一、Java对象结构
实例化一个Java对象之后,该对象在内存中的结构是怎么样的?Java对象(Object实例)结构包括三部分:对象头、对象体和对齐字节,具体下图所示
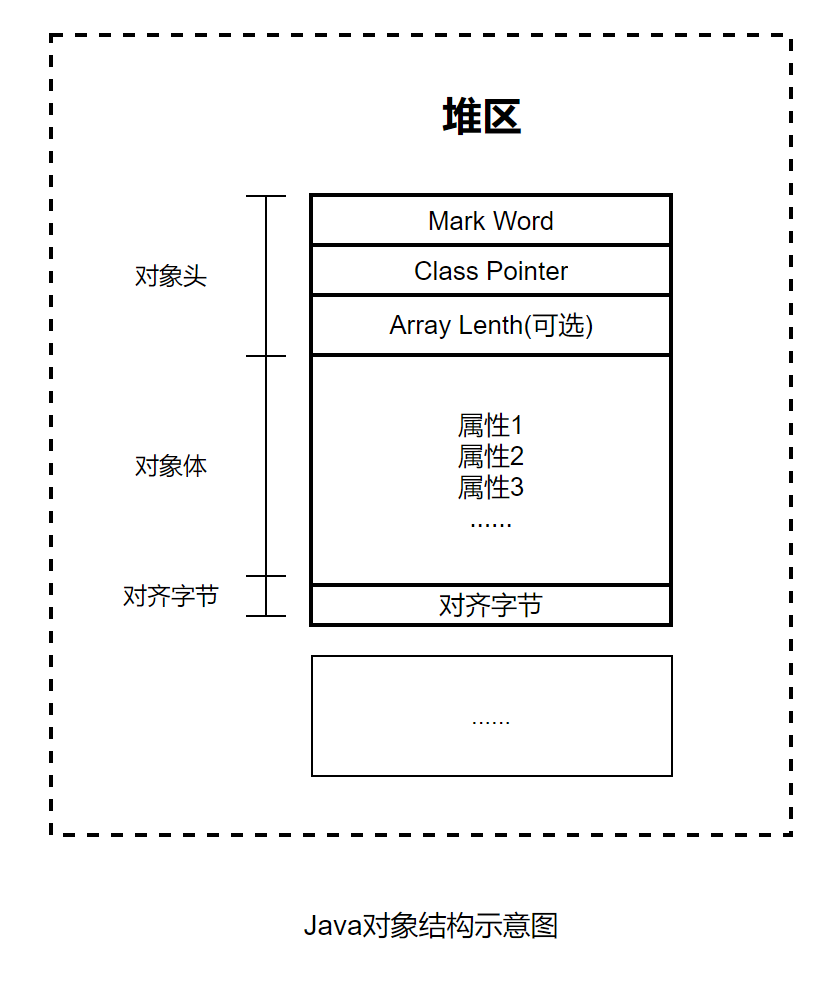
1、Java对象的三部分
(1)对象头
对象头包括三个字段,第一个字段叫作Mark Word(标记字),用于存储自身运行时的数据,例如GC标志位、哈希码、锁状态等信息。
第二个字段叫作Class Pointer(类对象指针),用于存放方法区Class对象的地址,虚拟机通过这个指针来确定这个对象是哪个类的实例。
第三个字段叫作Array Length(数组长度)。如果对象是一个Java数组,那么此字段必须有,用于记录数组长度的数据;如果对象不是一个Java数组,那么此字段不存在,所以这是一个可选字段。
(2)对象体
对象体包含对象的实例变量(成员变量),用于成员属性值,包括父类的成员属性值。这部分内存按4字节对齐。
(3)对齐字节
对齐字节也叫作填充对齐,其作用是用来保证Java对象所占内存字节数为8的倍数HotSpot VM的内存管理要求对象起始地址必须是8字节的整数倍。对象头本身是8的倍数,当对象的实例变量数据不是8的倍数时,便需要填充数据来保证8字节的对齐。
2、Mark Word的结构信息
Mark Word是对象头中的第一部分,Java内置锁有很多重要的信息都存在这里。Mark Word的位长度为JVM的一个Word大小,也就是说32位JVM的Mark Word为32位,64位JVM为64位。Mark Word的位长度不会受到Oop对象指针压缩选项的影响。
Java内置锁的状态总共有4种,级别由低到高依次为:无锁、偏向锁、轻量级锁和重量级锁。其实在JDK 1.6之前,Java内置锁还是一个重量级锁,是一个效率比较低下的锁,在JDK 1.6之后,JVM为了提高锁的获取与释放效率,对synchronized的实现进行了优化,引入了偏向锁和轻量级锁,从此以后Java内置锁的状态就有了4种(无锁、偏向锁、轻量级锁和重量级锁),并且4种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级,也就是说只能进行锁升级(从低级别到高级别)。以下是64位的Mark Word在不同的锁状态下的结构信息:
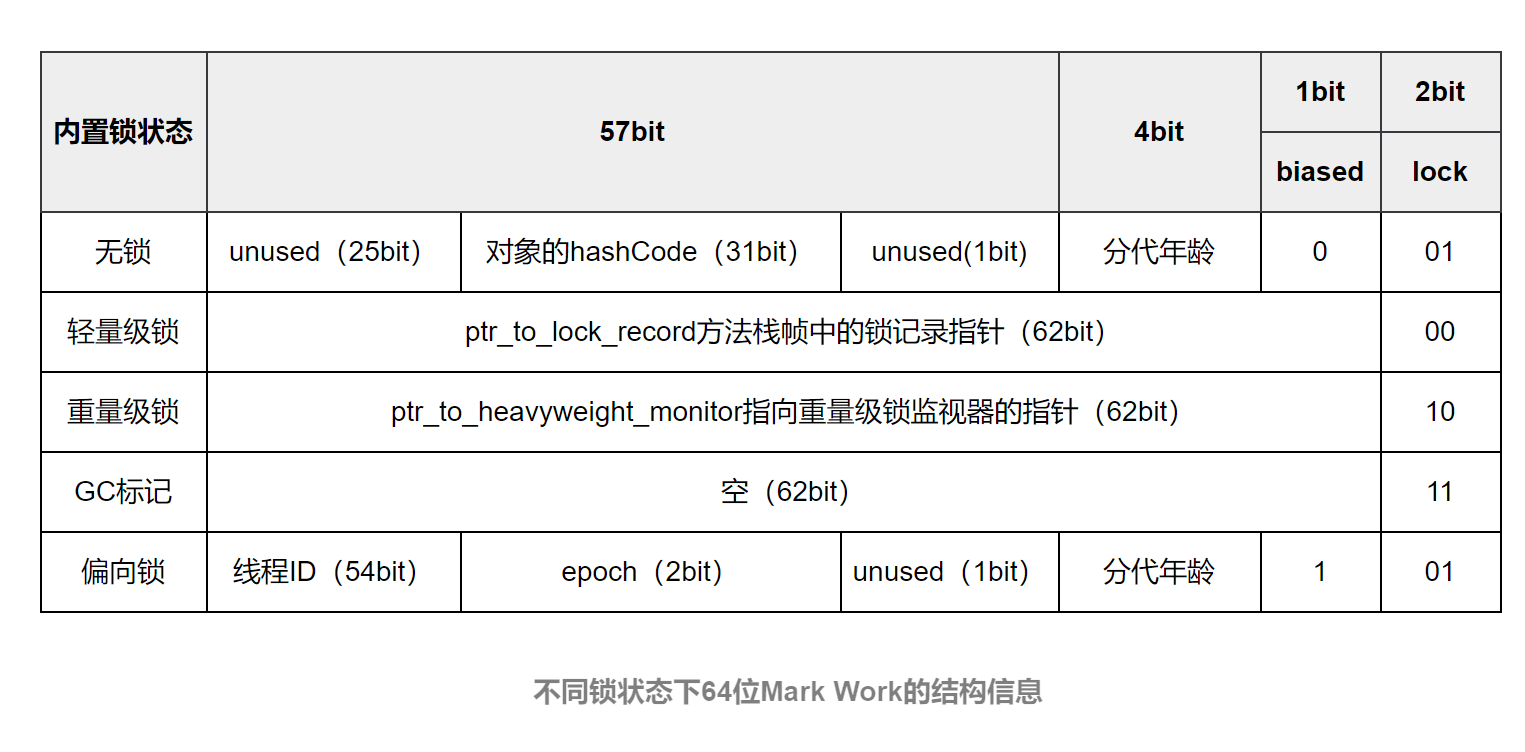
由于目前主流的JVM都是64位,因此我们使用64位的Mark Word。接下来对64位的Mark Word中各部分的内容进行具体介绍。
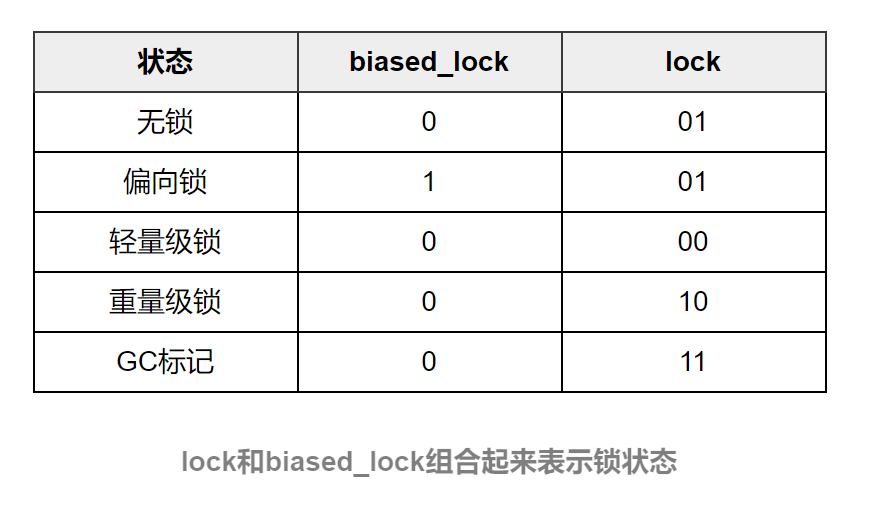
