目录
[一. 环境准备](#一. 环境准备)
[二. 安装Docker](#二. 安装Docker)
[三. admin节点安装cephadm](#三. admin节点安装cephadm)
[四. admin节点给另外四个主机导入镜像](#四. admin节点给另外四个主机导入镜像)
[五. 向集群中添加节点](#五. 向集群中添加节点)
[六. Ceph使用](#六. Ceph使用)
[检查 OSD 状态](#检查 OSD 状态)
[Ceph 集群中添加一个新的 OSD](#Ceph 集群中添加一个新的 OSD)
[列出当前 Ceph 集群中的所有数据池的名称](#列出当前 Ceph 集群中的所有数据池的名称)
[创建ODS pool](#创建ODS pool)
[RBD(RADOS Block Device)概述](#RBD(RADOS Block Device)概述)
[RBD 的主要特性](#RBD 的主要特性)
一. 环境准备
(实际实验磁盘远用不了这么多,自行按需给大小,但是数量就按照配置来实验)
|-----------|----------------|-----------------|----------------|-------------------------|-------------------------------------------|
| 节点 | 主机名 | IP | 系统 | 系统配置 | 软件版本 |
| admin | ceph-storage01 | 192.168.226.151 | rocky_linux9.4 | 2核4G内存根分区50G 两个各20G的空磁盘 | ceph version 18.2.3 Docker version 27.1.1 |
| | ceph-storage02 | 192.168.226.152 | rocky_linux9.4 | 2核4G内存根分区50G 两个各20G的空磁盘 | Docker version 27.1.1 |
| | ceph-storage03 | 192.168.226.153 | rocky_linux9.4 | 2核4G内存根分区50G 两个各20G的空磁盘 | Docker version 27.1.1 |
| | ceph-storage04 | 192.168.226.154 | rocky_linux9.4 | 2核4G内存根分区50G 两个各20G的空磁盘 | Docker version 27.1.1 |
| | ceph-storage05 | 192.168.226.155 | | 2核4G内存根分区50G 两个各20G的空磁盘 | Docker version 27.1.1 |
都需要进行关闭防火墙和selinux,进行时间同步,分别使用固定IP,下述为自动化脚本。
bash
#!/bin/bash
# 检查是否以 root 用户运行脚本
if [ "$(id -u)" -ne 0 ]; then
tput bold
tput setaf 1
tput setaf 3
echo "请以 root 用户运行此脚本。"
tput sgr0
exit 1
fi
# 启用网络接口
enable_network_interface() {
local interface=$1
if ip link set "$interface" up; then
tput bold
tput setaf 2
echo "网络接口 $interface 已启用。"
tput sgr0
else
tput bold
tput setaf 1
echo "无法启用网络接口 $interface,请检查接口名称。"
tput sgr0
exit 1
fi
}
# 配置 YUM 源
configure_yum_repos() {
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' \
-i.bak \
/etc/yum.repos.d/rocky*.repo
tput bold
tput setaf 2
echo "YUM 源配置已更新。"
tput sgr0
dnf makecache
yum -y install epel-release
}
# 停止和禁用防火墙,禁用 SELinux
configure_security() {
systemctl stop firewalld && systemctl disable firewalld
firewall-cmd --reload
tput bold
tput setaf 2
echo "防火墙已停止并禁用。"
tput sgr0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
tput bold
tput setaf 2
echo "SELinux 已禁用。"
tput sgr0
}
# 检查并安装chrony,进行时间同步
function install_and_sync_time_with_chrony() {
# 检查是否已经安装chrony
if ! command -v chronyd &>/dev/null; then
sudo dnf install -y chrony &> /dev/null
# 检查安装是否成功
if ! command -v chronyd &>/dev/null; then
tput bold
tput setaf 1
echo "安装 chrony 失败。请检查您的包管理器并重试。"
tput sgr0
exit 1
else
tput bold
tput setaf 2
echo "chrony 安装成功。"
tput sgr0
fi
else
tput bold
tput setaf 2
echo "chrony 已安装。"
tput sgr0
fi
# 配置windows的时间服务
echo "server time.windows.com iburst" | sudo tee -a /etc/chrony.conf
# 确保安装其他必要的软件包
sudo dnf install -y vim wget unzip tar lrzsz &> /dev/null
if [ $? -eq 0 ]; then
tput bold
tput setaf 2
echo "其他软件包安装成功。"
tput sgr0
else
tput bold
tput setaf 1
echo "安装其他软件包失败。"
tput sgr0
exit 1
fi
# 启动 chronyd 服务并启用开机启动
if sudo systemctl enable --now chronyd && sudo systemctl restart chronyd; then
tput bold
tput setaf 2
echo "chronyd 服务已成功启动并设置为开机启动。"
tput sgr0
else
tput bold
tput setaf 1
echo "启动或启用 chronyd 服务失败。请检查 systemctl 状态。"
tput sgr0
exit 1
fi
# 强制同步时间
sudo chronyc -a makestep
tput bold
tput setaf 2
echo "时间同步已成功完成。"
tput sgr0
}
# 自定义 IP 地址
configure_ip_address() {
tput bold
tput blink
tput setaf 1
read -p "******输入你要设置的IP >>> : " ip_a
tput sgr0
tput bold
tput blink
tput setaf 6
read -p "******输入你要设置的网关>>> : " gat
tput sgr0
tput bold
tput blink
tput setaf 3
read -p "******输入你要设置的DNS>>> : " dnns
tput sgr0
# 判断当前连接的名字
connection_name=$(nmcli -t -f NAME,DEVICE con show --active | grep -E "ens33|Wired connection 1" | cut -d: -f1)
if [[ "$connection_name" == "ens33" ]]; then
# 针对 ens33 连接进行配置
nmcli con mod "ens33" ipv4.method manual ipv4.addresses "${ip_a}/24" ipv4.gateway "${gat}" ipv4.dns "${dnns}" autoconnect yes
elif [[ "$connection_name" == "Wired connection 1" ]]; then
# 针对 Wired connection 1 连接进行配置
nmcli con mod "Wired connection 1" ipv4.method manual ipv4.addresses "${ip_a}/24" ipv4.gateway "${gat}" ipv4.dns "${dnns}" autoconnect yes
else
tput bold
tput setaf 1
echo "无法识别的网络连接名称:$connection_name"
tput sgr0
return 1
fi
tput setab 5
tput setaf 15
tput bold
echo "IP 地址配置成功,即将重启系统。"
tput sgr0
nmcli con up "$connection_name"
reboot
}
# 主函数
main() {
local interface="ens33"
enable_network_interface "$interface"
configure_yum_repos
configure_security
install_and_sync_time_with_chrony
configure_ip_address "$interface"
}
# 调用主函数
main修改主机名
bash
# 192.168.226.151
[root@bogon ~]# nmcli g hostname ceph-storage01
# 192.168.226.152
[root@bogon ~]# nmcli g hostname ceph-storage02
# 192.168.226.153
[root@bogon ~]# nmcli g hostname ceph-storage03
# 192.168.226.154
[root@bogon ~]# nmcli g hostname ceph-storage04
# 192.168.226.155
[root@bogon ~]# nmcli g hostname ceph-storage05给五台机器都配置本地解析
bash
[root@ceph-storage01 ~]# cat >> /etc/hosts << EOF
192.168.226.151 ceph-storage01
192.168.226.152 ceph-storage02
192.168.226.153 ceph-storage03
192.168.226.154 ceph-storage04
192.168.226.155 ceph-storage05
EOF配置五台机器SSH互信
bash
# 只需在ceph-storage01操作即可,然后将生成的SSH拷贝到其它主机
[root@ceph-storage01 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa
Your public key has been saved in /root/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:J7aLJBfaWswFptu6rLr80BGhWxsjTp9TYmZfMTgA9tg root@ceph-storage01
The key's randomart image is:
+---[RSA 3072]----+
| o.o. .o |
|. = .o o |
| = E .+. |
|o O Xo.. |
| o *... S . |
| . oB + + |
| . .+ O . |
|. .. B . . |
|o+oo=.. . |
+----[SHA256]-----+
[root@ceph-storage01 ~]# ssh-copy-id ceph-storage01
[root@ceph-storage01 ~]# scp -r .ssh ceph-storage02:/root/
[root@ceph-storage01 ~]# scp -r .ssh ceph-storage03:/root/
[root@ceph-storage01 ~]# scp -r .ssh ceph-storage04:/root/
[root@ceph-storage01 ~]# scp -r .ssh ceph-storage05:/root/二. 安装Docker
Docker五台服务器都需要安装
清理docker环境,避免错误
bash
[root@ceph-storage01 ~]# sudo yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engine
No match for argument: docker
No match for argument: docker-client
No match for argument: docker-client-latest
No match for argument: docker-common
No match for argument: docker-latest
No match for argument: docker-latest-logrotate
No match for argument: docker-logrotate
No match for argument: docker-engine
No packages marked for removal.
Dependencies resolved.
Nothing to do.
Complete!
[root@ceph-storage01 ~]# rm -rf /etc/systemd/system/docker.service.d
[root@ceph-storage01 ~]# rm -rf /var/lib/docker
[root@ceph-storage01 ~]# rm -rf /var/run/docker
[root@ceph-storage01 ~]# rpm -qa | grep docker
[root@ceph-storage01 ~]# yum remove -y docker-*
No match for argument: docker-*
No packages marked for removal.
