拉取镜像
shell
docker pull docker.elastic.co/logstash/logstash:8.14.3创建文件夹
json
mkdir /mnt/data/logstash创建默认文件
先不做目录挂载,run出一个容器
json
docker run -d --rm -it docker.elastic.co/logstash/logstash:8.14.3将config和pipeline从容器cp到宿主机
json
docker cp confident_driscoll:/usr/share/logstash/config /mnt/data/logstash/
docker cp confident_driscoll:/usr/share/logstash/pipeline /mnt/data/logstash/停止容器(启动时配置了 --rm ,停止后会自动删除)
json
docker stop confident_driscoll创建容器
shell
docker run --name logstash \
--network es-net \
-p 5044:5044 \
-v /mnt/data/logstash/pipeline/:/usr/share/logstash/pipeline/ \
-v /mnt/data/logstash/config/:/usr/share/logstash/config/ \
--restart=always \
-d docker.elastic.co/logstash/logstash:8.14.3修改配置文件
修改挂载出来的默认 logstash.yml 文件,这里位于 /mnt/data/logstash/config/ 目录,修改后配置如下:
yaml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://es:9200" ]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "123456"注意:这里明文的用户民和密码安全性较差,可改用使用 API 密钥的方式。
修改默认的 logstash.conf 文件,创建日志处理规则,位于 /mnt/data/logstash/pipeline/ 目录,修改后如下:
input {
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["es:9200"]
index => "iov-%{+YYYY.MM.dd}"
document_type => "_doc"
user => "elastic"
password => "123456"
}
}注:上面的各个属性值,根据实际环境进行配置。
