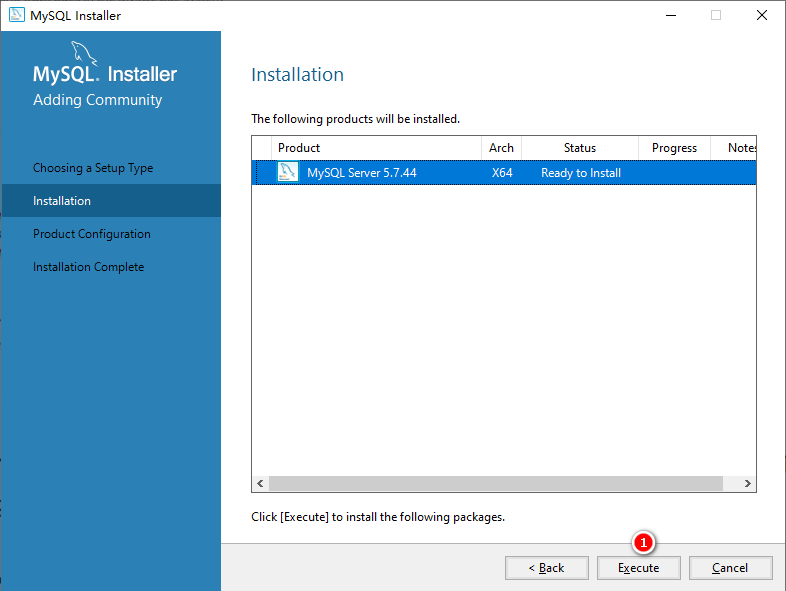
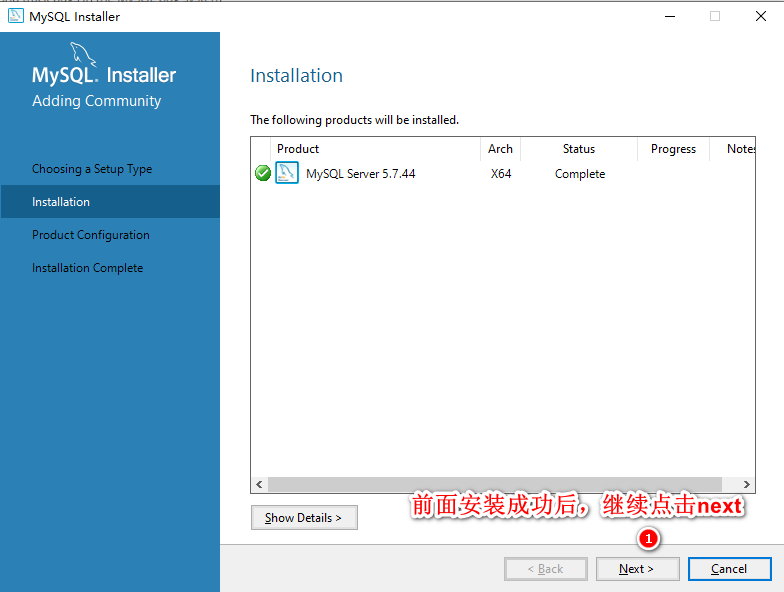
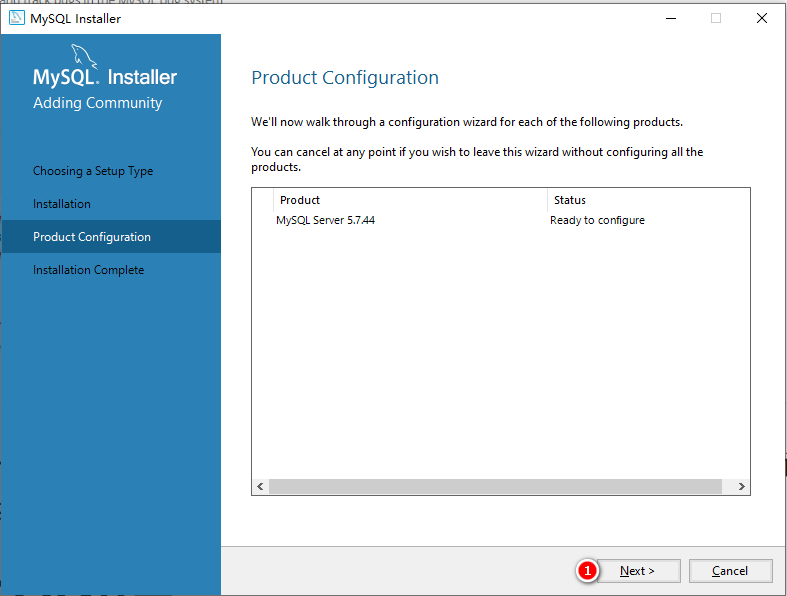
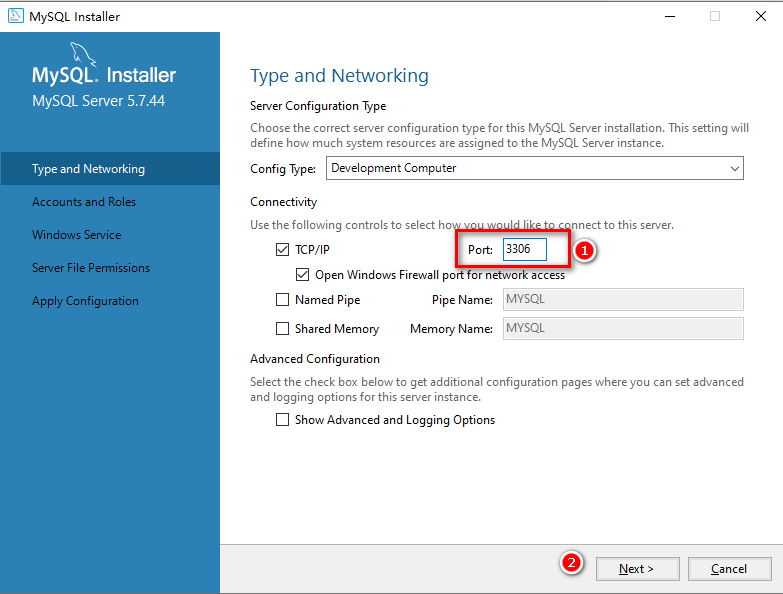
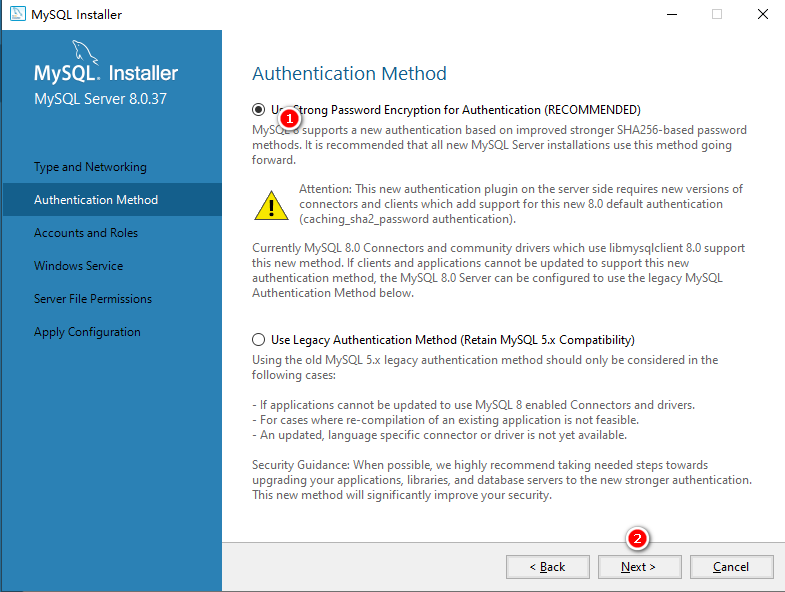
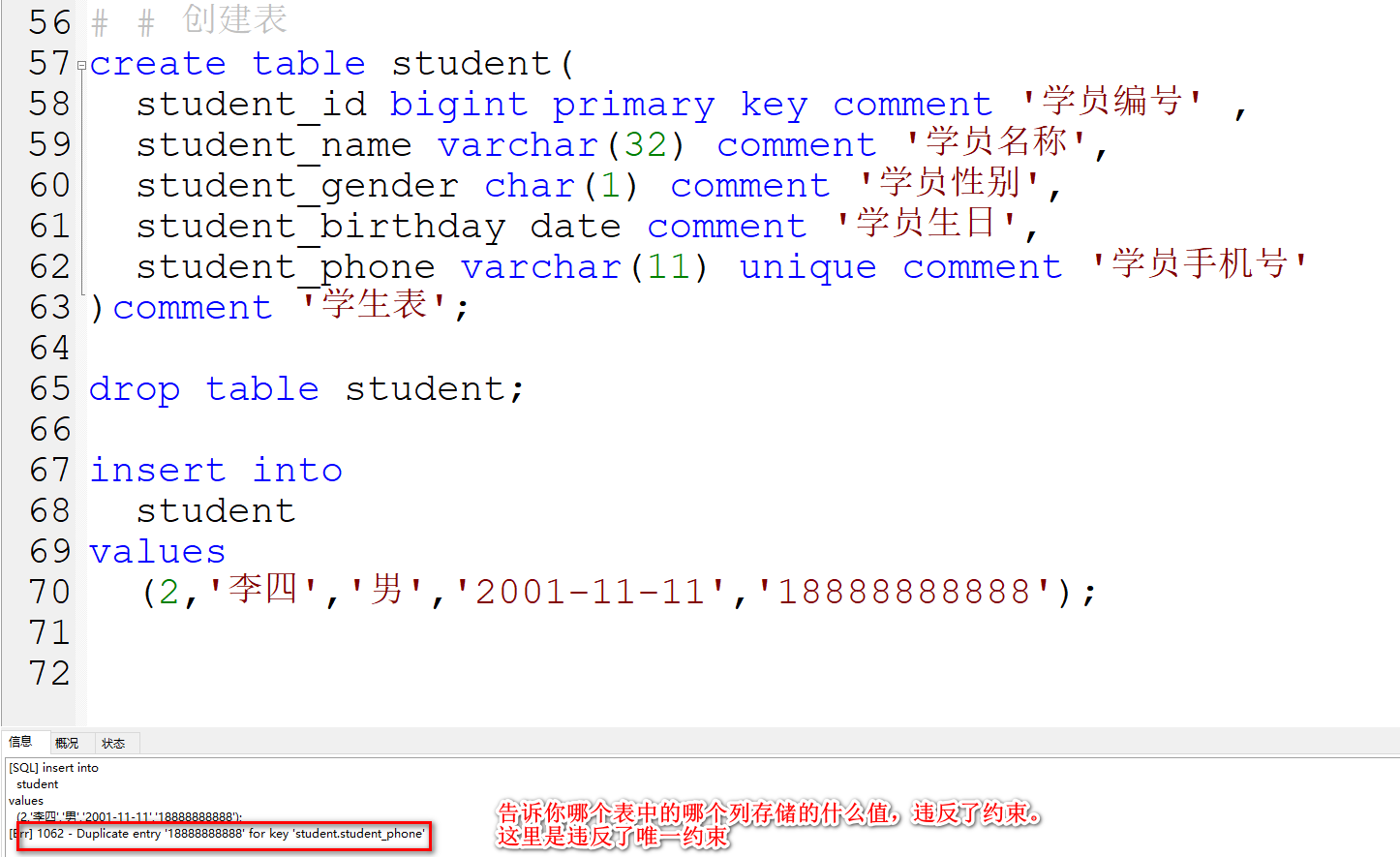
SELECT
first_name as "名", last_name as "姓", salary * 12 年薪
FROM
t_employees;
5.2.5 查询结果去重
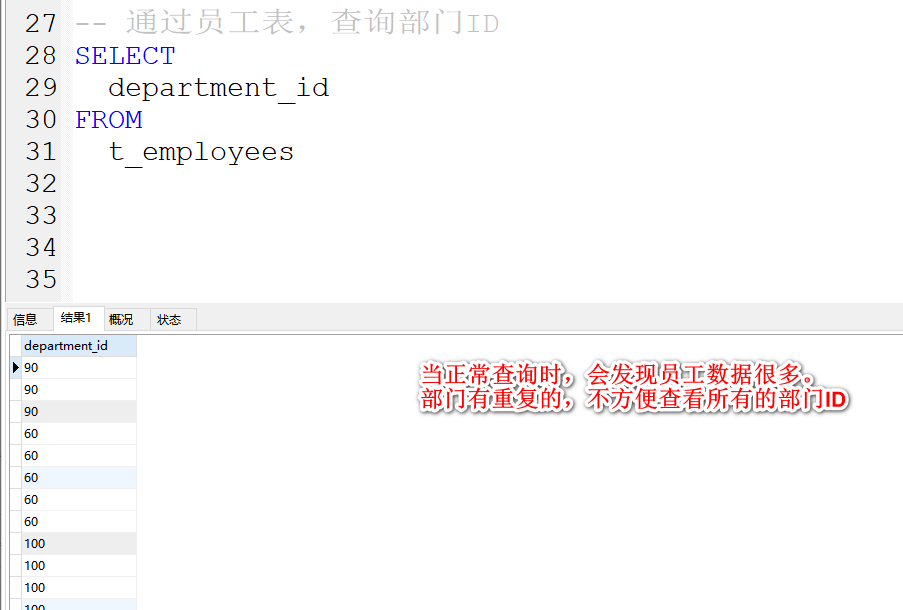
通过员工表,查询部门ID。
sql复制代码
-- 通过员工表,查询部门ID
SELECT
department_id
FROM
t_employees
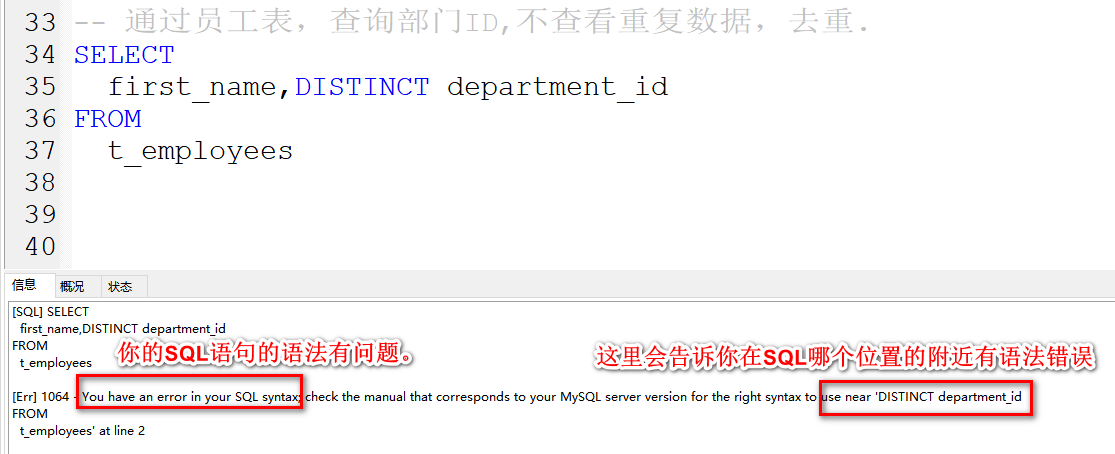
通过员工表,查询部门ID,不查看重复数据,去重。
DISTINCT放在所有列名的最前面,会帮你把数据重复的行,去掉。
sql复制代码
-- 通过员工表,查询部门ID,不查看重复数据,去重.
SELECT
DISTINCT department_id
FROM
t_employees
5.3 排序查询
在执行SELECT查询后,查询到的结果一般是跟表中的结果顺序一致的。
如果需要基于一些列做排序,可以使用MySQL提供的order by 操作
语法: SELECT 列名 FROM 表名 ORDER BY 排序列 排序规则 , 排序列 排序规则 ............
排序规则
描述
ASC(默认规则)
对前面排序列做升序排序
DESC
对前面排序列做降序排序
查询员工的编号,姓,薪资。 按照薪资的高低做降序排序
sql复制代码
