_systemd_unit_state{name="sshd.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"nginx服务停止告警
- alert: nginx_systemd_down
expr: node_systemd_unit_state{name="nginx.service", state="inactive", type="notify"} == 1
for: 1m
labels:
severity: 灾难
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.instance }}的{{ $labels.name }} 已经停止1分钟以上"2.编辑altermanager配置文件
cat /data/prometheus/prometheus.yml
global: # 全局的配置
resolve_timeout: 5m # 解析的超时时间
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '980521387@qq.com'
smtp_auth_username: '980521387@qq.com'
smtp_auth_password: 'kparebywhhvubced'
smtp_require_tls: false
route: # 将告警具体怎么发送
group_by: ['alertname'] # 根据标签进行分组
group_wait: 10s # 发送告警等待时间
group_interval: 10s # 发送告警邮件的间隔时间
repeat_interval: 1h # 重复的告警发送时间
receiver: 'email' # 接收者是谁
receivers: # 将告警发送给谁
- name: 'email'
email_configs:
- to: 'zhongjinlin31314@sunline.cn'
inhibit_rules: # 抑制告警
- source_match:
severity: 'critical' # 当收到同一台机器发送的critical时候,屏蔽掉warning类型的告警
target_match:
severity: 'warning'
equal: ['alertname', 'severity', 'instance'] # 根据这些标签来定义抑制3.验证altermanager配置文件
检查altermanager和Prometheus的配置文件,看看是否有报错,是否有发现规则
#检查altermanager配置文件
[root@zhongjl-test-02 /data/alertmanager]# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 1 inhibit rules
- 1 receivers
- 0 templates
#检查Prometheus的配置文件
[root@zhongjl-test-02 /data/alertmanager]# cd /data/prometheus/
[root@zhongjl-test-02 /data/prometheus]# ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 3 rule files found