修改后重启 logstash 服务。
配置logback
引入相关依赖包,这里使用的 gradle ,maven同理,如下:
// Logback Classic
implementation 'ch.qos.logback:logback-classic:1.2.3' // 使用适合你项目的版本
// Logstash Logback Encoder
implementation 'net.logstash.logback:logstash-logback-encoder:6.6' // 使用适合你项目的版本修改 logback-spring.xml 文件,若不存在则创建。位于 resources 下(这里是springboot项目),内容如下:
<configuration>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.1.110:5044</destination> <!-- Logstash的TCP端口 -->
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="info">
<appender-ref ref="LOGSTASH" />
<!-- 可以添加其他appender,如控制台或文件appender -->
</root>
</configuration>根据实际情况将上面的192.168.1.110:5044部分改成真实 logstash 的IP和端口。
验证功能
确认 ES 和 Logstash 已经正常启动,然后启动 spring boot 服务。进入 Kibana 可以看到已经有日志文件写入到es中。如下:
格式化日志
未处理前日志信息统一在message字段中,不方便我们管理。
这里主要针对设备的上传的原始数据进行格式化。
比如iov中的日志格式如下:
java
// 正常的设备上报信息,用imei区分
logger.warn("IMEI: {},DATA: {}", imei, ByteBufUtil.hexDump(rawMessage));
// 打印的错误日志
logger.error("测试报错日志");
// 系统报错
throw new DecoderException();修改logstash.conf
为了更方便管理日志,将 logstash.conf 修改如下:
input {
tcp {
port => 5044
codec => json_lines
}
}
filter {
# 使用grok过滤器来从message字段中提取imei和data
grok {
match => { "message" => "IMEI: %{WORD:imei},DATA: %{GREEDYDATA:data}" }
