Optiver股票大赛Top2开源!
↑↑↑关注后"星标"kaggle竞赛宝典
作者:杰少
Optiver第二名方案解读
简介

Optiver竞赛已经于今天结束了,竞赛也出现了极端情况,中间断崖式的情况,在Kaggle过往的竞赛中,一般出现这种情况的情况有三种:
-
过拟合排行榜数据,例如一些回归问题中,极值的测试;
-
匿名数据中存在某些特定的关系,常见于数据被特殊处理的问题中,逆向特征工程;
-
特殊指标的问题,一些后处理技巧等;
而本次比赛,也不例外,从赛后和前五的选手交流以及目前第二名选手的开源的来看,几乎全部都涉及到了时间信息的逆向特征工程。本篇文章,我们就一起解读一下该次竞赛。
开源的代码可以在后台回复:Optiver获取,当然也可以去kaggle code处寻找。
方案解读
01
时间逆向特征
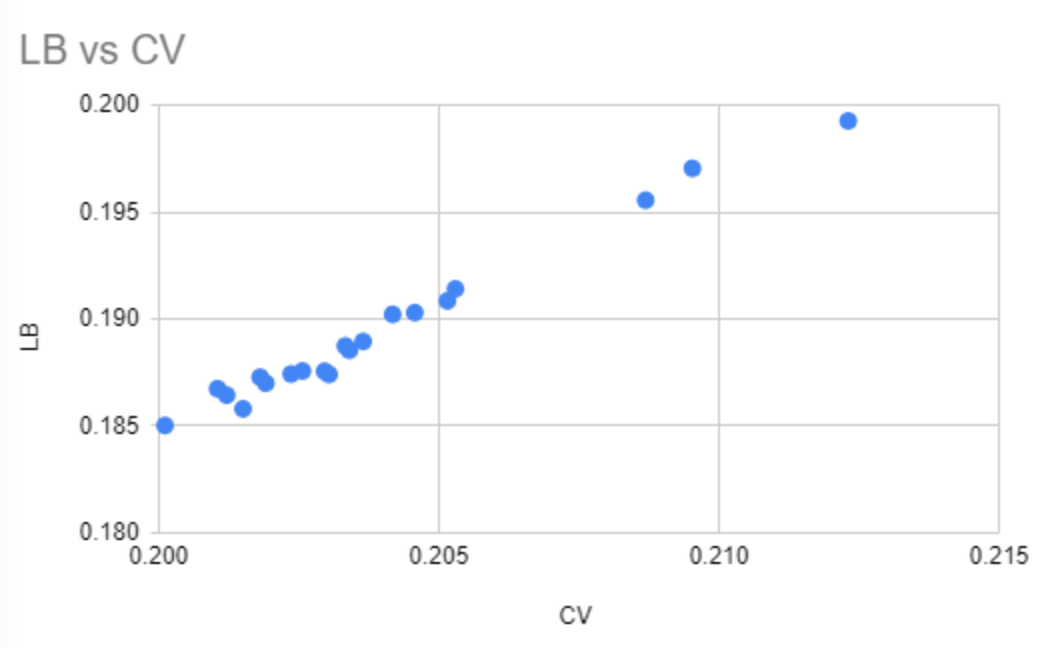
逆向的思路是:在本次竞赛中,因为竞赛数据是经过匿名化的,但是我们可以使用tick size来恢复在匿名之前的真实价格;
- tick size:是报价中最小的价格增量。https://en.wikipedia.org/wiki/Tick_size
使用计算得到的price,展开成下面的矩阵:
其中为time_id的个数,S是股票的个数,然后每个值是某个股票在某个时间点的price,剩下的就是基于该矩阵还原time_id的真实顺序,该处直接使用了TSNE将其压缩到qin
03
特征工程
3.1 特征构建
如果我们能以非常高的精度得到我们的数据产出顺序,那么未来阶段的RV很明显就是非常重要的特征,这边,使用许都距离metric来寻找最近的N个时间并计算RV的平均值等特征。
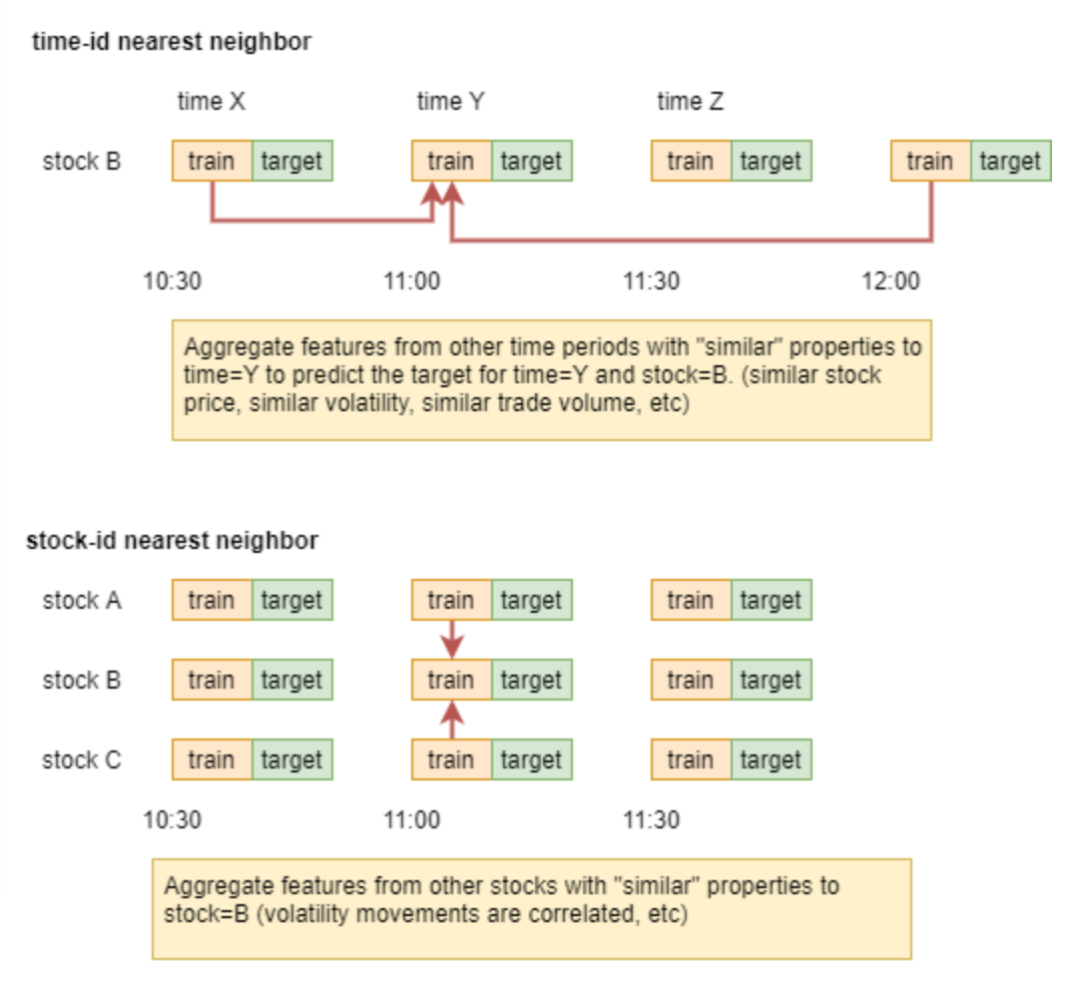
target_feature = 'book.log_return1.realized_volatility'
n_max = 40
# make neighbors
pivot = df.pivot('time_id', 'stock_id', 'price')
pivot = pivot.fillna(pivot.mean())
pivot = pd.DataFrame(minmax_scale(pivot))
nn = NearestNeighbors(n_neighbors=n_max, p=1)
nn.fit(pivot)
neighbors = nn.kneighbors(pivot)