SUCCESS: prometheus.yml is valid prometheus config file syntax
Checking rules/systemd.yml
SUCCESS: 3 rules found
Checking rules/target_down.yml
SUCCESS: 1 rules found
Checking rules/target_down.yml
SUCCESS: 1 rules found没有报错,并且发现了报警规则,可以重启prometheus和altermanager服务
systemctl restart prometheus.service alertmanager.service4.登陆web验证
登陆prometheus的web页面--点击Alerts,查看是否有规则等
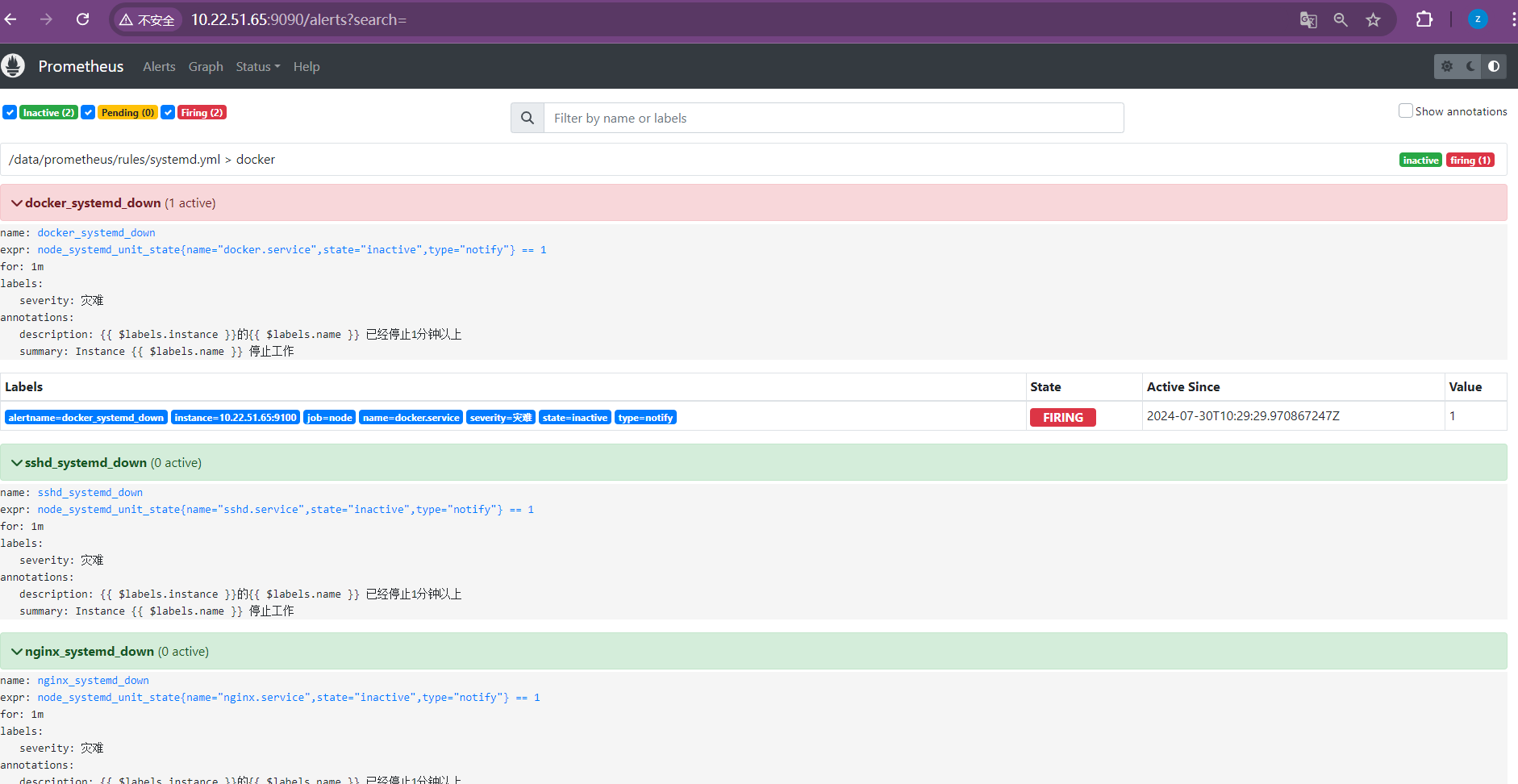
点击Status--再点击Rules
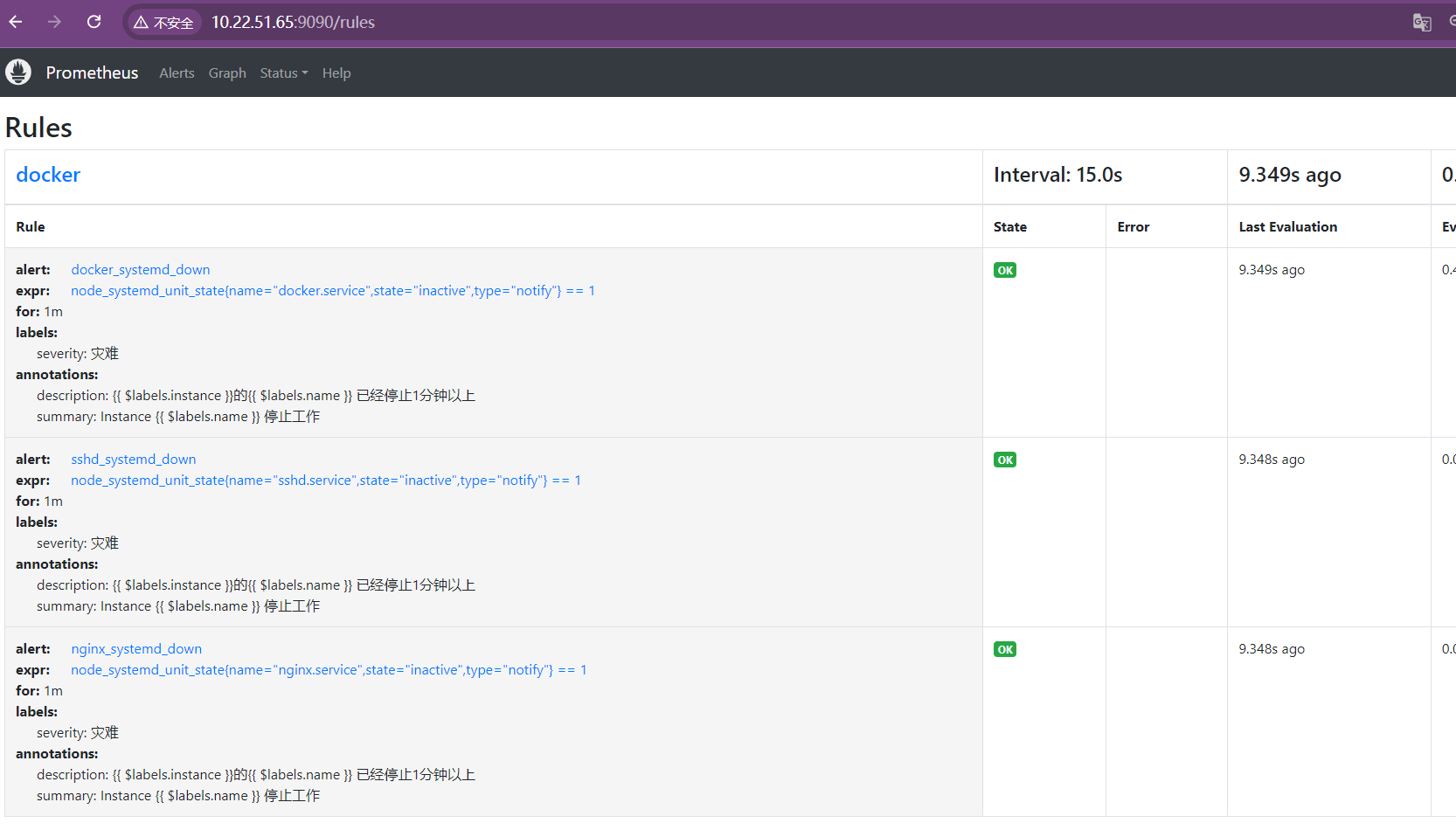
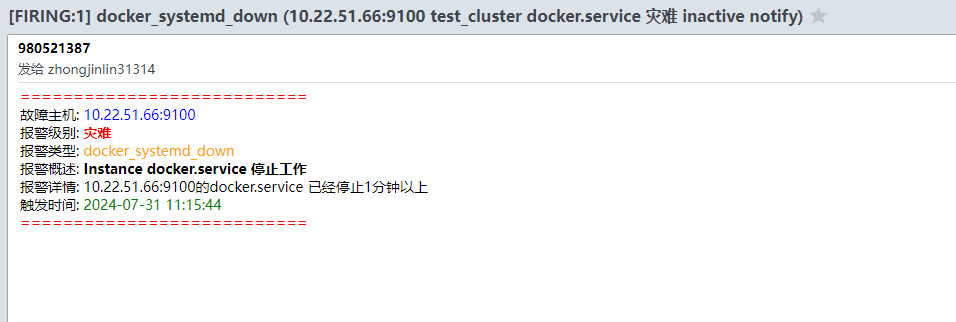
5.docker告警测试
停止docker,进行邮件报警测试
systemctl stop docker.socket
systemctl stop docker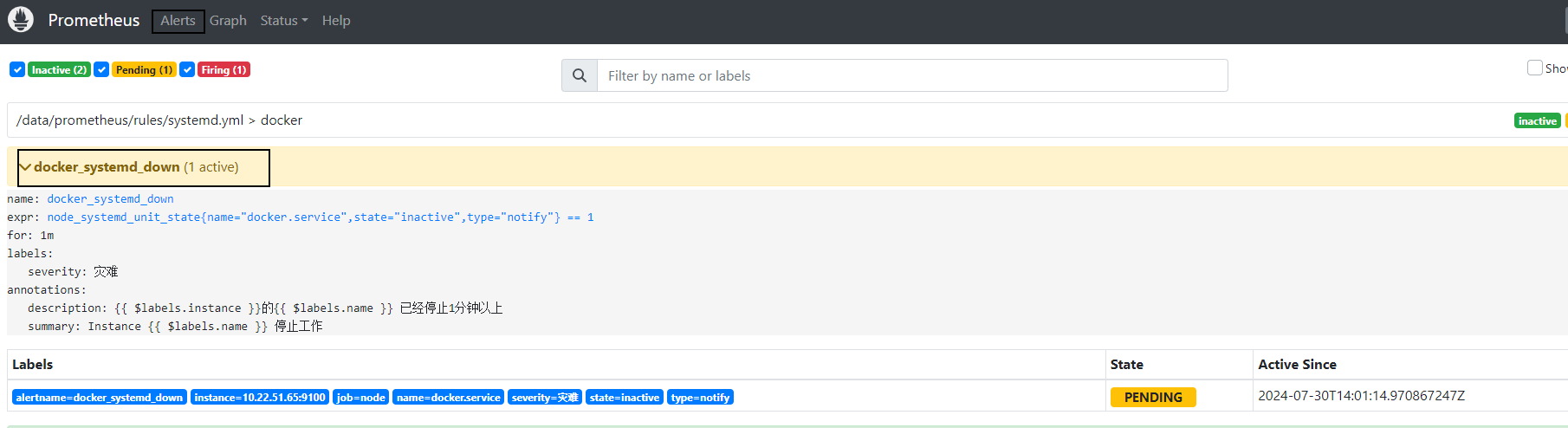
停止docker服务后,不会立即发送报警邮件,可以看到当前的状态已经是PENDING,这个时候altermanager已经收到prometheus的报告,说明docker服务已经挂掉了,等待状态变为FIRING的时候,才会发送邮件。
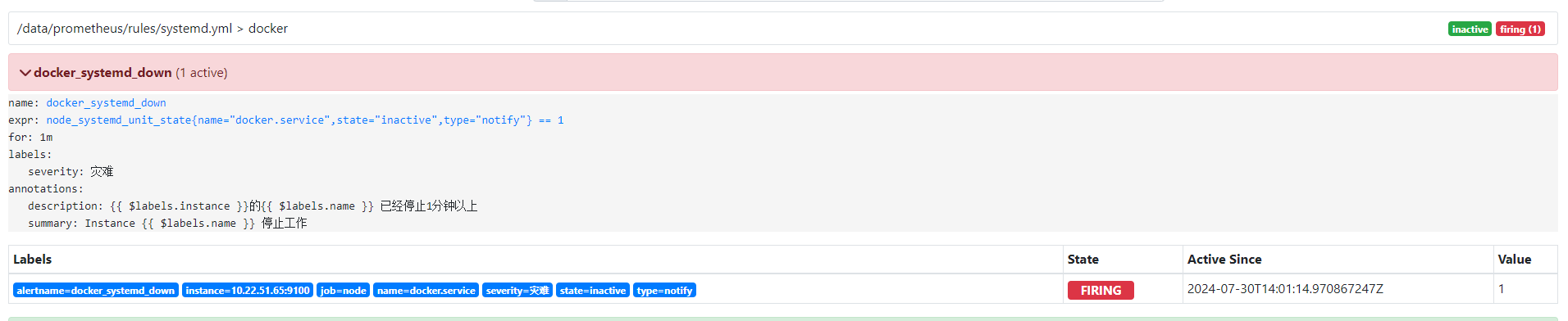
