1 介绍
年份:2017
作者:Zhizhong Li,Amazon AWS Rekognition;Derek Hoiem,伊利诺伊大学计算机科学教授
会议:IEEE transactions on pattern analysis and machine intelligence
引用量:4325
Li Z, Hoiem D. Learning without forgettingJ. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(12): 2935-2947.
作者提出了一种名为"Learning without Forgetting"(LwF)的方法。利用知识蒸馏损失来保持旧任务的输出,这是一种创新的损失函数应用,与传统的参数正则化方法相比,能够更直接地保留旧任务的知识。这种方法使用新任务数据来训练网络,同时保留原始功能。LwF的表现优于常用的特征提取和微调适应技术。


2 创新点
- 新任务学习与旧任务保留的结合 :
- 论文提出了一种新颖的方法,使得在训练卷积神经网络以学习新任务的同时,能够保留对旧任务的记忆,有效解决了灾难性遗忘问题。
- 无需旧任务数据 :
- LwF算法不需要旧任务的训练数据,只需要新任务的数据来更新网络,这与传统的多任务学习和迁移学习方法不同,后者通常需要访问所有任务的数据。
- 知识蒸馏的创新应用 :
- 利用知识蒸馏损失来保持旧任务的输出,这是一种创新的损失函数应用,与传统的参数正则化方法相比,能够更直接地保留旧任务的知识。
- 预热步骤与联合优化步骤 :
- 算法采用了预热步骤和联合优化步骤的训练策略,预热步骤首先训练新任务参数,然后联合优化步骤同时训练所有参数,这种分阶段的训练方法提高了学习效率和性能。
- 损失函数的平衡权重 :
- 通过引入损失平衡权重 λ o \lambda_o λo,LwF算法能够平衡新旧任务的损失,提供了一种灵活的方法来调整新旧任务性能之间的权衡。
3 相关研究
- Catastrophic Forgetting :
- 描述了在神经网络中,当学习新任务时,旧任务的性能可能会急剧下降的现象,这被称为灾难性遗忘。
- 文献:1 M. McCloskey and N. J. Cohen, "Catastrophic interference in connectionist networks: The sequential learning problem."
- Transfer Learning :
- 讨论了迁移学习,即在一个任务上学到的知识可以帮助另一个不同但相关任务的学习。
- 文献:5 J. Donahue et al., "Decaf: A deep convolutional activation feature for generic visual recognition;" 6 R. Girshick et al., "Rich feature hierarchies for accurate object detection and semantic segmentation."
- Multi-task Learning :
- 多任务学习,旨在同时提高多个任务的性能,通过共享表示来提高泛化能力。
- 文献:7 R. Caruana, "Multitask learning."
- Feature Extraction :
- 特征提取方法,其中预训练的深度CNN用于计算图像的特征,然后使用这些特征训练新任务的分类器。
- 文献:5 J. Donahue et al., "Decaf: A deep convolutional activation feature for generic visual recognition."
- Fine-tuning :
- 微调方法,通过修改预训练网络的参数来适应新任务,通常使用较小的学习率以避免大幅偏离原始参数。
- 文献:6 R. Girshick et al., "Rich feature hierarchies for accurate object detection and semantic segmentation."
- Joint Training :
- 联合训练,即同时优化所有任务的参数,通过交错不同任务的样本来进行训练。
- 文献:7 R. Caruana, "Multitask learning."
- Continual Learning or Lifelong Learning :
- 持续学习或终身学习,关注如何在学习新任务的同时保留对旧任务的记忆。
- 文献:24 S. Thrun, "Lifelong learning algorithms;" 25 T. Mitchell et al., "Never-ending learning."
- Knowledge Distillation :
- 知识蒸馏,一种将大型网络的知识转移到小型网络的方法,通过优化损失函数使得小型网络的输出接近大型网络。
- 文献:11 G. Hinton et al., "Distilling the knowledge in a neural network."
- Net2Net :
- Net2Net方法,可以快速初始化网络以进行超参数探索,通过生成一个更深、更宽的网络,该网络在功能上等同于现有的网络。
- 文献:20 T. Chen et al., "Net2net: Accelerating learning via knowledge transfer."
