引言
今天带来第一篇量化论文LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale笔记。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
大语言模型已被广泛采用,但推理时需要大量的GPU内存。我们开发了一种Int8矩阵乘法的过程,用于Transformer中的前馈和注意力投影层,这可以将推理所需的内存减少一半 ,同时保持全精度性能。
通过我们的方法,一个175B参数的16/32位检查点可以被加载、转换为Int8,并立即使用而不降级性能。
我们开发了一个两部分量化程序LLM.int8()。首先使用向量级量化,对矩阵乘法中的每个内积使用单独的归一化常数,从而对大多数特征进行量化。然而,对于突现的异常值(outlier),还包括了一种新的混合精度分解方案,将异常特征维度隔离到16位矩阵乘法中,同时仍然有99.9%以上的值在8位中进行乘法运算。
1. 总体介绍
大型预训练语言模型在自然语言处理中被广泛采用,但推理时需要大量的内存。对于参数数量达到或超过67亿的Transformer语言模型,前馈和注意力投影层及其矩阵乘法操作占用了95%的参数和65-85%的计算量。减少参数大小的一种方法是将其量化为更少的位数,并使用低位精度的矩阵乘法。为了实现这一目标,已经开发了Transformer的8位量化方法。虽然这些方法可以减少内存使用,但它们会导致性能下降,通常需要在训练后进一步调整量化,而且仅对参数少于3.5亿的模型进行了研究。对于最多350M参数的无降级量化尚未得到很好的理解,而几十亿级参数的量化仍然是一个未解的挑战。
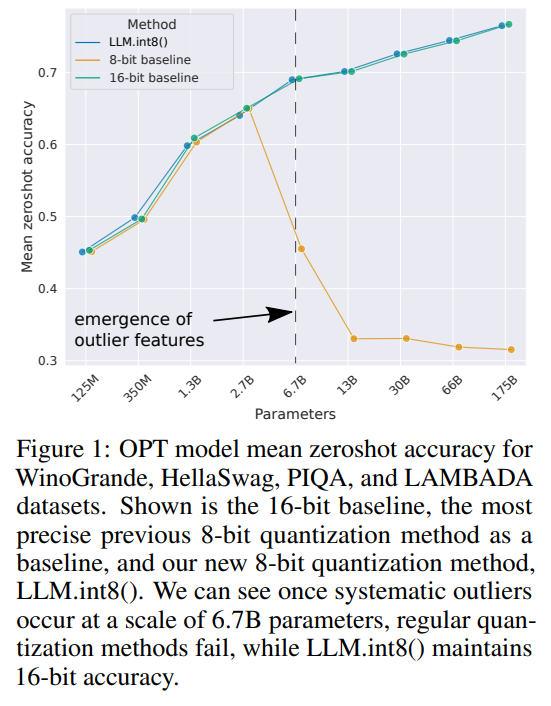
在本文中,我们提出了第一个几十亿级规模的Int8量化程序,用于Transformer模型且不会导致任何性能降级。我们的程序使得可以加载一个175B参数的Transformer模型,其权重为16位或32位,将前馈和注意力投影层转换为8位,并立即使用转换后的模型进行推理,而不会出现性能降级。我们通过解决两个关键挑战实现了这一结果:需要在超过10亿参数的规模下提高量化精度,以及需要明确表示那些稀疏但系统性的大幅度离群特征,这些特征一旦出现在所有Transformer层中,从67亿参数的规模开始会破坏量化精度。如图1所示。我们展示了通过我们方法的第一部分------向量级量化------在最多27亿参数的规模下保持性能的可能性。
对于向量级量化,矩阵乘法可以视为行向量和列向量的独立内积序列。因此,我们可以对每个内积使用单独的量化归一化常数来提高量化精度。在进行下一步操作之前,通过行和列归一化常数的外积来恢复矩阵乘法的输出。
为了在超过67亿参数的规模下避免性能降级,关键在于理解推理过程中隐藏状态特征维度中极端离群值的出现。为此,我们提供了一种新的描述性分析,显示出特征幅度大约比其他维度高出20倍的大特征首先出现在约25%的Transformer层中,然后随着Transformer参数扩展到60亿,逐渐扩散到其他层。在约67亿参数时,会发生相位转移(phase shift),所有Transformer层和75%的序列维度都受到极端幅度特征的影响。
这些离群值具有高度系统性:在67亿规模下,每个序列中出现15万个离群值,但它们集中在整个Transformer中的仅6个特征维度中。将这些离群特征维度设置为零会使top-1注意力softmax概率质量减少超过20%,并使验证困惑度增加600-1000%,尽管它们仅占所有输入特征的约0.1%。相比之下,移除相同数量的随机特征仅使概率最大减少0.3%,困惑度减少约0.1%。
为了支持有效的量化处理这些极端离群值,我们开发了混合精度分解,这是我们方法的第二部分。我们对离群特征维度执行16位矩阵乘法,对其他99.9%的维度执行8位矩阵乘法。我们将向量级量化和混合精度分解的组合命名为LLM.int8()。我们展示了通过使用LLM.int8(),可以在不降低性能的情况下对最多175B参数的LLM进行推理。我们的方法不仅提供了对这些离群值对模型性能影响的新见解,还使得首次能够在单台配备消费级GPU的服务器上使用非常大的模型,如OPT-175B/BLOOM。我们将软件(bitsandbytes)开源,并发布了Hugging Face Transformers的集成。
2. 背景知识
我们关注两个问题:量化技术在什么规模下以及为何会失败,以及这与量化精度有何关系。为了解答这些问题,我们研究了高精度的非对称量化(零点量化)和对称量化(绝对最大量化)。尽管零点量化通过使用数据类型的完整位范围提供了高精度,但由于实际限制,它很少被使用。绝对值最大量化是最常用的技术。
2.1 8位数据类型和量化
绝对值最大量化 通过乘 s x f 16 s_{x_{f16}} sxf16将输入缩放到8位范围[−127, 127],其中 s x f 16 s_{x_{f16}} sxf16是127除以整个张量的绝对最大值缩放系数,这相当于除以无限范数并乘以127。因此,对于FP16输入矩阵 X f 16 ∈ R s × h X_{f16} \in \R^{s \times h} Xf16∈Rs×h,Int8绝对值最大量化定义为:
X i 8 = ⌊ 127 ⋅ X f 16 max i j ( ∣ X f 1 6 i j ∣ ) ⌉ = ⌊ 127 ∥ X f 16 ∥ ∞ ⋅ X f 16 ⌉ = ⌊ s x f 16 ⋅ X f 16 ⌉ X_{i8} = \left\lfloor \frac{127 \cdot X_{f16}}{\max_{ij}(|X_{f16_{ij}}|)} \right\rceil = \left\lfloor\frac{127}{\|X_{f16}\|{\infty}} \cdot X{f16} \right\rceil= \left\lfloor s_{x_{f16}} \cdot X_{f16}\right\rceil Xi8=⌊maxij(∣Xf16ij∣)127⋅Xf16⌉=⌊∥Xf16∥∞127⋅Xf16⌉=⌊sxf16⋅Xf16⌉
其中 ⌊ ⌉ \lfloor \rceil ⌊⌉表示四舍五入。
零点量化 通过使用归一化的动态范围 n d x nd_x ndx进行缩放,然后通过零点 z p x zp_x zpx进行平移,将输入分布移到完整范围 [−127, 127]。通过这种仿射变换,任何输入张量都将利用数据类型的所有位,从而减少了不对称分布的量化误差。例如,对于ReLU输出,绝对最大量化中的值范围 [−127, 0) 未被使用,而零点量化中则使用了完整的 [−127, 127] 范围。零点量化由以下方程给出:
n d x f 16 = 2 ⋅ 127 max i j ( X f 16 i j ) − min i j ( X f 16 i j ) (1) nd_{x_{f16}} = \frac{2 \cdot 127}{\max_{ij}(X_{f16}^{ij}) - \min_{ij}(X_{f16}^{ij})} \tag 1 ndxf16=maxij(Xf16ij)−minij(Xf16ij)2⋅127(1)
z p x i 16 = ⌊ X f 16 ⋅ min i j ( X f 16 i j ) ⌉ (2) zp_{x_{i16}} = \lfloor X_{f16} \cdot \min_{ij}(X_{f16}^{ij}) \rceil \tag 2 zpxi16=⌊Xf16⋅ijmin(Xf16ij)⌉(2)
X i 8 = ⌊ n d x f 16 ⋅ X f 16 ⌉ (3) X_{i8} =\lfloor nd_{x_{f16}} \cdot X_{f16}\rceil \tag 3 Xi8=⌊ndxf16⋅Xf16⌉(3)
要在操作中使用零点量化,我们将张量 X i 8 X_{i8} Xi8 和零点 z p x i 16 zp_{x_{i16}} zpxi16输入到一个特殊指令中,该指令在执行16位整数操作之前,将 z p x i 16 zp_{x_{i16}} zpxi16加到 X i 8 X_{i8} Xi8的每个元素上。例如,要乘以两个零点量化的数字 A i 8 A_{i8} Ai8 和 B i 8 B_{i8} Bi8和它们的零点 z p a i 16 zp_{a_{i16}} zpai16和 z p b i 16 zp_{b_{i16}} zpbi16,计算:
C i 32 = multiply i 16 ( A z p a i 16 , B z p b i 16 ) = ( A i 8 + z p a i 16 ) ( B i 8 + z p b i 16 ) (4) C_{i32} = \text{multiply}{i16}(A{zp_{a_{i16}}}, B_{zp_{b_{i16}}}) = (A_{i8} + zp_{a_{i16}})(B_{i8} + zp_{b_{i16}}) \tag 4 Ci32=multiplyi16(Azpai16,Bzpbi16)=(Ai8+zpai16)(Bi8+zpbi16)(4)
其中,如果 multiply i 16 \text{multiply}{i16} multiplyi16 指令不可用(例如在GPU或TPU上),需要展开计算:
C i 32 = A i 8 B i 8 + A i 8 z p b i 16 + B i 8 z p a i 16 + z p a i 16 z p b i 16 (5) C{i32} = A_{i8} B_{i8} + A_{i8} zp_{b_{i16}} + B_{i8} zp_{a_{i16}} + zp_{a_{i16}} zp_{b_{i16}} \tag 5 Ci32=Ai8Bi8+Ai8zpbi16+Bi8zpai16+zpai16zpbi16(5)
其中 A i 8 B i 8 A_{i8} B_{i8} Ai8Bi8以 Int8 精度计算,其余部分以 Int16/32 精度计算。因此,如果没有 multiply i 16 \text{multiply}{i16} multiplyi16指令,零点量化可能会较慢。在这两种情况下,输出作为32位整数 C i 32 C{i32} Ci32 累加。要进行反量化(dequantize),我们需要除以缩放常数 n d a f 16 nd_{a_{f16}} ndaf16 和nd_{x_{f16}} 。