Dependencies resolved.
Nothing to do.
Complete!安装
bash
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
# Step 4: 更新并安装Docker-CE
sudo yum makecache
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo service docker start配置镜像加速器
bash
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.rainbond.cc" ,
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://pilvpemn.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker三. admin节点安装cephadm
选择第一台主机做admin节点,安装cephadm
bash
[root@ceph-storage01 ~]# dnf search release-ceph
[root@ceph-storage01 ~]# dnf install --assumeyes centos-release-ceph-reef
[root@ceph-storage01 ~]# dnf install --assumeyes cephadm
# 通过运行以下命令来确认cephadm现在位于你的环境变量中:
[root@ceph-storage01 ~]# which cephadm
/usr/sbin/cephadm如果没有安装成功cephadm,则执行本命令
bash
sudo dnf clean all
sudo dnf makecache
sudo dnf install cephadm -y在admin节点主机初始化集群
bash
[root@ceph-storage01 ~]# cephadm bootstrap --mon-ip 192.168.226.151 --initial-dashboard-user admin --initial-dashboard-password 123456
bash
[root@ceph-storage01 ~]# ss -tnlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 5 192.168.226.151:8765 0.0.0.0:* users:(("ceph-mgr",pid=5378,fd=45))
LISTEN 0 512 192.168.226.151:6789 0.0.0.0:* users:(("ceph-mon",pid=5186,fd=28))
LISTEN 0 512 0.0.0.0:6800 0.0.0.0:* users:(("ceph-mgr",pid=5378,fd=27))
LISTEN 0 512 0.0.0.0:6801 0.0.0.0:* users:(("ceph-mgr",pid=5378,fd=28))
LISTEN 0 5 192.168.226.151:7150 0.0.0.0:* users:(("ceph-mgr",pid=5378,fd=48))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=828,fd=3))
LISTEN 0 4096 0.0.0.0:9926 0.0.0.0:* users:(("ceph-exporter",pid=13547,fd=22))
LISTEN 0 512 192.168.226.151:3300 0.0.0.0:* users:(("ceph-mon",pid=5186,fd=27))
LISTEN 0 4096 *:9094 *:* users:(("alertmanager",pid=14417,fd=3))
LISTEN 0 4096 *:9093 *:* users:(("alertmanager",pid=14417,fd=8))
LISTEN 0 4096 *:9100 *:* users:(("node_exporter",pid=14051,fd=3))
LISTEN 0 5 *:8443 *:* users:(("ceph-mgr",pid=5378,fd=58))
LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=828,fd=4))
bash
[root@ceph-storage01 ~]# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v18 2bc0b0f4375d 2 weeks ago 1.25 GB
quay.io/ceph/ceph-grafana 9.4.7 954c08fa6188 8 months ago 647 MB
quay.io/prometheus/prometheus v2.43.0 a07b618ecd1d 16 months ago 235 MB
quay.io/prometheus/alertmanager v0.25.0 c8568f914cd2 19 months ago 66.5 MB
quay.io/prometheus/node-exporter v1.5.0 0da6a335fe13 20 months ago 23.9 MB日志目录位置:/var/log/ceph/cephadm.log
浏览器访问https://IP+8443端口 :例如我这里访问https://192.168.226.151:8443/
这里切记加上https://否则访问不到
用户名:admin
密码:123456






四. admin节点给另外四个主机导入镜像
将 ceph-storage01主机上podman中下载好的五个镜像,分别打包并导入另外四个集群的docker中。
这里我提供了三个脚本,podman批量打包导入脚本,批量远程用户拷贝目录脚本,docker镜像的批量打包导入脚本
bash
#!/bin/bash
# podman镜像打包与导入脚本
# 颜色和样式设置
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[0;33m'
BLUE='\033[0;34m'
BOLD='\033[1m'
RESET='\033[0m'
# 函数:创建目录(如果不存在的话)
create_directory() {
local dir="$1"
if [ ! -d "$dir" ]; then
echo -e "${YELLOW}${BOLD}目录 $dir 不存在. 正在创建...${RESET}"
mkdir -p "$dir"
fi
}
# 函数:将字符 ':' 和 '/' 替换为 '_',以便创建有效的文件名
sanitize_filename() {
echo "$1" | sed 's/:/_/g; s/\//_/g'
}
# 函数:打包所有镜像到指定目录
package_all_images() {
local dest_dir="$1"
create_directory "$dest_dir"
echo -e "${BLUE}${BOLD}正在列出所有镜像...${RESET}"
images=$(podman images --format "{{.Repository}}:{{.Tag}}")
for image in $images; do
local filename=$(sanitize_filename "$image")
local filepath="$dest_dir/$filename.tar"
echo -e "${GREEN}${BOLD}正在保存 $image 到 $filepath...${RESET}"
podman save -o "$filepath" "$image"
if [ $? -eq 0 ]; then
echo -e "${GREEN}${BOLD}$image 已成功保存为 $filepath${RESET}"
else
echo -e "${RED}${BOLD}$image 保存失败${RESET}"
fi
done
echo -e "${GREEN}${BOLD}所有镜像已打包到 $dest_dir。${RESET}"
}
# 函数:打包指定镜像到指定目录
package_specific_image() {
local image="$1"
local dest_dir="$2"
create_directory "$dest_dir"
local filename=$(sanitize_filename "$image")
local filepath="$dest_dir/$filename.tar"
echo -e "${GREEN}${BOLD}正在保存 $image 到 $filepath...${RESET}"
podman save -o "$filepath" "$image"
if [ $? -eq 0 ]; then
echo -e "${GREEN}${BOLD}镜像 $image 已打包到 $dest_dir。${RESET}"
else
echo -e "${RED}${BOLD}镜像 $image 打包失败${RESET}"
fi
}
# 函数:从指定目录导入镜像
import_images() {
local src_dir="$1"
if [ ! -d "$src_dir" ]; then
echo -e "${RED}${BOLD}目录 $src_dir 不存在. 退出...${RESET}"
exit 1
fi
echo -e "${BLUE}${BOLD}正在从 $src_dir 导入镜像...${RESET}"
for tar_file in "$src_dir"/*.tar; do
if [ -f "$tar_file" ]; then
echo -e "${GREEN}${BOLD}正在导入 $tar_file...${RESET}"
podman load -i "$tar_file"
if [ $? -eq 0 ]; then
echo -e "${GREEN}${BOLD}镜像 $tar_file 成功导入${RESET}"
else
echo -e "${RED}${BOLD}镜像 $tar_file 导入失败${RESET}"
fi
else
echo -e "${YELLOW}${BOLD}文件 $tar_file 不存在${RESET}"
fi
done
echo -e "${GREEN}${BOLD}所有镜像已从 $src_dir 导入。${RESET}"
}
# 主脚本逻辑
echo -e "${BLUE}${BOLD}请选择一个选项:${RESET}"
echo -e "${BLUE}1. 将所有镜像打包到指定目录${RESET}"
echo -e "${BLUE}2. 将指定镜像打包到指定目录${RESET}"
echo -e "${BLUE}3. 从指定目录导入镜像${RESET}"
read -r option
case $option in
1)
echo -e "${BLUE}请输入目标目录:${RESET}"
read -r dest_dir
package_all_images "$dest_dir"
;;
2)
echo -e "${BLUE}请输入镜像名称(例如 'ubuntu:latest'):${RESET}"
read -r image_name
echo -e "${BLUE}请输入目标目录:${RESET}"
read -r dest_dir
package_specific_image "$image_name" "$dest_dir"
;;
3)
echo -e "${BLUE}请输入包含 tar 文件的源目录:${RESET}"
read -r src_dir
import_images "$src_dir"
;;
*)
echo -e "${RED}${BOLD}无效的选项. 退出...${RESET}"
exit 1
;;
esac
bash
#!/bin/bash
#一键传输脚本
# 源目录路径
SOURCE_DIR="/data"
# 目标目录路径(在远程主机上)
TARGET_DIR="/data"
# 读取主机列表文件
HOSTS_FILE="hosts.txt"
# SSH用户名
SSH_USER="root"
# 检查主机列表文件是否存在
if [ ! -f "$HOSTS_FILE" ]; then
echo "主机列表文件 $HOSTS_FILE 不存在!"
