之前在《gpt-oss系列模型初探》介绍了GPT-OSS的相关内容,接下来个人尝试做了部署和测试,也遇到一些坑。
1. vllm部署遇坑
硬件条件:A800 / 4090 D
首先120B的模型参数大小在61G,所以A800一块卡或者4090D 4块卡就可以部署。
由于gpt-oss-120b模型使用MoE层的原生MXFP4精度进行训练,所以不能直接用vllm来部署,会报类型的错误:
Unknown quantization method: mxfp4. Must be one of 'aqlm', 'awq', 'deepspeedfp', 'tpu_int8', 'fp8', 'ptpc_fp8', 'fbgemm_fp8', 'modelopt', 'modelopt_fp4', 'marlin', 'bitblas', 'gguf', 'gptq_marlin_24', 'gptq_marlin', 'gptq_bitblas', 'awq_marlin', 'gptq', 'compressed-tensors', 'bitsandbytes', 'qqq', 'hqq', 'experts_int8', 'neuron_quant', 'ipex', 'quark', 'moe_wna16', 'torchao', 'auto-round', 'rtn', 'inc'
所以,官方给的vllm部署指令如下,推出了针对MXFP4的版本:
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
但是用官方的部署方案,依然报错,因为这个版本主要针对H系列的卡。

所以在4090系列、5090系列、A系列上都可能会遇到FlashAttention-3的问题:
Bug: gpt-oss -> FA3 not detected on RTX 5090 (Blackwell) -- Sinks are only supported in FlashAttention 3 #22279
issue链接:https://github.com/vllm-project/vllm/issues/22279
Bug: vllm/vllm-openai:gptoss AssertionError: Sinks are only supported in FlashAttention 3 (4090 48gb) #22331
issue链接:https://github.com/vllm-project/vllm/issues/22331
Bug: openai/gpt-oss-120b can't run on A100
而FlashAttention-3 是专为 Hopper GPU优化的版本,所以暂时没有更合适的方案。也尝试切换Attention版本:VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1,但推理的时候还是会报错。
所以暂时放弃使用vllm部署的方案,等官方推出更适配的版本,vllm官方提到正在推进wheel版本的更新。
