摘要
**目的:**开发一种基于自监督学习方法的高维MRI数据去噪框架,该框架无需基准真值。
**方法:**定量MRI面临着信噪比(SNR)的限制,而且复杂的非线性信号模型使得拟合过程容易受到噪声的影响。为了解决这些问题,本研究提出了一种快速的深度学习框架,该框架有效地利用了多维MRI数据中的冗余信息。本研究设计了一个自监督模型,仅使用噪声图像进行训练,从而避开了临床实践中缺乏干净数据的挑战。本研究使用了两个不同的数据集,即模拟磁化传递对比MR指纹(MTC-MRF)数据集和体内DWI图像数据集来验证模型的泛化能力。
**结果:**与之前的BM3D、tMPPCA和Patch2self方法相比,本文提出的方法显著提高了在轻度至重度噪声存在情况下的去噪性能,无论噪声分布如何。在经过去噪处理的图像中,后续的量化结果显示出明显的改善。
**结论:**MD-S2S(Multidimensional-Self2Self)去噪技术可以进一步应用于各种多维MRI数据,并提高组织参数图的量化精度。
引言
磁共振成像(MRI)是一种广泛应用于临床诊断和医学研究的非侵入性技术。图像的质量对于准确诊断和分析起着重要的作用。然而,图像质量可能会受到多种噪声源的影响,例如各种生理过程、涡流、运动、热噪声等。在许多分析任务中,识别和降低噪声对于清晰地区分病理症状和减少诊断错误至关重要。
定量MRI方法更容易受到噪声的影响,该方法将采集到的一组不同衰减程度的图像与多个组织和扫描参数的MR信号模型进行拟合。由于多个参数紧密交织,因而信号的微小变化可能导会致参数量化结果发生较大的变化。同样,对于扩散MRI技术,高b值图像中的噪声可能会造成对扩散系数的低估,DWI图像中的噪声会使扩散特性的表征复杂化。虽然基于深度学习的量化方法本身可以从卷积神经网络的特性中获益,但如果输入图像中存在较大的噪声且未经校正,将会影响组织的量化分析。因此,噪声抑制对于准确估计组织参数非常重要。
去噪方法可以显著减少组织参数量化中的噪声问题。目前广泛使用的几种降噪方法包括非局部均值滤波和主成分分析(PCA)。非局部均值滤波利用MR图像的局部和全局相似性实现稳健的噪声抑制。由于MRI信号可以很好地用几个主成分表示,基于PCA的方法成功地降低了热噪声。然而,深度学习方法在去噪性能和重建时间方面的表现均优于传统方法。
尽管监督式去噪方法取得了成功,但临床实践中干净数据的匮乏限制了该方法的临床实用性。虽然可以通过增加信号来获得干净的MRI图像,但这会延长成像采集时间。在这种情况下,可能会诱发患者的运动伪影,进而降低图像质量。因此,无需干净数据的去噪技术显得更为可取。最近的研究提出了使用自监督框架来更好地利用噪声图像本身的信息。尤其是,Self2Self模型使用单个噪声图像的子集作为网络的输入和输出,这是临床应用中非常理想的训练方案。尽管Patch2Self技术在医学图像去噪中采用了自监督学习,但使用一个简单的回归模型对来自不同扫描的同一位置的多个像素值进行单像素预测,这与使用基于卷积神经网络的模型相比仍有改进的空间。
