1、数据集定义
针对实际的微调需求,使用专门针对业务垂直领域的私有数据进行大模型微调才是我们需要做的。因此,我们需要探讨如何在LLaMA-Factory项目及上述创建的微调流程中引入自定义数据集进行微调。**对于LLaMA-Factory项目,目前仅支持两种格式的数据集:alpaca 和 sharegpt。
1.1 alpaca
alpaca 格式的数据集按照以下方式组织:
json
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
] 比较常见的alpaca_gpt4_data_zh.json就是标准的alpaca格式,我们自己在界面能够顺利加载的原因在于,所有的数据文件,在LLaMA-Factory项目中均使用dataset_info.json进行定义和管理,其存储位置在LLaMA-Factory/data目录下:
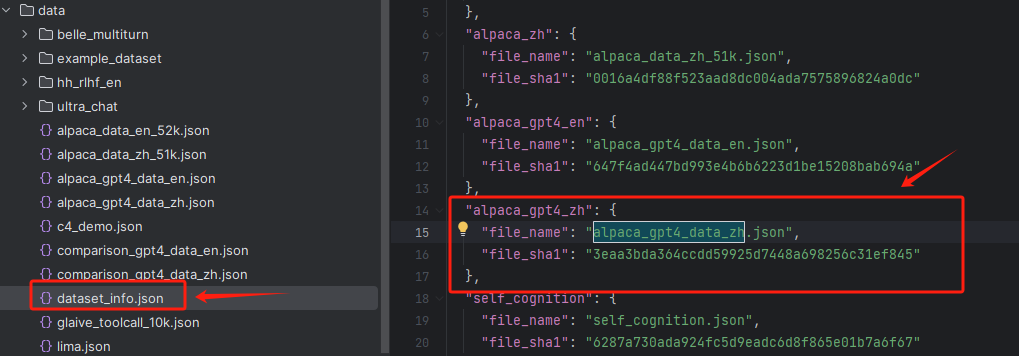
在这个文件中,定义一个数据集的格式如下:
json
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的 SHA-1 哈希值(可选,留空不影响训练)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system 列)"
}
}可以看到,上述的定义格式还是非常复杂的,但在使用过程中,我们并不需要全部去填写,其中比较关键的部分,且必须定义的参数是:
json
"数据集名称": {
"formatting": "sharegpt", # 数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)
"file_name": " ", # 具体的文件名称
"columns": {
...
...
...
},
"tags": {
...
...
...
}
},所以对于alpaca格式的数据,dataset_info.json 中的 columns 应为:
json
"数据集名称": {
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}1.2 sharegpt
反观另外一种支持的数据格式:sharegpt 格式,其标准形式如下:
json
[
{
"conversations": [
{
"from": "human",
"value": "用户指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
] 关于sharegpt 格式,在dataset_info.json中的定义形式就是如下:
json
"数据集名称": {
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt"
}
}1.3 数据准备
接下来,我们就来演示一下,应该如何在微调中加入自己的数据集。数据我们使用大模型自动生成100个问答对,这个可以自己想办法执行,我用的是傲慢与偏见小说的TXT传递给一个在线大模型,让他给生成100个问答对,然后保存到CSV中,我们读入数据查看下
python
import pandas as pd
data = pd.read_csv("aoman.csv",encoding='GBK')
data
定一个函数将其转换为sharegpt 需要的格式
python
import json
def export_modified_conversations_to_json(df, num_records, file_name, col_list):
"""
将对话数据以修改后的格式导出到 JSON 文件。
:param df: 包含对话数据的 DataFrame。
:param num_records: 要导出的记录数。
:param file_name: 输出 JSON 文件的名称。
:col_list:数据列
"""
output = []
# 遍历 DataFrame 并构建修改后所需的数据结构
for i, row in df.head(num_records).iterrows():
conversation = [
{"from": "human", "value": row[col_list[0]]},
{"from": "gpt", "value": row[col_list[1]]}
]
output.append({
"conversations": conversation,
"system": " ", # 系统提示词,可选填
"tools": " " # 工具描述,可选填
})
# 将列表转换为 JSON 格式并保存为文件
with open(file_name, 'w', encoding='utf-8') as file:
json.dump(output, file, ensure_ascii=False, indent=2)
# 注意:此代码假设df DataFrame已经存在,并且包含正确的列名(question,answer)。
# 在实际使用中,请确保df变量已正确定义,并包含所需数据。
bash
export_modified_conversations_to_json(data, data.shape[0], './Pride_and_Prejudice.json',data.columns[1:3])
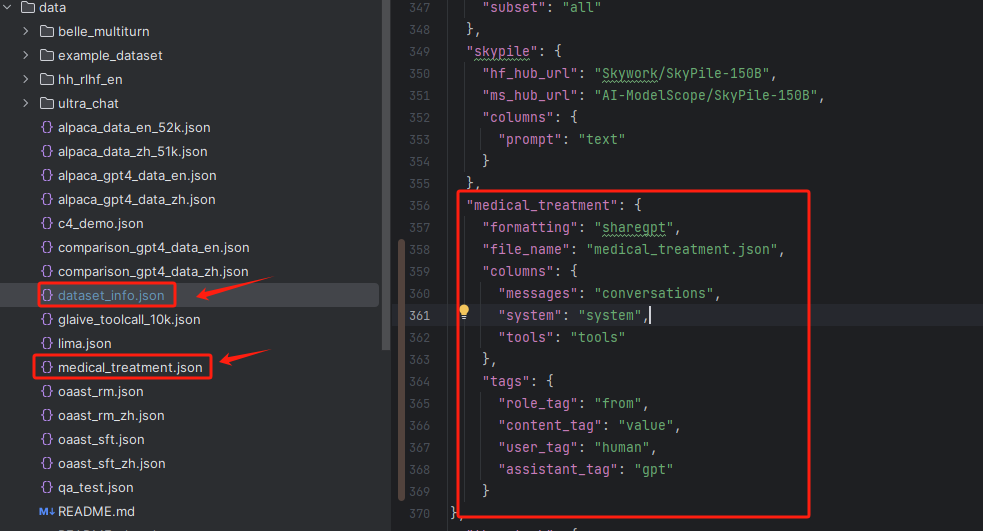
然后,需要执行的操作是,把该数据集移动到LLaMA-Factory/data中,并在dataset_info.json中指定如下内容:
json
"medical_treatment": {
"formatting": "sharegpt",
"file_name": "medical_treatment.json",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt"
}
},
2、微调
2.1 测试
我们先将没有微调的模型导入,找一个问题测试一下,看看答案,微调完后进行对比

