一.redis
穿透无中生有key,布隆过滤nul隔离
锁与非期解难题。缓存击穿过期key,
雪崩大量过期key,过期时间要随机。
面试必考三兄弟,可用限流来保底。
1.1 Redis的使用场景
根据自己简历上的业务进行回答
·缓存穿透、击穿、雪崩、双写一致、持久化、数据过期、淘汰策略
分布式锁 setnx、redisson
总结
1.2 什么是缓存穿透,怎么解决
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
解决方案一:缓存空数据解决方案二:布隆过滤器

1.3.什么是缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
解决方案一:互斥锁,强一致,性能差
解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致

1.4.什么是缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案一:给不同的Key的TTL添加随机值
解决方案二:利用Redis集群提高服务的可用性
解决方案三:给缓存业务添加降级限流策略
解决方案四:给业务添加多级缓存

1.5 数据库和redis双写一致性如何保证?redis做为缓存,mysql的数据如何与redis进行同步呢?
介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以,我们当时采用的是异步的方案同步的数据
我们当时是把抢券的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致,我们当时采用的是redisson提供的读写锁来保证数据的同步
那你来介绍一下异步的方案(你来介绍-下redisson读写锁的这种方案)
---允许延时一致的业务,采用异步通知
a.使用MQ中间中间件,更新数据之后,通知缓存删除
b.利用canal中间件,不需要修改业务代码,伪装为mysql的一个从节点,canal通过读取binlog数据更新缓存
---强一致性的,采用Redisson提供的读写锁
a.共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
b.排他锁:也叫独占锁writeLock,加锁之后,阻塞其他线程读写操作

1.6 redis持久化
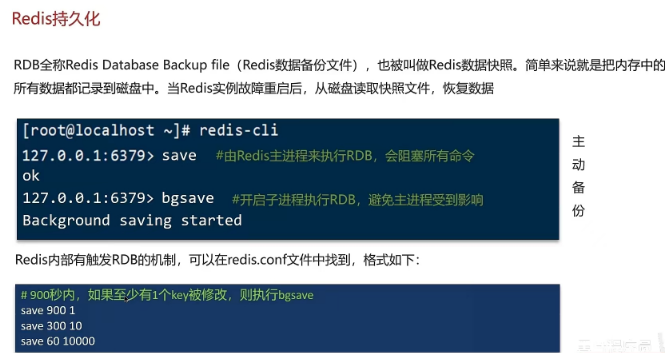
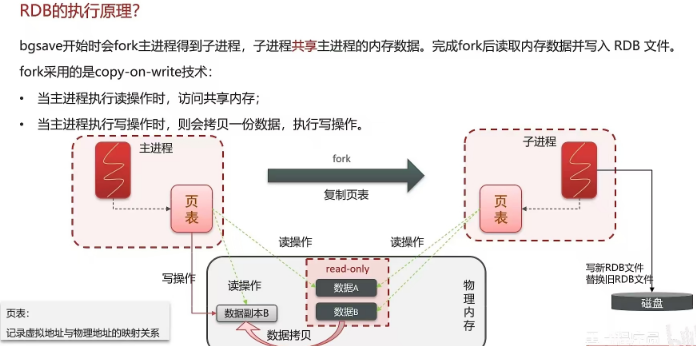

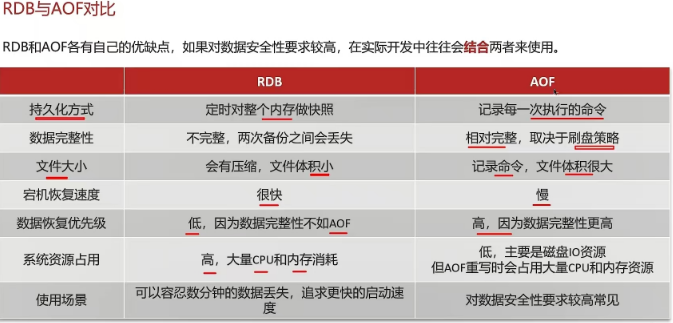
1.7 Redis的数据过期策略
惰性删除:访问key的时候判断是否过期,如果过期,则删除
定期删除:定期检查一定量的key是否过期(SLOW模式+FAST模式)
Redis的过期删除策略:惰性删除+定期删除两种策略进行配合使用

1.8redis的淘汰策略有哪些?



