背景
观测云 DataKit 是一个强大的数据采集工具,能够收集和监控容器化环境和 Kubernetes 集群的指标、对象和日志数据。通过灵活使用 DataKit 收集的数据,可以对 Kubernetes 集群进行深入的监控和分析,从而实现更好的运维和优化。以下是一些使用 DataKit 来优化 Kubernetes 监控和分析的建议:
- 多维度指标采集 :确保采集包括但不限于
kube_pod、kube_node、kube_deployment、kube_service和kube_daemonset等指标,以便全面了解集群状态。 - 实时监控:利用 DataKit 的实时数据采集能力和观测云的监控能力,对 Kubernetes 集群的运行状态进行实时监控,及时发现并响应问题。
- 自定义告警规则:在观测云上根据业务需求和集群运行特点,设置自定义的告警规则,当指标超出正常范围时,通过邮件、短信或即时通讯工具及时通知相关人员。
云原生使用场景下的痛点案例
Karpenter 是一个开源的 Kubernetes 集群自动扩缩容工具,它能够根据应用的负载动态地调整计算资源,以确保集群资源的高效利用。使用 AWS EKS 服务时,Karpenter 可以提供以下优势:
- 即时响应:Karpenter 能够快速响应应用负载的变化,自动调整 pod 和 node 的数量。
- 成本优化:通过移除低效节点和替换为更经济的资源,Karpenter 帮助降低集群的计算成本。
