论文题目:Learning Without Forgetting for Vision-Language Models(视觉语言模型的无遗忘学习)
期刊:TPAMI
摘要:类增量学习(CIL)或持续学习是现实世界中需要的一种能力,它要求学习系统在不忘记以前的任务的情况下适应新的任务。传统的CIL方法侧重于视觉信息来掌握核心特征,而视觉语言模型(VLM)的最新进展在借助文本信息学习泛化表示方面显示出了很好的能力。然而,当不断接受新课程的训练时,vlm往往会灾难性地忘记以前的知识。将vlm应用于CIL面临两大挑战:1)如何在不遗忘的情况下调整模型;2)如何充分利用多模态信息。为此,我们提出投影融合(PROOF),使vlm能够学习而不会忘记。为了解决第一个挑战,我们提出了基于固定图像/文本编码器的训练任务特定投影。当面对新的任务时,扩展新的投影,固定以前的投影,减轻了对旧概念的遗忘。对于第二个挑战,我们提出融合模块,以更好地利用跨模态信息。通过共同调整视觉和文本特征,该模型可以更好地捕获特定于任务的语义信息,从而促进识别。在具有各种持续学习场景和各种vlm的9个基准数据集上进行的广泛实验验证了PROOF达到了最先进的性能。
让视觉语言模型学会持续学习而不遗忘
引言
在人工智能快速发展的今天,**持续学习(Continual Learning)**能力已成为智能系统的关键需求。想象这样一个场景:一个图像识别系统需要不断学习识别新的物体类别,但每次学习新知识时,它都会忘记之前学过的东西------这就是机器学习领域著名的"灾难性遗忘(Catastrophic Forgetting)"问题。