# 注意:如果imei可能包含特殊字符(如空格、冒号等),您可能需要调整WORD为正则表达式模式
# 例如:(?<imei>[^,]+) 来匹配从IMEI:到逗号之前的所有内容
tag_on_failure => ["_grok_failed"] # 当grok失败时添加此标签
}
# 检查grok是否成功以及level字段的值
if "_grok_failed" in [tags] and [level] == "WARN" {
# 如果grok失败且level为WARN,则丢弃事件(可以通过drop过滤器或在输出阶段排除)
drop {}
} else if [level] in ["ERROR", "FATAL", "SEVERE"] and "_grok_failed" in [tags] {
# 如果level是ERROR及以上,但grok失败或没有imei和data,则设置imei为"error",data为message
mutate {
add_field => { "imei" => "error" }
add_field => { "data" => "%{message}" }
remove_field => ["tags"]
}
}
# ruby {
# code => "
# require 'time'
# event.set('datetime', event.get('@timestamp').time.localtime().strftime('%Y-%m-%d %H:%M:%S'))
# "
# }
# 使用mutate过滤器来移除不需要的字段
mutate {
remove_field => ["level_value", "@version", "message"]
}
}
output {
elasticsearch {
hosts => ["es:9200"]
index => "iov-%{+YYYY.MM.dd}"
document_type => "_doc"
user => "elastic"
password => "123456"
}
}具体更改内容,看上面的注解。
更改后重启logstash服务。
添加es动态模板
根据上面的 logstash.conf 配置文件,动态生成的索引。数据结构除了 @timestamp 字段为date类型,其他的都将默认声明为 text 类型,即都将分词。如下:
json
"iov-2024.07.30": {
