标记压缩通过减少冗余标记的数量(例如,修剪不重要的标记或合并相似的标记)来加快视觉变换器(
ViTs)的训练和推理。然而,当这些方法应用于下游任务时,如果训练和推理阶段的压缩程度不匹配,会导致显著的性能下降,这限制了标记压缩在现成训练模型上的应用。因此提出了标记补偿器(ToCom),以解耦两个阶段之间的压缩程度。该插件通过在预训练模型上额外执行了一个快速参数高效的自蒸馏阶段获得一个小型插件,描述了不同压缩程度下模型之间的差距。在推理过程中,ToCom可以直接插入到任何下游现成模型中,无论训练和推理的压缩程度是否匹配,都能获得通用的性能提升,而无需进一步训练。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Token Compensator: Altering Inference Cost of Vision Transformer without Re-Tuning

Introduction
视觉变换器(ViTs)在计算机视觉的多个领域取得了显著成功,包括图像分类、目标检测、语义分割等。然而,随着ViTs规模的快速增长,计算成本的增加已成为一个迫切问题。因此,大量研究工作集中在加速ViTs的训练和推理上。ViTs的特点在于能够处理可变数量的输入标记,除了卷积神经网络中广泛使用的传统技术,如模型剪枝、量化和蒸馏,近期的研究通过标记压缩来加速ViTs,例如修剪不重要的标记或合并相似的标记。
与剪枝和蒸馏等技术相比,标记压缩技术具有明显的优势。一些标记压缩方法(例如,ToMe)可以以零样本的方式应用于现成模型或用于加速训练。与量化不同,标记压缩方法不需要对低精度操作符的支持。此外,标记压缩方法与上述其他技术在操作上是正交的,使其在ViTs中具有广泛的适用性。
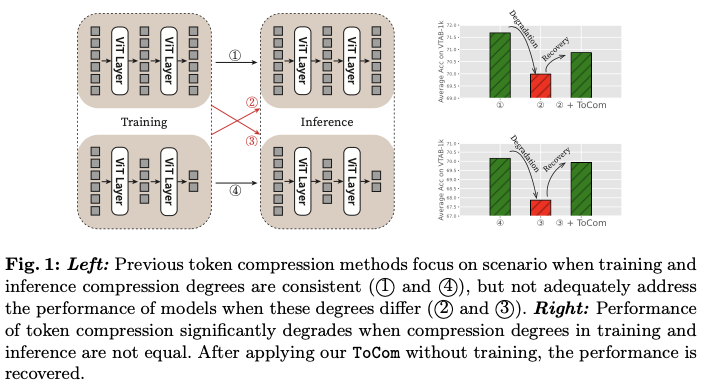
然而,当标记压缩应用于下游任务时,论文观察到如图1所示的以下缺点:
- 尽管一些标记压缩技术可以应用于现成模型,但通常会导致显著的性能下降。
- 即使标记压缩仅在训练期间应用以加速过程,而在推理期间不进行压缩,模型的性能仍然低于未经标记压缩训练的模型。
- 总之,当训练和推理阶段的标记压缩程度不一致时,模型的性能表现不佳。
论文指出,经过不同标记压缩程度微调的模型在参数层面存在一定的差距,这导致在推理过程中改变压缩程度时性能下降。此外,这一差距可以在不同的下游数据集之间转移。基于此,论文提出标记补偿器(Token Compensator,简称ToCom),这是一种旨在解耦训练和推理过程中的标记压缩程度的预训练插件。ToCom是一个参数高效的模块,仅包含少量参数,用于描述具有不同压缩程度的模型之间的差距。为了获得ToCom,在预训练数据集上通过不同压缩程度之间的快速自蒸馏过程进行训练。具体来说,教师模型和学生模型都是相同的冻结预训练模型,其中学生模型包括ToCom。在每一步中,教师模型和学生模型被随机分配不同的压缩程度,同时ToCom通过蒸馏学习它们之间的差距。此外,为不同的压缩程度设置分配不同ToCom参数的子集,使ToCom能够通过单一的训练过程适应各种压缩程度对。