(1)lock:锁状态标记位,占两个二进制位,由于希望用尽可能少的二进制位表示尽可能多的信息,因此设置了lock标记。该标记的值不同,整个Mark Word表示的含义就不同。
(2)biased_lock:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。
lock和biased_lock两个标记位组合在一起共同表示Object实例处于什么样的锁状态。二者组合的含义具体如下表所示
(3)age:4位的Java对象分代年龄。在GC中,对象在Survivor区复制一次,年龄就增加1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。由于age只有4位,因此最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
(4)identity_hashcode:31位的对象标识HashCode(哈希码)采用延迟加载技术,当调用Object.hashCode()方法或者System.identityHashCode()方法计算对象的HashCode后,其结果将被写到该对象头中。当对象被锁定时,该值会移动到Monitor(监视器)中。
(5)thread:54位的线程ID值为持有偏向锁的线程ID。
(6)epoch:偏向时间戳。
(7)ptr_to_lock_record:占62位,在轻量级锁的状态下指向栈帧中锁记录的指针。
二、使用JOL工具查看对象的布局
1、JOL工具的使用
JOL工具是一个jar包,使用它提供的工具类可以轻松解析出运行时java对象在内存中的结构,使用时首先需要引入maven GAV信息
xml
<!--Java Object Layout -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>当前最新版本是0.17版本,据观察,它和0.15之前(不包含0.15)的版本输出信息差异比较大,而普遍现在使用的版本都比较低,但是不妨碍在这里使用该工具做实验。
jol-core 常用的几个方法
ClassLayout.parseInstance(object).toPrintable():查看对象内部信息.GraphLayout.parseInstance(object).toPrintable():查看对象外部信息,包括引用的对象.GraphLayout.parseInstance(object).totalSize():查看对象总大小.VM.current().details():输出当前虚拟机信息
