
随着ChatGPT和Stable Diffusion的发布,最近一两年,生成式AI已经火爆全球,已然成为移动互联网后一个重要的"风口"。就图片/视频生成领域来说,Stable Diffusion模型发挥着极其重要的作用。由于Stable Diffusion模型参数量是10亿参数的大模型,通常业界都是运行部署在显卡上。
但是随着量化、剪枝等模型压缩技术的进步,以及手机等终端设备的算力、带宽、内存持续增大。使得大模型在终端设备部署也成为的可能。大模型在终端部署可以有效保护用户隐私,而且终端设备日常广泛使用、用户可以随时随地生成想要的内容。

MNN-Diffusion使用
本文是深度学习推理引擎MNN团队,做的Stable Diffusion端侧部署应用,代码开源,用户可以自行DIY各种好玩的Stable Diffusion应用。
MNN开源地址:
https://github.com/alibaba/MNN/tree/master
欢迎大家试用,使用教程如下:
https://mnn-docs.readthedocs.io/en/latest/transformers/diffusion.html
下面是在个人手机/电脑上生成的图片:

go
技术要点业界加速Stable Diffusion部署通常有两个方向,一是算法层面的优化,包括优化网络结构、减少计算量或者降低推理迭代步数;二是工程部署优化,通过量化/算子高效实现等方式提高硬件计算效率、提高访存效率。MNN作为推理引擎,主要聚焦在工程部署优化上,下面分享下MNN Diffusion GPU在性能/内存方面做了优化工作。
▐ Self-Attention优化
