本文将详细介绍如何使用Unsloth框架进行LLaMA 3.1-8B模型的微调,帮助您快速构建微调环境,并了解微调流程的基本步骤。本教程适合初学者,旨在帮助您在短时间内实现自己的专属模型微调。对于更复杂的微调参数和细节设置,将在后续文章中进一步阐述。
文将涵盖以下内容:
**1. Unsloth环境搭建:**指导您从零开始搭建Unsloth微调环境。
**2. 微调第一个LLaMA模型:**一步步教您如何通过Unsloth框架对LLaMA 3.1-8B进行微调,涵盖关键配置。
Unsloth环境搭建
最初,我在Windows 11环境下安装并运行了Unsloth,虽然安装过程顺利,但在模型微调过程中遇到了各种错误。尽管大部分问题都通过逐一解决了,但一些关键的GPU加速库仍然无法正常运行。这些库要求在Linux系统上才能正常运行并充分发挥其性能。
由于对Linux系统不够熟悉,我尝试通过编译工具在Windows上重新编译这些库,但问题依然未能解决。最终,我选择通过Windows上的WSL(Windows Subsystem for Linux)安装Ubuntu的方式来解决这些兼容性问题。这样既避免了完全切换到Linux的麻烦,又能够使用Linux环境来进行模型微调。
第一步:在WINDOWS上通过WSL安装UBUNTU
如果您使用的是Linux操作系统(建议使用Ubuntu),可以跳过这一部分的内容,直接进入后续步骤。同时,确保您在Linux系统上安装了显卡驱动,以便正常使用GPU进行加速。
如果您在Windows上通过WSL安装Ubuntu,由于WSL是一种虚拟化技术,您无需在WSL的Ubuntu系统中再次安装显卡驱动。只要Windows宿主机上已经正确安装并配置了显卡驱动,WSL内的Ubuntu系统将自动使用这些驱动配置,支持GPU加速。
windows11系统下,进入命令行工具,执行如下指令,即可快速安装完Ubuntu:
wsl -install从windows中进入Ubuntu系统,同样需要打开命令行,执行如下指令:
wsl -d ubuntu初次登录,会要求输入一个新的用户名、密码:

后续登录系统,会直接进入,而不必每次都输入用户名和密码:
(base) C:\Users\username>wsl -d ubuntuwsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。(base) root@WANG***-4090:/mnt/c/Users/username#第二步:升级系统相关组件
安装完ubuntu系统后,需要对相关的组件进行升级:
apt-get updateapt-get install -y curlapt-get install -y sudoapt-get install -y gpg第三步:安装Anaconda
建议安装Anaconda,安装相关的python包会非常方便,同时也便于对python环境进行管理。
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.shsudo sh Anaconda3-2024.06-1-Linux-x86_64.sh建议的安装目录:
/home/userName/anaconda3安装完成之后需要手动将其加入到环境变量中。需要在~/.bashrc的文件尾部增加如下内容:
export PATH="/home/wangjye/anaconda3/bin:$PATH"第四步:安装CUDA
这是最容易出错的过程,如果已经安装完驱动了,则需要在WINDOWS宿主机上运行命令 nvidia-smi 来查看硬件支持的CUDA版本,不论是WINDOWS还是LINUX一定要注意查看,不能安装错了。