最近,来自南洋理工大学和南京大学的研究团队在IEEE TPAMI 2025上发表了一篇重要论文,提出了**PROOF(PROjectiOn Fusion)**框架,成功解决了视觉-语言模型在类增量学习中的遗忘问题。这项研究不仅在理论上有所突破,更在9个基准数据集上取得了显著的性能提升。
问题的挑战性
传统方法的困境
当前的类增量学习面临两难境地:
-
视觉方法的局限: 传统CIL方法(如L2P、DualPrompt)主要关注视觉特征,虽然能够缓解遗忘,但忽略了文本中丰富的语义信息。就像一个只看图片不读文字说明的学生,学习效率自然大打折扣。
-
VLM微调的困境: CLIP等视觉-语言模型虽然能够利用跨模态信息,但顺序微调会导致灾难性遗忘。研究团队在论文中明确指出,当使用CoOp等方法顺序调优CLIP时,模型会严重遗忘先前学习的概念。
核心挑战
论文总结了将VLM应用于CIL的两大挑战:
- 如何在不遗忘的情况下适应模型?
- 如何充分利用多模态信息?
PROOF的创新解决方案

架构设计哲学
PROOF的设计遵循两个核心理念:
- Retentive(保持性): 模型应能保持预训练能力,从而保留泛化性并在未来任务上表现良好
- Comprehensive(全面性): 模型应能整合和调整来自多个模态的信息
技术创新详解
1. 可扩展投影机制
PROOF的第一个创新是任务特定的可扩展投影层。具体而言:
- 冻结主干网络: 保持CLIP的图像和文本编码器完全冻结,确保预训练知识不被破坏
