业务安全治理
1.账号安全
撞库
撞库分为垂直撞库和水平撞库两种,垂直撞库是对一个账号使用多个不同的密码进行尝试,可以理解为暴力破解,在做了"多次错误导致锁定"控制的应用上,垂直撞库很容易被发现。水平撞库则是利用同一个密码(比如123456)对多个账号进行尝试,由于对同一个账号的错误次数没有触发锁定条件,水平撞库往往更难从业务系统上直接发现
防撞库有几种主要的思路:
++1、验证码++
验证码一般包括图形验证码、短信验证码两种
图形验证码因低成本优势被广泛使用,但是,图形验证码存在一定的弊端,图形验证码通过去噪、二值化、切片等处理后,可以实现机器自动识别,网上有专门的验证码识别工具,搜索"验证码识别"还能找到一些打码平台。
同样,针对短信验证码,也有专门的平台,比如各大接码平台
有攻也有防,验证码的技术也在不断地发展,包括常见的问答模式、点选模式、拖动验证等
++2、页面混淆++
一个登录的表单,混淆前后变化非常大,包括元素的ID、Name全都变了样,传统的暴力破解工具在这里就失效了,因为没法定位到这些元素。

此类方案实施过程中需要注意两点:
- 网站系统内存在的一些接口,由于需要被调用,不适合用此方案进行保护,实施时需要注意做例外处理。
- 由于混淆会对HTML甚至js进行处理,需要考虑一些特殊业务场景下的兼容性问题,如浏览器版本、第三方控件、页面嵌套在C/S客户端中等。
++3、后端分析与拦截++
这里的后端处理,可能是专门的WAF设备,也可能是Nginx上的过滤模块,也可能是传统的防火墙。
一般的WAF都有对基于请求频率进行限制的功能,将需要保护的页面、时间、请求次数相关参数进行设置即可。
账户盗用
并不是单独设置了支付密码就安全了,因为坏人总会想办法拿到你的密码,比如上面的撞库,或者通过伪基站发送钓鱼短信诱使用户访问并在页面中输入用户密码等信息,一旦这些信息被坏人拿到,马上就会给受害者造成财产上的损失,所以危害极大
金融企业需要采用加强性验证、用户提醒等方式来保障用户账号安全
其工作原理是:当用户在一部新手机或新设备上登录网站或APP时,由于后台没有对应的设备指纹记录,所以用户输入成功用户和密码后,还会要求输入一个短信验证码(我们叫它二次认证),当达到一定的条件(比如成功在这个设备上登录5次)后才不会有这个二次认证