# aggregate
def make_nn_feature(df, neighbors, f_col, n=5, agg=np.mean, postfix=''):
pivot_aggs = pd.DataFrame(agg(neighbors[1:n,:,:], axis=0),
columns=feature_pivot.columns,
index=feature_pivot.index)
dst = pivot_aggs.unstack().reset_index()
dst.columns = ['stock_id', 'time_id', f'{f_col}_cluster{n}{postfix}_{agg.__name__}']
return dst
feature_pivot = df.pivot('time_id', 'stock_id', target_feature)
feature_pivot = feature_pivot.fillna(feature_pivot.mean())
neighbor_features = np.zeros((n_max, *feature_pivot.shape))
for i in range(n):
neighbor_features[i, :, :] += feature_pivot.values[neighbors[:, i], :]
for n in [2, 3, 5, 10, 20, 40]:
dst = make_nn_feature(df, neighbors, feature_pivot, n)
df = pd.merge(df, dst, on=['stock_id', 'time_id'], how='left')3.2 特征处理
基于时间序列的对抗验证,我们发现非常多的特征随着时间的变化影响很大,例如order_count和total_volume这些,所以我们将其转化为在某个时间点的rank进行处理,与此同时,使用np.log1p对大的skew大的值进行处理。
04
建模
模型处和开源的是类似的,1DCNN+MLP+LGB,其实我们发现TabNet在本次竞赛中效果也非常不错,不过考虑到时间原因,没有再使用。
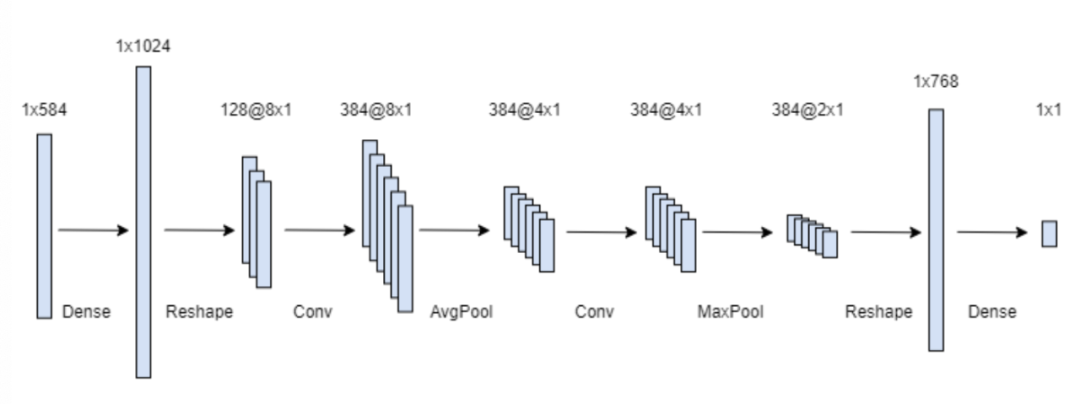
这些模型影响应该不是非常大,应该也不是核心。
参考文献

-
public 2nd place solution
-
Public 2nd Place Solution - Nearest Neighbors