- 简化运维:Karpenter 提供了一组默认设置,通过单一声明式的 NodePool 资源简化了配置过程。
然而,当出现异常调度,比如部署组实例数量或节点数量突然增加时,确实需要一种机制来即时通知负责人。
DataKit 数据采集+观测云突变监控
通过比较两个不同时间段内同一个指标的绝对或相对(%)变化值来判断是否产生异常情况。多应用于追踪某个指标的峰值或者数据变化,当出现异常情况时可以更精准地产生事件留做记录。
突变监控支持针对日志、指标、链路、网络等数据进行配置,支持数据量环比、同比、数据量百分比等突变数据进行监控配置。
以下为突变监控几个真实使用场景:
场景一:监控 kubernetes nodes 节点数量指标发生突变
在指标集 kubernetes 中,指标名称为 node,tag 名称为 cluster_name_k8s,含义分别为 node 节点数量以及 k8s 集群名称,通过监控 node 节点的变化趋势,当变化数量超过一定数量之后,发出监控告警,详细配置如下。
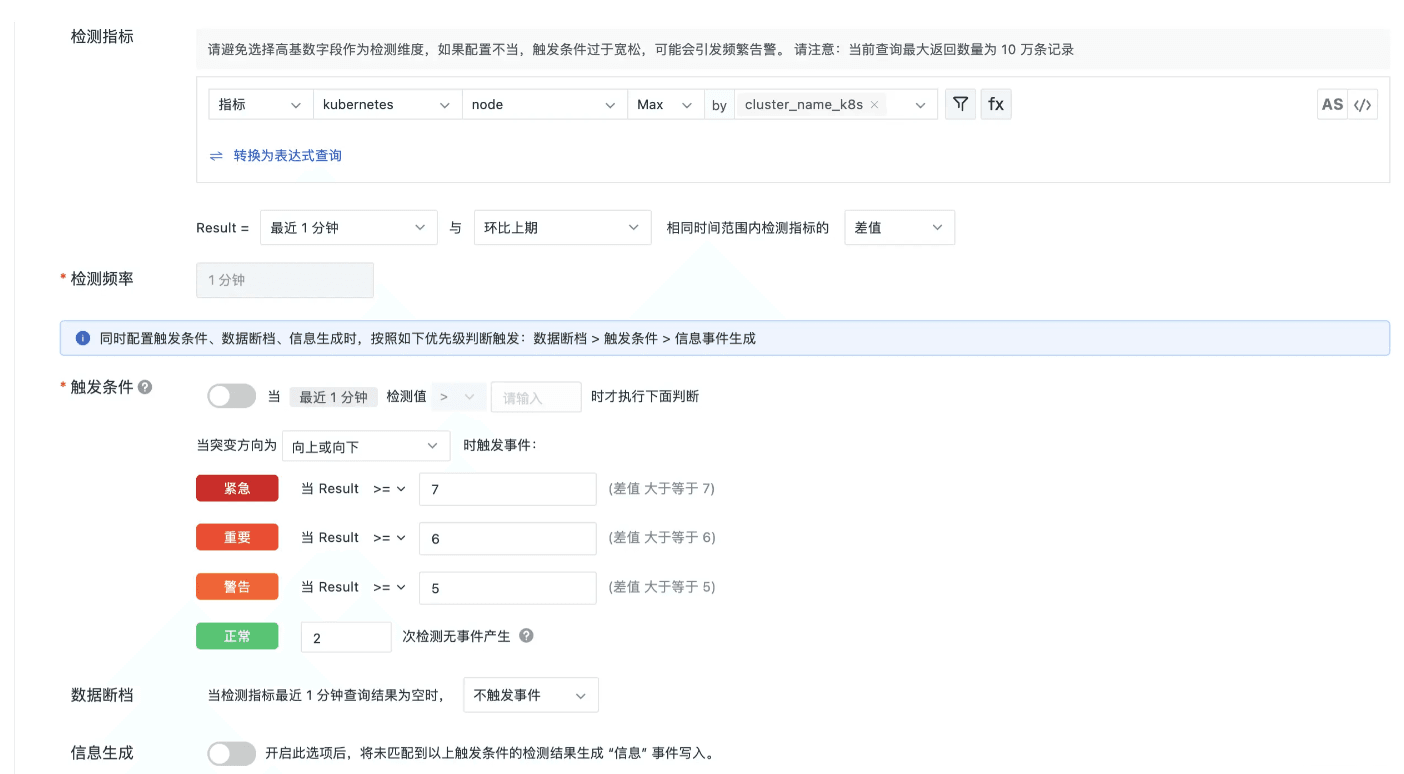
配置详解
- 环比上期对比:监控触发条件为环比最近 1 分钟与前一分钟的 node 数量指标 MAX 值之差。
- 检测频率:1 分钟执行一次检测。