首先创建一个简单的类Hello
java
public class Hello {
private Integer a = 1;
}接下来写一个启动类测试下
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info(VM.current().details());
Hello hello = new Hello();
log.info("hello obj status:{}", ClassLayout.parseInstance(hello).toPrintable());
}
}输出结果:
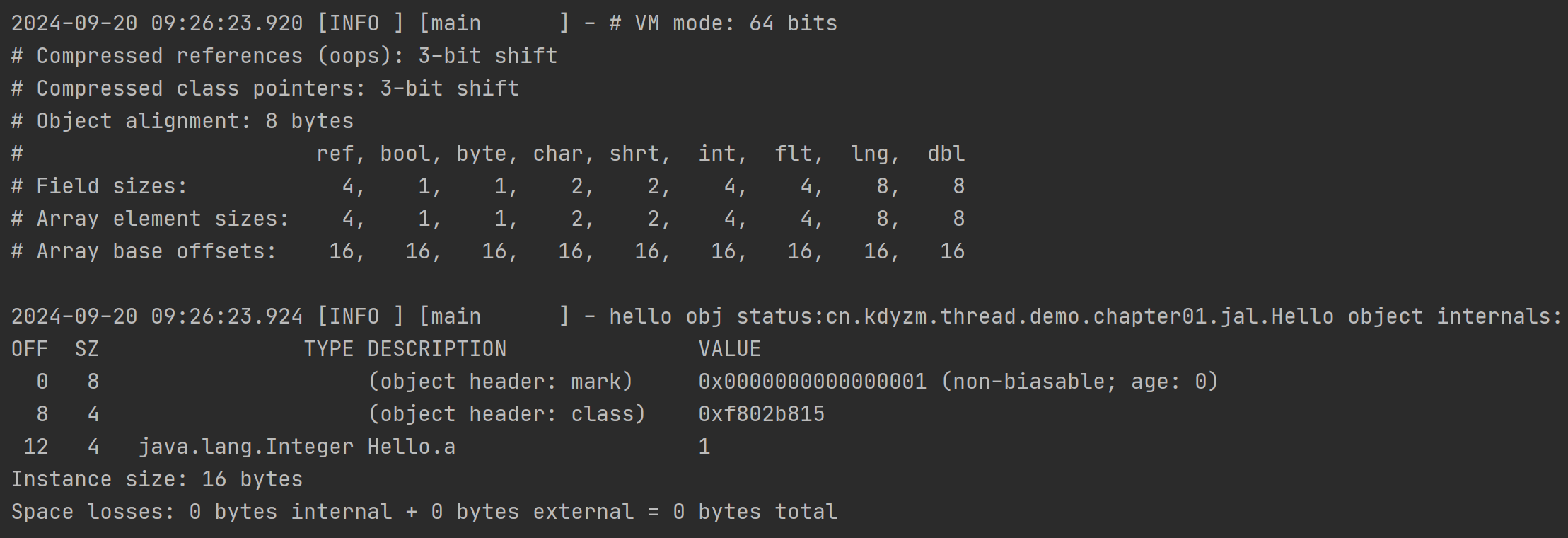
2、结果分析
在代码中,首先使用了VM.current().details() 方法获取到了当前java虚拟机的相关信息:
-
VM mode: 64 bits - 表示当前虚拟机是64位虚拟机
-
Compressed references (oops): 3-bit shift - 开启了对象指针压缩,在64位的Java虚拟机上,对象指针通常需要占用8字节(64位),但通过使用压缩指针技术,可以减少对象指针的占用空间,提高内存利用率。"3-bit shift" 意味着使用3位的位移操作来对对象指针进行压缩。通过将对象指针右移3位,可以消除指针中的一些无用位,从而减少对象指针的实际大小,使其占用更少的内存。
-
Compressed class pointers: 3-bit shift - 开启了类指针压缩,其余同上。
-
Object alignment: 8 bytes - 字节对齐使用8字节

这部分输出表示引用类型、boolean、byte、char、short、int、float、long、double类型的数据所占的字节数大小以及在数组中的大小和偏移量。
需要注意的是数组偏移量的概念,数组偏移量的数值其实就是对象头的大小,在上图中的16字节表示如果当前对象是数组,那对象头就是16字节,不要忘了,对象头中还有数组长度,在未开启对象指针压缩的情况下,它要占据4字节大小。
接下来是对象结构的输出分析。
三、对象结构输出解析
先回顾下对象结构
再来回顾下对象结构输出结果

-
OFF:偏移量,单位字节
-
SZ:大小,单位字节
-
TYPE DESCRIPTION:类型描述,这里显示的比较直观,甚至可以看到是对象头的哪一部分
-
VALUE:值,使用十六进制字符串表示,注意一个字节是8bit,占据两个16进制字符串,JOL0.15版本之前是小端序展示,0.15(包含0.15)版本之后使用大端序展示。
1、Mark Word解析

