1. 向量化检索的核心:从文本到数字的魔法
向量化数据检索,听起来是不是有点像科幻小说里的黑科技?其实,它的核心思想简单得让人拍大腿:把复杂的数据变成数字表示,然后用数学方法快速找到最相似的答案。这就像把一堆杂乱的书塞进一个超级聪明的图书馆管理员脑子里,他能瞬间告诉你哪本书最符合你的需求。
为什么向量化这么重要?
在开发大模型Agent时,数据检索是绕不过去的坎儿。无论是回答用户问题、提供上下文,还是驱动推荐系统,Agent都需要从海量数据中迅速挖出有用的信息。传统关键字搜索已经out了,向量化检索能捕捉语义的细微差别,比如"苹果"和"水果"之间的联系,或者"跑步"和"运动"的近义关系。这背后靠的是嵌入(embedding)技术,把文本、图像甚至音频变成高维向量,然后通过距离计算找到最相近的内容。
理论基础:嵌入的数学之美
嵌入的核心是把数据映射到高维空间。比如,一个句子"今天天气很好"可能被编码成一个768维的向量(比如BERT模型的输出)。这些向量有个神奇的特点:语义相近的内容,距离也近。我们常用余弦相似度或欧几里得距离来衡量两个向量的"亲密程度":
-
余弦相似度 :计算两个向量夹角的余弦值,值越接近1,说明越相似。公式是:
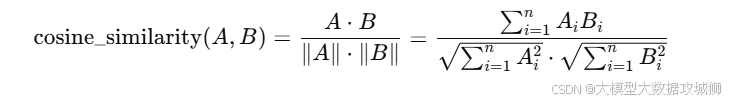
-
欧几里得距离 :直接算向量之间的直线距离,距离越小越相似。公式是:
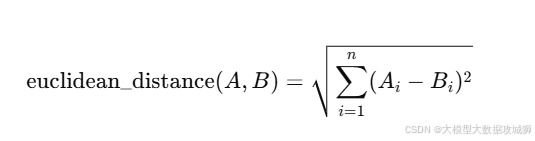
实例:从零开始的文本嵌入
假设你正在开发一个问答Agent,用户输入"如何提高跑步速度"。你需要从知识库里找相关内容。第一步是用预训练模型(比如Sentence-BERT)把用户问题和知识库里的文档都编码成向量。代码示例如下(用Python和Hugging Face的transformers库):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
query = "如何提高跑步速度"
docs = ["跑步技巧:提高速度的5个方法", "如何增强耐力", "饮食对运动的影响"]
query_embedding = model.encode(query)
doc_embeddings = model.encode(docs)接下来,计算查询向量和文档向量之间的相似度,选出最匹配的文档。这部分我们稍后会深入展开。
小贴士:选择合适的嵌入模型
-
轻量模型:如all-MiniLM-L6-v2,速度快,适合实时应用。
-
重型模型:如BERT或RoBERTa,精度高,但计算成本大。
-
多语言支持:如果你的Agent需要处理中文、日文等,选择支持多语言的模型,比如mBERT或XLM-R。
2. 数据预处理:让向量更"聪明"
向量化检索的成败,很大程度上取决于数据质量。你不能指望把一堆乱七八糟的文本扔给模型,然后祈祷它给你完美的结果。数据预处理就像给Agent的知识库做一次彻底的"大扫除"。
文本清洗的艺术
-
去除噪声:HTML标签、特殊字符、拼写错误都得清理。比如,中文文本里的全角标点(。、,)最好统一成半角(.,)。
-
分词 :中文不像英文有天然的空格分隔,分词是关键。用jieba或thulac这样的工具,能把"今天天气很好"切成"今天/天气/很/好"。分词质量直接影响嵌入效果。
-
去停用词:像"的"、"是"这样的词在中文里很常见,但对语义贡献不大,可以过滤掉。
实例:中文文本预处理
假设你的知识库里有篇文档:"跑步是一项非常棒的运动,能够增强心肺功能。"我们用Python和jieba来处理:
import jieba
text = "跑步是一项非常棒的运动,能够增强心肺功能。"
# 分词
words = jieba.cut(text)
# 去停用词
stopwords = {'是', '的', '非常', '能够'}
cleaned_words = [w for w in words if w not in stopwords]