2. Ollama部署
使用ollama部署,相对来说更顺滑。同样在4090 D机器上进行实验。需要使用最新版本0.11.4,只有新版本才能顺利拉取gpt-oss-120b模型。
推荐使用docker方式部署ollama。
一开始是通过发行版本部署,也就是将ollama-linux-amd64.tgz下载后解压,然后将lib和bin文件分别移动到/usr/local/lib 以及 /usr/local/bin目录下,然后执行ollama -v来验证部署是否成功。
接下来通过ollama serve启动服务,再通过ollama run gpt-oss:120b执行,是可以正常服务。

但是发现这种方式,ollama只能使用cpu推理,gpu 卡是一点都没有被利用。
网上也有很多人反馈ollama利用gpu的问题。所以只能切换到docker的模式部署做尝试。部署链路如下:
测试镜像能否识别GPU
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
镜像ollama拉取
docker pull ollama/ollama
启动镜像
docker run --gpus \"device=0,1,2,3,4,5,6,7 \" -d -v /data/shamodels/ollama_models:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
API调用ollama服务
curl http://localhost:11434/api/chat -d '{
"model": "gpt-oss:120b",
"messages": [
{ "role": "user", "content": "帮我写一篇100字探险小说" }
]
}'
生成结果:
夜色笼罩山谷,李航踏上古木桥,心跳如鼓。前方雾气翻滚,传来远古号角声。他拔剑冲锋,穿过荆棘,终于看到闪耀的金色城门,入口处刻着'勇者归来'四字。他跨步进入,发现内部有雕像与沉睡的巨龙勇气试炼才刚开始。
这样可以正常使用GPU资源
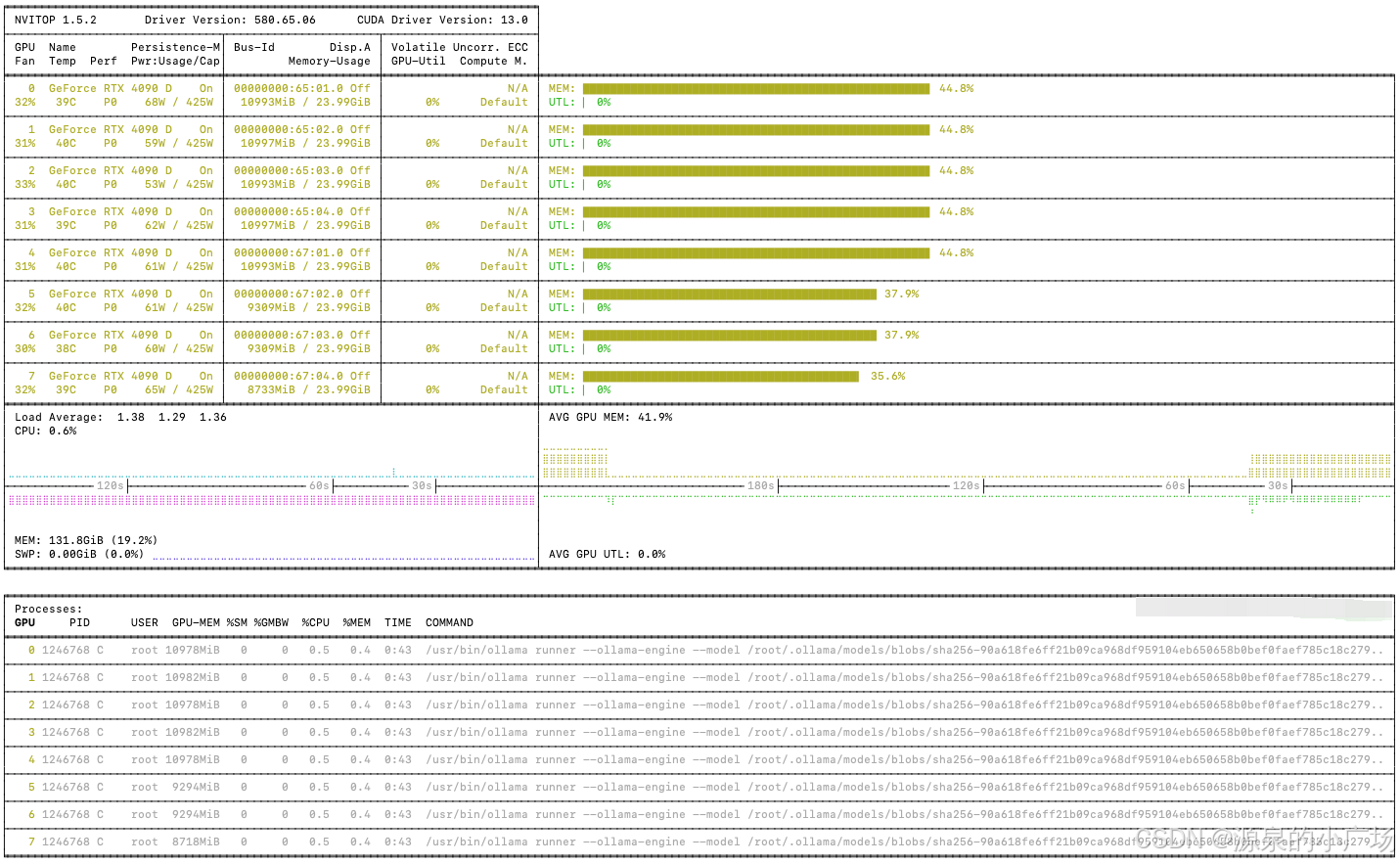
推理结果(由于激活参数只有5.1B,因此推理速度挺高,在30并发下生成速度可以达到 50+ token/s)。
另外ollama还有个有趣的现象,当长时间没有调用接口,会自动释放显存。当有新的请求进来,会快速load模型参数进行推理。
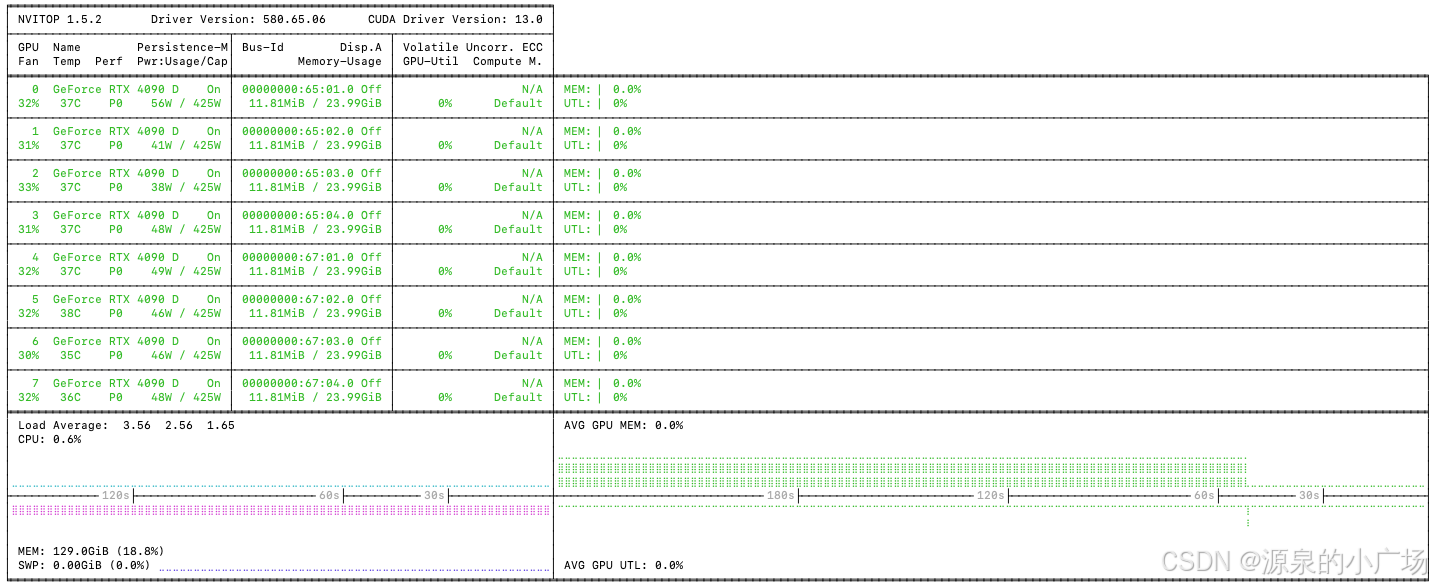
接口并发测试采用modelscope推出的evalscope:
bash
evalscope perf \
--url "http://IP:11434/v1/completions" \
--parallel 30 \
--model gpt-oss:120b \
--number 30 \
--api openai \
--dataset speed_benchmark \
--stream