MongoDB oplog简介
MongoDB Oplog是MongoDB Primary节点和Secondary节点在复制建立期间和建立完成之后的复制介质,Primary节点中的所有写入操作都会被记录到MongoDB的Oplog中,然后从库会来主库一直拉取Oplog并应用到自己的数据库中。这样每个Secondary节点都有oplog,记录着从主节点复制过来的信息,所以每个成员都可以作为同步源给其它节点。
MongoDB Oplog是MongoDB副本集主从复制的纽带,类似于MySQL中的binlog日志。
Oplog固定大小循环覆盖特点
MongoDB Oplog是local库下的一个固定集合。它是Capped collection,通俗意思就是它是固定大小,循环使用的:

Oplog记录的操作
oplog只记录改变数据库状态的操作。 比如,查询就不再存储在oplog中 。这是因为oplog只是作为从节点与主节点保持数据同步的机制。
存储在oplog中的操作也不是完全和主节点的操作一模一样的。这些操作在存储之前先要做"等释变换" ,以让其实现幂等性。 例如,使用"inc"执行的增加操作,会被转换成"set"操作。即:Oplog中一条操作,不管执行多少次效果都是一样的。
Oplog增长速度
oplog是固定大小,他只能保存特定数量的操作日志,通常oplog使用空间的增长速度跟系统处理写请求的速度相当,如果主节点上每分钟处理1KB的写入数据,那么oplog每分钟大约也写入1KB数据。如果单次操作影响到了多个文档(比如删除了多个文档或者更新了多个文档)则oplog可能就会有多条操作日志。db.testcoll.remove() 删除了1000000个文档,那么oplog中就会有1000000条操作日志。如果存在大批量的操作,oplog有可能很快就会被写满了。
副本集数据同步原理
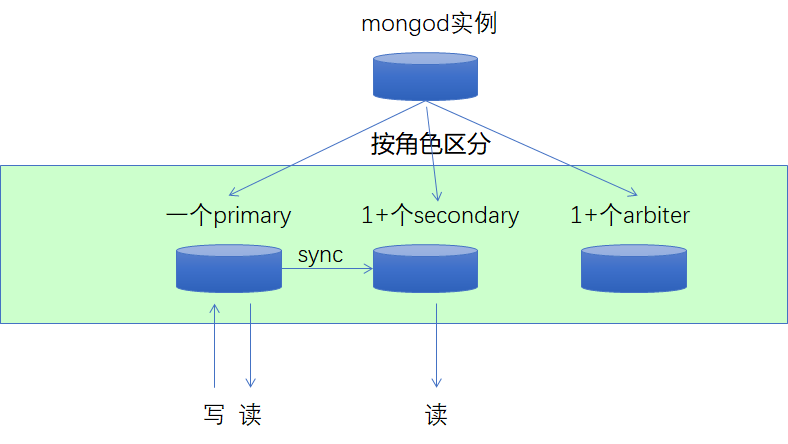
MongoDB默认是采取级联复制的架构 ,就是默认不一定选择主库作为自己的同步源,如果不想让其进行级联复制,可以通过chainingAllowed参数来进行控制。在级联复制的情况下,你也可以通过replSetSyncFrom命令来指定你想复制的同步源。所以这里说的同步源其实相对于从库来说就是它的主库。
从节点第一次启动时,会对主节点数据进行完整的同步。从节点复制主节点上的每个文档,耗费的资源可想而知。同步完成后,从节点开始查询主节点的oplog并执行这些操作,以保证数据是最新的。
如果从节点的操作已经被主节点落下很远了,从节点就跟不上同步了。跟不上同步的从节点无法一直不断地追赶主节点,因为主节点oplog的所有操作都太"新"了。从节点发生了宕机或者疲于应付读取时就会出现这种情况。也会在执行完完整同步以后发生类似的事,因为只要同步时间太长,同步完成时,oplog可能已经滚了一圈了。(oplog循环覆盖)
从节点跟不上同步时,复制就会停下,从节点需要重新做完整的同步。可以用{"resync":1}命令手动执行重新同步,也可以在启动从节点时使用--autoresync选项让其自动重新同步。重新同步代价高昂,所以要尽量避免,方法就是配置足够大的oplog。为了避免从节点跟不上,一定要确保主节点的oplog足够大,能存放相当长时间的操作记录。大的oplog显然会占用更多的磁盘空间,这就需要权衡一下,找个折中点(默认的oplog大小是剩余磁盘空间的5%)。
Oplog相关操作
查看当前的 Oplog 存储设置的大小
JavaScript
use local
db.oplog.rs.stats().maxSize查看 Oplog 最大大小和现在占用的大小,以及记录时长和时间
JavaScript
db.getReplicationInfo()
{
"logSizeMB" : 2560,
"usedMB" : 0.03,
"timeDiff" : 294447,
"timeDiffHours" : 81.79,
"tFirst" : "Tue May 25 2021 13:16:02 GMT+0800 (CST)",
"tLast" : "Fri May 28 2021 23:03:29 GMT+0800 (CST)",
"now" : "Fri May 28 2021 23:13:30 GMT+0800 (CST)"
}查询Oplog记录
JavaScript
db.oplog.rs.find()ts 的值: 表示该日志的时间戳
op 的值: i 表示 insert ,u 表示 update, d 表示 delete, c 表示的是 db cmd, db 表示声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.'), n 表示 noop,即空操作,其会定期执行以确保时效性
ns 的值: 表示操作所在的数据库和集合。
ui 的值: 表示当前登录用户的会话 id 值。
wall 的值: 表示该操作的执行时间,utc时间。
o 的值: 表示操作的内容,如果是插入,就会将插入的数据放到该位置。示例日志就是插入了一条数据{"_id" : ObjectId("60ac8b98ac0244635504dc3e"), "name" : "gxs", "age" : 20}