RAG中解析PDF的方法
一 pdf格式都有哪些
1.机器生成的pdf文件,包含图像,文本,可以被编辑
2.传统扫描文档,表现为图像,不能被编辑
3.带OCR的扫描文档。可能转OCR的过程中带入了错误。
二 pdf解析全科指南
全面指南---------用python提取PDF中各类文本内容的方法 https://www.luxiangdong.com/2023/10/05/extract/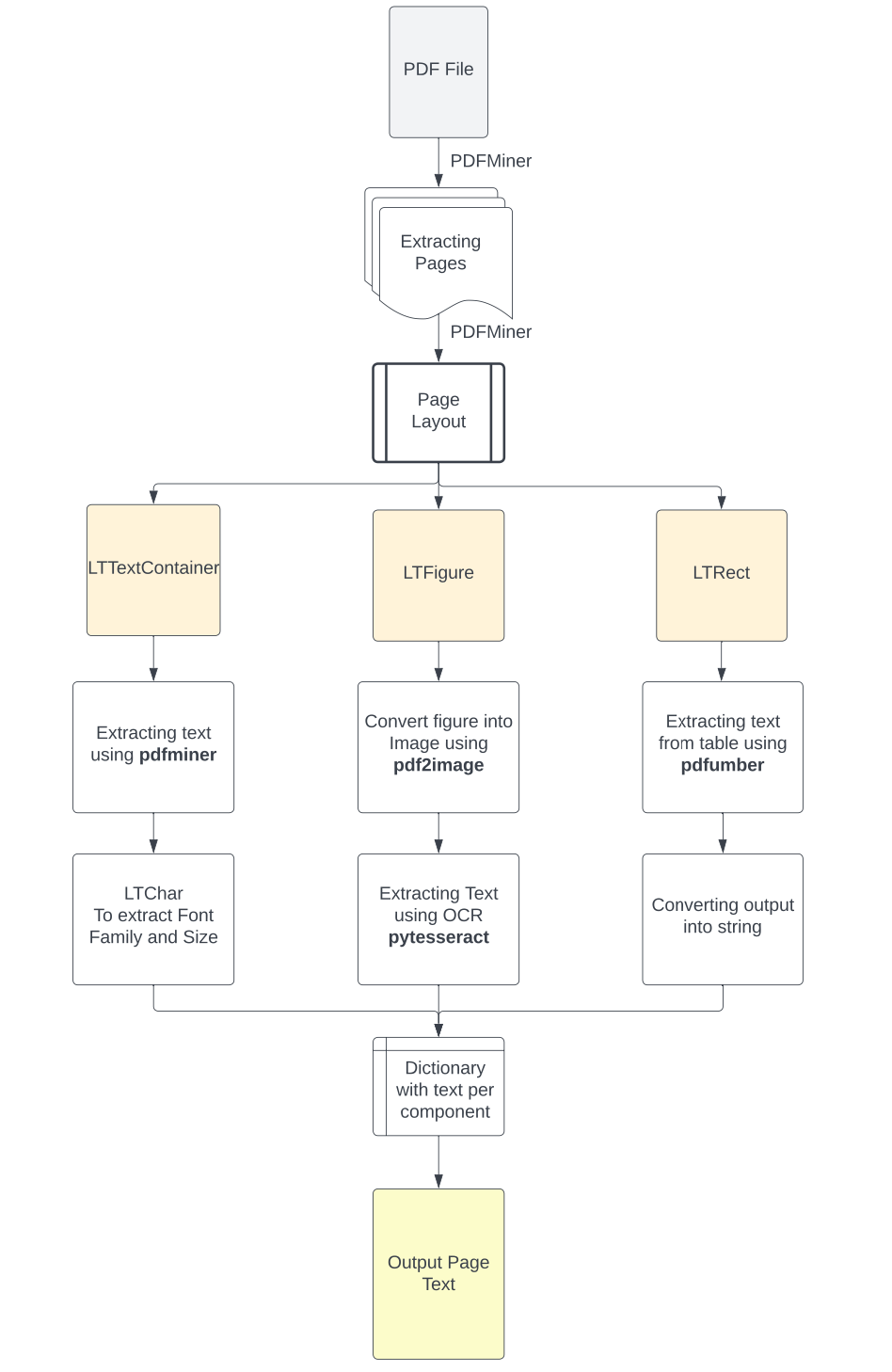
https://mp.weixin.qq.com/s/SjdoTv1htO6Ti98g3qgBjQ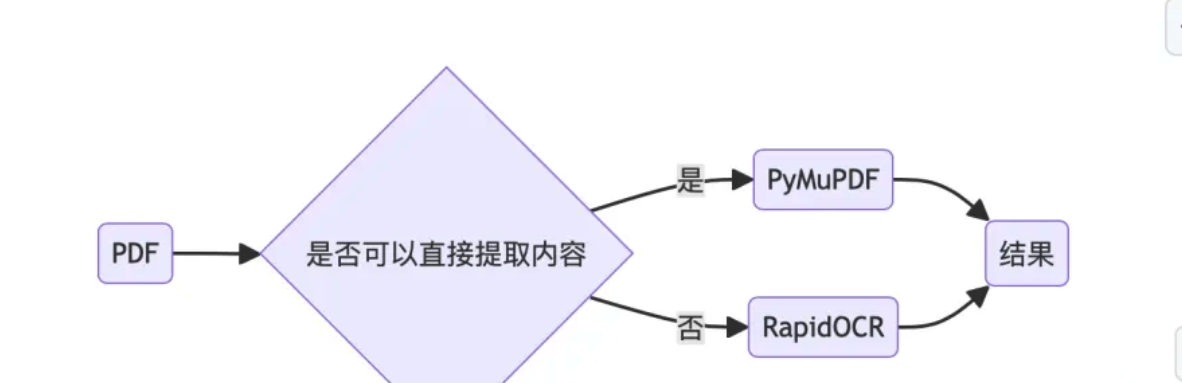
1.pdfplumber
https://blog.csdn.net/fuhanghang/article/details/122579548pdfplumber的主要类和方法
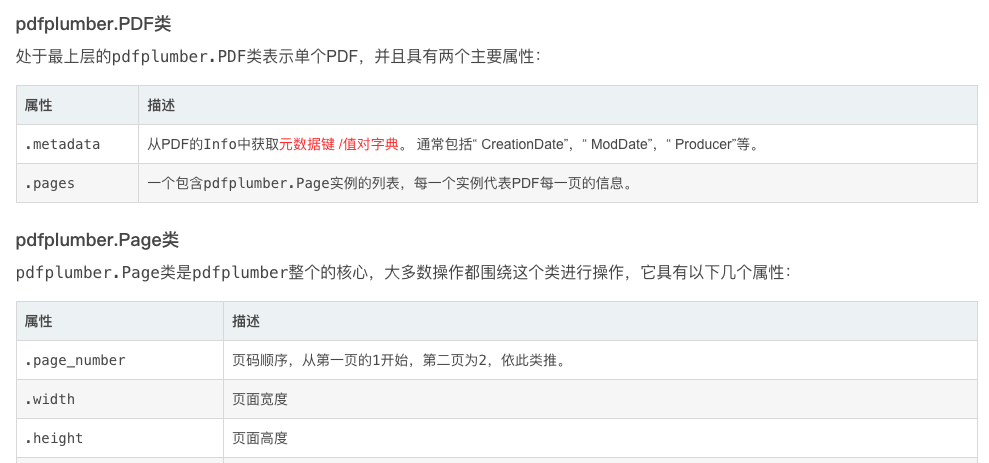
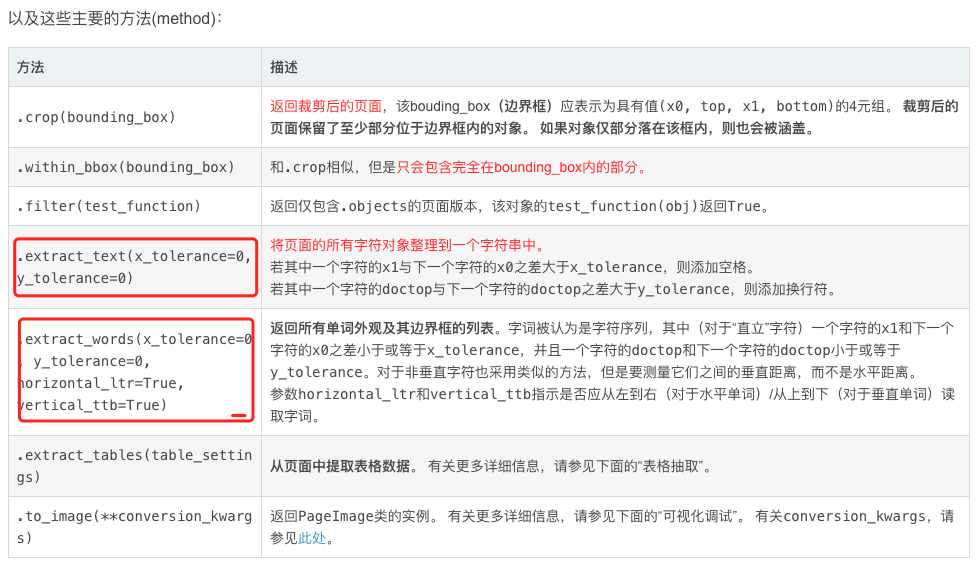
pdfplumber对于表格的提取

参考https://github.com/jsvine/pdfplumber/blob/stable/examples/notebooks/extract-table-ca-warn-report.ipynb
代码:
pdf = pdfplumber.open("../pdfs/ca-warn-report.pdf")
p0=pdf.pages[0]
im = p0.to_image() #display 第一页