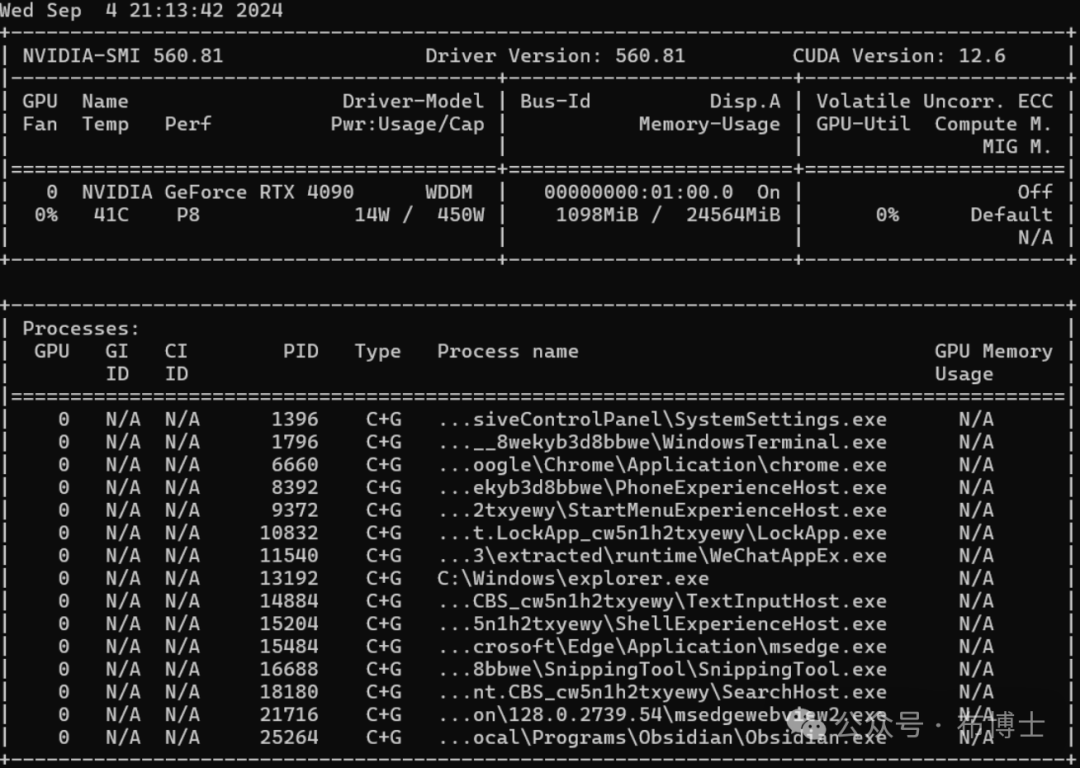
最大的坑是选择了不被支持的CUDA版本(如CUDA 12.6),导致PyTorch及TensorFlow都无法兼容4090显卡。因此选择低于12.6版本的CUDA。在这里我安装的是稳定版本的12.1。
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.runsudo sh cuda_12.1.0_530.30.02_linux.run安装过程会中断N次,提示少这样那样的文件,少什么文件按提示装什么。
然后再次安装CUDA,直接安装完成。
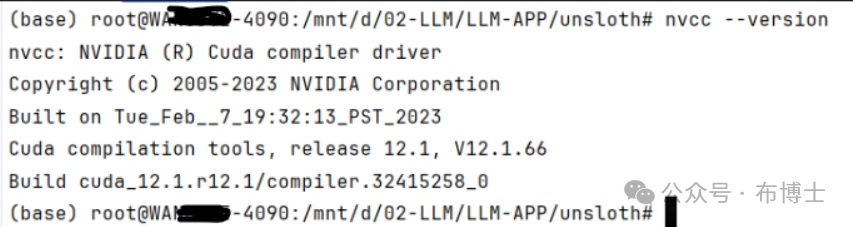
安装完成之后,如果运行nvcc --version查看是否安装成功,这里提示找不到指令。主要原因是因为CUDA的安装路径没有写入环境变量中,需要对~/.bashrc文件进行编辑,以下内容视不同操作系统的安装路径而不同:
export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH再次运行nvcc --version时,提示的结果如下,代表安装完成 :
第五步:安装pytorch
执行如下指令,完成python环境创建、安装python、安装pytorch对应的nvidia版本:
conda create --name unsloth_env \ python=3.10 \ pytorch-cuda=12.1 \ pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \ -y安装完成之后,还要验证一下安装的pytorch版本能否正常识别本机上安装的GPU,执行如下代码即可:
import torch print(torch.__version__) print(torch.cuda.is_available()) print(torch.cuda.device_count()) print(torch.cuda.get_device_name(0))返回结果如下:
2.4.0
True
1
NVIDIA GeForce RTX 4090
代表已经正确安装,并能够检测到GPU。
第六步:安装Unsloth
官方文档安装方法如下:
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git"通过如上指令安装会有时候会提示网络错误,实际上通过浏览器我是可以正常访问github.com的。
因此,改为手动安装的方法,登录http://github.com/unslothai/unsloth,手动下载zip压缩包,如下图所示:
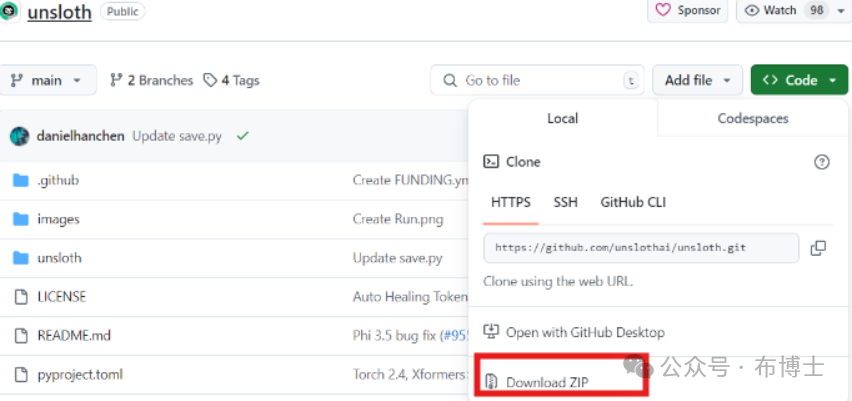
解压缩,并进入unsloth的解压缩目录,执行如下指令:
pip install ".[cu121-torch240]"安装成功,这里当时未截屏。至此,我们可以尝试进行模型训练,以验证unsloth是否能够正常工作。
微调第一个LLaMA模型
模型的微调一共包括如下5个大的步骤:
-
下载待微调的模型
-
模型加载
-
数据处理
-
模型参数配置
-
模型训练
-
模型推理测试
第一步:下载待微调的模型
这是非常重要的一步,登录unsloth官方网站可以直接复制使用,如果对llama3.1进行微调,还要在huggingface上申请该模型的使用权,申请需要至少几个小时才会回复,我申请失败,如下图所示:
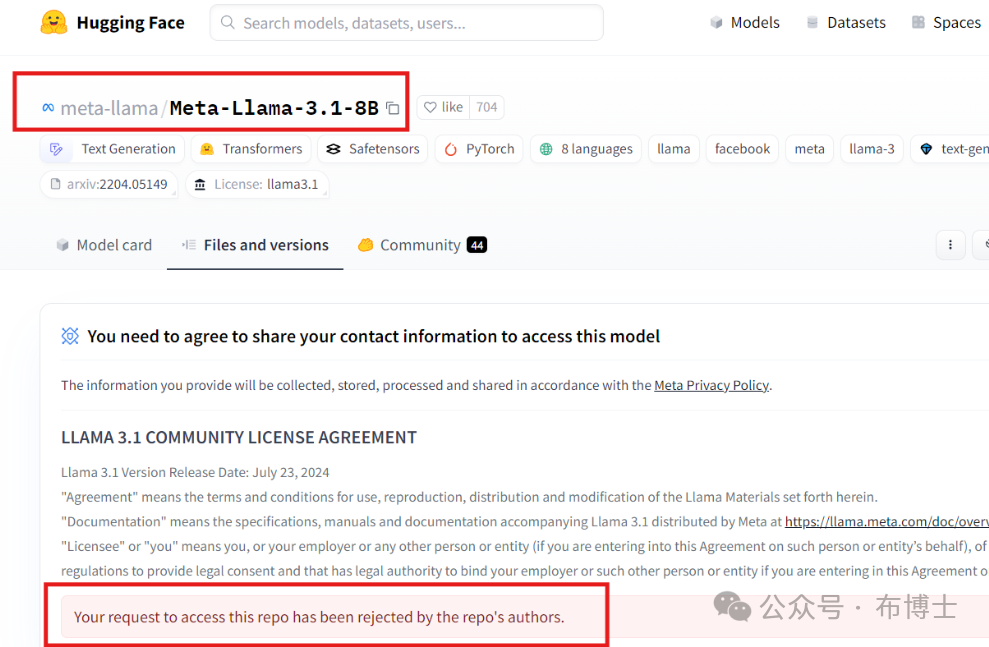