exit 1
fi
# 读取主机列表并拷贝目录
while IFS= read -r host; do
echo "拷贝目录到主机:$host"
scp -r -o StrictHostKeyChecking=no "$SOURCE_DIR" "$SSH_USER"@$host:"$TARGET_DIR"
done < "$HOSTS_FILE"
bash
#!/bin/bash
# docker镜像批量打包和导入脚本
# 判断是否安装tar工具
if ! command -v tar &> /dev/null; then
sudo yum install -y tar &> /dev/null
fi
# 存储目录
output_dir="/data"
mkdir -p "$output_dir"
# 打包镜像
save_image() {
docker images --format "{{.Repository}} {{.Tag}}" | while read -r line; do
# 分离出仓库和标签
repository=$(echo "$line" | awk '{print $1}' | awk -F '/' '{print $NF}')
tag=$(echo "$line" | awk '{print $2}')
# 构建完整的镜像名称
full_image_name="$repository:$tag"
# 检查镜像是否为 <none>,如果是则跳过
if [ "$repository" = "<none>" ]; then
tput bold
tput setaf 5
echo "跳过 <none> repository: $tag"
tput sgr0
continue
fi
# 打包镜像
tar_file="${output_dir}/${repository}_${tag}.tar"
docker save -o "$tar_file" "$full_image_name"
if [ $? -eq 0 ]; then
tput bold
tput setaf 2
echo "$full_image_name 成功保存"
tput sgr0
else
tput bold
tput setaf 1
echo "$full_image_name 保存失败"
tput sgr0
fi
done
}
# 导入镜像
load_image() {
# 指定镜像包所在的目录
image_dir="$output_dir"
# 导入所有镜像包
for image_file in "${image_dir}"/*.tar; do
if [ -f "$image_file" ]; then
# 导入镜像
docker load -i "$image_file"
if [ $? -eq 0 ]; then
tput bold
tput setaf 2
echo "镜像 $(basename "$image_file" .tar) 成功导入"
tput sgr0
else
tput bold
tput setaf 1
echo "镜像 $(basename "$image_file" .tar) 导入失败"
tput sgr0
fi
else
tput bold
tput setaf 5
echo "镜像文件 $image_file 不存在"
tput sgr0
fi
done
}
# 提示用户选择操作,直到输入正确
while true; do
tput bold
tput smul
tput setaf 3
tput setab 0
read -p "请选择操作:$(tput setaf 6) 1. 打包镜像 $(tput setaf 4) 2. 导入镜像 $(tput setaf 2) q. 退出:" select
tput sgr0
case "$select" in
1)
save_image
break
;;
2)
load_image
break
;;
q)
exit
;;
*)
tput bold
tput setaf 5
tput blink
echo "输入错误,请输入 1 或 2"
tput sgr0
;;
esac
done五. 向集群中添加节点
本步骤仅在admin节点,也就是ceph-storage01主机操作,其他四条不用。
同步密钥
bash
[root@ceph-storage01 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-storage02
[root@ceph-storage01 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-storage03
[root@ceph-storage01 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-storage04
[root@ceph-storage01 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-storage05进入客户端工具
bash
[root@ceph-storage01 ~]# cephadm shell
Inferring fsid 62a58a62-561e-11ef-9dc4-000c29a2177e
Inferring config /var/lib/ceph/62a58a62-561e-11ef-9dc4-000c29a2177e/mon.ceph-storage01/config
Using ceph image with id '2bc0b0f4375d' and tag 'v18' created on 2024-07-23 22:19:35 +0000 UTC
quay.io/ceph/ceph@sha256:6ac7f923aa1d23b43248ce0ddec7e1388855ee3d00813b52c3172b0b23b37906
[ceph: root@ceph-storage01 /]#
# 查看当前集群中的节点
[ceph: root@ceph-storage01 /]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-storage01 192.168.226.151 _admin
1 hosts in cluster
[ceph: root@ceph-storage01 /]# 添加节点
bash
[ceph: root@ceph-storage01 /]# ceph orch host add ceph-storage02
Added host 'ceph-storage02' with addr '192.168.226.152'
[ceph: root@ceph-storage01 /]# ceph orch host add ceph-storage03
Added host 'ceph-storage03' with addr '192.168.226.153'
[ceph: root@ceph-storage01 /]# ceph orch host add ceph-storage04
Added host 'ceph-storage04' with addr '192.168.226.154'
[ceph: root@ceph-storage01 /]# ceph orch host add ceph-storage05
Added host 'ceph-storage05' with addr '192.168.226.155'
# 查看当前集群中的节点
[ceph: root@ceph-storage01 /]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-storage01 192.168.226.151 _admin
ceph-storage02 192.168.226.152
ceph-storage03 192.168.226.153
ceph-storage04 192.168.226.154
ceph-storage05 192.168.226.155
5 hosts in cluster手动添加节点为mon
bash
[ceph: root@ceph-storage01 /]# ceph orch apply mon --placement="ceph-storage01,ceph-storage02,ceph-storage03"
bash
# 给 ceph-storage01 主机添加 "mon" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage01 mon
# 输出: Added label mon to host ceph-storage01
# 给 ceph-storage02 主机添加 "mon" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage02 mon
# 输出: Added label mon to host ceph-storage02
# 给 ceph-storage03 主机添加 "mon" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage03 mon
# 输出: Added label mon to host ceph-storage03
# 给 ceph-storage01 主机添加 "mgr" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage01 mgr
# 输出: Added label mgr to host ceph-storage01
# 给 ceph-storage02 主机添加 "mgr" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage02 mgr
# 输出: Added label mgr to host ceph-storage02
# 给 ceph-storage01 主机添加 "mds" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage01 mds
# 输出: Added label mds to host ceph-storage01
# 给 ceph-storage04 主机添加 "mds" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage04 mds
# 输出: Added label mds to host ceph-storage04
# 给 ceph-storage05 主机添加 "mds" 标签
[ceph: root@ceph-storage01 /]# ceph orch host label add ceph-storage05 mds
# 输出: Added label mds to host ceph-storage05
# 列出集群中所有主机及其标签和状态,可以用来检查标签是否已成功添加到主机上,并确认主机的角色分配是否符合预期。
[ceph: root@ceph-storage01 /]# ceph orch host ls
# 输出:
# HOST ADDR LABELS STATUS
# ceph-storage01 192.168.226.151 _admin,mon,mgr,mds
# ceph-storage02 192.168.226.152 mon,mgr
# ceph-storage03 192.168.226.153 mon
# ceph-storage04 192.168.226.154 mds
# ceph-storage05 192.168.226.155 mds
# 5 hosts in cluster
带有相同label的节点可以同时启动相同的服务,比如mds标签用于标识主机的角色或功能。例如,mon 标签表示监视器(Monitor)角色,mgr 表示管理器(Manager)角色,mds 表示元数据服务器(Metadata Server)角色。
标签分配结果
ceph-storage01: 拥有所有标签 (mon,mgr,mds),表示它被配置为多个角色的主机。ceph-storage02: 具有mon和mgr标签,表示它同时承担监视器和管理器角色。ceph-storage03: 仅有mon标签,表示它是一个监视器主机。ceph-storage04: 只有mds标签,表示它是一个元数据服务器主机。ceph-storage05: 也只有mds标签,表示它也是一个元数据服务器主机。
六. Ceph使用
Ceph的使用,仅在admin节点管理操作即可。
列出可用设备
bash
# 列出 Ceph 集群中所有可用的存储设备及其状态。
[ceph: root@ceph-storage01 /]# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph-storage01 /dev/sdb hdd 50.0G No 43s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph-storage01 /dev/sdc hdd 20.0G Yes 43s ago
ceph-storage01 /dev/sdd hdd 20.0G Yes 43s ago
ceph-storage01 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 43s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph-storage02 /dev/sdb hdd 50.0G No 35s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph-storage02 /dev/sdc hdd 20.0G Yes 35s ago
ceph-storage02 /dev/sdd hdd 20.0G Yes 35s ago
ceph-storage02 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 35s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph-storage03 /dev/sdb hdd 50.0G No 36s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph-storage03 /dev/sdc hdd 20.0G Yes 36s ago
ceph-storage03 /dev/sdd hdd 20.0G Yes 36s ago
ceph-storage03 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 36s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph-storage04 /dev/sdb hdd 50.0G No 35s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph-storage04 /dev/sdc hdd 20.0G Yes 35s ago
ceph-storage04 /dev/sdd hdd 20.0G Yes 35s ago
ceph-storage04 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 35s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
ceph-storage05 /dev/sdb hdd 50.0G No 35s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph-storage05 /dev/sdc hdd 20.0G Yes 35s ago
ceph-storage05 /dev/sdd hdd 20.0G Yes 35s ago
ceph-storage05 /dev/sr0 hdd VMware_Virtual_SATA_CDRW_Drive_01000000000000000001 1023M No 35s ago Failed to determine if device is BlueStore, Insufficient space (<5GB)
