一、OpenStack集成ceph服务
一)Openstack集成Ceph准备
1、OpenStack存储知识
1、OpenStack数据存储分类
Openstack环境中,数据存储可分为临时性存储与永久性存储。
临时性存储:主要由本地文件系统提供,并主要用于nova虚拟机的本地系统与临时数据盘,以及存储glance上传的系统镜像;
永久性存储:主要由cinder提供的块存储与swift提供的对象存储构成,以cinder提供的块存储应用最为广泛,块存储通常以云盘的形式挂载到虚拟机中使用。
2、OpenStack需要进行数据存储的组件
Openstack中需要进行数据存储的三大项目主要是nova项目(虚拟机镜像文件),glance项目(共用模版镜像)与cinder项目(块存储)。
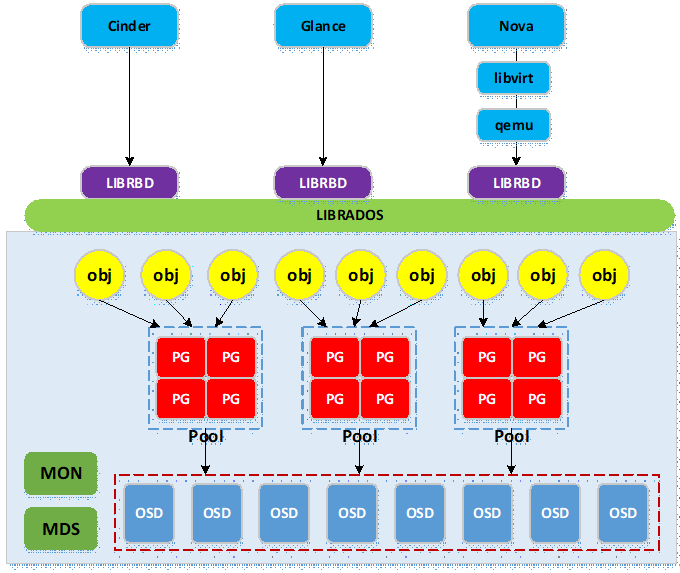
下图为cinder,glance与nova访问ceph集群的逻辑图:
- ceph与openstack集成主要用到ceph的rbd服务,ceph底层为rados存储集群,ceph通过librados库实现对底层rados的访问;
- openstack各项目客户端调用librbd,再由librbd调用librados访问底层rados;
- 实际使用中,nova需要使用libvirtdriver驱动以通过libvirt与qemu调用librbd;cinder与glance可直接调用librbd;
- 写入ceph集群的数据被条带切分成多个object,object通过hash函数映射到pg(构成pg容器池pool),然后pg通过几圈crush算法近似均匀地映射到物理存储设备osd(osd是基于文件系统的物理存储设备,如xfs,ext4等)。
2、创建pool
Ceph默认使用pool的形式存储数据,pool是对若干pg进行组织管理的逻辑划分,pg里的对象被映射到不同的osd,因此pool分布到整个集群里。
可以将不同的数据存入1个pool,但如此操作不便于客户端数据区分管理,因此一般是为每个客户端分别创建pool。
为cinder,nova,glance分别创建pool,命名为:volumes,vms,images
创建pool,需要覆盖默认的pg num,官方文档对pg num的数量有如下建议:
- http://docs.ceph.com/docs/master/rados/operations/placement-groups/;
- 同时综合考量全部pool的pg num总和的上限:pg num * 副本数量 < mon_max_pg_per_osd(默认200) * num_in_osds(osd总进程数);
1、pool创建在monitor节点操作,以controller01节点为例;
这里volumes池是永久性存储,vms是实例临时后端存储,images是镜像存储
su - cephde
$ sudo ceph osd pool create volumes 128
$ sudo ceph osd pool create vms 128
$ sudo ceph osd pool create images 1282、查看状态
[cephde@controller01 ~]$ sudo ceph pg stat
396 pgs: 396 active+undersized; 0B data, 6.03GiB used, 77.9GiB / 84.0GiB avail
[cephde@controller01 ~]$ sudo ceph osd lspools
1 vms,2 volumes,3 images,3、安装ceph客户端
1、控制节点安装python-rbd
- glance-api服务所在节点需要安装python-rbd
- 这里glance-api服务运行在3个控制节点上
sudo yum install python-rbd -y2、存储节点安装ceph-common
- cinder-volume与nova-compute服务所在节点需要安装ceph-common;
- 这里cinder-volume与nova-compute服务运行在3个计算(存储)节点
sudo yum install ceph-common -y3、授权设置
在控制节点controller01操作 (root用户执行)
1、创建用户
- ceph默认启用cephx authentication(见ceph.conf),需要为nova/cinder与glance客户端创建新的用户并授权;
- 可在管理节点上分别为运行cinder-volume与glance-api服务的节点创建client.glance与client.cinder用户并设置权限;
- 针对pool设置权限,pool名对应创建的pool