Int8 矩阵乘法与 16 位浮点输入和输出 给定隐藏状态 X f 16 ∈ R s × h X_{f16} \in \mathbb{R}^{s \times h} Xf16∈Rs×h 和权重 W f 16 ∈ R h × o W_{f16} \in \mathbb{R}^{h \times o} Wf16∈Rh×o,其中序列维度为 s s s,特征维度为 h h h,输出维度为 o o o,我们执行 8 位矩阵乘法,输入和输出均为 16 位,如下所示:
X f 16 W f 16 = C f 16 ≈ 1 c x f 16 c w f 16 C i 32 = S f 16 ⋅ C i 32 ≈ S f 16 ⋅ A i 8 B i 8 = S f 16 ⋅ Q ( A f 16 ) Q ( B f 16 ) (6) X_{f16} W_{f16} = C_{f16} \approx \frac{1}{c_{x_{f16}} c_{w_{f16}}} C_{i32} = S_{f16} \cdot C_{i32} \approx S_{f16} \cdot A_{i8} B_{i8} = S_{f16} \cdot Q(A_{f16}) Q(B_{f16}) \tag 6 Xf16Wf16=Cf16≈cxf16cwf161Ci32=Sf16⋅Ci32≈Sf16⋅Ai8Bi8=Sf16⋅Q(Af16)Q(Bf16)(6)
其中 Q ( ⋅ ) Q(\cdot) Q(⋅) 是绝对最大量化(absmax)或零点量化(zeropoint),而 c x f 16 c_{xf16} cxf16 和 c w f 16 c_{wf16} cwf16 是相应的张量级缩放常数(absmax 的 s x s_x sx 和 s w s_w sw 或零点量化的 n d x nd_x ndx 和 n d w nd_w ndw)。
3 Int8矩阵乘法的规模化
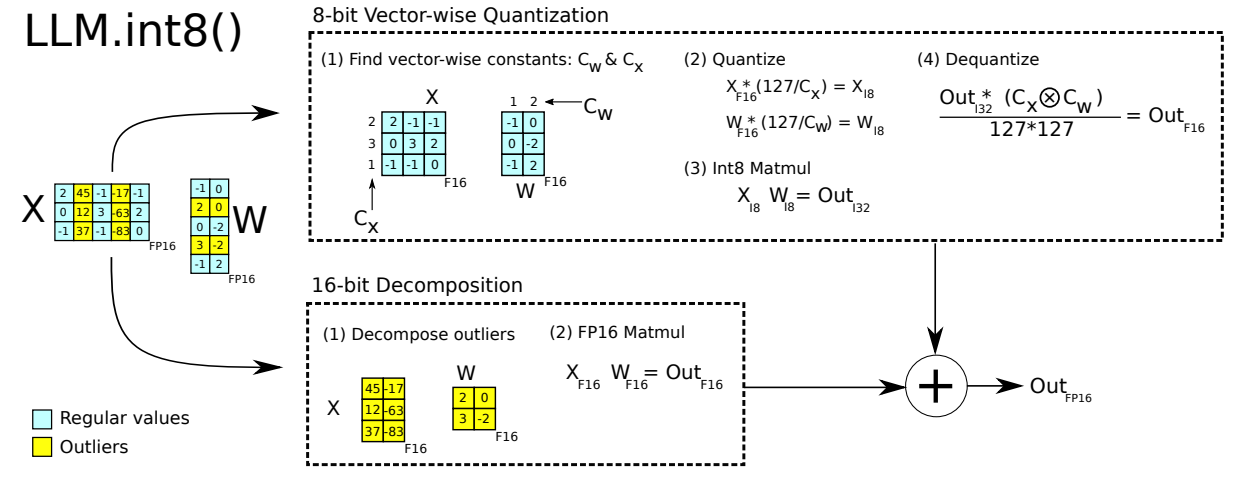
图 2:LLM.int8() 的示意图。给定 16 位浮点输入 X f 16 X_{f16} Xf16 和权重 W f 16 W_{f16} Wf16,特征和权重被分解为大幅度特征和其他值的子矩阵。异常特征矩阵以 16 位进行乘法运算。所有其他值以 8 位进行乘法运算。通过按行和列的绝对最大值对 C x C_x Cx 和 C w C_w Cw 进行缩放,然后将输出量化为 Int8,来执行 8 位向量级乘法。Int32 矩阵乘法的输出 O u t i 32 Out_{i32} Outi32 通过归一化常数 C x ⊗ C w C_x \otimes C_w Cx⊗Cw 的外积进行反量化。最后,异常输出和常规输出都以 16 位浮点数格式累积。
使用每个张量一个缩放常数的量化方法主要面临的挑战是,单个异常值会降低所有其他值的量化精度。因此,每个张量多个缩放常数会更理想,这样异常值的影响被限制在每个块内。我们通过使用向量级量化改进了一种最常见的块级量化方法------行级量化。
为了处理在所有Transformer层中出现的大幅度异常特征(超过 6.7B 规模),单纯的向量级量化已经不再足够。为此,我们开发了混合精度分解,其中小幅度特征维度(约 0.1%)以 16 位精度表示,而其他 99.9% 的值则以 8 位精度进行乘法运算。由于大多数条目仍以低精度表示,我们与 16 位相比保留了约 50% 的内存减少。
向量级量化和混合精度分解如图 2 所示。LLM.int8() 方法是 absmax 向量级量化和混合精度分解的结合。
3.1 向量级量化
增加矩阵乘法中的缩放常数数量的一种方法是将矩阵乘法视为依赖的内积。给定隐藏状态 X f 16 ∈ R b × h \mathbf{X}{f16} \in \mathbb{R}^{b \times h} Xf16∈Rb×h 和权重矩阵 W f 16 ∈ R h × o \mathbf{W}{f16} \in \mathbb{R}^{h \times o} Wf16∈Rh×o,可以为 X f 16 \mathbf{X}{f16} Xf16 的每一行分配不同的缩放常数 c x f 16 c{x_{f16}} cxf16,为 W f 16 \mathbf{W}{f16} Wf16 的每一列 分配 c w c{w} cw。为了反量化,我们通过 1 / ( c x f 16 c w f 16 ) 1/(c_{x_{f16}}c_{w_{f16}}) 1/(cxf16cwf16) 来反归一化(denormalization)每个内积结果。对于整个矩阵乘法,这等同于通过外积 c x f 16 ⊗ c w f 16 \mathbf{c}{x{f16}} \otimes \mathbf{c}{w{f16}} cxf16⊗cwf16 进行反归一化,其中 c x ∈ R s \mathbf{c}{x} \in \mathbb{R}^{s} cx∈Rs 和 c w ∈ R o \mathbf{c}{w} \in \mathbb{R}^{o} cw∈Ro。因此,具有行和列常数的矩阵乘法的完整方程为:
C f 16 ≈ 1 c x f 16 ⊗ c w f 16 C i 32 = S ⋅ C i 32 = S ⋅ A i 8 B i 8 = S ⋅ Q ( A f 16 ) Q ( B f 16 ) , (7) \mathbf{C}{f{16}} \approx \frac{1}{\mathbf{c}{x{f16}} \otimes \mathbf{c}{w{f16}}} \mathbf{C}{i32} = S \cdot \mathbf{C}{i32} = \mathbf{S} \cdot \mathbf{A}{i8} \mathbf{B}{i8} = \mathbf{S} \cdot Q(\mathbf{A}{f16}) \ Q(\mathbf{B}{f16}), \tag 7 Cf16≈cxf16⊗cwf161Ci32=S⋅Ci32=S⋅Ai8Bi8=S⋅Q(Af16) Q(Bf16),(7)
这就是我们称之为矩阵乘法的向量级量化。
3.2 LLM.int8() 的核心:混合精度分解
在我们的分析中,我们展示了对于十亿级 8 位Transformer来说,一个显著的问题是它们具有大幅度特征(列),这些特征对于Transformer性能至关重要,需要高精度量化。然而,向量级量化,我们最好的量化技术,量化了每一行的隐藏状态,这对于异常特征无效。幸运的是,我们发现这些异常特征在实际中既稀疏又具有系统性,仅占所有特征维度的约 0.1%,因此我们开发了一种新的分解技术,专注于这些特定维度的高精度乘法。
我们发现,对于输入矩阵 X f 16 ∈ R s × h \mathbf{X}{f16} \in \mathbb{R}^{s \times h} Xf16∈Rs×h,这些异常值在几乎所有序列维度中系统性出现,但仅限于特定的特征/隐藏维度 h h h。因此,我们提出了矩阵乘法的混合精度分解,其中我们将异常特征维度分离为集合 O = { i ∣ i ∈ Z , 0 ≤ i ≤ h } O = \{i \mid i \in \mathbb{Z}, 0 \leq i \leq h\} O={i∣i∈Z,0≤i≤h},该集合包含所有具有大于阈值 α \alpha α 的异常值的维度。在我们的工作中,我们发现 α = 6.0 \alpha = 6.0 α=6.0 足以将Transformer性能降级减少到接近零。使用爱因斯坦标记法,其中所有索引为上标,给定权重矩阵 W f 16 ∈ R h × o \mathbf{W}{f16} \in \mathbb{R}^{h \times o} Wf16∈Rh×o,矩阵乘法的混合精度分解定义如下:
C f 16 ≈ ∑ h ∈ O X f 16 h W f 16 h + S f 16 ⋅ ∑ h ∉ O X i 8 h W i 8 h (8) \mathbf{C}{f16} \approx \sum{h \in O} \mathbf{X}{f16}^{h} \mathbf{W}{f16}^{h} + \mathbf{S}{f16} \cdot \sum{h \notin O} \mathbf{X}{i8}^{h} \mathbf{W}{i8}^{h} \tag 8 Cf16≈h∈O∑Xf16hWf16h+Sf16⋅h∈/O∑Xi8hWi8h(8)
其中 S f 16 \mathbf{S}{f16} Sf16 是 Int8 输入和权重矩阵 X i 8 \mathbf{X}{i8} Xi8 和 W i 8 \mathbf{W}_{i8} Wi8 的反归一化项。
这种将 8 位和 16 位分开的方法允许对异常值进行高精度乘法,同时使用 8 位权重的内存高效矩阵乘法,这些权重占总值的 99.9% 以上。由于异常特征维度的数量在最多 13B 参数的Transformer中不超过 7( ∣ O ∣ ≤ 7 |O| \le 7 ∣O∣≤7),因此这种分解操作仅消耗约 0.1% 的额外内存。
3.3 实验设置
我们测量了量化方法在将几种公开预训练语言模型的规模扩大到 175B 参数时的鲁棒性。关键问题不在于某种量化方法对特定模型的性能如何,而在于这种方法在规模扩大时的表现趋势。
我们使用了两种实验设置。一种基于语言建模的困惑度,我们发现这是一个非常鲁棒的度量,能够对量化降级非常敏感。我们使用这种设置来比较不同的量化基准。此外,我们还评估了 OPT 模型在各种不同最终任务上的零样本准确性降级,并将我们的方法与 16 位基准进行比较。
对于语言建模设置,我们使用了在 fairseq中预训练的稠密自回归Transformer,范围从 125M 到 13B 参数。这些Transformer在 Books、英文 Wikipedia、CC-News、OpenWebText等上进行了预训练。
为了评估 Int8 量化后的语言建模降级,评估了 8 位Transformer在 C4 语料库的验证数据上的困惑度,该语料库是 Common Crawl 语料库的一个子集。使用 NVIDIA A40 GPU 进行此评估。
为了测量零样本性能的降级,使用了 OPT 模型,并在 EleutherAI 语言模型评估工具上评估这些模型。
3.4 主要结果
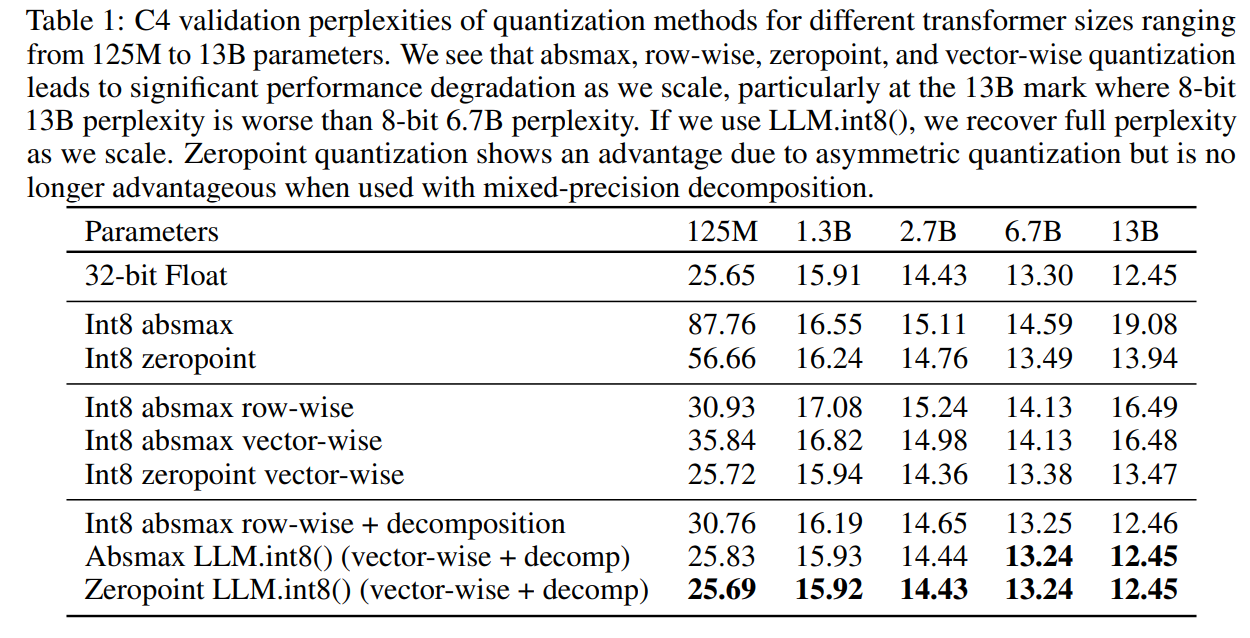
在 C4 语料库上评估的从 125M 到 13B Int8 模型的主要语言建模困惑度结果见表 1。我们看到,absmax、行级和零点量化在规模扩大时表现不佳,其中 2.7B 参数后的模型性能低于较小的模型。零点量化在超过 6.7B 参数时也失效。 LLM.int8() 方法是唯一一个能够保持困惑度的方案。
当我们查看 OPT 模型在 EleutherAI 语言模型评估工具上的零样本性能扩展趋势图1时,LLM.int8() 在从 125M 扩展到 175B 参数时保持了完整的 16 位性能。另一方面,基准的 8 位 absmax 向量级量化表现不佳,并且性能退化为随机表现。