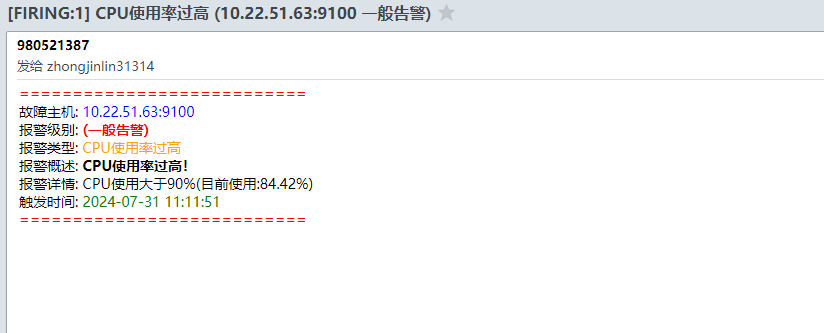
6.邮件截图
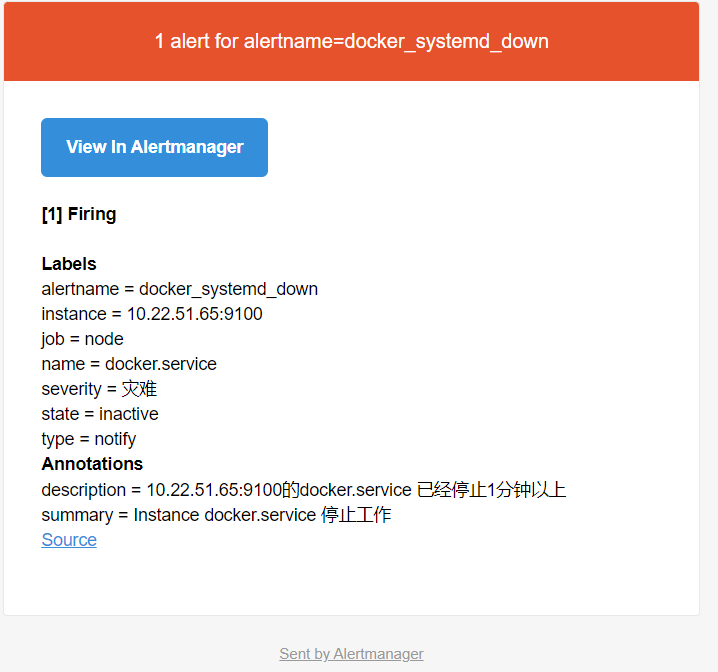
如需配置多台告警,需保证以下条件:
-
检查其他节点上的
node_exporter配置,确保node_exporter服务文件中包含--collector.systemd参数。(参考步骤:7.无法发送消息处理) -
确保prometheus配置包含node节点,如:
- job_name: 'node' static_configs: - targets: ['10.22.51.63:9100', '10.22.51.65:9100', '10.22.51.66:9100']
在 Prometheus Web 界面(通常是 http://<prometheus_host>:9090)中,执行以下 PromQL 查询,确认可以抓取到所有节点上的 node_systemd_unit_state 指标:
node_systemd_unit_state{name="docker.service"}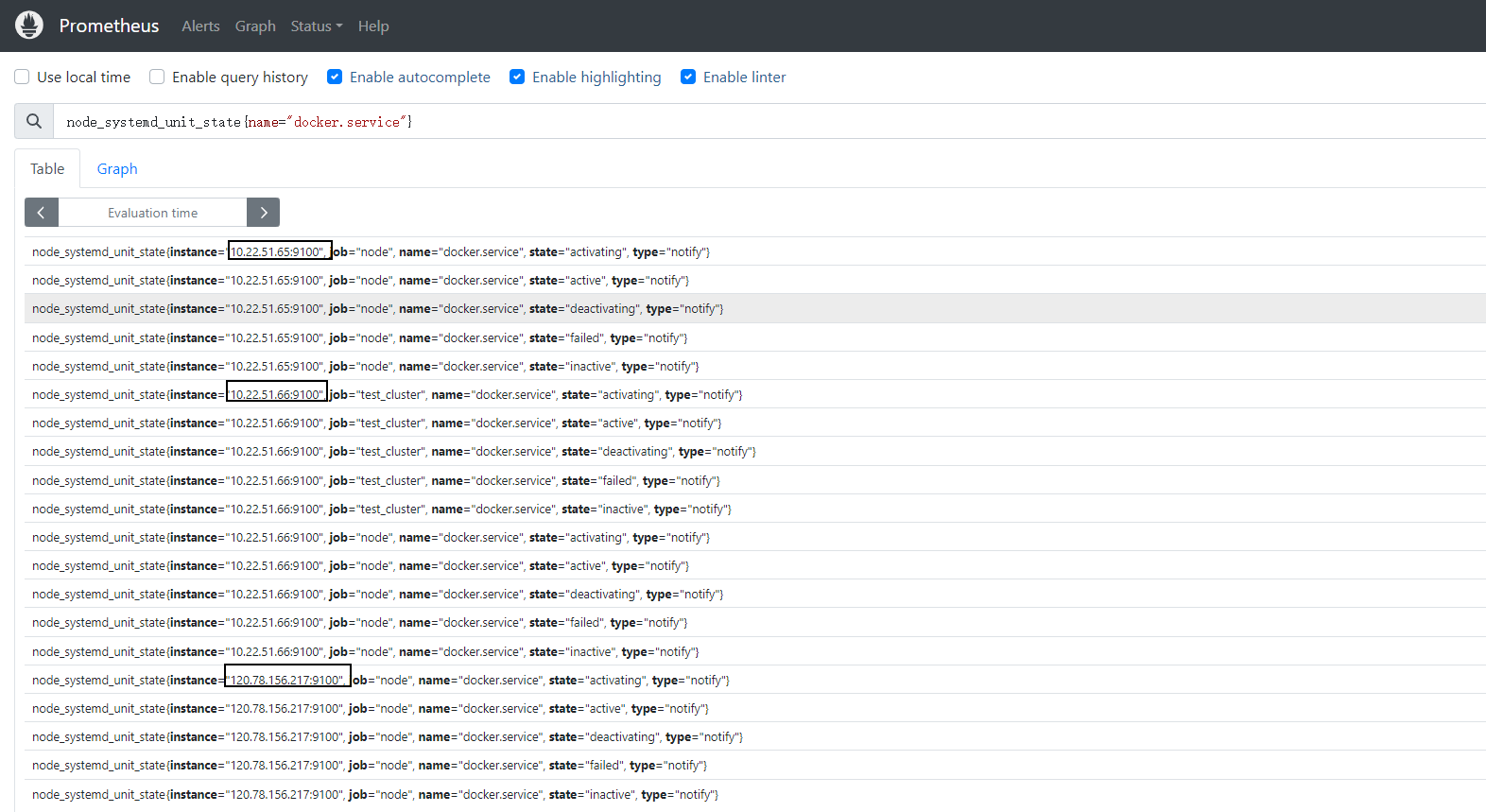
7.无法发送消息处理
如停止后,无法发送消息,确保 node_exporter 启动时包含了 systemd 采集器。如果 node_exporter 没有正确配置为采集 systemd 状态,Prometheus 将无法获取 Docker 服务状态。
修改vim /usr/lib/systemd/system/node_exporter.service,在 [Service] 部分添加 --collector.systemd 参数,然后,重新加载 systemd 配置并重启 node_exporter 服务::