数据淘汰策略
Redis提供了8种不同的数据淘汰策略,默认是noeviction不删除任何数据,内1.存不足直接报错
LRU:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰2.
优先级越高。
3.LFU:最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
平时开发过程中用的比较多的就是alkeys-lru(结合自己的业务场景)

1.8 redis分布式锁,是如何实现的?
先按照自己简历上的业务进行描述分布式锁使用的场景
我们当使用的redisson实现的分布式锁,底层是setnx和lua脚本(保证原子性)
Redisson实现分布式锁如何合理的控制锁的有效时长?
在redisson的分布式锁中,提供了一个WatchDog(看门狗),一个线程获取锁成功以后WatchDog会给持有锁的线程续期(默认是每隔10秒续期一次)
Redisson的这个锁,可以重入吗?
可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用的hash结构来存储线程信息和重入的次数
Redisson锁能解决主从数据一致的问题吗
不能解决,但是可以使用redisson提供的红锁来解决,但是这样的话,性能就太低了,如果业务中非要保证数据的强一致性,建议采用zookeeper实现的分布式锁

1.9 redis的主从同步
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离-般都是一主多从,主节点负责写数据,从节点负责读数据
能说一下,主从同步数据的流程
全量同步:
1.从节点请求主节点同步数据(replication id、offset )
2.主节点判断是否是第一次请求,是第一次就与从节点同步版本信息(replication id 和offset)
3.主节点执行bgsave ,生成rdb文件后,发送给从节点去执行
4.在rdb生成执行期间,主节点会以命令的方式记录到缓冲区(一个日志文件)
5.把生成之后的命令日志文件发送给从节点进行同步
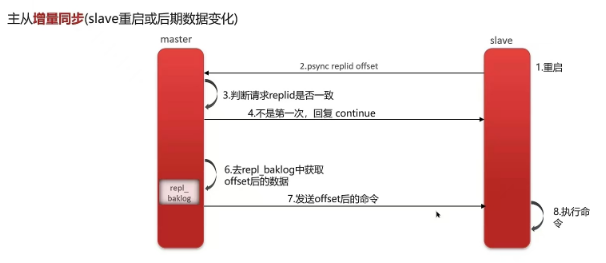
增量同步:
1.从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
2.主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步


1.10 怎么保证Redis的高并发高可用(redis哨兵集群)
哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
你们使用redis是单点还是集群,哪种集群
主从(1主1从)+哨兵就可以了。单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点
redis集群脑裂,该怎么解决呢?
集群脑裂是由于主节点和从节点和sentine!处于不同的网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将老的主节点降为从节点,这时再从新master同步数据,就会导致数据丢失
解决:我们可以修改redis的配置,可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求就可以避免大量的数据丢失
1.11 redis的分片集群有什么作用
a.集群中有多个master,每个master保存不同数据
b.每个master都可以有多个slave节点
c.master之间通过ping监测彼此健康状态1
d.客户端请求可以访问集群任意节点,最终都会被转发到正确节点
Redis分片集群中数据是怎么存储和读取的?
Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽
将16384个插槽分配到不同的实例
读写数据:根据key的有效部分计算哈希值,对16384取余(有效部分,如果key前面有太括号,大括号的内容就是有效部分,如果没有,则以key本身做为有效部分)余数做为插槽,寻找插槽所在的实例

1.12 能解释-下redis中的 I/O多路复用模型?
1.I/0多路复用
是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/0多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
- Redis网络模型
就是使用I/0多路复用结合事件的处理器来应对多个Socket请求
> 连接应答处理器
>命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件上
>命令请求处理器,在Redis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时 候,依然是单线程
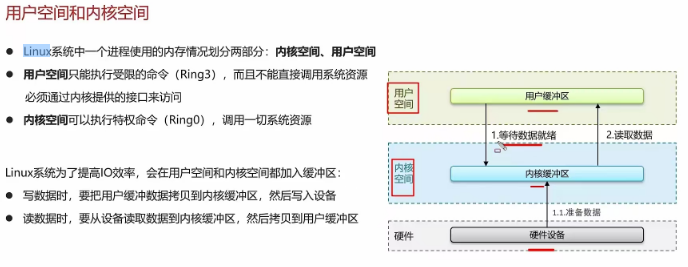

