Milvus 是一个专为在大规模密集向量数据集上进行相似性搜索而设计的开源向量数据库系统。其架构建立在流行的向量搜索库之上,如 Faiss、HNSW、DiskANN 和 SCANN,能够处理数百万、数十亿甚至数万亿的向量数据。为了全面了解 Milvus 架构,我们首先需要熟悉嵌入检索的基本原理。
Milvus 的核心功能
Milvus 支持多种高级功能,包括数据分片、流式数据摄取、动态模式、结合向量和标量数据的混合搜索、多向量搜索、稀疏向量搜索等。此外,Milvus 的架构设计灵活,支持不同场景下的嵌入检索。为确保高性能和可扩展性,建议将 Milvus 部署在 Kubernetes 上,以实现最佳的弹性和可用性。
Milvus 的架构概览
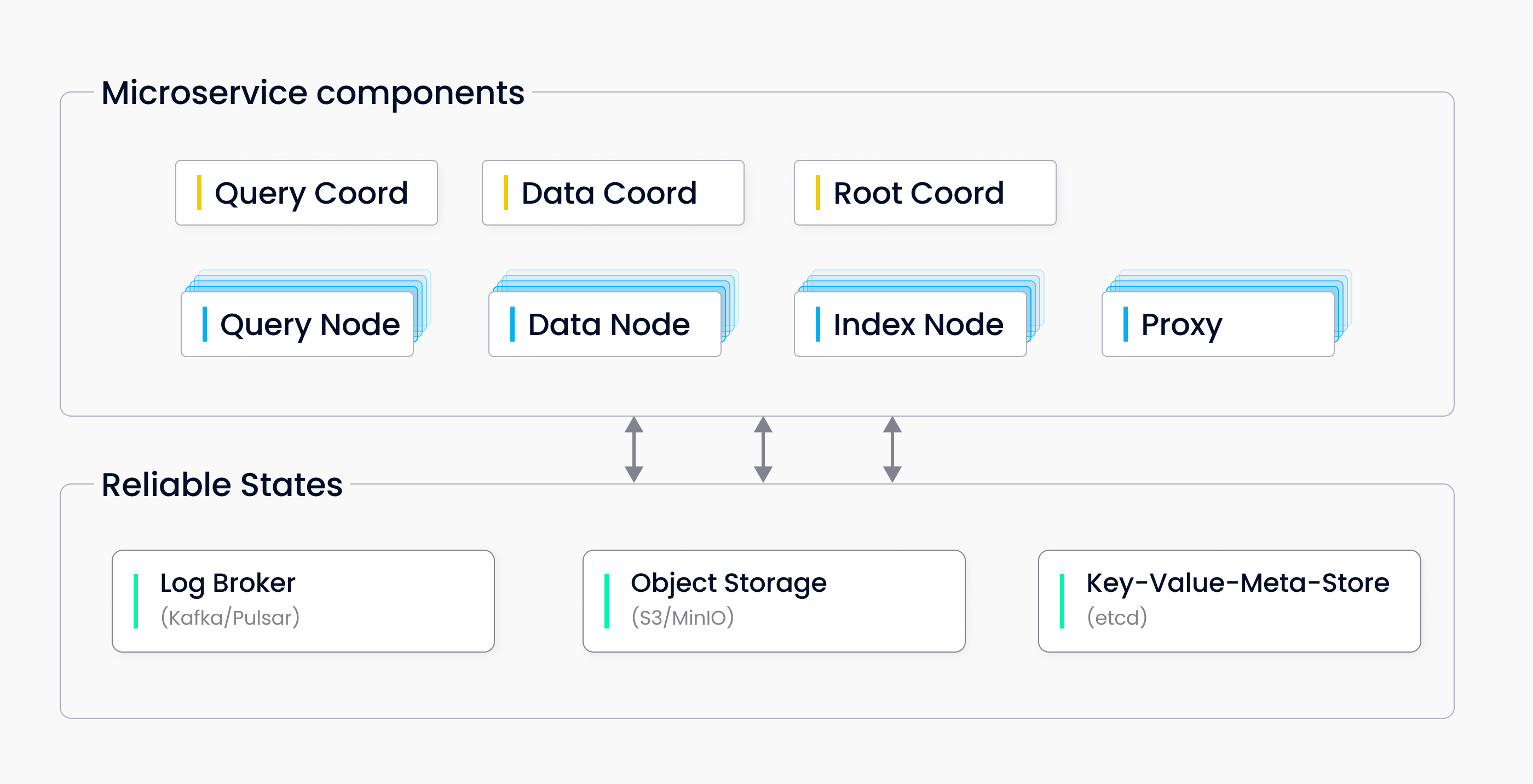
Milvus 采用共享存储架构,遵循计算与存储分离的设计原则。它的架构由四层组成:接入层、协调服务、工作节点和存储层。通过这种设计,各个层在扩展或灾难恢复时可以独立运作。
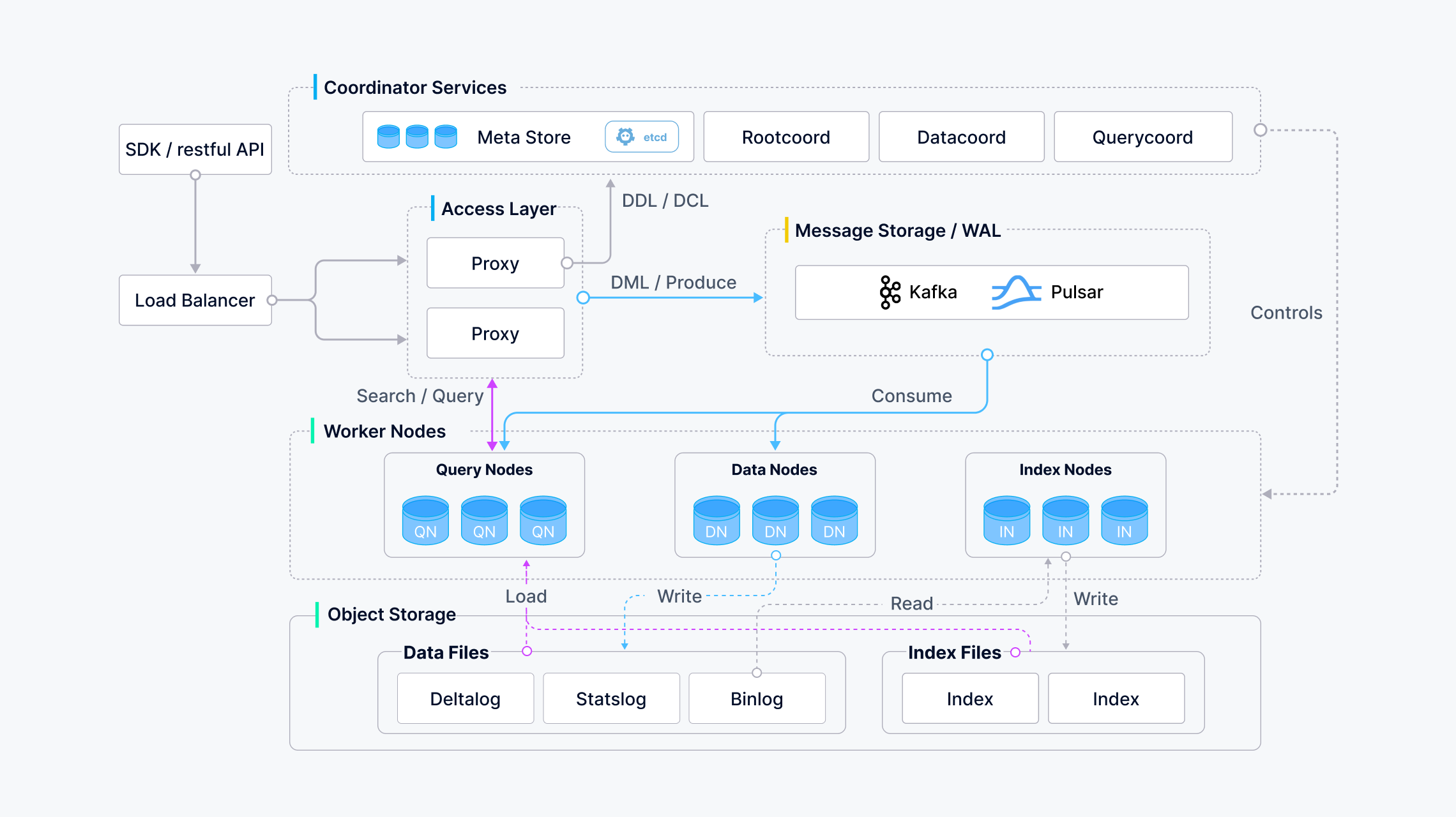
1. 接入层
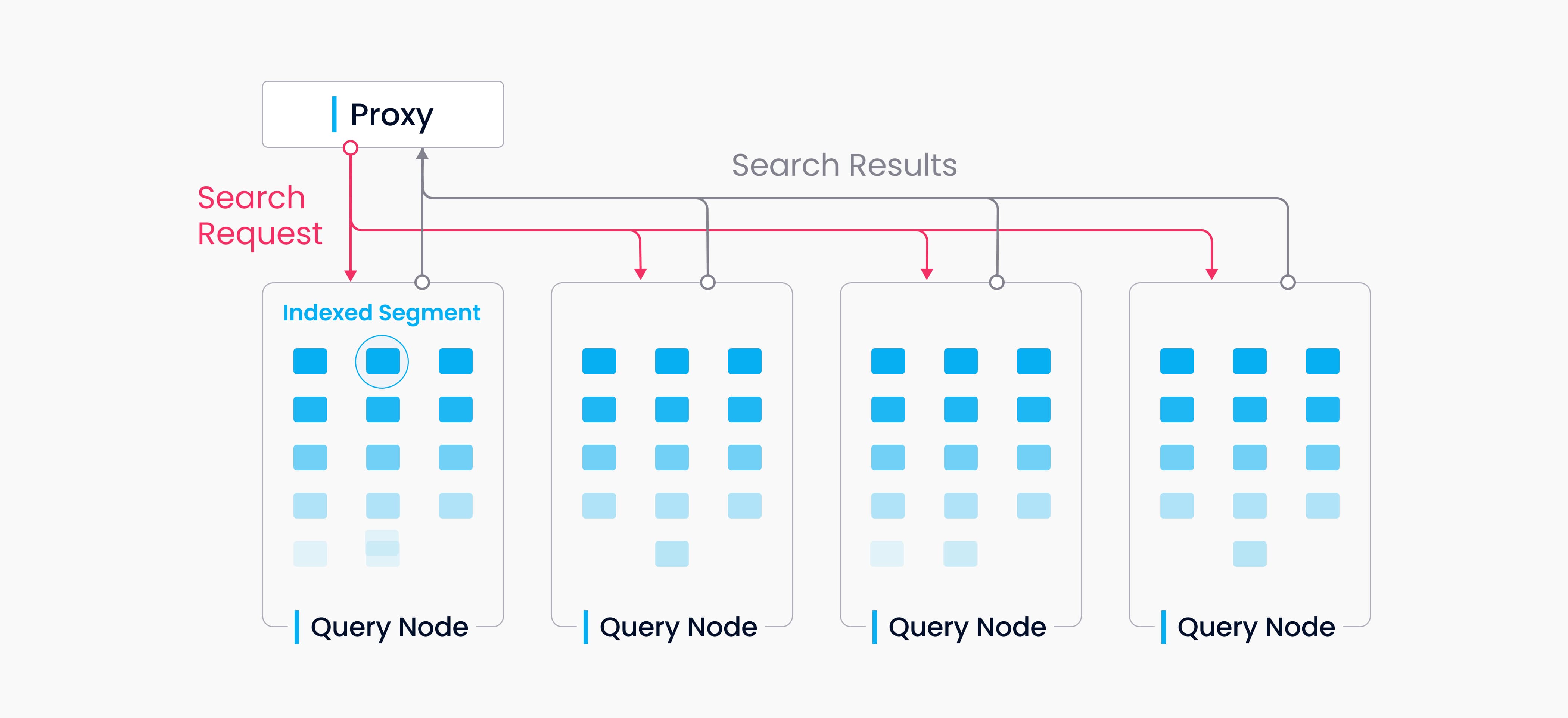
接入层是用户与系统交互的入口。该层由一组无状态的代理组成,负责验证客户端请求并返回搜索结果。其功能包括:
- 代理无状态:使用 Nginx、Kubernetes Ingress、NodePort 和 LVS 等负载均衡组件提供统一服务地址。
- 大规模并行处理(MPP)架构:代理会对中间结果进行汇总和后处理,并将最终结果返回给客户端。
2. 协调服务
协调服务是系统的"大脑",负责将任务分配给工作节点。其任务包括集群拓扑管理、负载均衡、时间戳生成、数据管理等。协调器分为三种类型:
- 根协调器(Root Coordinator):处理 DDL 和 DCL 请求,管理时间戳 Oracle(TSO)等。
- 查询协调器(Query Coordinator):负责查询节点的拓扑管理和负载均衡。
