JVM 虚拟机的编译器
编译器可以分为:前端编译器、JIT 编译器、AOT编译器。

前端编译器:源代码 --> 字节码
在Java语言中,JDK安装目录中的javac就是编译器。它负责将Java源代码编译为字节码。因为处于编译的前期,javac也叫做前端编译器。
JIT 编译器:字节码 --> 机器码
即时编译器(Just-In-Time Compiler,JIT)
Java源代码转化为 字节码之后,要运行它,有两种选择:
- 使用 Java 解释器,执行字节码。
- 使用 JIT(Just-In-Time Compiler) 编译器 将字节码 转化为 机器码。
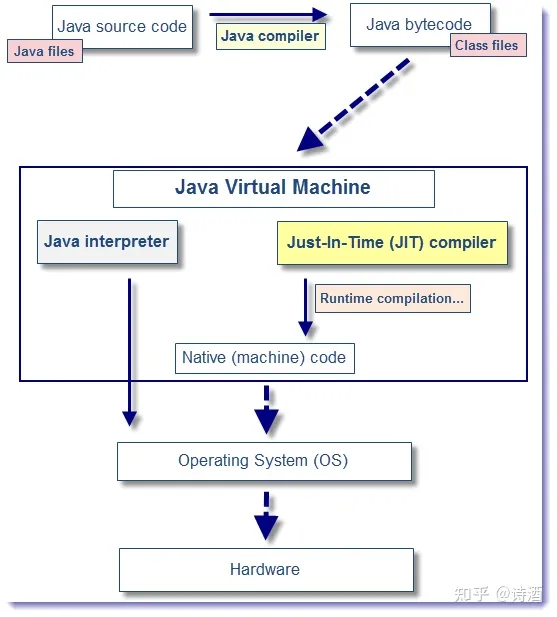
JIT 编译器在程序运行时,对频繁执行的字节码进行即时编译,将其转换为本地机器码,从而提高程序的执行效率。
HotSpot 虚拟机的两个即时编译器
在 HotSpot 虚拟机内置了两个即时编译器,分别称为 Client Compiler 和 Server Compiler 。这两种不同的编译器衍生出两种不同的编译模式,我们分别称之为:C1 编译模式 ,C2 编译模式。
- C1 编译模式会将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。
- C2 编译模式,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
AOT 编译器:源代码 --> 机器码
提前编译器(Ahead-of-Time Compiler,AOT)
AOT 编译器的基本思想是:在程序执行前生成 Java 方法的本地代码,以便在程序运行时直接使用本地代码。
HotSpot 虚拟机的三种运行模式
注意,对于 HotSpot 虚拟机来说,其一共有三种运行模式可选,分别是:
- 混合模式 (Mixed Mode) 。即 C1 和 C2 两种模式混合起来使用,这是默认的运行模式。如果你想单独使用 C1 模式或 C2 模式,使用
-client或-server打开即可。 - 解释模式 (Interpreted Mode)。即所有代码都解释执行,使用
-Xint参数可以打开这个模式。 - 编译模式(Compiled Mode)。 此模式优先采用编译,但是无法编译时也会解释执行,使用 -Xcomp 打开这种模式。
在命令行中输入 java -version 可以看到,我机器上的虚拟机使用 Mixed Mode 运行模式。