# 查询员工的编号,姓,薪资。 按照薪资的高低做降序排序
SELECT
employee_id,last_name, salary
FROM
t_employees
ORDER BY
salary DESC
查询员工的姓,工资,入职时间。 优先按照工资做降序,再根据入职时间做升序
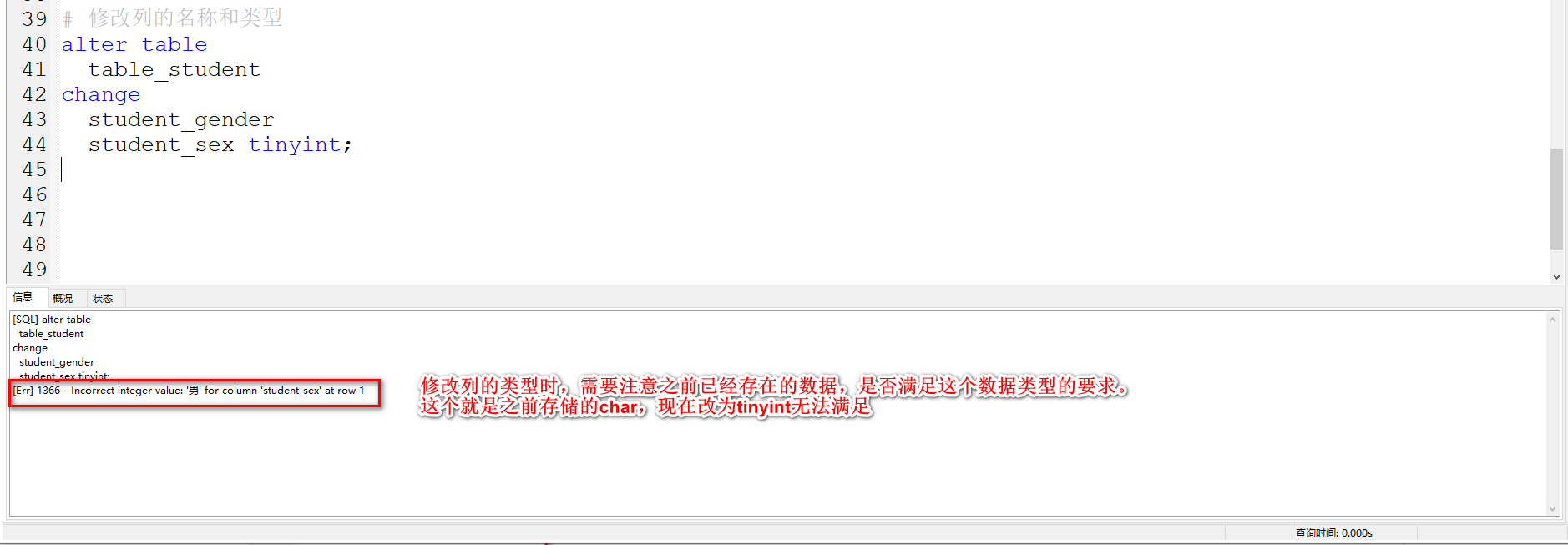
sql复制代码
-- 查询员工的姓,工资,入职时间。 优先按照工资做降序,再根据入职时间做升序
-- 运行选中的SQL的快捷键 ,Ctrl + Shift + R
SELECT
last_name 姓, salary 工资, hire_date 入职时间
FROM
t_employees
ORDER BY
salary DESC,
hire_date
5.4 条件查询
语法:select 列明 from 表名 where 条件
关键字
描述
where
在查询结果中,筛选符合条件的查询结果,条件为布尔表达式
5.4.1 等值判断(=)
注意:与Java不中,Java中是==,而在MySQL中是=
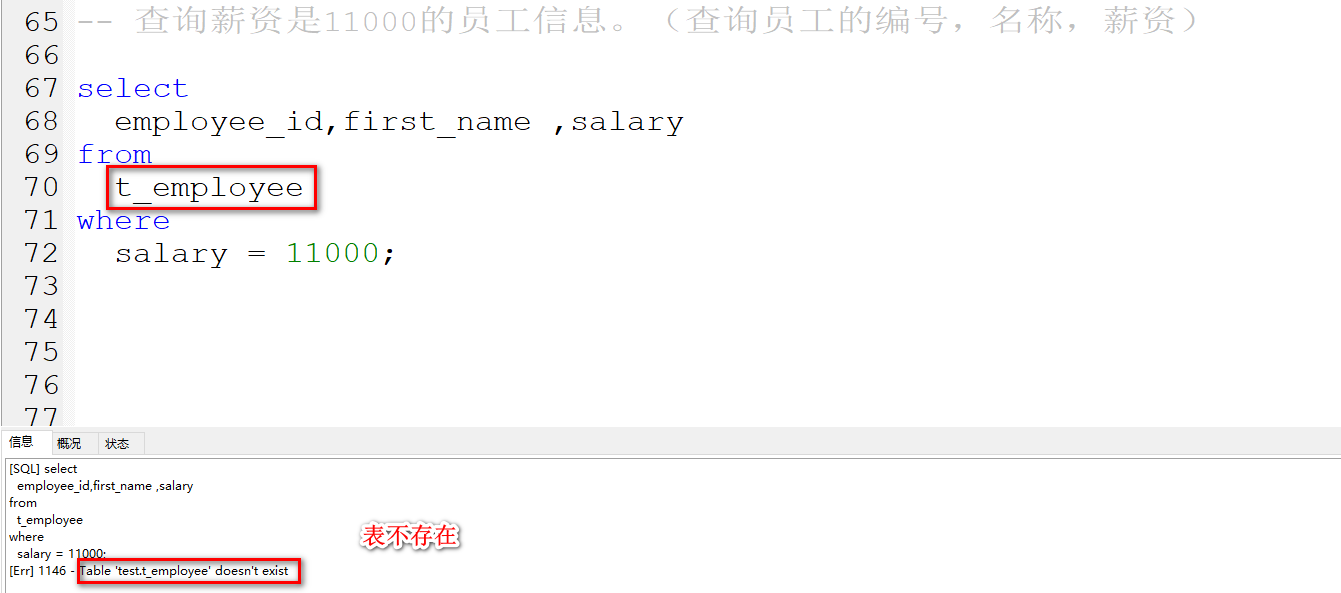
查询薪资是11000的员工信息。(查询员工的编号,名称,薪资)
sql复制代码
select
employee_id,first_name ,salary
from
t_employees
where
salary = 11000;
5.4.2 不等值判断(<、>、<=、>=、!=、<>)
其中,前四个没啥说的,常规的大于,小于之类的判断。
其中 != 和 <> 都代表不等于的意思。
查询薪资是大于11000员工信息。(查询员工的编号,名称,薪资)
sql复制代码
select
employee_id,first_name ,salary
from
t_employees
WHERE
salary > 11000;
5.4.3 逻辑判断(and,or,not)
类似Java中的 && ,|| ,!