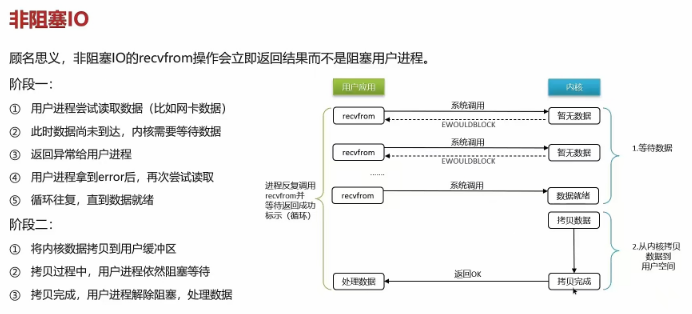
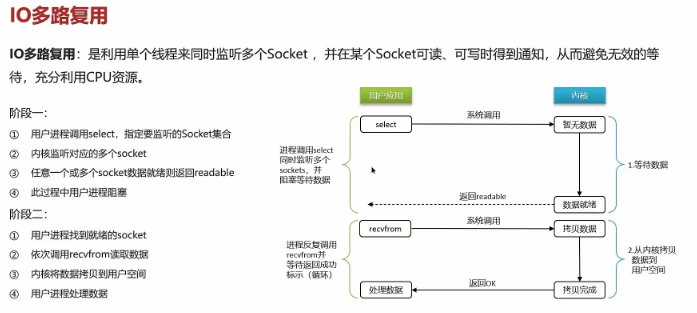
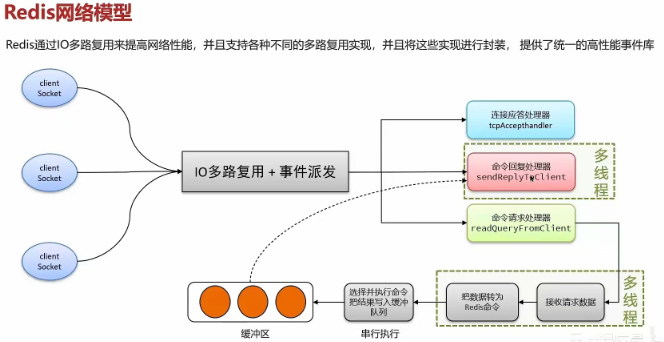

二 mysql
2.1 如何定位慢查询?
1:介绍一下当时产生问题的场景(我们当时的一个接口测试的时候非常的慢,压测的结果大概5秒钟)
2.我们系统中当时采用了运维工具(Skywalking),可以监测出哪个接口,最终因为是sql的问题
3.在mysql中开启了慢日志查询,我们设置的值就是2秒,一旦sql执行超过2秒就会记录到日志中(调试阶段)