以下是各字段的说明:
HOST: 设备所在的主机名。
PATH: 设备的路径,例如 /dev/sdb。
TYPE: 设备类型,通常为 hdd 或 ssd。
DEVICE ID: 设备的标识符或名称。
SIZE: 设备的总容量。
AVAILABLE: 设备是否可用。Yes 表示可用,No 表示不可用。
REFRESHED: 上次更新的时间。
REJECT REASONS: 设备不可用的原因,如有文件系统、空间不足、检测到LVM等。AVAILABLE 列的值应满足以下条件:
- 没有分区:设备上没有分区表。
- 没有LVM配置:设备未配置为LVM物理卷。
- 没有被挂载:设备未被挂载到任何目录。
- 没有文件系统:设备上没有现有的文件系统。
- 没有ceph bluestore osd:设备没有配置为Ceph BlueStore OSD。
- 大于5G:设备的总容量大于5GB。
在实际应用中,即会自动识别每台机器上的空硬盘,满足条件的会在AVAILABLE 列显示为yes
清除设备数据---针对有数据的设备
对于可以使用的硬盘,如何里面有数据,可以进行下述命令清楚数据
bash
# 使用 Ceph orchestrator 对指定设备进行 "zap" 操作
# `ceph orch device zap` 命令用于清除("zap")指定 Ceph 存储设备上的所有数据。
# 选项 `--force` 强制执行操作,即使设备上可能有数据。
# 在这个例子中,`/dev/sdc` 是目标设备,`ceph-storage02` 是执行操作的 Ceph 存储节点。
[ceph: root@ceph-storage01 /]# ceph orch device zap ceph-storage02 /dev/sdc --force
zap successful for /dev/sdc on ceph-storage02 # 操作成功的提示信息
# 表示设备 `/dev/sdc` 在节点 `ceph-storage02` 上的 "zap" 操作已经成功完成。
或者登录对应的机器执行
# sgdisk --zap-all /dev/sdd检查 OSD 状态
bash
[ceph: root@ceph-storage01 /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0 root default Ceph 集群中添加一个新的 OSD
bash
# 方法一:手动添加单个可用设备
[ceph: root@ceph-storage01 /]# ceph orch daemon add osd ceph-storage01:/dev/sdc
bash
# 方法二:一次性添加所有可用设备
[ceph: root@ceph-storage01 /]# ceph orch apply osd --all-available-devices
bash
# 再次查看 OSD 状态
[ceph: root@ceph-storage01 /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.19485 root default
-3 0.03897 host ceph-storage01
0 hdd 0.01949 osd.0 up 1.00000 1.00000
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-9 0.03897 host ceph-storage02
5 hdd 0.01949 osd.5 up 1.00000 1.00000
9 hdd 0.01949 osd.9 up 1.00000 1.00000
-5 0.03897 host ceph-storage03
3 hdd 0.01949 osd.3 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-11 0.03897 host ceph-storage04
2 hdd 0.01949 osd.2 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-7 0.03897 host ceph-storage05
4 hdd 0.01949 osd.4 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000查看集群的健康状态
bash
[ceph: root@ceph-storage01 /]# ceph -s
cluster:
id: 2091bd16-561f-11ef-85dc-000c29a2177e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-storage01,ceph-storage02,ceph-storage03 (age 5m)
mgr: ceph-storage02.abqgll(active, since 5m), standbys: ceph-storage01.mhqcff
osd: 10 osds: 10 up (since 74s), 10 in (since 94s)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 267 MiB used, 200 GiB / 200 GiB avail
pgs: 1 active+clean
[ceph: root@ceph-storage01 /]# ceph status
cluster:
id: 2091bd16-561f-11ef-85dc-000c29a2177e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-storage01,ceph-storage02,ceph-storage03 (age 21m)
mgr: ceph-storage02.abqgll(active, since 21m), standbys: ceph-storage01.mhqcff
osd: 10 osds: 10 up (since 17m), 10 in (since 17m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 267 MiB used, 200 GiB / 200 GiB avail
pgs: 1 active+clean指定MDS
MDS(Metadata Server,元数据服务器)在 Ceph 集群中负责处理文件系统的元数据。元数据是指文件系统的结构信息,例如文件的名称、权限、位置等,与实际的文件数据(即对象存储在 OSD 上)不同。
bash
# 部署mds进程
[ceph: root@ceph-storage01 /]# ceph orch apply mds myfs --placement="ceph-storage01,ceph-storage02,ceph-storage03"
Scheduled mds.myfs update...
# 列出 Ceph 集群中所有的 MDS(Metadata Server)守护进程的信息的命令。它显示了当前正在运行的 MDS 实例及其状态。
[ceph: root@ceph-storage01 /]# ceph orch ps --daemon_type mds
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
mds.myfs.ceph-storage01.weppfs ceph-storage01 running (8s) 6s ago 8s 12.9M - 18.2.4 2bc0b0f4375d a886ca09d667
mds.myfs.ceph-storage02.zsnsgl ceph-storage02 running (11s) 2s ago 11s 18.6M - 18.2.4 2bc0b0f4375d 16ca9dc7b79c
mds.myfs.ceph-storage03.pavvry ceph-storage03 running (10s) 2s ago 10s 17.4M - 18.2.4 2bc0b0f4375d 015b2cc627fa 列出当前 Ceph 集群中的所有数据池的名称
bash
[ceph: root@ceph-storage01 /]# ceph osd pool ls
.mgr创建ODS pool
bash
# 设置全局配置,将所有新创建的池的默认副本数设置为 3
[ceph: root@ceph-storage01 /]# ceph config set global osd_pool_default_size 3
# 创建名为 'rbds' 的池,设置 pg_num 和 pgp_num 都为 128
[ceph: root@ceph-storage01 /]# ceph osd pool create rbds 128 128
pool 'rbds' created
# 创建名为 'cephfs_data' 的池,设置 pg_num 和 pgp_num 都为 128
[ceph: root@ceph-storage01 /]# ceph osd pool create cephfs_data 128 128
pool 'cephfs_data' created
# 创建名为 'cephfs_metadata' 的池,设置 pg_num 和 pgp_num 都为 64
[ceph: root@ceph-storage01 /]# ceph osd pool create cephfs_metadata 64 64
pool 'cephfs_metadata' created
# 列出所有池的简要信息
[ceph: root@ceph-storage01 /]# ceph osd pool ls
.mgr
rbds
cephfs_data
cephfs_metadata
# 列出所有池的详细信息
[ceph: root@ceph-storage01 /]# ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 28 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 10.00
pool 2 'rbds' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 116 pgp_num 109 pg_num_target 32 pgp_num_target 32 autoscale_mode on last_change 90 lfor 0/90/88 flags hashpspool stripe_width 0 read_balance_score 1.38
pool 3 'cephfs_data' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 pg_num_target 32 pgp_num_target 32 autoscale_mode on last_change 91 flags hashpspool stripe_width 0 read_balance_score 1.25
pool 4 'cephfs_metadata' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 48 flags hashpspool stripe_width 0 read_balance_score 1.56扩展命令
bash
# 设置名为 'cephfs_data' 的数据池副本数为 2
[ceph: root@ceph-storage01 /]# ceph osd pool set cephfs_data size 2
# 设置名为 'cephfs_metadata' 的数据池副本数为 2
[ceph: root@ceph-storage01 /]# ceph osd pool set cephfs_metadata size 2
# 查看名为 'cephfs_metadata' 的数据池的副本数
[ceph: root@ceph-storage01 /]# ceph osd pool get cephfs_metadata size
# 查看名为 'cephfs_data' 的数据池的副本数
[ceph: root@ceph-storage01 /]# ceph osd pool get cephfs_data size
# 设置允许删除数据池的配置
[ceph: root@ceph-storage01 /]# ceph config set mon mon_allow_pool_delete true
# 设置禁止删除数据池的配置
[ceph: root@ceph-storage01 /]# ceph config set mon mon_allow_pool_delete false
# 删除名为 'pg_name' 的数据池
[ceph: root@ceph-storage01 /]# ceph osd pool rm pg_name pg_name --yes-i-really-really-mean-it为新的pool指定application
bash
# 启用 'rbd' 应用程序在名为 'rbds' 的数据池上
[ceph: root@ceph-storage01 /]# ceph osd pool application enable rbds rbd
# 说明:此命令将 'rbd' 应用程序启用在 'rbds' 数据池上。RADOS Block Device (RBD) 是 Ceph 的块存储应用程序。启用后,可以在此数据池中创建 RBD 镜像。
# 启用 'cephfs' 应用程序在名为 'cephfs_data' 的数据池上
[ceph: root@ceph-storage01 /]# ceph osd pool application enable cephfs_data cephfs
# 说明:此命令将 'cephfs' 应用程序启用在 'cephfs_data' 数据池上。Ceph 文件系统 (CephFS) 是 Ceph 的文件存储应用程序。启用后,数据池可以用于 CephFS 文件存储。
# 启用 'cephfs' 应用程序在名为 'cephfs_metadata' 的数据池上
[ceph: root@ceph-storage01 /]# ceph osd pool application enable cephfs_metadata cephfs
# 说明:此命令将 'cephfs' 应用程序启用在 'cephfs_metadata' 数据池上。此池专门用于 CephFS 的元数据存储。启用后,数据池可以用于 CephFS 文件系统的元数据存储。CephFS的创建与删除
新增一台虚拟机,作为客户端使用,进行时间同步,关闭防火墙和selinux
|------------|---------------------|------------|----------------|
| 主机名 | IP | 节点 | 配置 |
| client | 192.168.226.156 | client | 1核1G-38G磁盘 |
给这个客户端机器安装ceph
bash
[root@client ~]# dnf search release-ceph
[root@client ~]# dnf install --assumeyes centos-release-ceph-reef
[root@client ~]# dnf install --assumeyes cephadm
[root@client ~]# cephadm version创建
在admin节点执行
bash
# 创建一个新的 Ceph 文件系统,名为 cephfs
# cephfs_metadata 池用于存储文件系统的元数据
# cephfs_data 池用于存储文件数据
[ceph: root@ceph-storage01 /]# ceph fs new cephfs cephfs_metadata cephfs_data
Pool 'cephfs_data' (id '3') has pg autoscale mode 'on' but is not marked as bulk.
