背景
随着业务的增加,数据集成任务大量增长,越来越多的数据源的需要支持,原有的系统已经无法完全支撑现有体量。

现有的数据集成平台短板慢慢展现导致部分业务线无法快速对接。数据源的架构在变得繁多和复杂,数据应用也逐渐变得更加垂直和场景化,这也倒逼了现代数据架构飞速发展。从而数据集成已经从一项技术管理工作升级为系统工程。
整体方案
对于整套系统的实施,我们首先对以下核心事情的做了处理:
确定数据集成的目标和范围
目前公司有大量的任务是基于 Trino 和 Kyuubi 这两个开源组件进行数据查询的加速和一站式 SQL 的统一管理,由于有大量的任务已经接入到系统中,这需要新的系统直接适配以前的任务 ,并进行自动迁移工作。
选择适合的数据集成工具和技术
在选择数据集成工具和技术时,需要考虑与原有系统无缝集成的工作量以及可持续性扩展的效率。
选型可以参考这篇文章:https://mp.weixin.qq.com/s/nFF31Rc3E0ia5jAl2ibRPw
我们经过一些开源软件的对比,在底层支撑系统中我们选择了数据集成工具的新起之秀 Apache SeaTunnel 和 Dinky 这两个开源软件。
虽然在选择 Apache SeaTunnel 的时候,当时还未支持这两个组件,但是我们还是决定进行二次开发以便对其支持。
Apache SeaTunnel 集成
我们在 SeaTunnel 中提供了对 Trino 和 Kyuubi 的 JDBC ⽀ 持⽅式,⽬前只实现了对 SOURCE 端的⽀持。
在 SeaTunnel 中对组件的 JDBC ⽀持⽅式实现很简单,我们可以参考 MySQL 的实现⽅式来实现它。
构建⽀持 Trino 的 Dialect
Dialect 需要实现 JdbcDialect 和 JdbcDialectFactory 这两个接⼝类。
TrinoDialect 的实现代码如下:
@Override
public String dialectName() {
return "Trino";
}
@Override
public JdbcRowConverter getRowConverter() {
return new TrinoJdbcRowConverter();
}
@Override
public JdbcDialectTypeMapper getJdbcDialectTypeMapper() {
return new TrinoTypeMapper();
}PrestoDialectFactory 的实现代码:
@Override
public boolean acceptsURL(@NonNull String url) {
// 通过 jdbc:presto 实现对 Presto 的⽀持