因为当前虚拟机是64位的虚拟机,所以Mark Word在对象头中占据8字节,也就是64位。它不受指针压缩的影响,占据内存大小只和当前虚拟机有关系。
当前的值是十六进制数值:0x0000000000000001,为了好看点,将它按照字节分割开:00 00 00 00 00 00 00 01,然后,来回顾下mark workd的内存结构:
最后一个字节是十六进制的01,转化为二进制数,就是00000001,那倒数三个bit就是001,偏向锁标志位biased是0,lock标志位是01,对应的是无锁状态下的mark word数据结构。
2、Class Pointer 解析

该字段在64位虚拟机下开启指针压缩占据4字节,未开启指针压缩占据8字节,它指向方法区的内存地址,即Class对象所在的位置。
3、对象体解析

Hello类只有一个Integer类型的变量a,它在64位虚拟机下开启指针压缩占据4字节,未开启指针压缩占据8字节大小。需要注意的是,这里的8字节存储的是Integer对象指针大小,而非int类型的数值所占内存大小。
四、不同条件下的对象结构变化
1、Mark Word中的hashCode
在无锁状态下,对象头中的mark word字段有31bit是用于存放hashCode的值的,但是在之前的打印输出中,hashCode全是0,这是为什么?
想要hashCode的值能够在mark word中展示,需要满足两个条件:
- 目标类不能重写hashCode方法
- 目标对象需要调用hashCode方法生成hashCode
上面的实验中,Hello类很简单
java
public class Hello {
private Integer a = 1;
}没有重写hashCode方法,使用JOL工具分析没有看到hashCode值,是因为没有调用hashCode()方法生成hashCode值
接下来改下启动类,调用下hashCode方法,重新输出解析结果
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info(VM.current().details());
Hello hello = new Hello();
hello.hashCode();
log.info("hello obj status:{}", ClassLayout.parseInstance(hello).toPrintable());
}
}输出结果
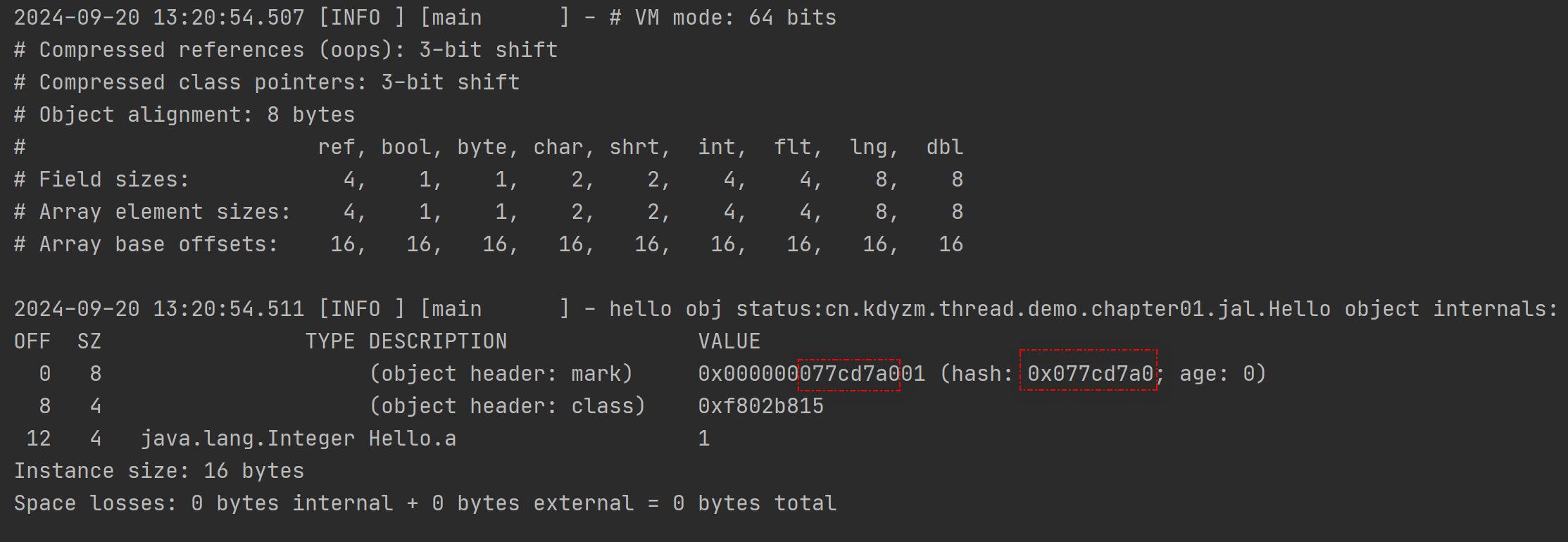
可以看到,Mark Word中已经有了hashCode的值。
2、字节对齐