# 结果:['跑步', '一项', '棒', '运动', '增强', '心肺', '功能']结构化数据如何向量化?
如果你的知识库包含表格、JSON等结构化数据怎么办?别慌! 可以把结构化数据"翻译"成自然语言。比如,一个JSON对象:
{
"title": "跑步技巧",
"content": "每天跑5公里可以提高耐力"
}可以转成:"标题:跑步技巧。内容:每天跑5公里可以提高耐力。"然后再用嵌入模型编码。
小贴士:批量处理优化
-
批量编码:一次性编码多条文本,比逐条编码快得多。Sentence-BERT支持批量处理,记得设置batch_size。
-
缓存嵌入:如果知识库内容不常变,预先算好嵌入并存到数据库,查询时直接加载,省时省力。
3. 索引构建:让检索快如闪电
有了高质量的向量,接下来是索引 ,也就是如何高效存储和查询这些向量。想象一下,知识库里有1000万条文档,每条都对应一个768维向量。如果每次查询都全量扫描,Agent估计得"累瘫"。所以,高效索引是向量化检索的灵魂。
近似最近邻(ANN)检索
全量计算相似度太慢,我们需要近似最近邻(ANN)算法。ANN牺牲一点精度,换来速度的大幅提升。常用算法包括:
-
HNSW(层次导航小世界):速度和精度平衡好,Faiss库的首选。
-
IVF(倒排文件):适合超大规模数据集,分块存储向量。
-
PQ(乘积量化):通过压缩向量降低内存占用,适合资源受限场景。
实例:用Faiss构建索引
Faiss是Facebook开源的向量检索神器,简单易用。以下是一个用Faiss构建HNSW索引的例子:
import faiss
import numpy as np
# 假设doc_embeddings是文档的向量,形状为(n, 768)
index = faiss.IndexHNSWFlat(768, 32) # 768是向量维度,32是HNSW参数
index.add(doc_embeddings) # 添加向量到索引
# 查询
k = 5 # 返回Top-5结果
distances, indices = index.search(query_embedding[np.newaxis, :], k)小贴士:索引优化
-
调整HNSW参数:增大M(连接数)提高精度,但会增加内存和构建时间。
-
量化压缩:用IndexIVFPQ可以大幅减少内存占用,适合嵌入维度高的场景。
-
GPU加速:Faiss支持GPU,查询速度能提升10倍以上,但需要兼容的硬件。
4. 检索后处理:让结果更精准
找到Top-K个候选结果只是第一步,后处理能让你的Agent从"还行"变成"惊艳"。后处理的目的是过滤噪声、重新排序,甚至融合多模态信息。
重新排序(Re-ranking)
ANN检索返回的结果不一定完美,可以用更精确的模型重新排序。比如,用一个跨编码器(cross-encoder)模型,输入查询和候选文档,计算更精准的相似度分数:
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
pairs = [(query, docs[i]) for i in indices[0]]
scores = cross_encoder.predict(pairs)
# 根据分数重新排序
sorted_results = [docs[i] for i in np.argsort(scores)[::-1]]过滤与阈值
设定相似度阈值,过滤掉无关结果。比如,只保留余弦相似度>0.8的文档。这样可以避免Agent返回一堆"似是而非"的答案。
多模态融合
如果你的Agent需要处理图像+文本,可以把图像和文本的嵌入向量拼接,或者用CLIP模型生成统一的多模态嵌入。CLIP的中文支持也不错,比如openai/clip-vit-base-patch32。
小贴士:后处理的取舍
-
速度 vs 精度:跨编码器精度高但慢,适合对结果质量要求高的场景。
-
动态阈值:根据查询的复杂程度动态调整阈值,比如简单查询用高阈值,复杂查询用低阈值。
5. 实时更新:让向量索引"活"起来
知识库不是一成不变的石头,它得像个活物,能随时呼吸新鲜数据。用户可能上传新文档,编辑旧内容,或者删除过时的条目。如果你的向量索引不能跟上这些变化,Agent的回答迟早会变成"昨天的黄花"。所以,动态维护索引是向量化检索系统的一个硬核挑战。
增量索引的艺术
与其每次都重建整个索引(那得慢到让人抓狂),不如用增量更新。Faiss支持动态添加和删除向量,但要小心,频繁操作可能会让索引结构变"乱"。以下是增量添加的例子:
import faiss
import numpy as np
# 假设已有HNSW索引
index = faiss.IndexHNSWFlat(768, 32)
# 新增文档
new_docs = ["如何选择跑鞋", "夜跑的注意事项"]
new_embeddings = model.encode(new_docs)
index.add(new_embeddings) # 直接追加到索引删除就稍微麻烦点,Faiss的HNSW索引不支持直接删除。你得记录每个向量的ID,重建索引时剔除不需要的ID:
# 假设每个向量有唯一ID
index = faiss.IndexIDMap(faiss.IndexHNSWFlat(768, 32))
ids = np.array([1001, 1002]) # 新文档的ID
index.add_with_ids(new_embeddings, ids)