Consider setting the flag by running
# ceph osd pool set cephfs_data bulk true
new fs with metadata pool 4 and data pool 3注:
bash# 如果要删除 Ceph 文件系统,需要先将其设置为 fail 状态 ceph fs fail cephfs # 删除 Ceph 文件系统,使用 --yes-i-really-really-mean-it 参数以确认删除操作 ceph fs rm cephfs --yes-i-really-really-mean-it
在admin节点获取一个密钥
bash
# 获取并显示 Ceph 集群的管理员客户端(client.admin)的密钥
[ceph: root@ceph-storage01 /]# ceph auth get-key client.admin
# 使用 SCP 命令将本地的 Ceph 配置文件复制到远程主机
[ceph: root@ceph-storage01 /]# scp /etc/ceph/ceph.conf root@192.168.226.156:/etc/ceph/ceph.conf在client客户端执行
bash
# 在客户端创建一个挂载点目录,用于挂载 Ceph 文件系统
[root@client ~]# mkdir /mnt/mycephfs
# 挂载 Ceph 文件系统到指定的目录,使用密钥进行身份验证
[root@client ~]# mount -t ceph 192.168.226.151:6789:/ /mnt/mycephfs -o name=admin,secret=AQCrwrVm/7fIMxAAv30br0kwBWBo9CeggOFPTg==
# 查看挂载情况,确认挂载是否成功
[root@client ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 369M 0 369M 0% /dev/shm
tmpfs tmpfs 148M 8.6M 139M 6% /run
/dev/mapper/rl-root xfs 37G 7.9G 29G 22% /
/dev/sda1 xfs 960M 225M 736M 24% /boot
tmpfs tmpfs 74M 0 74M 0% /run/user/0
192.168.226.151:6789:/ ceph 64G 0 64G 0% /mnt/mycephfs注:
前述用法会把密码遗留在 Bash 历史里,更安全的方法是从文件读密码。
例如下述代码的形式:
bashmount -t ceph 192.168.226.151:6789:/ /mnt/mycephfs -o name=admin,secretfile=/etc/ceph/admin.secret要卸载 Ceph 文件系统,可以用unmount 命令,例如:
bashumount /mnt/mycephfs
接下来在客户端创建一个大文件
bash
# 进入挂载点
[root@client ~]# cd /mnt/mycephfs/
# 创建一个指定大小大文件
[root@client mycephfs]# dd if=/dev/zero of=a.txt bs=1M count=2300
# 再创建一个
[root@client mycephfs]# echo "这是在192.168。226.156的client客户端写入创建的。" > /mnt/mycephfs/ceshi.txt
#查看大小
[root@client mycephfs]# du -sh *
2.3G a.txt
512 ceshi.txt在admin节点查看Ceph 集群状态
bash
[ceph: root@ceph-storage01 /]# ceph -s
cluster:
id: 2091bd16-561f-11ef-85dc-000c29a2177e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-storage01,ceph-storage02,ceph-storage03 (age 113m)
mgr: ceph-storage01.mhqcff(active, since 113m), standbys: ceph-storage02.abqgll
mds: 1/1 daemons up, 2 standby
osd: 10 osds: 10 up (since 113m), 10 in (since 113m)
data:
volumes: 1/1 healthy
pools: 4 pools, 81 pgs
objects: 601 objects, 2.2 GiB
usage: 7.5 GiB used, 192 GiB / 200 GiB avail
pgs: 81 active+clean其中data: 显示了集群的数据状态。
volumes: 1 个数据卷,状态正常。
pools: 4 个池(pool),共有 81 个放置组(PGs)。
objects: 集群中有 600 个对象,总数据量为 2.2 GiB。
usage: 总空间为 200 GiB,已使用 7.5 GiB,剩余 192 GiB 可用。
pgs: 所有 81 个放置组都处于 active+clean 状态,表示数据已经完全同步并且健康。
在 Ceph 集群中,usage 中显示的 7.5 GiB 是集群中所有数据的总使用量,这个量包括了数据对象、元数据、以及存储的其他开销。
实际数据:我们创建的 a.txt 文件大小为 2.3 GiB,尽管这在文件系统中是实际存储的内容,但在 Ceph 中可能会因为副本、冗余和其他存储机制而占用更多的空间。
副本:Ceph 默认会存储数据的多个副本以保证数据的可靠性和冗余。例如,使用的是三副本(replication size 3),2.3 GiB 的数据将会占用 2.3 GiB × 3 = 6.9 GiB。
在另外一台主机上也挂载,然后查看,这里我是随便选的主机,在192.168.226.152为ceph-storage02的主机上挂载
bash
[root@ceph-storage02 ~]# mount -t ceph 192.168.226.151:6789:/ /mnt -o name=admin,secret=AQCrwrVm/7fIMxAAv30br0kwBWBo9CeggOFPTg==
[root@ceph-storage02 ~]# ll /mnt
total 2355201
-rw-r--r-- 1 root root 2411724800 Aug 10 15:28 a.txt
-rw-r--r-- 1 root root 63 Aug 10 15:30 ceshi.txt
[root@ceph-storage02 ~]# cat /mnt/ceshi.txt
这是在192.168。226.156的client客户端写入创建的。可以看到文件会共享过来。
查看监控
浏览器访问https://admin节点的IP+3000端口,例如我这里访问https://192.168.226.151:3000/



设置开机自动挂载
bash
# 创建并编辑密钥文件,将密钥写入 /etc/ceph/ceph.client.admin.keyring,如过没有就自行创建该文件,这里略过
[root@client ~]# vim /etc/ceph/ceph.client.admin.keyring
AQCrwrVm/7fIMxAAv30br0kwBWBo9CeggOFPTg==
bash
# 添加以下行到 /etc/fstab 文件末尾
# 192.168.226.151:6789:/ 表示 Ceph Monitor 的地址和端口
# /mnt/mycephfs 是挂载点
# ceph 是文件系统类型
# name=admin 指定使用的 Ceph 用户名
# secretfile=/etc/ceph/admin.secret 指定密钥文件的位置
# _netdev 表示这是一个网络文件系统,确保在网络可用时挂载
# 0 0 用于备份和检查选项
[root@client ~]# vim /etc/fstab #再该文件最后追加入下述配置
192.168.226.151:6789:/ /mnt/mycephfs ceph name=admin,secretfile=/etc/ceph/ceph.client.admin.keyring,_netdev 0 0
# 使用 mount -a 命令测试 /etc/fstab 中的挂载配置
[root@client ~]# mount -a # 挂载 /etc/fstab 中配置的所有文件系统RBD相关操作
在 Ceph 存储系统中,RBD(RADOS Block Device)是一个关键的组件,提供块存储服务。
RBD(RADOS Block Device)概述
1. 块存储服务:
- RBD 提供类似于传统硬盘驱动器的块存储服务。它允许用户在 Ceph 集群上创建和管理块设备,这些设备可以像本地磁盘一样使用。
2. Ceph 的核心组件:
- Ceph 是一个分布式存储系统,设计用于提供高可用性、高可靠性和高性能的存储服务。RBD 是 Ceph 的一个重要组成部分,特别适用于需要块存储的场景,如虚拟化和数据库应用。
3. RADOS 层:
- RBD 基于 Ceph 的底层存储引擎 RADOS(Reliable Autonomic Distributed Object Store)。RADOS 提供高可用性和数据持久性,RBD 通过 RADOS 存储块设备的数据。
RBD 的主要特性
1. 动态扩展:
- RBD 支持动态扩展,可以根据需要增加卷的大小,而无需停机或重新分区。
2. 快照和克隆:
- 支持创建快照(snapshot)和克隆(clone)。快照可以用来记录设备在某一时刻的状态,克隆则可以基于现有块设备创建新的实例,通常用于快速部署测试环境。
3. 高性能:
- RBD 设计为高性能块存储,支持高吞吐量和低延迟访问,适合高负载应用。
4. 备份和恢复:
- 提供备份和恢复功能,可以将数据从 RBD 卷中备份并恢复,确保数据的持久性和可靠性。
5. 兼容性:
- RBD 可以与多种操作系统和应用程序兼容,支持通过标准的块设备接口(如 Linux 的
radosgw和rados工具)进行操作。
创建
bash
[ceph: root@ceph-storage01 /]# rbd ls rbds # 列出 'rbds' 池中的所有 RBD 图像
[ceph: root@ceph-storage01 /]# rbd create rbds/rbd01 --size 12G # 创建一个名为 'rbd01',大小为 12GiB 的 RBD 图像
[ceph: root@ceph-storage01 /]# rbd ls rbds # 再次列出 'rbds' 池中的所有 RBD 图像,确认创建成功
rbd01
[ceph: root@ceph-storage01 /]# rbd info rbds/rbd01 # 显示名为 'rbd01' 的 RBD 图像的详细信息
rbd image 'rbd01':
size 12 GiB in 3072 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: d3c61180ba6a
block_name_prefix: rbd_data.d3c61180ba6a
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Aug 10 08:55:34 2024
access_timestamp: Sat Aug 10 08:55:34 2024
modify_timestamp: Sat Aug 10 08:55:34 2024注:
bash# 取消RBD的object-map, fast-diff, deep-flatten特性,因为要用到kubernetes或者其他地方 [ceph: root@ceph-storage01 /]# rbd feature disable rbds/rbd01 object-map fast-diff deep-flatten [ceph: root@ceph-storage01 /]# rbd info rbds/rbd01
客户端操作
这也是在admin节点上操作,即主机名为ceph-storage01
需要有rbd模块
下载
bash
[root@ceph-storage01 ~]# sudo dnf install -y ceph ceph-common ceph-osd ceph-mds ceph-mgr
# 查看是否安装成功
[root@ceph-storage01 ~]# which rbd
/usr/bin/rbd
bash
# 列出当前加载的内核模块,并过滤出包含 'rbd' 的模块
[root@ceph-storage01 ~]# lsmod | grep rbd
# 如果没有 'rbd' 模块,则加载 'rbd' 内核模块
[root@ceph-storage01 ~]# modprobe rbd
# 再次列出当前加载的内核模块,并过滤出包含 'rbd' 的模块,确认 'rbd' 模块已经加载
[root@ceph-storage01 ~]# lsmod | grep rbd
rbd 155648 0
libceph 581632 1 rbd
# 映射 Ceph RADOS Block Device (RBD) 图像到本地设备,rbds/rbd01 是 Ceph pool 和 image 名称
[root@ceph-storage01 ~]# rbd map rbds/rbd01
/dev/rbd0
# 查看映射到本地的 RBD 设备的块设备信息,确认设备 /dev/rbd0 已被创建
[root@ceph-storage01 ~]# lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 12G 0 disk
# 显示当前所有映射的 RBD 设备信息
[root@ceph-storage01 ~]# rbd showmapped
id pool namespace image snap device
0 rbds rbd01 - /dev/rbd0
# 格式化映射的 RBD 设备 /dev/rbd0 为 XFS 文件系统
[root@ceph-storage01 ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=16, agsize=196608 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1 nrext64=0
data = bsize=4096 blocks=3145728, imaxpct=25
= sunit=16 swidth=16 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=16384, version=2
= sectsz=512 sunit=16 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.
