简介
就在2月21日,ARM发布了新一代面向服务器的高性能处理器N3和V3,N系列平衡性能和功耗,而V系列则注重更高的性能。此次发布的N3,单个die最高32核(并加入到CCS,Compute Subsystems,包含Core,System Ip等),以CCS来讨论,每瓦性能比上一代提升20%-50%。而Neoverse V3,单个die最高64核(加入CCS),ARM似乎更强调其AI相关的分析能力,并于Neoverse V2 相比,Neoverse V3 在机器学习方面提供了+96%的性能提升,在RDBMS上提供了+16%的性能提升,在加密货币方面提供了+9%的性能提升,在整数工作负载方面提供了+12% 的性能提升。与此同时,相关的系统IP同时发布,例如新一代的CMN S3,这将取代前一代的CMN700,但没有更多的信息。


V3微架构的改变
Neoverse™ V3处理器应用 Arm®v9.2-A架构,Core接口使用DSU-120,Core总体性能提升没有官方数据,部分分析认为相比较前代提升大约在10~20%。
MMU

MMU,左为V3,右为V2
MMU仍然延续经典的2级TLB结构,更细节的微架构设计手册没有过多的描述,Translation Cache,聚合,预取等传统技术依然存在,对于L2 TLB,3代微架构没有明显的改变。最大的改变是 L1 TLB,其中ITLB的entry从V2的48entry升级到V3的128entry,而DTLB 从48entry升级为96entry。最具特点的是ITLB的巨大升级,可能是为了应对AI场景下,指令集地址变化更频繁。这也是为什么ARM对V3更强调AI场景的分析。
L1 Cache

ICache,上为V3,下为V2
ICache的改变主要在V3抛弃了Macro-Operation Cache(手册没提,应该是放弃了),这里亦安分析可能是对于精简指令集,这种做法性价比不高,或者设计确实没有达到理想的状态,再者,ARM本身非常关注功耗,所以在V3处理器版本抛弃了这种微架构。手机端A77,A78,X1,X2,X3均具有MOPCache,X4放弃该微架构。
DCache在参数上描述无差异。
L2 Cache
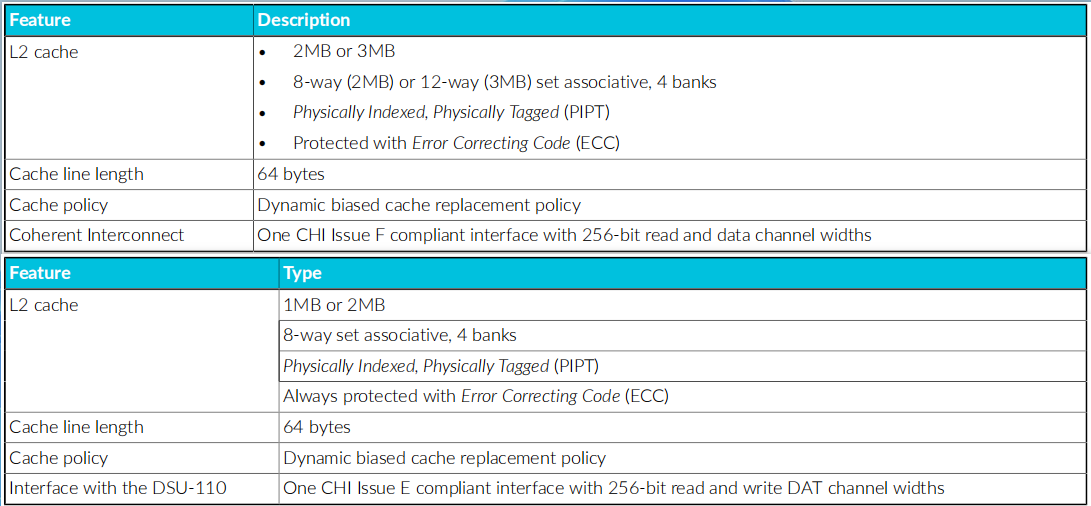
L2 cache,上V3,下V2
L2从官方描述上看,从原来的V2(1-2MB)升级V3(2-3MB),其它参数没有明显变化,详细的微架构尚不清楚。
总结
由于V3/N3刚刚发布,其它例如预测器,乱序等模块的微架构尚不清晰,等待公布更多信息再聊,除去按照惯例的性能提升描述,比较值得关注的是ARM对处理器涉及AI分析的强调,由此可以知道近几年AI发展对整个芯片行业的巨大冲击,似乎只有往AI上靠,才会获得市场的青睐,这一场AI争夺战已经进入白热化,芯片行业本身就处在中心。