因此,直接从huggingface上的模型文件下载到本地文件系统并进行加载的,注意以下模型相关的文件,都要手动下载下来,刚开始只下载了.safetensors模型文件,结果报了一大堆错误,他需要从config.json还有tokenizer.json中读取很多配置,所以全部都下载下来了。
现在,待微调的模型已经下载完成。
注意: 如果你已经通过了 Hugging Face 的审核,下载步骤可以省略。你可以直接通过 Hugging Face 的接口下载相应的模型文件。下载完成后,模型会被缓存到本地文件系统,下次微调时无需重复下载。此外,获得模型使用权后,你还需要从 Hugging Face 获取一个 API Key,并将该模型与 API Key 关联。
不过,手动下载模型相对简单,建议直接下载以简化流程。
第二步,模型加载
通过vscode或pycharm之类的IDE新建一个jupyter文件(方便调试,调试过程中会提示你缺少这样那样的库,需要安装),复制以下代码:
import json from unsloth import FastLanguageModel import torch max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally! dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+ load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False. # 4bit pre quantized models we support for 4x faster downloading + no OOMs. fourbit_models = [ "unsloth/Meta-Llama-3.1-8B-bnb-4bit", # Llama-3.1 15 trillion tokens model 2x faster! "unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit", "unsloth/Meta-Llama-3.1-70B-bnb-4bit", "unsloth/Meta-Llama-3.1-405B-bnb-4bit", # We also uploaded 4bit for 405b! "unsloth/Mistral-Nemo-Base-2407-bnb-4bit", # New Mistral 12b 2x faster! "unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit", "unsloth/mistral-7b-v0.3-bnb-4bit", # Mistral v3 2x faster! "unsloth/mistral-7b-instruct-v0.3-bnb-4bit", "unsloth/Phi-3.5-mini-instruct", # Phi-3.5 2x faster! "unsloth/Phi-3-medium-4k-instruct", "unsloth/gemma-2-9b-bnb-4bit", "unsloth/gemma-2-27b-bnb-4bit", # Gemma 2x faster! ] # More models at https://huggingface.co/unsloth # 载入的模型 ,如下目录文件是我下载之后存入本地文件系统中的文件。model_path ="/mnt/d/02-LLM/LLM-APP/00-models/unsloth-llama-3.1-8b-bnb-4bit" # 加载模型和分词器 model, tokenizer = FastLanguageModel.from_pretrained( model_name = model_path, # Choose any model from above list! max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, # token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf )注意如下代码:
model_path ="/mnt/d/02-LLM/LLM-APP/00-models/unsloth-llama-3.1-8b-bnb-4bit" 由于代码是在wsl中的ubuntu系统内运行,因此这里不能使用windows本地的文件路径,要改为ubuntu mnt之后的文件路径。
还有要注释掉token行,因为我们没有通过hugging face网站加载模型。
至此,模型已经加载完成,会有如下图所示的提示:

第三步,数据处理
一般在进行微调时,大模型都有自己的接入数据的格式 ,因此,需要对数据进行格式转换,如下为原始的数据格式,是标准的json文档 :
[ { "instruction": "请把现代汉语翻译成古文", "input": "世界及其所产生的一切现象,都是来源于物质。", "output": "天地与其所产焉,物也。" }, { "instruction": "请把现代汉语翻译成古文", "input": "以概念来称谓事物而不超过事物的实际范围,只是概念的外延。", "output": "物以物其所物而不过焉,实也。" }]而模型需要的训练数据模式如下:
[ {"text":"Instruction: 请把现代汉语翻译成古文\nInput: 世界及其所产生的一切现象,都是来源于物质。\nOutput: 天地与其所产焉,物也。"}, {"text":"Instruction: 请把现代汉语翻译成古文\nInput: 世界及其所产生的一切现象,都是来源于物质。\nOutput: 天地与其所产焉,物也。"}]因此,需要 对其进行格式转换,数据处理代码如下:
# 获取本地的数据集 local_dataset_path = "./data.json" # 修改为你的数据集路径 # 载入的模型 model_path ="/mnt/d/02-LLM/LLM-APP/00-models/unsloth-llama-3.1-8b-bnb-4bit" # 加载本地数据集 print('载入本地数据:start...') with open(local_dataset_path, 'r', encoding='utf-8') as f: data = json.load(f) # 将数据转换为 datasets.Dataset 对象 from datasets import Dataset train_dataset = Dataset.from_list([ { "text": f"Instruction: {item['instruction']}\nInput: {item['input']}\nOutput: {item['output']}" } for item in data if isinstance(item, dict) and 'instruction' in item and 'input' in item and 'output' in item ]) print(f"处理后的训练数据集大小: {len(train_dataset)}")运行结果如下:
载入本地数据:start...处理后的训练数据集大小: 457124第四步,模型参数配置