4 算法原理

- 定义参数
- 假设一个CNN有一组共享参数 (\theta_s)(例如AlexNet中的五个卷积层和两个全连接层)。
- 旧任务有特定的参数 (\theta_o)(例如用于ImageNet分类的输出层及其权重)。
- 新任务有随机初始化的特定参数 (\theta_n)(例如场景分类器)。
- 原始网络对新任务图像的旧任务输出 (y_o)。
- 根据新任务调整网络结构
- 根据新任务的分类输出数量,调整输出层的节点。
- 训练过程 :
- 使用随机梯度下降(SGD)训练网络,最小化所有任务的损失和正则化项 ®。正则化项通常是一个简单的权重衰减(0.0005)。
- 训练分为两个步骤:
- 预热步骤(warm-up step) :冻结 θ s \theta_s θs和 θ o \theta_o θo,只训练 θ n \theta_n θn直到收敛。这有助于提高新任务的性能。新任务损失使用的是多类分类的常用损失函数,例如多项式逻辑损失(multinomial logistic loss)
L w a r m − u p = L n e w ( y n , y ^ n ) L_{warm-up}=L_{new}(y_n,\hat{y}_n) Lwarm−up=Lnew(yn,y^n)
- **联合优化步骤(joint-optimize step)**:联合训练所有权重$\theta_s$、$\theta_o$和$\theta_n$直到收敛。这有助于在新任务上优化共享参数,同时保留旧任务的性能。旧任务损失使用的是知识蒸馏损失(Knowledge Distillation loss),这是一种修改后的交叉熵损失,增加了对较小概率的权重,以鼓励网络输出接近原始网络的输出。通过损失平衡权重$\lambda_o$来调整新旧任务损失的相对重要性,在新任务和旧任务性能之间取得平衡。L j o i n t = λ o L o l d ( y o , y ^ o ) + L n e w ( y n , y ^ n ) + R ( θ s , θ o , θ n ) L_{joint}=λ_{o}L_{old}(y_{o},\hat{y}o)+L{new}(y_n,\hat{y}_n)+R(\theta_s,\theta_o,\theta_n) Ljoint=λoLold(yo,y^o)+Lnew(yn,y^n)+R(θs,θo,θn)
5 实验分析
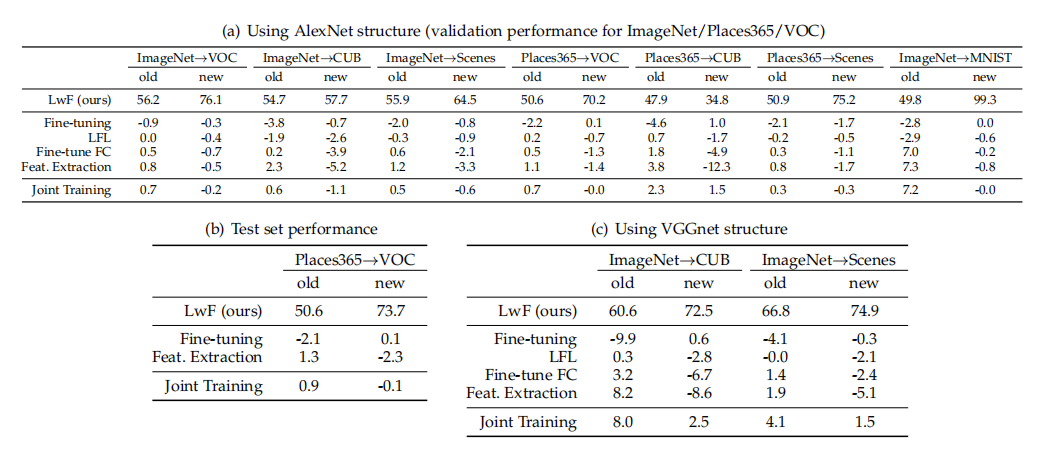
(1)不同方法性能比较
不同方法相对于LwF的性能差异。实验结果以与LwF方法的比较为基础来报告,以便进行比较。对于VOC数据集,使用平均精度均值(mAP)来衡量性能,而对于其他数据集,则使用准确率(acc)
- 正值:表示某种方法的性能高于LwF方法。例如,如果某个方法在新任务上的准确率比LwF方法高出2%,则这个差值会表示为+2%。