从JOL输出上来看,使用的是8字节对齐,而对象正好是16字节,是8的整数倍,所以并没有使用字节对齐,为了能看到字节对齐的效果,再给Hello类新增一个成员变量Integer b = 2,已知一个整型变量在这里占用4字节大小空间,对象大小会变成20字节,那就不是8的整数倍,会有4字节的对齐字节填充,改下Hello类
java
public class Hello {
private Integer a = 1;
private Integer b = 2;
}然后运行启动类
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info(VM.current().details());
Hello hello = new Hello();
hello.hashCode();
log.info("hello obj status:{}", ClassLayout.parseInstance(hello).toPrintable());
}
}运行结果:
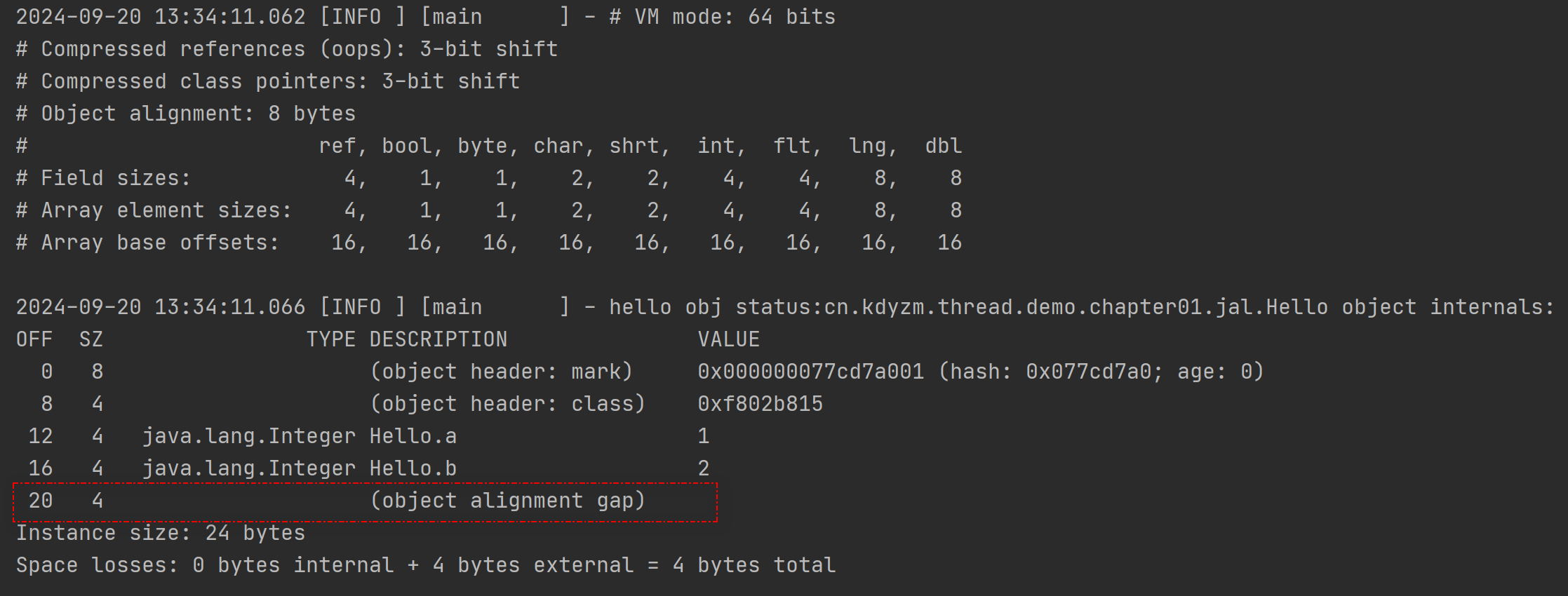
果然,为了对齐8字节,多了4字节的填充,整个对象实例大小变成了24字节。
3、数组类型的对象结构
数组类型的对象和普通的对象肯定不一样,甚至在对象头中专门有个"数组长度"来记录数组的长度。改变下启动类,看看Integer数组的对象结构
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info(VM.current().details());
Integer[] a = new Integer[]{1, 2, 3};
a.hashCode();
log.info("hello obj status:{}", ClassLayout.parseInstance(a).toPrintable());
}
}输出结果
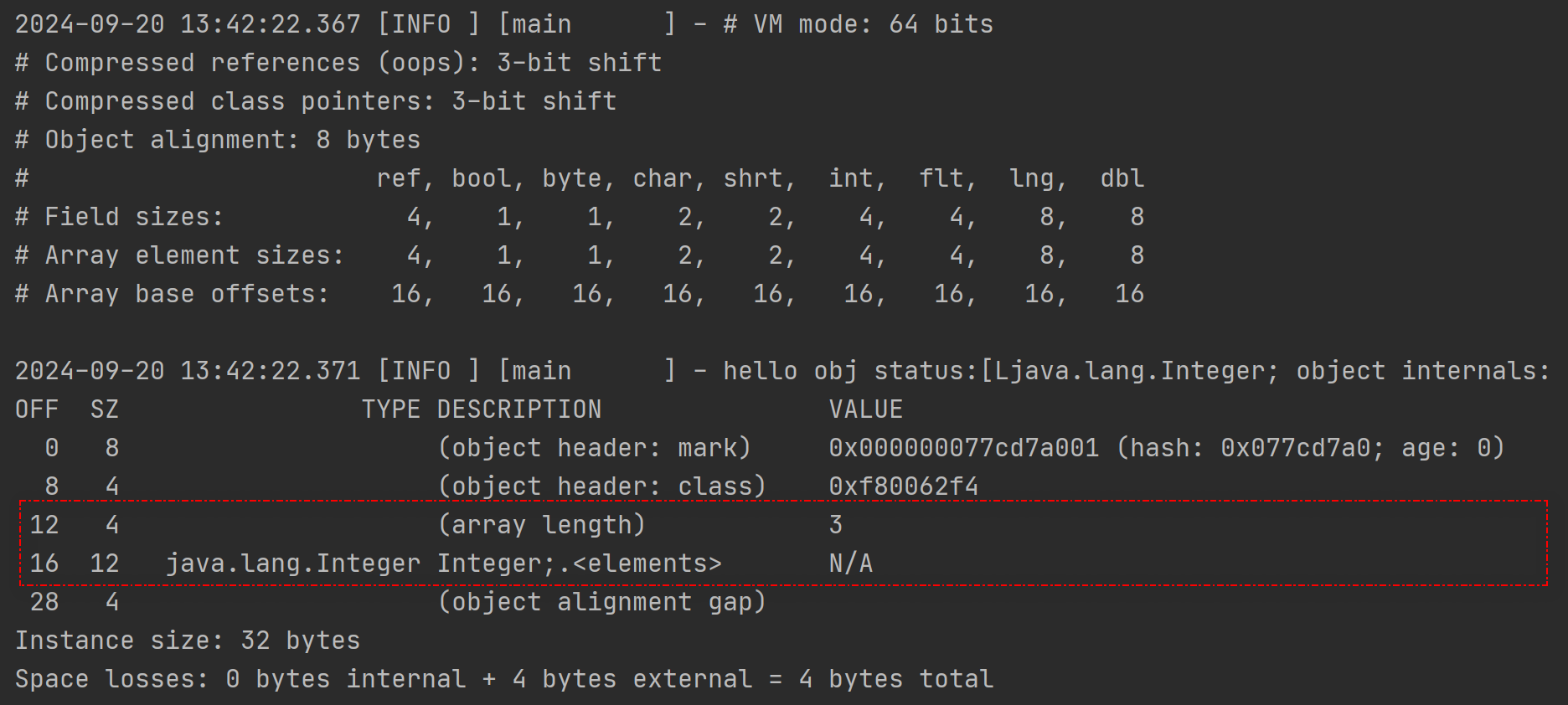
标红部分相对于普通的对象,数组对象多了个数组长度的字段;而且接下来3个整数,共占据了12字节大小的内存空间。
再仔细看看,加上数组长度部分,对象头部分一共占据了16字节大小的空间,这个和上面的Array base offsets的大小一致,这是因为要想访问到真正的对象值,从对象开始要经过16字节的对象头才能读取到对象,这16字节也就是每个元素读取的"偏移量"了。
4、指针压缩
开启指针压缩: -XX:+UseCompressedOops
关闭指针压缩: -XX:-UseCompressedOops
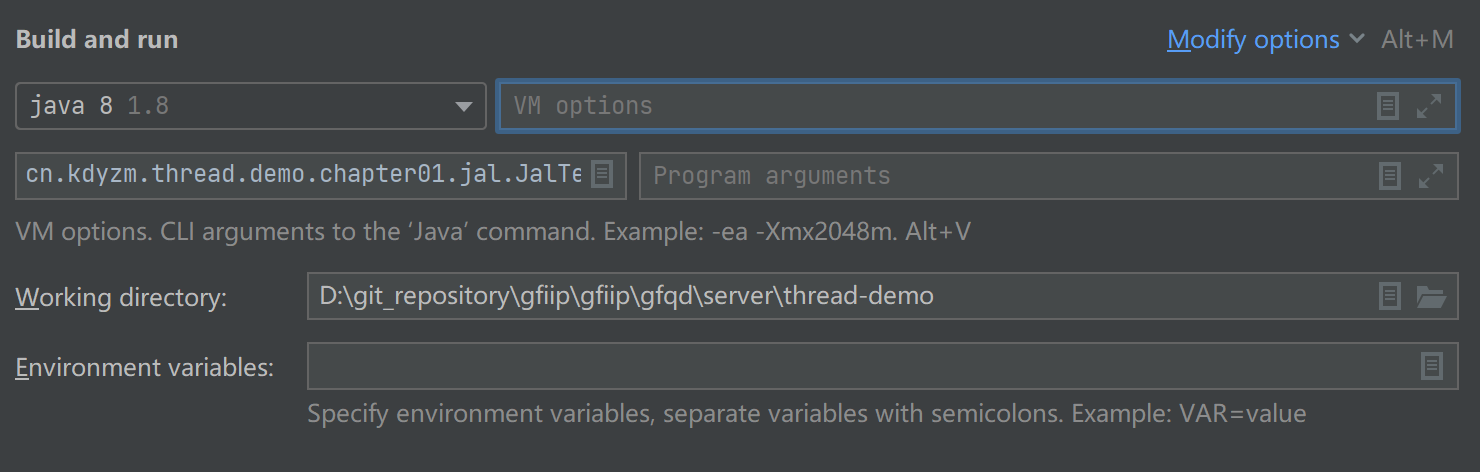