[root@controller01 ~]# ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images'
[client.cinder]
key = AQCv3plbaAahKxAAjIsIVNMR++B7X22AkkviPA==
[root@controller01 ~]# ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images'
[client.glance]
key = AQDB3plbufA/CBAAlFdliGPJbhM1wCgORaZ+3w==2、推动client.glance秘钥(可以使用脚本)
将创建client.glance用户生成的秘钥推送到运行glance-api服务的节点
ceph auth get-or-create client.glance | ssh root@controller01 tee /etc/ceph/ceph.client.glance.keyring
ceph auth get-or-create client.glance | ssh root@controller02 tee /etc/ceph/ceph.client.glance.keyring
ceph auth get-or-create client.glance | ssh root@controller03 tee /etc/ceph/ceph.client.glance.keyring同时修改秘钥文件的属主与用户组
ssh root@controller01 chown glance:glance /etc/ceph/ceph.client.glance.keyring
ssh root@controller02 chown glance:glance /etc/ceph/ceph.client.glance.keyring
ssh root@controller03 chown glance:glance /etc/ceph/ceph.client.glance.keyring3、推送client.cinder秘钥(nova-volume)
将创建的client.cinder用户生成的秘钥推送到运行cinder-volume服务的节点(计算节点)
ceph auth get-or-create client.cinder | ssh root@compute01 tee /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh root@compute02 tee /etc/ceph/ceph.client.cinder.keyring同时修改秘钥文件的属主与用户组
ssh root@compute01 chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
ssh root@compute02 chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring4、推送client.cinder秘钥(nova-compute)
这里nova-compute服务与nova-volume服务运行在相同节点,不必重复操作
5、libvirt秘钥
nova-compute所在节点需要将client.cinder用户的秘钥文件存储到libvirt中;当基于ceph后端的cinder卷被attach到虚拟机实例时,libvirt需要用到该秘钥以访问ceph集群;
在管理节点向计算(存储)节点推送client.cinder秘钥文件,生成的文件是临时性的,将秘钥添加到libvirt后可删除
ceph auth get-key client.cinder | ssh root@compute01 tee /etc/ceph/client.cinder.key
ceph auth get-key client.cinder | ssh root@compute02 tee /etc/ceph/client.cinder.key在计算(存储)节点将秘钥加入
- 首先生成1个uuid,全部计算(存储)节点可共用此uuid(其他节点不用操作)
- uuid后续配置nova.conf文件时也会用到,请保持一致。
[root@compute01 ~]# uuidgen
d6addd93-c7ba-43e3-a9dd-ee53677cbd2c添加秘钥
cat>/etc/ceph/secret.xml<<EOF
<secret ephemeral='no' private='no'>
<uuid>d6addd93-c7ba-43e3-a9dd-ee53677cbd2c</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