bash
# 配置开机自动映射 RBD 设备
# 这一步骤是为了确保在系统启动时自动映射 Ceph RADOS Block Device (RBD) 图像
# 编辑 /etc/rc.local 文件,添加自动映射命令
[root@ceph-storage01 ~]# vim /etc/rc.local
# 在文件中添加以下行
# 这行命令将在系统启动时自动映射 Ceph RADOS Block Device (RBD) 图像 rbds/rbd01
rbd map rbds/rbd01
# 保存并退出 vim 编辑器
# 使 /etc/rc.local 文件可执行
# 这一步骤是必要的,因为 /etc/rc.local 文件需要具有执行权限才能在系统启动时运行
[root@ceph-storage01 ~]# chmod a+x /etc/rc.local断开映射的方法
bash
# 断开 RBD 设备的映射
# 这一步骤将卸载 Ceph RADOS Block Device (RBD) 图像 rbds/rbd01,从而解除设备与 Ceph 集群的关联
# 使用 rbd unmap 命令来断开 RBD 设备的映射
# rbds/rbd01 是要断开的 Ceph RADOS Block Device 图像
[root@ceph-storage01 ~]# rbd unmap rbds/rbd01
# 显示当前映射的 RBD 设备信息
# 这一步骤用于确认设备映射已经成功断开
[root@ceph-storage01 ~]# rbd showmapped补充
bash
# 查看版本
ceph tell mon.* version # 查看监视器 (mon) 版本
ceph tell osd.* version # 查看对象存储守护进程 (osd) 版本
ceph tell mds.* version # 查看元数据服务器 (mds) 版本
# 服务管理
ceph orch ls # 列出当前的服务
ceph orch rm {service_name} # 删除服务,{service_name} 是服务名称
ceph orch daemon rm {daemon_name} [--force] # 删除指定守护进程,{daemon_name} 是守护进程名称
# RBD 操作
# 创建镜像
rbd create -p rbds --image rbd01 --size 10G
# 或简写为
rbd create rbds/rbd01 --size 10G
# 镜像管理
rbd ls -l -p rbd-demo # 查看存储池下镜像
rbd info -p rbd-demo --image rbd-demo1.img # 查看镜像详细信息
rbd resize -p rbd-demo --image rbd-demo1.img --size 20G # 修改镜像大小(减少时加 --allow-shrink)
rbd rm -p rbd-demo --image rbd-demo2.img # 删除镜像,无法找回
rbd trash move rbd-demo/rbd-demo1.img # 移动到回收站
rbd ls -l -p rbd-demo # 查看回收站中的镜像
rbd trash list -p rbd-demo # 查看回收站中的镜像
rbd trash restore rbd-demo/acc62785c8bb # 还原镜像
# 客户端操作
rbd showmapped # 查看映射
rbd device list # 查看设备
rbd unmap rbd-demo/rbd-demo1.img # 断开映射
# 快照管理
rbd snap create --pool rbd-demo --image rbd-demo1.img --snap demo1_snap1 # 创建快照
# 或简写为
rbd snap create rbd-demo/rbd-demo1.img@demo1_snap1
rbd snap list rbd-demo/rbd-demo1.img # 列出所有快照,可加 --format json --pretty-format 以 JSON 格式输出
# 快照还原
rbd unmap rbd-demo/rbd-demo1.img # 客户端操作:断开映射
rbd snap rollback rbd-demo/rbd-demo1.img@demo1_snap1 # 管理操作:还原快照
rbd map rbd-demo/rbd-demo1.img # 客户端操作:重新映射
# 修改 CRUSH 规则
ceph osd crush rule ls # 列出 CRUSH 规则
ceph osd crush rule create-replicated on-ssd default host ssd # 创建 SSD 规则
ceph osd crush rule create-replicated on-hdd default host hdd # 创建 HDD 规则
ceph osd crush rule ls # 查看现有 CRUSH 规则
# 应用 CRUSH 规则到池
ceph osd pool create bench.ssd 64 64 on-ssd # 创建应用 SSD 规则的池
ceph osd pool create bench.hdd 128 128 on-hdd # 创建应用 HDD 规则的池部署RGW服务
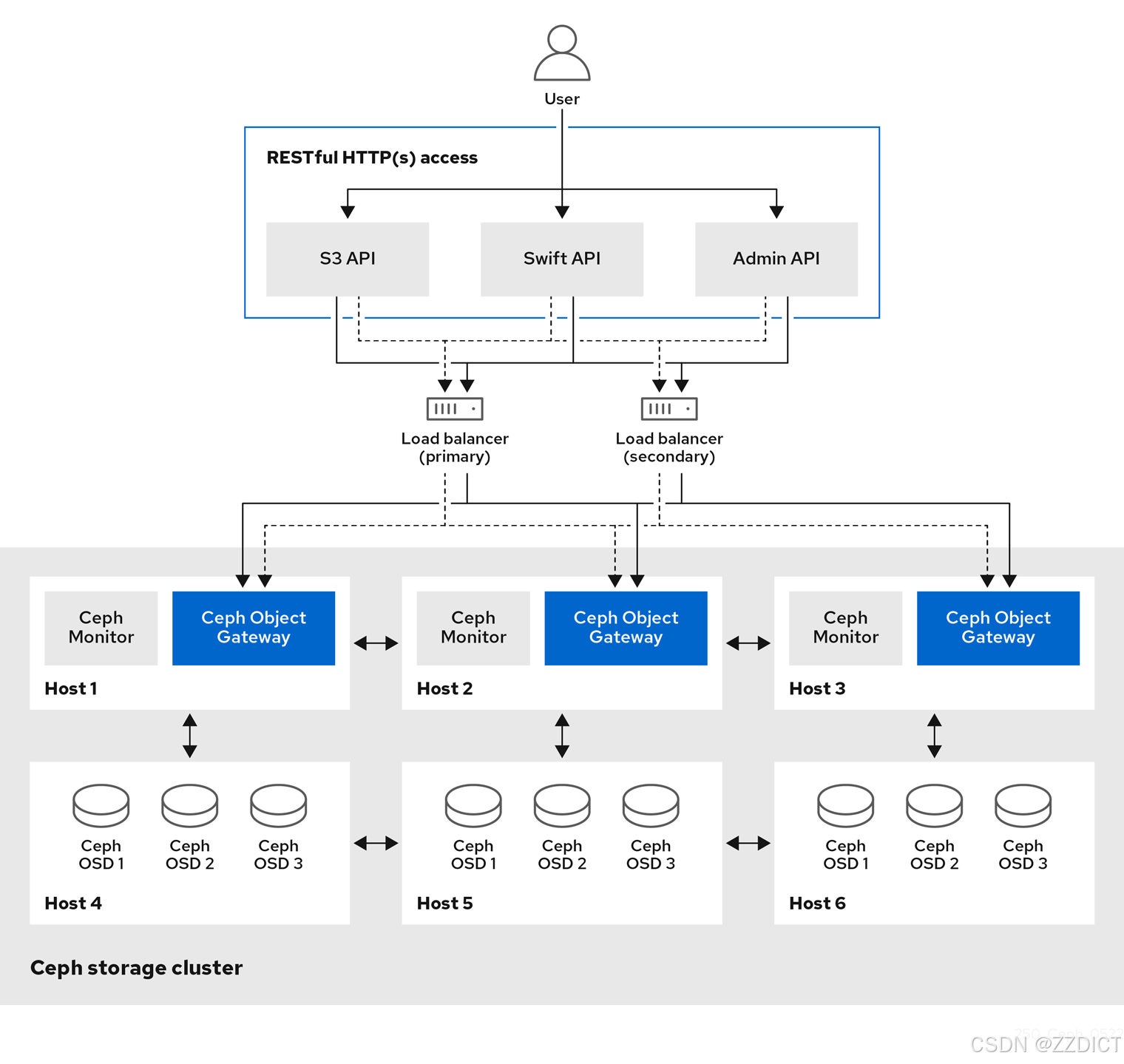
Ceph RGW(RADOS Gateway)是 Ceph 的一个组件,提供对象存储接口,使用户能够通过兼容 S3(Amazon Simple Storage Service)和 Swift(OpenStack Object Storage)API 来访问 Ceph 存储集群。它允许用户以对象形式存储数据,并支持多种功能,如:
- 数据存储:以对象的形式存储文件或数据。
- 访问控制:通过 ACL(访问控制列表)和桶策略来管理数据访问权限。
- 数据分发:支持对象的静态内容分发,如图片和视频。
- 多租户支持:支持在同一 RGW 实例中隔离多个用户或组织的数据。
bash
# 为指定的主机添加标签 'rgw'
[root@ceph-storage01 ~]# ceph orch host label add ceph-storage04 rgw # 将 'rgw' 标签添加到主机 'ceph-storage04'
[root@ceph-storage01 ~]# ceph orch host label add ceph-storage05 rgw # 将 'rgw' 标签添加到主机 'ceph-storage05'
# 应用 RGW 服务并指定放置规则
[root@ceph-storage01 ~]# ceph orch apply rgw rgw --placement="label:rgw count-per-host:2" --port=8000
# 'rgw':服务名称
# --placement="label:rgw count-per-host:2":在标记为 'rgw' 的主机上每台主机运行 2 个 RGW 实例
# --port=8000:指定 RGW 服务监听的端口为 8000
# 执行此命令将调度 RGW 服务更新
bash
# 列出所有 Ceph 服务
[ceph: root@ceph-storage01 /]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 3m ago 29h count:1
ceph-exporter 5/5 4m ago 29h *
crash 5/5 4m ago 29h *
grafana ?:3000 1/1 3m ago 29h count:1
mds.myfs 3/3 3m ago 8h ceph-storage01;ceph-storage02;ceph-storage03
mgr 2/2 3m ago 29h count:2
mon 3/3 3m ago 28h ceph-storage01;ceph-storage02;ceph-storage03
node-exporter ?:9100 5/5 4m ago 29h *
osd.all-available-devices 10 4m ago 9h *
prometheus ?:9095 1/1 3m ago 29h count:1
rgw.rgw ?:8000 4/4 4m ago 5m count-per-host:2;label:rgw
bash
# 列出所有 RGW 守护进程的状态
[ceph: root@ceph-storage01 /]# ceph orch ps --daemon_type rgw
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
rgw.rgw.ceph-storage04.ifjaln ceph-storage04 *:8001 running (32m) 38s ago 32m 101M - 18.2.4 2bc0b0f4375d 454921108f4e
rgw.rgw.ceph-storage04.xagqqg ceph-storage04 *:8000 running (32m) 38s ago 32m 123M - 18.2.4 2bc0b0f4375d 1c3dae56f48e
rgw.rgw.ceph-storage05.gavkvv ceph-storage05 *:8000 running (32m) 41s ago 32m 85.4M - 18.2.4 2bc0b0f4375d 72b3f39ce746
rgw.rgw.ceph-storage05.ryyvio ceph-storage05 *:8001 running (32m) 41s ago 32m 85.3M - 18.2.4 2bc0b0f4375d 545f24a11dff
bash
