本系列文章介绍
在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 "Milvus 向量数据库进阶" 这个系列文章中,我们会聚焦回答这一类问题,如 "在 AI 应用开发的不同阶段,向量数据库应该如何选型","如何正确的构建 RAG 多租系统" 等。虽然这个系列名为进阶,但内容同时适用于初级和进阶用户。我们希望通过这些内容的介绍,帮助大家在向量数据库应用的过程中少走弯路。
01.
背景回顾
上篇文章咱们聊了 to B 大型知识库系统向量数据库中台的多租设计。这篇文章继续这个主题,咱们来聊一聊 to C RAG 场景的向量数据库多用户设计。这类应用的基本特征是涉及个性化对话,如智能助理,情感陪伴,个性化推荐等。典型需求是为每个用户维护独立的对话上下文检索库,通过 RAG 提升对话的连贯性与深度。
这类 to C 的 RAG 多租设计主要需要解决这么几个关键问题:
**极高的用户数量。**典型的例子如 Character AI, 用户数量或创建的对话机器人实例数量都在千万这个量级。如何在向量数据库中维护千万量级的独立上下文内容是一个比较大的系统设计挑战。
**系统持续扩容。**考虑到每月巨大的新用户与对话上下文增量,如何完成平稳的系统扩容是第二项挑战。
**成本优化。**在 to C 的 RAG 应用中,一般活跃用户占比不会超过 10%。特别是对于运营时间较长的项目,由于总注册用户基数大,活跃用户比例在 5% 以内。如何更有效的将系统资源向活跃用户倾斜,并尽可能降低非活跃用户的数据维护成本,是第三项比较大的挑战。
02.
数据隔离粒度与多租支持数量
在深入这几个问题之前,我们先回顾一下向量数据库提供的几个数据隔离层级:
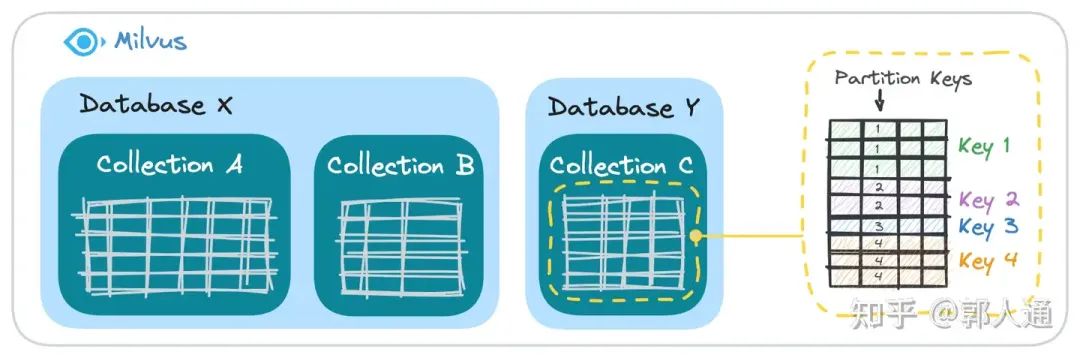
图1. Milvus 数据隔离层级
以 Milvus 为例,数据组织粒度从大到小一共有三种选择:Database,Collection,Partition Key/Partition。上文讲到的 to B 大型知识库系统中,我们一般为每个租户提供一到多个 Database,以满足数据规模及知识库构建灵活度的需要。对于 to C 对话上下文的数据隔离,一般会选择在 Colletion,或 Partition Key 这两层实现。