- 添加投影层: 在冻结编码器之后添加线性投影层Pi(·)和Pt(·),将特征映射到适配空间
- 任务扩展策略: 每当新任务到来时,初始化新的投影层并冻结旧的,实现知识累积而非覆盖
数学上,投影聚合表示为:
Pi(z) = Σ(m=1 to b) P^m_i(z)
Pt(w) = Σ(n=1 to b) P^n_t(w)这种设计的巧妙之处在于:每个投影层仅包含d×d个参数(对于ViT-B/16,d=512),相对于CLIP的1.5亿参数几乎可以忽略不计,但却能有效编码任务特定信息。
2. 跨模态融合模块
PROOF的第二个创新是自注意力驱动的跨模态融合。
上下文信息构建包含三个关键组件:
-
视觉原型P : 为每个类别计算的代表性视觉特征,公式为
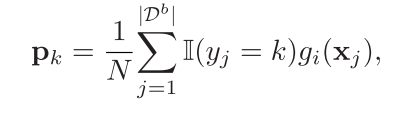
-
文本特征W: 使用模板文本生成的类别文本嵌入
-
可学习上下文提示C: 每个任务的可扩展提示向量,用于编码任务特定信息
融合过程通过自注意力机制实现:
[P̃i(z), P̃, W̃, C̃] = SelfAttention([Pi(z), P, W, C])这种设计允许模型根据上下文信息自适应地调整查询嵌入。例如,当查询图像是"熊猫"时,模型会强调黑眼圈和耳朵等判别性特征;当是"猫"时,则会突出胡须和尾巴。
3. 多目标聚合推理
PROOF设计了三种互补的匹配目标:
- 投影匹配(fPM): 直接匹配投影后的视觉和文本特征
- 视觉匹配(fVM): 匹配融合后的查询嵌入与视觉原型
- 文本匹配(fTM): 匹配融合后的查询嵌入与文本特征