EOF
virsh secret-define --file /etc/ceph/secret.xml
virsh secret-set-value --secret d6addd93-c7ba-43e3-a9dd-ee53677cbd2c --base64 $(cat /etc/ceph/client.cinder.key)

扩展知识:
virsh命令详解:virsh 命令_virsh nodesuspend --help csdn-CSDN博客
http://virtual.51cto.com/art/201611/520859.htm
二)glance集成ceph
控制节点操作
1、配置glance-api.conf
在运行glance-api服务的节点修改glance-api.conf文件,含3个控制节点,以controller01节点为例
以下只列出涉及glance集成ceph的section
1、修改glance的配置文件
vim /etc/glance/glance-api.conf
# 打开copy-on-write功能
[DEFAULT]
show_image_direct_url = True
# 变更默认使用的本地文件存储为ceph rbd存储;
# 注意红色字体部分前后一致
[glance_store]
#stores = file,http
#default_store = file
#filesystem_store_datadir = /var/lib/glance/images/
stores = rbd
default_store = rbd
rbd_store_chunk_size = 8
rbd_store_pool = images
rbd_store_user = glance
rbd_store_ceph_conf = /etc/ceph/ceph.conf2、变更配置文件,重启服务
systemctl restart openstack-glance-api.service
systemctl restart openstack-glance-registry.service
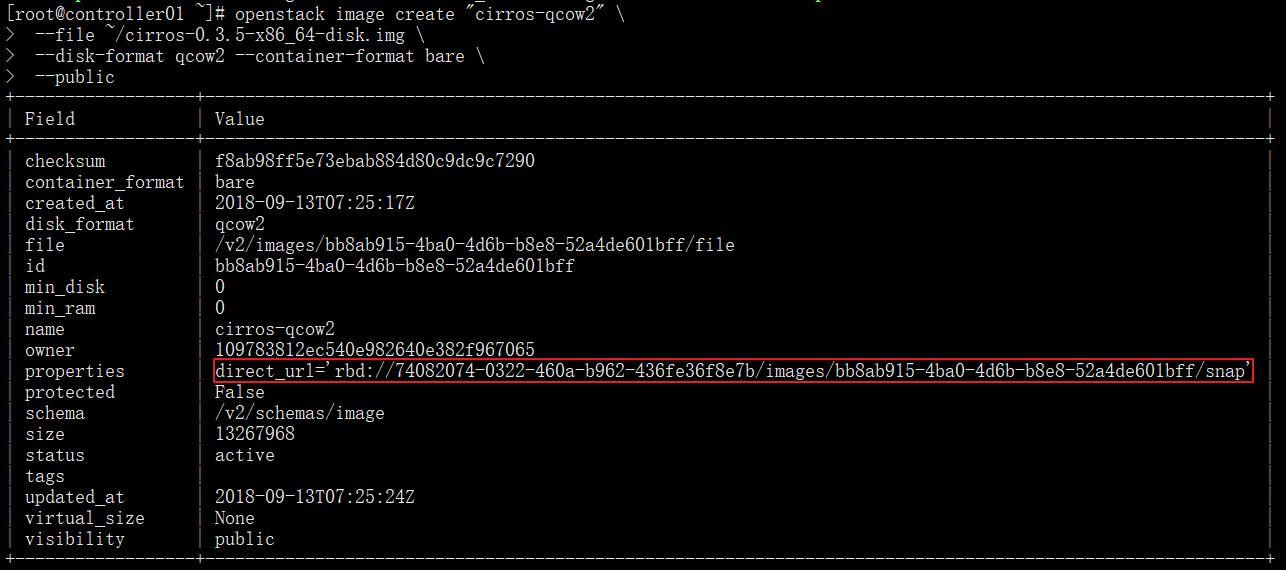
systemctl status openstack-glance-api.service openstack-glance-registry.service2、上传镜像
镜像上传后,默认地址为ceph集群(ID)的images pool下
openstack image create "cirros-qcow2" \
--file ~/cirros-0.3.5-x86_64-disk.img \
--disk-format qcow2 --container-format bare \
--public
检查镜像是否存在
[root@controller01 ~]# rbd ls images
bb8ab915-4ba0-4d6b-b8e8-52a4de601bff3、定义pool类型
控制节点操作
1、images启用后,ceph集群状态变为HEALTH_WARN
[root@controller01 ~]# ceph -s
cluster:
id: 7e861d4a-a9ea-46e2-b272-89025cda8ca9
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum controller03,controller01,controller02
mgr: controller01_mgr(active), standbys: controller03_mgr, controller02_mgr
osd: 6 osds: 6 up, 6 in
data:
pools: 3 pools, 384 pgs
objects: 8 objects, 12.7MiB
usage: 6.05GiB used, 77.9GiB / 84.0GiB avail
pgs: 384 active+clean
io:
client: 0B/s rd, 0op/s rd, 0op/s wr2、使用"ceph health detail",能给出解决办法;
未定义pool池类型,可定义为'cephfs', 'rbd', 'rgw'等
[root@controller01 ~]# ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool 'images'
use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.3、同时解决volumes与vms两个pool的问题