其中 and 左右的条件都需要满足才可以。
其中 or 左右的条件,满足其一就可以查询到。
其中 not 会将条件取反
查询薪资是11000大洋,并且提成是0.3的员工信息(查询员工的编号,名称,薪资,提成)
sql复制代码
select
employee_id,first_name ,salary ,commission_pct
from
t_employees
where
salary = 11000 and commission_pct = 0.3;
5.4.4 区间查询(between 数值 and 数值)
这个between and其实就相当于 用大于等于和小于等于的组合。
包含边界的。
需要指定好字段值的边界。并且需要左侧的数值小,右侧的数值大。不然无法查询到结果。
查询员工的薪资在5000~10000之间的员工信息。(查询员工的编号,名称,薪资)
sql复制代码
select
employee_id,first_name ,salary
from
t_employees
where
salary between 5000 and 10000;
5.4.5 NULL 值判断(is null、is not null)
当对某个列判断是否是NULL值时,不能使用 = 或者 != 之类的方式。
必须采用 字段 is null 、 字段 is not null 的方式
查询没有提成的员工信息(查询员工的编号,名称,薪资,提成)
sql复制代码
select
employee_id,first_name ,salary,commission_pct
from
t_employees
where
commission_pct is not null;
5.4.6 字段多值判断(in)
正常如果涉及到了某一个字段,可以为多个值的匹配条件时。
正常可能需要 字段 = xxx or 字段 = yyy or 字段 = zzz。 写着成本太高。
可以采用in来实现。
字段 in (xxx,yyy,zzz)
查询员工属于60,70,80,90号部门的员工信息。(查询员工的编号,名称,薪资,部门编号)
sql复制代码
select
employee_id,first_name ,salary,department_id
from
t_employees
where
department_id in (60,70,80,90);
5.4.7 模糊查询(like)
模糊查询一般是来匹配字符串的。
其中有两个关键字。 % _
字段 like 's%' :查询出这个字段中以s开头的数据。
字段 like 's_' :查询出s开头,并且后面只有一个字符
%:代表任意长度的任意字符
_:代表单个任意字符
Ps:这两个特殊字符只能配合like使用
查询名字以L开头的员工信息(查询员工的编号,名称,薪资)
sql复制代码
select
employee_id,first_name ,salary
from
t_employees
where
first_name like 'L%'
查询名字以L开头,但是名字长度为4个字符的员工信息(查询员工的编号,名称,薪资)
java复制代码
select
employee_id,first_name ,salary
from
t_employees
where
first_name like 'L___'
5.4.8 分支结构查询(case when then else end)
语法:这里的分支结构查询一般是放在select后面的特殊操作。
复制代码
case
when 条件1 then 结果1
when 条件2 then 结果2
when 条件3 then 结果3
..................
else 结果
end
可以认为是case开头,end结尾,中间写when then的内容
就是类似Java中的switch
查询员工信息,并根据薪资范围,体现出员工的薪资等级
salary 0 ~ 4000 = E
salary 4000 ~ 6000 = D
salary 6000 ~ 8000 = C
salary 8000 ~ 10000 = B
salary 10000 ~ ...... = A
sql复制代码
select
employee_id,first_name ,salary ,
case
when salary >= 0 and salary < 4000 then 'E'
when salary >= 4000 and salary < 6000 then 'D'
when salary >= 6000 and salary < 8000 then 'C'
when salary >= 8000 and salary < 10000 then 'B'
else 'A'
end as salary_level
from
t_employees;
语法:select 列名 from 表名 where 条件 group by 列名
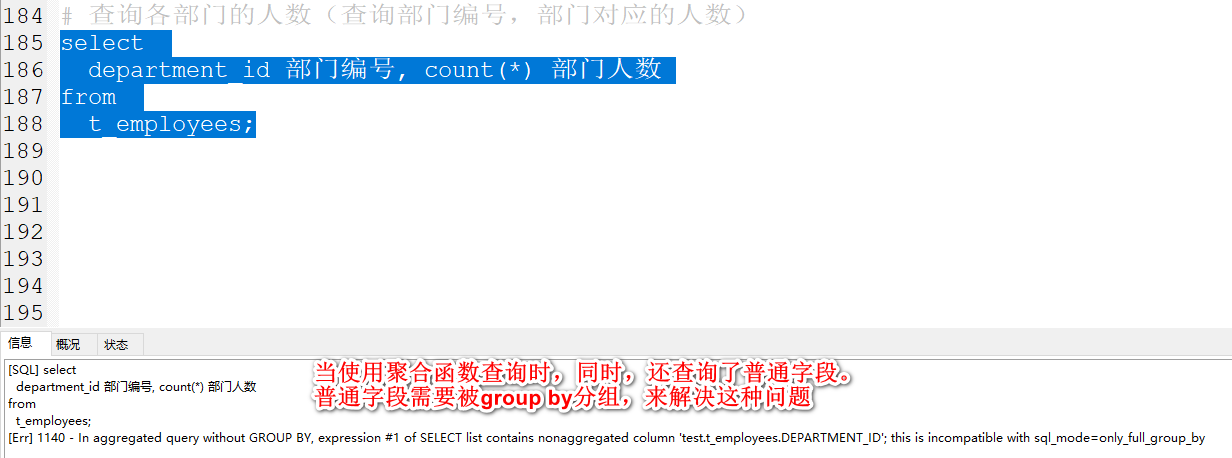
查询各部门的人数(查询部门编号,部门对应的人数)
sql复制代码
select
department_id 部门编号, count(*) 部门人数
from
t_employees
group by department_id;
查询各个部门的平均工资(查询部门编号,部门的平均工资)
sql复制代码
select
department_id 部门编号, avg(salary) 平均工资
from
t_employees
group by department_id;
查询各个部门、各个岗位的人数(部门编号,岗位信息,人数)
1、根据department_id分组。
2、根据job_id分组
3、做count统计查询
sql复制代码
select
department_id 部门编号, job_id 岗位信息, count(*) 人数
from
t_employees
group by department_id,job_id;
# 查询各个部门、各个岗位,薪资大于5000的人数(部门编号,岗位信息,人数)
select
department_id 部门编号, job_id 岗位信息, count(*) 人数
from
t_employees
where
salary > 5000
group by department_id,job_id;
5.9 分组过滤查询
如果需要在做过分组之后,再次对接过做二次筛选,需要使用having的方式编写条件
语法: select 列名 from 表名 where 条件 group by 列名 having 条件 order by 列名