- 负值:表示某种方法的性能低于LwF方法。例如,如果某种方法在旧任务上的准确率比LwF方法低1%,则这个差值会表示为-1%。
(2)逐步向预训练网络添加新任务时的每种任务的表现

在大多数情况下,LwF方法的性能随着时间的退化速度比微调(fine-tuning)慢,并且在大多数情况下优于特征提取方法。对于Places2到VOC的任务对,LwF方法的性能与联合训练相当,表明在这种情况下,不需要旧任务数据也能达到类似性能。
(3)新任务训练集大小减少(即数据子采样)对比较方法的影响
x轴显示了训练集大小的减少,即从完整的训练集逐渐减少到较小的子集。

即使在训练数据较少的情况下,LwF方法相对于其他方法仍然表现出更好的性能,这显示了LwF在不同数据条件下的稳健性。随着训练集大小的减少,所有方法的性能都可能受到影响,但LwF方法能够更好地保持性能,尤其是在新任务上。
(4)LwF算法的扩展性
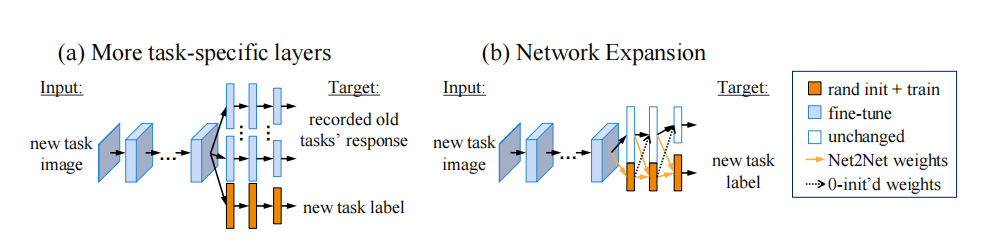
图(a)中表示每个新任务有自己的全连接层,可以针对特定的任务进行训练和优化。
图(b)在网络扩展方法中,通过在现有层之上添加新的节点来扩展网络,这些节点为新任务提供了额外的表示能力。新增节点的权重初始化方法参考了Net2Net的扩展方式,即复制现有节点的权重。
理论上将更多层设为任务特定可能有助于新任务的学习,但实验结果表明,这种方法并没有带来一致的性能提升。这可能是因为过多的任务特定层增加了模型的复杂性,而没有相应的性能收益。
LwF可以应用于网络扩展,通过解冻所有节点并匹配旧任务的输出响应,进一步优化新旧任务的平衡。
(5)其他设计选择的对比
包括改变任务特定层的数量、使用网络扩展技术、调整共享参数的学习率,以及使用不同的损失函数。
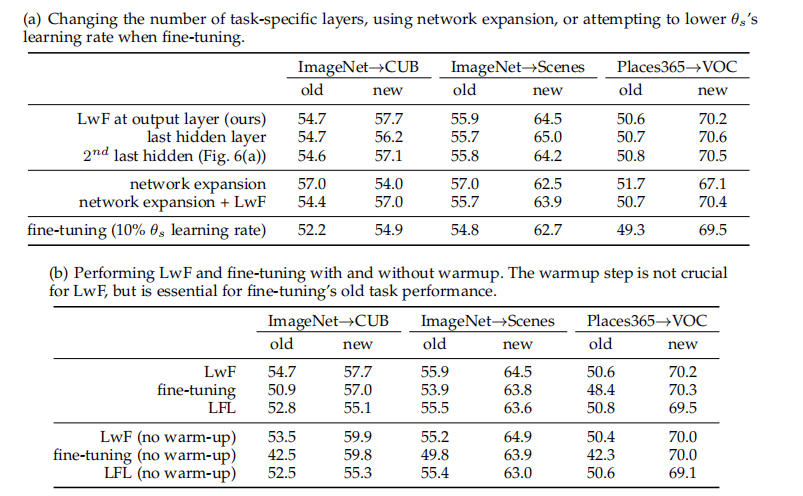
- 表中比较了仅在输出层(最后一层)与其他层也作为任务特定时的性能差异。实验结果表明,仅在输出层进行任务特定化与在更多层进行任务特定化相比,并没有表现出一致的性能优势或劣势。
- 网络扩展是一种在现有层上添加新节点的方法,以增加网络容量。表中比较了仅进行网络扩展与结合LwF进行网络扩展的性能。结果显示,虽然网络扩展可以提供一些性能提升,但结合LwF并没有带来额外的性能增益。
- 表中探讨了在微调过程中降低共享参数学习率的效果。实验结果表明,仅仅降低学习率并不足以保持旧任务的性能,而且可能会降低新任务的性能。这强调了LwF方法中输出保持损失的重要性。
- 表中比较了使用L1损失、L2损失、交叉熵损失和知识蒸馏损失的性能。实验结果表明,知识蒸馏损失略微优于其他损失函数,尽管优势不是很显著。知识蒸馏损失在某些情况下可能提供轻微的性能提升,但总体而言,损失函数的选择并不是影响LwF性能的关键因素。
(6)不同方法在新旧任务上的性能