# 列出所有 Ceph 存储池
[ceph: root@ceph-storage01 /]# ceph osd pool ls
.mgr
rbds
cephfs_data
cephfs_metadata
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta
# 输出解释:
# .mgr: 存储管理器使用的池,通常用于存储管理相关数据
# rbds: 自定义存储池,用于 RADOS Block Device (RBD) 镜像,通常用于块存储
# cephfs_data: Ceph 文件系统 (CephFS) 使用的数据池
# cephfs_metadata: Ceph 文件系统 (CephFS) 使用的元数据池
# .rgw.root: RADOS Gateway (RGW) 使用的根池
# default.rgw.log: RGW 使用的日志池
# default.rgw.control: RGW 使用的控制池
# default.rgw.meta: RGW 使用的元数据池
# 各池的作用:
# - 存储池用于存储 Ceph 集群的不同类型的数据,池的名称通常表示其用途或关联的服务。
# - `.mgr` 和 `.rgw.root` 是 Ceph 系统池,通常由 Ceph 系统或服务自动创建并管理。
# - `rbds`、`cephfs_data`、`cephfs_metadata` 和 RGW 相关池 (`default.rgw.*`) 是用户自定义池或服务池,用于特定的数据存储需求。创建RGW用户
bash
# 创建一个新的 RGW 用户
[ceph: root@ceph-storage01 /]# radosgw-admin user create --uid xiaobai --display-name="Ceph RGW S3 style test user"
# 输出示例:
{
"user_id": "xiaobai", # 用户的唯一标识符
"display_name": "Ceph RGW S3 style test user", # 用户的显示名称
"email": "", # 用户的电子邮件(未设置)
"suspended": 0, # 用户是否被暂停(0 表示未暂停)
"max_buckets": 1000, # 用户可以创建的最大桶数量
"subusers": [], # 用户的子用户(此用户没有子用户)
"keys": [ # 用户的访问密钥
{
"user": "xiaobai", # 用户标识符
"access_key": "CDOID6HK3UVPT76BSGYJ", # 用户的访问密钥
"secret_key": "2uRa8cBtQjza2qlHBUAmdQbDQtVEgAWjUOMeNhW0" # 用户的秘密密钥
}
],
"swift_keys": [], # Swift 密钥(此用户没有 Swift 密钥)
"caps": [], # 用户的权限(此用户没有特殊权限)
"op_mask": "read, write, delete", # 用户的操作掩码,定义了可执行的操作(读、写、删除)
"default_placement": "", # 默认放置策略(未设置)
"default_storage_class": "", # 默认存储类(未设置)
"placement_tags": [], # 放置标签(此用户没有标签)
"bucket_quota": { # 桶配额设置
"enabled": false, # 是否启用桶配额
"check_on_raw": false, # 是否对原始数据进行检查
"max_size": -1, # 最大桶大小(-1 表示无限制)
"max_size_kb": 0, # 最大桶大小(以 KB 为单位,0 表示无限制)
"max_objects": -1 # 最大对象数(-1 表示无限制)
},
"user_quota": { # 用户配额设置
"enabled": false, # 是否启用用户配额
"check_on_raw": false, # 是否对原始数据进行检查
"max_size": -1, # 最大用户存储大小(-1 表示无限制)
"max_size_kb": 0, # 最大用户存储大小(以 KB 为单位,0 表示无限制)
"max_objects": -1 # 最大用户对象数(-1 表示无限制)
},
"temp_url_keys": [], # 临时 URL 密钥(此用户没有临时 URL 密钥)
"type": "rgw", # 用户类型(RGW 表示 RADOS Gateway 用户)
"mfa_ids": [] # 多因素认证 ID(此用户没有 MFA 配置)
}配置客户端

这里带client端,192.168.226.156主机操作
bash
# 安装 EPEL 仓库(Extra Packages for Enterprise Linux)
[root@client ~]# yum install -y epel-release
# 安装 s3cmd 工具,用于与 S3 兼容存储交互
[root@client ~]# yum install -y s3cmd
# 安装 HAProxy,负载均衡器和代理工具
[root@client ~]# yum install -y haproxy
# 备份现有的 HAProxy 配置文件
[root@client ~]# cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
# 向 HAProxy 配置文件中添加新的配置
[root@client ~]# cat >> /etc/haproxy/haproxy.cfg <<EOF
# 定义一个名为 rgw 的监听器
listen rgw
# 绑定到 IP 地址 192.168.226.156 的 80 端口,用的本机IP
bind 192.168.226.156:80
# 使用 TCP 模式
mode tcp
# 使用轮询负载均衡算法
balance roundrobin
# 定义后端服务器
# 服务器 ceph-storage04,监听 192.168.226.154 的 8000 端口
server ceph-storage04 192.168.226.154:8000 check
# 服务器 ceph-storage04,监听 192.168.226.154 的 8001 端口
server ceph-storage04 192.168.226.154:8001 check
# 服务器 ceph-storage05,监听 192.168.226.155 的 8000 端口
server ceph-storage05 192.168.226.155:8000 check
# 服务器 ceph-storage05,监听 192.168.226.155 的 8001 端口
server ceph-storage05 192.168.226.155:8001 check
EOF
# 启动 HAProxy 服务
[root@client ~]# systemctl start haproxy
bash
# 配置 s3cmd 工具,设置与 S3 兼容存储的连接
[root@client ~]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key [CDOID6HK3UVPT76BSGYJ]: CDOID6HK3UVPT76BSGYJ
Secret Key [2uRa8cBtQjza2qlHBUAmdQbDQtVEgAWjUOMeNhW0]: 2uRa8cBtQjza2qlHBUAmdQbDQtVEgAWjUOMeNhW0
Default Region [US]:
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [192.168.226.100]: 192.168.226.156
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [192.168.226.100:80/%(bucket)]: 192.168.226.156:80/%(bucket)
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password:
Path to GPG program [/usr/bin/gpg]:
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [No]: False
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name [192.168.226.100]: 192.168.226.156
HTTP Proxy server port [3128]: 80
New settings:
Access Key: CDOID6HK3UVPT76BSGYJ
Secret Key: 2uRa8cBtQjza2qlHBUAmdQbDQtVEgAWjUOMeNhW0
Default Region: US
S3 Endpoint: 192.168.226.156
DNS-style bucket+hostname:port template for accessing a bucket: 192.168.226.156:80/%(bucket)
Encryption password:
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name: 192.168.226.156
HTTP Proxy server port: 80
Test access with supplied credentials? [Y/n] Y
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Not configured. Never mind.