查询各个部门、各个岗位的人数(部门编号,岗位信息,人数),只查看人数大于10个的
sql复制代码
select
department_id 部门编号, job_id 岗位信息, count(*) 人数
from
t_employees
group by department_id,job_id
having 人数 > 10;
查询各个部门中,平均薪资大于10000的部门信息(部门编号,平均薪资)
sql复制代码
select
department_id 部门编号,avg(salary) avg_salary
from
t_employees
group by department_id
having avg_salary > 10000;
# 查询各个部门中,所有员工平均薪资大于10000的部门信息(部门编号,平均薪资),在根据平均薪资做排序
select
department_id 部门编号,avg(salary) avg_salary
from
t_employees
group by department_id
having avg_salary > 10000
order by avg_salary asc;
5.10 限定查询
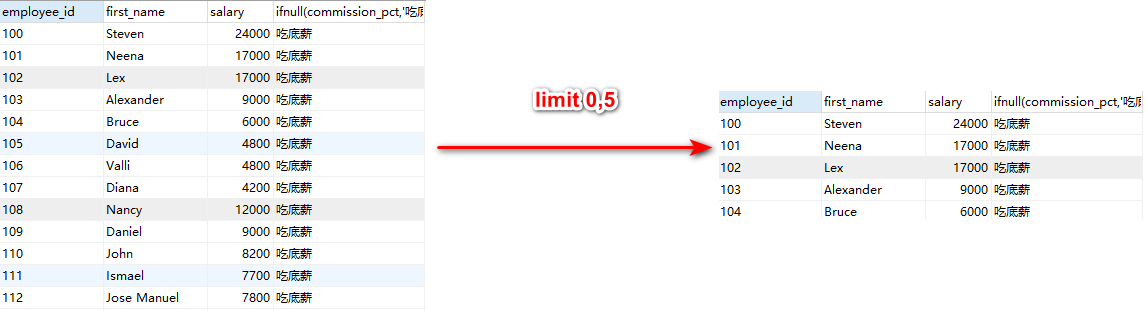
比如查询时,查询到了上千条的数据,但是暂时只需要前5条,可以基于limit只获取前5条数据返回。
采用limit帮助咱们实现。 limit是MySQL特有的一个关键字。
语法:select 列名 from 表名 where 条件 group by 列名 having 条件 order by 列名 limit 起始行,行数
起始行(offset):你返回的数据,从第几行开始, 从第0行开始。
行数(size):一共返回几行数据
limit 0,5:从第一行数据开始,往下一共返回5条。
limit的第一个offset可以省略不写,不写代表写的是0。
查询表中薪资最高的前5名员工的所有信息。
薪资最高的话,需要基于salary做降序排序。
基于limit,只返回前5条数据。
sql复制代码
select
*
from
t_employees
order by salary desc
limit 0,5
查询表中薪资最高的6~10名员工的所有信息。
sql复制代码
select
*
from
t_employees
order by salary desc
limit 5,5
limit很多时候可以同于分页操作,比如需要分页时
可以采用limit,在数据库中查询到不同页数的数据,给页面返回,让页面展示数据即可。
5.11 子查询
查询语句返回的结果,可以再次看成一张表去操作。
select 列名 from 表名 where 条件(子查询操作替代一些值)
select 列名 from (子查询的结果集) where 条件
5.11.1 子查询作为查询字段某个值
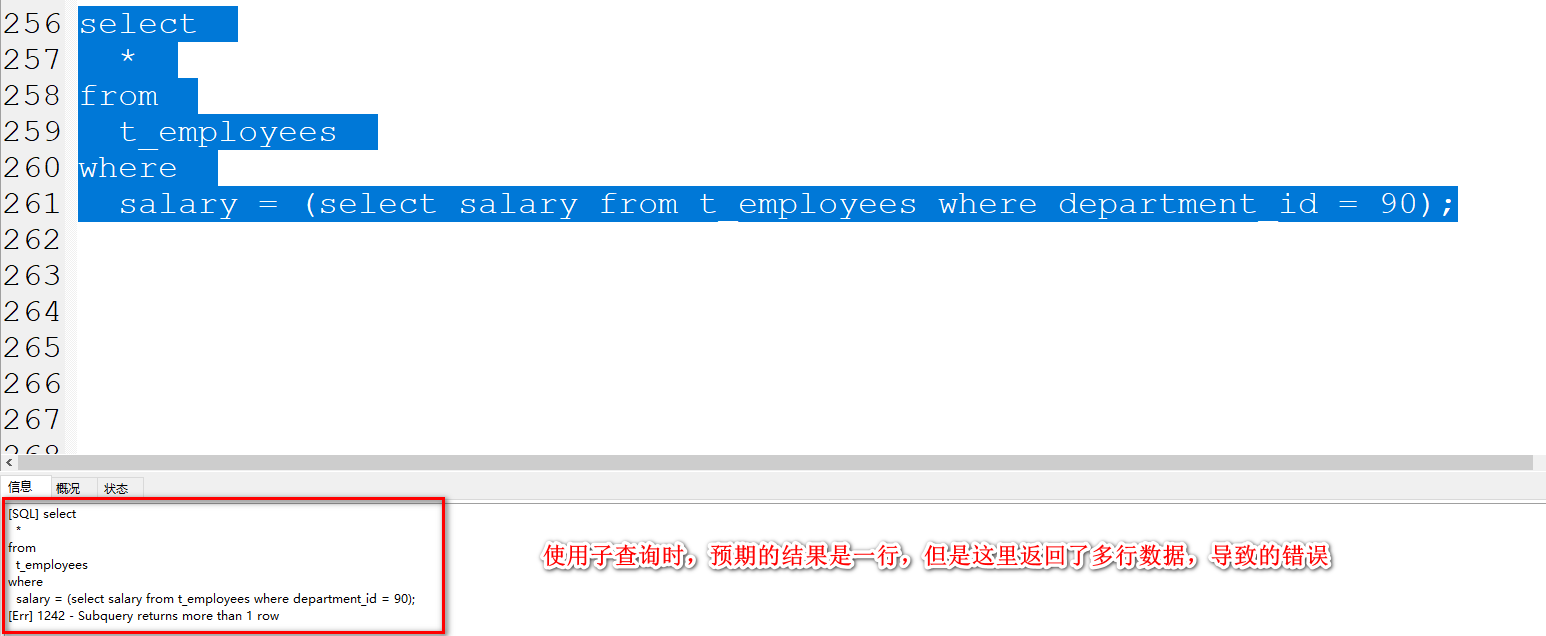
查询薪资和Bruce工资一致的员工信息。
通过查询可以得到Bruce的工资信息
再基于另一个查询,将前面的Bruce的薪资结果作为条件判断的一环,从而实现利用子查询得到结果
1、查询Bruce的工资信息,返回 单列单行
select salary from t_employees where first_name = 'Bruce';
2、基于Bruce的工资信息查询与其薪资一致的员工信息
sql复制代码
select
*
from
t_employees
where
salary = (select salary from t_employees where first_name = 'Bruce');
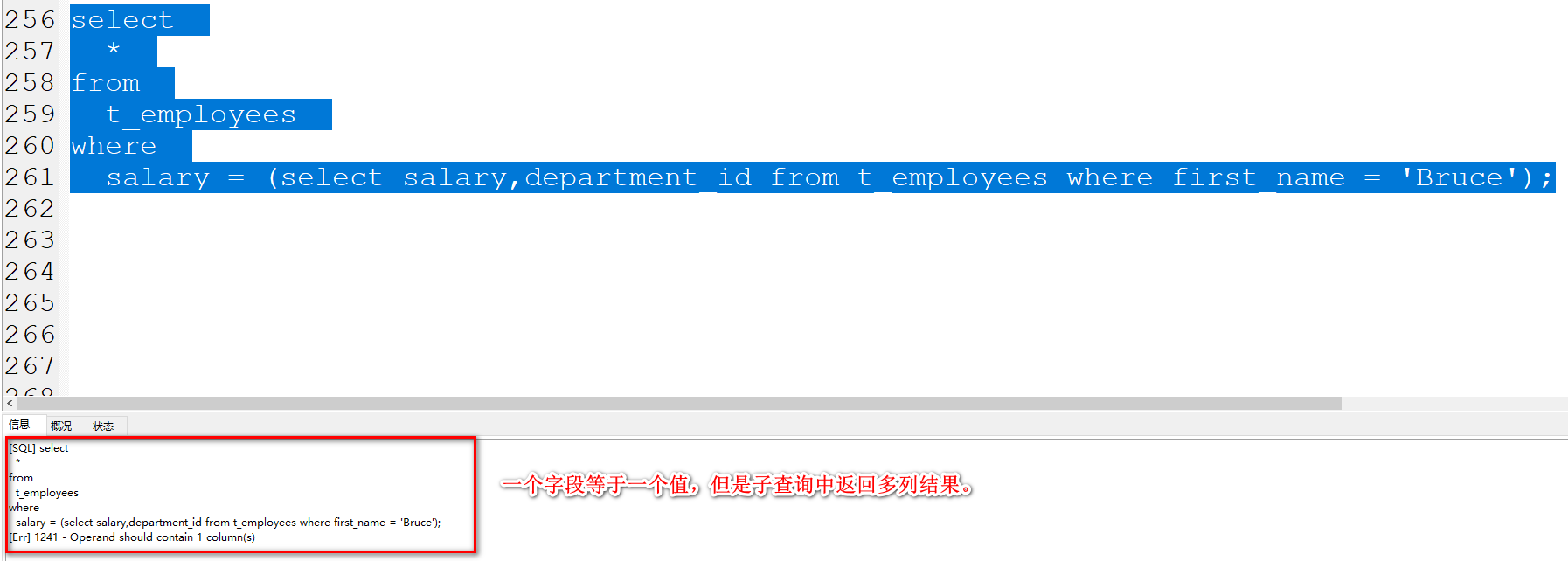
5.11.2 子查询作为 字段多值判断的值
因为字段多值判断是采用in的方式去做条件筛选。 一个字段需要多个值。
在利用子查询时,应当返回 单列多行 数据。
查询last_name为King同一部门的员工信息
1、查询last_name为King的部门信息。
select department_id from t_employees where last_name = 'King';
2、基于上述查询返回的结果,查看同部门的员工信息
sql复制代码
select
*
from
t_employees
where
department_id in (select department_id from t_employees where last_name = 'King');
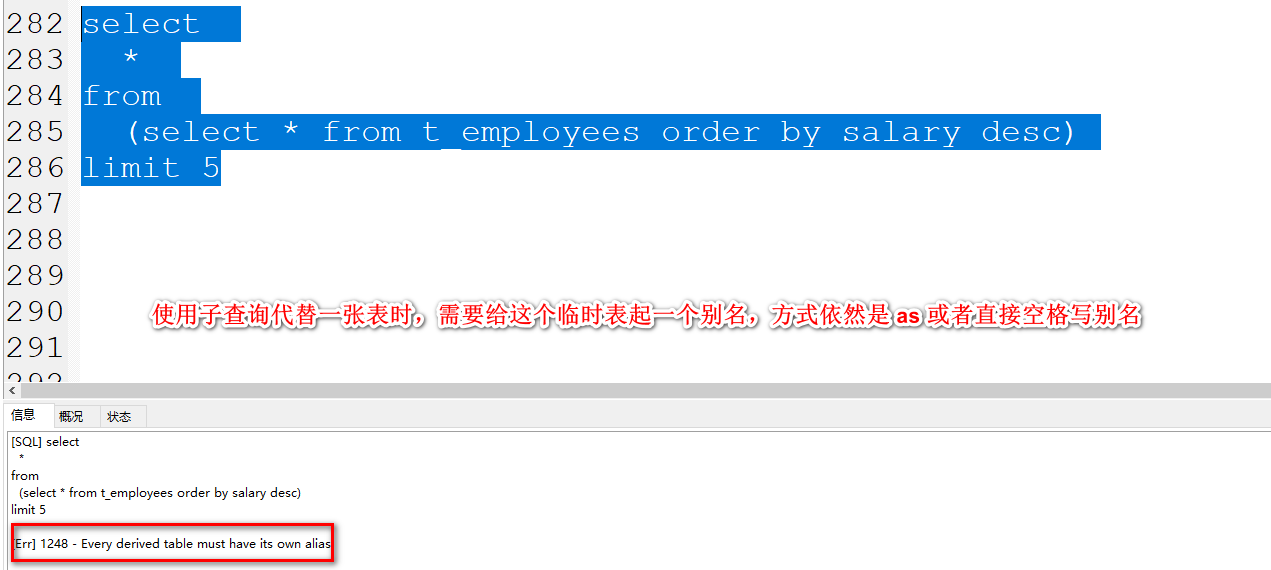
5.11.3 子查询作为 一张表操作。
可以直接基于子查询返回的结果集做二次筛选。
查询员工表中,工资排名前5名的员工。
这个查询可以直接使用order by 排序,然后基于limit做筛选。
就为了使用,搞两个SQL实现,利用子查询来玩。
1、查询员工的信息,基于salary做降序排序。
select * from t_employees order by salary desc;
2、将上述的结果基于limit筛选出前5条。
sql复制代码
select
*
from
(select * from t_employees order by salary desc) as temp
limit 5
5.11.4 子查询的ALL、ANY(了解)
之前在给字段做=判断时,子查询必须返回单列单行的数据,不然报错。
其实在做=判断时,即便返回了单列多行数据,也可以采用ALL、ANY关键字解决问题。
查询工资高于60部门员工的,所有人的信息。
select salary from t_employees where department_id = 60;
1、查询比60部门所有员工薪资都高的员工信息。
sql复制代码
select
*
from
t_employees
where
salary > ALL (select salary from t_employees where department_id = 60);
2、查询比60部门任意一名员工薪资高的员工信息。
sql复制代码
select
*
from
t_employees
where
salary > ANY (select salary from t_employees where department_id = 60);
语法:select 列名 from 表1 连接方式 表2 on 连接条件连接方式 表3 on 连接条件 ............