table = p0.extract_table() 抽取其中最大的表格
import pandas as pd
df = pd.DataFrame(table[1:], columns=table[0])
for column in ["Effective", "Received"]:
df[column] = df[column].str.replace(" ", "") 使用panda来吧table抽取到的数据转成dataFrame格式2.layout parser
layoutparser 是一个基于深度学习的文档图像分析工具包,它提供了布局检测、OCR识别、布局分析等接口,适用于处理和分析扫描文档或图像中的文字。
https://zhuanlan.zhihu.com/p/391138225首先,将pdf的每一页转为图像,以便对其执行OCR来提取文本块。
pip install pdf2image
images = convert_from_bytes(open('FILE PATH', 'rb').read()) #将pdf的每一页转为图像并保存在内存中
image = np.array(image) #将图像转为像素值数据解析pdf论文的话,使用特定模型
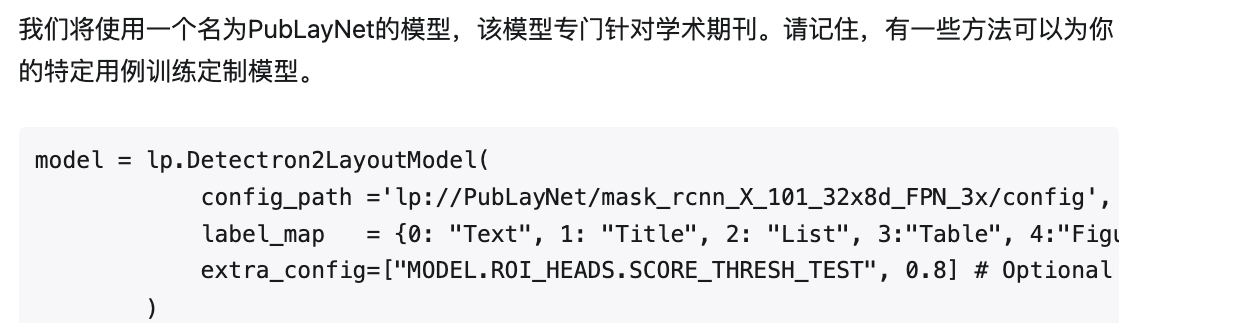
参考 https://zhuanlan.zhihu.com/p/602615194LayoutParser为常见的OCR工具提供了统一的接口,示例代码如下:
text
ocr_agent = lp.TesseractAgent() layourparser要与Tesseract 这个包相结合