在推理过程中,将ToCom直接集成到在下游任务上进行微调的现成模型中,而无需进一步训练。通过选择ToCom参数的子集,微调后的模型可以直接应用于各种标记压缩程度,并达到与训练和推理压缩程度一致时相当的性能。重要的是,ToCom只需预训练一次,即可应用于在任意下游数据集上经过微调的模型,不论其标记压缩程度如何,从而使任何单一的现成模型能够处理动态延迟约束,而无需修改参数。
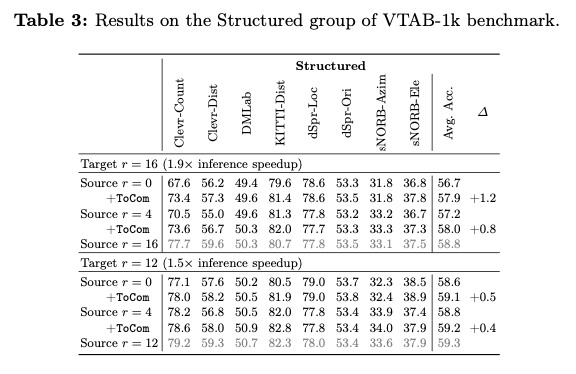
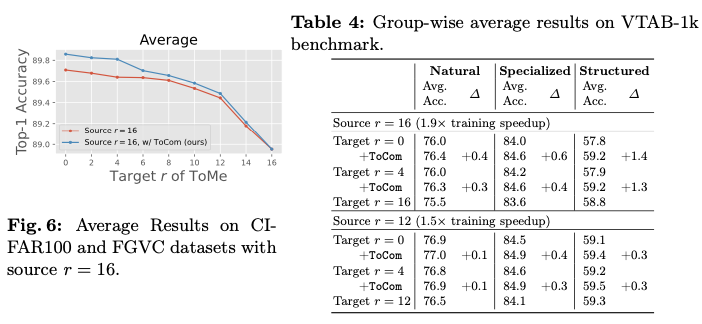
论文在超过20个数据集上进行了实验,涵盖了各种压缩程度设置。实验结果表明,ToCom作为一个即插即用的模块,能够有效地解耦训练和推理过程中的标记压缩程度。例如,在VTAB-1k基准测试中,ToCom在DeiT-B的平均性能上比ToMe最高可提升2.0%,如图1所示。ToCom还可以应用于不同规模的模型或在不同对象上预训练的模型,或者用于增强各种标记压缩方法,包括标记合并和标记剪枝。
Delve into Token Compression
Impact of Compression Degrees
首先,对ViTs中的标记压缩方法进行公式化。ViTs的单层由两个模块组成,即多头自注意力(MHSA)和多层感知机(MLP)。该层可以被形式化为
\\\begin{equation} \\widetilde{\\mathbf{X}}\^l=\\mathbf{X}\^l+\\textrm{MHSA}(\\textrm{LN}(\\mathbf{X}\^l)), \\quad \\mathbf{X}\^{l+1}=\\widetilde{\\mathbf{X}}\^l+\\textrm{MLP}(\\textrm{LN}(\\widetilde{\\mathbf{X}}\^l)), \\end{equation} \\
其中, \(\mathbf{X}^l \in \mathbb{R}^{N \times d}\) 是第 \(l\) 层的输入,具有长度 \(N\) 和维度 \(d\) ,LN表示层归一化。
论文主要关注一种具有代表性且最先进的无训练标记压缩方法ToMe,并进一步推广到其他方法。ToMe在MHSA和MLP模块之间操作,利用图像块标记的键来评估它们的相似性,并通过二分软匹配将 \(r\) 个相似的标记进行合并。
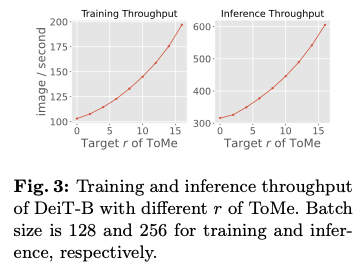
在ToMe中,每层合并的标记数量被视为超参数,以调整ViTs的吞吐量,这通常在训练之前根据推理需求来确定。合并的标记越多,模型在训练和推理时的速度就越快,如图3所示。然而,在实际场景中,训练期间的压缩程度(称为源压缩程度)和推理期间的压缩程度(称为目标压缩程度)可能不一定相等。也就是说,一个在某一压缩程度下训练好的现成模型,可能会在没重新训练的情况下进行不同的压缩程度下的应用。这种情况具有实际意义,例如,使用下载的checkpoint而无法访问训练数据或重新训练资源时,或根据服务器负载动态调整推理期间的压缩程度。此外,在现有计算资源有限的情况下,可能需要在训练期间使用较高的压缩程度以减少内存和时间开销,但在推理期间恢复到较低的压缩程度以确保性能。
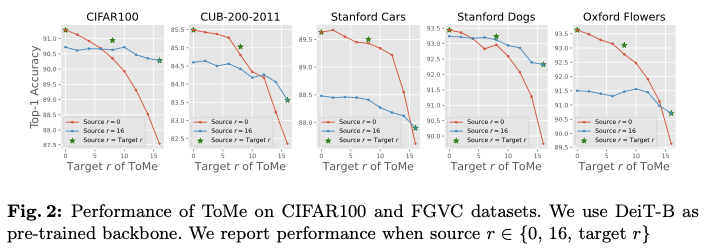
