CCR 概述
CCR(Cross Cluster Replication)也就是跨集群数据复制,能够在库/表级别将源集群的数据变更同步到目标集群,可用于提升在线服务的数据可用性、隔离在离线负载、建设两地三中心等。
CCR 通常被用于容灾备份、读写分离、集团与公司间数据传输和隔离升级等场景。
容灾备份:通常是将企业的数据备份到另一个集群与机房中,当突发事件导致业务中断或丢失时,可以从备份中恢复数据或快速进行主备切换。一般在对 SLA 要求比较高的场景中,都需要进行容灾备份,比如在金融、医疗、电子商务等领域中比较常见。
读写分离:读写分离是将数据的查询操作和写入操作进行分离,目的是降低读写操作的相互影响并提升资源的利用率。比如在数据库写入压力过大或在高并发场景中,采用读写分离可以将读/写操作分散到多个地域的只读/只写的数据库案例上,减少读写间的互相影响,有效保证数据库的性能及稳定性。
集团与分公司间数据传输:集团总部为了对集团内数据进行统一管控和分析,通常需要分布在各地域的分公司及时将数据传输同步到集团总部,避免因为数据不一致而引起的管理混乱和决策错误,有利于提高集团的管理效率和决策质量。
隔离升级:当在对系统集群升级时,有可能因为某些原因需要进行版本回滚,传统的升级模式往往会因为元数据不兼容的原因无法回滚。而使用 CCR 可以解决该问题,先构建一个备用的集群进行升级并双跑验证,用户可以依次升级各个集群,同时 CCR 也不依赖特定版本,使版本的回滚变得可行。
原理
名词解释
源集群 (srcCluster) :业务写入数据的集群 目标集群 (destCluster) :跨集群复制的目标集群 binlog :源集群变更日志,记录了源集群的数据修改和操作,是目标集群数据重放和恢复的凭据 Syncer:一个轻量的CCR任务控制节点,可以单节点部署,也可以多节点高可用部署
架构说明
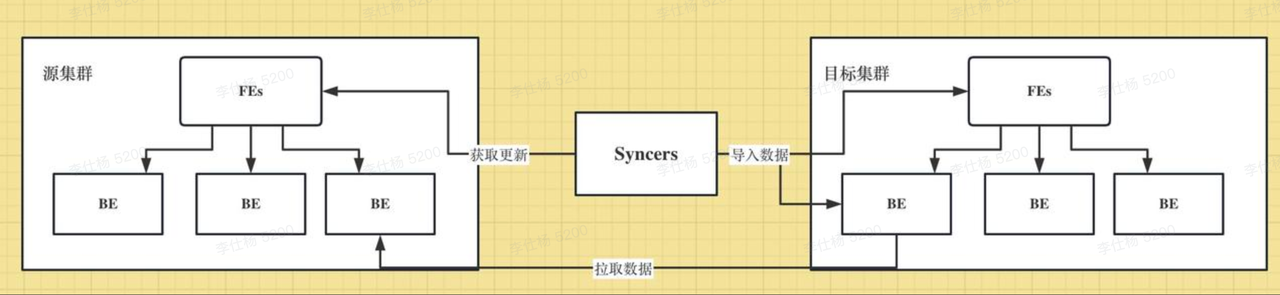
Syncer从源集群批量获取库/表的binlog,并根据binlog中的信息在目标集群重放,从而实现数据的全量/增量复制。
如果binlog是数据变更,则通知目标集群从源集群拉取数据。
如果binlog是元数据变更,则在目标集群发起对应的操作。
注:需要Doris 2.0 以上版本
使用说明
- 在fe.conf、be.conf中打开binlog feature配置项
Plain
enable_feature_binlog = true- 部署源、目标doris集群
- 部署Syncer
Plain
git clone https://github.com/selectdb/ccr-syncer
cd ccr-syncer
# -j 开启多线程编译# --output指定输出的路径名称,默认名称为output
bash build.sh <-j NUM_OF_THREAD> <--output SYNCER_OUTPUT_DIR>cd SYNCER_OUTPUT_DIR
# 启动syncer,加上--daemon使syncer在后台运行
bash bin/start_syncer.sh --daemon
# 停止syncer
bash bin/stop_syncer.sh更多启动选项参考启动配置,停止Syncer请见停止说明
- 打开源集群中被同步库/表的binlog
Plain
-- enable database binlog
ALTER DATABASE db_name SET properties ("binlog.enable" = "true");
-- enable table binlog
ALTER TABLE table_name SET ("binlog.enable" = "true");如果是库同步,则需要打开库中所有表的binlog.enable,这个过程可以通过脚本快速完成,脚本的使用方法见脚本说明文档
- 向Syncer发起同步任务
Plain
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "demo",
"table": "example_tbl"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "ccrt",
"table": "copy"
}}' http://127.0.0.1:9190/create_ccr- name: CCR同步任务的名称,唯一即可
- host、port:对应集群master的host和mysql(jdbc) 的端口
- thrift_port:对应FE的rpc_port
- user、password:syncer以何种身份去开启事务、拉取数据等
- database、table:
- 如果是db级别的同步,则填入dbName,tableName为空
- 如果是表级别同步,则需要填入dbName、tableName
其他操作详见操作列表
Syncer操作列表
请求的通用模板
Plain
curl -X POST -H "Content-Type: application/json" -d {json_body} http://ccr_syncer_host:ccr_syncer_port/operatorjson_body: 以json的格式发送操作所需信息
operator:对应Syncer的不同操作
operators
- get_lag 查看同步进度
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/get_lag其中job_name是create_ccr时创建的name
- pause 暂停同步任务
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/pause- resume 恢复同步任务
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/resume- delete 删除同步任务
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/delete- list_jobs 列出所有job名称
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{}' http://ccr_syncer_host:ccr_syncer_port/list_jobs- job_detail 展示job的详细信息
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/job_detail- job_progress 展示job的详细进度信息
Plain
curl -X POST -L --post303 -H "Content-Type: application/json" -d '{ "name": "job_name"}' http://ccr_syncer_host:ccr_syncer_port/job_progress- metrics 获取golang以及ccr job的metrics信息
Plain
curl -L --post303 http://ccr_syncer_host:ccr_syncer_port/metrics 启动说明
根据配置选项启动Syncer,并且在默认或指定路径下保存一个pid文件,pid文件的命名方式为host_port.pid。
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
Plain
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成后文中的start_syncer.sh指的是该路径下的start_syncer.sh!!!