- 触发条件:向上或向下,即取差值的绝对值进行判断;检测对比 node 数量相差超过 5 个发出警告事件,超过 6 个重要事件,超过 7 个发出紧急事件。
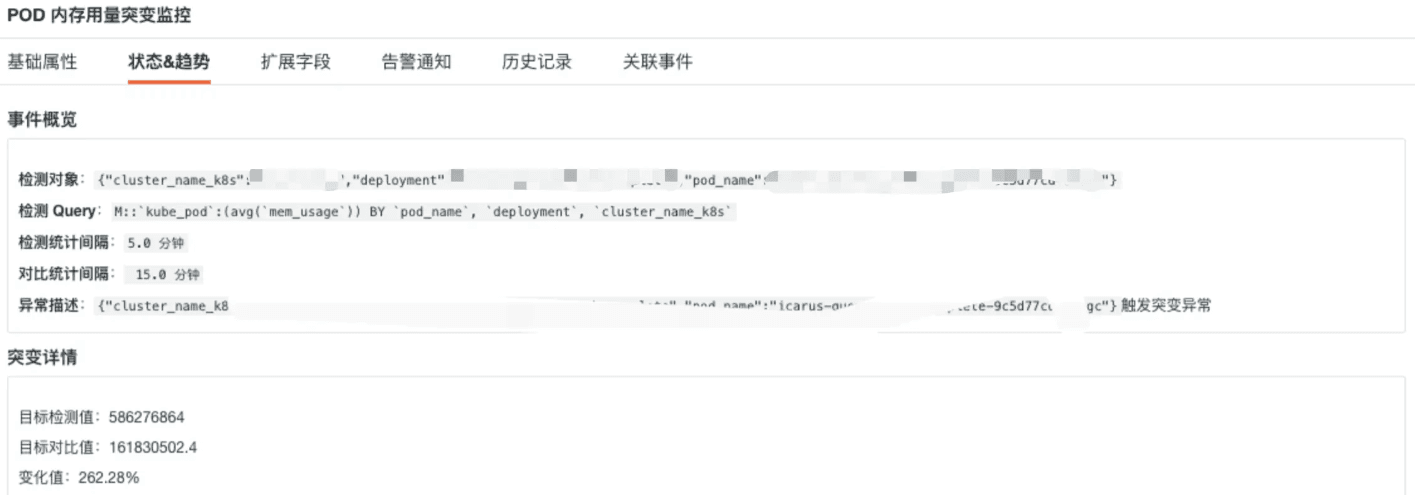
场景二:监控 pod 内存用量发生突增
在指标集 kube_pod 中,指标名称为 mem_usage,tag 名称为 cluster_name_k8s、pod_name、deployment,指标含义为 pod 节点内存用量,标签含义为 k8s 集群名称、POD 名称、部署组名称,通过监控节点内存的变化趋势,当变化数量超过一定数量之后,发出监控告警,详细配置如下。

配置详解
- 差值百分比:监控触发条件为环比最近 5 分钟与最近 15 分钟内存用量平均值的差值百分比。
- 执行条件:最近 5 分钟内存使用量超过 100 MB 再触发检测, 规避无用告警
- 检测频率:5 分钟执行一次检测。
- 触发条件:差值百分比进行判断,向上含义为差值百分比大于 0 时,触发检测;对比内存用量相差增加 100% 发出警告事件,增加 200% 发出重要事件,增加 300% 发出紧急事件。
场景三:监控 pod 频繁发生重启
在指标集 kube_pod 中,指标名称为 restarts,tag 名称为 cluster_name_k8s、pod_name、deployment,指标含义为 pod 重启次数,pod 不重建情况下为递增值,标签含义为 k8s 集群名称、POD 名称、部署组名称,通过监控节点内存的变化趋势,当变化数量超过一定数量之后,发出监控告警,详细配置如下。