# 删除ID为1001的向量
index.remove_ids(np.array([1001]))定时刷新 vs 实时更新
-
定时刷新:每隔一段时间(比如每天凌晨)重建索引,适合数据更新不频繁的场景。好处是索引结构更优,查询效率高。
-
实时更新:适合高动态场景,比如用户实时上传内容的社交平台。但要小心索引碎片化,可能需要定期"整理"。
小贴士:动态更新的优化
-
批量更新:攒一批更新再操作,减少索引锁定的时间。
-
版本控制:给索引加版本号,更新时切换到新版本,避免查询中断。
-
监控性能:用index.ntotal检查索引大小,确保内存不被撑爆。
6. 分布式检索:征服海量数据
当你的知识库大到像个"数据海洋",单机索引可能直接"翻船"。分布式检索是解救方案,让你的Agent在千万级甚至亿级向量中依然游刃有余。
分布式索引的架构
分布式检索通常把索引分成多个分片(shards),分布在不同机器上。查询时,Agent向所有分片发送请求,合并结果后返回。常见框架有:
-
Elasticsearch:支持向量搜索(需要插件),适合混合文本和向量检索。
-
Milvus:专为向量检索设计,支持分布式部署,性能强劲。
-
Faiss + 自定义分片:如果你想完全掌控,Faiss可以手动分片,配合消息队列(如Kafka)实现分布式查询。
实例:用Milvus实现分布式检索
Milvus是个开源的向量数据库,专为海量向量检索优化。以下是基本用法:
from pymilvus import connections, Collection
# 连接Milvus服务器
connections.connect(host='localhost', port='19530')
# 创建集合
collection = Collection('docs')
# 插入向量
collection.insert([new_embeddings, ids])
# 查询
results = collection.search(data=query_embedding, anns_field='embedding', param={"metric_type": "L2", "params": {"nprobe": 10}}, limit=5)负载均衡与容错
-
分片策略:按数据类型或语义分片,比如把"运动"相关文档放一个分片,"饮食"放另一个。
-
副本机制:每个分片多存几份副本,防止单点故障。
-
动态扩展:用Kubernetes等工具,自动根据负载增减节点。
小贴士:分布式系统的坑
-
一致性问题:分布式环境下,更新可能有延迟,考虑用"最终一致性"模型。
-
网络开销:查询所有分片会增加延迟,尽量减少跨节点通信。
-
监控工具:用Prometheus+Grafana监控查询延迟和分片健康状态。
7. 评估与优化:如何知道你的检索"行不行"
做完检索系统,你总得知道它到底好不好用吧?评估 就像给Agent做个体检,找出问题,优化疗效。向量化检索的评估主要看精度 和速度。
评估指标
-
召回率(Recall@K) :Top-K结果里包含多少相关文档。公式是:

-
精确率(Precision@K):Top-K结果里相关文档的比例。
-
平均倒排秩(MRR):衡量第一个相关结果的排名,适合问答场景。
-
查询延迟:从输入查询到返回结果的时间,实时应用一般要求<100ms。
构建评估数据集
你需要一个标注数据集,包含查询和对应的相关文档。比如:
-
查询:"如何提高跑步速度"
-
相关文档:"跑步技巧:提高速度的5个方法", "如何选择跑鞋"
-
无关文档:"烹饪意大利面"
可以用人工标注或半自动化方式(比如用已有模型初步筛选,再人工校对)。
优化技巧
-
调参:调整索引参数(如HNSW的M或IVF的nprobe),在精度和速度间找平衡。
-
模型微调:用领域数据微调嵌入模型,比如用跑步相关的问答数据微调Sentence-BERT。
-
缓存热点查询:把常见查询的Top-K结果缓存到Redis,减少重复计算。
实例:计算Recall@5
假设你有100个查询,每个查询有标注的相关文档。以下是Python代码:
def calculate_recall_at_k(predictions, ground_truth, k):
recalls = []
for query_id, true_docs in ground_truth.items():
pred_docs = predictions[query_id][:k]
relevant = len(set(pred_docs) & set(true_docs))
recalls.append(relevant / len(true_docs))
return sum(recalls) / len(recalls)
# 示例数据
ground_truth = {1: ["doc1", "doc2"], 2: ["doc3"]}
predictions = {1: ["doc1", "doc4", "doc5"], 2: ["doc3", "doc6"]}
recall = calculate_recall_at_k(predictions, ground_truth, 5)
print(f"Recall@5: {recall:.3f}")8. 实际案例:打造一个问答Agent的检索模块
理论讲了一堆,实战才是硬道理!让我们来动手做一个问答Agent的检索模块,从数据准备到结果返回,全程走一遍。
场景设定
你的Agent要回答运动相关的问题,知识库有1万条文档(文章、问答、指南)。用户输入:"夜跑有什么注意事项?"