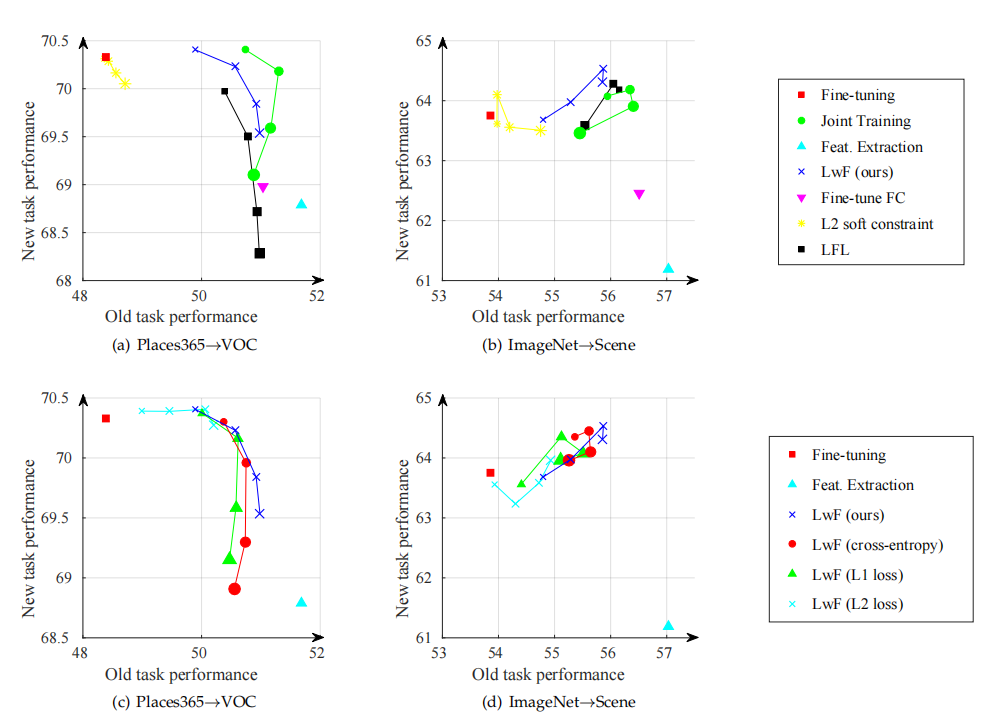
- LwF方法在新任务上通常优于微调(fine-tuning)和其他基线方法,并且在旧任务上的性能也显著优于微调。
- 联合训练(Joint Training)作为上界,使用旧任务数据,通常在旧任务上表现最佳,但在新任务上可能不如LwF。
- 不同的损失函数(如L1、L2、交叉熵和知识蒸馏损失)对LwF方法的性能有轻微影响。知识蒸馏损失通常提供稍微好一点的性能,但优势不大。
6 思考
(1)使用知识蒸馏的损失函数去做联合优化很有启发。
(2)本文中特征提取的算法原理
特征提取(Feature Extraction)是一种迁移学习方法,其核心思想是利用在一个大型、多样化的数据集(如ImageNet)上预训练的卷积神经网络(CNN)来为新任务提取特征。以下是特征提取方法的算法原理:
- 使用预训练的网络:选择一个在大规模数据集上预训练好的CNN模型,该模型已经在其参数中学习到了丰富的特征表示。
- 固定共享层:在特征提取方法中,预训练网络的共享参数 θs 被冻结,即不对其进行进一步的训练更新。
- 提取特征:通过前向传播,使用冻结的共享层来提取输入数据的特征表示。这些特征通常是网络中最后一层全连接层之前的激活输出。
- 训练新任务的分类器:在提取的特征之上训练一个新的分类器(例如,一个新的全连接层),这个分类器专门针对新任务进行训练,以学习如何根据特征表示对新任务的类别进行分类。
- 新任务训练:使用新任务的数据来训练新分类器,而原始的共享层参数保持不变,这样新任务就能从预训练网络中受益,同时避免了对旧知识的灾难性遗忘。
参考文献 5 J. Donahue et al., "Decaf: A deep convolutional activation feature for generic visual recognition," in International Conference in Machine Learning (ICML), 2014
(3)本文中微调的算法原理
微调(Fine-tuning)是一种迁移学习技术,用于将预训练的模型调整到一个新的、通常数据量较小的任务上。以下是微调方法的算法原理:
- 预训练模型:从一个大型数据集(如ImageNet)开始,该数据集已经在模型的参数中学习到了通用的特征表示。
- 修改网络结构:根据新任务的需求,可能需要对网络结构进行修改。例如,对于一个新的分类任务,可能需要替换或扩展网络的输出层,以适应新任务的类别数。
- 冻结共享层:在某些微调策略中,可以选择冻结网络的某些层(通常是底层),以保留学习到的通用特征。
- 训练新任务参数:使用新任务的数据来训练网络的某些层,特别是那些被修改或新添加的层。这通常涉及到使用比原始预训练时更小的学习率。
- 反向传播:通过反向传播算法来更新网络的参数,以最小化新任务的损失函数。
