首先声明一点,逆向这块我是纯小白,我是通过看各种博客,反复折腾才搞出来的,写的有错误的地方,还请各位大佬多多指正
0 前置条件
确认需要逆向的exe文件是不是通过pyinstaller打包的,如果不是,那么这个方法就是无效的
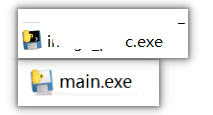
我们可以通过图标来确定,pyinstaller打包的图标一般如下两种
1 需要用到的环境及工具
(1)电脑需要有python环境,我用的是python3.9
(2)pyinstxtractor.py ---- 将.exe解包
官方GitHub地址 https://github.com/countercept/python-exe-unpacker/blob/master/pyinstxtractor.py
(3)uncompyle6 ---- .pyc转.py
# 安装可以加上清华镜像源,自行搜索安装即可
pip install uncompyle6(4)WinHex ---- 16进制编辑(用其他也可以)
2 将exe文件进行解包
将pyinstxtractor.py文件和需要解包的exe文件(我这里叫xxxx.exx)放在同一个目录下,执行如下命令
python pyinstxtractor.py xxxx.exe解包后会生成一个xxxx.exe_extracted文件夹,我们可以通过这个文件夹看到这个exe文件是通过什么版本的python打包的
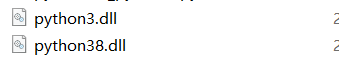
可以看到,我这个exe文件是通过python3.8打包的,但具体是哪个版本的,就无法得知
在xxxx.exe_extracted文件中,我们只需要关注该目录下没有后缀名的文件和PYZ-00.pyz_extracted这个文件夹
没有后缀名的文件,在我这个例子中有两个: 1 和 struct
其中,这个1文件其实就是程序的入口文件,PYZ-00.pyz_extracted文件夹存放主程序的一些依赖库,包括自己写的

PYZ-00.pyz_extracted这个文件夹下的文件大概如下,分两种情况
1 文件都是以pyc结尾的,说明没有加密,我们可以用uncompyle6 将其反编译成.py文件(也就是源码)
2 文件都是以.pyc.encrypted 结尾的,说明经过了加密,感兴趣的可以研究如何解密,我这里就不说明了
3 将pyc文件转为py文件
将pyc文件转为py文件,最重要的是需要补全magic head。想要快速将pyc转为py文件,而不需要补全magic head,请直接看3.3节。
3.1 反编译程序入口文件
上面说过,在我这个例子中,1这个文件就是程序的入口文件,一般来说你的exe文件如果是demo.exe,那么你这个入口文件大概率是demo。
(1)重命名程序入口文件
上面说过1这个文件是没有后缀名的,需要给它加上.pyc的后缀名,变为1.pyc;同理,将struct文件改为struct.pyc
(2)用WinHex打开上面1.pyc 和 struct.pyc,对比字节码的差异,补全magic head
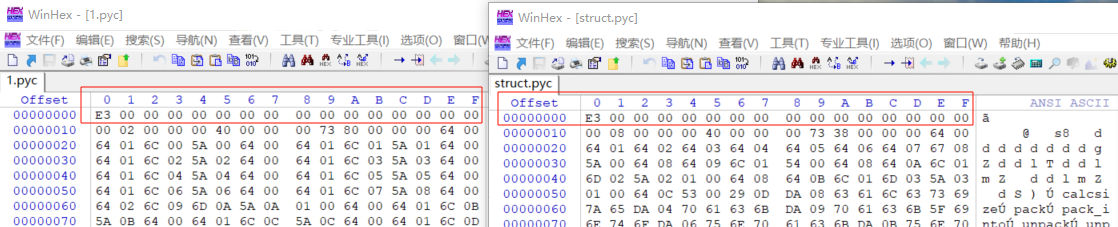
这里我就有点懵,因为我看其它博客struct.pyc文件打开后,第一行并不是E3开头,而是类似下面这种

这里无法根据struct.pyc进行补全,我又搜索其它博客,发现有人和我情况一样,struct.pyc打开直接就是E3开头,可惜没有人回答这个问题
不多说,直接上解决办法:在exe解包的目录下有一个base_library.zip压缩包,打开这个压缩包,随便找一个oyc文件,使用WinHex打开,这里我打开的是base_library中的abc.pyc文件
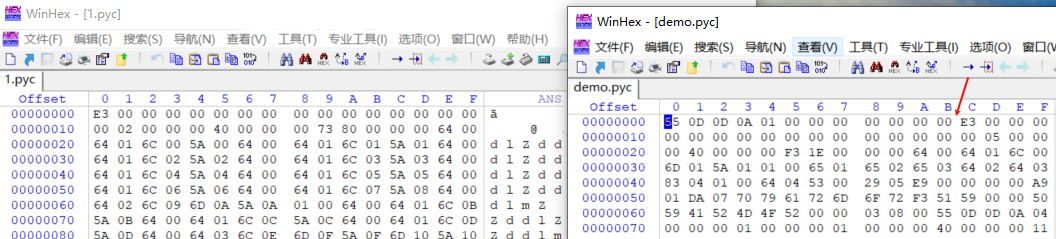
对比两个文件,发现 55 0d 0d 0a 01这第一行的字节码就是我们需要的magic head

我们直接把abc.pyc文件中的第一行复制,添加到1.pyc文件中的第一行

保存,然后用 uncompyle6 反编译