尽管我们的主要关注点是节省内存,我们也测量了 LLM.int8() 的运行时间。与 FP16 基准相比,量化开销可能会减慢参数少于 6.7B 的模型的推理速度。然而,6.7B 参数或更少的模型适合大多数 GPU,并且在实际中对量化的需求较少。对于与 175B 模型相当的大规模矩阵乘法,LLM.int8() 的运行时间大约快两倍。
4 大规模Transformer中的大幅度特征的出现
随着Transformer模型规模的扩大,大幅度的异常特征会出现,并对所有层及其量化产生强烈影响。给定一个隐藏状态 X ∈ R s × h \mathbf{X} \in {\mathbb{R}}^{s \times h} X∈Rs×h,其中 s s s 是序列/令牌维度, h h h 是隐藏/特征维度,我们定义一个特征为特定的维度 h i h_{i} hi。我们的分析关注于一个特定的特征维度 h i h_{i} hi 在给定Transformer的所有层中的表现。
我们发现异常特征对注意力机制和Transformer的整体预测性能有显著影响。在 13B 模型中,每个 2048 令牌序列中存在多达 150k 的异常特征,这些异常特征具有高度的系统性,仅表示最多 7 个独特的特征维度 h i h_{i} hi。这项分析的洞察对于开发混合精度分解方法至关重要。
4.1 发现异常特征
我们旨在选择一个小的特征子集进行分析,以便结果既可理解又不过于复杂,同时能够捕捉重要的概率性和结构性模式。我们使用了一种经验方法来找到这些约束。我们根据以下标准定义异常特征:特征的幅度至少为 6.0,影响至少 25% 的层,并影响至少 6% 的序列维度。
更正式地,给定一个具有 L L L 层的Transformer和隐藏状态 X l ∈ R s × h , l = 0... L \mathbf{X}{l} \in \mathbb{R}^{s \times h}, l=0...L Xl∈Rs×h,l=0...L,其中 s s s 是序列维度, h h h 是特征维度,我们定义一个特征为隐藏状态 X l i \mathbf{X}{l_{i}} Xli 中的特定维度 h i h_{i} hi。我们追踪具有至少一个幅度为 α ≥ 6 \alpha \geq 6 α≥6 的值的维度 h i h_{i} hi,并且我们只收集那些在至少 25% 的Transformer层 0... L 0...L 0...L 中出现的相同特征维度 h i h_{i} hi,并且在所有隐藏状态 X l \mathbf{X}_{l} Xl 中的至少 6% 的序列维度 s s s 中出现的异常值。由于特征异常值仅在注意力投影(key/query/value/output)和前馈网络扩展层(第一个子层)中出现,我们在此分析中忽略了注意力函数和 FFN 收缩层(第二个子层)。
使用混合精度分解时,如果我们将任何幅度为 6 或更大的特征视为异常特征,困惑度降级会停止。对于受到异常值影响的层数,大模型中的异常特征具有系统性:它们要么出现在大多数层中,要么根本不存在。另一方面,小模型中的异常特征是概率性的:它们有时在每个序列中的某些层中出现。因此,我们将检测到异常特征所需的层数阈值设置为仅限于我们的最小模型(125M 参数)中的单个异常值。这一阈值对应于至少 25% 的Transformer层受到相同特征维度的异常值的影响。第二常见的异常值仅出现在单个层(2% 的层),这表明这一阈值是合理的。我们使用相同的程序来确定在 125M 模型中受到异常特征影响的序列维度的阈值:异常值出现在至少 6% 的序列维度中。
我们测试了高达 13B 参数的模型。为了确保观察到的现象不是由于软件中的错误,评估了在三种不同软件框架中训练的Transformer模型。
4.2 测量异常特征的影响
为了证明异常特征对注意力机制和预测性能至关重要,在将隐藏状态 X l \mathbf{X}_{l} Xl 输入到注意力投影层之前,将异常特征设置为零,然后比较去除异常特征后的顶级 softmax 概率与正常 softmax 概率。对所有层独立执行此操作,意味着前向传递正常的 softmax 概率值,以避免级联错误,并隔离异常特征的影响。还报告了如果移除异常特征维度(将其设置为零)并将这些修改后的隐藏状态通过Transformer传播时的困惑度降级。作为对照,我们对随机非异常特征维度应用相同的程序,并注意注意力机制和困惑度的降级。
主要定量结果可以总结为以下四点:
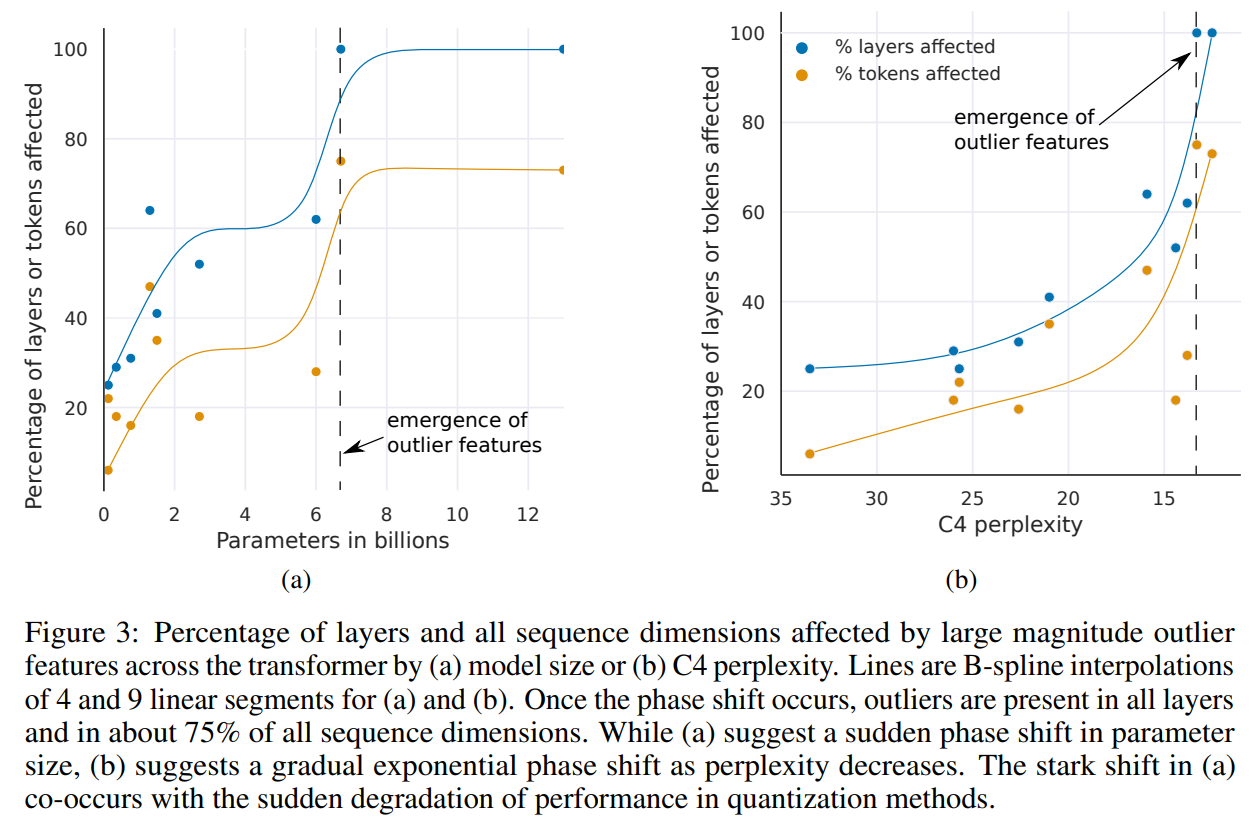
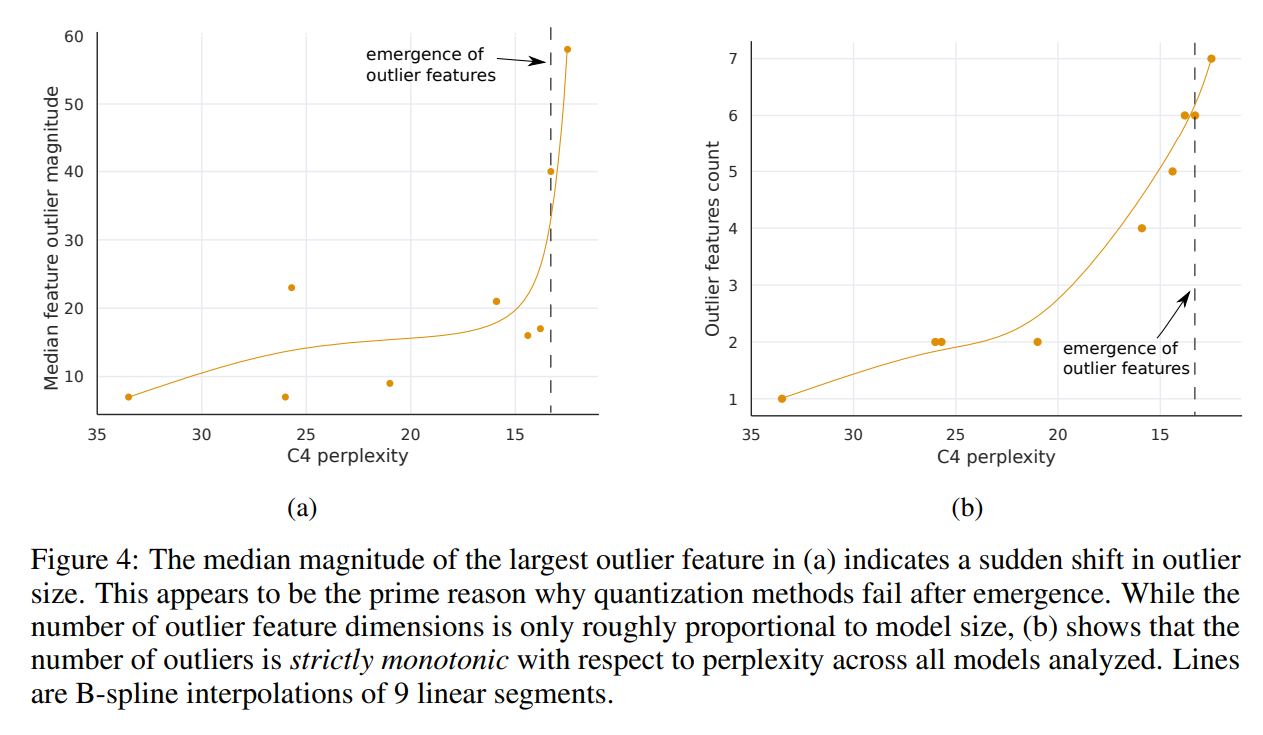
(1)按参数数量测量时,Transformer所有层中的大幅度特征的出现发生在 6B 和 6.7B 参数之间的突然转变,如图 3a 所示,受影响的层的百分比从 65% 增加到 100%。受影响的序列维度的数量迅速从 35% 增加到 75%。这一突然变化与量化开始失败的点同时发生。
(2)或者,按困惑度测量时,Transformer所有层中的大幅度特征的出现可以平滑地按照困惑度递减的指数函数来观察,如图 3b 所示。这表明,出现并没有突然发生,可能通过研究小模型中的指数趋势在相位变化发生之前检测到新兴特征。这也表明,出现不仅仅与模型大小有关,还与困惑度有关,困惑度与训练数据量、数据质量等多个额外因素相关。