受Self2Self的启发,本研究提出了多维Self2Self(MD-S2S)方法,该方法利用多维MRI数据中的相干信息。特别是,定量MRI方法需要从单个时间层进行多次采集以拟合信号模型。因此,来自同一层的多个图像具有相似的背景,从而导致信息冗余。鉴于每次扫描的噪声是独立的,具有相似图像背景的多次扫描将有助于恢复出清晰的图像。本研究进一步扩展了针对单个图像进行优化的Self2Self框架,以利用MRI数据的可重复性来处理测试阶段的未知数据。
方法
自监督学习框架
多维Self2Self(MD-S2S)通过使用同一组噪声图像的两个互补子集来训练神经网络,从而减轻了对干净数据的需求。如图1所示,输入(

)是噪声图像(X)和掩模(M)的逐元素乘积。掩模的每个像素都是从伯努利分布中独立采样的(本研究排除像素的概率为p=0.3)。另一方面,目标(
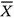
)是噪声图像(X)和互补掩模(1−M)的逐元素乘积。因此,用于网络训练的图像对(
,X)可以描述为:
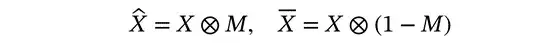
其中,⊗表示逐元素乘法。输入和目标图像分别从同一噪声图像中提取。这使得卷积神经网络(f)具有J不变性,其中输入(
)和目标输出(
)是独立的,因此可以通过最小化自监督损失(E||f(
)−X||)间接地最小化监督损失(E||f(
)−Y||)。因此,在没有真实值(Y)的情况下训练MD-S2S网络,目标函数可以表示为:
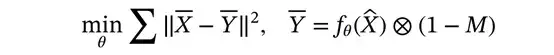
其中,
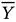
是网络生成的带有互补掩模的输出图像, 表示网络f 的参数。本研究使用ResNet,在每个Resblock的卷积层之间添加一个dropout层,并在网络的末端添加一个额外的1×1卷积层,如图1所示。请注意,只有被互补掩模(1−M)掩码的像素用于计算损失。
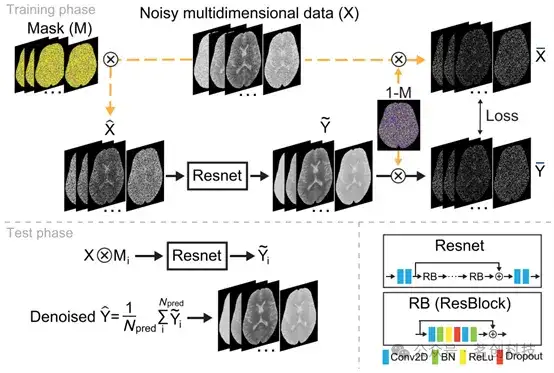
图1.多维Self2Self(MD-S2S)框架示意图。