ceph osd pool application enable images rbd
ceph osd pool application enable volumes rbd
ceph osd pool application enable vms rbd

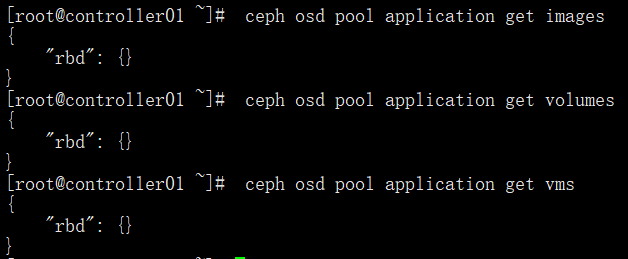
4、查看各个pool中的application
[root@controller01 ~]# ceph health detail
HEALTH_OK查看各个pool中的application
ceph osd pool application get images
ceph osd pool application get volumes
ceph osd pool application get vms
三)Cinder集成Ceph
1、配置cinder.conf
- cinder利用插件式结构,支持同时使用多种后端存储;
- 在cinder-volume所在节点设置cinder.conf中设置相应的ceph rbd驱动即可;
在存储节点操作
1、修改配置文件,以下只列出涉及cinder集成ceph的section
vim /etc/cinder/cinder.conf
# 后端使用ceph存储
[DEFAULT]
enabled_backends = ceph
# 新增[ceph] section;
# 注意红色字体部分前后一致
[ceph]
# ceph rbd驱动
volume_driver = cinder.volume.drivers.rbd.RBDDriver
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = true
rbd_max_clone_depth = 5
rbd_store_chunk_size = 4
rados_connect_timeout = -1
# 如果配置多后端,则“glance_api_version”必须配置在[DEFAULT] section
glance_api_version = 2
rbd_user = cinder
rbd_secret_uuid = d6addd93-c7ba-43e3-a9dd-ee53677cbd2c
volume_backend_name = ceph2、变更配置文件后重启服务
启动块存储卷服务,并查看服务状态
systemctl restart openstack-cinder-volume.service
systemctl status openstack-cinder-volume.service2、验证
在控制节点验证
查看cinder服务状态,cinder-volume集成ceph后,状态为"up"
. admin-openrc方法一:
cinder service-list
方法二:
openstack volume service list执行结果如下
[root@controller01 ~]# openstack volume service list
+------------------+----------------+------+---------+-------+----------------------------+
| Binary | Host | Zone | Status | State | Updated At |
+------------------+----------------+------+---------+-------+----------------------------+
| cinder-scheduler | controller01 | nova | enabled | up | 2018-09-19T05:00:20.000000 |
| cinder-scheduler | controller03 | nova | enabled | up | 2018-09-19T05:00:23.000000 |
| cinder-scheduler | controller02 | nova | enabled | up | 2018-09-19T05:00:19.000000 |
| cinder-volume | compute01@ceph | nova | enabled | up | 2018-09-19T05:00:19.000000 |
| cinder-volume | compute02@ceph | nova | enabled | up | 2018-09-19T05:00:21.000000 |[root@controller01 ~]# cinder service-list