"aliases": {},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"data": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"imei": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"level": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"logger_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"thread_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "iov-2024.07.30",
"creation_date": "1722317697099",
"number_of_replicas": "1",
"uuid": "5OoDo8eITpqdhBMKPMBaeg",
"version": {
"created": "8505000"
}
}
}
}
}这会导致浪费大量的空间和性能,比如我们的imei、logger_name、thread_name和level字段,完全没有必要进行分词,精准查找即可,所以现在我们需要在logstash上传日志到es时,精准的建立字段的类型。这里采用es动态索引模板的方式。
使用 Kibana 开发者工具执行如下指令,创建索引模板:
json
PUT /_index_template/iov_template
{
"index_patterns": ["iov-*"],
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"data": {
"type": "text" ,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"imei": {
"type": "keyword"
},
"level": {
"type": "keyword"
},
"logger_name": {
"type": "keyword"
},
"thread_name": {
"type": "keyword"
}
}
}
}
}这个模板将自动应用于任何以iov-开头的新索引。当让适用于以iov-开头,后跟日期(如iov-2024.07.30)的索引名称。如果字段名称可以和模板对应上,那么字段类型将跟模板一致。
创建模板后,再次测试日志插入,查看类型,发现模板已经生效:
json
{
"iov-2024.07.30": {
"aliases": {},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"data": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"imei": {
"type": "keyword"