在测试阶段,dropout层保持与训练阶段相同的活跃状态,这种做法可以提供一种类似自举聚合效应的方式来减少模型预测的方差。此外,对掩模(Mi)进行Npred次独立采样,并输入到网络中,从而获得Npred组去噪图像。如果恢复图像中仍然存在噪声,则可以通过对其进行平均来进一步抑制噪声。因此,最终的去噪图像(
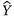
)如下:
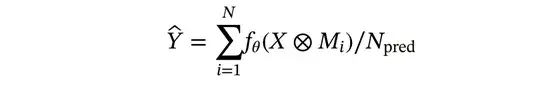
该网络是在GeForce RTX 3090(Santa Clara,CA)上使用Pytorch实现的。使用自适应矩估计(ADAM)优化器对网络进行了30000个epochs的训练。MTC-MRF数据集的初始学习率和批大小分别为10-4和1;DWI数据集的初始学习率为10-5,批大小为3。此外,数据增强方案包括在每个epoch中对输入图像进行水平、垂直和对角翻转,并随机应用增强。训练时间为3.5h,DWI图像为128×128×10(b值)×5(层)。相关代码可在以下网址获取:https://github.com/B9Kang/Multidimensional-Self2Self-MD-S2S.git。
数字化体模研究:MTC-MRF
通过改进的基于Brainweb的数字体模对所提方法进行验证。根据先前的研究,分别对灰质(GM)、白质(WM)和脑脊液(CSF)进行四种组织参数(kmw、Mom、T2m和T1w)赋值。通过双池Bloch方程,使用四幅清晰的组织参数图生成合成的MTC-MRF图像。采用LOAS法优化MRF采集方案。为了训练MD-S2S网络,使用来自10个数字脑体模的130层图像进行训练,并使用来自两个数字体模的26层图像进行测试。
通过两种类型的数字体模研究来评估去噪性能及其对量化精度的影响。在第一个数字体模研究中,合成的MTC-MRF图像包含加性高斯白噪声(AWGN)和Rician噪声(σ(SD)=0.1、0.06和0.03)。同时对噪声水平为λ(预期发生率)=108、109和1010的泊松噪声分布进行检验。然后使用带噪声的MTC-MRF图像来评估MD-S2S方法的有效性。对相同图像应用块匹配和3D滤波(BM3D)、张量Marchenko-Pastur主成分分析(tMPPCA)以及Patch2Self方法进行比较研究。对于Patch2Self方法,本研究采用了四层64通道的多层感知器(MLP)在数字体模和在体研究中建立回归模型。需要注意的是,BM3D对噪声水平是非盲的,并假定噪声服从高斯分布;因此,假设Rician噪声具有相同的噪声水平。此外,Patch2Self无法执行基于单个图像的去噪,因此相关结果被排除在外。