启动选项
--daemon
后台运行Syncer,默认为false
Plain
bash bin/start_syncer.sh --daemon--db_type
Syncer目前能够使用两种数据库来保存自身的元数据,分别为sqlite3(对应本地存储)和mysql 或者postgresql(本地或远端存储)
Plain
bash bin/start_syncer.sh --db_type mysql默认值为sqlite3 在使用mysql或者postgresql存储元数据时,Syncer会使用CREATE IF NOT EXISTS来创建一个名为ccr的库,ccr相关的元数据表都会保存在其中
--db_dir
这个选项仅在db使用 **sqlite3**时生效 可以通过此选项来指定sqlite3生成的db文件名及路径。
Plain
bash bin/start_syncer.sh --db_dir /path/to/ccr.db默认路径为SYNCER_OUTPUT_DIR/db,文件名为ccr.db
--db_host & db_port & db_user & db_password
这个选项仅在db使用 **mysql或者 postgresql**时生效
Plain
bash bin/start_syncer.sh --db_host 127.0.0.1 --db_port 3306 --db_user root --db_password "qwe123456"db_host、db_port的默认值如例子中所示,db_user、db_password默认值为空
--log_dir
日志的输出路径
Plain
bash bin/start_syncer.sh --log_dir /path/to/ccr_syncer.log默认路径为SYNCER_OUTPUT_DIR/log,文件名为ccr_syncer.log
--log_level
用于指定Syncer日志的输出等级。
Plain
bash bin/start_syncer.sh --log_level info
time level msg hooks
[2023-07-18 16:30:18] TRACE This is trace type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] DEBUG This is debug type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] INFO This is info type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] WARN This is warn type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] ERROR This is error type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] FATAL This is fatal type. ccrName=xxx line=xxx在--daemon下,log_level默认值为info 在前台运行时,log_level默认值为trace,同时日志会通过 tee 来保存到log_dir
--host && --port
用于指定Syncer的host和port,其中host只起到在集群中的区分自身的作用,可以理解为Syncer的name,集群中Syncer的名称为host:port
Plain
bash bin/start_syncer.sh --host 127.0.0.1 --port 9190host默认值为127.0.0.1,port的默认值为9190
--pid_dir
用于指定pid文件的保存路径
pid文件是stop_syncer.sh脚本用于关闭Syncer的凭据,里面保存了对应Syncer的进程号,为了方便Syncer的集群化管理,可以指定pid文件的保存路径
Plain
bash bin/start_syncer.sh --pid_dir /path/to/pids默认值为SYNCER_OUTPUT_DIR/bin
--commit_txn_timeout
用于指定提交事务超时时间
Plain
bash bin/start_syncer.sh --commit_txn_timeout 33s默认值为33s
--connect_timeout duration
用于指定连接超时时间
Plain
bash bin/start_syncer.sh --connect_timeout 10s默认值为1s
--local_repo_name string
用于指定本地仓库名称
Plain
bash bin/start_syncer.sh --local_repo_name "repo_name"默认值为""
--rpc_timeout duration
用于指定rpc超时时间
Plain
bash bin/start_syncer.sh --rpc_timeout 30s默认值为3s
停止说明
根据默认或指定路径下pid文件中的进程号关闭对应Syncer,pid文件的命名方式为host_port.pid。
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
Plain
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成后文中的stop_syncer.sh指的是该路径下的stop_syncer.sh!!!
停止选项
有三种关闭方法:
- 关闭目录下单个Syncer 指定要关闭Syncer的host && port,注意要与start_syncer时指定的host一致
- 批量关闭目录下指定Syncer 指定要关闭的pid文件名,以空格分隔,用
" "包裹 - 关闭目录下所有Syncer 默认即可
--pid_dir
指定pid文件所在目录,上述三种关闭方法都依赖于pid文件的所在目录执行
Plain
bash bin/stop_syncer.sh --pid_dir /path/to/pids例子中的执行效果就是关闭/path/to/pids下所有pid文件对应的Syncers(方法3 ),--pid_dir可与上面三种关闭方法组合使用。
默认值为SYNCER_OUTPUT_DIR/bin
--host && --port
关闭pid_dir路径下host:port对应的Syncer
Plain
bash bin/stop_syncer.sh --host 127.0.0.1 --port 9190host的默认值为127.0.0.1,port默认值为空 即,单独指定host时方法1 不生效,会退化为方法3 。 host与port都不为空时方法1才能生效
--files
关闭pid_dir路径下指定pid文件名对应的Syncer
Plain
bash bin/stop_syncer.sh --files "127.0.0.1_9190.pid 127.0.0.1_9191.pid"文件之间用空格分隔,整体需要用" "包裹住
开启库中所有表的binlog
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
Plain
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成后文中的enable_db_binlog.sh指的是该路径下的enable_db_binlog.sh!!!
使用说明
Plain
bash bin/enable_db_binlog.sh -h host -p port -u user -P password -d db