},
"level": {
"type": "keyword"
},
"logger_name": {
"type": "keyword"
},
"thread_name": {
"type": "keyword"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "iov-2024.07.30",
"creation_date": "1722320800301",
"number_of_replicas": "1",
"uuid": "pGrsRAN4Rg6HsP2mmhrGpA",
"version": {
"created": "8505000"
}
}
}
}
}好了,现在日志数据已经有了需要的字段,并且正确的设置了字段类型。
设置索引声明周期
创建ILM配置文件:
shell
PUT _ilm/policy/log_retention_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "2d", // 这里设置为2天,但实际上在单机模式下,你可能需要外部脚本来控制滚动
"max_size": "30gb" // 你可以设置一个足够大的大小限制,以避免基于大小的滚动
}
}
},
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}这个策略将包含两个阶段:hot 和 delete。hot 阶段将不执行任何特殊操作(除了可能的滚动),而 delete 阶段将在索引达到7天时删除它。
注意 :在单机模式下,rollover 操作可能不会自动按 max_age 触发,因为Elasticsearch的ILM滚动通常依赖于索引的大小或索引中事件的时间戳(如果配置了max_docs_per_partition)。在这种情况下,你可能需要依赖外部脚本来控制索引的滚动。
修改索引模板
修改索引模板,使用上面定义的ILM策略。修改后如下:
shell
PUT /_index_template/iov_template
{
"index_patterns": ["iov-*"],
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"data": {
"type": "text" ,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"imei": {
"type": "keyword"
},
"level": {
"type": "keyword"
},
"logger_name": {
"type": "keyword"
},
"thread_name": {