2.2 SQL语句执行很慢,如何分析呢?
可以采用MySQL自带的分析工具 EXPLAIN
通过key和key len检查是否命中了索引(索引本身存在是否有失效的情况)
通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
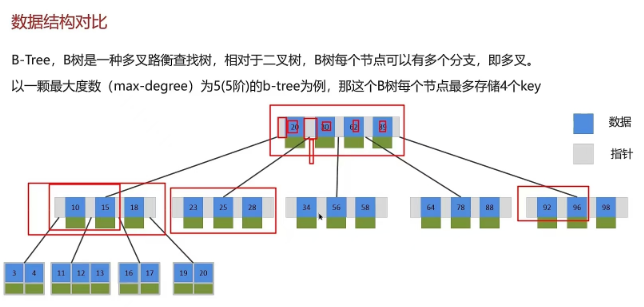
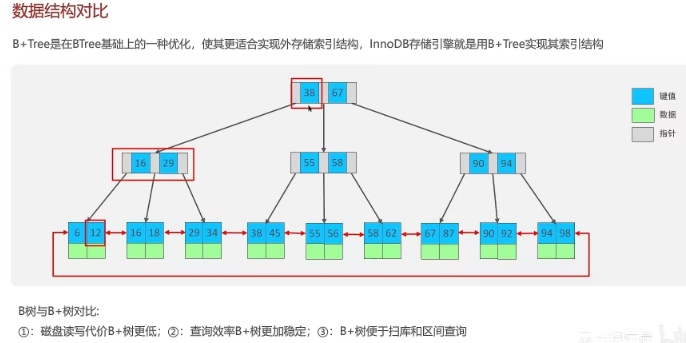
2.3 了解过索引吗?(什么是索引)
索引(index)是帮助MySQL高效获取数据的数据结构(有序)
提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引的底层数据结构了解过嘛?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
阶数更多,路径更短
磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
B+树便于扫库和区间查询,叶子节点是一个双向链表



2.4知道什么叫覆盖索引嘛 ?
覆盖索引是指查询使用了索引,返回的列,必须在索引中全部能够找到
使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select*
MYSQL超大分页怎么处理?
问题:在数据量比较大时,limit分页查询,需要对数据进行排序,效率低
解决方案:覆盖索引+子查询
2.5 索引创建原则有哪些?
1).针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
2).针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3).尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
4).如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5).尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6).要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7).如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。

2.6什么情况下索引会失效?
① 违反最左前缀法则
② 范围查询右边的列,不能使用索引
③ 不要在索引列上进行运算操作, 索引将失效
④ 字符串不加单引号,造成索引失效。(类型转换)
⑤ 以%开头的Like模糊查询,索引失效

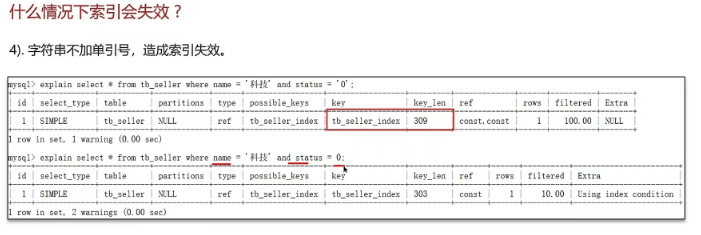

2.7谈谈你对sql的优化的经验
·---表的设计优化(参考阿里开发手册《嵩山版》)
① 比如设置合适的数值(tinyint int bigint),要根据实际情况选择
② 比如设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
---SQL语句优化
① SELECT语句务必指明字段名称(避免直接使用select*)
② SQL语句要避免造成索引失效的写法
③ 尽量用union all代替union union会多一次过滤,效率低
④避免在where子句中对字段进行表达式操作
G)Join优化 能用innerioin 就不用left join right join,如必须使用 一定要以小表为驱动内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。leftjoin 或 right join,不会重新调整顺序

2.8 事务的特性是什么?
原子性( Atomicity)
-致性( Consistency )
隔离性( lsolation )
●持久性( Durability
ACID,分别指的是:原子性、一致性、隔离性、持久性;我举个例子A向B转账500,转账成功,A扣除500元,B增加500元,原子操作体现在要么都成功,要么都失败
在转账的过程中,数据要一致,A扣除了500,B必须增加500
在转账的过程中,隔离性体现在A像B转账,不能受其他事务干扰
在转账的过程中,持久性体现在事务提交后,要把数据持久化(可以说是落盘操作)
2.9并发事务带来哪些问题?怎么解决这些问题呢?MySQL的默认隔离级别是?
并发事务的问题:.
① 脏读:一个事务读到另外一个事务还没有提交的数据。
② 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同
③ 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了"幻影"。
隔离级别:
①READ UNCOMMITTED 未提交读脏读、 不可重复读、幻读
② READ COMMITTED 读已提交 不可重复读、幻读
③ REPEATABLE READ 可重复读 幻读
④ SERIALIZABLE 串行化