(3)一旦异常特征出现在Transformer的所有层中,中位数异常特征幅度会迅速增加,如图 4a 所示。异常特征的大幅度及其不对称分布破坏了 Int8 量化的精度。这是量化方法在 6.7B 规模下失败的核心原因------量化分布的范围过大,导致大多数量化区间为空,小量化值被量化为零,基本上消除了信息。假设除了 Int8 推理之外,常规 16 位浮点训练也由于 6.7B 规模以上的异常值变得不稳定------如果你乘以充满 60 幅度值的向量,很容易超过最大 16 位值 65535。
(4)异常特征的数量与 C4 困惑度递减严格单调相关,如图 4b 所示,而与模型大小的关系是非单调的。这表明,模型困惑度而非单纯的模型大小决定了相位变化。假设模型大小只是众多需要达到出现的一个重要变量。
这些异常特征在相位变化发生后具有高度系统性。例如,对于一个 6.7B 的Transformer,序列长度为 2048,我们发现每个序列大约有 150k 个异常特征,但这些特征仅集中在 6 个不同的隐藏维度中。
这些异常特征对Transformer性能至关重要。如果移除异常特征,平均top-1 softmax 概率从约 40% 降低到约 20%,验证困惑度增加了 600--1000%,尽管最多只有 7 个异常特征维度。当我们移除 7 个随机特征维度时,顶级概率仅减少 0.02--0.3%,困惑度增加 0.1%。这突显了这些特征维度的关键性。对于这些异常特征,量化精度至关重要,因为即使是微小的误差也会极大地影响模型性能。
4.3 量化性能的解释
分析表明,在大型Transformer中,特定特征维度的异常值无处不在,这些特征维度对Transformer的性能至关重要。由于按行和按向量量化方法分别对每个隐藏状态序列维度 s s s(行)进行缩放,而异常值则发生在特征维度 h h h(列),因此这两种方法无法有效处理这些异常值。这就是为什么 absmax 量化方法在异常值出现后会迅速失败的原因。
然而,几乎所有异常值都有严格的不对称分布:它们要么完全是正值,要么完全是负值。这使得零点量化对这些异常值特别有效,因为零点量化是一种不对称量化方法,可以将这些异常值缩放到完整的 − 127 , 127 -127,127 −127,127 范围。这解释了我们在表 1 中量化扩展基准测试的强大表现。然而,在 13B 规模下,即使是零点量化也会由于量化误差积累和异常值幅度的快速增长而失败,如图 4a 所示。
如果我们使用包含混合精度分解的完整 LLM.int8() 方法,则零点量化的优势消失,表明剩余的分解特征是对称的。然而,按向量量化仍然比按行量化具有优势,这表明需要增强的量化精度来保持完整的预测性能。
5 相关工作
在量化数据类型和Transformer量化方面,有一些紧密相关的工作,如下所述。。
8 位数据类型。我们的工作研究了围绕 Int8 数据类型的量化技术,因为它目前是 GPU 支持的唯一 8 位数据类型。其他常见的数据类型包括定点或浮点 8 位数据类型(FP8)。这些数据类型通常具有符号位和不同的指数位和分数位组合。例如,这种数据类型的一个常见变体具有 5 位的指数和 2 位的分数,并使用无缩放常数或零点缩放。这些数据类型对于大幅度值具有较大的误差,因为它们只有 2 位用于分数,但对于小幅度值提供较高的精度。Jin 等提供了对特定固定点指数/分数位宽度在具有特定标准差的输入下的最优性的出色分析。我们相信 FP8 数据类型相比 Int8 数据类型提供了更好的性能,但目前,GPU 和 TPU 均不支持这一数据类型。
语言模型中的异常特征。大幅度的异常特征在语言模型中已被研究过。以往的工作证明了Transformer中异常值出现与层归一化以及令牌频率分布之间的理论关系。类似地,Kovaleva 等将 BERT 模型家族中的异常值出现归因于 LayerNorm,Puccetti 等通过实证研究表明,异常值的出现与训练分布中令牌的频率相关。我们进一步扩展了这项工作,展示了自回归模型的规模如何与这些异常特征的出现属性相关,并说明了适当建模异常值对于有效量化的重要性。
数十亿规模Transformer量化。有两种方法与我们的方法平行发展:nuQmm和 ZeroQuant。这两种方法都使用相同的量化方案:组级量化,它具有比按向量量化更细的量化归一化常数粒度。这种方案提供了更高的量化精度,但也需要自定义 CUDA 内核。nuQmm 和 ZeroQuant 都旨在加速推理和减少内存占用,而我们则专注于在 8 位内存占用下保持预测性能。nuQmm 和 ZeroQuant 评估的最大模型分别为 2.7B 和 20B 参数。ZeroQuant 实现了 20B 模型的 8 位量化零降级性能。我们展示了我们的方法允许对高达 176B 参数的模型进行零降级量化。nuQmm 和 ZeroQuant 都建议更细的量化粒度可以有效地量化大型模型。这些方法与 LLM.int8() 互补。另一个平行的工作是 GLM-130B,它使用了我们工作的见解来实现零降级 8 位量化。GLM-130B 通过 8 位权重存储执行完整的 16 位精度矩阵乘法。

6. 讨论和限制