内连接语法: select 列名 from 表1 inner join 表2 on 连接条件
外连接:
左外连接:select 列名 from 表1 left outer join 表2 on 连接条件
右外连接:select 列名 from 表1 right outer join 表2 on 连接条件 内连接查询操作。
内连接查询,针对哪些 连接条件 无法满足的数据,会直接筛选掉。
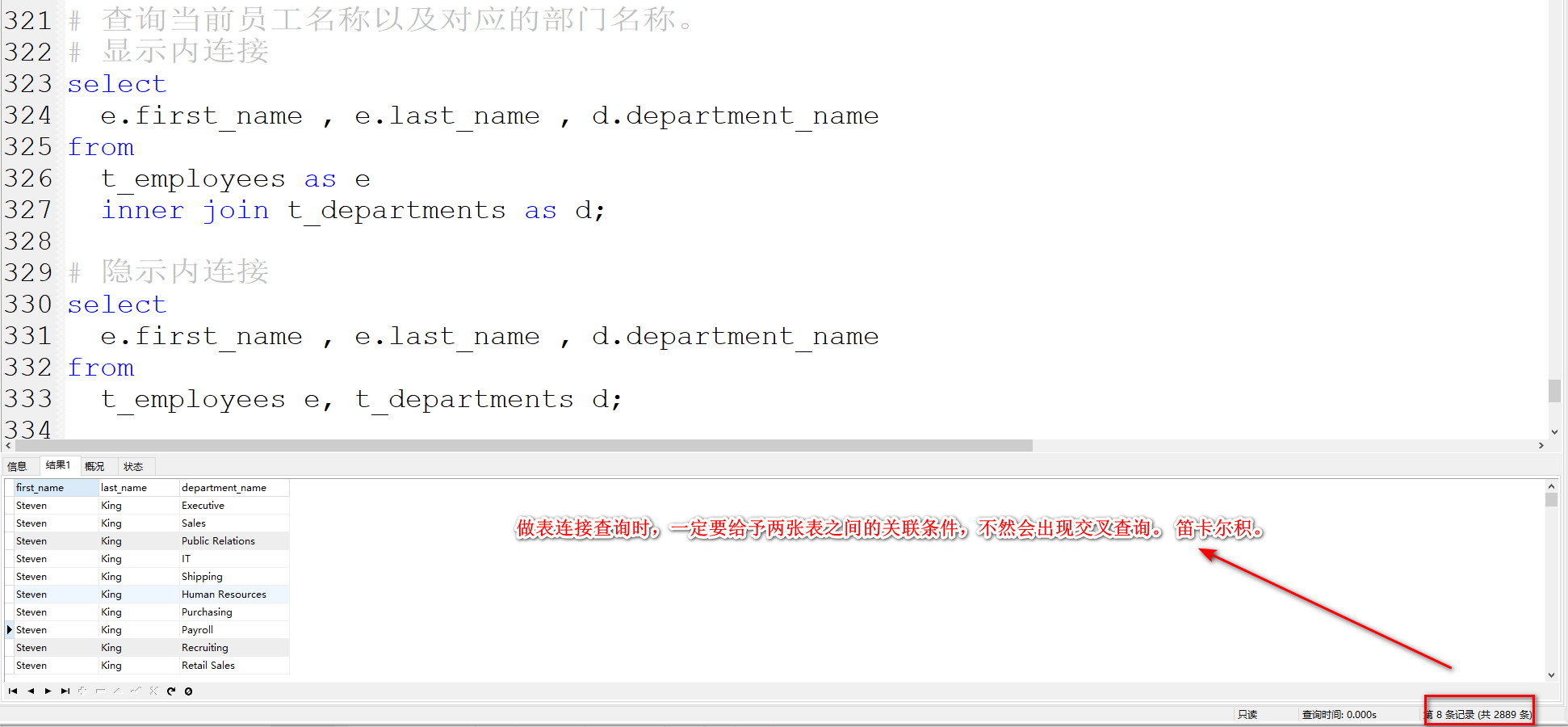
查询当前员工名称以及对应的部门名称。
sql复制代码
# 显示内连接
select
e.first_name , e.last_name , d.department_name
from
t_employees as e
inner join t_departments as d on e.department_id = d.department_id;
# 隐示内连接
select
e.first_name , e.last_name , d.department_name
from
t_employees e, t_departments d
where
e.department_id = d.department_id;
查询员工的名称,部门的名称,部门所在国家的信息(三张表联查)
sql复制代码
# 查询员工的名称,部门的名称,部门所在国家的信息(三张表联查)
# 显示内连接
select
e.first_name , e.last_name ,d.department_name,l.city
from
t_employees e
inner join t_departments d on e.department_id = d.department_id
inner join t_locations l on l.location_id = d.location_id;
# 隐示内连接
select
e.first_name , e.last_name ,d.department_name,l.city
from
t_employees e , t_departments d ,t_locations l
where
e.department_id = d.department_id
and d.location_id = l.location_id;
外连接查询
还是基于前面玩的查询,查询当前员工名称以及对应的部门名称。
因为之前用的内连接的方式,导致一个员工
发现,最后的部门Id是一个NULL,导致后续查询时,并没有这个员工的信息返回。
现在可以采用外链接的方式,来解决这个问题。
外链接前面说过左外的语法,和右外的语法。
其实就是将左边的表,或者是右边的表作为基准表,基准表回返回全部的数据,无论连接条件是否满足。
sql复制代码
# 查询当前 所有 员工名称以及对应的部门名称。
select
e.first_name , e.last_name ,d.department_name
from
t_employees e left outer join t_departments d
on e.department_id = d.department_id;
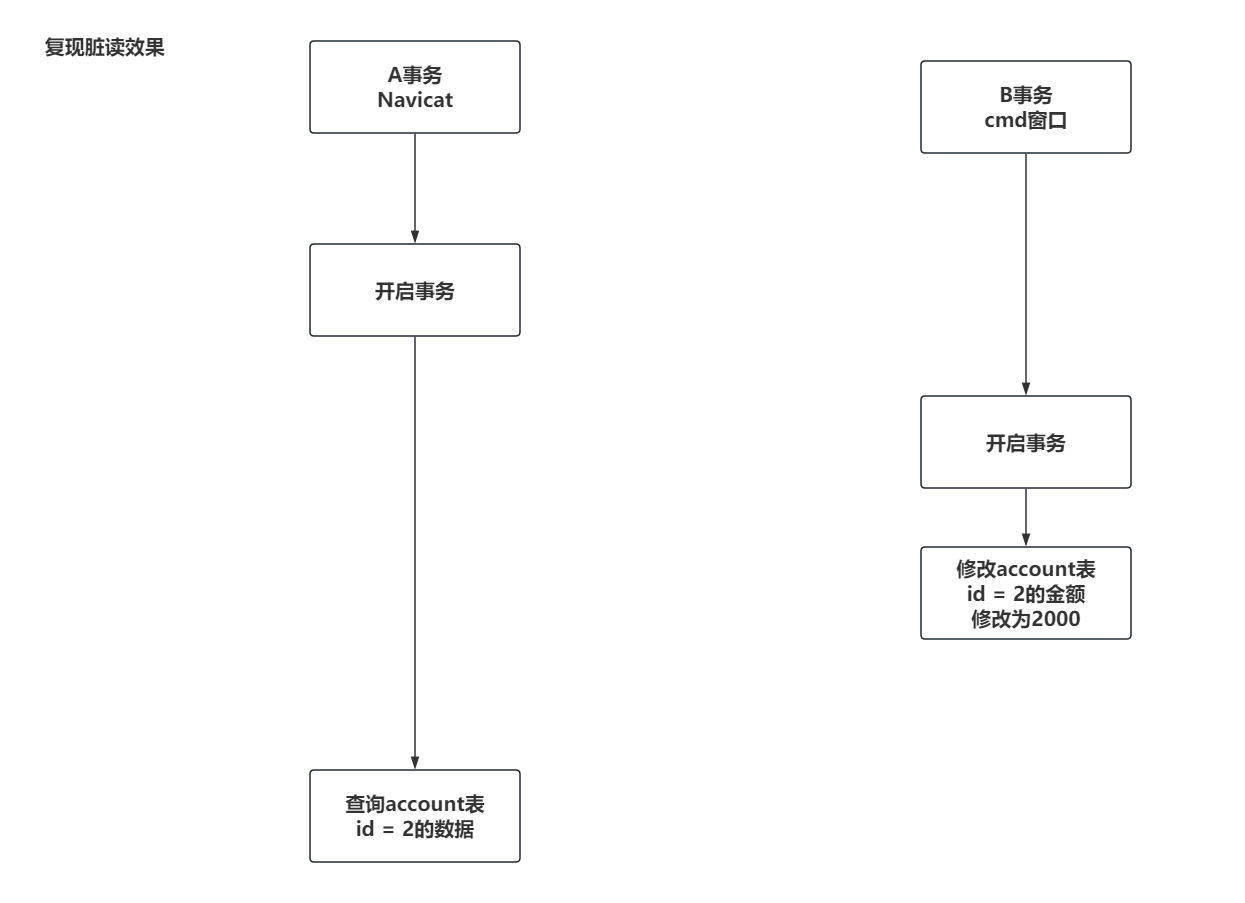
-- 为了查看到所有问题的效果,这里优先将事务的隔离级别设置为最低等级。READ-UNCOMMITTED。
set global transaction_isolation = 'READ-UNCOMMITTED';
-- 因为设置的是全局的事务隔离级别,设置完毕后,关闭连接,重新打开,才会生效。
select @@transaction_isolation;
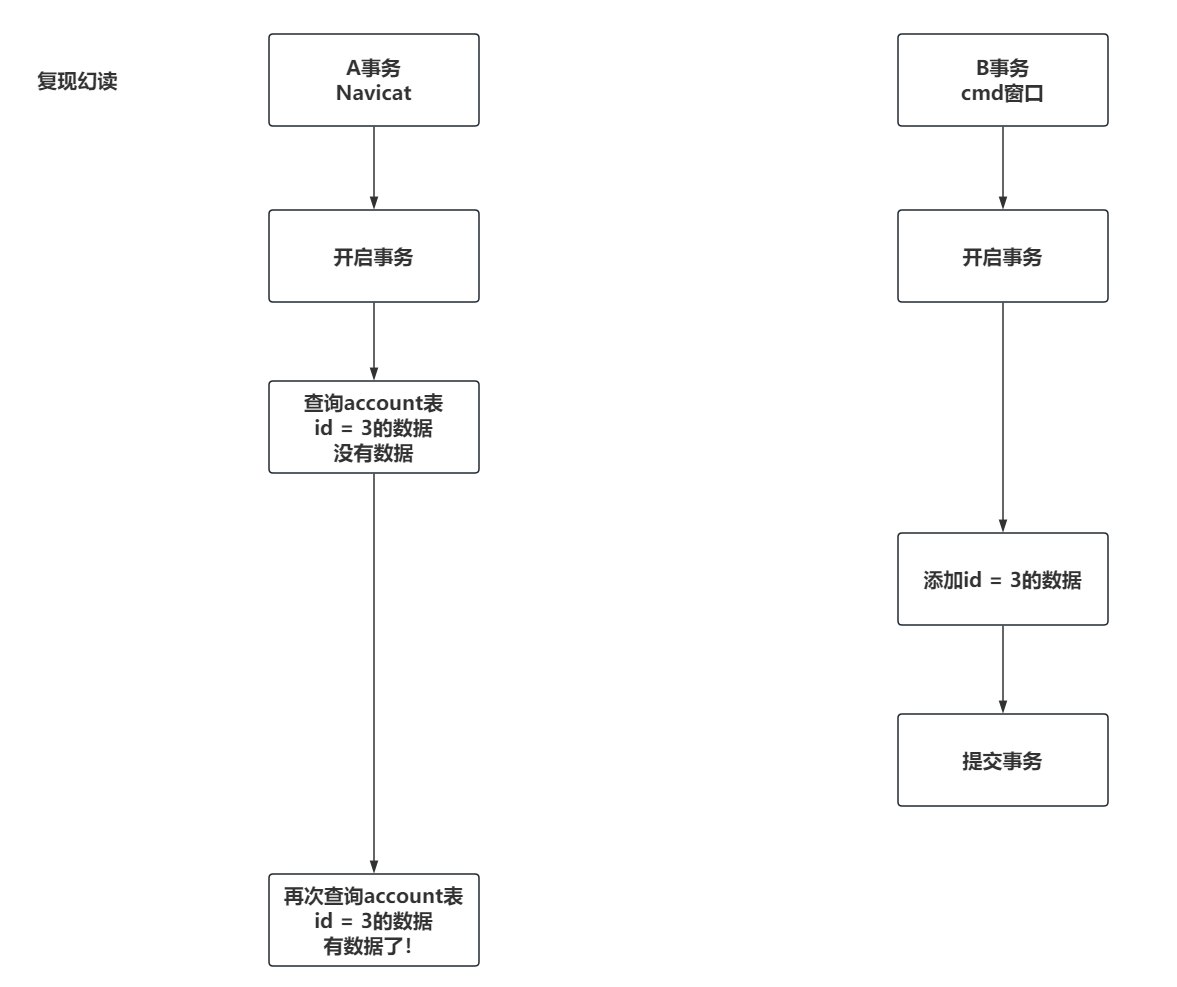
复现脏读效果:
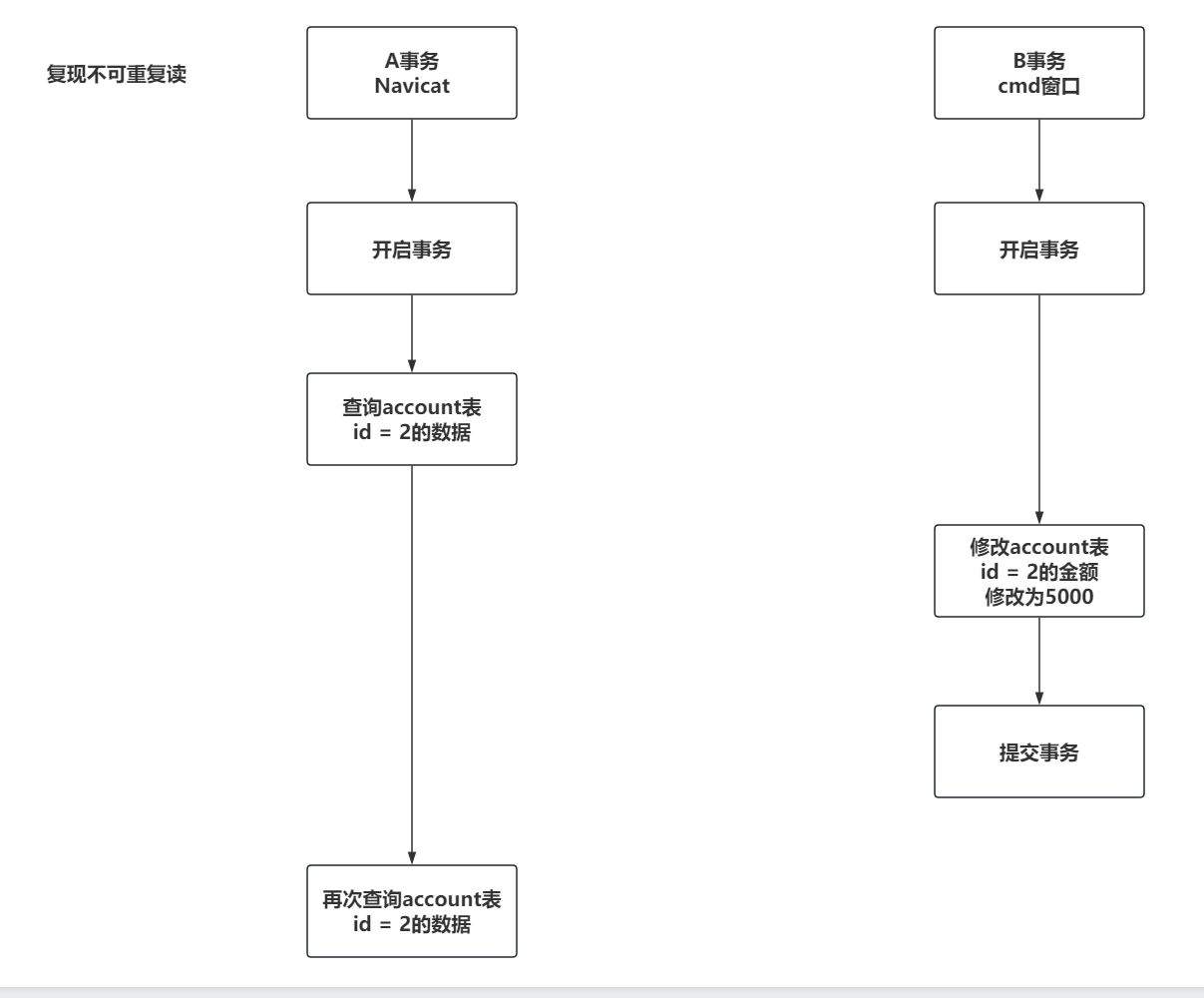
复现不可重复读效果:
复现幻读的效果:
9.6 事务的隔离级别
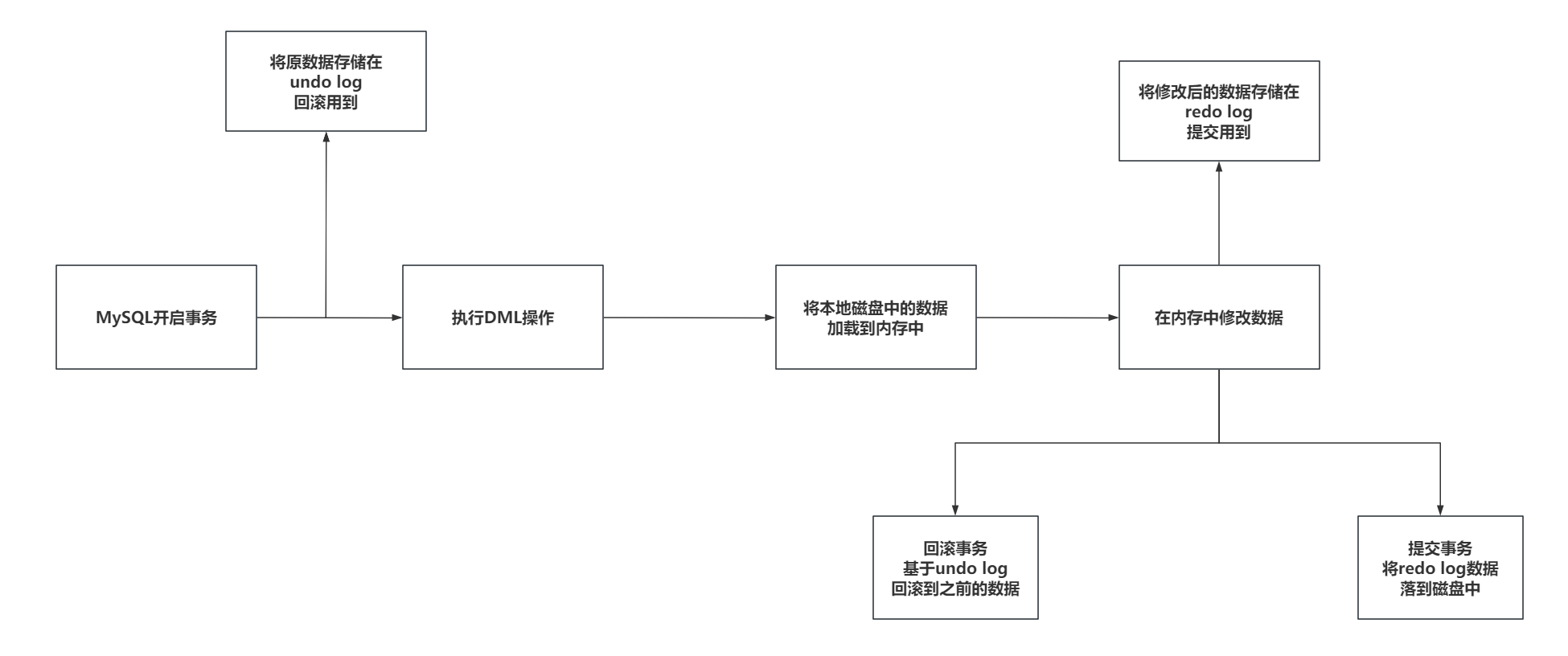
事务的隔离级别就是用来解决前面9.5聊到的事务并发的三个问题的。
READ-UNCOMMITTED(读未提交):可以读取到未提交事务的数据。
(一个问题都不能解决)
READ-COMMITTED(读已提交):可以读取到已经提交事务的数据。
(只能解决脏读)
Oracle默认隔离级别是READ-COMMITTED
REPEATABLE-READ(可重复读):会让一次事务多次查询同一数据结果一致(修改导致)。
(可以解决脏读和不可重读)
MySQL默认隔离级别是可重复读REPEATABLE-READ
SERIALIZABLE(串行化):上锁,所有问题都能解决。
(可以解决所有问题)
为了解决上面说道的各种问题,这里可以设置事务的隔离级别,然后查看效果
查看事务的隔离级别的方式:
复制代码
select @@transaction_isolation;
设置事务的隔离级别,可以设置全局的,也可以针对当前连接设置。
sql复制代码
-- 全局的事务隔离级别设置。(设置完,需要关闭连接,重新打开)
set global transaction_isolation = 'SERIALIZABLE';
-- 当前会话的事务隔离级别设置。
set session transaction_isolation = 'SERIALIZABLE';
十、权限控制DCL操作(了解)
DCL就是Data Control Language,一般就是对于用户的权限做一些授权操作之类的内容。
直接构建用户,基于用户操作对应库表的权限。
10.1 用户的操作
创建用户: create user 用户名@IP地址 identified by 密码;