最终分类通过聚合三者实现:f(x) = fPM(x) + fVM(x) + fTM(x)
训练时优化交叉熵损失:
L = ℓ(fPM(x),y) + ℓ(fVM(x),y) + ℓ(fTM(x),y)实验验证:数据说话
基准测试表现
研究团队在9个数据集上进行了全面评估,使用两种常用的CLIP权重(OpenAI和OpenCLIP LAION-400M)。
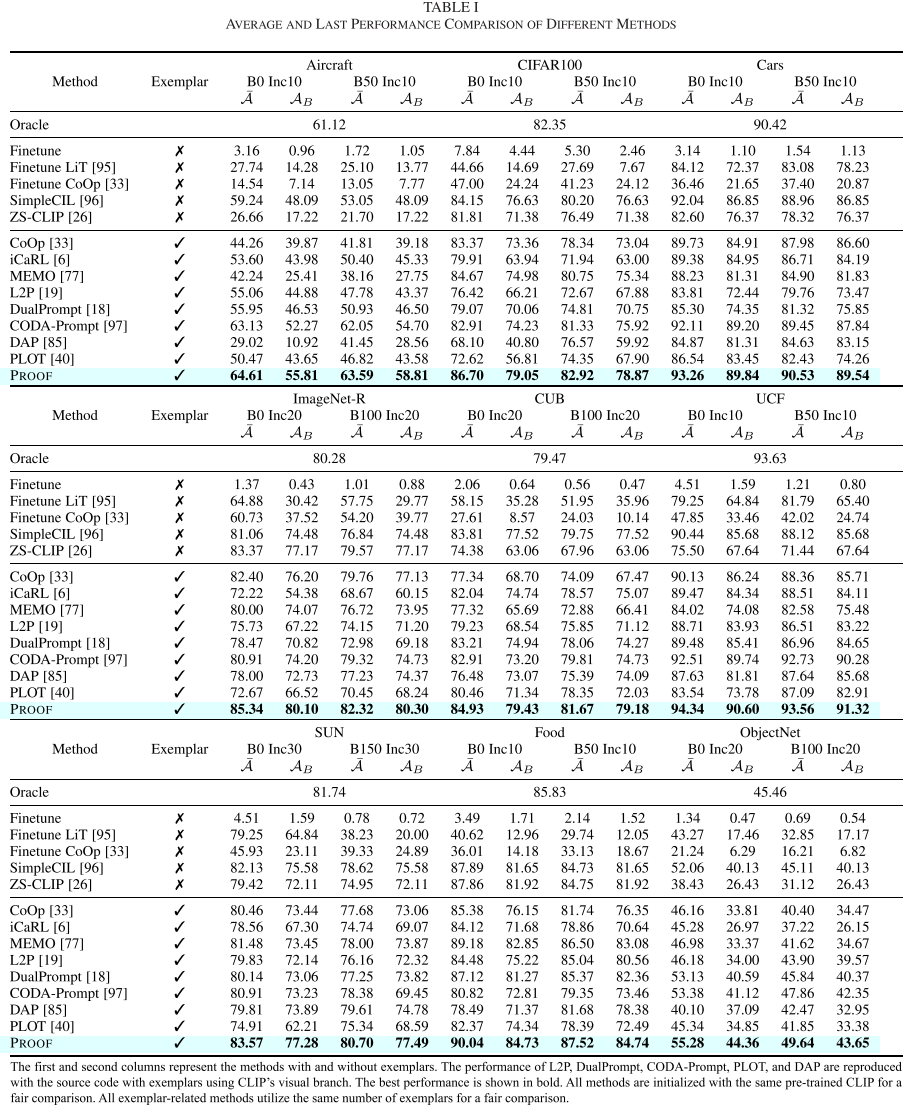
在CIFAR100 Base0 Inc10设置下:
- PROOF平均准确率: 86.70%
- 最终准确率: 82.92%
- 相比最佳对比方法提升: 约2-3个百分点
跨数据集稳定性: PROOF在所有9个数据集上都取得了最佳性能:
| 数据集 | 平均准确率 | 最终准确率 |
|---|---|---|
| Aircraft | 64.61% | 55.81% |
| CIFAR100 | 86.70% | 82.92% |
| CUB | 86.70% | 79.05% |
| ImageNet-R | 80.10% | 80.10% |
| Food | 85.34% | 79.43% |
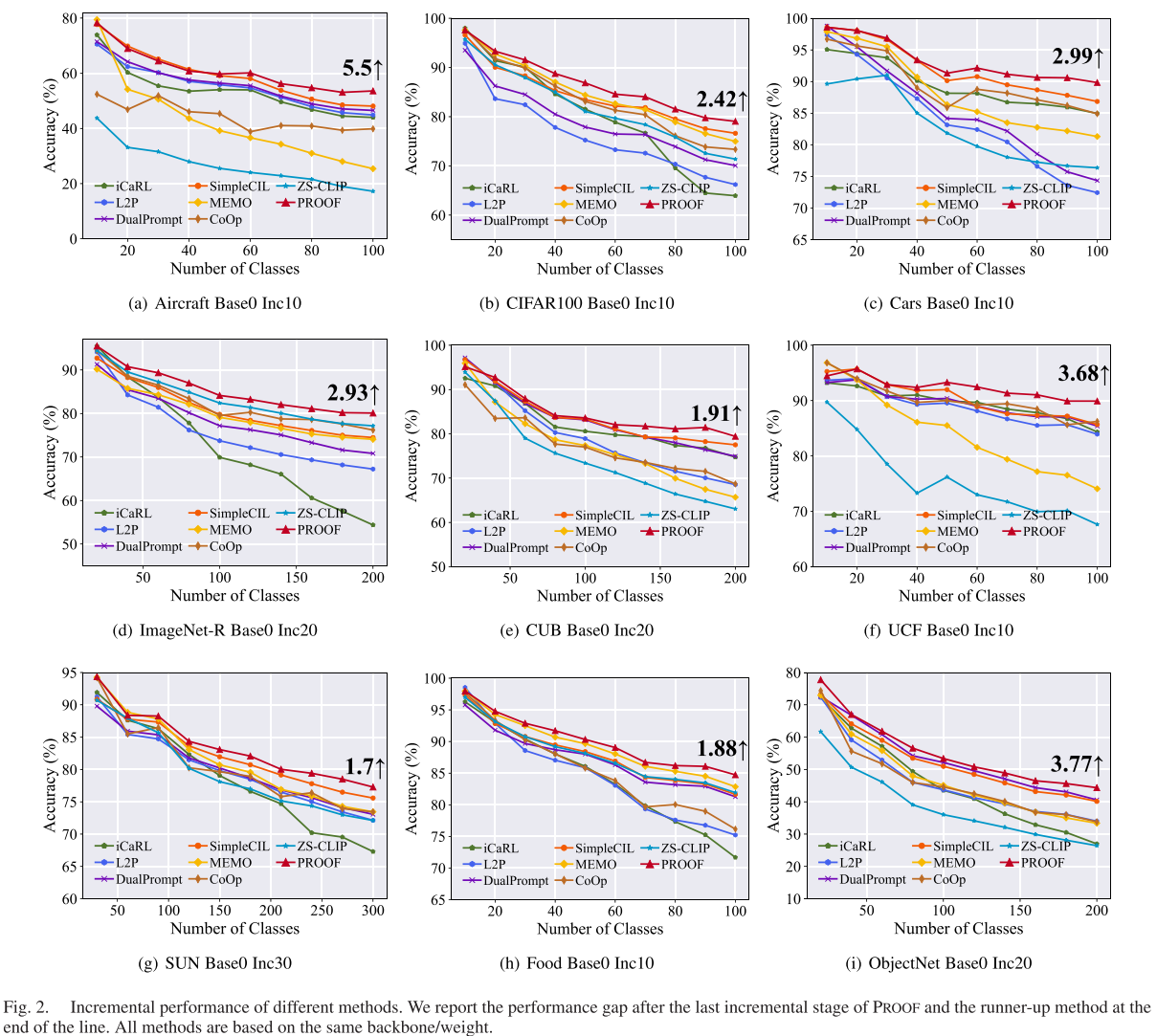
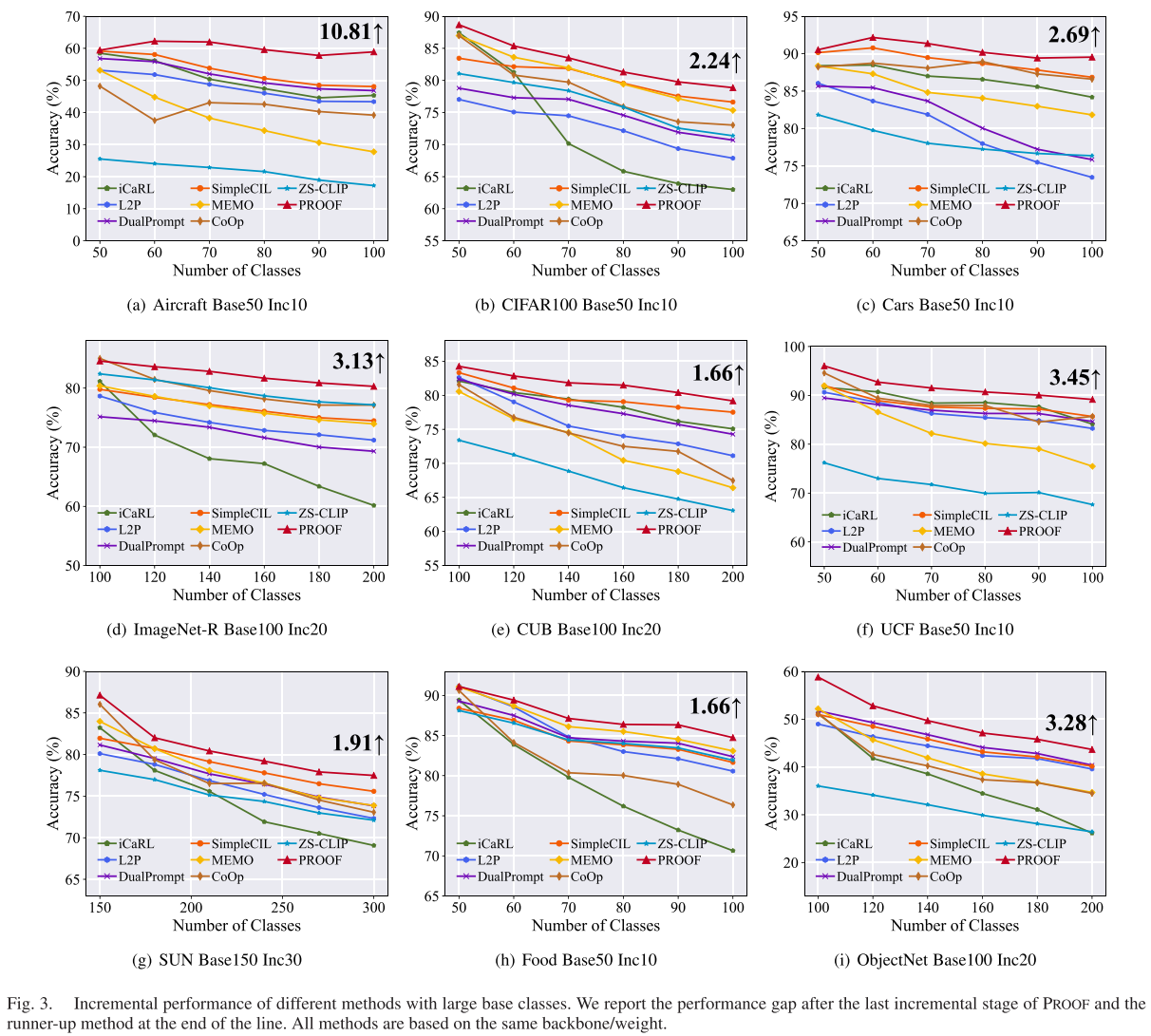
消融实验洞察
研究团队进行了细致的消融实验来验证每个组件的贡献:
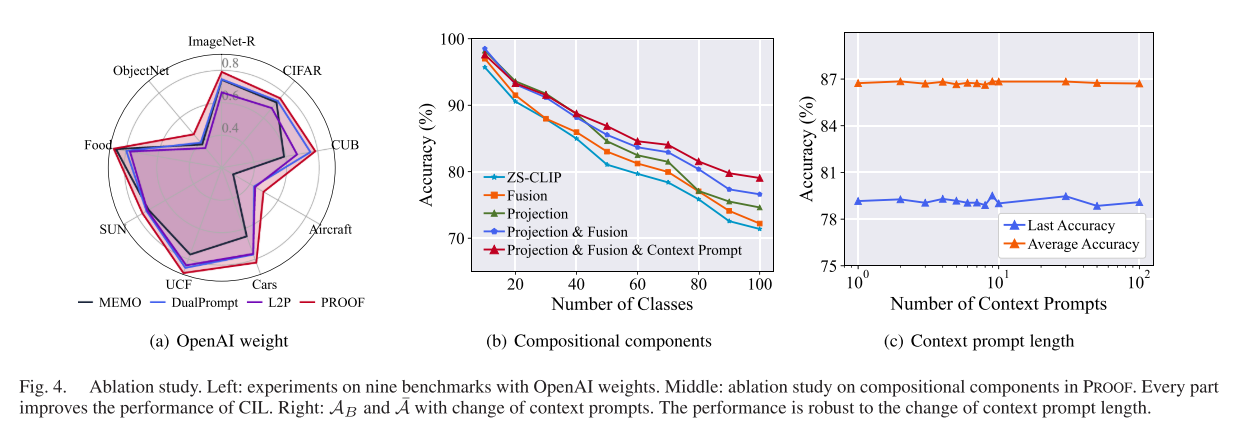