我们首次证明了数十亿参数的Transformer模型可以量化到 Int8,用于推理而不会出现性能下降。我们通过分析大规模异常大幅度特征的洞察,开发了混合精度分解方法,将异常特征隔离到单独的 16 位矩阵乘法中。结合按向量量化的方法,我们的 LLM.int8() 方法经过实验证明可以恢复高达 175B 参数模型的完整推理性能。
我们工作的主要局限性在于,分析仅限于 Int8 数据类型,并未研究 8 位浮点(FP8)数据类型。由于当前的 GPU 和 TPU 不支持这种数据类型。
第三个局限性是我们没有对注意力函数使用 Int8 乘法。由于我们关注的是减少内存占用,而注意力函数没有使用任何参数,因此并不严格需要。然而,初步探索表明,解决这一问题需要额外的量化方法。
最后一个局限性是我们关注的是推理,而未研究训练或微调。
A 与 16 位精度的内存使用对比

表 3 比较了不同开源模型在 16 位推理和 LLM.int8() 下的内存占用情况。LLM.int8() 使得在配备消费级 GPU 的单节点上运行最大开源模型 OPT-175B 和 BLOOM-176B 成为可能。
B 额外相关工作
少于 10 亿参数的Transformer模型的量化。Transformer的量化研究主要集中在少于 10 亿参数的掩码语言模型上,包括 BERT和 RoBERTa。8 位 BERT/RoBERTa 的变种包括 Q8BERT、QBERT、带有量化噪声的乘积量化、TernaryBERT和 BinaryBERT。Zhao 等的工作同时进行了量化和剪枝。这些模型都需要进行量化感知微调或训练后量化才能在低精度下使用。与我们的方法相比,该模型可以直接使用而不会出现性能下降。
如果将矩阵乘法视为 1x1 卷积,那么按向量量化等同于卷积的通道量化结合行量化。Wu 等在 BERT 尺寸的Transformer(350M 参数)中使用了这一方法,而我们是首次研究自回归和大规模模型的按向量量化。我们了解到的唯一其他量化Transformer的工作是 Chen 等,该工作在前向传播中使用了零点量化,在反向传播中使用了零点-行量化。然而,这项工作仍然是针对少于 10 亿参数的Transformer。我们在评估中比较了零点量化和行量化,并且不需要训练后量化。
低位宽和卷积网络的量化。使用少于 8 位的数据类型的工作通常用于卷积网络,以减少内存占用并提高移动设备上的推理速度,同时最小化模型的退化。研究了不同位宽的方法:1 位方法、2 到 3 位、4 位、更多位或可变数量的位。我们关注的是 8 位Transformer,这些Transformer不会退化性能,并且可以利用常用 GPU 通过 Int8 张量核心加速推理。
另一条关注卷积网络量化的工作是学习调整量化过程以改善量化误差。例如,使用 Hessian 信息、步长量化、软量化、通过线性规划优化的混合精度和其他学习量化方法。
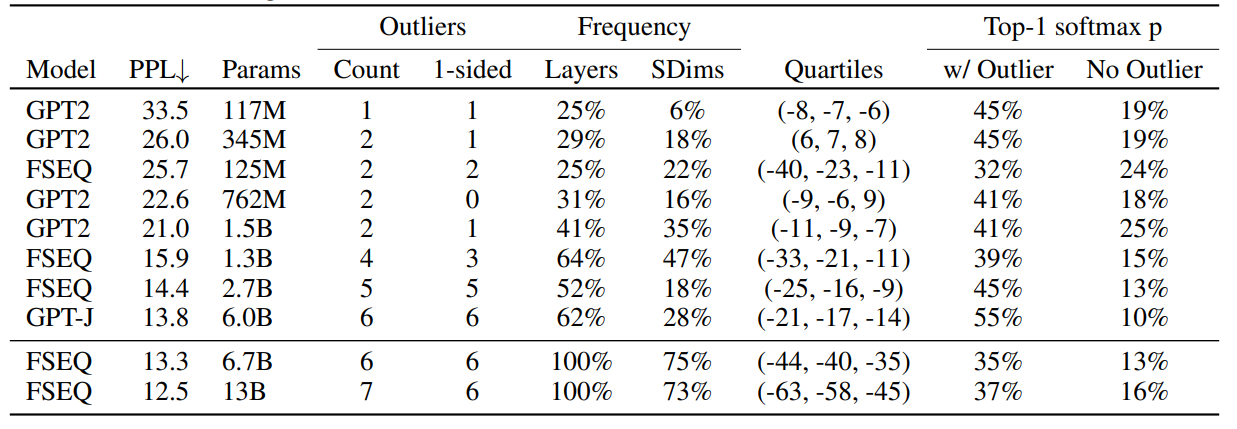
表 4:出现的异常值的统计汇总,这些异常值的幅度至少为 6,并且出现在至少 25% 的所有层和至少 6% 的所有序列维度中。我们可以看到,C4 验证困惑度越低,异常值越多。异常值通常是单侧的,其四分位数的最大范围表明,异常值的幅度比其他特征维度的最大幅度大 3 到 20 倍,其他特征维度的范围通常为 -3.5, 3.5。随着规模的增大,异常值在Transformer的所有层中变得越来越普遍,并且几乎出现在所有序列维度中。当参数量达到 6.7B 时发生了一个相变,即相同的异常值在所有层中出现在同一特征维度中,占所有序列维度的约 75%。尽管异常值仅占所有特征的约 0.1%,但它们对大软最大概率至关重要。如果去除异常值,平均 top-1 软最大概率会缩小约 20%。由于异常值在序列维度 s 上主要是非对称分布,这些异常维度干扰了对称 absmax 量化,并偏向非对称的零点量化。这解释了我们在验证困惑度分析中的结果。这些观察似乎是普遍的,因为它们发生在不同软件框架训练的模型中,并且在不同的推理框架(中也出现。这些异常值对Transformer架构的轻微变化(旋转嵌入、嵌入规范、残差缩放、不同初始化)也表现出一定的鲁棒性。
C 异常值特征详细数据
表 4 提供了我们对异常值特征分析的详细数据。我们列出了每个Transformer中最常见的异常值的四分位数,以及那些单侧异常值的数量,即其分布是非对称的,不经过零点的异常值。
D 推理加速与减速
D.1 矩阵乘法基准测试
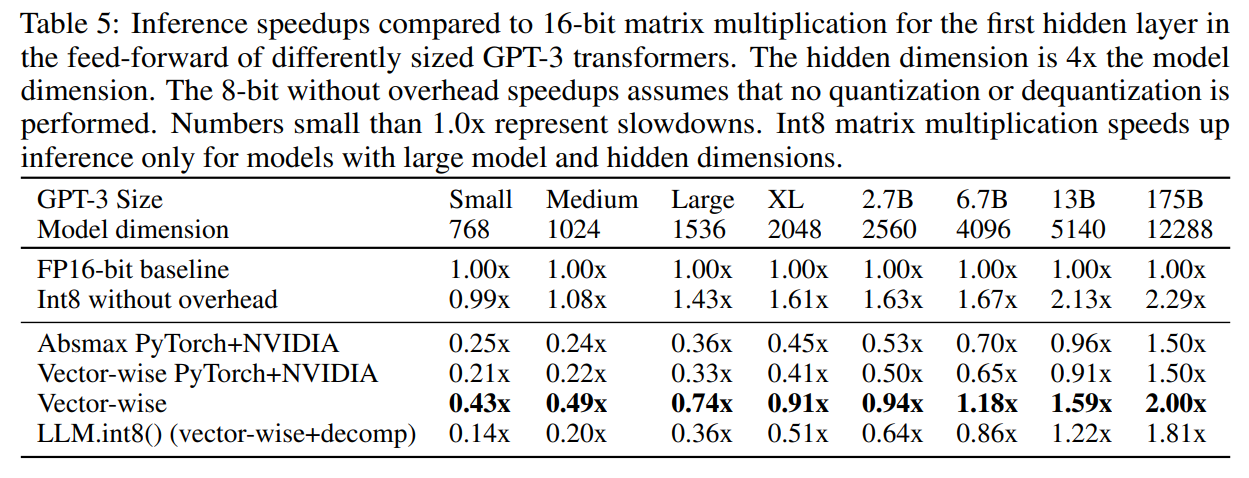
表 5: 不同尺寸的 GPT-3 Transformer的前馈网络中第一个隐藏层的 16 位矩阵乘法与推理加速对比。隐藏维度是模型维度的 4 倍。不考虑开销的 8 位加速比假设未进行量化或反量化。小于 1.0x 的数字表示减速。Int8 矩阵乘法仅在模型和隐藏维度较大的模型中加速推理。
尽管我们的工作重点是内存效率,以使模型可访问,Int8 方法通常也用于加速推理。我们发现,量化和分解的开销是显著的,Int8 矩阵乘法本身仅在整个 GPU 被充分利用时才具有优势,这仅在大规模矩阵乘法中才会发生。这仅在模型维度为 4096 或更大的 LLM 中才会出现。