此外,还对训练模型在各种噪声分布和水平上进行了测试,以评估对数据分布变化的稳健性,即使用单一高斯噪声水平(σ=0.03)训练的MD-S2S模型在不同噪声水平(σ=0.06和0.1)下进行测试,并且使用高斯噪声分布训练的模型应用于Rician和泊松噪声分布。此外,还进行了MTC定量分析,以评估各种噪声分布对组织参数估计的影响。采用基于递归神经网络的MTC量化方法进行定量分析。从干净的MTC-MRF图像中估计组织参数图。训练数据集的参数取值范围为kmw(5-100Hz)、Mom(2%-17%)、T2m(1-100μs)、T1w(0.2-3.0s)和T1w/T2w(1-30)。
在第二个体模研究中,通过减少MTC-MRF扫描的数量(#1,#3,#5,#10,#20,#30和#40)来评估MD-S2S的去噪性能。此外,还评估了高斯噪声(σ=0.1、0.06和0.03)和Rician噪声(σ=0.1、0.06和0.03)的三种不同噪声水平。使用MATLAB(MathWorks,Natick,MA)在64位Windows操作系统上进行Bloch模拟。
DWI测量
使用带有32通道头线圈的3T磁共振扫描仪(Verio,Siemens Healthcare,Erlangen,Germany)对十名健康被试进行扫描。使用二次相位重聚焦EPI序列采集DWI图像,参数如下:TR=3300ms,TE=107ms,层数=5,平均采集次数=1,FOV=230×230mm,矩阵大小=128×128,衰减因子=5/8,层厚=1.8mm,像素带宽=1502Hz/像素。为获得清晰的DWI图像,对同一组单个被试的DWI图像进行15次重复采集并取平均值。b值分别为0、20、60、100、200、400、600、1000、1500和2000s/mm2。加速度因子为2。对于MD-S2S数据集,使用九名被试的数据(45个时间层)进行训练,一名被试的数据(5个时间层)用于测试。
通过计算去噪后DWI图像与未去噪DWI参考图像的PSNR,比较MD-S2S方法与BM3D、tMPPCA、Patch2self方法的效能。此外,采用IVIM-DKI定量方法来测量噪声对组织定量的影响。组织参数范围为f(0-0.4),D(3-100μm2/ms),Dp(3-50μm2/ms),以及K(0-4)。通过计算平均绝对误差(MAE),将从去噪DWI图像估计的IVIM-DKI定量图与参考图像进行比较。
结果
数字化体模研究:MTC-MRF