技术上讲,Collection 提供了更好的隔离性,是数据的表间隔离。而 Partition Key 是逻辑上的表内隔离。我们可以简单的把 Partition Key 理解为一个 Hash 分桶的过程:数据模型上我们将用户的 ID 或独立对话上下文的 ID 作为 Key。数据插入时,向量数据库系统内部会根据每条数据的 Key 进行 Hash,并插入对应的桶。查询时,我们需要在查询语句中将这个 ID 做为过滤条件,系统会找到对应的桶完成查询。
Collection 和 Partition Key 这两个粒度进行数据隔离各有优缺点,等下我们会逐步展开对比。一个快速的选型原则是:如果你的用户数量在几千或万这个量级,你可以考虑为每个用户分配一个 Collection;如果你的用户数量在几百万甚至上千万这个量级,你应该考虑为每个用户分配一个 Partition Key。
假设我们以 32 vCPU,128 GB Memory 的物理资源部署向量数据库。对于 Collection 方案,每个数据库实例大概可以支撑 5000 个用户 (即一套系统支撑 5000 个 Collection),以及 1000 个活跃用户 (有读写行为)。平均可支撑的单用户向量数据条数在 5000-10000 (以768维向量估计)。对于这个实例上的所有用户,系统提供 200-1000 左右的总 QPS。考虑公有云常见机型,单用户在向量数据库的硬件成本 每年每用户在 ¥3-10 这个区间。
同样的物理资源,对于 Partition Key 方案,单系统可支撑的用户数量在十万级。假设平均每个用户的向量数据条数是 100,单实例可支撑约 30 万用户, 其中活跃用户在 1万- 3万。系统提供的总 QPS 在 500 - 2000。单用户在向量数据库的年成本大致是 ¥0.1-0.4。
除了用户总量及单用户成本,每个用户的数据模型是否异构也是选型的重要考量。这里 "数据模型异构" 指的是不同用户的 Collection Schema 是否有差异。在绝大多数 to C 的 RAG 场景中,表的 Schema 都是在应用的业务侧进行设计,用户不会根据自己的应用需求进行自定义,因此是同构的。这样的情况,Collection 或 Partition Key 都可以适用。但如果你的应用中,不同用户的向量数据库表的 Schema 各不相同,就只能选用 Collection 进行数据隔离。因为在同一个 Collection 内,所有的 Partition Key 对应的 Schema 都需要保持一致(如图1中的示例)。