Save settings? [y/N] y
Configuration saved to '/root/.s3cfg'
在执行本步骤中,一些重要配置点如下选择:
# S3 Access Key 和 Secret Key,用于认证你的请求
access_key = CDOID6HK3UVPT76BSGYJ #在admin节点使用radosgw-admin user create --uid xiaobai --display-name="Ceph RGW S3 style test user"中弹出的消息复制
secret_key = 2uRa8cBtQjza2qlHBUAmdQbDQtVEgAWjUOMeNhW0 #也是在admin查看
# 默认区域,这里设置为 US,如果你的存储服务在其他区域,请调整
default_region = US #这里我直接回车
# S3 Endpoint 的 IP 地址或域名,你的存储服务在这个地址上
host_base = 192.168.226.156 #代理的IP
host_bucket = 192.168.226.156:80/%(bucket) #代理IP加端口加上后面的/%(bucket)
# 加密设置,如果需要加密传输的文件,可以在这里设置加密密码,这里不设置直接回车
encryption_password =
# 指定 GPG 程序路径,用于加密文件(如果使用 GPG),这里直接回车
path_to_gpg = /usr/bin/gpg
# 是否使用 HTTPS 协议进行安全通信,设置为 False 表示使用 HTTP,输入False再回车
use_https = False
# 如果需要通过 HTTP 代理访问 S3 存储服务,设置代理服务器的地址和端口 ,这里输入代理的IP 下面就是端口
proxy = 192.168.226.156
proxy_port = 80
# 见到这输入Y回车
Test access with supplied credentials? [Y/n] Y
#这里输入y回车
Save settings? [y/N] y
bash
# 查看当前用户主目录下的 .s3cfg 文件内容,这个文件用于配置 s3cmd 工具与 S3 兼容存储的连接。
[root@client ~]# cat .s3cfg测试
bash
# 列出所有 S3 存储桶
[root@client ~]# s3cmd ls
# 输出结果为空,说明在执行此命令时没有存储桶,或者 S3 存储桶列表为空
# 创建一个新的 S3 存储桶,名称为 'mybucket'
[root@client ~]# s3cmd mb s3://mybucket
Bucket 's3://mybucket/' created
# 输出结果表明存储桶 'mybucket' 已成功创建
# 列出所有 S3 存储桶
[root@client ~]# s3cmd ls
# 输出结果显示刚刚创建的存储桶 'mybucket'
2024-08-10 13:39 s3://mybucket
bash
# 使用 Zmodem 协议接收文件,通常用于通过终端上传文件,上传一个图片和视频
[root@client ~]# rz
# 列出当前目录的文件
[root@client ~]# ll
total 32368
-rw-------. 1 root root 815 Jun 6 14:00 anaconda-ks.cfg
-rw-r--r-- 1 root root 3673 Aug 6 20:39 images.jpg
-rw-r--r-- 1 root root 33127749 Aug 10 21:52 shipin.mp4
# 将图片上传到 S3 存储桶
[root@client ~]# s3cmd put images.jpg s3://mybucket/file/
upload: 'images.jpg' -> 's3://mybucket/file/images.jpg' [1 of 1]
3673 of 3673 100% in 0s 204.16 KB/s done
# 将视频上传到 S3 存储桶
[root@client ~]# s3cmd put shipin.mp4 s3://mybucket/file/
upload: 'shipin.mp4' -> 's3://mybucket/file/shipin.mp4' [part 1 of 3, 15MB] [1 of 1]
15728640 of 15728640 100% in 0s 42.96 MB/s done
upload: 'shipin.mp4' -> 's3://mybucket/file/shipin.mp4' [part 2 of 3, 15MB] [1 of 1]
15728640 of 15728640 100% in 0s 47.77 MB/s done
upload: 'shipin.mp4' -> 's3://mybucket/file/shipin.mp4' [part 3 of 3, 1631KB] [1 of 1]
1670469 of 1670469 100% in 0s 20.69 MB/s done
# 列出 S3 存储桶中的文件
[root@client ~]# s3cmd ls s3://mybucket/file/
2024-08-10 13:55 3673 s3://mybucket/file/images.jpg
2024-08-10 13:56 33127749 s3://mybucket/file/shipin.mp4
# 从 S3 存储桶下载图片到本地 /tmp 目录
[root@client ~]# s3cmd get s3://mybucket/file/images.jpg /tmp
download: 's3://mybucket/file/images.jpg' -> '/tmp/images.jpg' [1 of 1]
3673 of 3673 100% in 0s 567.37 KB/s done
# 列出 /tmp 目录下的图片文件
[root@client ~]# ll /tmp |grep *.jpg
-rw-r--r-- 1 root root 3673 Aug 10 13:55 images.jpg
# 生成一个签名的 URL,用于访问存储桶中的视频,链接有效期为1年
[root@client ~]# s3cmd signurl s3://mybucket/file/shipin.mp4 $(date -d 'now + 1 year' +%s)
http://192.168.226.156/mybucket/file/shipin.mp4?AWSAccessKeyId=CDOID6HK3UVPT76BSGYJ&Expires=1754834321&Signature=fhRIyJn7Wg5qSmFZEuoDt9ogaxA%3D
# 删除 S3 存储桶中的图片文件
[root@client ~]# s3cmd rm s3://mybucket/file/images.jpg
delete: 's3://mybucket/file/images.jpg'
# 强制删除 S3 存储桶中的所有内容
[root@client ~]# s3cmd del -r --force s3://mybucket/
delete: 's3://mybucket/file/shipin.mp4'
# 删除 S3 存储桶
[root@client ~]# s3cmd rb s3://mybucket
Bucket 's3://mybucket/' removed
# 列出所有 S3 存储桶
[root@client ~]# s3cmd ls
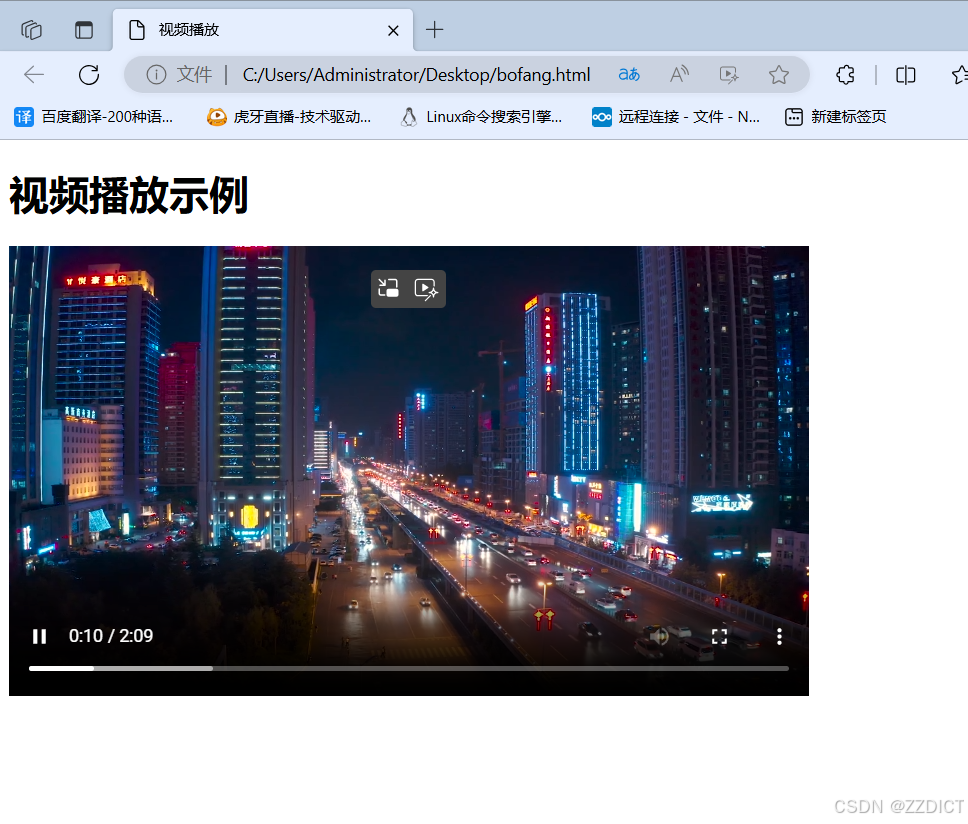
# 输出显示没有存储桶,因为刚刚创建的存储桶 'mybucket' 已被删除在桌面创建一个以.html结尾的文件,输入下述代码,使用刚刚生成的视频链接,用浏览器打开就可以看到你的视频的播放
bash
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Video Playback</title>
</head>
<body>
<h1>Video Playback Example</h1>
<video width="640" height="360" controls>
<source src="http://192.168.226.156/mybucket/file/shipin.mp4?AWSAccessKeyId=CDOID6HK3UVPT76BSGYJ&Expires=1754834321&Signature=fhRIyJn7Wg5qSmFZEuoDt9ogaxA%3D" type="video/mp4">
Your browser does not support the video tag.
</video>
</body>
</html>