除了以上方法外,不少应用还会按场景使用验证码、异地登录提醒等功能,比如当发现账号在非常用的地点登录时,可以通过验证码进行二次认证,或者登录成功后给用户发一个异地登录提醒的信息等
2.爬虫与反爬虫
主流的反爬虫技术,一般分为后台限制及前端变化两种:
++1、后台限制++
设置robots.txt文件针对单个IP访问超过阈值后封锁IP,针对单个Session访问超过阈值后封锁Session,针对单个User-Agent访问超过阈值进行封锁,组合前几个值进行访问统计超阈值进行阻断或者发验证码要求验证。比较暴力一点的是直接阻断一些类似PycURL、libwww-perl等User-Agent的访问,某些国产WAF中关于爬虫防护的内容中就列举了常见的爬虫UA以供用户选择。
当然这些都容易绕过,不遵守robots协议、换IP、换Session、换UA都相对简单,此时可以通过蜜罐技术设置假的robots,放置一些hidden的表单项,或者一些注释掉的页面链接等,不会影响用户体验,但爬虫一旦访问即说明有问题,可以进一步干预,比如阻断。
++2、前端变化++
后端限制效果可以马上呈现,但随着爬虫技术的不断提升,在后端能做的工作越来越有限,而且还会存在误伤的问题,所以更多企业把精力放在前端上,对重要的页面内容进行保护,防止被批量爬取。
前端技术多种多样,我们简单看几个实际案例来体会一下:
1️⃣ 某代理IP网站页面,为了保护上面公布的IP地址不被人爬取,对IP地址数字和字符做了拼凑处理
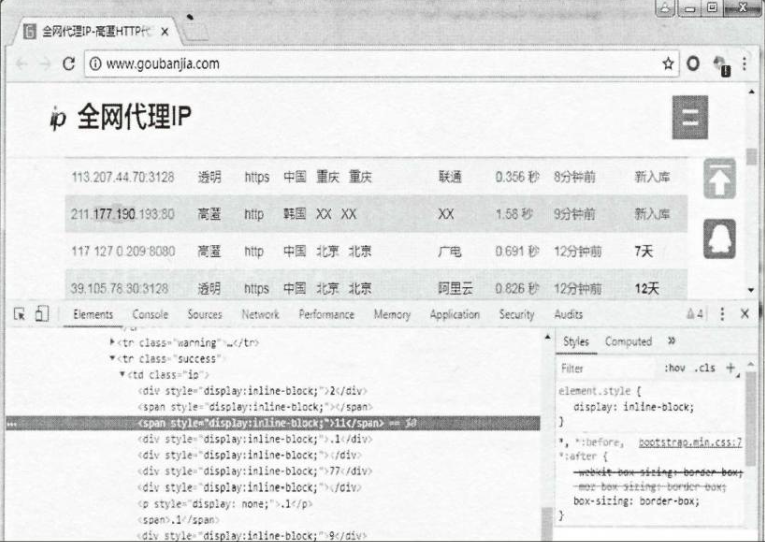
但是聪明的爬虫如果拼接上面的div和span标签,也能获取到正确的IP地址
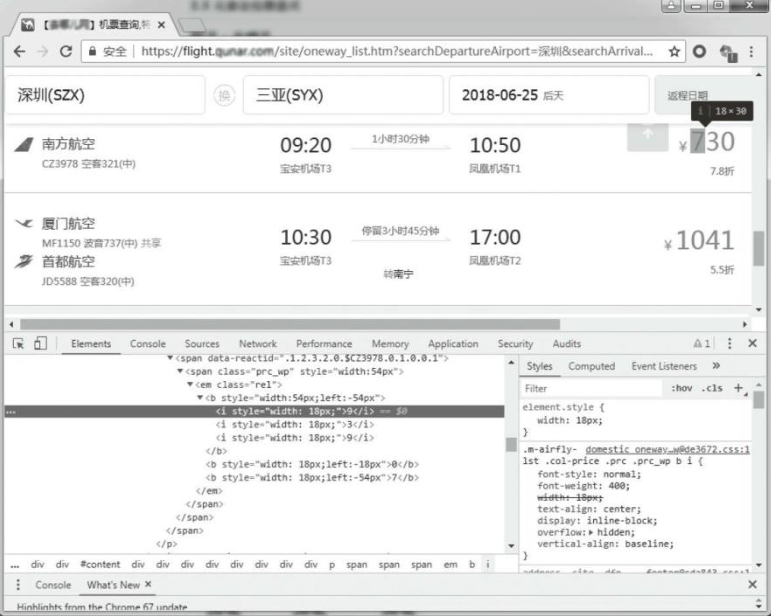
2️⃣ 三位数的价格就会生成3个b标签,其中第一个b标签里包含3个i标签,利用元素定位覆盖错误的i标签,从而最终给用户显示正确的价格,但爬虫就难搞了,拼凑不行还得要解析CSS并进行计算偏移覆盖情况
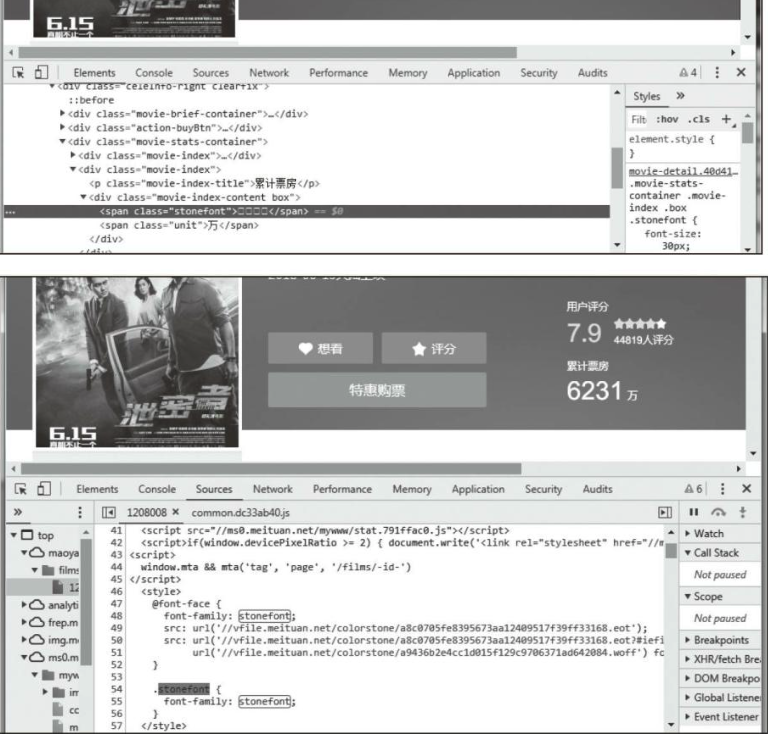
3️⃣ 打开某电影网站,随便找个电影查看其累计票房数据。票房数里展示的根本不是数字,而是使用了font-face定义了字符集,并且每次刷新,字符集的URL还是动态变化的,如果要爬这个数字,可能还不如OCR识别来的更好一些