- 数据协调器(Data Coordinator):管理数据节点和索引节点的拓扑结构,触发数据刷新、压缩和索引构建。
3. 工作节点
工作节点是系统的"手"和"脚",负责执行来自代理的 DML 命令。由于存储和计算分离,工作节点是无状态的,因此可以灵活扩展和灾难恢复。工作节点包括:
- 查询节点:订阅增量日志数据,运行向量和标量数据之间的混合搜索。
- 数据节点:处理数据插入、更新等操作,将日志数据快照存储在对象存储中。
- 索引节点:负责索引构建。
4. 存储层
存储层是系统的"骨架",负责数据的持久性。包括以下子模块:
- 元存储:用于存储元数据,如集合模式和消息检查点。Milvus 使用 etcd 作为元存储,确保高可用性和强一致性。
- 对象存储:用于存储日志快照文件、索引文件和中间查询结果。Milvus 支持 MinIO、AWS S3 和 Azure Blob 作为对象存储。
- 日志代理 :负责日志的持久化和发布-订阅服务。Milvus 集群使用 Pulsar 作为日志代理,单机版使用 RocksDB。
数据处理流程
Milvus 的数据处理包括数据插入、索引建立和数据查询三个关键步骤。
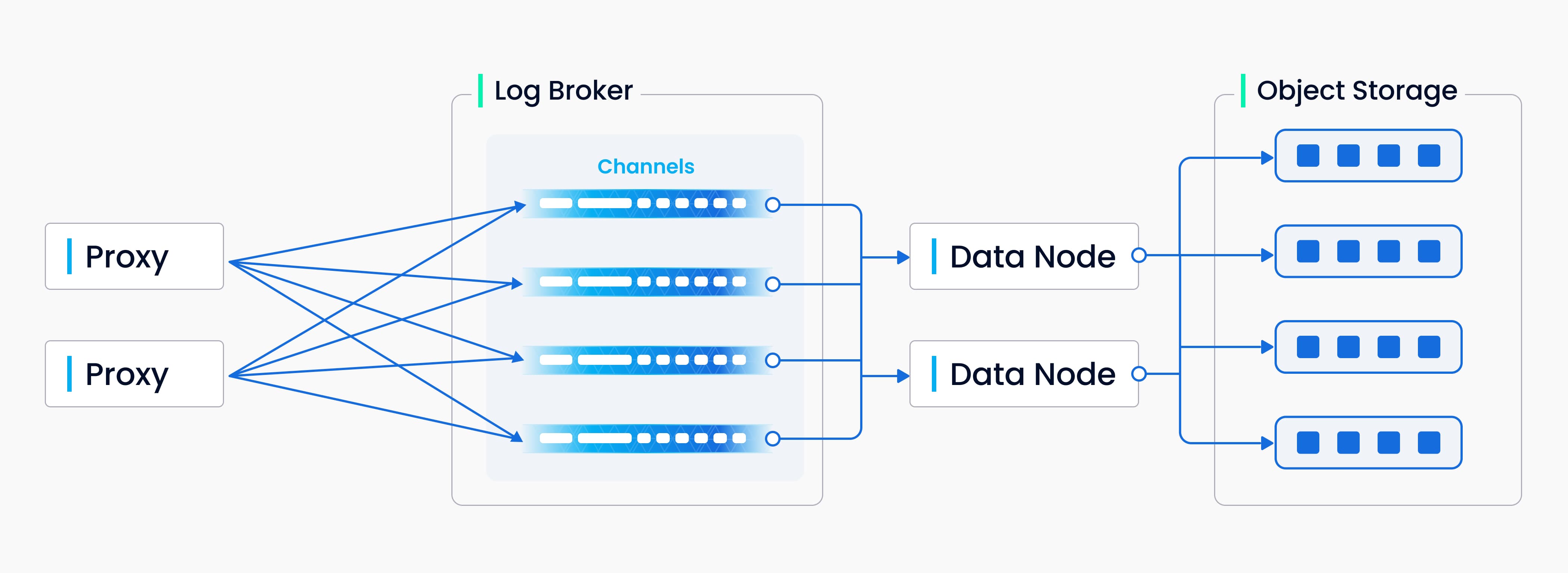
1. 数据插入
每个集合可以分为若干分片,每个分片对应一个虚拟通道(vChannel)。插入或删除请求根据主键的哈希值路由到不同的分片,代理会为每个请求分配时间戳,确保数据请求的顺序正确。DML 请求会写入日志序列,并最终由数据节点处理并存储。
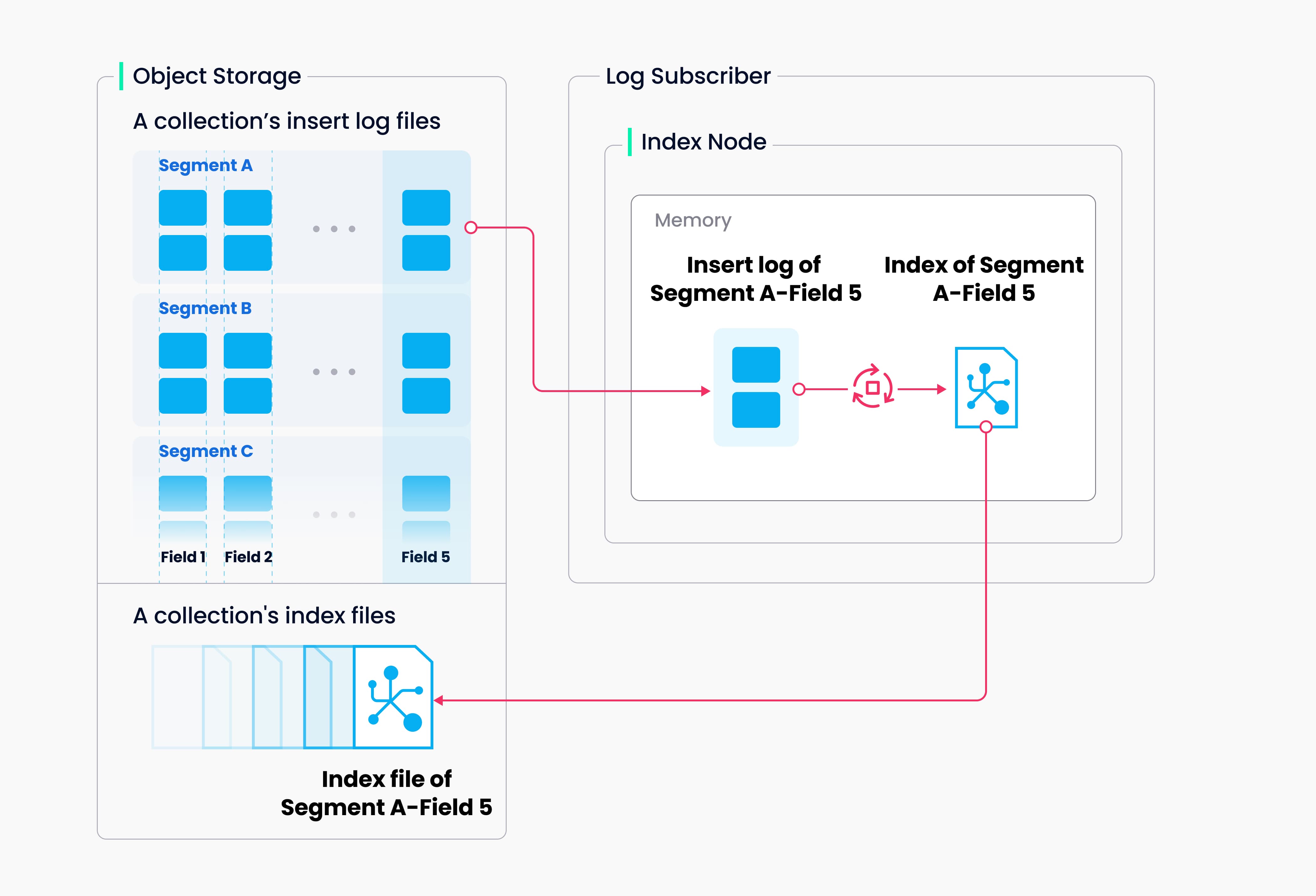
2. 索引构建
Milvus 通过索引节点构建索引,每个集合分为多个分段,每个分段都有自己的索引。索引构建过程中需要加载日志快照,将其反序列化为向量数据,并进行训练后建立索引。索引构建是一个计算和内存密集型操作,常用 K-means 或图遍历等技术加速处理。
3. 数据查询
查询节点从对象存储中加载索引,并对指定的集合进行向量搜索。搜索请求会并发分发给所有查询节点,每个节点独立处理搜索请求,最后由代理汇总并返回最终结果。