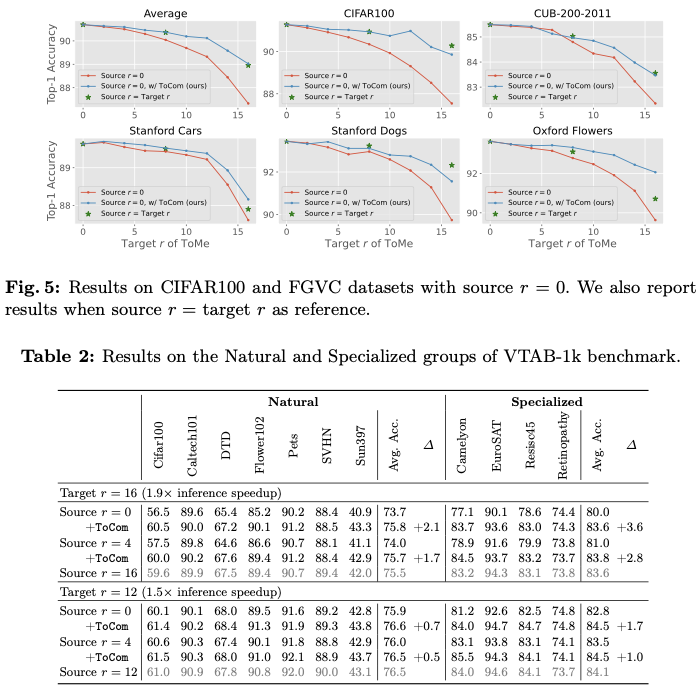
为了研究标记压缩方法在源压缩程度与目标压缩程度不一致时的性能,论文在五个下游数据集上进行了实验。如图2所示,论文对DeiT-B进行了ToMe的 \(r=0\) 和 \(16\) 的微调,并报告了在推理期间使用 \(r=0, 2, 4, \ldots, 16\) 的性能。可以看到,对于特定的目标压缩程度,当源压缩程度与其匹配时,模型的表现更好。源压缩程度与目标压缩程度之间的差距越大,性能下降的程度就越显著。
然而,由于在较低压缩程度下训练的模型在训练期间接触到了更多的标记,这意味着它们遇到的信息范围比在较高压缩程度下训练的模型更广泛,因此,前者在各种目标压缩程度下理应优于后者。这表明,不同源压缩程度下训练的模型之间存在差距,使得在不同压缩程度之间的迁移效果较差。
Transfer across Tasks
对于具有不同源压缩程度的模型之间的差距,是否可以在不同任务之间转移?更具体地说,令 \(\mathcal{M}m^{\mathcal{D_A}}\) 和 \(\mathcal{M}{n}^{\mathcal{D_A}}\) 表示在数据集 \(\mathcal{D_A}\) 上以压缩程度 \(m\) 和 \(n\) 训练的模型, \(\mathcal{M}m^{\mathcal{D_B}}\) 和 \(\mathcal{M}{n}^{\mathcal{D_B}}\) 表示在数据集 \(\mathcal{D_B}\) 上训练的模型。如果这种差距是可转移的,应该有
\\\begin{equation} \\mathcal{M}_{m}\^{\\mathcal{D_A}} - \\mathcal{M}_n\^{\\mathcal{D_A}} \\approx \\mathcal{M}_{m}\^{\\mathcal{D_B}} - \\mathcal{M}_n\^{\\mathcal{D_B}}, \\label{eq:transfer} \\end{equation} \\
其中 \(+\) 和 \(-\) 分别是逐元素的加法和减法。为了验证这一点,将公式重新写为
\\\begin{equation} \\mathcal{M}_{m}\^{\\mathcal{D_A}} - \\mathcal{M}_n\^{\\mathcal{D_A}} + \\mathcal{M}_n\^{\\mathcal{D_B}} \\approx \\mathcal{M}_{m}\^{\\mathcal{D_B}}, \\label{eq:transfer2} \\end{equation} \\
这意味着 \((\mathcal{M}_{m}^{\mathcal{D_A}} - \mathcal{M}_n^{\mathcal{D_A}} + \mathcal{M}_n^{\mathcal{D_B}})\) 在以目标压缩程度 \(m\) 对数据集 \(\mathcal{D_B}\) 进行评估时,应当比 \(\mathcal{M}n^{\mathcal{D_B}}\) 的表现更好。换句话说, \((\mathcal{M}{m}^{\mathcal{D_A}} - \mathcal{M}n^{\mathcal{D_A}})\) 在数据集 \(\mathcal{D_A}\) 上的差距可以转移到 \(\mathcal{D_B}\) ,并有助于缩小 \(\mathcal{M}{m}^{\mathcal{D_B}}\) 和 \(\mathcal{M}_n^{\mathcal{D_B}}\) 之间的差距。