2.2 数据查看
当我们将数据文件配置好后,就可以在启动的界面找到相应的文件,然后查看其数据格式,

2.3 开始微调
查看显存占用,因为数据集量只有100条,所以显存占用比较小

微调过程,可以发现loss是一直在下降,微调用了10个epoch

3、预测
3.1 预测指标
选择刚才的数据进行预测,发现评估指标很差,主要是数据集太少,而且训练轮数也比较低,真实任务需要大量的数据集和训练迭代才能达到比较好的效果

预测任务的评估结果,使用了 BLEU 和 ROUGE 这两种常用的机器翻译评估指标,以及其他一些性能指标。以下是每个指标的解析:
BLEU (BiLingual Evaluation Understudy)
- predict_bleu-4 : 2.306378
- 这表明模型生成的翻译文本与参考翻译之间的相似度为 23.06%。
- BLEU 分数越高,翻译质量越好。
- BLEU 分数通常在 0 到 100 之间,分数越高越好。
ROUGE (Recall-Oriented Understudy for Goals)
- predict_rouge-1 : 19.632283
- 这表明模型生成的翻译文本与参考翻译之间的匹配度(召回率)为 19.63%。
- ROUGE-1 评估模型生成的单词与参考翻译中单词的匹配情况。
- predict_rouge-2 : 3.859137
- 这表明模型生成的翻译文本与参考翻译之间的匹配度(F1 分数)为 3.86%。
- ROUGE-2 评估模型生成的短语与参考翻译中短语的匹配情况。
- predict_rouge-l : 13.356055
- 这表明模型生成的翻译文本与参考翻译之间的匹配度(F1 分数)为 13.36%。
- ROUGE-L 评估模型生成的句子与参考翻译中句子的匹配情况。
其他性能指标
- predict_model_preparation_time : 0.004 秒
- 这表明模型准备时间(例如加载模型权重)为 0.004 秒。
- predict_runtime : 215.3883 秒
- 这表明模型生成整个翻译文本所需的时间为 215.3883 秒。
- predict_samples_per_second : 0.464 个样本/秒
- 这表明模型每秒生成的样本数为 0.464 个样本。
- predict_steps_per_second : 0.232 步/秒
- 这表明模型每秒进行的计算步骤数为 0.232 步。
总结
根据这些评估结果,我们可以看出模型的翻译质量还有提升空间,特别是在 BLEU 和 ROUGE 分数方面。模型的生成速度也相对较慢。您可以考虑尝试一些改进策略,例如:
- 这表明模型每秒进行的计算步骤数为 0.232 步。
- 使用更大的模型: 更大的模型通常可以生成更高质量的翻译。
- 使用不同的训练数据: 使用更高质量或更多样化的训练数据可以提高模型的性能。
- 使用不同的优化算法 : 不同的优化算法可能会对模型的性能产生不同的影响。
希望这些信息能帮助您更好地理解这段代码!
3.2 预测结果
预测的文件会模型存储在save文件夹下相应的模型文件中

3.3 预测效果
输入微调前同样的问题来对比下