ExecStart=/data/node_exporter/node_exporter --collector.systemd
systemctl daemon-reload
systemctl restart node_exporter访问 Prometheus Web 界面,通常是 http://<prometheus_host>:9090。在查询栏输入以下查询:
node_systemd_unit_state{name="docker.service"}查看返回的结果,确认是否有 inactive 的状态数据。
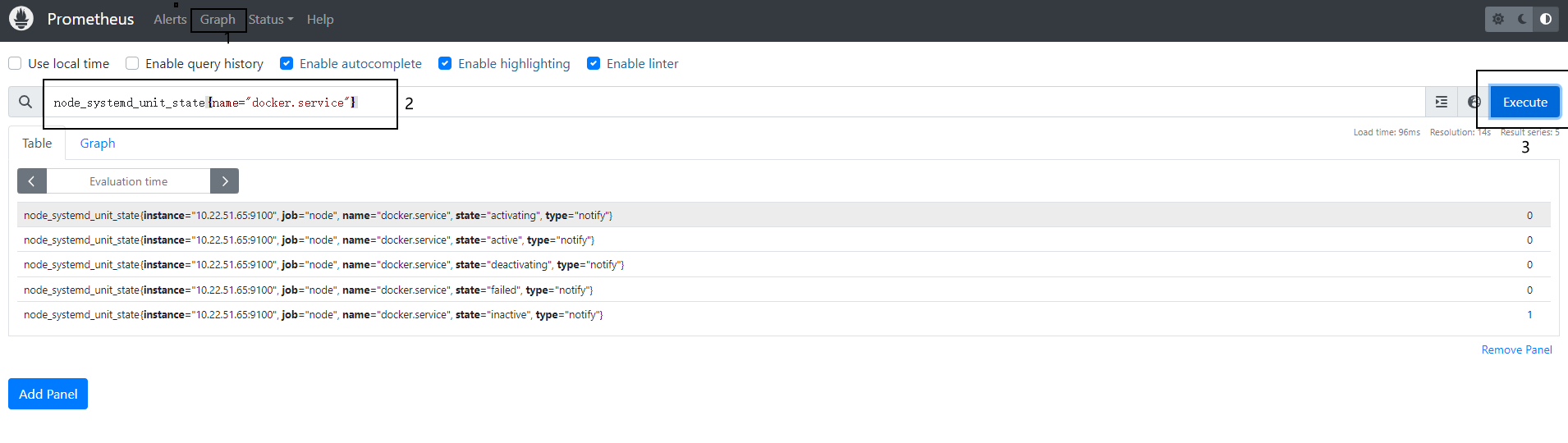
6、采集失败告警
这条规则针对目标服务器宕机,网络连接问题,Node Exporter 服务未运行等问题。
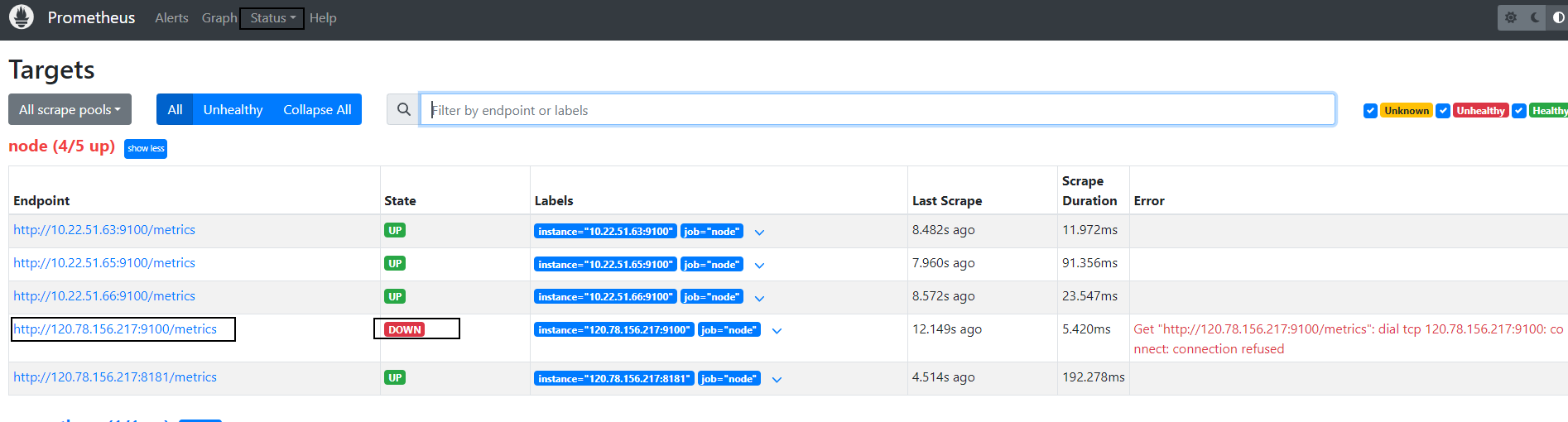
1.告警规则说明
当Prometheus 无法抓取目标 http://120.78.156.217:9100/metrics 的指标,并显示了 "connection refused" 错误。如图:
2.创建告警规则文件
1.首先,在 rules 目录下创建一个新的规则文件,比如 vim /data/prometheus/rules/target_down.yml:
groups:
- name: target_down
rules:
- alert: TargetDown
expr: up == 0
for: 1m
labels:
severity: 灾难
annotations:
summary: "抓取目标 {{ $labels.instance }} 下线"