这是非常重要的一步,需要配置各种参数,如max_steps、per_device_train_batch_size、r、lora_alpha等,在这里不进行详细说明,后续会有单独的文章内容进行详细介绍,代码如下:
from trl import SFTTrainer from transformers import TrainingArguments from unsloth import is_bfloat16_supported model = FastLanguageModel.get_peft_model( model, r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128 target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 32, lora_dropout = 0, # Supports any, but = 0 is optimized bias = "none", # Supports any, but = "none" is optimized # [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes! use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context random_state = 3407, use_rslora = False, # We support rank stabilized LoRA loftq_config = None, # And LoftQ ) trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = train_dataset, dataset_text_field = "text", max_seq_length = max_seq_length, dataset_num_proc = 2, packing = False, # Can make training 5x faster for short sequences. args = TrainingArguments( per_device_train_batch_size = 4, gradient_accumulation_steps = 8, warmup_steps = 500, # num_train_epochs = 1, # Set this for 1 full training run. max_steps = 3000, learning_rate = 3e-5, fp16 = not is_bfloat16_supported(), bf16 = is_bfloat16_supported(), logging_steps = 100, optim = "adamw_8bit", weight_decay = 0.01, lr_scheduler_type = "linear", seed = 3407, output_dir = "outputs", ), )第五步,模型训练
只有一行代码如下:
# 5. 训练 trainer_stats = trainer.train()下图为运行的第一步执行过程,以及运行完成之后的耗时统计。
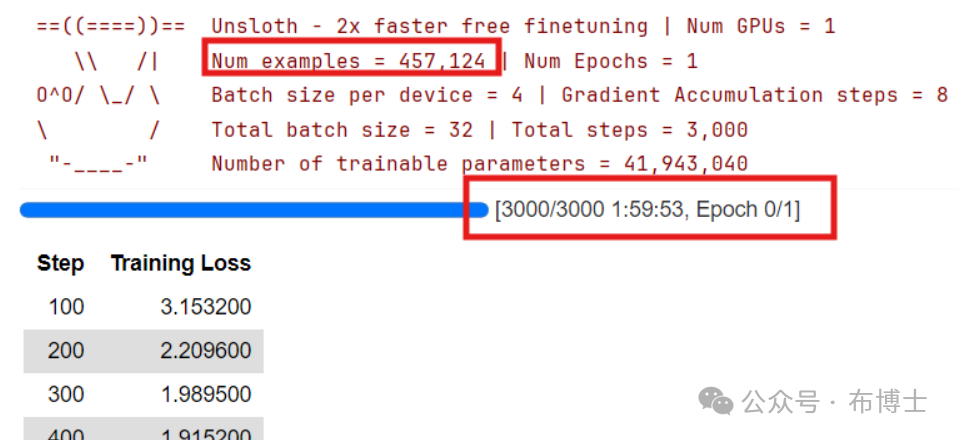
第六步,推理测试
模型微调完成之后,我们需要对模型进行推理测试,如下代码是构建了一个提示词模板,将system prompt指令以及用户输入的指令和古文内容,可以通过该提示词模板进行格式化处理,然后提供给微调后的模型进行推理使用:
alpaca_prompt = """你的任务是将给定的现代汉语文本转换为符合古文。请注意保持原文的核心思想和情感,同时运用适当的古文词汇、语法结构和修辞手法,使转换后的文本读起来如同古代文人的笔触一般。翻译要求:避免句子重复,确保语言通顺,符合古文表达习惯。例如:将"以正确的概念来校正不正确的概念,又以不正确的概念的失误之处,反过来探究正确的概念之所以正确的所在。"翻译为"以其所正,正其所不正;以其所不正,疑其所正。",确保语言通顺,符合古文表达习惯。 ### Instruction: {} ### Input: {} ### output: {}""" 执行推理的代码如下:
FastLanguageModel.for_inference(model) # Enable native 2x faster inference inputs = tokenizer( [ alpaca_prompt.format( "请把现代汉语翻译成古文", # instruction "这个管道昇在同时代人里也是极具个性和才华的。这时,赵孟頫在京城获得赏识,不再是那个只在吴兴有薄名,却不能靠书画养活自己,不得不去教私塾的教书先生。", # input "", # output - leave this blank for generation! ) ], return_tensors = "pt").to("cuda") # Generate the output outputs = model.generate(**inputs, max_new_tokens=64, use_cache=True) # Decode the output decoded_output = tokenizer.batch_decode(outputs, skip_special_tokens=True) #print(decoded_output) # 提取输出结果中原有的input文本 # 假设输出格式是一致的,古文在"### output:\n"后面 # print(decoded_output[0]) original_text = decoded_output[0].split("### Input:\n")[1].split("### output:\n")[0].strip() # Extract the translated ancient Chinese text # Assuming the output format is consistent and the ancient text starts after "### output:\n" translated_text = decoded_output[0].split("### output:\n")[1].strip() print("原始的现代汉语:" + original_text) print("翻译后的古文:" + translated_text)执行的结果如下:
原始的现代汉语:这个管道昇在同时代人里也是极具个性和才华的。这时,赵孟頫在京城获得赏识,不再是那个只在吴兴有薄名,却不能靠书画养活自己,不得不去教私塾的教书先生。翻译后的古文:管仲之才亦异于当世,时赵孟頫在京得赏识,乃非吴兴薄名,不能自养,负笈私门者也。是翻译为古文了,但是将管道昇翻译为"管仲"了!!!先不管了,后续再对微调的过程进行参数优化。
总结
本文详细介绍了如何使用Unsloth框架在WSL环境下对LLaMA 3.1-8B模型进行微调的全过程。通过从环境搭建、微调过程等,读者可以一步步了解如何高效微调自己的专属模型,并通过实例演示了微调后模型的推理效果。本教程特别适合初学者,帮助他们快速掌握Unsloth框架的应用。