2.10 undo log和redo log的区别
redo log:记录的是数据页的物理变化,服务宕机可用来同步数据
undo log :记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据.
redo log 保证了事务的持久性,undolog 保证了事务的原子性和一致性
++++其中redolog日志记录的是数据页的物理变化,服务机可用来同步数据,而undolog不同,它主要记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据,比如我们删除一条数据的时候,就会在undolog日志文件中新增一条delete语句,如果发生回滚就执行逆操作;++++
++++redolog保证了事务的持久性,undolog保证了事务的原子性和一致性++++
2.11 事务中的隔离性是如何保证的呢?(你解释一下MVCC)

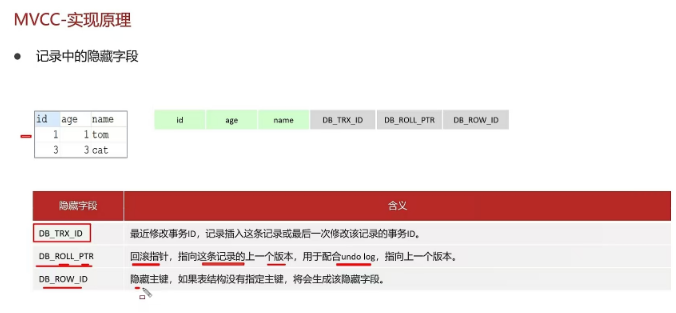

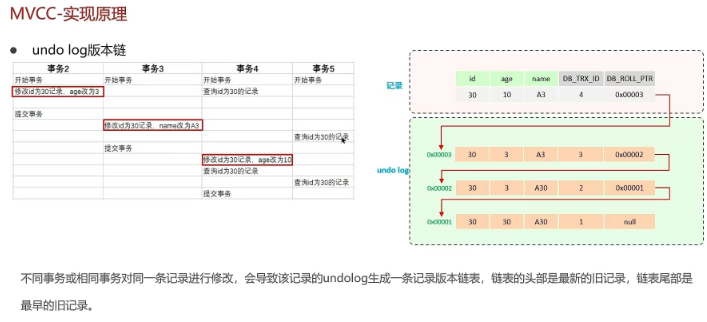
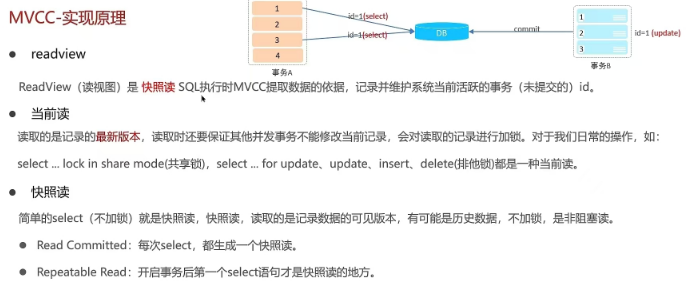
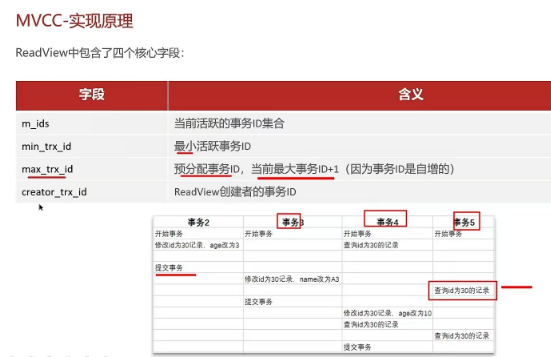

2.12 mysql 主从同步原理

MVSQL主从复制的核心就是二进制日志binog(DDL(数据定义语言)语句和 DML(数据操纵语言)语句)① ① 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
② 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log。
③ 从库重做中继日志中的事件,将改变反映它自己的数据

2.13分库分表

分库之后的问题:
1.分布式事务一致性问题.
2.跨节点关联查询.
3.跨节点分页、排序函数
4.主键避重
应该使用 分库分表中间件:
sharding-sphere
mycat