description: "Prometheus 无法抓取目标 {{ $labels.instance }},状态为 DOWN 超过 1 分钟。"在 prometheus.yml 中添加这个规则文件:
rule_files:
- "rules/*.yml"
- "rules/target_down.yml"保存并重启 Prometheus 以应用新的配置
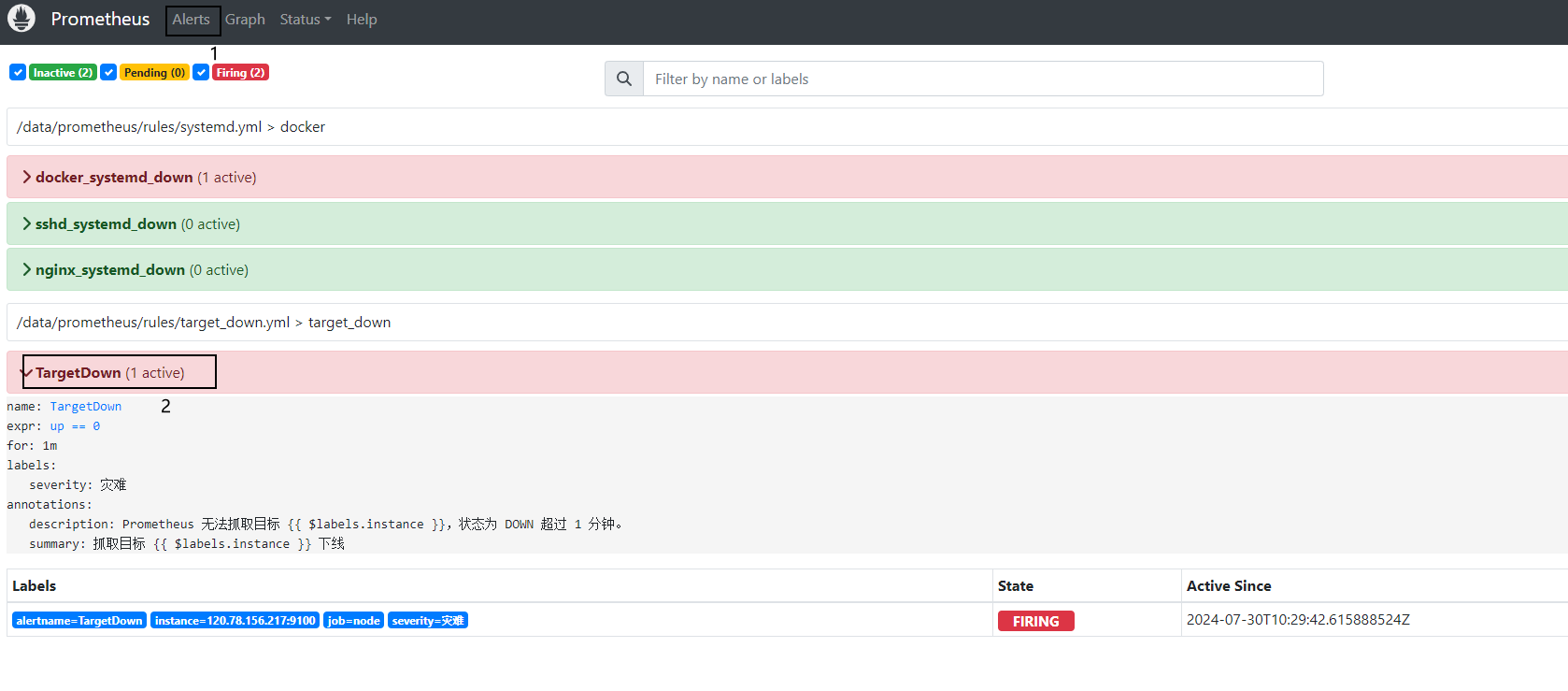
3.验证告警规则
通过 Prometheus 的 Web 界面 http://<prometheus_host>:9090 查看新的告警规则是否加载正确。
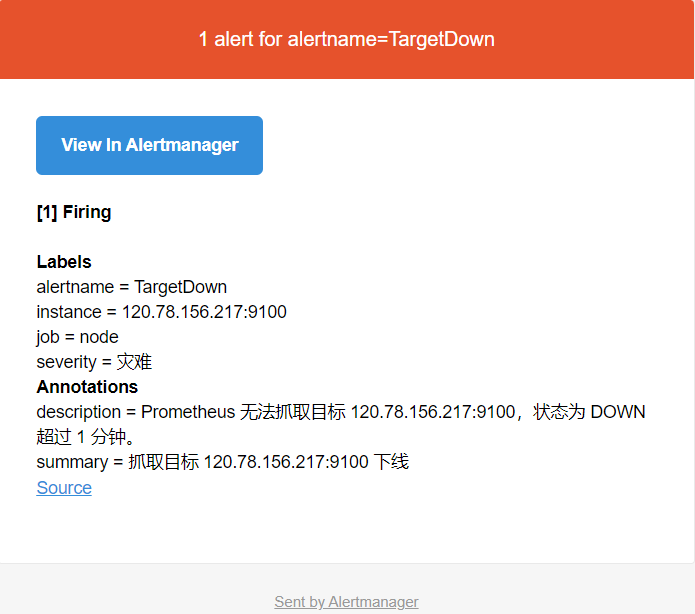
登陆120.78.156.217服务器,手动停止Node-exporter,确认当 http://120.78.156.217:9100/metrics 无法访问时,新的告警会被触发。
8、引入告警模板
mkdir -p /data/alertmanager/templates
#{{ define "email.from" }}xxxx@163.com{{ end }}
#{{ define "email.to" }}xxxx@163.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
<span style="color:red; font-weight:bold;">===========================</span><br>
故障主机: <span style="color:blue;">{{ .Labels.instance }}</span> <br>