-
组件重要性(CIFAR100 B0 Inc10):
- 仅投影: 性能提升明显
- 仅融合: 性能提升明显
- 投影+融合: 性能进一步提升
- 投影+融合+上下文提示: 最佳性能
-
上下文提示长度鲁棒性 : 实验测试了c从1到100的不同长度,发现c=3时即可达到稳定的优秀性能,表明提示只需较小规模即可编码任务特定信息。
-
投影层类型选择 : 对比了线性层、SSF(Scale-Shift-Freeze)和Adapter三种实现,发现单个线性层性能最佳,验证了简单线性映射即可有效弥合视觉-文本域间隙的假设。
真实世界验证:TV100数据集
为了验证PROOF在真实世界场景中的表现,研究团队构建了一个特殊的数据集TV100,包含2021年后发布的100部电视剧(CLIP训练数据截止于2021年)。
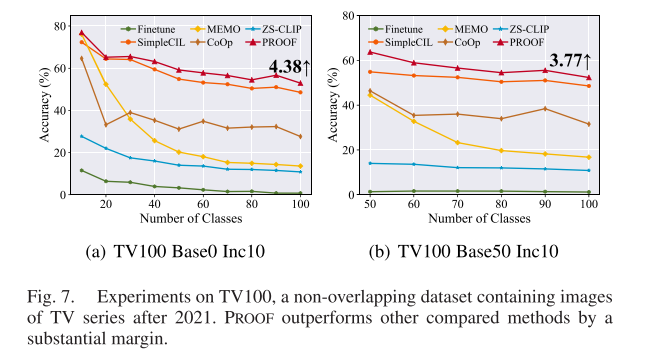
关键发现:
- 预训练CLIP零样本准确率: 仅约10%
- PROOF在此数据集上: 仍显著优于所有对比方法
这证明了PROOF不仅在标准基准上有效,在面对真正"未见过"的概念时同样表现出色。
跨模态检索任务
PROOF的通用性还体现在其他持续学习场景中。在Flickr30K数据集的持续跨模态检索任务上:
- 图像检索 (IR@1): 最后阶段召回率提升2.5个百分点
- 文本检索 (TR@1): 最后阶段召回率提升2.5个百分点
- 在R@5和R@10指标上同样保持领先
零样本性能权衡
论文还探讨了一个重要问题:持续学习是否会损害模型的零样本泛化能力?