这里的IP地址,是指定Host列,也就是当前用户可以基于哪个IP地址连接当前MySQL
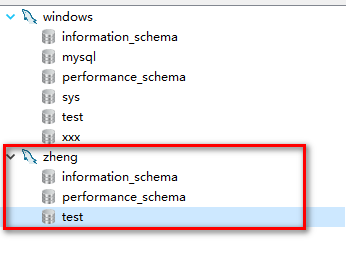
创建一个用户,用户名是zheng,密码是zheng,采用默认的IP,%。
sql复制代码
#创建一个用户,用户名是zheng,密码是zheng。
create user 'zheng' identified by 'zheng';
create user 'zhang'@'%' identified by 'zhang';
# 将之前玩的employee表中薪资大于5000的信息数据封装为一个视图
select * from t_employees where salary > 5000;
# 构建为视图
create view v_emp_salary_gt_fivethousand as (select * from t_employees where salary > 5000);
11.4 视图使用
视图的使用和正常操作表是一样的。
前面构建好的v_emp_salary_gt_fivethousand就可以直接查询
sql复制代码
# 查询视图
select first_name,last_name from v_emp_salary_gt_fivethousand;
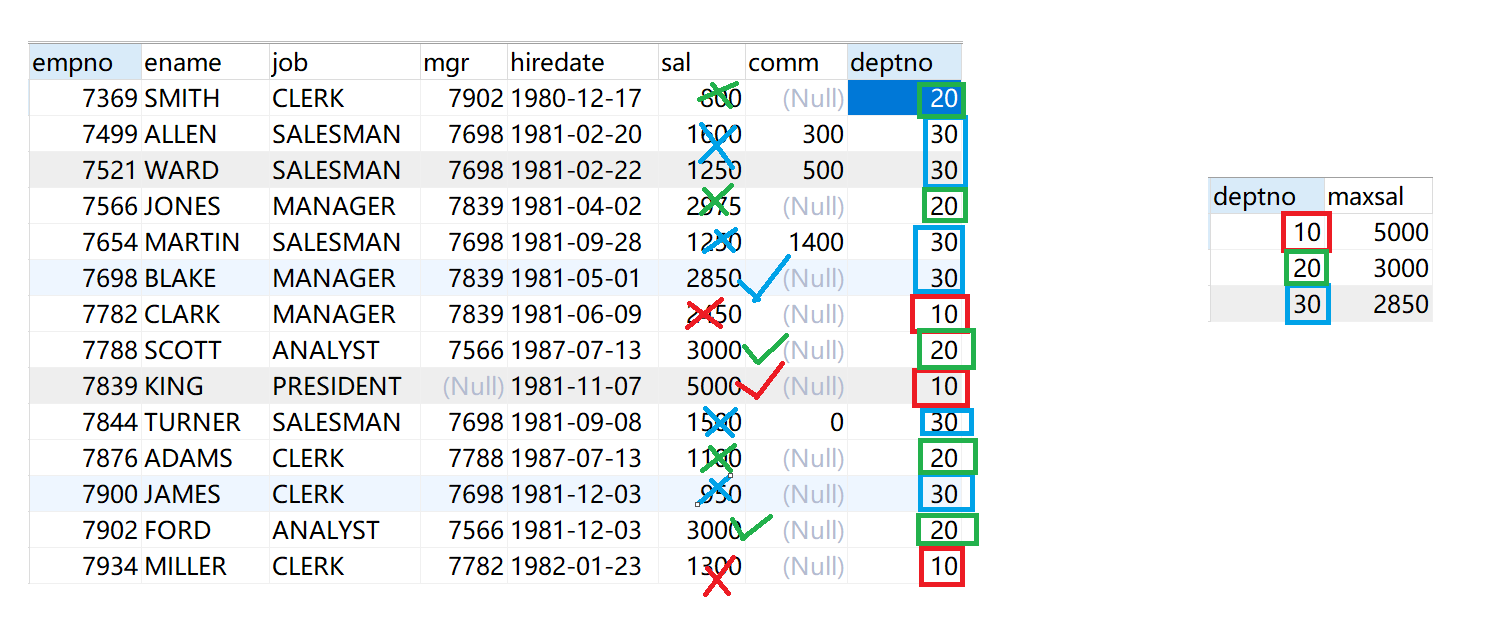
# 首先先完成查询每个部门的最高薪资。 需要利用聚合函数的max,并且对部门编号做一个分组。
select deptno,max(sal) as maxsal from emp group by deptno;
# 将前面查询到的部门最高薪资,和当前的emp表做一个表连接操作,查询出每个部门薪资最高的员工名称
select
e.ename,e.deptno,m.maxsal
from
emp e inner join (select deptno,max(sal) as maxsal from emp group by deptno) m
on e.deptno = m.deptno and e.sal = m.maxsal;
14.2.2 查询哪些员工薪资在部门的平均薪资之上
首先,依然还是在员工表中查询。
需要查询员工名称,员工薪资,部门编号,部门平均薪资
首先需要先将各个部门的平均薪资查询出来,根据聚合函数avg以及对部门编号分组查询。
然后将查询的平均薪资和员工表做一个关联。
sql复制代码
-- 查询哪些员工薪资在部门的平均薪资之上
-- 需要查询员工名称,员工薪资,部门编号,部门平均薪资
# 首先需要先将各个部门的平均薪资查询出来,根据聚合函数avg以及对部门编号分组查询。
select deptno,avg(sal) avgsal from emp group by deptno;
# 将员工表和上述查询部门平均薪资的表关联到一起,条件是部门编号一致 and 员工薪资大于平均薪资
select
e.ename,e.sal,e.deptno,a.avgsal
from
emp e inner join (select deptno,avg(sal) avgsal from emp group by deptno) a
on e.deptno = a.deptno and e.sal > a.avgsal;
14.2.3 查询每个部门的平均薪资等级
首先这里需要查询员工表和薪资等级表。
需要查询部门编号以及部门的平均薪资等级
首先需要查询所有员工的薪资等级是多少。
直接将上述的查询结果作为一个from的虚拟表,直接对部门做分组,针对薪资等级做avg平均值即可
sql复制代码
-- 查询每个部门的平均薪资等级
-- 需要查询部门编号以及部门的平均薪资等级
# 首先需要查询所有员工的薪资等级是多少。
select
e.deptno,s.grade
from
emp e inner join salgrade s
on e.sal between s.losal and hisal
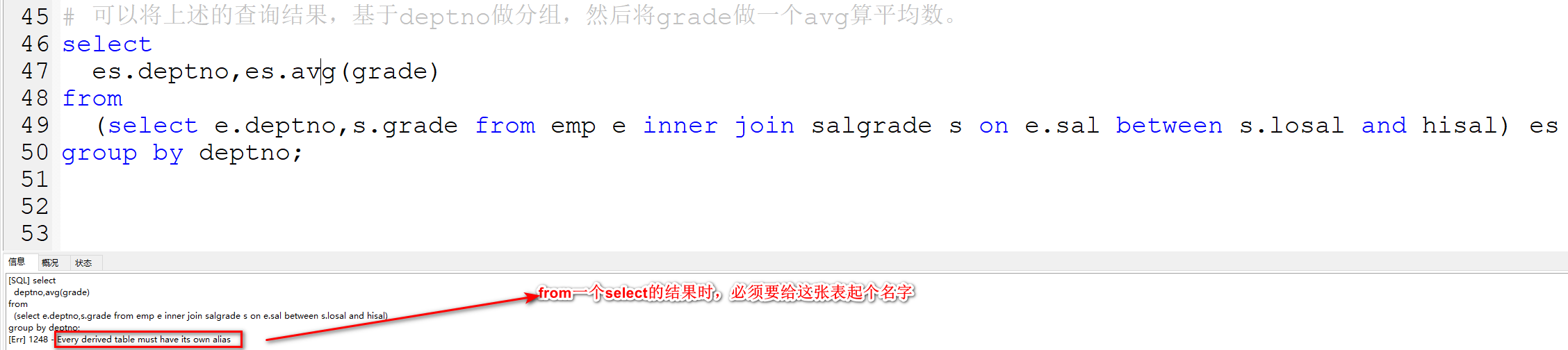
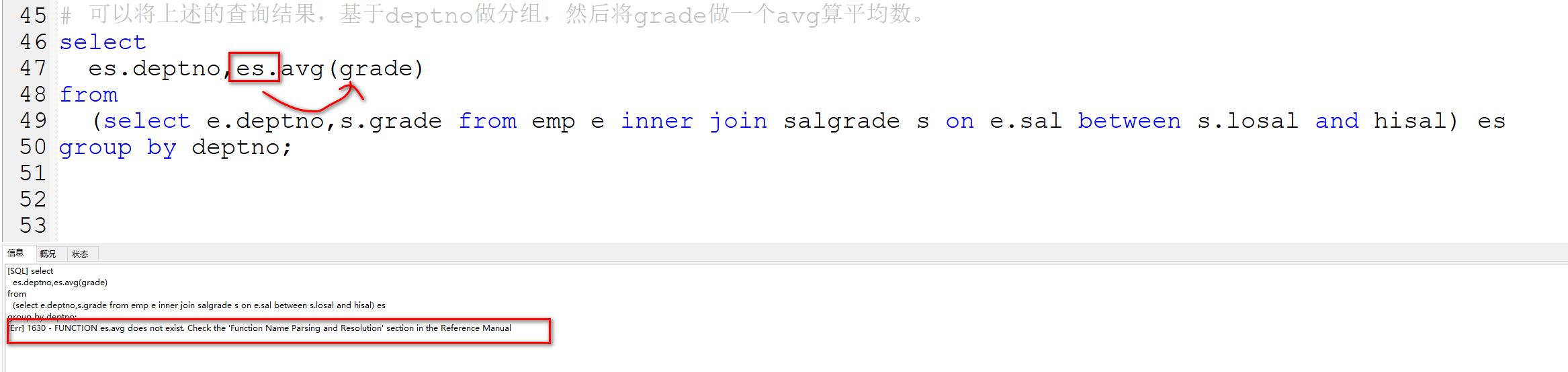
# 可以将上述的查询结果,基于deptno做分组,然后将grade做一个avg算平均数。
select
es.deptno,avg(es.grade)
from
(select e.deptno,s.grade from emp e inner join salgrade s on e.sal between s.losal and hisal) es
group by deptno;
14.2.4 查询平均薪资最高的部门名称
首先需要查询员工表和部门表
需要查询出来部门的名称和平均薪资
首先平均薪资单独的emp表就可以查询出来,再基于排序和limit,就可以只查询出平均薪资最高的部门
然后将上述查询结果的内容,和dept表做表连接,查询出薪资最高的部门信息
sql复制代码
-- 查询平均薪资最高的部门名称
-- 需要查询出来部门的名称和平均薪资
# 首先平均薪资单独的emp表就可以查询出来,再基于排序和limit,就可以只查询出平均薪资最高的部门
select deptno,avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1
# 基于上述查询的结果,和dept表做一个表连接操作
select
d.dname,da.avgsal
from
dept d inner join (select deptno,avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1) da
on d.deptno = da.deptno;