在Intelij中,在下图中的VM Options中添加该参数即可
需要注意的是,指针压缩在java8及以后的版本中是默认开启的。
接下来看看指针压缩在开启和没开启的情况下,相同的解析代码打印出来的结果
代码:
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info("\n{}",VM.current().details());
Integer[] a = new Integer[]{1, 2, 3};
a.hashCode();
log.info("hello obj status:\n{}", ClassLayout.parseInstance(a).toPrintable());
}
}开启指针压缩的解析结果:
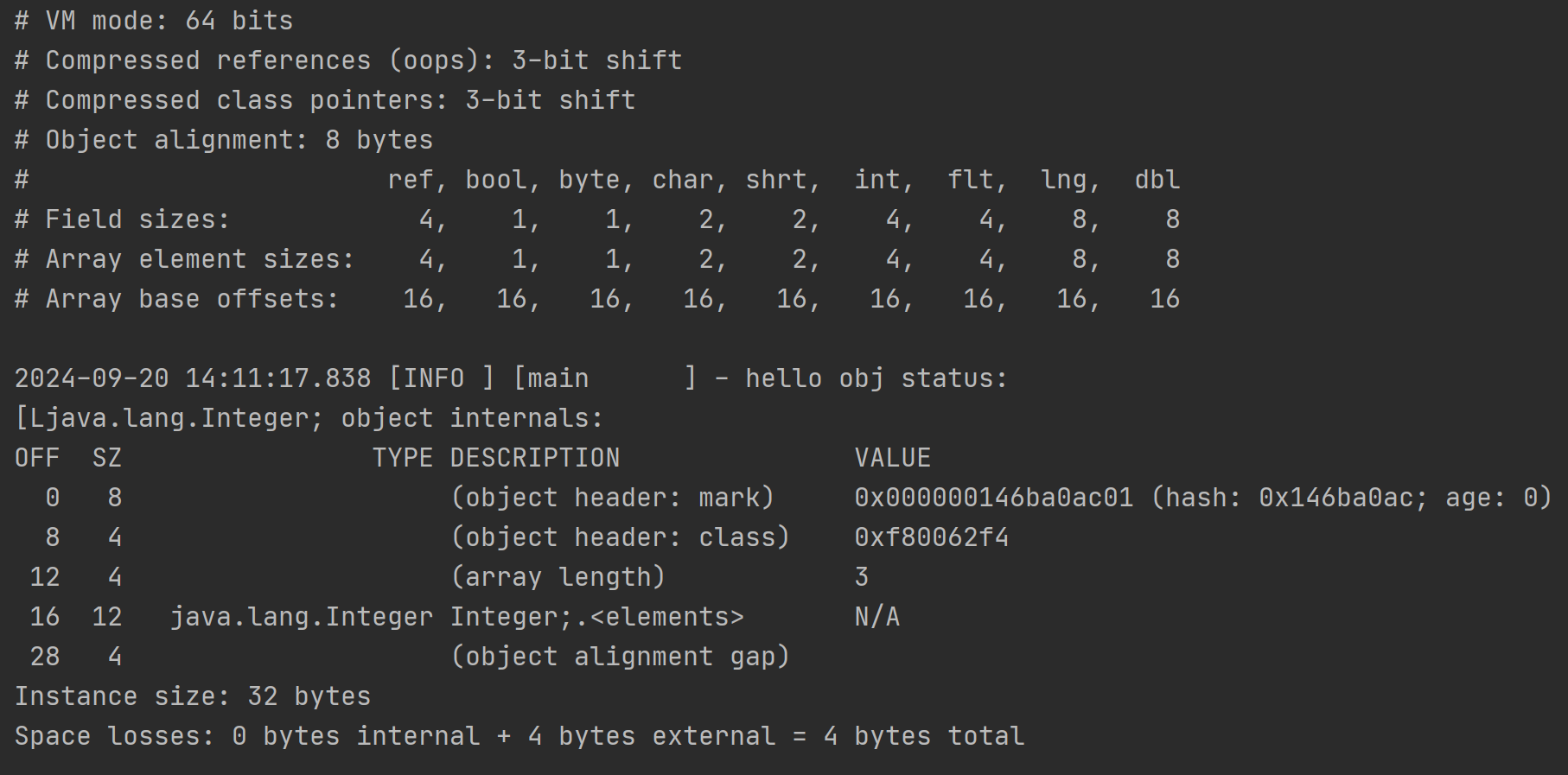
未开启指针压缩的结果:
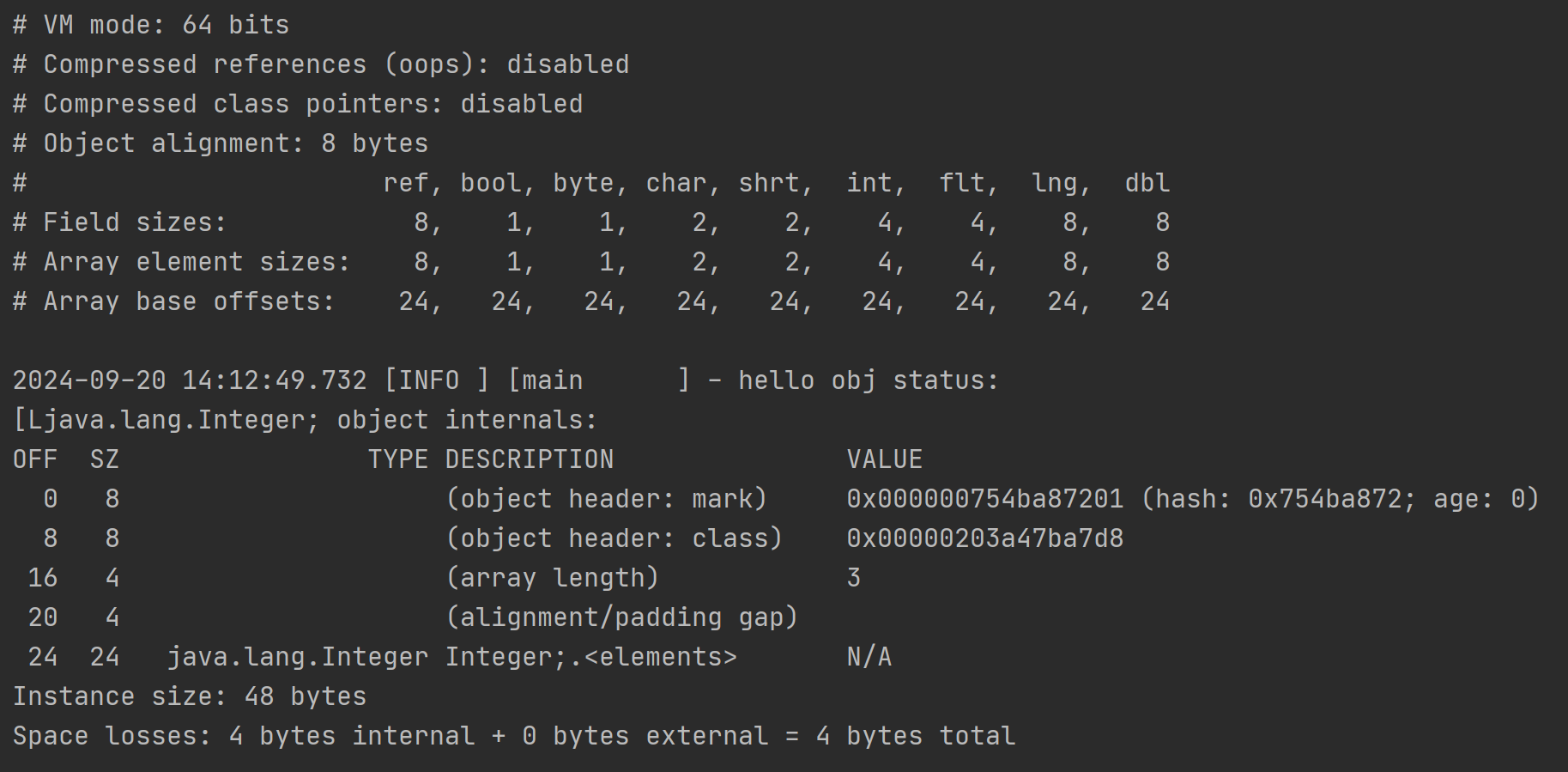
以开启指针压缩后的结果为基础,观察下未开启指针压缩的结果
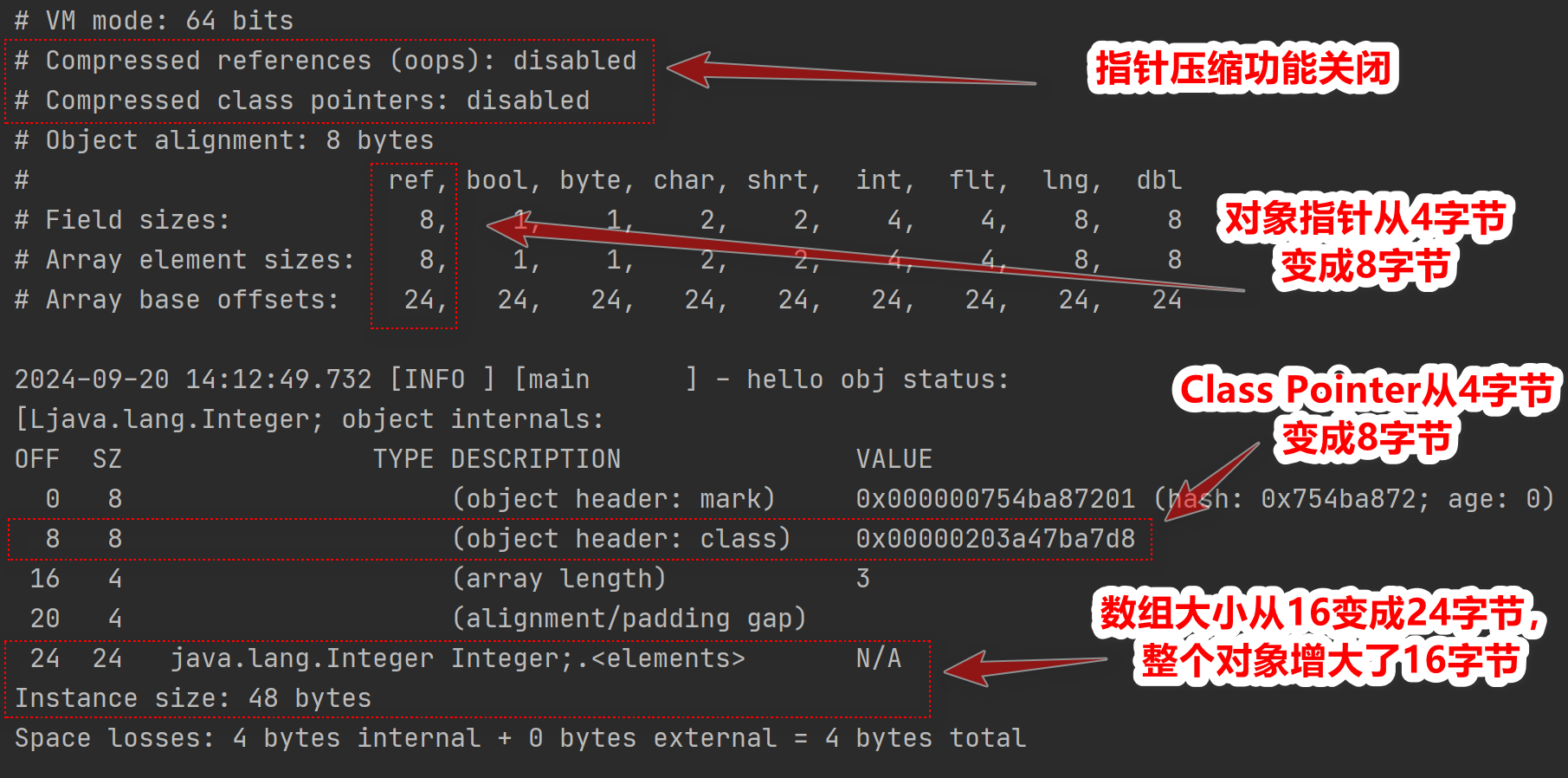
需要注意的是这里的Integer\[\]数组里面都是Integer对象,而非int类型的数值,它是Integer基本类型包装类的实例,这里的数组内存地址中存储的是每个Integer对象的指针引用,从输出的VM信息的对照表中,"ref"类型占据8字节,所以才是3*8为24字节大小。
可以看到,开启指针压缩以后,会产生两个影响
- 对象引用类型会从8字节变成4字节
- 对象头中的Class Pointer类型会从8字节变成4字节
确实能节省空间。
五、扩展阅读
1、大端序和小端序
大端序(Big Endian)和小端序(Little Endian)是两种不同的存储数据的方式,特别是在多字节数据类型(比如整数)在计算机内存中的存储顺序方面有所体现。
- 大端序(Big Endian):在大端序中,数据的高位字节存储在低地址,而低位字节存储在高地址。类比于数字的书写方式,高位数字在左边,低位数字在右边。因此,数据的最高有效字节(Most Significant Byte,MSB)存储在最低的地址处。
- 小端序(Little Endian):相反地,在小端序中,数据的低位字节存储在低地址,而高位字节存储在高地址。这种方式与我们阅读数字的顺序一致,即从低位到高位。因此,数据的最低有效字节(Least Significant Byte,LSB)存储在最低的地址处。
这两种存储方式可以用一个简单的例子来说明:
假设要存储一个 4 字节的整数 0x12345678:
- 在大端序中,存储顺序为