报警级别: <span style="color:red; font-weight:bold;">{{ .Labels.severity }} {{ if .Labels.status }} ({{ .Labels.status }}) {{ end }}</span> <br>
报警类型: <span style="color:orange;">{{ .Labels.alertname }}</span> <br>
报警概述: <span style="font-weight:bold;">{{ .Annotations.summary }}</span> <br>
报警详情: {{ .Annotations.description }} <br>
触发时间: <span style="color:green;">{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</span> <br>
<span style="color:red; font-weight:bold;">===========================</span><br>
{{ end }}
{{ end }}修改alertmanager.yml,增加
html: '{{ template "email.to.html" . }}'
templates:
- '/data/alertmanager/templates/emails.tmpl'完整配置如下:
global: # 全局的配置
resolve_timeout: 5m # 解析的超时时间
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '980521387@qq.com'
smtp_auth_username: '980521387@qq.com'
smtp_auth_password: 'kparebywhhvubced'
smtp_require_tls: false
route: # 将告警具体怎么发送
group_by: ['alertname'] # 根据标签进行分组
group_wait: 10s # 发送告警等待时间
group_interval: 10s # 发送告警邮件的间隔时间
repeat_interval: 1h # 重复的告警发送时间
receiver: 'email' # 接收者是谁
receivers: # 将告警发送给谁
- name: 'email'
email_configs:
- to: 'zhongjinlin31314@sunline.cn'
html: '{{ template "email.to.html" . }}'
templates:
- '/data/alertmanager/templates/emails.tmpl'
inhibit_rules: # 抑制告警
- source_match:
severity: 'critical' # 当收到同一台机器发送的critical时候,屏蔽掉warning类型的告警
target_match:
severity: 'warning'
equal: ['alertname', 'severity', 'instance', 'status'] # 根据这些标签来定义抑制9、模拟测试
找台监控的服务器,多开终端,执行命令
cat /dev/urandom | md5sum显示效果