return url.startsWith("jdbc:presto:") || url.startsWith("jdbc:trino:");
}
@Override
public JdbcDialect create() {
return new TrinoDialect();
}需要注意的是:我们在代码中也同时⽀持了
Presto
构建 Trino 数据类型转换器
数据类型转换器实现⽐较简单,核⼼就是对数据类型的⽀持,以下是部分实现代码:
@Override
public SeatunnelDataType<?> mapping(ResultSetMetaData metadata, int colIndex) throws SQLException {
String columnType = metadata.getColumnTypeName(colIndex).toUpperCase();
// VARCHAR(x) ---> VARCHAR
if (columnType.indexOf("(") > -1) {
columnType = columnType.split("\\(")[0];
}
int precision = metadata.getPrecision(colIndex);
int scale = metadata.getScale(colIndex);
switch (columnType) {
case PRESTO_BOOLEAN:
return BasicType.BOOLEAN_TYPE;
case PRESTO_TINYINT:
return BasicType.BYTE_TYPE;
case PRESTO_INTEGER:
return BasicType.INT_TYPE;
case PRESTO_SMALLINT:
return BasicType.SHORT_TYPE;
case PRESTO_BIGINT:
return BasicType.LONG_TYPE;
case PRESTO_DECIMAL:
return new DecimalType(precision, scale);
case PRESTO_REAL:
return BasicType.FLOAT_TYPE;
case PRESTO_DOUBLE:
return BasicType.DOUBLE_TYPE;
case PRESTO_CHAR:
case PRESTO_VARCHAR:
case PRESTO_JSON:
case PRESTO_ARRAY:
return BasicType.STRING_TYPE;
case PRESTO_DATE:
return LocalTimeType.LOCAL_DATE_TYPE;
case PRESTO_TIME:
return LocalTimeType.LOCAL_TIME_TYPE;
case PRESTO_TIMESTAMP:
return LocalTimeType.LOCAL_DATE_TIME_TYPE;
case PRESTO_VARBINARY:
case PRESTO_BINARY:
return PrimitiveByteArrayType.INSTANCE;
//Doesn't support yet
case PRESTO_MAP:
case PRESTO_ROW:
default:
final String jdbcColumnName = metadata.getColumnName(colIndex);
throw new JdbcConnectorException(CommonErrorCode.UNSUPPORTED_OPERATION,
String.format(
"Doesn't support Trino type '%s' on column '%s' yet.",
columnType, jdbcColumnName));
}
}需要注意的是:需要我们特殊处理
VARCHAR(x)这种带有位数的数据类型。
⽀持 TIMESTAMP WITH TIME ZONE
如果我们在编写的 SQL 中指定了时区后,默认在 SeaTunnel 框架中是不⽀持的,我们需要修改从⽽⽀持它。
修改 org.apache.seatunnel.api.table.type.LocalTimeType ⽀持携带时区
public static final LocalTimeType<LocalDateTime>
LOCAL_DATE_TIME_TYPE_WITH_ZONE = new LocalTimeType<>(LocalDateTime.class, SqlType.TIMESTAMP);修改对应于 Spark 或 Flink 中的 TypeConverterUtils 进⾏⽀持它。需要注意对时区的截取以及设置。
Kyuubi的对接集成和Trino⽅式⼀致。
设计实践
以下为数据集成平台架构图:
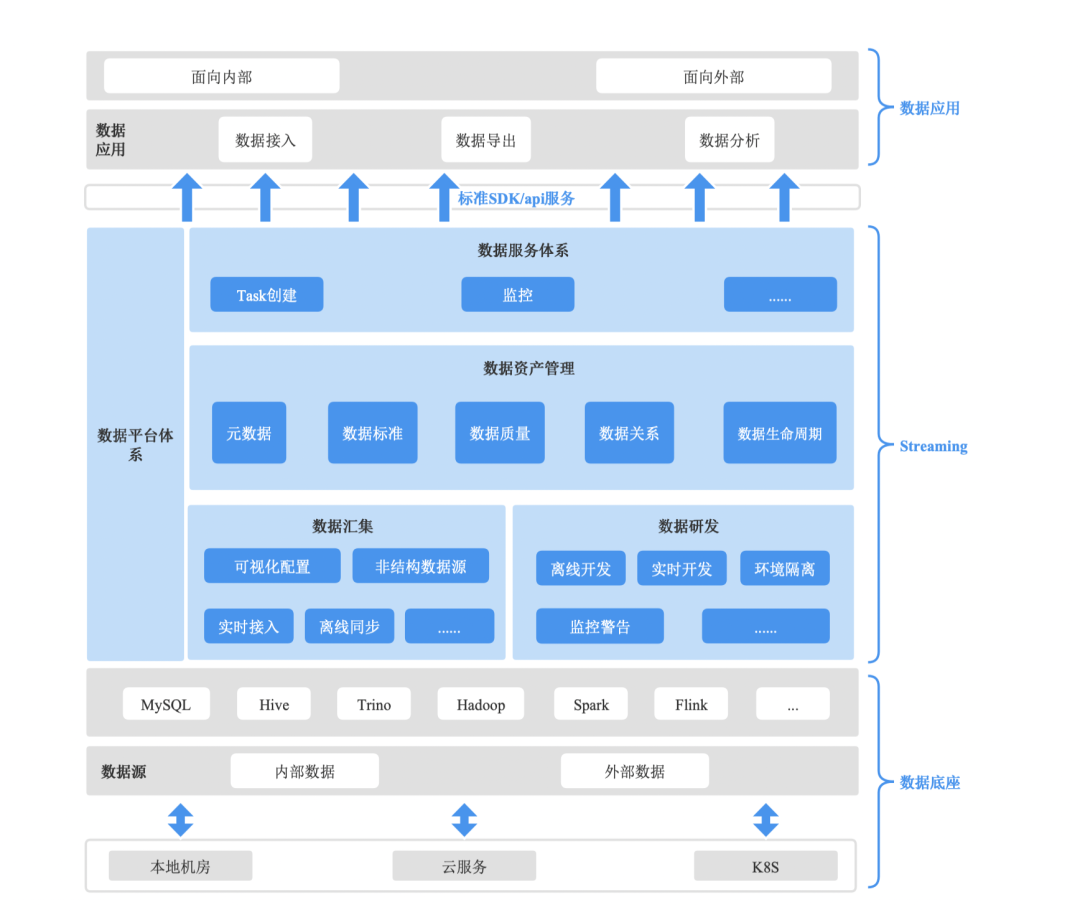
通过架构图我们可以看出我们的数据集成平台功能还是比较完善的,核心分为:
-
数据服务体系
-
数据资产管理
-
数据汇集
-
数据研发
-
数据监控等
通过各个模块的整合以及资源的调整我们可以使用平台做出一条完善的数据链路。
下图为任务的具体发布流程:
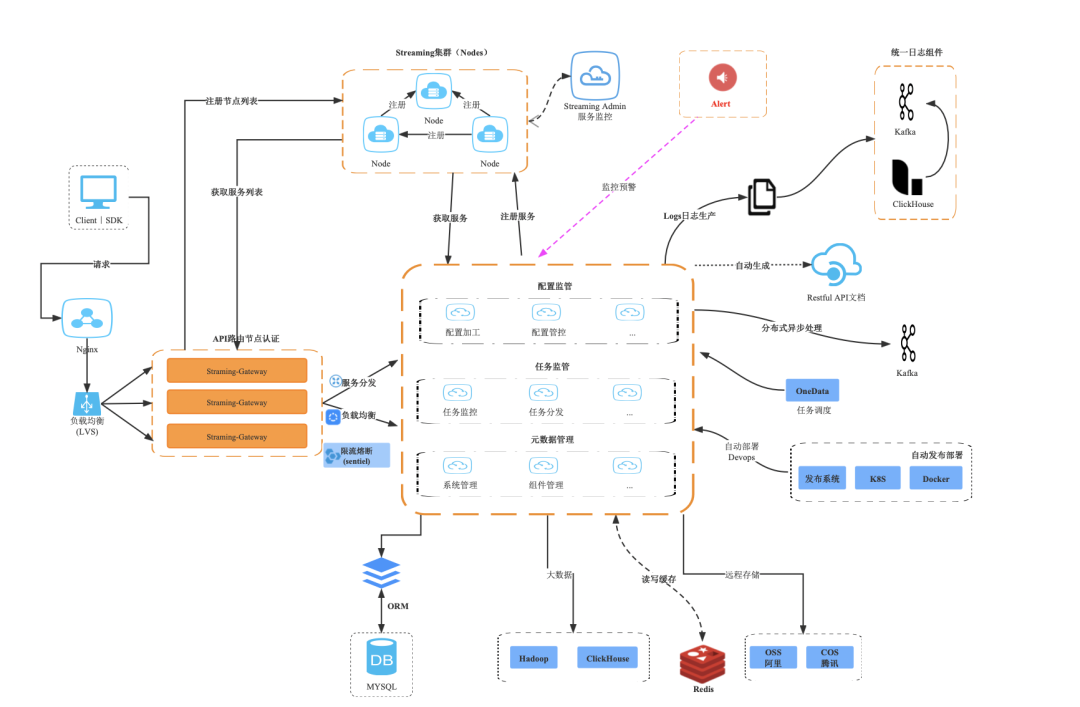