uncompyle6 -o 1.py 1.pyc反编译后,没有报错,并且生成了1.py文件,打开1.pyc文件,能够看到源码,说明magic head是正确的
3.2 反编译依赖库
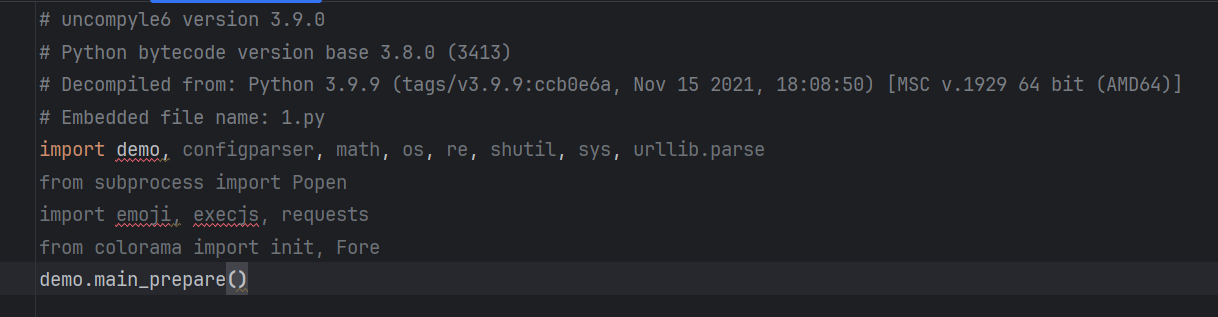
反编译程序入口后,我们可以看到,该程序依赖了一个demo的库,这个库肯定是作者自己写的
依赖的demo库在PYZ-00.pyz_extracted文件夹中可以找到,打开demo.pyc与1.pyc进行对比
这里我们可以发现,依赖库缺失的字节是在中间位置,这里我们看到缺少的是12-15位的四个字节 00 00 00 00
补全缺失的四个字节

保存,然后用 uncompyle6 反编译
uncompyle6 -o demo.py demo.pyc反编译后,没有报错,并且生成了demo.py文件,打开demo.pyc文件,能够看到源码,说明我们补全的字节码是正确的

可以看到,作者这里使用了PyArmor对源码进行了加密处理,这种加密方式目前无解
但如果你发编译的代码没有经过类型的加密,那么你到这一步是可以完全解密出来对应的依赖库,当然,依赖库可能不止一个,但方法都是一样的
3.3 快速补全magic head
上面的3.1和3.2节,均是在教你如何补全通过分析文件来补全magic head,这对新手来说理解起来有些困难并且在操作过程中,如果遇到想我一个struct.pyc文件直接就是E3开头,更是天崩开局,,,,
所谓的快速补全magic head,其实就是使用最新版本的pyinstxtractor.py文件,经过实测,我发现最新版本的pyinstxtractor.py能够直接对程序入口pyc文件和依赖库pyc文件自动补全magic head,着实厉害。
最新的pyinstxtractor.py文件内容,我会贴在下方,避免有些伙伴无法连接GitHub
不用补全magic head后,你就可以直接使用 uncompyle6 反编译,帮助我们节约了不少时间
uncompyle6 -o xxx.py xxx.pyc最新的pyinstxtractor内容如下
"""
PyInstaller Extractor v2.0 (Supports pyinstaller 6.9.0, 6.8.0, 6.7.0, 6.6.0, 6.5.0, 6.4.0, 6.3.0, 6.2.0, 6.1.0, 6.0.0, 5.13.2, 5.13.1, 5.13.0, 5.12.0, 5.11.0, 5.10.1, 5.10.0, 5.9.0, 5.8.0, 5.7.0, 5.6.2, 5.6.1, 5.6, 5.5, 5.4.1, 5.4, 5.3, 5.2, 5.1, 5.0.1, 5.0, 4.10, 4.9, 4.8, 4.7, 4.6, 4.5.1, 4.5, 4.4, 4.3, 4.2, 4.1, 4.0, 3.6, 3.5, 3.4, 3.3, 3.2, 3.1, 3.0, 2.1, 2.0)
Author : Extreme Coders
E-mail : extremecoders(at)hotmail(dot)com
Web : https://0xec.blogspot.com
Date : 26-March-2020
Url : https://github.com/extremecoders-re/pyinstxtractor
For any suggestions, leave a comment on
https://forum.tuts4you.com/topic/34455-pyinstaller-extractor/
This script extracts a pyinstaller generated executable file.
Pyinstaller installation is not needed. The script has it all.
For best results, it is recommended to run this script in the