"type": "keyword"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "log_retention_policy",
"index.lifecycle.rollover_alias": "iov_logs"
}
}
}在索引模板中,指定了之前定义的ILM策略,并设置一个别名用于索引滚动。
查看日志数据
使用Kibana开发者工具
在 Kibana 开发者工具中执行如下语句可以查看到对应日志记录:
json
GET /iov-2024.07.30/_search查询结果如下:
json
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "iov-2024.07.30",
"_id": "Lo9RApEBFb2jjdrpyxet",
"_score": 1,
"_ignored": [
"data.keyword"
],
"_source": {
"data": """io.netty.handler.codec.DecoderException
at com.thgcgps.iovservice.network.codec.MsgFrameDecode.decode(MsgFrameDecode.java:109)
at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:493)
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:432)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:271)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:377)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:363)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:355)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:377)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:363)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:163)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:714)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.base/java.lang.Thread.run(Thread.java:829)
""",
"thread_name": "nioEventLoopGroup-5-1",
"@timestamp": "2024-07-30T06:26:38.415Z",
"level": "ERROR",
"logger_name": "com.thgcgps.iovservice.network.server.TcpServerHandler",
"imei": "error"
}
},
{
"_index": "iov-2024.07.30",
"_id": "L49RApEBFb2jjdrpyxet",
"_score": 1,
"_source": {
"data": "测试报错日志",
"thread_name": "nioEventLoopGroup-5-1",
"@timestamp": "2024-07-30T06:26:38.413Z",
"level": "ERROR",
"logger_name": "com.thgcgps.iovservice.network.codec.MsgFrameDecode",
"imei": "error"
}
},
{
"_index": "iov-2024.07.30",
"_id": "LY9RApEBFb2jjdrpyxet",
"_score": 1,
"_source": {
"data": "78780a1344050400020035c60e0d0a",
"thread_name": "nioEventLoopGroup-5-1",
"@timestamp": "2024-07-30T06:26:38.412Z",
"level": "WARN",
"logger_name": "com.thgcgps.iovservice.network.codec.MsgFrameDecode",
"imei": "0868755128633153"
}
}
]
}
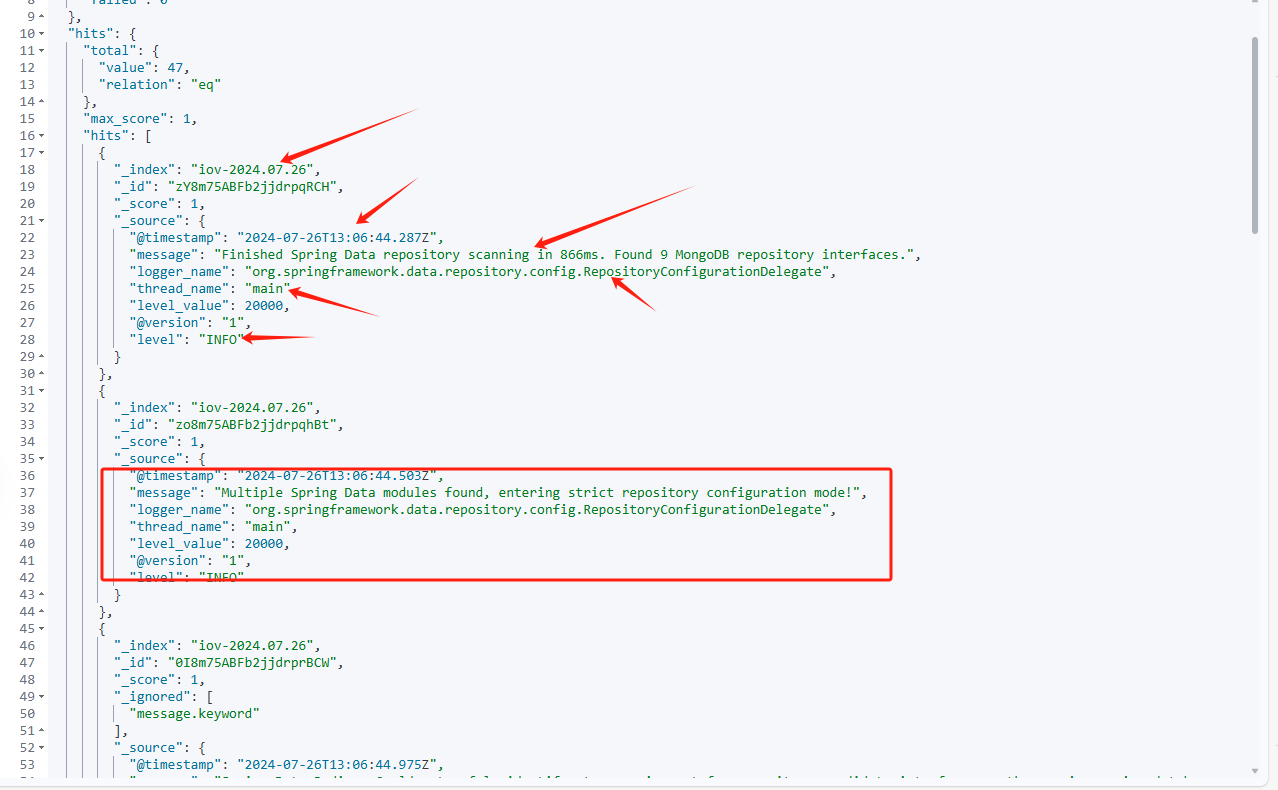
}可以看到,这里的数据即我们代码中测试的相关日志,即系统报错,打印的error日志和最关注的设备上报日志。但这里的结果并不方便观察和整理。并且时间格式也不理想,时区也并不是北京时间。
使用Kibana的Discover功能
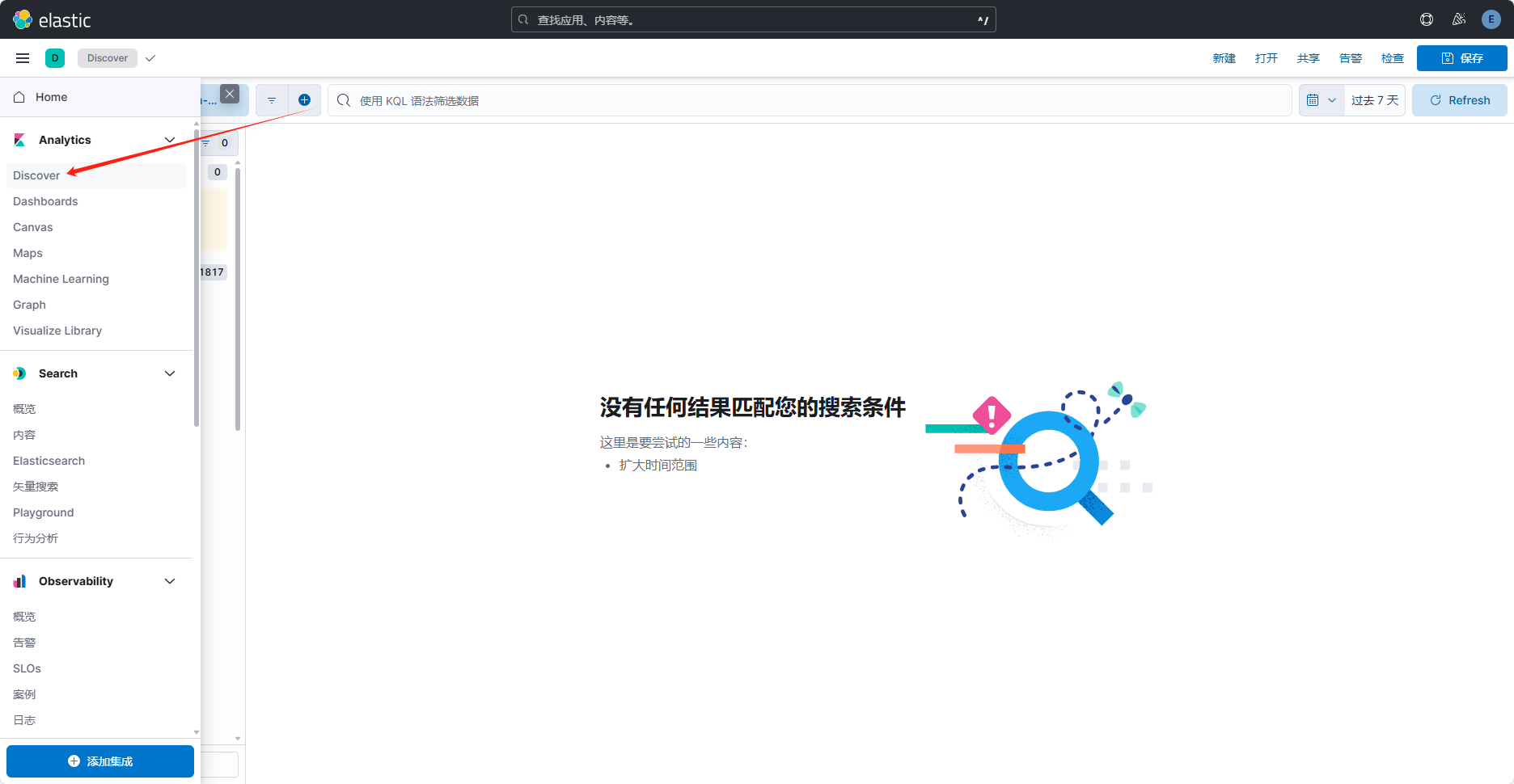
进入 Kibana 管理界面,点击 Discover ,如图:
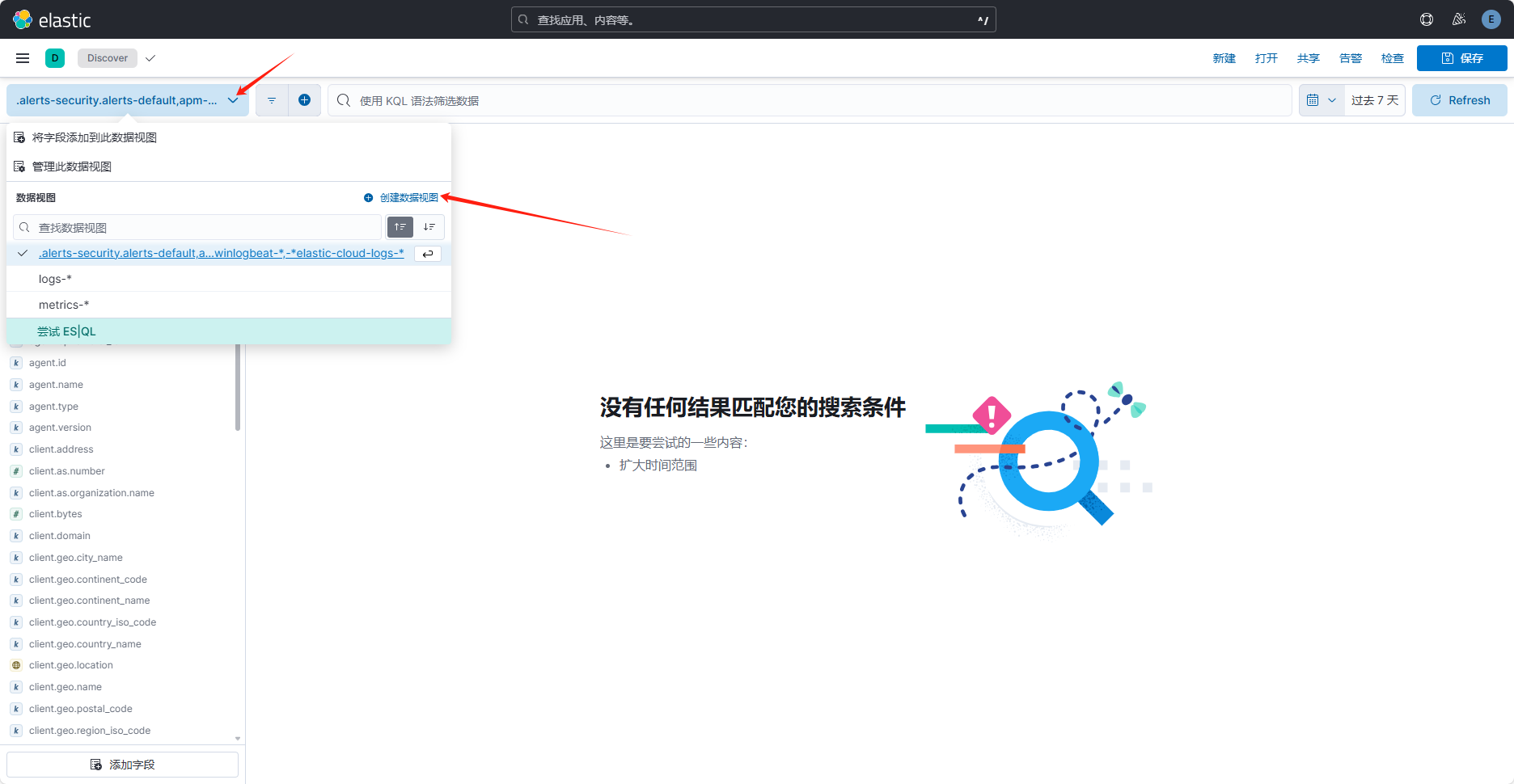
进入后创建一个数据视图:
创建时,输入名称,和索引模式即可:
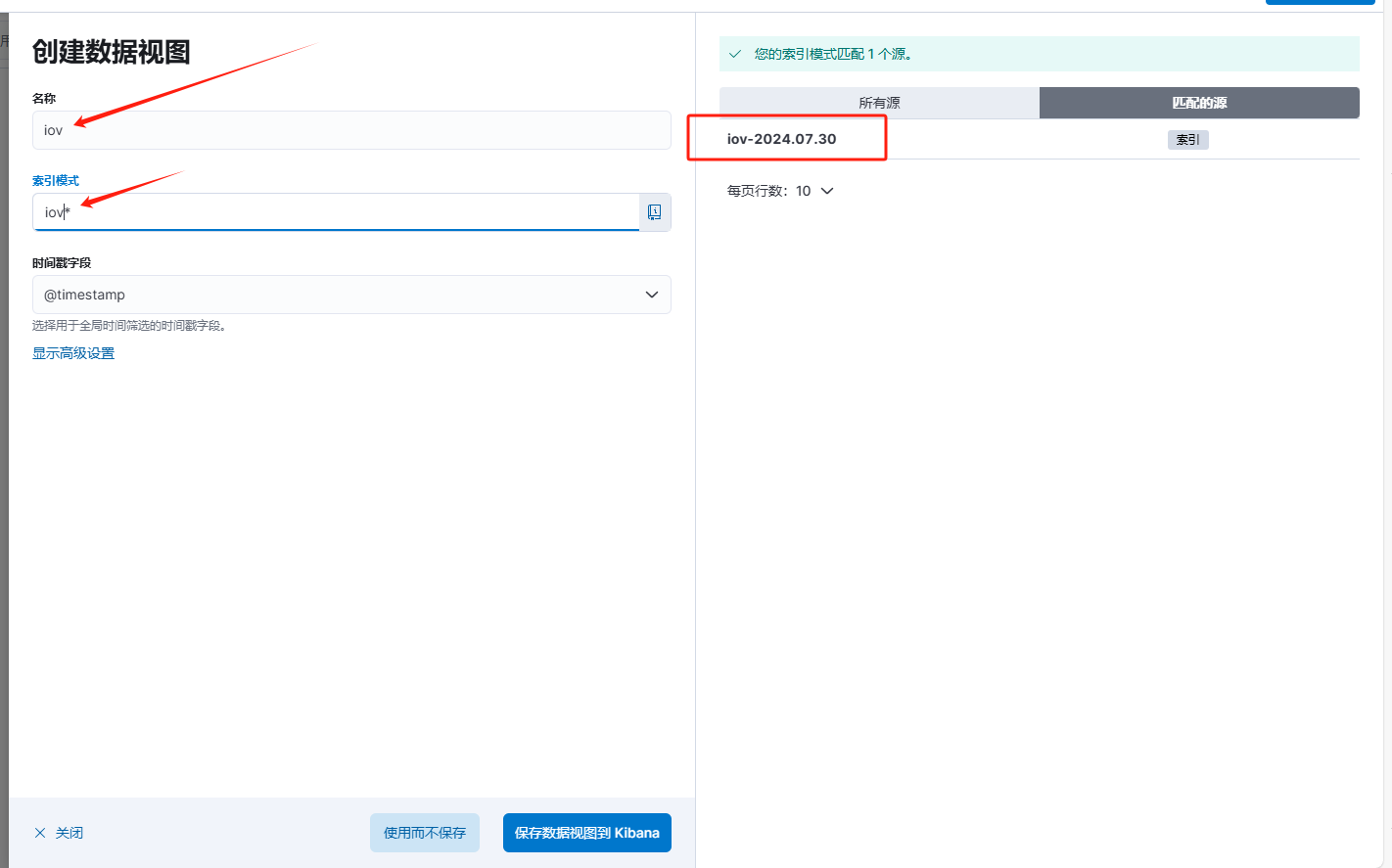