Knowhere:核心向量执行引擎
Knowhere 是 Milvus 的核心向量执行引擎,支持异构计算。它集成了多个向量搜索库,如 Faiss、Hnswlib 和 Annoy,并根据硬件选择最适合的计算方式(如 SIMD 指令)。Knowhere 支持多种性能优化,包括比特集机制(实现软删除)、二进制向量索引和 SIMD 指令集优化等。
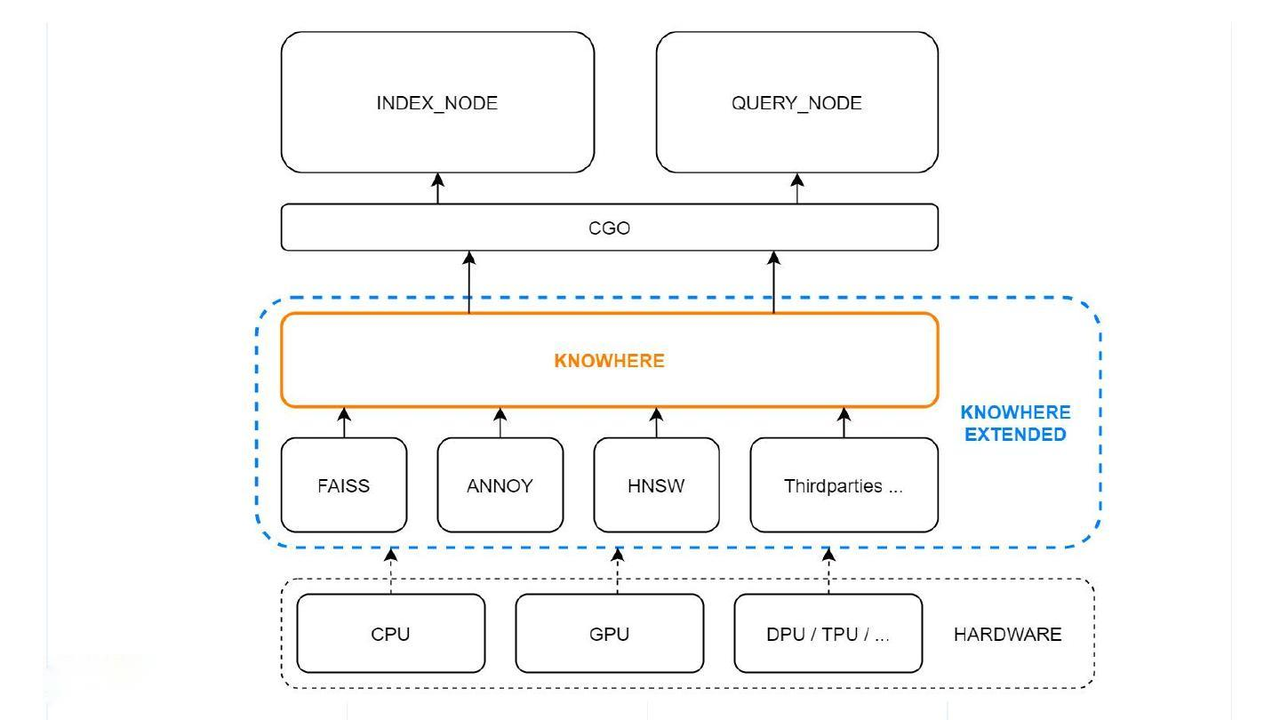
Knowhere 的代码结构
Knowhere 中的主要计算涉及向量操作,其索引建立流程包括四个步骤:创建索引、训练数据、插入数据和建立索引。Knowhere 支持多种索引类型,如 IVF、HNSW、Annoy 等。此外,Knowhere 还支持自动选择合适的 SIMD 指令,以优化查询和索引构建的性能。
总结
Milvus 通过其共享存储架构、无状态工作节点和多层设计,实现了大规模密集向量数据的高效处理和查询。其灵活的架构不仅支持多种向量搜索库,还能根据不同硬件环境进行优化,确保性能的最大化。通过合理利用 Kubernetes 进行部署,Milvus 可以轻松应对各种数据量和查询场景的需求。
附录1:应用技术介绍
1. etcd
etcd 是一个分布式键值存储系统,专门用于存储和共享数据,特别适合在分布式系统中作为元数据存储和服务注册使用。它通过 Raft 共识算法保证高可用性和强一致性,使其非常适合用于分布式系统的配置管理、服务发现、分布式锁等场景。
- 高可用性:etcd 使用 Raft 算法,提供分布式系统中数据的强一致性,即使在网络分区或节点故障时,也能保证数据一致。
- 服务发现:etcd 通过其键值存储,允许系统中的服务注册自己并相互发现。这对于分布式系统中的自动化扩展和动态配置非常重要。
- 数据持久性:etcd 支持数据的持久化,适合用作系统的配置存储、元数据存储等场景。它的事务支持确保了操作的原子性。
常用场景:
- Kubernetes 使用 etcd 作为其集群数据的存储系统。