4️⃣ 除了上面这些前端技巧外,还有以下经验值得参考:
- 关键数据可以考虑文本转成图片,甚至添加水印
- 网站请求的URL复杂化,尽量不暴露数据的唯一键(如ID等),避免爬虫通过修改ID即可轻松爬取其他信息
- 前端HTML页面根据用户点击情况动态加载,即查询页面源码时,只能看到列表的第一条数据
- 结合账号登录情况,对页面进行保护,比如Token等
- 结合蜜罐思路,确认异常时可以返回虚假数据
3.API网关防护
API作为应用程序之间通信的桥梁,容易成为攻击者的目标,因此需要多层次的防护措施来确保API的安全性
- Key认证:通过API密钥(API Key)对请求方进行身份验证,确保只有授权用户或应用程序能够访问API。每个API密钥通常与特定的权限绑定,确保不同的用户只能访问与其权限匹配的API资源。
- ACL控制(访问控制列表):ACL用于定义哪些IP地址、用户或系统有权访问API。通过配置ACL,可以限制未授权的访问,从而增加API的安全性。
- Bot检测:用于识别并阻止自动化的恶意机器人程序。恶意Bot可能会发起大量的API请求,从而耗尽资源或进行数据盗取。Bot检测技术通过分析请求行为、使用CAPTCHA等方式区分合法用户和自动化程序。
- CC限速(访问速率控制):防止API被恶意滥用的一种技术手段,通过限制单个IP或用户的请求速率,避免资源被快速耗尽或服务被拒绝。CC限速通常应用于防止DDoS(分布式拒绝服务)攻击。
商业解决方案:
- Imperva 和 F5 等公司提供专业的API安全产品。这些解决方案通常集成了WAF(Web应用防火墙)和DDoS防护功能,能够提供更高级别的API保护,如实时流量分析、自动化攻击防护和合规管理。
开源解决方案:
- Kong 是一个流行的API网关,它允许用户在流量到达API之前对其进行控制。Kong提供了多种插件,用于身份验证、速率限制、日志记录和安全功能,能够灵活地实现API防护。
4.钓鱼与反制
钓鱼发现
++1、钓鱼域名主动发现++
钓鱼网站一般为了增加可信度,会注册一些跟企业相关的域名,如果我们能主动去爬与企业相关的域名,便有可能提前发现。