same version of python as was used to create the executable.
This is just to prevent unmarshalling errors(if any) while
extracting the PYZ archive.
Usage : Just copy this script to the directory where your exe resides
and run the script with the exe file name as a parameter
C:\\path\\to\\exe\\>python pyinstxtractor.py <filename>
$ /path/to/exe/python pyinstxtractor.py <filename>
Licensed under GNU General Public License (GPL) v3.
You are free to modify this source.
CHANGELOG
================================================
Version 1.1 (Jan 28, 2014)
-------------------------------------------------
- First Release
- Supports only pyinstaller 2.0
Version 1.2 (Sept 12, 2015)
-------------------------------------------------
- Added support for pyinstaller 2.1 and 3.0 dev
- Cleaned up code
- Script is now more verbose
- Executable extracted within a dedicated sub-directory
(Support for pyinstaller 3.0 dev is experimental)
Version 1.3 (Dec 12, 2015)
-------------------------------------------------
- Added support for pyinstaller 3.0 final
- Script is compatible with both python 2.x & 3.x (Thanks to Moritz Kroll @ Avira Operations GmbH & Co. KG)
Version 1.4 (Jan 19, 2016)
-------------------------------------------------
- Fixed a bug when writing pyc files >= version 3.3 (Thanks to Daniello Alto: https://github.com/Djamana)
Version 1.5 (March 1, 2016)
-------------------------------------------------
- Added support for pyinstaller 3.1 (Thanks to Berwyn Hoyt for reporting)
Version 1.6 (Sept 5, 2016)
-------------------------------------------------
- Added support for pyinstaller 3.2
- Extractor will use a random name while extracting unnamed files.
- For encrypted pyz archives it will dump the contents as is. Previously, the tool would fail.