JVM 虚拟机类加载过程
Java 中的类加载过程分为:加载(Loading) 、链接(Linking) 、初始化(Initialization) 。

-
加载(Loading) :阶段的目的是将类的
.class文件加载到JVM中。在这个阶段,JVM 会根据类的全限定名来获取定义该类的二进制字节流,并将这个字节流所代表的静态存储结构 转化为方法区的运行时数据结构。 -
链接(Linking) :又分为 ++验证(Verification)++ 、++准备(Prepartion)++ 、++解析(Resolution)++。
- 验证 :校验类的正确性,包括:
- 文件格式验证:验证字节流是否符合Class文件格式的规范。比如,是否以
0xCAFEBABE开头。 - 元数据验证:对字节码描述进行语义分析,是否遵循Java规范。比如一个类是否继承了多个类。
- 字节码验证:比如验证指令代码序列是否能够正常工作。
- 符号引用验证:确保解析动作能够正确执行。
- 文件格式验证:验证字节流是否符合Class文件格式的规范。比如,是否以
- 准备 :给 类中定义的变量(被
static修饰的静态变量)分配内存,并设置初始值。 - 解析:虚拟机将 常量池 内的 符号引用 替换为 直接引用。(解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行)
- 验证 :校验类的正确性,包括:
-
初始化(Initialization) :初始化阶段是执行初始化方法
<clinit>()方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的 Java 程序代码(字节码)。对于初始化阶段,有些情况必须立即初始化(如下)。其他情况,则是进行懒加载(首次用到的时候才初始化)
- 遇到
new、getstatic、putstatic或invokestatic这四条字节码指令时,会立即初始化。 - 使用反射机制时,立即初始化。
- 初始化一个类时,其父类没初始化,则会立即初始化父类。
- 遇到
-
卸载(Unloading):对象被垃圾回收。
类加载器
类加载器 主要作用于 JVM 虚拟机类加载过程中的 加载阶段。
如何比较两个类是否"相等"
对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性。所以:比较两个类是否"相等",只有在这两个类是由同一个类加载器加载的前提下才有意义 ,否则,即使这两个类来源于同一个 Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
双亲委派机制
站在JAVA虚拟机的角度来讲,只存在两种不同的类加载器:
- 一种是启动类加载器(
Bootstrap ClassLoader) ,这个类加载器使用C++语言实现,++是虚拟机自身的一部分++; - 另外一种就是其他所有的类加载器,++这些类加载器都由Java语言实现++ ,独立存在于虚拟机外部,并且全都继承自抽象类
java.lang.ClassLoader。
每一个类都有一个对应它的类加载器。系统中的 ClassLoader 在协同工作的时候会默认使用 双亲委派模型。其工作过程为:
- 当一个类加载器收到了类加载的请求,不会自己去加载这个类,而是委派给父类加载器完成。
- 只有当父类加载器无法完成这个加载请求时(它搜索范围中没找到对应的类信息),子加载器才会尝试自己去完成加载。

父类加载器
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。
三层类加载器
双亲委派机制中的主要的三层类加载器,他们分别是:启动类加载器、扩展类加载器、应用程序类加载器。
- BootstrapClassLoader(启动类加载器) :最顶层的加载类,由 C++实现,负责加载
%JAVA_HOME%/lib目录下的jar包和类,或者被-Xbootclasspath参数指定的路径中的所有类。 - ExtensionClassLoader(扩展类加载器) :主要负责加载
%JRE_HOME%/lib/ext目录下的jar包和类,或被java.ext.dirs系统变量所指定的路径下的jar包。 - AppClassLoader(应用程序类加载器) :面向我们用户的加载器,负责加载当前应用
classpath下的所有 jar 包和类。
双亲委派机制的好处
双亲委派模型保证了 Java 程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类)。
如何破坏双亲委派机制
答:有如下几种方法:
-
通过自定义类加载器,重写
loadClass()方法,可以改变这种默认的加载顺序,从而破坏双亲委派机制。比如,可以先尝试从自己指定的路径去加载类,如果找不到再调用父类的
loadClass方法。 -
线程上下文类加载器:当 JVM 需要加载类且当前类加载器无法完成时,会尝试使用线程上下文类加载器,从而绕过双亲委派机制从特定类加载器加载类。
线程上下文类加载器
在双亲委托模型下,类的加载是由下至上的,即下层的类加载器会委托上层进行加载。
但对于SPI来说,有些接口是Java核心库所提供的,而Java核心库是由启动类加载器来加载的,而这些接口的实现却来自不同的Jar包(厂商提供JDBC的实现有Oracle,MySQL等), Java的启动类加载器不会加载其他来源的jar包,这样传统的双亲委托模型就无法满足SPI的要求 。而通过给当前线程设置上下文类加载器,就可以由设置的上下文类加载器来实现对于接口实现类的加载。
SPI(Service Provider Interface)即服务提供者接口。
- SPI 是一种用于实现框架扩展和插件化的机制。它定义了一组接口,允许第三方为这些接口提供具体的实现。
- 例如,Java 的数据库连接(JDBC)就是一个典型的 SPI 应用。JDBC 定义了一组用于与数据库进行交互的接口,而不同的数据库厂商提供了各自的实现。