12 34 56 78。 - 在小端序中,存储顺序为
78 56 34 12。
2、老版本的JOL
老版本的JOL(0.15之前)输出的值是小端序的,可以做个实验,将maven坐标改成0.14版本
xml
<!--Java Object Layout -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.14</version>
</dependency>同时要引入新的工具类
xml
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.32</version>
</dependency>然后修改Hello类
java
import cn.hutool.core.util.ByteUtil;
import cn.hutool.core.util.HexUtil;
/**
* @author kdyzm
* @date 2024/9/19
*/
public class Hello {
private int a = 1;
private int b = 2;
public String hexHash() {
//对象的原始 hashCode,Java默认为大端模式
int hashCode = this.hashCode();
//转成小端模式的字节数组
byte[] hashCode_LE = ByteUtil.intToBytes(hashCode, ByteOrder.LITTLE_ENDIAN);
//转成十六进制形式的字符串
return HexUtil.encodeHexStr(hashCode_LE);
}
}启动类:
java
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* @author kdyzm
* @date 2024/9/19
*/
@Slf4j
public class JalTest {
public static void main(String[] args) {
log.info("\n{}", VM.current().details());
Hello hello = new Hello();
log.info("算的十六进制hashCode:{}", hello.hexHash());
log.info("JOL解析工具输出对象结构:{}", ClassLayout.parseInstance(hello).toPrintable());
}
}输出结果:
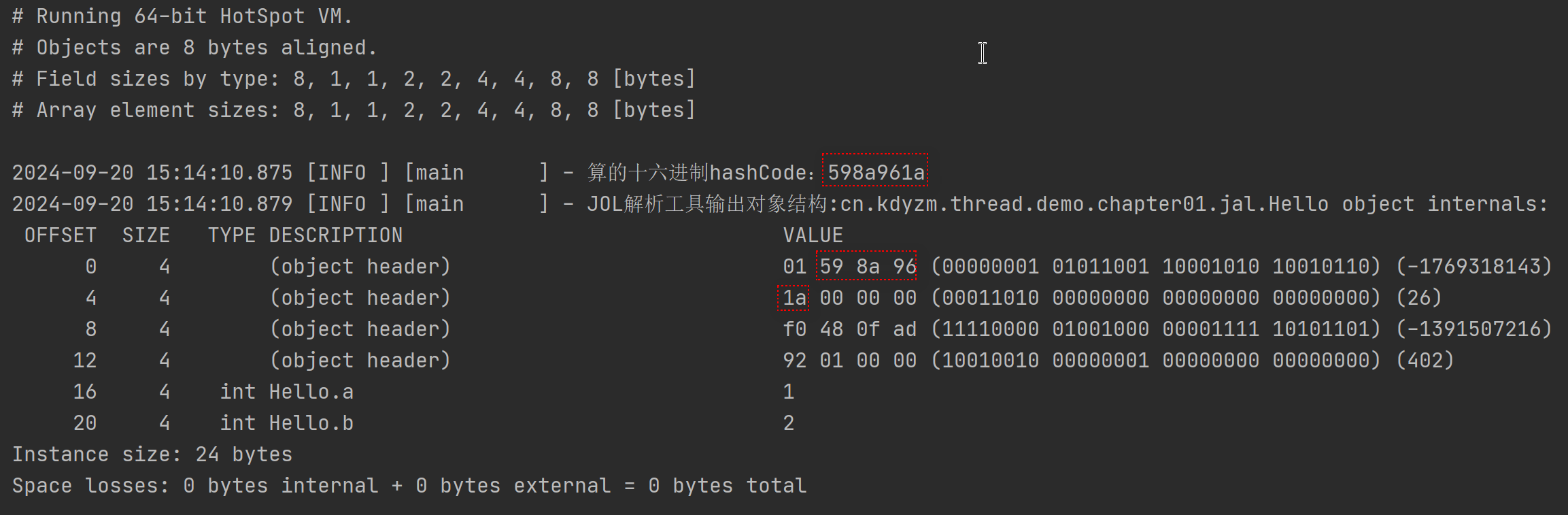