步骤拆解
-
数据预处理:
-
用jieba分词,清理停用词。
-
把文档转成向量,用all-MiniLM-L6-v2模型。
-
-
构建索引:
-
用Faiss的HNSW索引,设置M=32。
-
预计算所有文档的嵌入,存到索引。
-
-
查询处理:
-
对用户输入"夜跑有什么注意事项"编码。
-
用索引检索Top-10候选文档。
-
-
后处理:
-
用跨编码器重新排序。
-
过滤相似度<0.7的文档。
-
-
返回结果:
- 把Top-3文档的内容返回给Agent,用于生成回答。
完整代码
from sentence_transformers import SentenceTransformer, CrossEncoder
import faiss
import jieba
import numpy as np
# 加载模型
embedder = SentenceTransformer('all-MiniLM-L6-v2')
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# 预处理文档
docs = ["夜跑注意事项:穿反光衣,带手电筒", "跑步技巧:提高速度", "饮食建议"]
cleaned_docs = [' '.join([w for w in jieba.cut(doc) if w not in {'的', '是'}]) for doc in docs]
doc_embeddings = embedder.encode(cleaned_docs, batch_size=32)
# 构建索引
index = faiss.IndexHNSWFlat(768, 32)
index.add(doc_embeddings)
# 查询
query = "夜跑有什么注意事项"
cleaned_query = ' '.join([w for w in jieba.cut(query) if w not in {'的', '是'}])
query_embedding = embedder.encode(cleaned_query)
# 检索Top-10
k = 10
distances, indices = index.search(query_embedding[np.newaxis, :], k)
# 重新排序
pairs = [(query, docs[i]) for i in indices[0]]
scores = cross_encoder.predict(pairs)
sorted_indices = indices[0][np.argsort(scores)[::-1]]
top_docs = [docs[i] for i in sorted_indices if scores[i] > 0.7]
print("Top匹配结果:", top_docs)输出示例
Top匹配结果:["夜跑注意事项:穿反光衣,带手电筒"]小贴士:实战中的注意点
-
冷启动:首次构建索引可能很慢,考虑用多线程或分布式计算。
-
错误处理:用户输入可能包含拼写错误,用模糊匹配或纠错模型预处理。
-
多语言支持:如果知识库有英文内容,切换到多语言模型。
9. 常见问题与调试技巧:让你的检索系统少走弯路
打造一个向量化检索系统,就像组装一辆跑车,零件齐全还得调校到位才能飞驰。实际开发中,总会遇到各种"坑",从索引崩盘到结果跑偏。别慌!这一章我们来聊聊常见问题 和调试技巧,帮你的Agent少踩雷。
问题1:检索结果不相关
症状 :用户问"如何挑选跑鞋",结果返回一堆"烹饪食谱"。
原因:
-
嵌入模型不合适:通用模型可能对你的领域不敏感,比如运动领域的术语。
-
数据预处理不到位:分词错误或噪声未清理,导致向量偏离语义。
-
索引参数问题:ANN算法(如HNSW)的参数设置不当,召回率低。
解决办法:
-
微调嵌入模型:用领域数据(如运动相关的问答对)微调Sentence-BERT。Hugging Face的Trainer类可以帮你搞定:
from sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [InputExample(texts=["如何挑选跑鞋", "选择跑鞋的5个技巧"], label=1.0)] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16) train_loss = losses.CosineSimilarityLoss(model) model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1) -
检查分词:用jieba.lcut()打印分词结果,确保"跑鞋"没被切成"跑"和"鞋"。
-
调优索引:增加HNSW的M(连接数)或IVF的nprobe,提高召回率。比如:
index = faiss.IndexHNSWFlat(768, 64) # 增大M到64
问题2:查询速度慢得像乌龟
症状 :用户输入一个问题,Agent半天不吐结果。
原因:
-
索引规模过大:百万级向量全塞一台机器,内存或CPU吃不消。
-
后处理太复杂:跨编码器重新排序耗时长。
-
无缓存:热点查询反复计算。
解决办法:
-
分片索引:用Milvus或Elasticsearch分片存储,分散压力。