这里的索引模式需要和匹配的源对应,支持通配符,上图即使用 * 通配符创建。填写好后,点击使用而不保存(即临时的数据视图,刷新页面或跳转页面后就销毁了)或者 点击保存数据视图到Kibana(下次进入可以直接选择无需重建)。这里因为日志日期会有变动,创建了一个临时的。
创建好的数据视图如下:
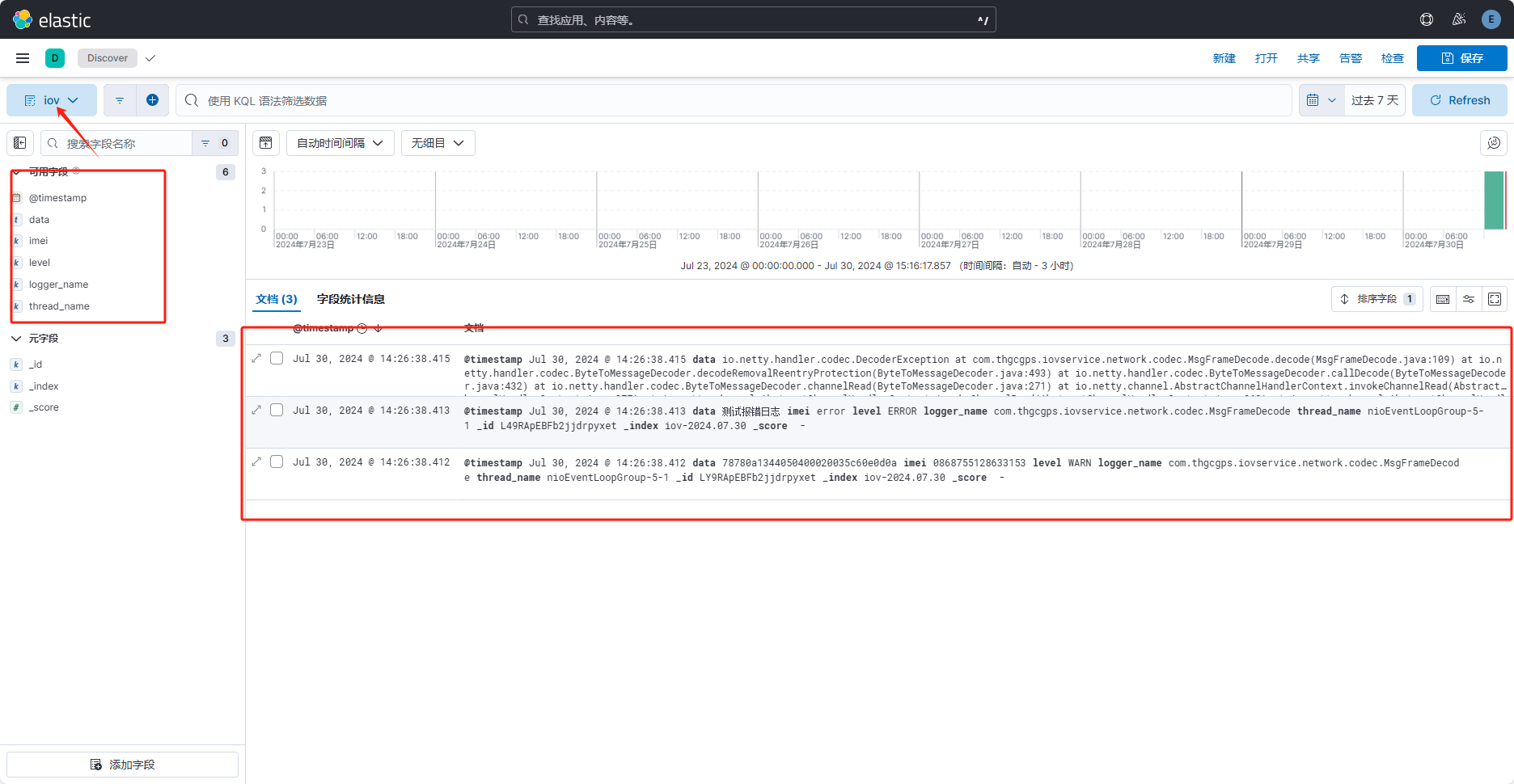
点击"可用字段"后的"+"号,即可查看指定字段。如图:
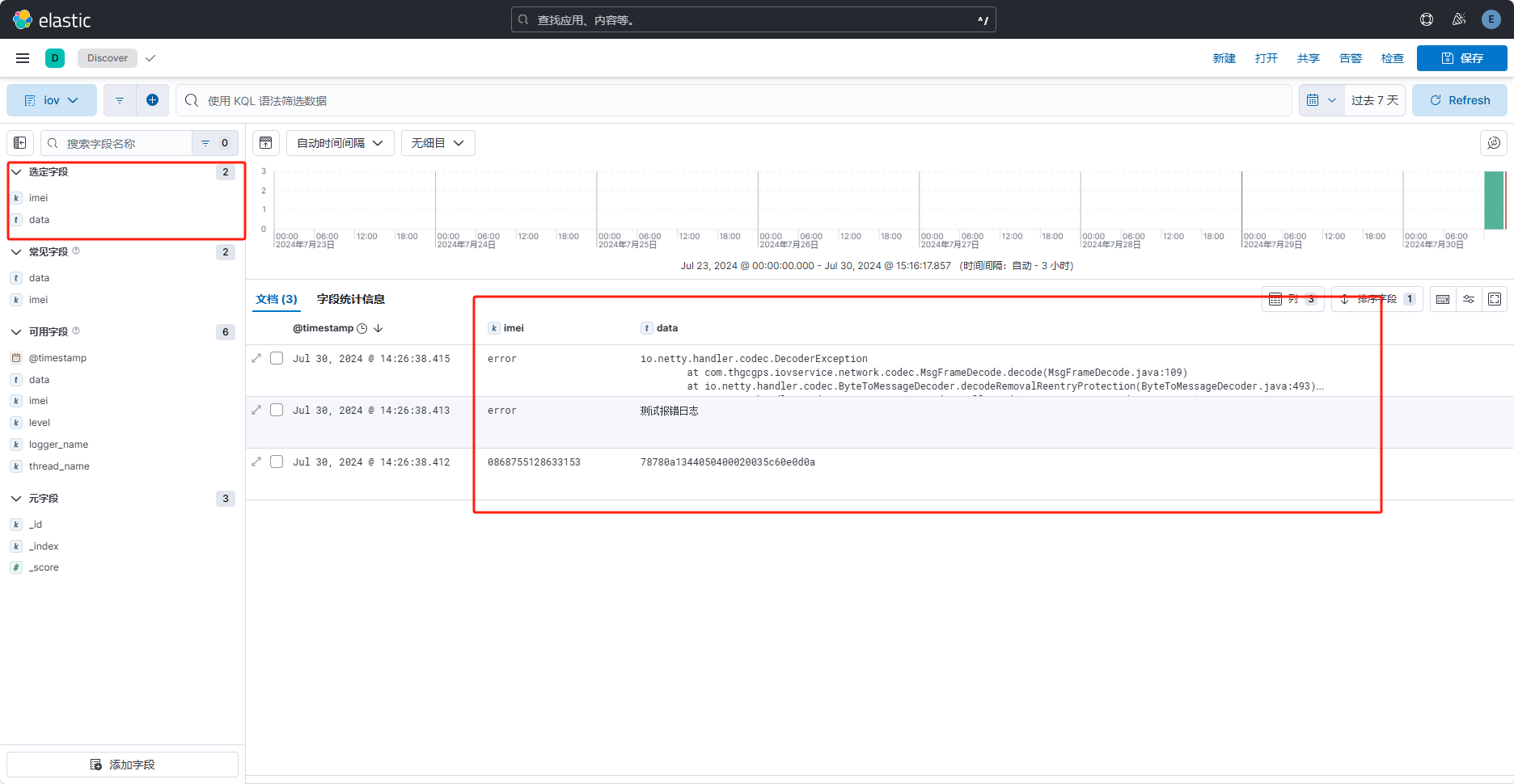
"选中字段"即当前产看的字段。
若想搜索指定的值,可在搜索框中使用KQL语法搜索数据(光标点击搜素框后即有提示),如图:
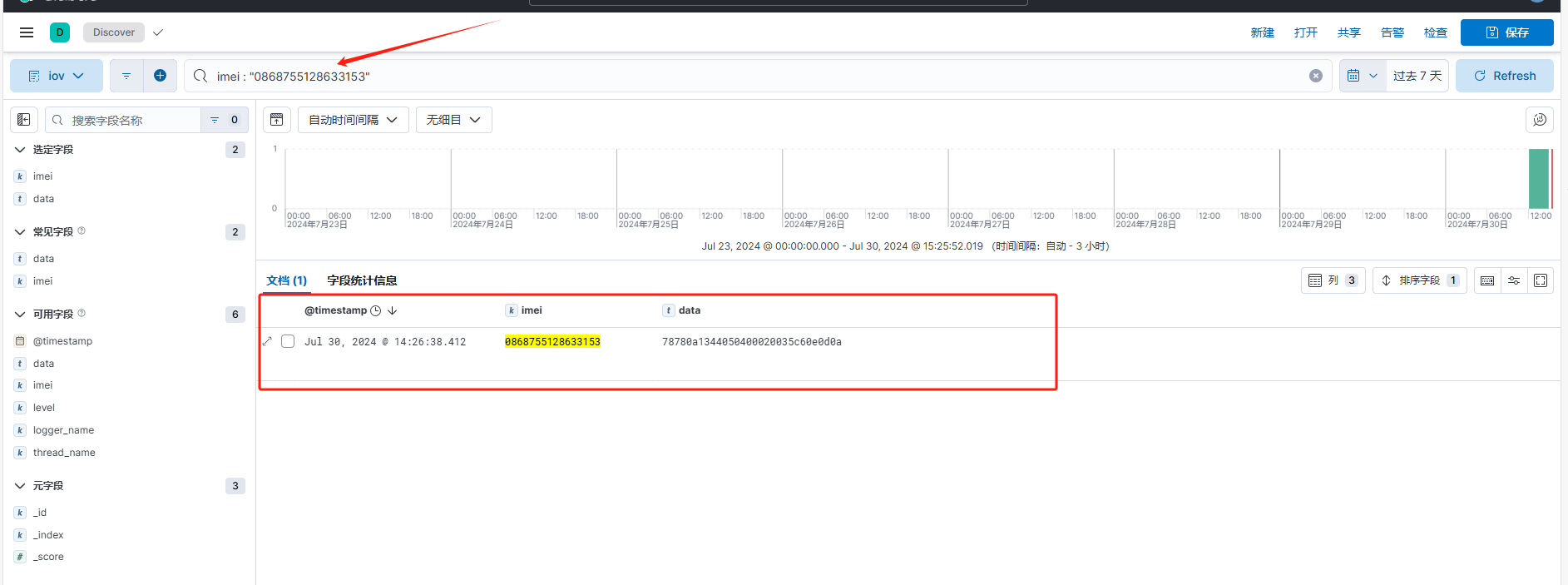
因为imei字段之前设置了字段类型,控制其不分词,所以当使用imei字段时,要精确搜索。而这里的data字段支持全文搜索,如下:
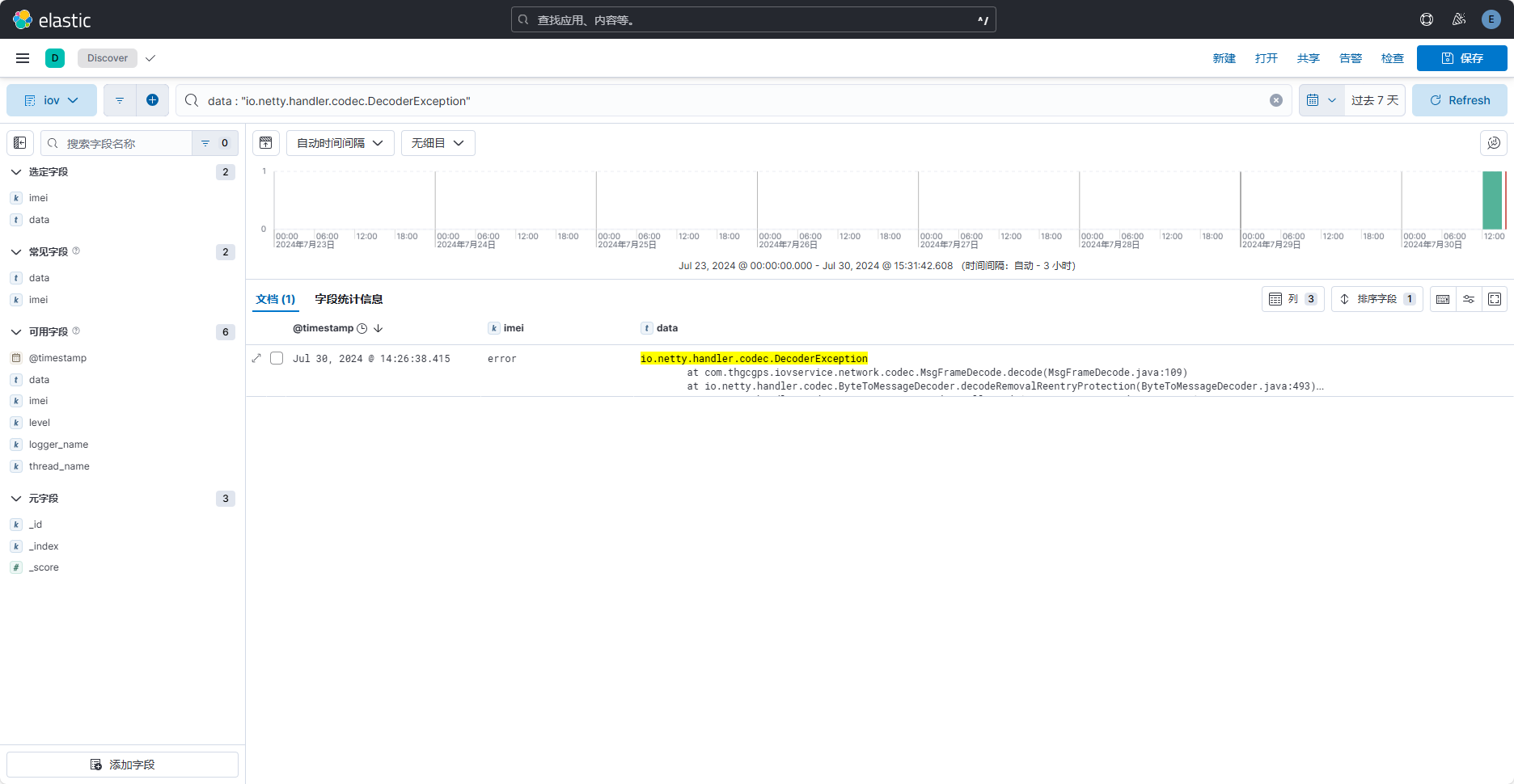
注意:这里因为设置模板时,没有指定分词器,所以当前时默认的 standard 分词器。分词效果并不好由于数据上报的日志由数字和字母组成,也不是很适合分词。可以考虑data也不进行分词。或者更改一下数据上报的日志,比如区分出心跳和定位等信息,然后即可根据特定类型进行查找。
上面的 @timestamp 字段,日期时间虽然是对的,但并不符合我们常见的表达方式,这里可以设置其格式以达到预期效果,点击该字段,选择"编辑数据视图字段",如下:
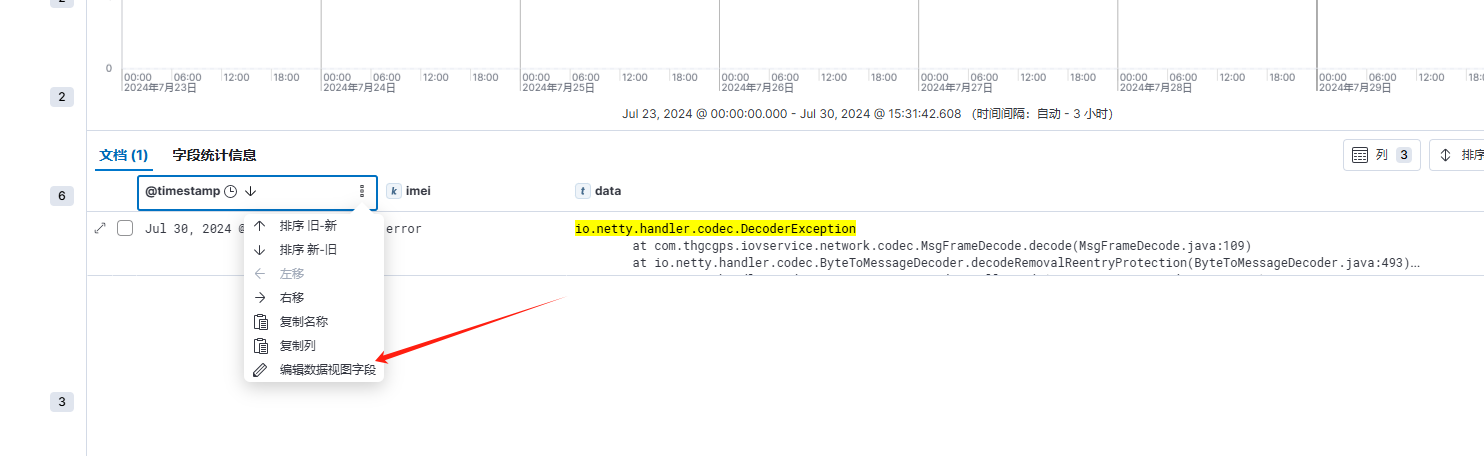
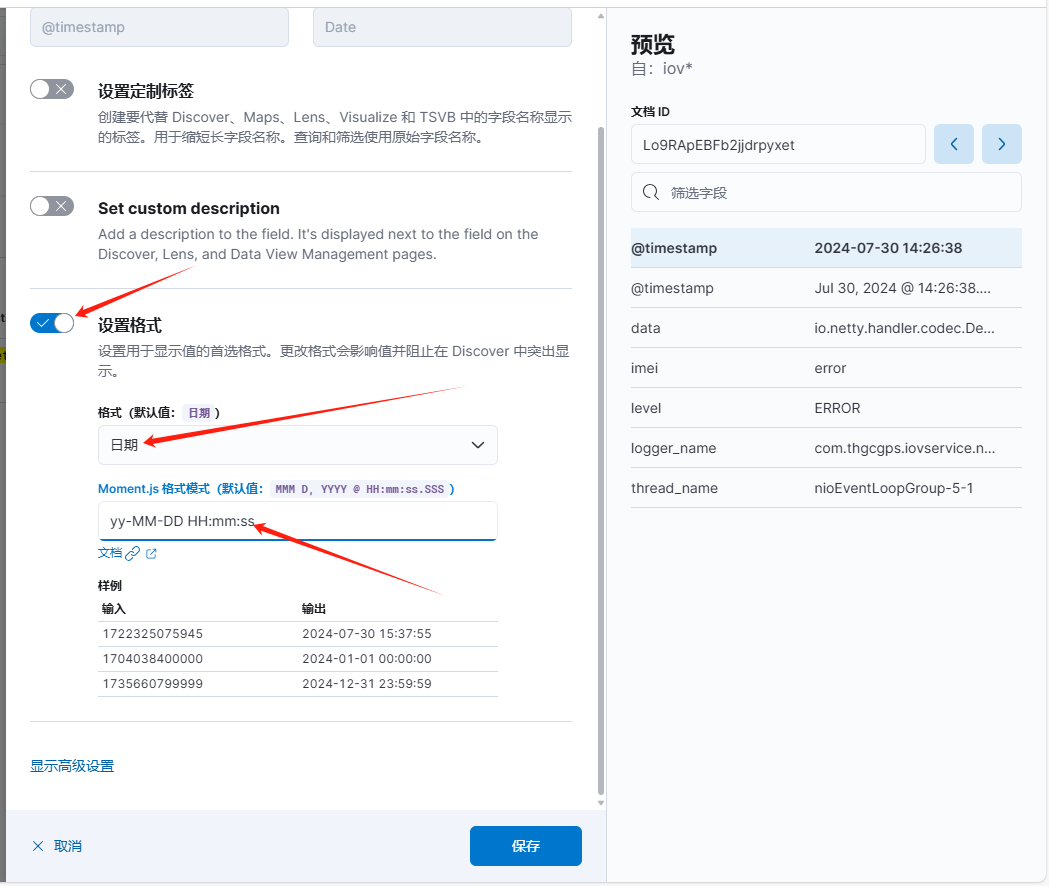
打开"设置格式"选项,格式选择"日期",然后根据指定规则,输入如下格式 "yy-MM-DD HH:mm:ss",然后点击保存,如下:
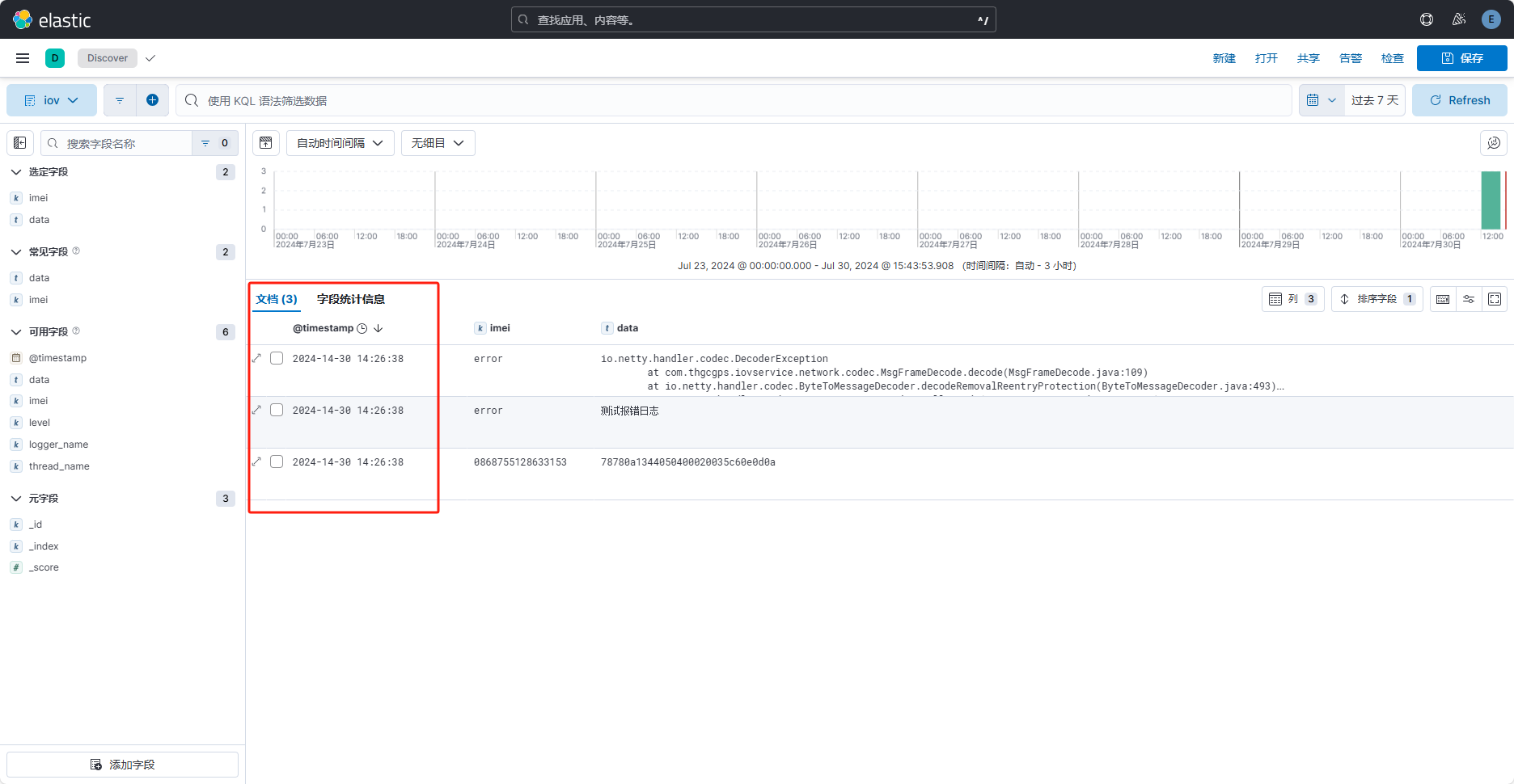
保存后时间展示如下:
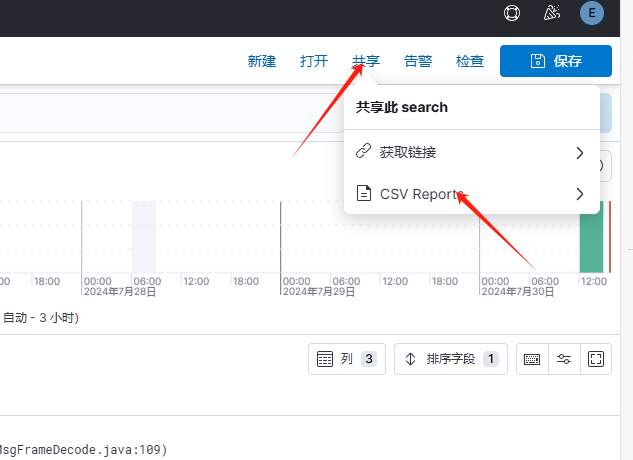
若需要导出,可点击"共享",然后选择"CSV Reports"
然后点击 "Generate CSV"即可,然后右下角会弹出一个快速访问Reports的连接,点击即可跳转到下载页面
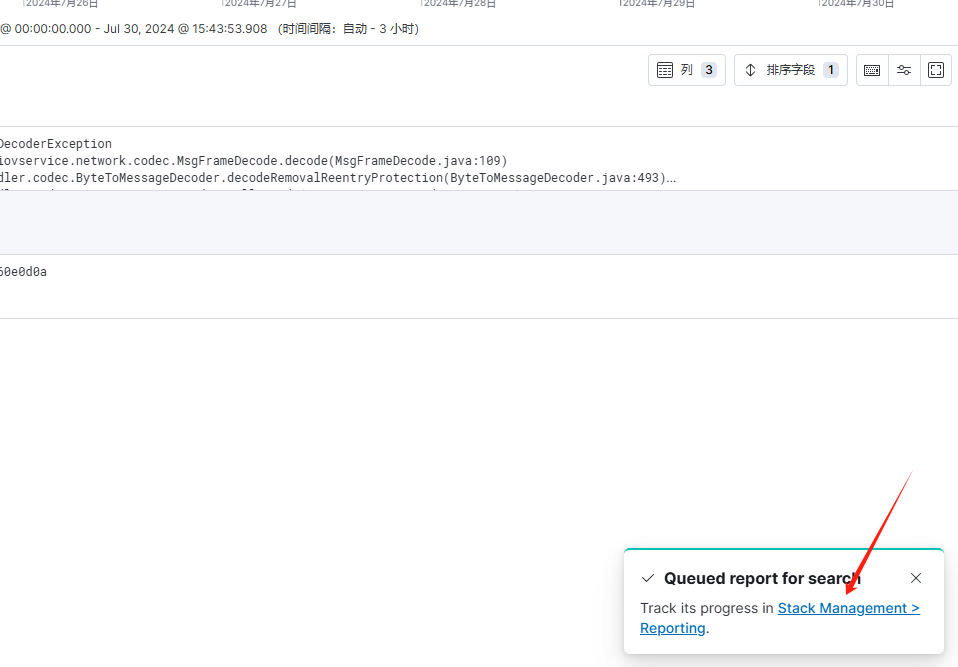
也可以点击"Management"中的"Stack Management"功能如下
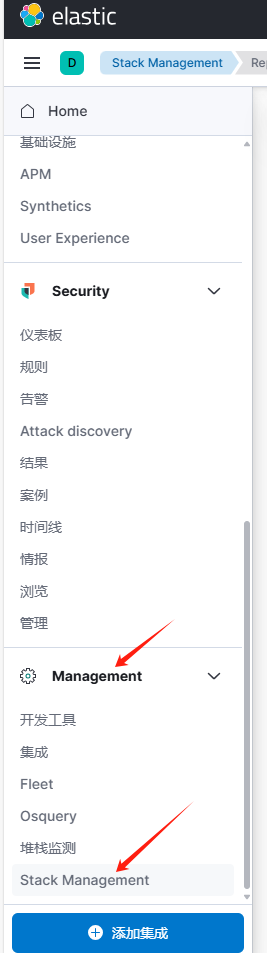
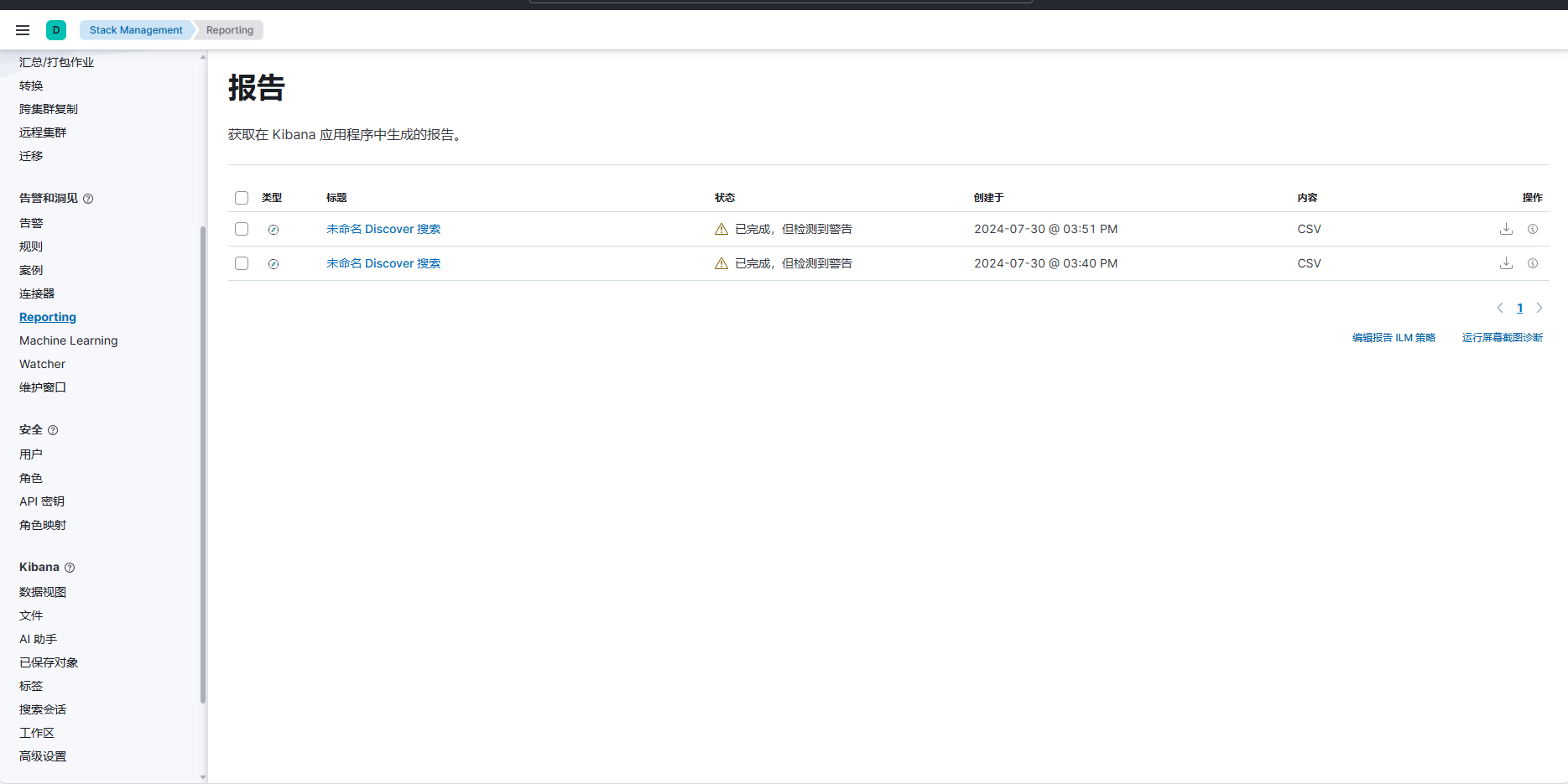
然后点击"Reporting"即可看到可下载的CSV文件。
**