当客户端发起请求后,主节点会获取已经注册的 Nodes 列表,通过 Gateway 校验 API 是否可用,此时会获取到某个 Node 作为任务分发的主节点,在该节点中会自动配置当前任务的一些监管控制等逻辑,在任务执行期间会产生 Log Driver, Monitor Driver, Resource Driver 等多个 Driver 驱动器用于管理和监控任务的生命周期。
当任务执行结束后,系统会根据用户指定的配置进行最终任务的状态分发并做销毁,从而一整条任务的流水线构建完成。
发布任务
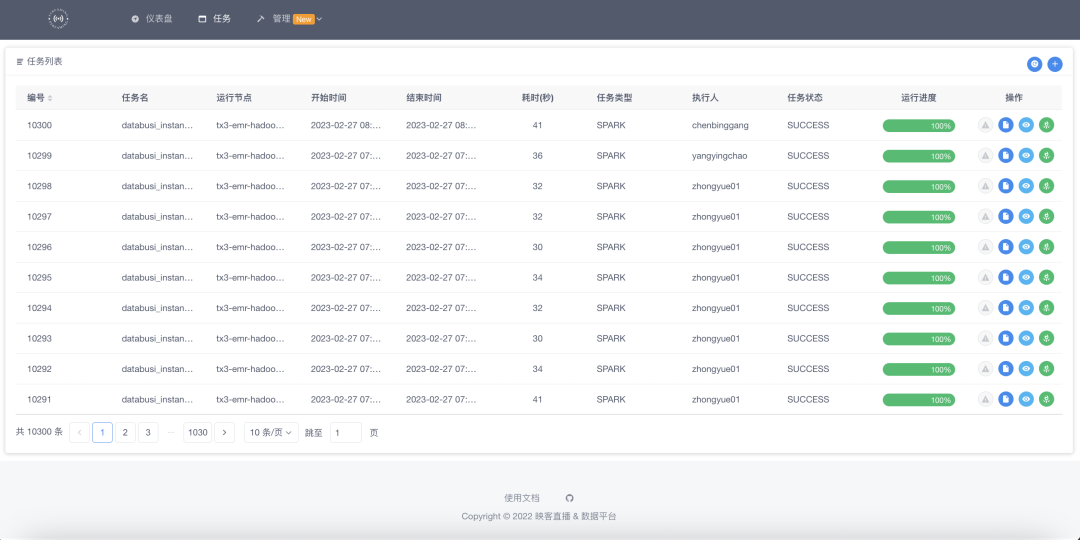
平台提供了数据任务的一整套流水线,通过新任务构建我们可以支持在平台中发布一个新任务,该任务会集成监控,资源管理等功能。
以上是平台的一个任务展示列表,我们通过模拟一个新的任务来进行平台的体验。
在平台中我们的任务接入方式很简单,分为:
-
DSL 介入
-
SQL 接入 (实验功能)
以下是一个任务的 DSL 参数,他模拟通过查询 Presto 将数据写入到 ClickHouse 中,并提供给用户查询
{
"appKey": "datateam",
"deployMode": "yarn",
"username": "demo",
"taskName": "datateam_demo_first_task",
"timeout": 900,
"sources": [
{
"source": "Jdbc",
"configure": [
{
"field": "host",
"value": "localhost",
"split": false
},
{
"field": "port",
"value": "8080",
"split": false
},
{
"field": "type",
"value": "presto",
"split": false
},
{
"field": "user",
"value": "default",
"split": false
},
{
"field": "query",
"value": "select 'xxx' as name, 12 as age",
"split": false
},
{
"field": "result_table_name",
"value": "datateam_demo_first_task_presto_source",
"split": false
},
{
"field": "fields",
"value": [
{
"column": "name",
"origin": "名称",
"type": "string"
},
{