使用代码如下
import layoutparser as lp
image = cv2. imread (" image_file ") # load images
model = lp. Detectron2LayoutModel ("lp :// PubLayNet / faster_rcnn_R_50_FPN_3x / config ")
layout = model . detect ( image )3.paddlepaddle的工具
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7/ppstructure
该代码从pdf中结构出各个标题层级的关系,又在word中重建该结构。
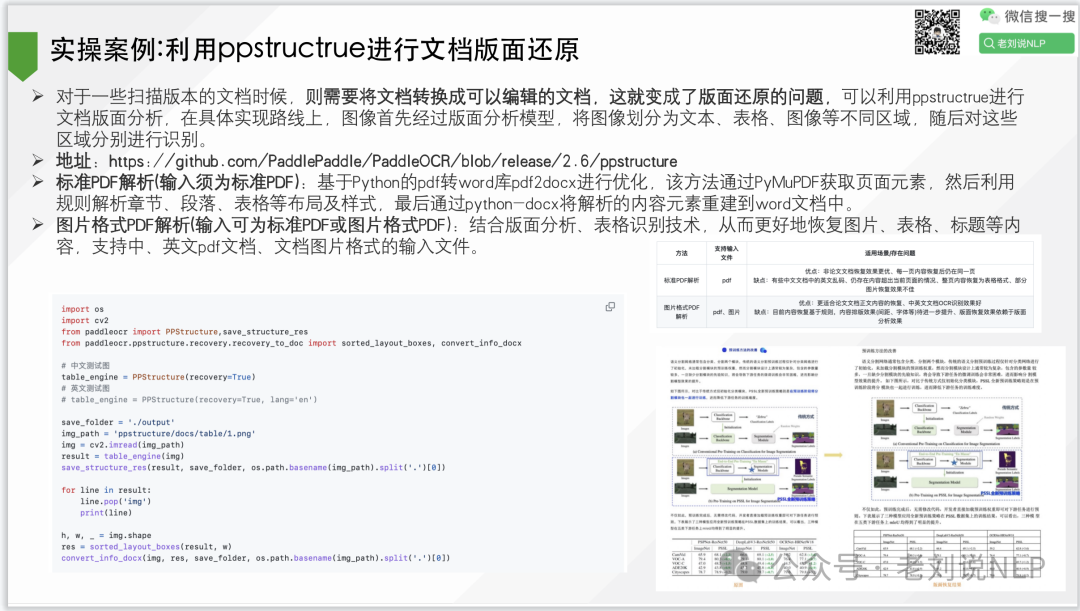
4.其他解析pdf获得子标题的方法
1.先ocr,再版面解析
https://www.textin.com/experience/pdf-to-word
2.用fitz提取,再写正则规则匹配
3.参考论文
https://arxiv.org/pdf/2308.14978.pdf
4.google的document ai
5.参考如下项目
https://github.com/OKC13/General-Documents-Layout-parser
6.使用如下接口
https://apifox.com/apidoc/shared-a55f1a3d-4871-41b7-8f1a-3af83807410b/api-120356017