- 平衡新旧知识:微调过程中的一个关键挑战是平衡新任务学习与保留旧任务知识之间的关系,避免对旧任务性能的灾难性遗忘。
参考文献 6 R. Girshick et al., "Rich feature hierarchies for accurate object detection and semantic segmentation," in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014。
(4)新增节点的权重初始化方法参考了Net2Net的扩展方式,其中Net2Net是什么意思?
Net2Net是一种用于加速深度学习模型训练的技术,由Terry Chen、Ian Goodfellow和Jon Shlens在他们的论文中提出。这项技术的核心思想是允许网络在不牺牲性能的情况下快速适应新任务,通过将一个已经训练好的网络转化为一个具有更多或更少层的新网络,同时保持两者在功能上的等价性。Net2Net通过复制已有的层来扩展网络,每个新层的节点(或神经元)是原层节点的副本。新层的权重是通过原层的权重进行初始化的,这样可以保留已经学到的知识,并为新任务的学习提供一个良好的起点。
(5)本文微调算法和特征提取算法的异同是什么?
相同点:
- 预训练基础:两者都使用在大型数据集(如ImageNet)上预训练的卷积神经网络(CNN)作为基础。
- 参数重用:它们都利用了预训练模型中学习到的参数,尤其是网络的底层参数,这些参数捕获了通用的特征表示。
- 适应性:两种方法都旨在使模型适应新的数据集或任务,同时保留从原始任务中学到的知识。
不同点:
- 参数更新:
- 特征提取:通常只训练新任务的顶层,底层的共享参数被冻结,不进行更新。
- 微调:不仅训练新任务的顶层,还可能更新一部分或全部共享参数,以更好地适应新任务。
- 网络结构修改:
- 特征提取:不需要修改网络结构,直接在预训练模型的基础上添加新的分类层。
- 微调:可能需要根据新任务的需要修改网络结构,例如改变或扩展输出层。
- 训练策略:
- 特征提取:训练过程集中在新添加的顶层,底层参数保持不变。
- 微调:训练过程涉及整个网络或网络的一部分,使用较小的学习率来微调参数。
- 对新任务的适应性:
- 特征提取:由于只训练顶层,对新任务的适应性可能有限,但可以快速部署。
- 微调:通过对共享层的微调,可以更好地适应新任务,但风险是可能会损害旧任务的性能(灾难性遗忘)。
- 性能影响:
- 特征提取:通常在新任务上的性能不如微调,因为底层特征没有针对新任务进行优化。
- 微调:可能在新任务上实现更好的性能,但需要仔细平衡以保护旧任务的性能。
- 训练数据的需求:
- 特征提取:由于底层参数不更新,对新任务的训练数据量需求较少。
- 微调:需要足够的新任务训练数据来有效更新参数,否则可能引起过拟合。