# 上述的limit看着不错,但是存在问题。
# 第一步:查询出平均薪资的最大值。
select avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1;
# 第二步:查询出和平均薪资最大值一致的部门编号。
select deptno,avg(sal) as maxavgsal from emp group by deptno having maxavgsal = (select avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1);
# 第三部:基于部门编号查询出部门的名称。
select
d.dname,avg(sal) as maxavgsal
from emp e inner join dept d on e.deptno = d.deptno
group by d.dname
having maxavgsal = (select avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1);
14.2.5 查询薪水比自己领导还高的员工信息。
首先需要查询emp表,但是需要两张emp一个作为普通员工信息,一个作为领导信息
查询员工名称和员工薪资,领导名称和领导薪资
直接将两张emp表做连接,连接的条件是员工表中的mgr,与领导表中的empno作为条件。
sql复制代码
-- 查询薪水比自己领导还高的员工信息。
-- 查询员工名称和员工薪资,领导名称和领导薪资
# 直接将两张emp表做连接,连接的条件是员工表中的mgr,与领导表中的empno作为条件。
select
e.ename,e.sal,me.ename,me.sal
from
emp e inner join emp me on e.mgr = me.empno
where
e.sal > me.sal;
14.2.6 查询比普通员工的最高薪资还要高的领导名称
首先查询的依然是emp表。
查询出领导的名称和薪资即可。
要先分出来哪些是普通员工,哪些是领导。 领导的empno都在mgr字段上。
分成三步查询。
1、先查询出所有的领导的empno,只需要查询mgr字段即可,做个去重。
2、再基于上面查询出来的领导的empno,筛选出普通员工,查询出普通员工中的最高薪资。
3、再查询领导信息,薪资大于普通员工的最高薪资的领导信息查询出来。
sql复制代码
-- 查询比普通员工的最高薪资还要高的领导名称
-- 1、先查询出所有的领导的empno,只需要查询mgr字段即可,做个去重。
select distinct mgr from emp where mgr is not null;
-- 2、再基于上面查询出来的领导的empno,筛选出普通员工,查询出普通员工中的最高薪资。
select max(sal) as maxsal from emp where empno not in (select distinct mgr from emp where mgr is not null);
-- 3、再查询领导信息,薪资大于普通员工的最高薪资的领导信息查询出来。
select
ename,sal
from
emp
where
empno in (select distinct mgr from emp where mgr is not null)
and sal > (select max(sal) as maxsal from emp where empno not in (select distinct mgr from emp where mgr is not null));
14.2.7 查询每个薪资等级有多少个员工
首先必然需要查询员工表以及薪资等级表的关联操作。
查询出薪资等级和对应的员工个数即可。
分成两步操作:
1、先基于emp和salgrade表查询出每位员工的薪资等级
2、在上述的基础上,再根据grade字段进行分组,查询count即可。
sql复制代码
-- 查询每个薪资等级有多少个员工
# 1、先基于emp和salgrade表查询出每位员工的薪资等级
select
e.ename,s.grade
from
emp e inner join salgrade s on e.sal between s.losal and s.hisal;
# 2、在上述的基础上,再根据grade字段进行分组,查询count即可。
select
s.grade,count(1)
from
emp e inner join salgrade s on e.sal between s.losal and s.hisal
group by s.grade
order by s.grade;
14.2.8 查询出入职时间早于其领导的员工信息和部门信息
首先需要查询emp表两张,同时还要查询出对应的部门信息,还要关联部门表。
需要查询出员工名称,部门名称,领导名称,领导部门
分成两步操作:
1、查询出员工及其领导信息,并且追加上一个判断,员工的入职时间,要早于领导的入职时间
2、再上述的基础上,再额外关联两张部门表,查询出对应的部门名称即可。
sql复制代码
-- 查询出入职时间早于其领导的员工信息
# 需要查询出员工名称,部门名称,领导名称,领导部门
# 1、查询出员工及其领导信息,并且追加上一个判断,员工的入职时间,要早于领导的入职时间
select
e.ename 员工名称,m.ename 领导名称
from
emp e inner join emp m on e.mgr = m.empno
where
e.hiredate < m.hiredate;
# 2、再上述的基础上,再额外关联两张部门表,查询出对应的部门名称即可。
select
