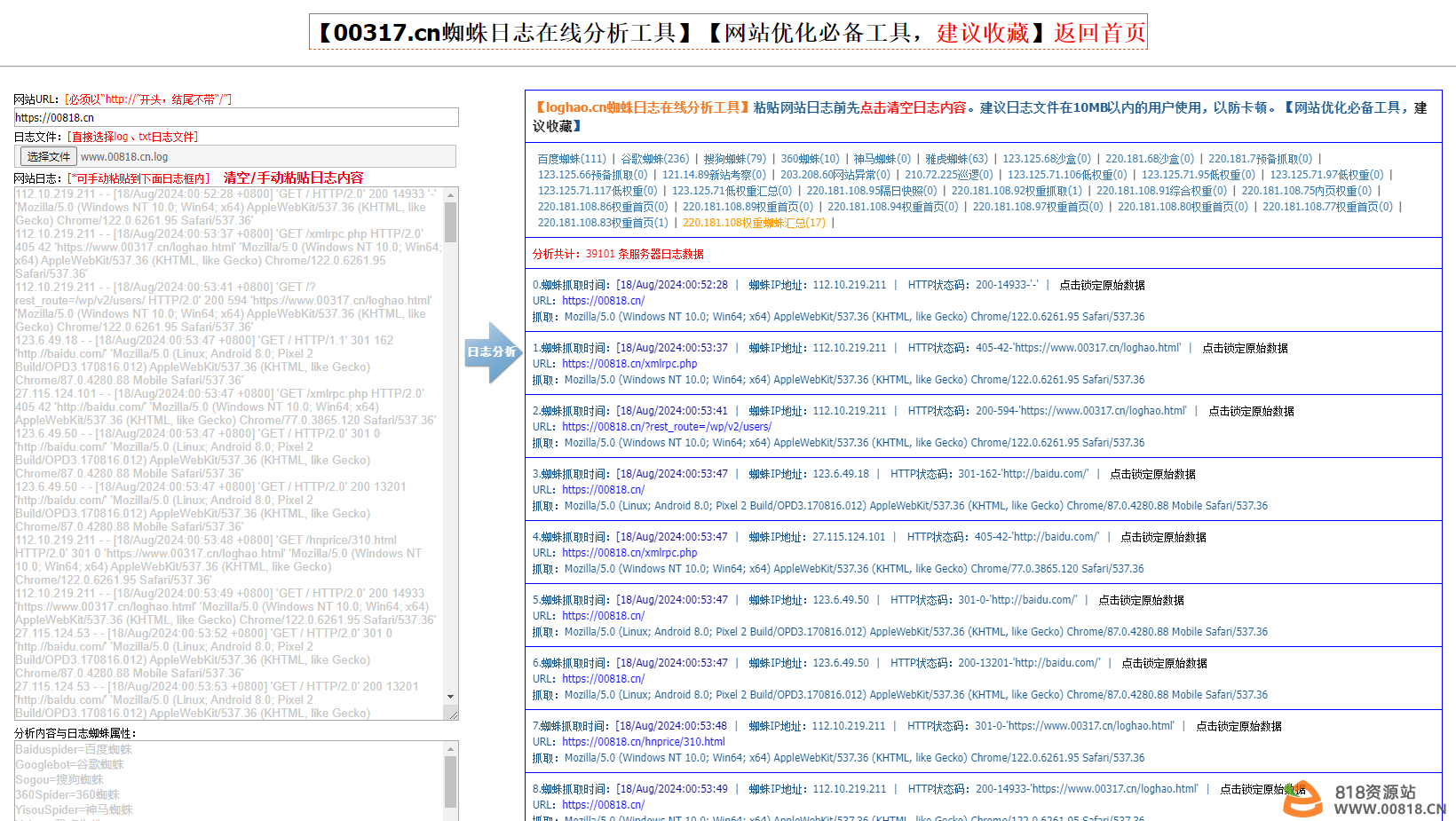
蜘蛛日志在线分析工具是一款开源的工具,可用于快速分析网站访问日志中搜索引擎网络爬虫的抓取记录。如果你的服务器运行在linux宝塔面板环境下,你只需要登录宝塔面板的linux控制面板,在左侧导航栏中点击"文件",然后进入wwwlogs文件目录即可找到网站访问日志。
ps:经实测,Windows系统的服务器沒有日志记录功能。
将网址日志全部內容拷贝到左边,随后点一下剖析按键,就能便捷的查询搜索引擎网络爬虫的抓取记录了。
蜘蛛日志在线分析工具是一款开源的工具,可用于快速分析网站访问日志中搜索引擎网络爬虫的抓取记录。如果你的服务器运行在linux宝塔面板环境下,你只需要登录宝塔面板的linux控制面板,在左侧导航栏中点击"文件",然后进入wwwlogs文件目录即可找到网站访问日志。
ps:经实测,Windows系统的服务器沒有日志记录功能。
将网址日志全部內容拷贝到左边,随后点一下剖析按键,就能便捷的查询搜索引擎网络爬虫的抓取记录了。