Host
表示服务器主机的地址和端口号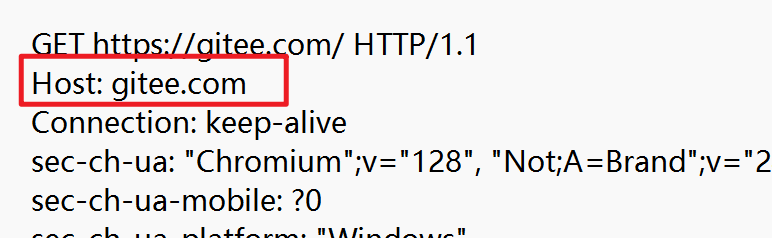
URL 里面不是已经有 Host 了吗,为什么还要写一次?
- 这里的
Host和URL中的IP地址、端口什么的,绝大部分情况下是一样的,少数情况下可能不同 - 当前我们经过某个代理进行转发。过程中,
URL中的IP指向的是代理服务器的IP;Host中的IP指向的是最终目标的地址
Content-Length/Content-Type
这俩都和 body 密切相关,如果你这个数据包没有 body,也就不会有这两个字段
Content-Length表示body中的数据长度Content-Type表示body中的数据格式
通过这个长度,来处理"粘包问题 "。HTTP 底层也是基于 TCP。连续传输多个 HTTP 数据报,此时接收方这边的接收缓冲区里面就会积累多个包的数据,应用程序在读取这些数据的时候就需要明确包之间的边界
- 如果是没有
body的请求/响应,直接使用空行作为分隔符 - 如果有
body,空行就不是结束标记了,从空行开始来读取body,body要读多长就取决于Content-Length。读完之后,这个包就结束了
body 里面可以传输很多种格式,程序员也可以自己约定任意的格式,但是有些格式是非常常见的:
请求中:
-
application/jsonbody就是json
-
application/x-www-form-urlencoded- 称为
form表单 - 通过
HTML中的form标签构造出来的一种格式。这个格式的特点,认为是把query string放到body中了
- 称为
-
multipart/form-data- 上传文件时使用的
- 第二种格式也是可以的
响应中:
text/plain,纯文本text/html,htmltext/csss,cssapplication/javascript,jsapplication/jsonimage/pngimage/jpg
!quote 抓的包是灰色的
- 由于浏览器和服务器之间要进行多次网络交互,整体的过程是比较低效的
- 为了提升效率,就会把一些固定不变的内容在浏览器本地的机器硬盘上进行缓存(css、图片、js 很少发生改变)
- 保存到硬盘上之后,后续再请求,就可以直接从硬盘上读取数据,减少了网络交互的开销
- 抓到硬盘上的数据,就是灰色的
使用
Ctrl+f,强制刷新,就可以不读取缓存,直接读取服务器数据
User-Agent(简称 UA)

- 32 位系统支持的最大内存为 4GB
- 这块部分主要就是操作系统的信息和浏览器的信息。描述了用户在使用什么样的设备在上网
上古时期,UA 是非常关键的部分,不同用户使用的上网的设备差异很大(当年计算机发展日新月异),在同一个时间段内,新的和旧的会同时存在
- 最老的浏览器,只能显示文本
- 之后能显示图片
- 能支持 js
- 支持 flash 等动画效果
- ...
如果你是一个程序员,你要写一个网站,你写的网站是否要使用新的特性呢?
- 使用新特性,佬的设备就无法正常打开
- 不使用新特性,你这个网站就打不过竞争对手
我们就可以借助 UA 来解决上述问题。UA 里面记录了系统和浏览器的信息,服务器就可以针对此时的 UA 信息进行判定 - 如果用户用的是很老的设备,返回的页面就不包含新的特性,确保这个页面能正常访问
- 如果用户用的是新的设备,返回的页面就包含新特性,确保这个页面体验足够好
随着时间推移,浏览器现在都差不多了,UA 好像无用武之地了?
- 其实仍然很有用
现在的市面上上网的设备存在这两类:
| PC | 屏幕大 | 更宽 |
|---|---|---|
| 手机 | 屏幕小 | 更窄 |
| 对应的返回的页面布局就应该有差异。UA 里面包含了系统信息,就可以判定系统是 PC 的还是移动端的,此时就可以根据这个信息来返回不同的页面了 |
使用手机浏览器的时候,很多手机浏览器都有一个功能------"手动修改 UA ",手动把 UA 改成 PC 端的 UA,这样就能访问电脑端的网页了
响应式布局
给 PC 端维护一套代码,给移动端维护一套代码,搞两套代码有点麻烦,并且手机尺寸区别也很大,还有平板什么的。前端后来提出了解决上述问题的技术方案------"响应式布局"
通过一套代码,适应不同尺寸的显示器。CSS3 提供了一套特性------"媒体查询",可以感知到当前屏幕的尺寸,根据不同的尺寸,应用不同的样式
所以现在也有越来越多的网站,不再依赖 UA 来进行区分了
User-Agent的故事: https://zhuanlan.zhihu.com/p/398807396