Eureka架构介绍
Eureka在设计时采用的是AP原则,是Netflix的一个子模块,用于微服务的服务注册与发现
- P:Partition tolerance,网络分区容错。类似多机房部署,保证服务稳定性
- A: Availability,可用性
- C:Consistency ,一致性
对于任意一个系统只能同时满足两个,一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性
- CA 单点集群,满足一致性和可用性,在可扩展性上不太强,关系型数据库
- CP 满足一致性,分区容忍性的系统,通常性能不是特别高,非关系型数据库MongoDB、HBase、Redis等
- AP 满足可用性,分区容忍性的系统,通常对于一致性要求低一些,CouchDB
对于分布式系统中分区容错是必须要具备的,所以只能选择CP和AP
Eureka架构
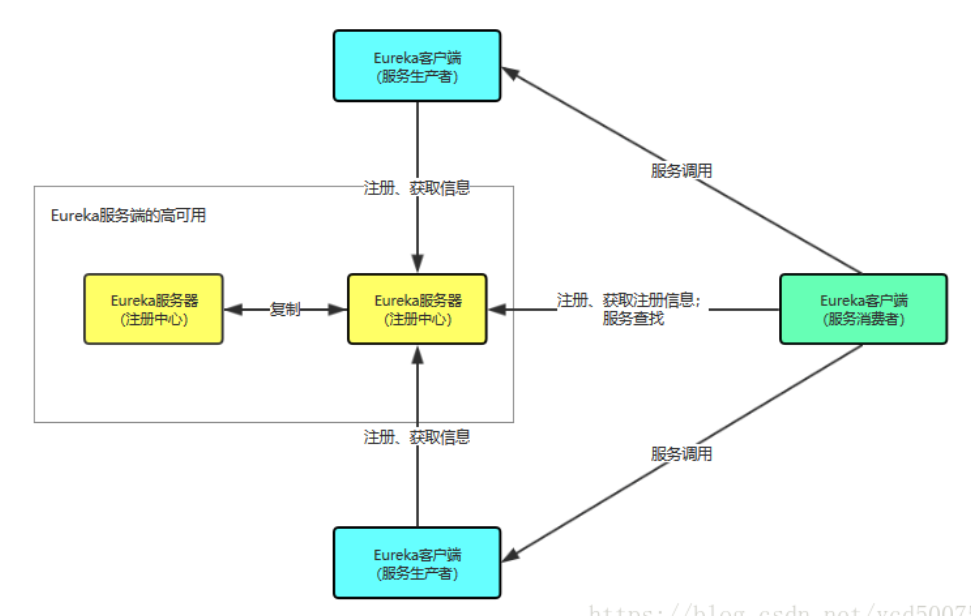
采用C-S架构,Eureka Server作为服务注册的服务器,是服务注册中心
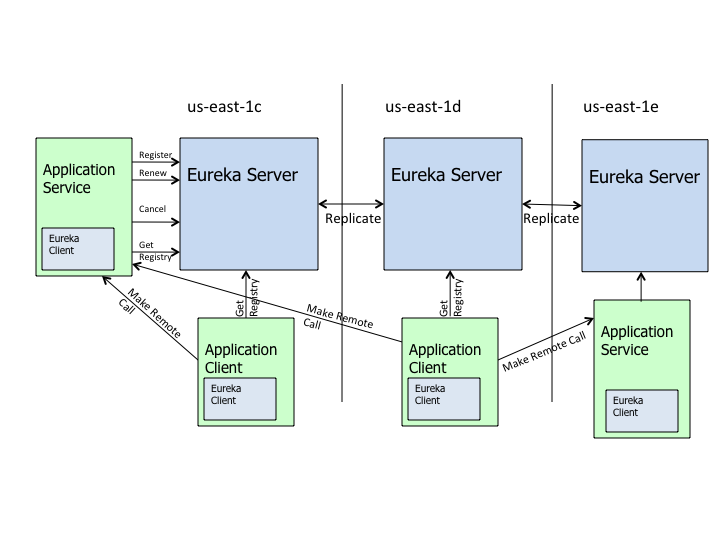
系统中其他的微服务,作为Eureka的客户端连接到Eureka Server并维持心跳,可以通过Eureka Server来监控系统中各个微服务是否正常运行
自我保护机制
在某一时刻某个微服务不可用了,但是eureka不会立刻清理,而是依旧会对该微服务的信息进行保存
默认情况下,如果Eureka Server在一定时间内没有接收到某个微服务实例的心跳,Eureka Server将会注销该实例(默认90s),但是有时可能是由于网络通信问题,微服务和Eureka Server之间无法正常通信,但是此时该微服务实例实际是正常的,所以本不应该注销该实例。Eureka通过自我保护机制来解决该问题,当Eureka Server在短时间内丢失过多客户端的时候,那么该节点就会进入自我保护模式,一旦进入该模式,Eureka Server就会保护服务注册表中的信息,不再删除服务注册表中的数据,当网络故障恢复后(收到的心跳数重新恢复到阈值以上),Eureka Server会自动退出自我保护模式
可以使用
eureka.server.enable-self-preservation=false禁用自我保护模式,可以在本地测试时关闭,在正式上线时不建议关闭
什么情况下会出现自我保护
Renews threshold:server期望在每分钟中收到的心跳次数
Renews (last min):上一分钟内收到的心跳次数
当renews/threshold<0.85时,就会进入自我保护机制
自我保护机制会导致出现的情况
- Eureka Server不会从注册表中移除因为长时间没有收到心跳而过期的服务
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上,保证当前节点依然可用
- 当网络稳定时,当前Eureka Server新的注册信息会被同步到其他节点上
与zookeeper的区别
C(一致性)、A(可用性)和P(分区容错性)
-
eureka是AP原则,而zookeeper是CP原则
zookeeper的CP原则,当master节点因为网络故障与其他节点失去联系时,剩余的节点就会重新进行leader的选举,在选举期间整个zookeeper集群是不可用的,就会导致选举期间注册服务瘫痪(30s~120s)
Eureka的AP原则,Eureka中各个节点是平等的,几个节点挂掉不会影响正常的节点工作,正常的节点依然可以正常提供注册和查询服务,只要有一台Eureka还在,就可以保证注册服务可用,只不过可能查到的信息不是最新的(不保证强一致性),且存在自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,则认为客户端与注册中心之间出现了网络故障,此时会出现以下情况
- Eureka不再从注册表中移除因长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会同步到其他节点上(保证当前节点依旧可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中
https://zhhll.icu/2021/框架/微服务/springcloud/注册中心/Eureka/3.Eureka架构介绍/