研究团队提出了PROOF†变体,采用残差投影格式:
Pi(z) = Σ(m=1 to b) (P^m_i(z) + z)实验结果显示:
- PROOF†在未见类别上的准确率AU接近ZS-CLIP
- LAION匹配分数保持在与ZS-CLIP相似的水平
- 在已见类别和未见类别的调和平均AHM上取得平衡
这表明通过适当的设计,可以在适应性和泛化性之间取得良好平衡。
技术细节与实现
参数效率分析
PROOF的额外参数来源于三部分:
- 投影层: 2b × d² (b为任务数)
- 融合模块: 3 × d² (自注意力的Q、K、V矩阵)
- 视觉原型: B × d (B为总类别数)
总参数量: (2b+3) × d² + B × d
对于典型设置(d=512, b=10, B=100):
- 额外参数: 约13M
- CLIP主干参数: 约150M
- 额外参数占比: 不到9%
更重要的是,投影层可以在推理时合并:
Pî(z) = Σ P^m_i(z) = Σ P^m_i × z = (Σ P^m_i) × z这意味着推理时只需存储一个合并后的投影矩阵,将存储需求从(2b+3)×d²降至5×d²。
训练策略
PROOF的训练过程遵循以下步骤(Algorithm 1):
- 初始化: 提取新类别的视觉原型
- 冻结旧知识: 冻结之前任务的投影和上下文提示
- 扩展新组件: 初始化新的投影层P^b_i、P^b_t和上下文提示c^b
- 联合训练 : 在当前数据Db和示例集E上优化:
- 计算投影匹配损失
- 执行跨模态融合
- 计算视觉和文本匹配损失
- 梯度更新: 仅更新当前任务的可训练参数
训练配置:
- 优化器: SGD with momentum
- 批大小: 64
- 训练轮数: 5 epochs
- 学习率: 0.001,余弦退火衰减
- 每类示例数: 20(使用herding算法选择)
方法的优势与局限
核心优势
- 通用性强: 适用于多种VLM(CLIP、BEiT-3)和多种持续学习场景(CIL、跨模态检索)
- 参数高效: 额外参数不到主干网络的10%,且支持推理时合并
- 性能卓越: 在所有测试数据集上都达到了SOTA性能
- 设计简洁: 核心思想清晰,易于理解和实现
- 可扩展性: 可以灵活调整以在适应性和泛化性之间取得平衡
潜在局限
- 示例依赖: 仍然需要存储少量旧类别示例(每类20个)
- 任务边界假设: 假设任务边界是已知的
- 计算开销: 自注意力机制在类别数量很大时可能成为瓶颈
未来展望
论文指出了几个值得探索的方向:
- 无示例学习: 将PROOF扩展到完全无示例的场景
- 任务无关学习: 移除对明确任务边界的依赖
- 更大规模验证: 在更大规模的数据集(如完整ImageNet)上验证
- 其他VLM: 探索PROOF在更多先进VLM(如Flamingo、BLIP-2)上的应用
结语
PROOF为视觉-语言模型的持续学习提供了一个优雅而有效的解决方案。通过可扩展投影和跨模态融合的巧妙结合,它成功克服了灾难性遗忘问题,同时充分利用了多模态信息。
实验数据充分证明了其有效性:在9个基准数据集上全面领先,在非重叠数据集上表现出色,在跨模态检索任务上同样有效。更重要的是,PROOF的设计理念------保持预训练知识的同时渐进式扩展任务特定组件------为未来的持续学习研究提供了宝贵的启示。
随着基础模型规模的不断增大,如何让这些模型高效地进行持续学习变得越来越重要。PROOF展示了一条可行的道路:不是从头训练,而是巧妙地"补丁式"扩展;不是单模态学习,而是跨模态协同。这种思路对于构建真正智能的、能够持续学习的AI系统具有重要意义。