先不管老版本的输出和新版本的差异性,总之可以看到小端序手动算的hashCode和jol解析得到的hashCode是一致的,说明老版本的jol(0.15之前)输出是小端序的,对应我们的Mark Word图例来看
我们的图例是按照大端序来画的,所以老版本的输出第一个字节01才是Mark Word上述图例的最后一个字节。
代码不变,改变JOL版本号为0.15
java
<!--Java Object Layout -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.15</version>
</dependency>运行结果如下
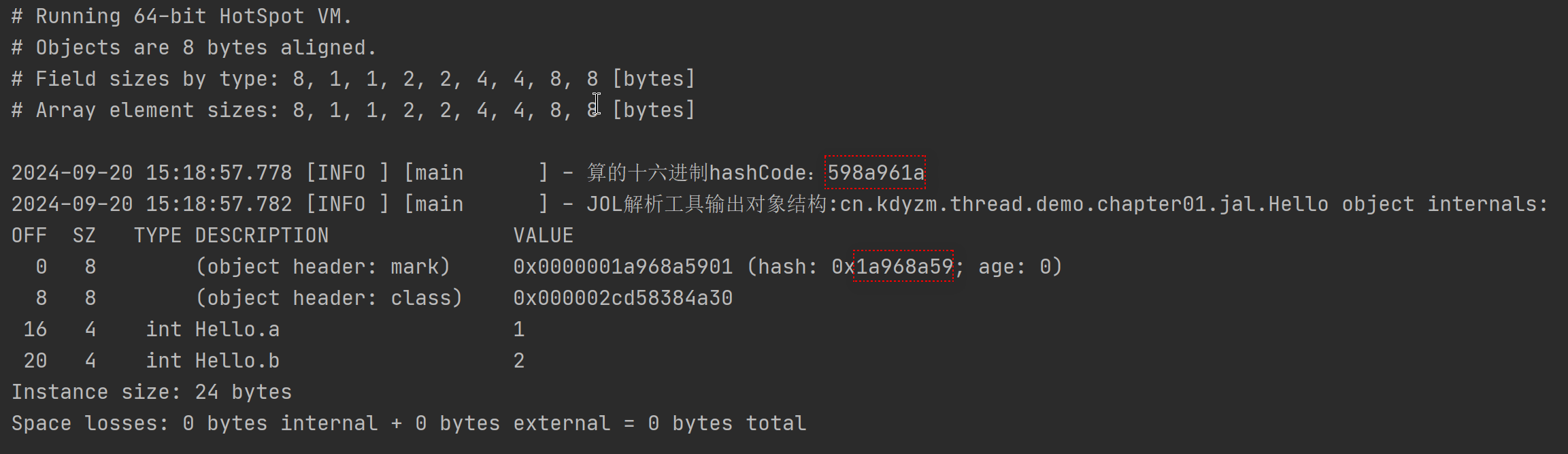
可以看到手动计算的hashCode和jol解析的hashCode字节码颠倒过来了,也就是说,从0.15版本号开始,jol的输出变成了大端序输出了。
3、hutool的bug
上面的代码中有用到hutool工具类计算hashCode值的十六进制字符串,一开始我引入的依赖是这样的
xml
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.3</version>
</dependency>其中有个很重要的int类型转换字节数组的方法:cn.hutool.core.util.ByteUtil#intToBytes(int, java.nio.ByteOrder)
源代码这样子:
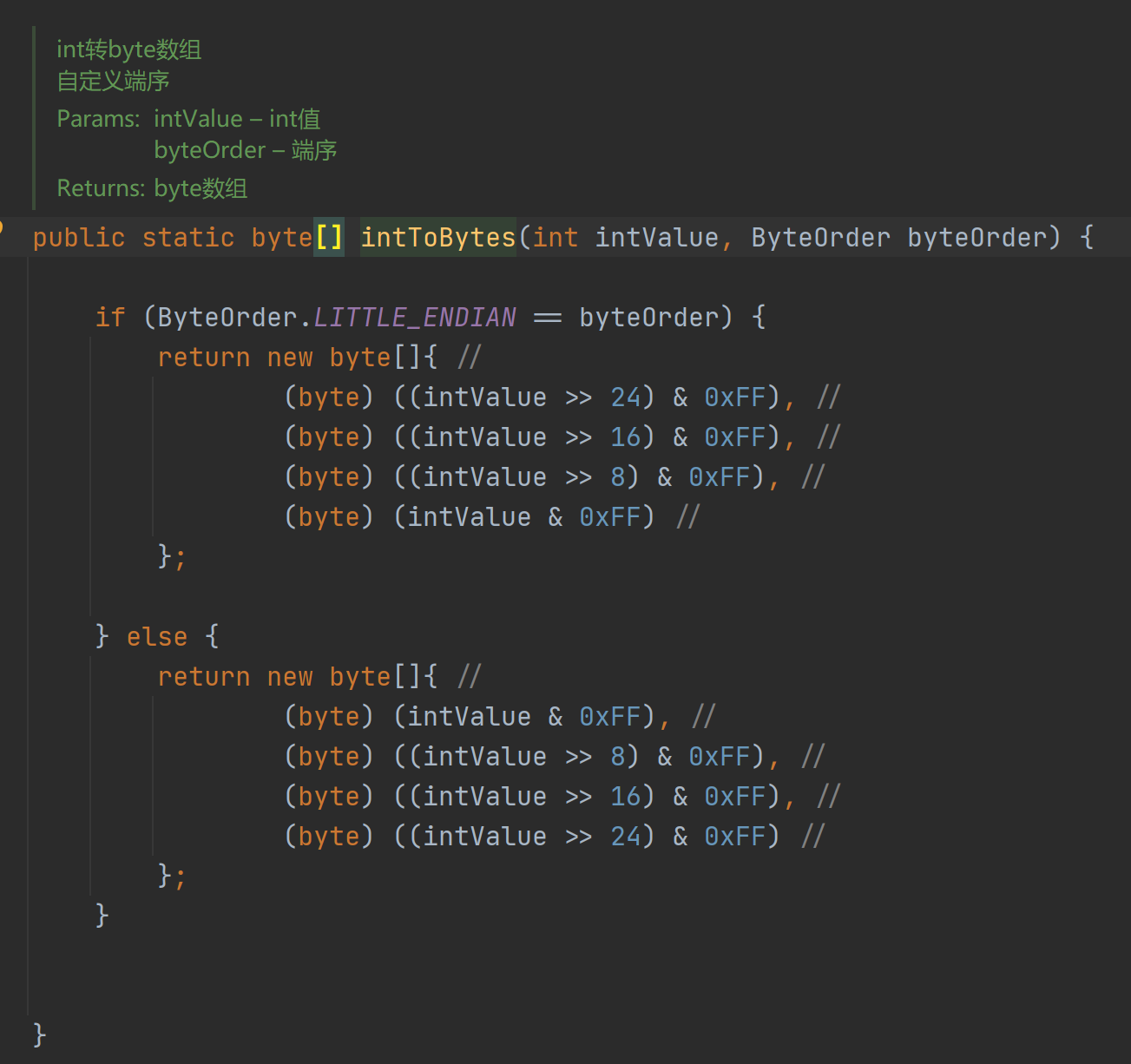
很明显的bug,它判断了小端序标志,但是却返回了大端序的字节数组,不出意外的,我的代码运行的有矛盾。。所以我专门去gitee上看了下,发现它的master代码已经发生了变化
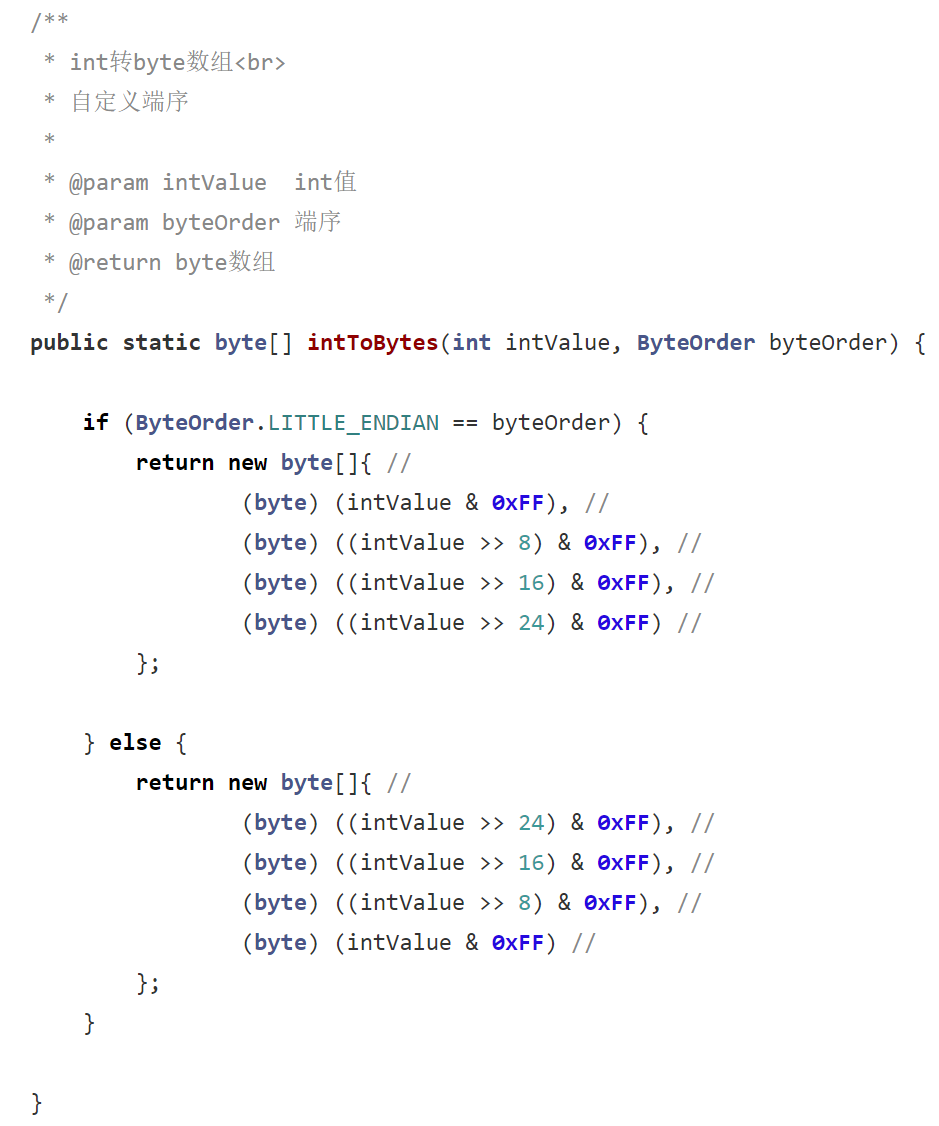
没错,它master代码已经修复了。。找了找commit,发现了这个

对应的COMMIT记录链接:https://gitee.com/dromara/hutool/commit/d4a7ddac3b30db516aec752562cae3436a4877c0
还被人吐槽了,哈哈哈,引入5.8.32版本就解决了
xml
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.32</version>
</dependency>END.
参考文档
《Java高并发核心编程 卷2:多线程、锁、JMM、JUC、高并发设计模式》
看到最后了,欢迎关注我的个人博客⌯'▾'⌯:https://blog.kdyzm.cn