表 5 展示了原始矩阵乘法和量化开销的详细基准测试。cuBLASLt 中的原始 Int8 矩阵乘法在模型大小为 5140(隐藏尺寸 20560)时开始比 cuBLAS 快两倍。如果输入需要量化且输出需要反量化------如果不是整个Transformer都用 Int8 完成,这是一项严格要求------则与 16 位相比的加速比降至 1.6 倍。模型大小为 2560 或更小的模型会变慢。添加混合精度分解会进一步减慢推理速度,因此只有 13B 和 175B 模型有加速效果。
通过为混合精度分解优化 CUDA 内核,这些数字可以显著提高。然而,我们还发现现有的自定义 CUDA 内核比我们使用的默认 PyTorch 和 NVIDIA 提供的量化内核快得多,这些默认内核会减慢所有矩阵乘法,除了 175B 模型。
D.2 端到端基准测试

表 6: 关于运行不同类型的 BLOOM-176B 模型推理所使用的 GPU 数量的消融研究。我们比较了量化的 BLOOM-176B 模型和原生 BLOOM-176B 模型使用的 GPU 数量。还报告了不同批量大小下每个令牌的生成速度(毫秒)。我们使用集成了 HuggingFace accelerate 库的 transformers中的方法来处理多 GPU 推理。我们的方法通过使用比原生模型更少的 GPU 达到了与原生模型相似的性能。
除了矩阵乘法基准测试,我们还测试了 Hugging Face 中 BLOOM-176B 的端到端推理速度。Hugging Face 使用了具有缓存注意值的优化实现。由于这种推理是分布式的,因此通信依赖性较强,我们预计由于 Int8 推理带来的总体加速和减速会较小,因为整体推理运行时间的大部分是固定的通信开销。
我们与 16 位基准测试进行比较,并尝试使用较大批量大小或较少 GPU 的设置进行 Int8 推理,因为我们可以在较少的设备上容纳更大的模型。在表 6 中可以看到我们的基准测试结果。总体而言,Int8 推理稍微慢一些,但与 16 位推理相比,延迟接近于毫秒级每令牌的速度。
E 训练结果
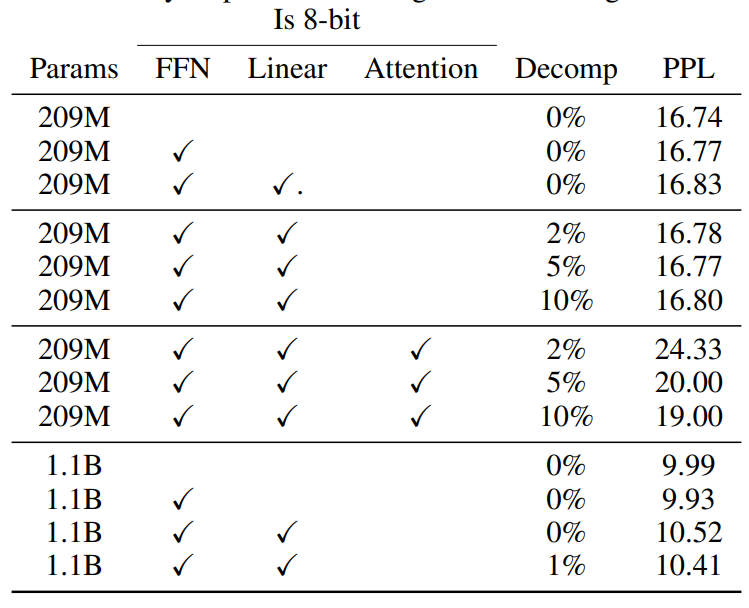
表 7: 小规模和大规模语言建模的初步结果。使用 8 位进行注意力计算会严重影响性能,并且混合精度分解无法完全恢复性能。虽然小规模语言模型对于 8 位 FFN 和 8 位线性投影的注意力层性能接近基准,但在大规模下性能会下降。
在多种训练设置下测试了 Int8 训练,并与 32 位基准进行比较。我们测试了不同的设置,包括使用 8 位前馈网络进行Transformer训练(带有和不带有 8 位线性投影的注意力层),以及 8 位的注意力本身,并与 32 位性能进行比较。我们测试了两个任务:(1) 在部分 RoBERTa 语料库上进行语言建模,包括 Books、CC-News、OpenWebText和 CC-Stories;(2) 在 WMT 14+ WMT16上进行神经机器翻译(NMT)。
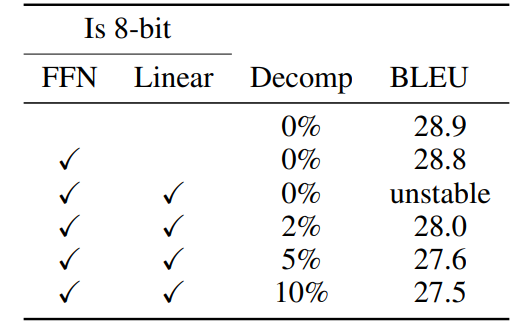
表 8:WMT14+16 上 8 位 FFN 和线性注意力层的神经机器翻译结果。 Decomp表示在 16 位而非 8 位下计算的百分比。BLEU 分数是三次随机种子的中位数。
结果见表 7 和表 8。我们可以看到,对于训练,使用 Int8 数据类型和向量级量化的注意力线性投影会导致 NMT 和 1.1B 语言模型性能下降,但 209M 语言建模则没有受到影响。如果使用混合精度分解,结果会有所改善,但在大多数情况下不足以恢复完整的性能。这表明,使用 8 位 FFN 层进行训练比较简单,而其他层则需要额外的技术或不同于 Int8 的数据类型,以在大规模 8 位训练中避免性能下降。
F 微调结果
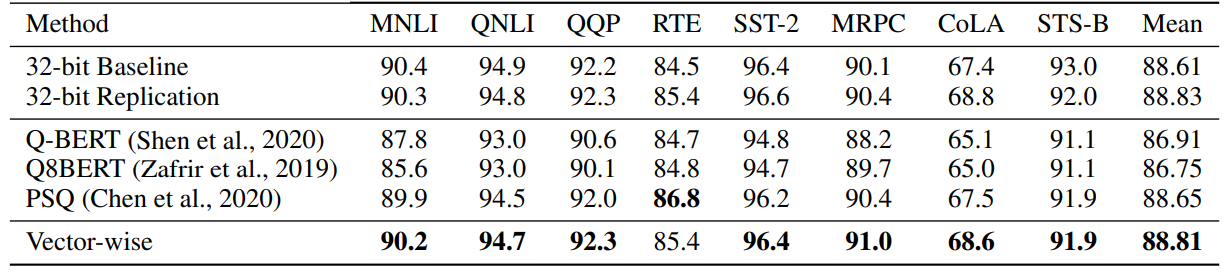
表 9:GLUE 微调结果,针对 8 位前馈层的量化方法,同时其余部分为 16 位。未使用混合精度分解。我们可以看到,向量级量化在基准线之上有所提升。
还在 GLUE 数据集上微调了 8 位 RoBERTa-large。我们运行了两种不同的设置:(1) 与其他 Int8 方法进行比较;(2) 比较 8 位 FFN 层和 8 位注意力投影层的微调性能与 32 位的退化情况。我们使用 5 个随机种子进行微调,并报告中位数性能。
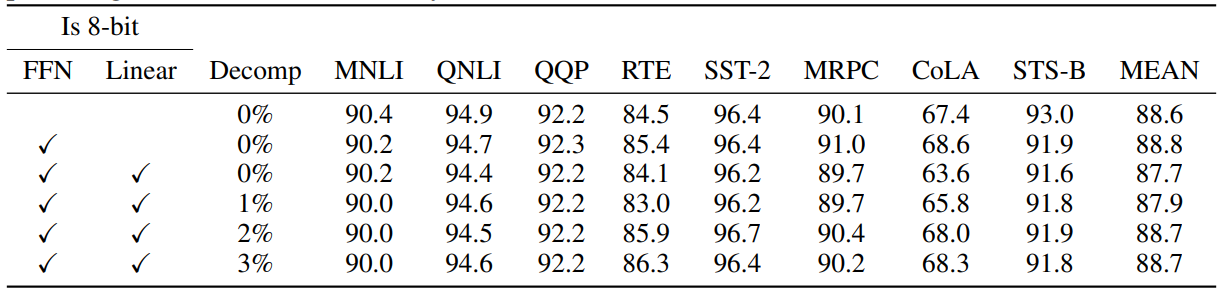
表 10:GLUE 数据集上 8 位前馈网络(FFN)和线性注意力层的详细分析。得分为 5 次随机种子的中位数。Decomp 指示被分解为 16 位矩阵乘法的百分比。与推理相比,如果线性注意力层也转换为 8 位,则微调似乎需要更高的分解百分比。
表 9 比较了与不同的先前 8 位微调方法的结果,并显示向量级量化在其他方法上有所改进。表 10 显示了 8 位 FFN 和/或线性注意力投影层的性能,以及如果使用混合精度分解时的改进情况。我们发现 8 位 FFN 层不会导致性能下降,而 8 位注意力线性投影层会导致性能下降,除非与混合精度分解结合,其中至少 2% 的最大幅度维度使用 16 位计算而不是 8 位。这些结果突显了混合精度分解在微调中的关键作用,以避免性能下降。
总结
⭐ 作者开发了一个两部分量化程序LLM.int8()。首先使用向量级量化,对矩阵乘法中的每个内积使用单独的归一化常数,从而对大多数特征进行量化。然而,对于突现的异常值(outlier),还包括了一种新的混合精度分解方案,将异常特征维度隔离到16位矩阵乘法中,同时仍然有99.9%以上的值在8位中进行乘法运算。