利用改进的Brainweb数字体模和双池Bloch方程评估MD-S2S去噪方法的性能。如图2所示,本研究方法成功地从受不同水平高斯噪声(σ=0.1、0.06和0.03)影响的嘈杂图像中去除了噪声。然而,BM3D和tMPPCA方法不能完全去噪嘈杂图像,在真实值图像与去噪图像之间的差异图中显示出高残差信号。在第三次扫描和不同噪声分布(高斯和Rician噪声分布σ=0.1、0.06和0.03;泊松噪声分布λ=108、109和1010)条件下,含噪输入图像与使用BM3D、tMPPCA、Patch2self和MD-S2S方法去噪后图像的峰值信噪比(PSNR)如表1所示。本文提出的方法在不同噪声分布和噪声水平下的表现均优于其他方法。MD-S2S对于超出分布(OOD)数据集在噪声分布和噪声水平方面具有较好的鲁棒性。此外,使用基于深度学习的MTC量化方法,对去噪后的图像进行定量水和MTC图估计。如图3所示,嘈杂的MTC-MRF图像不足以准确量化水和MTC图。此外,BM3D和tMPPCA去噪后的MTC-MRF图像难以准确估计组织参数图,尤其是半固态大分子的交换速率和T2弛豫时间。虽然Patch2self相比前两种方法能更准确地估算定量参数图,但噪声仍然比较明显。然而,使用本文提出的方法,从去噪MTC-MRF图像中观察到的参考组织参数图和估计图之间具有很好的一致性。
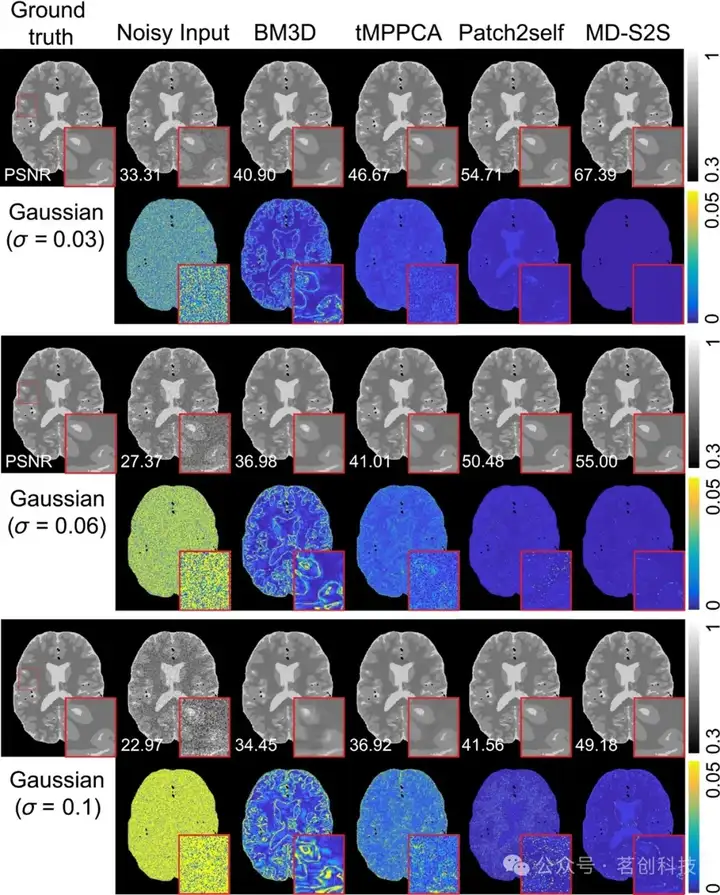
图2.基于Bloch方程的Brainweb数字体模研究,其中添加了不同水平(σ=0.1、0.06和0.03)的高斯噪声。
表1.计算了40个动态扫描图像中第三个动态扫描图像的真实值与各种去噪处理后图像之间的峰值信噪比(PSNR)。
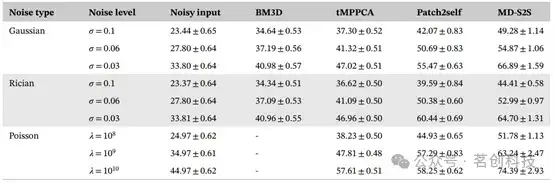
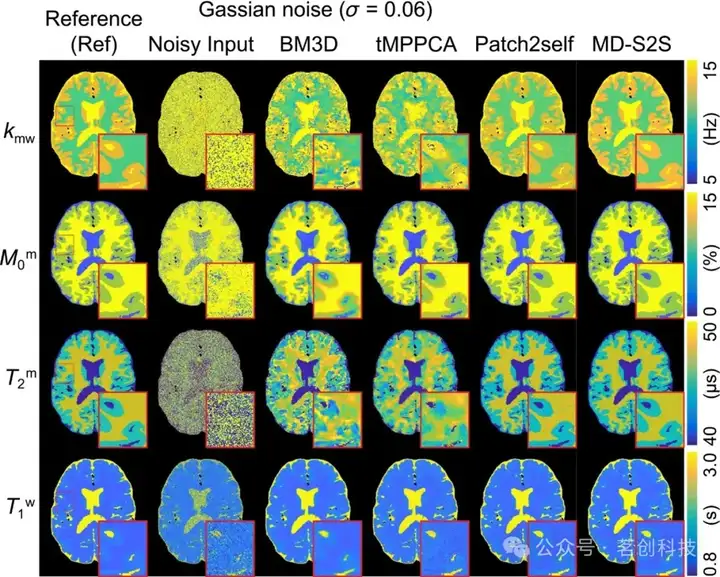
图3.通过基于深度学习的量化方法估计MTC参数图和水的T1图。
为了测量MD-S2S如何有效利用多维数据,本研究评估了在不同数量的MTC-MRF扫描(#1、#3、#5、#10、#20、#30和#40)下的去噪性能。扫描数量的减少会导致PSNR和SSIM值降低,表明多维数据有助于去噪(图4)。去噪图像的放大视图显示,当扫描数量较少时(例如1、3和5个),无法恢复图像中的结构。这种趋势在各种噪声分布和水平下都是一致的(图5)。然而,当扫描数量超过20时,PSNR的改善效果达到饱和。而随着扫描数量的增加,SSIM值达到饱和的速度更快。
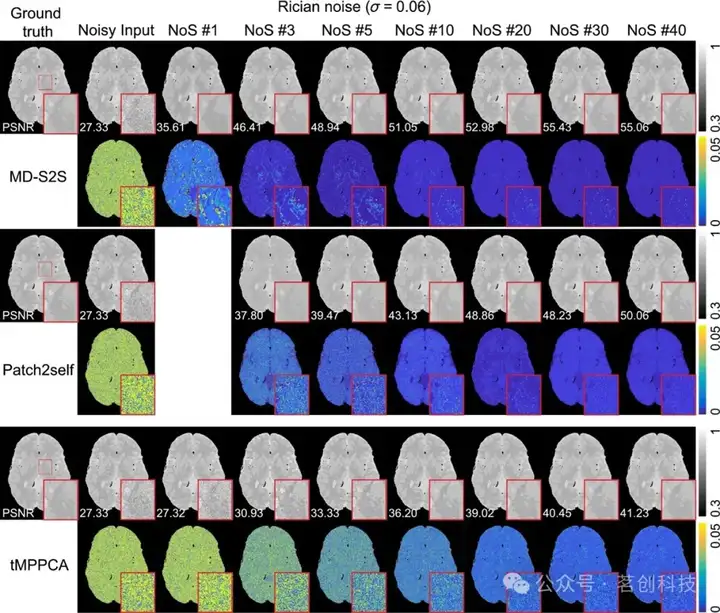
图4.使用tMPPCA、Patch2Self以及MD-S2S方法对不同数量扫描图像进行去噪后的MTC-MRF图像。

图5.tMPPCA、Patch2Self和MD-S2S方法在不同扫描数量(#1、#3、#5、#10、#20、#30和#40)下的去噪性能。
DWI测量