- 在 Milvus 中,etcd 用于存储系统的元数据(如集合模式、消息检查点等),并且提供服务注册和健康检查。
2. MinIO
MinIO 是一款高性能的对象存储系统,完全兼容 Amazon S3 API,旨在处理大量非结构化数据(如图片、视频、备份文件等)。它特别擅长在私有云和本地存储环境中提供与 AWS S3 相似的对象存储功能。
- 兼容性:MinIO 提供与 AWS S3 API 兼容的接口,应用程序可以使用标准 S3 客户端与 MinIO 进行交互,无需修改代码。
- 性能优越:MinIO 针对高速对象存储进行了优化,特别是对大规模并行请求的处理能力。
- 轻量级和可扩展性:MinIO 是一个轻量级的存储解决方案,可以在较小的计算资源下运行,但它也支持水平扩展,以应对更大的存储需求。
常用场景:
- 私有云环境中提供类似 AWS S3 的对象存储。
- 用于存储非结构化数据的集群架构中,比如 Milvus 的对象存储层。
3. AWS S3
AWS S3(Amazon Simple Storage Service) 是 Amazon Web Services 提供的对象存储服务,是世界上最受欢迎的云存储服务之一。S3 适合存储任何规模的文件,并通过 REST API 提供高可用的存储解决方案。
- 可扩展性和高可用性:AWS S3 提供几乎无限的存储空间,能够自动扩展以处理海量数据。S3 背后的架构可以容忍多个数据中心的故障,确保数据的高可用性。
- 安全性和权限控制:通过提供精细的权限控制机制(如基于 IAM 角色的权限、存储桶策略、对象级别的权限等),S3 允许对存储的对象进行严格的访问控制。
- 按需定价:S3 根据存储的数据量和 API 调用频率收费,按使用付费,非常适合具有弹性需求的应用场景。
常用场景:
- 存储备份数据、媒体文件、大数据分析结果等。
- 用于静态网站托管或内容分发网络(CDN)。
- Milvus 可以选择将对象存储部分托管在 AWS S3 上,进行数据的持久化和索引管理。
4. Azure Blob