首先,整理一些关键字,以便生成需要爬取的域名。下面以钓鱼网站中的wap.95588ccz.com为例进行分析,wap有时候可以改为www或者m,95588ccz则可以变化为xx95588或者95588xx,这个xx可以取1~4位的字符,后面.com则可能变化为.net、.org、.cn、.com.cn、.info、.tk等等,每新多一个变化对应着生成的域名成指数增长。
其次,将生成的域名去请求类似8.8.8.8这样的DNS服务器查询,由于涉及大量的域名请求,所以建议在境外部署多台VPS进行分布式请求,一来提升效率,二来防止请求过多被限制。
最后,将解析出来的域名,进行适当的黑白名单的过滤处理后,再报送到后台,便于后续跟进处置。如果某天通过其他渠道发现有新的钓鱼网站域名,又可以针对性地改进上面这个过程。
++2、外部合作发现++
在实际工作中,可能需要与多家外部机构合作,有的提供的是接口,有的可能仅能提供邮件,相互提供的数据可能还存在重复,所以我们需要有一套系统将这些信息进行汇总,利用一些技术手段进行截图,进而做图片相似性判断,便于接下来的应对处置。
钓鱼处置
++1、关闭或封禁钓鱼网站++
一般企业是不具备能力去关闭钓鱼网站的,所以这个时候都需要找外部合作机构,比如Cncert、RSA等;腾讯、360等在移动终端上提供了安全防护类功能,所以也可以合作,将钓鱼网站信息反馈给对方,这样当用户访问恶意的链接的时候,会被手机上的安全防护功能拦截。
++2、对钓鱼网站进行反制++
对钓鱼网站进行反制的目的是尽可能地减少用户损失,一般有几种操作:
- 入侵或逆向拿数据
钓鱼网站提供恶意APP下载,通过逆向就可以找到一些类似于手机号(一般用来转发特定验证码短信)、邮箱账号密码(一般用来记录用户的通讯录、手机短信等)的信息,登录这些邮箱往往也会看到一些吓人的数据。拿到这些数据后,可以提供给业务部门,让他们通知受害用户,避免遭受损失
- 大量写虚假数据
很多钓鱼网站根本不会校验用户输入的卡号到底是不是真实的卡号,所以可以通过脚本生成大量卡号密码提交到钓鱼网站,可以给对方增加一些工作量,也为我们争取更多的时间。有些钓鱼网站开发得不好,甚至在写入垃圾数据过多时,自己就崩溃了
- DDoS攻击
在境外申请VPS对钓鱼网站进行流量压制,让用户访问变得非常慢或者无法访问。建议不要轻易使用,或者使用时讲究技巧,打打停停,一是怕VPS提供商发现后导致VPS不可用,二是如果招惹黑产反过来DDoS就有点麻烦了
- 通过调整业务逻辑解决
例如账户盗用场景里的二次认证,钓鱼网站搞到了用户密码也没法交易