+------------------+----------------+------+---------+-------+----------------------------+-----------------+
| Binary | Host | Zone | Status | State | Updated_at | Disabled Reason |
+------------------+----------------+------+---------+-------+----------------------------+-----------------+
| cinder-scheduler | controller01 | nova | enabled | up | 2018-09-19T04:39:59.000000 | - |
| cinder-scheduler | controller02 | nova | enabled | up | 2018-09-19T04:39:59.000000 | - |
| cinder-scheduler | controller03 | nova | enabled | up | 2018-09-19T04:40:02.000000 | - |
| cinder-volume | compute01@ceph | nova | enabled | up | 2018-09-19T04:39:59.000000 | - |
| cinder-volume | compute02@ceph | nova | enabled | up | 2018-09-19T04:40:01.000000 | - |3、生成volume
1、设置卷类型
在任意控制节点为cinder的ceph后端存储创建对应的type,在配置多存储后端时可区分类型;
可通过"cinder type-list"查看
[root@controller01 ~]# cinder type-create ceph
+--------------------------------------+------+-------------+-----------+
| ID | Name | Description | Is_Public |
+--------------------------------------+------+-------------+-----------+
| 406ee6a7-9e8f-49c4-b476-f475ab6f4749 | ceph | - | True |
+--------------------------------------+------+-------------+-----------+为ceph type设置扩展规格,键值" volume_backend_name",value值"ceph"
[root@controller01 ~]# cinder type-key ceph set volume_backend_name=ceph
[root@controller01 ~]# cinder extra-specs-list
+--------------------------------------+------+---------------------------------+
| ID | Name | extra_specs |
+--------------------------------------+------+---------------------------------+
| 406ee6a7-9e8f-49c4-b476-f475ab6f4749 | ceph | {'volume_backend_name': 'ceph'} |
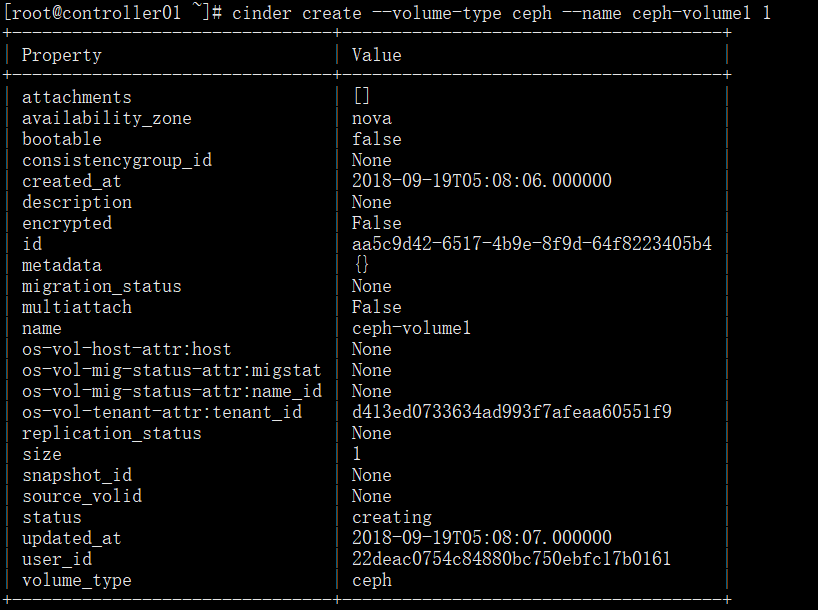
+--------------------------------------+------+---------------------------------+2、生成volume
生成volume:最后的数字"1"代表容量为1G
cinder create --volume-type ceph --name ceph-volume1 1
检查生成的volume
方法一:
cinder list
方法二:
openstack volume list
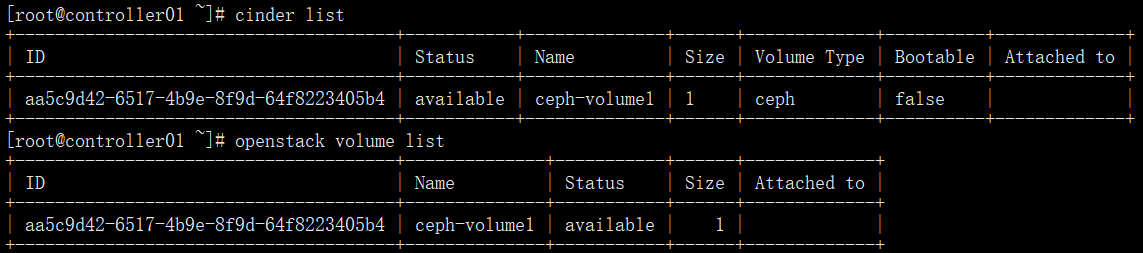
检查ceph集群的volumes pool
rbd ls volumes

四)Nova集成Ceph
1、配置ceph.conf
- 如果需要从ceph rbd中启动虚拟机,必须将ceph配置为nova的临时后端;
- 推荐在计算节点的配置文件中启用rbd cache功能;