Version 1.7 (March 13, 2017)
-------------------------------------------------
- Made the script compatible with python 2.6 (Thanks to Ross for reporting)
Version 1.8 (April 28, 2017)
-------------------------------------------------
- Support for sub-directories in .pyz files (Thanks to Moritz Kroll @ Avira Operations GmbH & Co. KG)
Version 1.9 (November 29, 2017)
-------------------------------------------------
- Added support for pyinstaller 3.3
- Display the scripts which are run at entry (Thanks to Michael Gillespie @ malwarehunterteam for the feature request)
Version 2.0 (March 26, 2020)
-------------------------------------------------
- Project migrated to github
- Supports pyinstaller 3.6
- Added support for Python 3.7, 3.8
- The header of all extracted pyc's are now automatically fixed
"""
from __future__ import print_function
import os
import struct
import marshal
import zlib
import sys
from uuid import uuid4 as uniquename
class CTOCEntry:
def __init__(self, position, cmprsdDataSize, uncmprsdDataSize, cmprsFlag, typeCmprsData, name):
self.position = position
self.cmprsdDataSize = cmprsdDataSize
self.uncmprsdDataSize = uncmprsdDataSize
self.cmprsFlag = cmprsFlag
self.typeCmprsData = typeCmprsData
self.name = name
class PyInstArchive:
PYINST20_COOKIE_SIZE = 24 # For pyinstaller 2.0
PYINST21_COOKIE_SIZE = 24 + 64 # For pyinstaller 2.1+
MAGIC = b'MEI\014\013\012\013\016' # Magic number which identifies pyinstaller
def __init__(self, path):
self.filePath = path
self.pycMagic = b'\0' * 4
self.barePycList = [] # List of pyc's whose headers have to be fixed
def open(self):
try:
self.fPtr = open(self.filePath, 'rb')
self.fileSize = os.stat(self.filePath).st_size
except:
print('[!] Error: Could not open {0}'.format(self.filePath))
return False
return True
def close(self):
try:
self.fPtr.close()
except:
pass
def checkFile(self):
print('[+] Processing {0}'.format(self.filePath))
searchChunkSize = 8192
endPos = self.fileSize
self.cookiePos = -1
if endPos < len(self.MAGIC):
print('[!] Error : File is too short or truncated')
return False
while True:
startPos = endPos - searchChunkSize if endPos >= searchChunkSize else 0
chunkSize = endPos - startPos
if chunkSize < len(self.MAGIC):
break
self.fPtr.seek(startPos, os.SEEK_SET)
data = self.fPtr.read(chunkSize)
offs = data.rfind(self.MAGIC)
if offs != -1:
self.cookiePos = startPos + offs
break
endPos = startPos + len(self.MAGIC) - 1
if startPos == 0:
break
if self.cookiePos == -1:
print('[!] Error : Missing cookie, unsupported pyinstaller version or not a pyinstaller archive')
return False
self.fPtr.seek(self.cookiePos + self.PYINST20_COOKIE_SIZE, os.SEEK_SET)
if b'python' in self.fPtr.read(64).lower():
print('[+] Pyinstaller version: 2.1+')
self.pyinstVer = 21 # pyinstaller 2.1+
else:
self.pyinstVer = 20 # pyinstaller 2.0
print('[+] Pyinstaller version: 2.0')
return True
def getCArchiveInfo(self):
try:
if self.pyinstVer == 20:
self.fPtr.seek(self.cookiePos, os.SEEK_SET)
# Read CArchive cookie
(magic, lengthofPackage, toc, tocLen, pyver) = \
struct.unpack('!8siiii', self.fPtr.read(self.PYINST20_COOKIE_SIZE))
elif self.pyinstVer == 21:
self.fPtr.seek(self.cookiePos, os.SEEK_SET)
# Read CArchive cookie
(magic, lengthofPackage, toc, tocLen, pyver, pylibname) = \
struct.unpack('!8sIIii64s', self.fPtr.read(self.PYINST21_COOKIE_SIZE))
except:
print('[!] Error : The file is not a pyinstaller archive')
return False
self.pymaj, self.pymin = (pyver//100, pyver%100) if pyver >= 100 else (pyver//10, pyver%10)
print('[+] Python version: {0}.{1}'.format(self.pymaj, self.pymin))