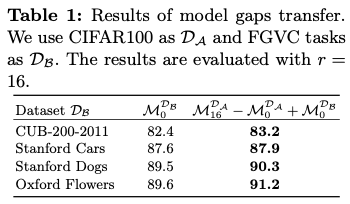
在ToMe上进行初步实验,使用CIFAR100作为 \(\mathcal{D_A}\) , \(m=16\) , \(n=0\) 。在表1中,展示了使用不同FGVC数据集作为 \(\mathcal{D_B}\) 时的结果。通过添加 \((\mathcal{M}_{16}^{\mathcal{D_A}} - \mathcal{M}_0^{\mathcal{D_A}})\) , \(\mathcal{M}_0^{\mathcal{D_B}}\) 在 \(r=16\) 下的表现明显提高,验证了在不同任务中存在源压缩程度之间的模型差距的正向迁移,这表明可以使用通用插件来建模这种差距,从而在各种下游任务中提高具有不等源和目标压缩程度的标记压缩性能。
Token Compensator
Arithmetic of Parameter-Efficient Modules
当训练和推理过程中的压缩程度不相等时,由于不同压缩程度的模型在行为上存在差异,导致其参数空间中出现不同的局部最小值,从而使模型性能下降。为了在这种情况下提升标记压缩的性能,尤其是在现成模型上,论文打算寻找一个通用插件以弥补具有不同压缩程度的模型之间的差距,假设两个特定压缩程度的模型在不同数据集上表现出类似的差距。假设有一个插件 \(\mathcal{P}_{m\rightarrow n}\) ,可以弥补在ToMe训练下的模型 \(\mathcal{M}m\) (压缩程度 \(r=m\) )和模型 \(\mathcal{M}{n}\) (压缩程度 \(r=n\) )之间的差距。如果 \(\mathcal{M}_m\) 是现成模型,可以期望
\\\begin{equation} \\mathcal{M}_m \\oplus \\mathcal{P}_{m\\rightarrow n} = \\mathcal{M}'_n \\approx \\mathcal{M}_n, \\label{eq:plugin} \\end{equation} \\
其中 \(\oplus\) 表示架构层面的聚合, \(\mathcal{M}'_n\) 是用于以 \(r=n\) 进行推理的合成模型。
然而,由于压缩程度选择的范围广(例如,DeiT-B在ToMe中的 \(r \in \{0, 1, ..., 16\}\) ),为所有可能的压缩程度对(即 \(16\times17\) 种 \((m,n)\) 组合)训练和存储这些插件会导致显著的训练和存储开销。为此,论文从三个方面解决这个问题。
首先,受到参数高效微调的启发,该方法使用轻量级模块来描述预训练模型与微调模型之间的差距,论文也采用了参数高效模块来描述具有不同压缩程度的模型之间的差距。具体来说,使用LoRA作为 \(\mathcal{P}_{m\rightarrow n}\) ,即对 \(\mathcal{M}'_n\) 的所有权重矩阵 \(\mathbf{W}\in\mathbb{R}^{d_1\times d_2}\) ,有