Azure Blob 存储 是 Microsoft Azure 提供的对象存储服务,适用于存储大量非结构化数据。Blob 是 Binary Large Object 的缩写,意味着 Azure Blob 可以存储任何类型的数据,如文档、图片、视频等。
- 对象存储模型:Azure Blob 提供三种存储模式:块 Blob、追加 Blob 和页 Blob。块 Blob 是最常见的存储类型,通常用于存储视频、图片和文档等数据。追加 Blob 则适合日志数据的存储,页 Blob 则用于大规模随机访问数据。
- 全球分布和冗余:Azure Blob 可以在全球多个数据中心间复制数据,支持区域冗余存储(ZRS)、本地冗余存储(LRS)和异地冗余存储(GRS)等多种冗余模式,确保数据安全和可访问性。
- 与 Azure 生态系统集成:作为 Microsoft Azure 云的一部分,Blob 存储可以无缝地与其他 Azure 服务集成,如虚拟机、容器、数据湖等。
常用场景:
- 存储数据备份、大文件、日志数据等。
- 作为大数据分析、机器学习工作流的输入数据存储。
- Milvus 可以使用 Azure Blob 来托管其对象存储层的数据。
5. Pulsar
Apache Pulsar 是一个分布式的、原生支持多租户的消息队列和流处理平台。它具备消息的发布-订阅机制,允许消息在不同的生产者和消费者之间传递。Pulsar 具有高可用性、低延迟和水平扩展能力,非常适合用于处理实时数据流。
- 多租户架构:Pulsar 设计支持多租户,这使得它能够在单个集群中支持多个独立的应用或团队,具有很好的隔离性。
- 消息队列和流处理:Pulsar 同时支持队列模式和流处理模式,用户可以根据需求选择不同的消息处理模式。
- 持久性和高可用性:Pulsar 内置了持久化存储机制,能够保证消息的持久性和高可用性。它还提供了多副本容错机制,在系统出现故障时也能保证消息数据不会丢失。
常用场景:
- 实时消息处理,如物联网数据、金融交易日志的处理。
- Milvus 中使用 Pulsar 作为日志代理,确保数据流的持久性和事件通知机制。
6. RocksDB