03.
系统持续扩容
像 Milvus 这样相对成熟的向量数据库系统都支持垂直和水平扩展。在项目的早期,我们一般只需要部署一套向量数据库系统实例,通过垂直和水平扩展支撑用户的增长。
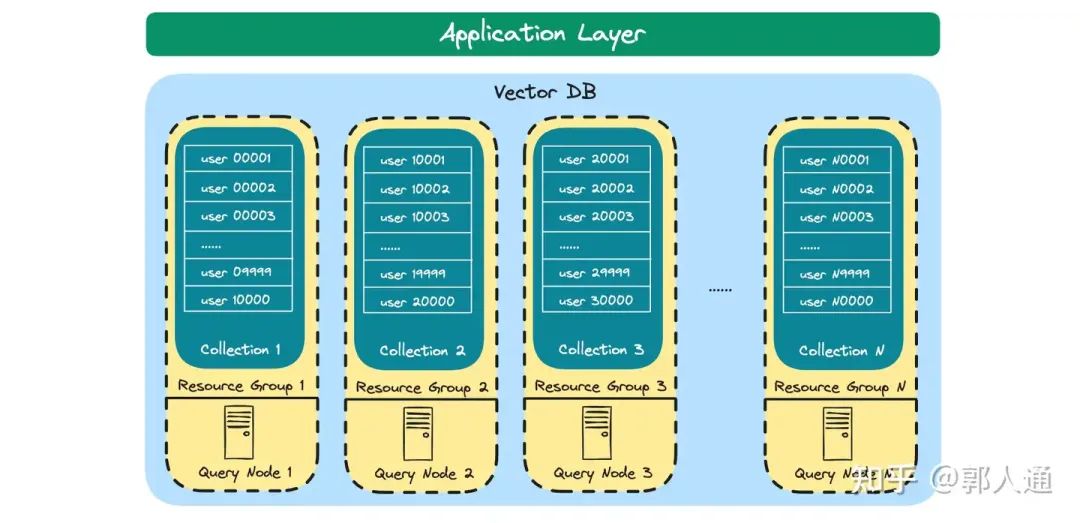
图2. 基于 partition key 方案的多租扩容
如果我们采用基于 partition key 的方案,单系统可支撑的用户数量在十万级,甚至超过百万。这时候我们需要在单个系统内通过 Collection 将用户分成若干个组,每个组的所有用户数据放到一个 Collection,用户间数据通过 partition key 机制进行隔离。
同时,我们也需要关注系统异常的爆炸半径。Milvus 提供了 Resource Group 能力,支持 Collection 到物理资源的映射。这样,我们可以将每个用户组所在的 Collection 映射到相互独立的物理查询节点。
随着用户持续增长,当前资源水位较高时,我们可以向系统内并入新的物理节点,并将其绑定至一个新的 Resource Group。这样,我们就扩展了一个新的池子。
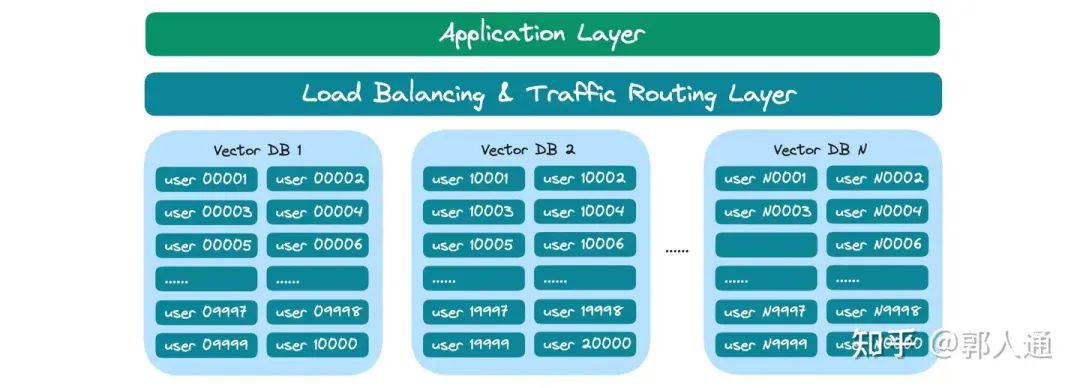
图3. 基于 collection 方案的多租扩容
在项目的高速增长期,不管是出于用户规模的原因,或是进一步提高系统整体稳定性的考虑,我们都可以考虑部署多套向量数据库实例,进而将用户分到多个物理上完全隔离的用户池。在这个架构中,我们需要在应用层和向量数据库层之间增加 Routing 层,避免上下两层间的硬链接,提供统一服务访问地址,以及扩缩容、用户跨数据库调度的灵活性。
如果我们考虑通过 Collection 的方案进行用户间数据隔离,一般单系统实例可支撑的表数量存在上限,超过上限往往会导致系统性能下降或稳定性问题,因此当表的数量接近系统能力上限时,也需要考虑上述架构。
04.