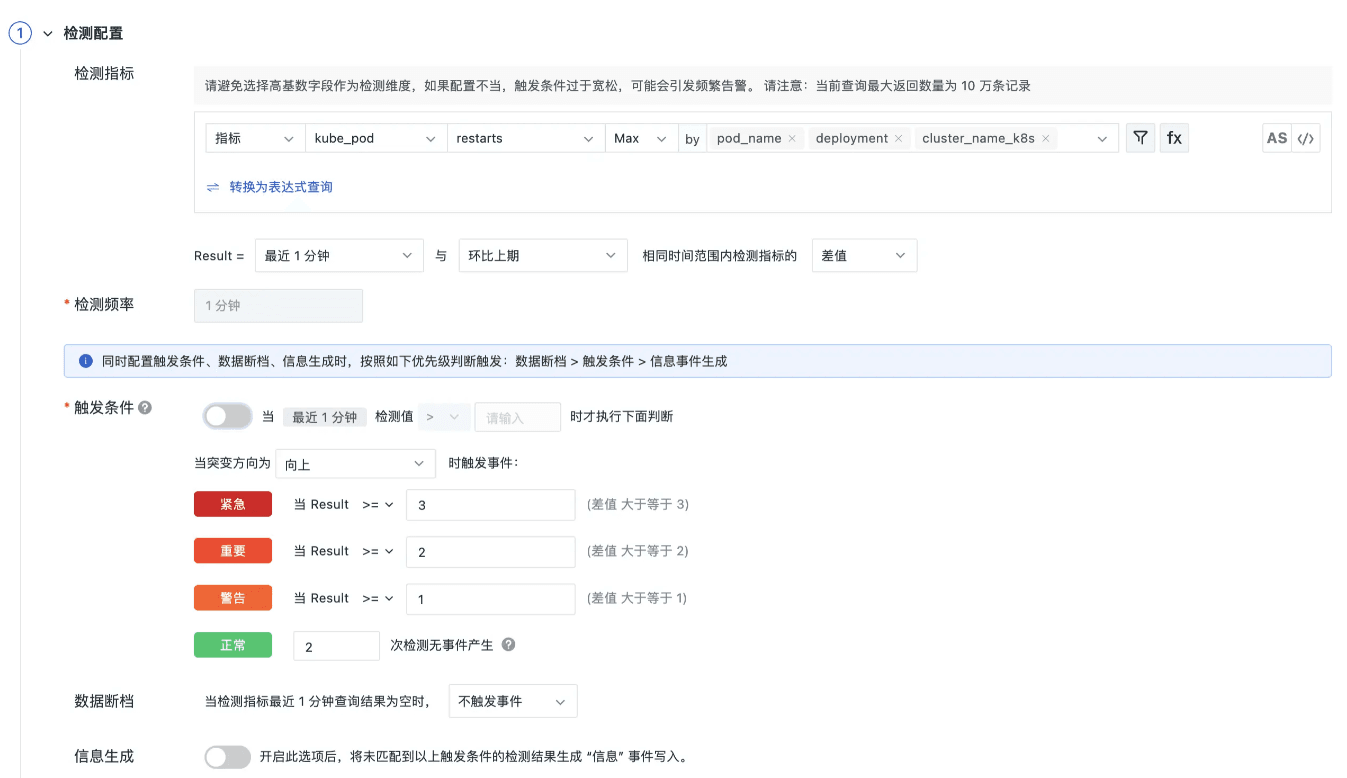
配置详解
- 环比上期对比:监控触发条件为环比最近 1 分钟与前一分钟的重启次数指标 MAX 值之差。
- 检测频率:1 分钟执行一次检测。
- 触发条件:向上对比,差值大于 0 触发检测;检测对比重启次数相差超过 1 个发出警告事件,超过 2 个重要事件,超过 3 个发出紧急事件。
场景四:通过 ebpf 获取网络数据后,监控网络请求量突变
DataKit 开启 ebpf 采集后,可以采集到 4层/7层网络数据,通过分析 httpflow 下的 count 指标,可以达到监控接口请求量突增需求,配置详情如下。
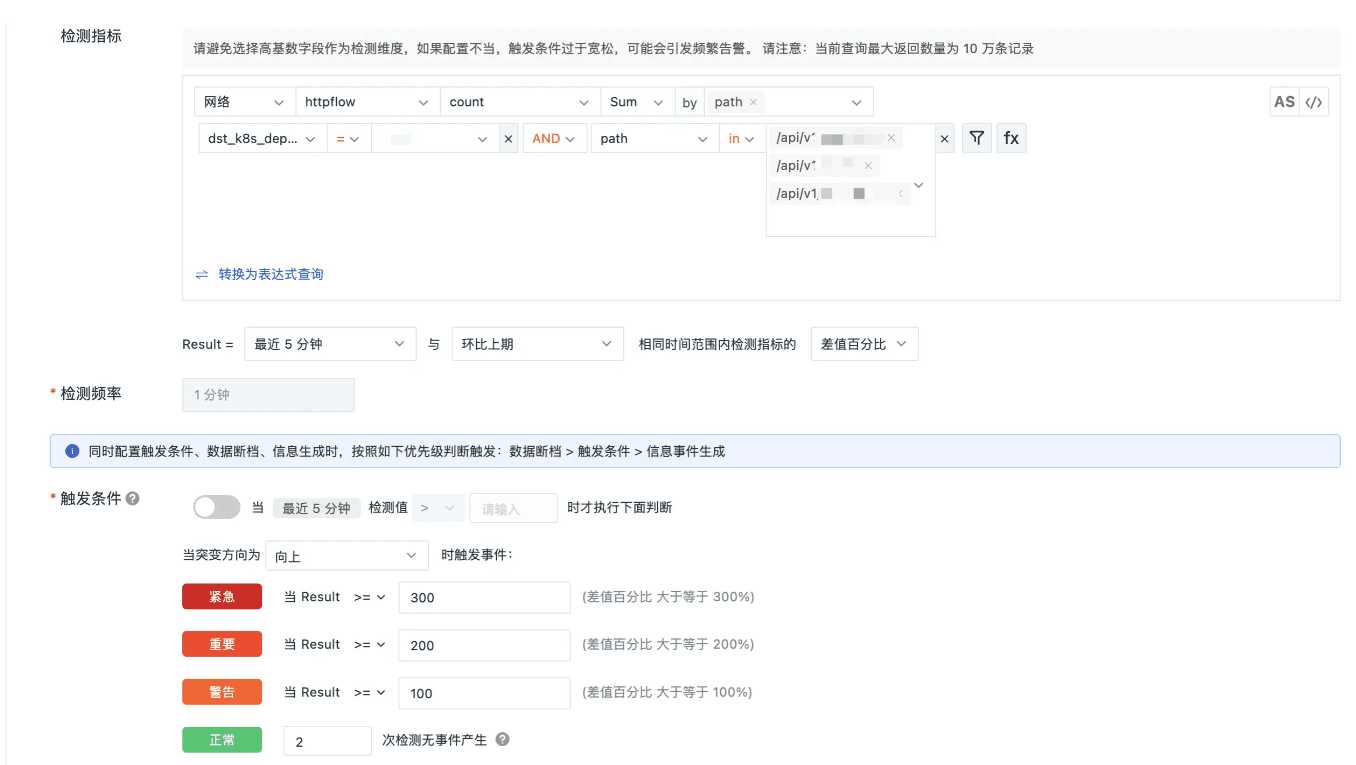
配置详解
- 监控条件配置: 过滤部署组名称为***,请求的接口地址路径包含***。
- 差值百分比:监控触发条件为环比上期最近5分钟与前5分钟差值的百分比。
- 检测频率:5 分钟执行一次检测。
- 触发条件:差值百分比进行判断,向上含义为差值百分比大于 0 时,触发检测;对比请求量相差增加 100% 发出警告事件,增加 200% 发出重要事件,增加 300% 发出紧急事件。
使用效果
告警基础属性数据

告警状态&趋势数据