5.大数据风控
风控介绍
Nebula是国内安全公司威胁猎人团队开源的一款风控系统,重点解决恶意注册、账号被盗、内容欺诈三方面的业务安全问题,其系统架构如图所示:
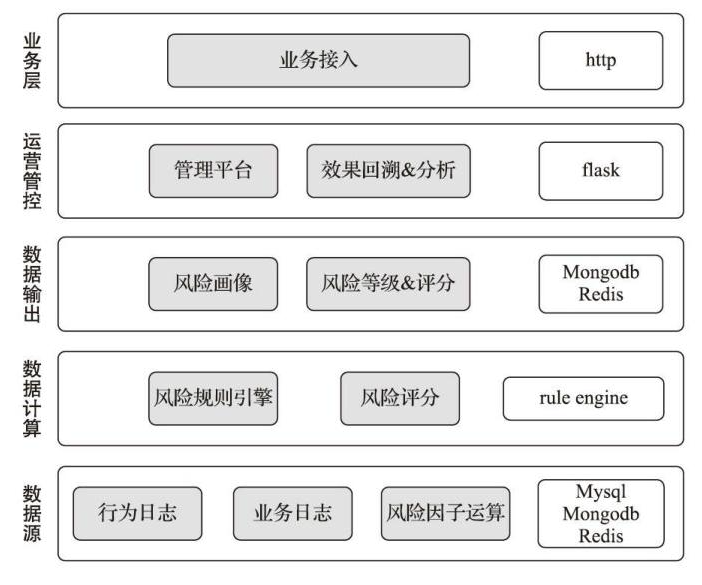
风控系统的工作方式:
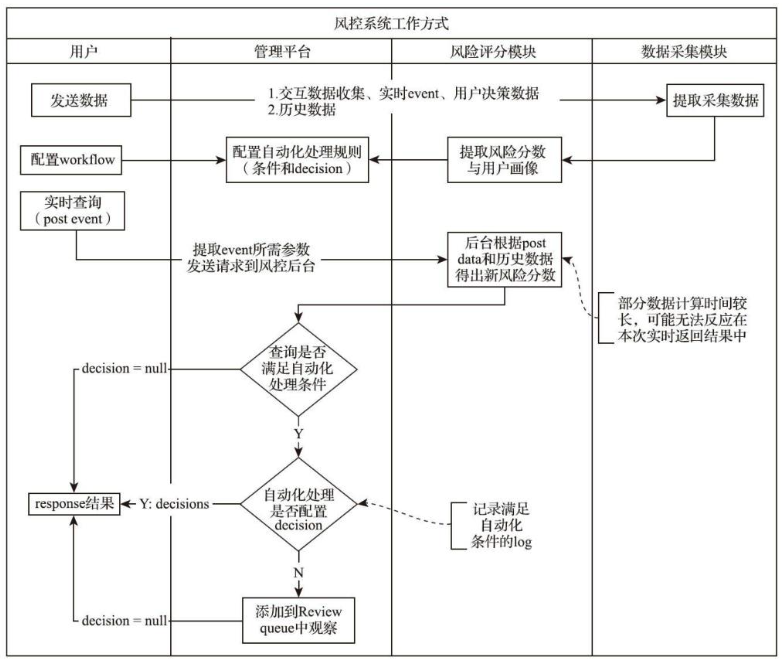
++1、数据源层++
大数据风控的基础在于数据,全面、高质量的数据可以帮助我们准确地进行风险控制。除了来自业务系统的日志外,还可以有更多的外部输入数据,比如以下几个方面:
- 用户基本信息,除了我们所熟知的姓名、身份证、银行卡、手机号外,还有学历信息、收入情况,甚至包含当前设备、当前位置等
- 用户的征信数据,除了人行征信系统外,还有一些其他网贷平台上的逾期或黑名单信息,比如某网贷平台的黑名单数据
- 历史交易信息,包括历史交易额、历史交易笔数、历史行为等
- 运营商数据,比如入网时长、入网状态、每月消费情况、通话记录、短信情况等,通过运营商数据可以判断用户的设备是否有异常
- 用户行为数据,包括用户的搜索记录、购买记录、社交数据等,通过这些数据可以判断识别该用户是一个什么样的人、有多强的消费能力、社会关系如何,等等
++2、数据计算与数据输出层++
通过风险规则引擎对数据源进行计算,得到相应的风险等级或分数。以贷款为例,这里的规则一般包括准入规则、反欺诈规则等
准入规则可以理解为一些政策上的要求,比如18岁以下的人不能放贷,大学生不能放贷等;或者一些业务上的要求,例如偏远地区放了贷款,万一不还则催收成本高,因此建议不放贷款等。还有一些场景,比如系统在前期测试时只允许特定的人群参与等。
反欺诈规则的主要目的是,识别用户是否有骗贷风险,以及有多大的骗贷风险。规则制定的时候可以基于用户画像,目的在于通过打标签的方法识别不同的用户群体的风险程度。其标签可以按照用户还款行为、用户申请轨迹、用户基本信息等方面进行考虑。
++3、运营管控层++
这一层的功能主要服务于风控规则的快速迭代和系统的个性化配置,比如对规则内容的调整、规则的启停等进行管理
通过这一层对风险情报进行展示,对风险决策进行配置,对决策效果进行回溯分析,以便业务层进行相关的动作

++4、业务层++
涉及具体的业务场景,比如快捷支付、直付通、转账交易等