e.ename 员工名称,d.dname 员工部门,m.ename 领导名称 ,md.dname 领导部门
from
emp e inner join emp m on e.mgr = m.empno
inner join dept d on e.deptno = d.deptno
inner join dept md on m.deptno = md.deptno
where
e.hiredate < m.hiredate;
14.2.9 查询出至少有5位员工的部门信息
首先需要查询emp和dept表,需要两张表做一个关联。
需要查询部门的编号,部门的名称,部门的员工人数。
分成两步走:
1、关联员工和部门表,查询出部门信息和部门的员工人数。
2、在上述的基础上,筛选出员工人数大于5个的部门信息。
sql复制代码
-- 查询出至少有5位员工的部门信息
# 需要查询部门的编号,部门的名称,部门的员工人数。
# 分成两步走:
# 1、关联员工和部门表,查询出部门信息和部门的员工人数。
select
d.deptno,d.dname,count(1)
from
emp e inner join dept d on e.deptno = d.deptno
group by d.deptno;
# 2、在上述的基础上,筛选出员工人数大于5个的部门信息。
select
d.deptno,d.dname,count(1) as empcount
from
emp e inner join dept d on e.deptno = d.deptno
group by d.deptno
having empcount >= 5
-- 查询出薪资高于公司薪资的平均水平的员工名称,所在部门,上级领导名称,员工名称的薪资水平
# 需要查询员工名称,所在部门,上级领导名称,员工名称的薪资水平
# 分成四步走:
# 1、查询出员工信息和所在部门的信息。
select
e.ename,d.dname
from
emp e inner join dept d on e.deptno = d.deptno;
# 2、在上述的基础上筛选出薪资高于公司平均水平的员工。
select
e.ename,d.dname
from
emp e inner join dept d on e.deptno = d.deptno
where e.sal > (select avg(sal) from emp);
# 3、在上述的基础上再追加查询员工的领导名称。
select
e.ename 员工名称,d.dname 员工部门, m.ename 领导名称
from
emp e inner join dept d on e.deptno = d.deptno
left join emp m on e.mgr = m.empno
where e.sal > (select avg(sal) from emp);
# 4、在上述的基础上,再追加查询员工的薪资水平。
select
e.ename 员工名称,d.dname 员工部门, m.ename 领导名称,s.grade 员工薪资等级
from
emp e inner join dept d on e.deptno = d.deptno
left join emp m on e.mgr = m.empno
inner join salgrade s on e.sal between s.losal and s.hisal
where e.sal > (select avg(sal) from emp);
14.2.11 查询与'SCOTT'从事相同工作的员工名称和部门名称
首先需要查询emp和dept的关联查询,同时需要子查询来找到'SCOTT'的工作作为条件筛选的值
需要查询员工名称和部门名称
分成两步走
1、正常的查询出员工的名称和所在的部门
2、基于'SCOTT'从事的工作筛选出对应的员工信息
sql复制代码
-- 查询与'SCOTT'从事相同工作的员工名称和部门名称
# 需要查询员工名称和部门名称
# 分成两步走
# 1、正常的查询出员工的名称和所在的部门
select
e.ename,d.dname
from
emp e inner join dept d on e.deptno = d.deptno;
# 2、基于'SCOTT'从事的工作筛选出对应的员工信息
select
e.ename,d.dname
from
emp e inner join dept d on e.deptno = d.deptno
where
e.job = (select job from emp where ename = 'SCOTT') and ename != 'SCOTT';
-- 查询部门的平均薪资,以2000作为点,返回'大于2000'或者'小于2000'或者'等于2000'的结果
# 查询部门编号,以及部门的薪资导致是大于,小于,等于2000的结果。
# 分成两步操作
# 1、查询每个部门的平均薪资。
select
d.deptno,
avg(e.sal)
from
emp e inner join dept d on e.deptno = d.deptno
group by d.deptno;
# 2、基于上述查询,将平均薪资的返回结果替换为需求中的大于,小于,等于2000的结果。
select
d.deptno,
avg(e.sal) 平均薪资,
case
when avg(e.sal) = 2000 then '等于2000'
when avg(e.sal) > 2000 then '大于2000'
else '小于2000'
end as 是否大于2000
from
emp e inner join dept d on e.deptno = d.deptno
group by d.deptno;