# Additional data after the cookie
tailBytes = self.fileSize - self.cookiePos - (self.PYINST20_COOKIE_SIZE if self.pyinstVer == 20 else self.PYINST21_COOKIE_SIZE)
# Overlay is the data appended at the end of the PE
self.overlaySize = lengthofPackage + tailBytes
self.overlayPos = self.fileSize - self.overlaySize
self.tableOfContentsPos = self.overlayPos + toc
self.tableOfContentsSize = tocLen
print('[+] Length of package: {0} bytes'.format(lengthofPackage))
return True
def parseTOC(self):
# Go to the table of contents
self.fPtr.seek(self.tableOfContentsPos, os.SEEK_SET)
self.tocList = []
parsedLen = 0
# Parse table of contents
while parsedLen < self.tableOfContentsSize:
(entrySize, ) = struct.unpack('!i', self.fPtr.read(4))
nameLen = struct.calcsize('!iIIIBc')
(entryPos, cmprsdDataSize, uncmprsdDataSize, cmprsFlag, typeCmprsData, name) = \
struct.unpack( \
'!IIIBc{0}s'.format(entrySize - nameLen), \
self.fPtr.read(entrySize - 4))
try:
name = name.decode("utf-8").rstrip("\0")
except UnicodeDecodeError:
newName = str(uniquename())
print('[!] Warning: File name {0} contains invalid bytes. Using random name {1}'.format(name, newName))
name = newName
# Prevent writing outside the extraction directory
if name.startswith("/"):
name = name.lstrip("/")
if len(name) == 0:
name = str(uniquename())
print('[!] Warning: Found an unamed file in CArchive. Using random name {0}'.format(name))
self.tocList.append( \
CTOCEntry( \
self.overlayPos + entryPos, \
cmprsdDataSize, \
uncmprsdDataSize, \
cmprsFlag, \
typeCmprsData, \
name \
))
parsedLen += entrySize
print('[+] Found {0} files in CArchive'.format(len(self.tocList)))
def _writeRawData(self, filepath, data):
nm = filepath.replace('\\', os.path.sep).replace('/', os.path.sep).replace('..', '__')
nmDir = os.path.dirname(nm)
if nmDir != '' and not os.path.exists(nmDir): # Check if path exists, create if not
os.makedirs(nmDir)
with open(nm, 'wb') as f:
f.write(data)
def extractFiles(self):
print('[+] Beginning extraction...please standby')
extractionDir = os.path.join(os.getcwd(), os.path.basename(self.filePath) + '_extracted')
if not os.path.exists(extractionDir):
os.mkdir(extractionDir)
os.chdir(extractionDir)
for entry in self.tocList:
self.fPtr.seek(entry.position, os.SEEK_SET)
data = self.fPtr.read(entry.cmprsdDataSize)
if entry.cmprsFlag == 1:
try:
data = zlib.decompress(data)
except zlib.error:
print('[!] Error : Failed to decompress {0}'.format(entry.name))
continue
# Malware may tamper with the uncompressed size
# Comment out the assertion in such a case
assert len(data) == entry.uncmprsdDataSize # Sanity Check
if entry.typeCmprsData == b'd' or entry.typeCmprsData == b'o':
# d -> ARCHIVE_ITEM_DEPENDENCY
# o -> ARCHIVE_ITEM_RUNTIME_OPTION
# These are runtime options, not files
continue
basePath = os.path.dirname(entry.name)
if basePath != '':
# Check if path exists, create if not
if not os.path.exists(basePath):
os.makedirs(basePath)
if entry.typeCmprsData == b's':
# s -> ARCHIVE_ITEM_PYSOURCE
# Entry point are expected to be python scripts
print('[+] Possible entry point: {0}.pyc'.format(entry.name))
if self.pycMagic == b'\0' * 4:
# if we don't have the pyc header yet, fix them in a later pass
self.barePycList.append(entry.name + '.pyc')
self._writePyc(entry.name + '.pyc', data)
elif entry.typeCmprsData == b'M' or entry.typeCmprsData == b'm':
# M -> ARCHIVE_ITEM_PYPACKAGE
# m -> ARCHIVE_ITEM_PYMODULE
# packages and modules are pyc files with their header intact
# From PyInstaller 5.3 and above pyc headers are no longer stored
# https://github.com/pyinstaller/pyinstaller/commit/a97fdf
if data[2:4] == b'\r\n':
# < pyinstaller 5.3
if self.pycMagic == b'\0' * 4:
self.pycMagic = data[0:4]