成本优化
在成本优化方面,我们主要考虑利用数据的冷热性质、或用户的活跃性质进行优化。从技术上看,一方面我们希望将热数据/活跃用户数据放置在内存层,保证数据访问的低延迟和高吞吐;另一方面,我们希望将冷数据/非活跃用户数据放置在磁盘层(一般需要SSD),使这部分用户的数据维护成本接近存储成本。
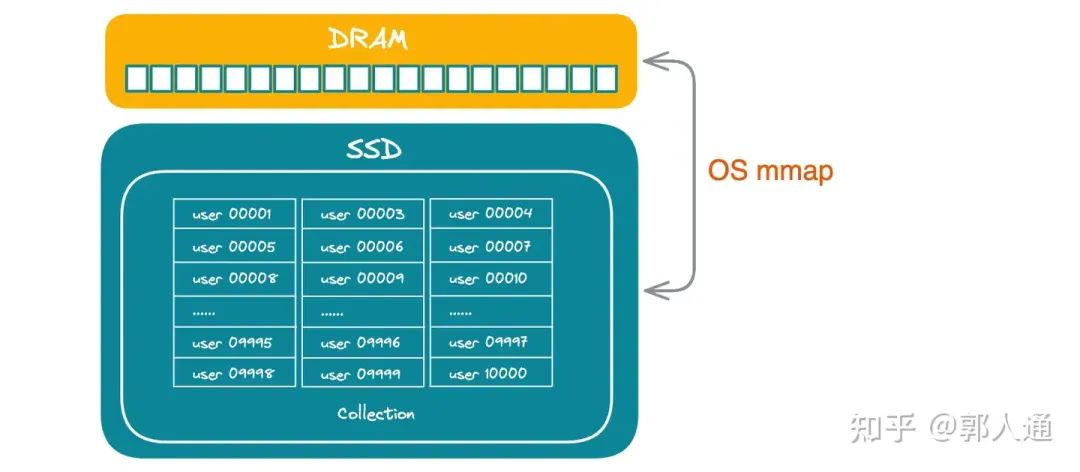
图4. partition key 的冷热存储
如果我们采用 partition key 方案进行数据隔离,Milvus 提供了 mmap 机制进行冷热数据向多层存储的映射。mmap 本身是操作系统层提供的文件到内存自动映射机制,由操作系统根据数据页的访问热度自动控制页面是否需要加载至内存,或替换到磁盘。
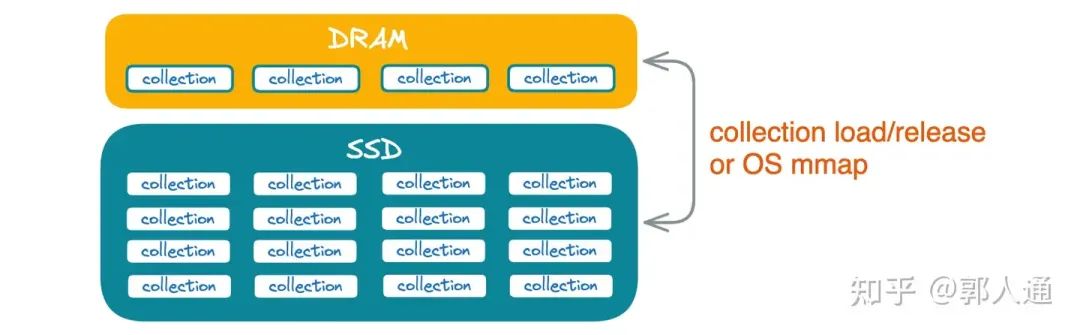
图5. collection 的冷热存储
如果我们采用 collection 方案进行数据隔离,同样可以开启 mmap 进行自动的冷热数据管理。与此同时,Milvus 还提供了逻辑层的显式数据加载/释放能力。我们可以通过 load/release 这对操作,在业务层控制是否将一个非活跃用户的 collection 在内存上释放,或将一个回归活跃的用户的 collection 从磁盘加载至内存。
mmap 和 load/release 机制可以结合使用,在这种情况下,一个被 load 到内存的 collection 中如果包含非活跃访问的数据页,也将会被操作系统自动从内存中移除。需要注意的是,在 mmap 机制中,数据从磁盘到内存的移动过程应用侧是不感知的,而 load/release 在应用侧必须感知。向量数据库不能对一个在 release 状态的 collection 进行查询。因此,在考虑使用 load/release 进行 collection 的显式加载/释放时,需要在业务侧设计 collection 的 load/release 触发策略。例如在用户登录时触发 load 进行预加载,或一周无任何访问行为,触发release 释放内存资源。此外,对于较大的 collection,需要考虑 load 操作的数据加载延迟,如果 load 耗时超过秒级,一般在业务侧用户会有感知。
作者介绍

郭人通,Zilliz 合伙人和产品总监,CCF 分布式计算与系统专委会执行委员。专注于开发面向 AI 的高效并可扩展的数据分析系统。郭人通拥有华中科技大学计算机软件与理论博士学位。
推荐阅读