使用噪声DWI图像训练的MD-S2S网络,没有使用干净的参考DWI图像,用于减少健康志愿者的人脑图像中的噪声。通过实验获得10个b值的DWI图像,并使用tMPPCA、Patch2self和MD-S2S方法进行去噪,如图6所示。实验结果表明,使用MD-S2S方法得到的去噪图像与15次重复采集的参考图像具有很好的一致性。b值为100s/mm2时,tMPPCA、Patch2self以及MD-S2S方法的含噪和去噪图像的PSNR值分别为41.40、41.75和42.47dB;当b值为600s/mm2时,分别为37.42、39.50和40.48dB;当b值为2000s/mm2时,分别为33.72、36.14和38.01dB。b值越低,扩散梯度场的信号衰减较小,PSNR越高。但本文方法的SNR改善在b值较高(即b值为2000s/mm2时)的情况下更为显著。
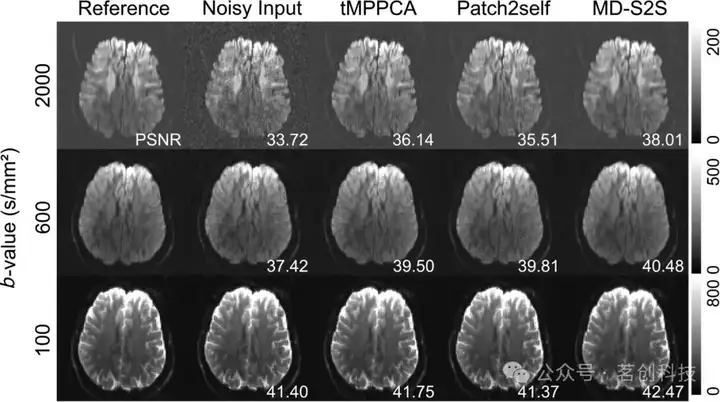
图6.b值为100、600和2000s/mm2时的DWI图像。
此外,对去噪后的图像进行IVIM-DKI定量分析。图7显示了从基于字典的量化方法估计的IVIM-DKI参数图。由于MD-S2S方法在DWI图像中具有最佳的PSNR,因而获得了更好的IVIM-DKI量化结果。从含噪以及经过tMPPCA、Patch2self和MD-S2S去噪后图像估计得到的组织参数图的MAE值分别为:f为0.078、0.067和0.062,D为0.13、0.11和0.10μm2/ms,Dp为12.48、7.84和6.23μm2/ms,K为0.19、0.15和0.14。
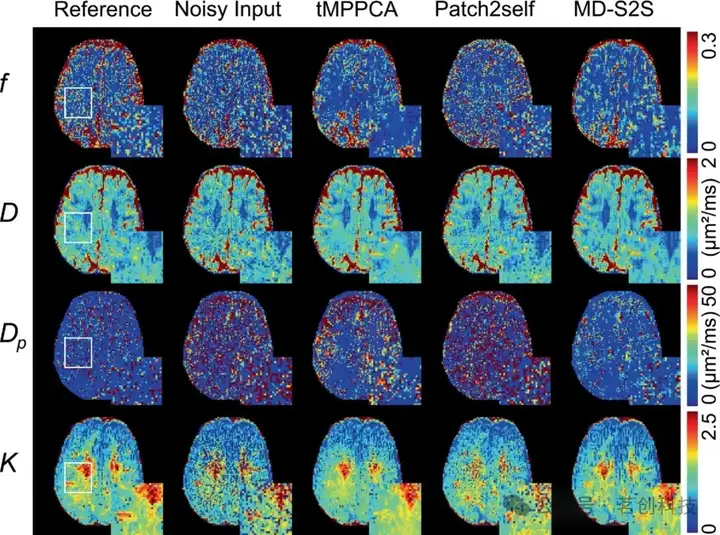
图7.IVIM-DKI定量参数图。
结论
本研究开发了一个快速的深度学习框架,以更好地利用多维MRI数据中的冗余信息进行去噪。此外,自监督网络仅利用噪声数据进行训练,避开了临床实践中缺乏干净数据的挑战。本研究通过模拟MTC-MRF数据集和DWI数据集验证了MD-S2S方法的泛化能力。该方法显著提高了在轻度到重度噪声存在时的去噪性能,因此具有较高的量化精度。MD-S2S去噪技术不仅适用于处理各种多维定量MRI数据,还适用于多对比度MRI数据。
参考文献:Kang B, Lee W, Seo H, Heo H-Y, Park HW. Self-supervised learning for denoising of multidimensional MRI data. Magn Reson Med. 2024;1-15. doi: 10.1002/mrm.30197
小伙伴们关注茗创科技,将第一时间收到精彩内容推送哦~