\\\begin{equation} \\begin{cases} \\mathbf{W}_{\\mathcal{M}'_n} = \\mathbf{W}_{\\mathcal{M}_m} + s\\cdot\\mathbf{A}\\mathbf{B},\\quad\&\\textit{if}\\ \\mathbf{W} \\in\\{\\mathbf{W}_q,\\mathbf{W}_v\\},\\\\ \\mathbf{W}_{\\mathcal{M}'_n} = \\mathbf{W}_{\\mathcal{M}_m}, \\quad\&\\textit{otherwise}, \\end{cases} \\end{equation} \\
其中, \(\mathbf{W}_q\) 和 \(\mathbf{W}_v\) 是查询和值变换的权重矩阵, \(s\) 是一个超参数, \(\mathbf{A}\in\mathbb{R}^{d_1\times h}\) 和 \(\mathbf{B}\in\mathbb{R}^{h\times d_2}\) 是LoRA模块。LoRA模块仅占模型参数的约0.1%,并且在推理时不会增加额外的计算。
其次,使用LoRA来估计仅相邻压缩程度之间的差距,即 \(n=m+1\) 。对于 \(n>m+1\) 的情况,简单地累积 \(m\) 和 \(n\) 之间的所有插件,即
\\\begin{equation} \\mathcal{M}_m \\oplus \\left( \\bigoplus_{i=m}\^{n-1}\\mathcal{P}_{i\\rightarrow i+1}\\right) = \\mathcal{M}'_n \\approx \\mathcal{M}_n. \\label{eq:plus} \\end{equation} \\
第三,假设模型之间的差距是可逆的,即 \(\mathcal{P}{n\rightarrow m}=\ominus \mathcal{P}{m\rightarrow n}\) 。当 \(n<m\) 时,插件被"减去",即
\\\begin{equation} \\mathcal{M}_m \\ominus \\left( \\bigoplus_{i=n}\^{m-1}\\mathcal{P}_{i\\rightarrow i+1}\\right) = \\mathcal{M}'_n \\approx \\mathcal{M}_n, \\label{eq:minus} \\end{equation} \\
其中, \(\ominus\) 是 \(\oplus\) 的逆运算。为了实现 \(\ominus\) ,我们从权重中减去LoRA乘积 \(\mathbf{A}\mathbf{B}\) ,而不是加上它。
现在,只需训练和存储16组LoRA插件,以支持所有压缩程度对,这些插件的大小仍然相对于ViT主干来说微不足道,这些插件的集合称为Token Compensator(ToCom)。由于ToCom的轻量特性,它可以以最小的开销加载到RAM中,从而实现实时推理吞吐量切换。