RocksDB 是一个高性能的嵌入式键值存储系统,基于 LSM 树结构。它由 Facebook 开发,用于需要高写入性能的场景,如持久化缓存、流式数据处理、区块链等。
- LSM 树存储引擎:RocksDB 使用 LSM(Log-Structured Merge Tree)结构,这使得它非常适合高写入密集型的工作负载。LSM 树通过批量写入和合并操作优化了磁盘 IO 性能。
- 持久化和快速读写:RocksDB 支持持久化的键值对存储,并且能够在 SSD 等硬件上实现非常高的读写性能。
- 内嵌式存储:RocksDB 通常作为嵌入式数据库与应用一起运行,应用可以直接与其进行交互,而不需要通过网络协议访问外部数据库。
常用场景:
- 高性能缓存、流处理、日志持久化。
- 在 Milvus 单机版中,RocksDB 作为日志代理使用,提供本地持久化服务。
附录2:MinIO实例
以下是一个 MinIO 安装和使用的详细步骤示例,适用于本地部署环境(Linux 环境为例)。
1. 安装 MinIO
a. 下载 MinIO 服务器二进制文件
你可以直接从 MinIO 官方网站下载最新版的 MinIO 服务器二进制文件:
bash
wget https://dl.min.io/server/minio/release/linux-amd64/miniob. 给二进制文件添加执行权限
下载完成后,需要给 MinIO 二进制文件添加执行权限:
bash
chmod +x minioc. 启动 MinIO 服务器
启动 MinIO 服务器时,需要指定一个目录来存储数据,例如 /mnt/data 目录。如果你还没有该目录,可以先创建一个:
bash
mkdir -p /mnt/data启动 MinIO 服务器:
bash
./minio server /mnt/data此命令将在本地启动一个 MinIO 服务器,并将数据存储在 /mnt/data 目录下。默认情况下,MinIO 服务会运行在 9000 端口,你可以通过 http://127.0.0.1:9000 访问它。
启动后,你会看到类似如下的信息:
bash
Endpoint: http://127.0.0.1:9000 http://192.168.1.100:9000
AccessKey: YOUR-ACCESS-KEY
SecretKey: YOUR-SECRET-KEY
Region: us-east-1
SQS ARNs: <none>记下这些信息中的 AccessKey 和 SecretKey,因为你稍后需要使用它们进行身份验证。
2. 访问 MinIO 控制台
打开浏览器,访问 http://127.0.0.1:9000,你会看到 MinIO 的登录界面。使用刚刚在终端中显示的 AccessKey 和 SecretKey 登录。
登录成功后,进入 MinIO 的 Web 控制台,你可以在这里管理存储桶和对象文件。
3. 使用 mc(MinIO Client)与 MinIO 交互
MinIO 提供了一个名为 mc 的客户端工具,用于与 MinIO 服务器进行交互。你可以使用 mc 进行对象存储的管理操作,如创建存储桶、上传文件等。
a. 下载 mc 客户端
bash
wget https://dl.min.io/client/mc/release/linux-amd64/mcb. 给 mc 文件添加执行权限
bash
chmod +x mcc. 配置 mc 客户端
在配置之前,你需要为 MinIO 添加一个别名。运行以下命令,指定你的 MinIO 服务地址、AccessKey 和 SecretKey:
bash
./mc alias set myminio http://127.0.0.1:9000 YOUR-ACCESS-KEY YOUR-SECRET-KEY这里的 myminio 是你为 MinIO 服务设置的别名。
d. 创建存储桶
你可以通过以下命令创建一个存储桶:
bash
./mc mb myminio/mybuckete. 上传文件到存储桶
将本地文件上传到刚刚创建的存储桶:
bash
./mc cp /path/to/yourfile.txt myminio/mybucketf. 列出存储桶中的对象