"column": "age",
"origin": null,
"type": "int"
}
],
"split": true
}
]
}
],
"sinks": [
{
"sink": "Clickhouse",
"configure": [
{
"field": "host",
"value": "127.0.0.1",
"split": false
},
{
"field": "port",
"value": "9000",
"split": false
},
{
"field": "database",
"value": "test",
"split": false
},
{
"field": "table",
"value": "datateam_demo_first_task",
"split": false
},
{
"field": "columns",
"value": [
"name",
"age"
],
"split": false
}
]
}
],
"hooks": [
{
"hook": "Kafka",
"rule": "SUCCESS",
"configure": [
{
"field": "format",
"value": "JSON"
}
]
}
],
"platform": "Data"
}只需要这样一个简单的 JSON 配置即可实现查询 Presto 将数据写入到 ClickHouse 中, 并会将最终的写入结果以 JSON 形式发送到指定的 Kafka Hook 中。
通过以上配置平台生成一个任务并分发到集群中,并执行设置的内容,在该 DSL 中我们设置的是 SQL,平台会在集群中去执行我们输入的 SQL 内容。
当然平台提供还提供 SQL 方式接入,我们只需要编写一个简单的 SQL 即可实现任务的接入,以下是一个简单的任务 SQL
CREATE TASK `datateam_demo_first_task`
WITH INPUT Jdbc (
url=`localhost`,
port=`8080`,
type=`presto`,
username=`default`,
result_table_name=`datateam_demo_first_task_presto_source`,
fields={
format=`name`|`名称`
}
)
WITH OUTPUT Clickhouse(
host=`127.0.0.1`,
port=`8123`,
database=default,
columns=[`name`, `age`]
)
WITH HOOK Kafka(
rule=`SUCCESS`,
fields={
format=`JSON`