Training ToCom
如前所述,ToCom应该是一个适用于任何下游数据集的通用插件。为了增强ToCom的泛化能力,将ToCom的训练整合为ViT主干的预训练阶段的扩展。具体而言,利用预训练数据(例如ImageNet)来训练ToCom。

为了获得支持任意压缩程度对的ToCom,论文提出了一种自蒸馏方法来训练它。以ToMe为例,使用 \(\widehat{\mathcal{M}}_n\) 来表示通过在现成的预训练模型上直接应用ToMe( \(r=n\) )得到的模型。训练损失的构造如下,
\\\begin{equation} \\mathcal{L} = \\begin{cases} \\mathcal{L}_{KD}\\left(\\widehat{\\mathcal{M}}_m \\oplus \\left( \\bigoplus_{i=m}\^{n-1}\\mathcal{P}_{i\\rightarrow (i+1)}\\right), \\widehat{\\mathcal{M}}_n\\right),\&\\textit{if}\\ n \> m \\\\ \\mathcal{L}_{KD}\\left(\\widehat{\\mathcal{M}}_m \\ominus \\left( \\bigoplus_{i=n}\^{m-1}\\mathcal{P}_{i\\rightarrow (i+1)}\\right), \\widehat{\\mathcal{M}}_n\\right),\&\\textit{if}\\ n \< m \\end{cases} \\end{equation} \\
其中 \(m\) 和 \(n\) 在每次训练步骤中随机抽取,且满足 \(m \neq n\) , \(\mathcal{L}_{KD}\) 是带有软目标的知识蒸馏损失,即,
\\\begin{equation} \\mathcal{L}_{KD}(\\mathcal{M}_{s}, \\mathcal{M}_{t})=\\textrm{KL}(\\mathcal{M}_{s}(\\boldsymbol{x}), \\mathcal{M}_{t}(\\boldsymbol{x})), \\end{equation} \\
其中 \(\textrm{KL}\) 表示Kullback--Leibler散度, \(\boldsymbol{x}\) 是输入。
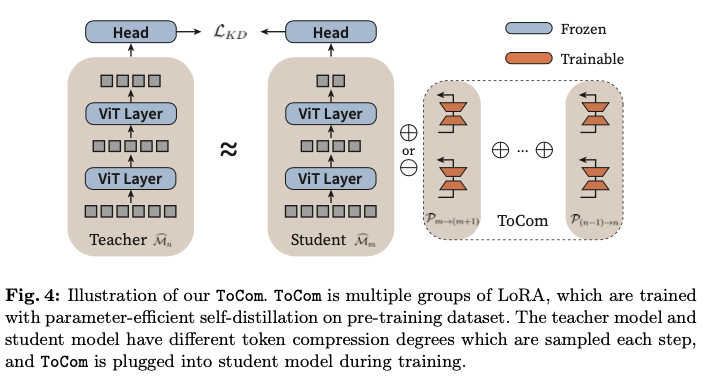
如图4所示,在蒸馏过程中,冻结所有预训练的参数,包括分类头,只更新参数高效的ToCom。值得注意的是,虽然ToCom需要在大规模数据集上进行训练,但它的模型较轻量且收敛迅速。因此,与主干网络的预训练相比,它的训练开销可以忽略不计。
在训练完成ToCom后,可以直接将其部署到任何在下游任务上微调的现成模型上,进行任何源度数到目标度数的转换。将ToCom的LoRA产物加到或减去现成模型的权重上,用于推理而无需进一步训练。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