列出存储桶中的对象:
bash
./mc ls myminio/mybucketg. 下载文件
从存储桶下载文件:
bash
./mc cp myminio/mybucket/yourfile.txt /path/to/local/directory/4. MinIO 访问策略
MinIO 允许你为存储桶设置访问策略。例如,可以将存储桶设为公开访问,允许所有人读取存储桶内的文件。
a. 设置公开访问策略
将存储桶 mybucket 设置为公开可读:
bash
./mc policy set public myminio/mybucket5. 通过 S3 API 进行操作
MinIO 是兼容 S3 的对象存储,因此你可以使用 S3 SDK 与 MinIO 进行交互。
a. Python 示例
安装 boto3(Python 的 S3 SDK):
bash
pip install boto3以下是一个简单的 Python 示例,用于上传文件到 MinIO:
python
import boto3
from botocore.client import Config
# 创建 S3 客户端
s3 = boto3.client('s3',
endpoint_url='http://127.0.0.1:9000',
aws_access_key_id='YOUR-ACCESS-KEY',
aws_secret_access_key='YOUR-SECRET-KEY',
config=Config(signature_version='s3v4'),
region_name='us-east-1')
# 上传文件到存储桶
s3.upload_file('local_file.txt', 'mybucket', 'remote_file.txt')这个例子使用了 boto3 连接到 MinIO,上传本地文件到 mybucket 存储桶中。
6. 停止 MinIO 服务
如果你需要停止 MinIO 服务器,可以使用以下命令终止进程:
bash
pkill minio