}
)
WITH QUREY
select 'xxx' as name, 12 as age系统会通过解析 SQL Node 将配置转化为可执行参数从而进行发布任务。
日志管理 Log Driver
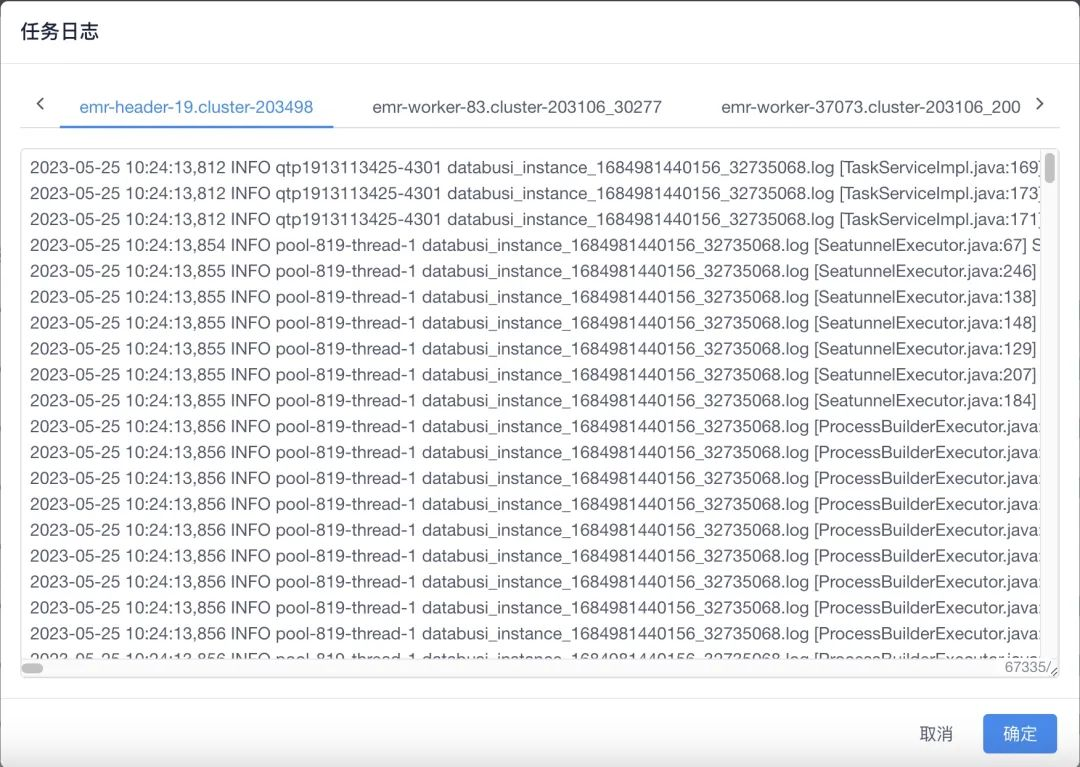
系统中有丰富的任务日志管理,不仅仅包含提交机执行的详细日志还包含集群中运行的详细日志。
当任务发布后,系统默认会构建 Log Driver 他会去采集集群中当前任务的运行日志,直到任务运行结束 Log Driver 回随即销毁。Log Driver 销毁后系统默认会调用并解析 Log Aggregation 来获取集群最终运行状态,从而将其更新至底层存储中。
超时及重试机制 Monitor Driver
当任务发布成功后系统会启动一个 Monitor Driver, 他主要用于对该任务的的一些监控操作,其中最核心的就是超时和重试机制。
- 超时机制
用户可以指定 timeout 参数用来配置当前任务的超时时间,一般当系统中任务较多或节点负载较高时,在任务发布时系统会自动抽取相关任务一周内执行记录,通过分析该执行记录(执行消耗资源,消耗时间等)进行 timeout 参数的重新设定,从而适配当前任务的执行过程不受外部依赖所影响导致任务异常退出。
- 重试机制
重试机制一般不会被触发。他拥有两种模式,分别是自动与手动。在自动模式中只有运行状态 FAILURE 并且异常信息触发系统默认指定重试规则才会被应用。手动模式中用户可以配置自定义重试规则。两种模式可以并存,默认手动模式会覆盖自动模式。
当然
Monitor Driver负责的不只是超时和重试,还会负责任务执行中的一些流程。当然包含了整个任务的生命周期,从任务的构建到任务的结束以及数据的落地都有实时响应以及反馈。
资源管控 Resource Driver
每个任务拥有独立的 Resource Driver, 当任务执行完成后 Resource Driver 随即启动,他会采集当前任务在集群中所使用的资源信息,以下是一个资源图
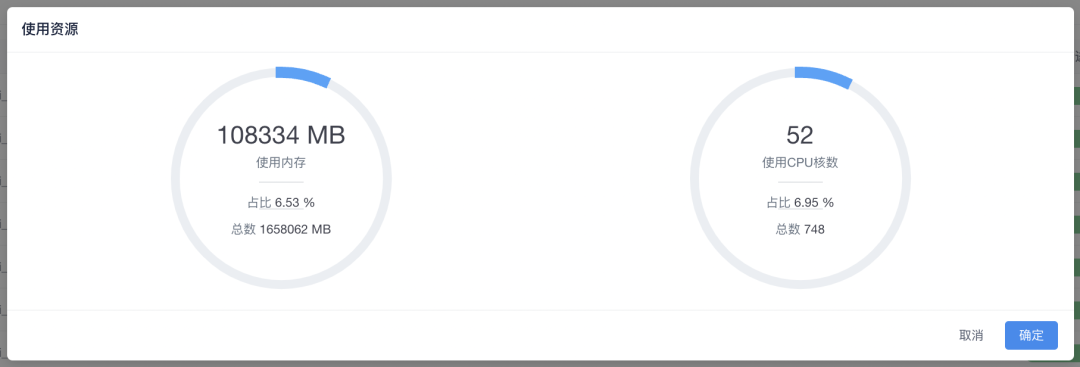
我们可以清楚的看到该任务消耗的内存以及 CPU。
未来展望
流式任务
目前平台大多都是批处理任务,但是会有一些流式任务,目前只是一些简单的方式实现,还没有完善的 Driver 体系,无法完整的监管其生命周期,后续会对该类型任务推出完善的 Driver 机制。
优化接入方式
目前大部分任务对接还是基于 DSL 方式,这样导致数据分析人员以及数仓人员无法快速对接平台,虽然推出 SQL 方式但目前还是实验功能,后续将会完善并将其完全引入系统中。
本文由 白鲸开源科技 提供发布支持!