self._writeRawData(entry.name + '.pyc', data)
else:
# >= pyinstaller 5.3
if self.pycMagic == b'\0' * 4:
# if we don't have the pyc header yet, fix them in a later pass
self.barePycList.append(entry.name + '.pyc')
self._writePyc(entry.name + '.pyc', data)
else:
self._writeRawData(entry.name, data)
if entry.typeCmprsData == b'z' or entry.typeCmprsData == b'Z':
self._extractPyz(entry.name)
# Fix bare pyc's if any
self._fixBarePycs()
def _fixBarePycs(self):
for pycFile in self.barePycList:
with open(pycFile, 'r+b') as pycFile:
# Overwrite the first four bytes
pycFile.write(self.pycMagic)
def _writePyc(self, filename, data):
with open(filename, 'wb') as pycFile:
pycFile.write(self.pycMagic) # pyc magic
if self.pymaj >= 3 and self.pymin >= 7: # PEP 552 -- Deterministic pycs
pycFile.write(b'\0' * 4) # Bitfield
pycFile.write(b'\0' * 8) # (Timestamp + size) || hash
else:
pycFile.write(b'\0' * 4) # Timestamp
if self.pymaj >= 3 and self.pymin >= 3:
pycFile.write(b'\0' * 4) # Size parameter added in Python 3.3
pycFile.write(data)
def _extractPyz(self, name):
dirName = name + '_extracted'
# Create a directory for the contents of the pyz
if not os.path.exists(dirName):
os.mkdir(dirName)
with open(name, 'rb') as f:
pyzMagic = f.read(4)
assert pyzMagic == b'PYZ\0' # Sanity Check
pyzPycMagic = f.read(4) # Python magic value
if self.pycMagic == b'\0' * 4:
self.pycMagic = pyzPycMagic
elif self.pycMagic != pyzPycMagic:
self.pycMagic = pyzPycMagic
print('[!] Warning: pyc magic of files inside PYZ archive are different from those in CArchive')
# Skip PYZ extraction if not running under the same python version
if self.pymaj != sys.version_info.major or self.pymin != sys.version_info.minor:
print('[!] Warning: This script is running in a different Python version than the one used to build the executable.')
print('[!] Please run this script in Python {0}.{1} to prevent extraction errors during unmarshalling'.format(self.pymaj, self.pymin))
print('[!] Skipping pyz extraction')
return
(tocPosition, ) = struct.unpack('!i', f.read(4))
f.seek(tocPosition, os.SEEK_SET)
try:
toc = marshal.load(f)
except:
print('[!] Unmarshalling FAILED. Cannot extract {0}. Extracting remaining files.'.format(name))
return
print('[+] Found {0} files in PYZ archive'.format(len(toc)))
# From pyinstaller 3.1+ toc is a list of tuples
if type(toc) == list:
toc = dict(toc)
for key in toc.keys():
(ispkg, pos, length) = toc[key]
f.seek(pos, os.SEEK_SET)
fileName = key
try:
# for Python > 3.3 some keys are bytes object some are str object
fileName = fileName.decode('utf-8')
except:
pass
# Prevent writing outside dirName
fileName = fileName.replace('..', '__').replace('.', os.path.sep)
if ispkg == 1:
filePath = os.path.join(dirName, fileName, '__init__.pyc')
else:
filePath = os.path.join(dirName, fileName + '.pyc')
fileDir = os.path.dirname(filePath)
if not os.path.exists(fileDir):
os.makedirs(fileDir)
try:
data = f.read(length)
data = zlib.decompress(data)
except:
print('[!] Error: Failed to decompress {0}, probably encrypted. Extracting as is.'.format(filePath))
open(filePath + '.encrypted', 'wb').write(data)
else:
self._writePyc(filePath, data)
def main():
if len(sys.argv) < 2:
print('[+] Usage: pyinstxtractor.py <filename>')
else:
arch = PyInstArchive(sys.argv[1])
if arch.open():
if arch.checkFile():
if arch.getCArchiveInfo():
arch.parseTOC()
arch.extractFiles()
arch.close()
print('[+] Successfully extracted pyinstaller archive: {0}'.format(sys.argv[1]))
print('')
print('You can now use a python decompiler on the pyc files within the extracted directory')
return
arch.close()
if __name__ == '__main__':
main()