-
简化后处理:只对Top-10结果跑跨编码器,或者用更轻量的模型。
-
加缓存:用Redis缓存热门查询的Top-K结果:
import redis r = redis.Redis(host='localhost', port=6379, db=0) query = "如何挑选跑鞋" if r.exists(query): results = r.get(query).decode('utf-8') else: results = index.search(query_embedding[np.newaxis, :], k=5) r.set(query, str(results), ex=3600) # 缓存1小时
问题3:中文支持拉胯
症状 :英文查询效果不错,中文查询一塌糊涂。
原因:
-
模型对中文支持弱,比如用英文预训练的BERT。
-
分词不准确,中文语义被切得稀碎。
解决办法:
-
换模型:用支持多语言的模型,如paraphrase-multilingual-MiniLM-L12-v2。
-
优化分词:结合领域词典,比如给jieba加运动相关术语:
import jieba jieba.add_word("跑鞋") jieba.add_word("心肺功能") text = "跑鞋对心肺功能的影响" print(jieba.lcut(text)) # 输出:['跑鞋', '对', '心肺功能', '的', '影响'] -
预训练增强:用中文语料(如中文维基或领域文档)继续预训练模型。
调试神器
-
日志记录:用logging模块记录每次查询的输入、向量和Top-K结果,便于追溯问题。
-
可视化向量:用t-SNE或UMAP降维,检查向量分布,看看语义相近的文档是否真的"靠得近"。
-
小规模测试:先用1000条文档测试,确认效果再扩展到全量数据。
小贴士:防坑指南
-
定期检查索引健康:用Faiss的index.is_trained和index.ntotal确认索引状态。
-
异常输入处理:用户可能输入空字符串或乱码,提前过滤。
-
版本兼容:升级Faiss或Milvus时,检查API兼容性,避免代码崩盘。
10. 实战进阶:优化Agent的端到端体验
到这里,你已经掌握了向量化检索的核心技术,但用户要的不是技术,是丝滑的体验。
端到端流程
-
输入解析:用户可能输入模糊或口语化的问题,比如"跑步咋练快点"。需要预处理:
-
用NLP模型(如BERT)识别意图。
-
纠正常见拼写错误,比如"跑步"写成"跑布"。
-
-
检索+生成:检索Top-K文档后,喂给大模型生成自然语言回答。
-
结果展示:把检索结果和生成回答整合,突出重点信息。
实例:端到端问答Agent
假设用户问:"夜跑安全吗?"以下是完整流程:
from sentence_transformers import SentenceTransformer
from transformers import pipeline
import faiss
import jieba
# 加载模型
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
generator = pipeline('text-generation', model='gpt2-chinese')
# 索引(假设已构建)
index = faiss.IndexHNSWFlat(768, 32)
docs = ["夜跑注意事项:穿反光衣,避免偏僻路线", "跑步技巧"]
doc_embeddings = embedder.encode(docs)
index.add(doc_embeddings)
# 用户输入
query = "夜跑安全吗"
cleaned_query = ' '.join(jieba.lcut(query))
query_embedding = embedder.encode(cleaned_query)
# 检索
k = 5
distances, indices = index.search(query_embedding[np.newaxis, :], k)
top_docs = [docs[i] for i in indices[0]]
# 生成回答
prompt = f"用户问题:{query}\n相关信息:{' '.join(top_docs)}\n回答:"
answer = generator(prompt, max_length=100)[0]['generated_text']
print(answer)输出示例
用户问题:夜跑安全吗
相关信息:夜跑注意事项:穿反光衣,避免偏僻路线
回答:夜跑是安全的,但需要注意一些事项。穿反光衣可以提高能见度,避免在偏僻的路线跑步,选择人多的区域更安全。优化用户体验
-
多轮对话:记录用户历史问题,优化后续检索。
-
结果多样性:避免Top-K结果全是相似的文档,用MMR(最大边际相关性)算法增加多样性。
-
反馈循环:让用户点"赞"或"踩",用反馈数据微调模型。
小贴士:体验提升的细节
-
响应时间:目标是查询+生成<1秒,用异步处理(如asyncio)加速。
-
多语言切换:检测用户输入语言,自动切换嵌入模型。
-
错误提示:如果检索不到结果,返回友好的提示,比如"抱歉,没找到相关内容,要不换个问法?"