- 为了便于故障排查,配置admin socket参数,这样每个使用ceph rbd的虚拟机都有1个socket将有利于虚拟机性能分析与故障解决;
相关配置只涉及全部计算节点ceph.conf文件的client与client.cinder字段,以compute01节点为例
1、更改配置文件
vim /etc/ceph/ceph.conf
[client]
rbd cache = true
rbd cache writethrough until flush = true
admin socket = /var/run/ceph/guests/$cluster-$type.$id.$pid.$cctid.asok
log file = /var/log/qemu/qemu-guest-$pid.log
rbd concurrent management ops = 20
[client.cinder]
keyring = /etc/ceph/ceph.client.cinder.keyring2、创建ceph.conf文件中指定的socker与log相关的目录,并更改属主
mkdir -p /var/run/ceph/guests/ /var/log/qemu/
chown qemu:libvirt /var/run/ceph/guests/ /var/log/qemu/ 2、配置nova.conf
在全部计算节点配置nova后端使用ceph集群的vms池,以compute01节点为例
1、修改配置
vim /etc/nova/nova.conf
[libvirt]
images_type = rbd
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_user = cinder
# uuid前后一致
rbd_secret_uuid = d6addd93-c7ba-43e3-a9dd-ee53677cbd2c
disk_cachemodes="network=writeback"
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED"
# 禁用文件注入
inject_password = false
inject_key = false
inject_partition = -2
# 虚拟机临时root磁盘discard功能,”unmap”参数在scsi接口类型磁盘释放后可立即释放空间
hw_disk_discard = unmap
# 通过“egrep -c '(vmx|svm)' /proc/cpuinfo”命令查看主机是否支持硬件加速,返回1或者更大的值表示支持,返回0表示不支持;
# # 支持硬件加速使用”kvm”类型,不支持则使用”qemu”类型;
# # 一般虚拟机不支持硬件加速
# 原有配置
virt_type=kvm2、重启服务
systemctl restart libvirtd.service
systemctl restart openstack-nova-compute.service
systemctl status libvirtd.service openstack-nova-compute.service 3、配置live-migration
1、修改/etc/libvirt/libvirtd.conf
在全部计算节点操作
注意:根据不同主机,将监听地址改成对应的IP地址
egrep -vn "^$|^#" /etc/libvirt/libvirtd.conf
# 取消以下三行的注释
22:listen_tls = 0
33:listen_tcp = 1
45:tcp_port = "16509"
# 取消注释,并修改监听端口
55:listen_addr = "10.20.9.46"
# 取消注释,同时取消认证
158:auth_tcp = "none" 2、修改/etc/sysconfig/libvirtd
在全部计算节点操作
egrep -vn "^$|^#" /etc/sysconfig/libvirtd
# 取消注释
9:LIBVIRTD_ARGS="--listen" 3、设置防火墙iptables
- live-migration时,源计算节点主动连接目的计算节点tcp16509端口,可以使用"virsh -c qemu+tcp://{node_ip or node_name}/system"连接目的计算节点测试;
- 迁移前后,在源目计算节点上的被迁移instance使用tcp49152~49161端口做临时通信;
- 因虚拟机已经启用iptables相关规则,此时切忌随意重启iptables服务,尽量使用插入的方式添加规则;
- 同时以修改配置文件的方式写入相关规则,切忌使用"iptables saved"命令;
在全部计算节点操作(若开了防火墙,需要设置)
iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 16509 -j ACCEPT
iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 49152:49161 -j ACCEPT 4、重启服务
libvirtd与nova-compute服务都需要重启
systemctl restart libvirtd.service
systemctl restart openstack-nova-compute.service
systemctl status libvirtd.service openstack-nova-compute.service
netstat -tunlp | grep 16509 4、验证
在任意控制节点操作
如果使用ceph提供的volume做启动盘,即虚拟机运行镜像文件存放在共享存储上,此时可以方便地进行live-migration。
1、创建基于ceph存储的bootable存储卷
当nova从rbd启动instance时,镜像格式必须是raw格式,否则虚拟机在启动时glance-api与cinder均会报错;
首先进行格式转换,将*.img文件转换为*.raw文件(这个没有返回值,执行完在指定的目录下生成指定格式的文件)
qemu-img convert -f qcow2 -O raw ~/cirros-0.3.5-x86_64-disk.img ~/cirros-0.3.5-x86_64-disk.raw生成raw格式镜像
openstack image create "cirros-raw" \
--file ~/cirros-0.3.5-x86_64-disk.raw \
--disk-format raw --container-format bare \
--public
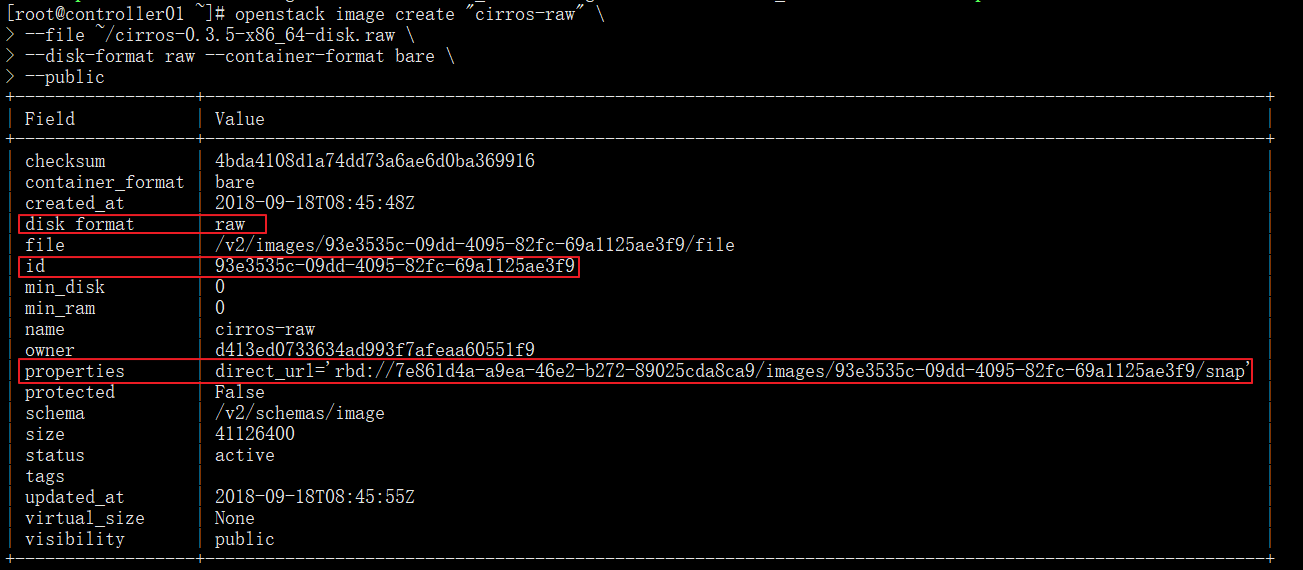
使用新镜像创建bootable卷(注意image-id根据自己的做出更改)
cinder create --image-id 93e3535c-09dd-4095-82fc-69a1125ae3f9 --volume-type ceph --name ceph-bootable1 2#查看新创建的bootable卷
cinder list 从基于ceph后端的volumes新建实例;
"--boot-volume"指定具有"bootable"属性的卷,启动后,虚拟机运行在volumes卷
[root@controller01 ~]# nova boot --flavor m1.tiny \
--boot-volume db0f83c0-14f7-4548-8807-4b1f593630a4 \
--nic net-id=91e78b9c-cfcd-4af2-851a-a27839edf571 \
--security-group default \
cirros-cephvolumes-instance1 2、从ceph rbd启动虚拟机(命令行创建实例)
--nic:net-id指网络id,非subnet-id;
最后"cirros-cephrbd-instance1"为instance名
nova boot --flavor m1.tiny --image cirros-raw --nic net-id=91e78b9c-cfcd-4af2-851a-a27839edf571 --security-group default cirros-cephrbd-instance1查询生成的instance
nova list 查看生成的instance的详细信息
nova show 7648251c-62a1-4f98-ba3f-e5f30f5804b4 验证是否从ceph rbd启动
rbd ls vms 3、对rbd启动的虚拟机进行live-migration
使用"nova show 7648251c-62a1-4f98-ba3f-e5f30f5804b4"得知从rbd启动的instance在迁移前位于compute02节点;
或使用"nova hypervisor-servers compute02"进行验证;
nova live-migration cirros-cephrbd-instance1 compute01迁移过程中可查看状态
nova list 迁移完成后,查看instacn所在节点;
或使用"nova show 7648251c-62a1-4f98-ba3f-e5f30f5804b4"命令查看"hypervisor_hostname"
nova hypervisor-servers compute02
nova hypervisor-servers compute0