Transformer结构中Self-Attention是一个基础结构,也是性能耗时的关键。如下结构是一个典型的Attention结构:
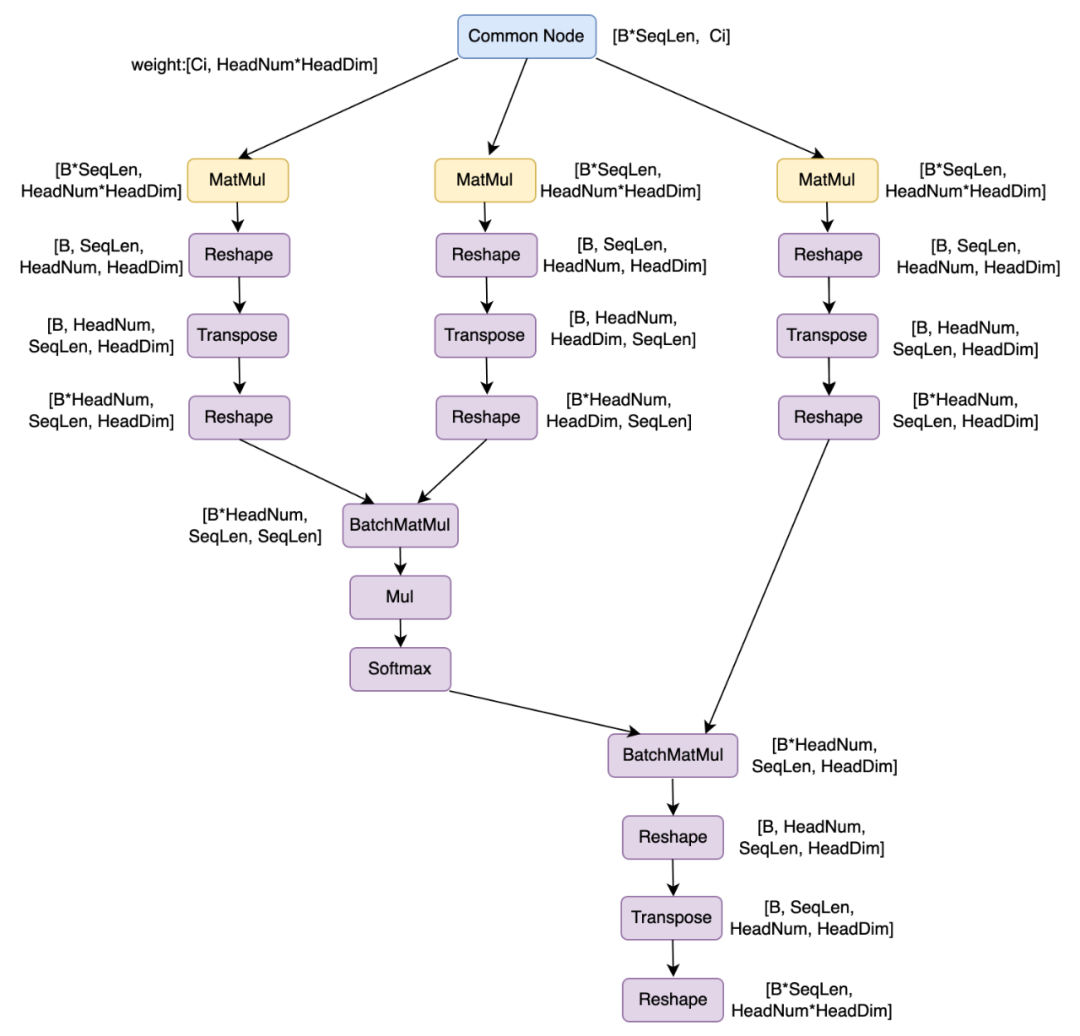
一个共有节点,分别经过三个Linear层,得到Query/Key/Value,Query/Key经过形状变换进行BatchMatMul操作,再进行Scale,取Softmax操作;该结果和Value经过形状变换做BatchMatMul;之后把结果进行形状变换,得到最终的输出。可以看到上述总共有19个算子,包括12个形状变化算子,7个计算型算子。
大量的形状变化会带来很多的访存耗时,对于GPU高算力的硬件来说,访存耗时往往容易成为热点。因此,将上述结构,融合成2个算子,第一个是将三个Linear层权重融合在一起,只做一个Linear,这样形成更大的矩阵乘尺寸,更容易打满GPU算力,带来性能收益;第二个算子是将Attention算子融合成一个算子Fused-MultiHead-Attention,融合之后在该新算子内部仅需5个Kernel就可以实现整个Attention功能。消除了大量额外的形状变换算子,降低了访存压力,同时可以更容易基于Attention算子特性做进一步优化工作。
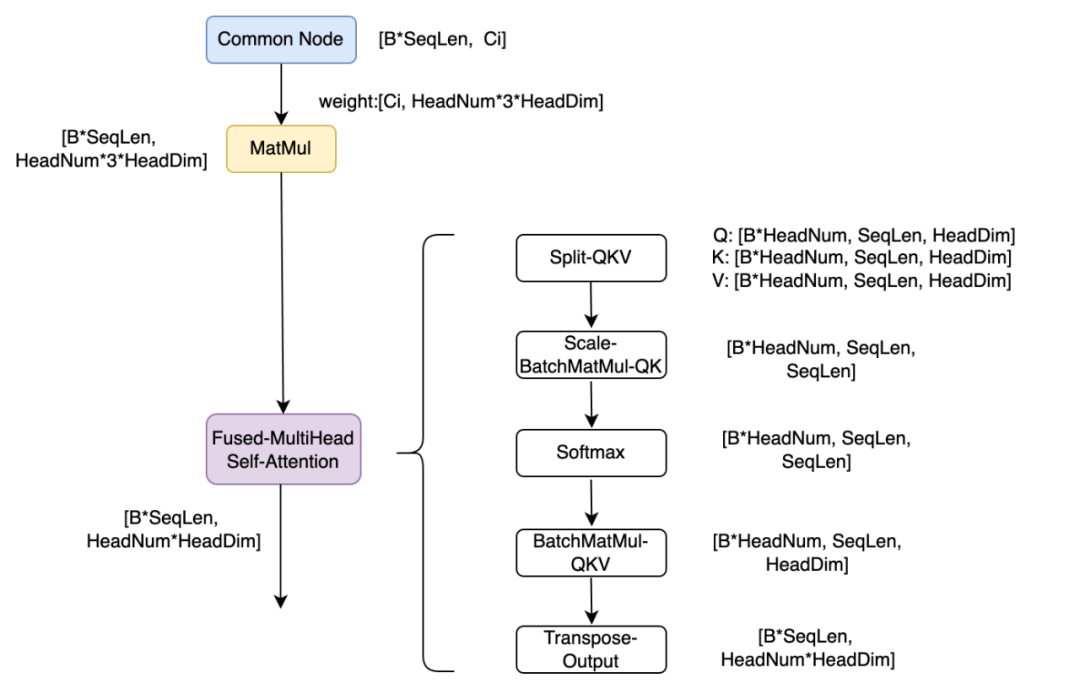
▐ GroupNorm/SplitGeLU融合
在Stable Diffusion中,有一个通用的结构ResnetBlock,其中包含了BroadCast Binary + GroupNorm + SiLU结构,在onnx模型图结构中包含了如下13个算子:
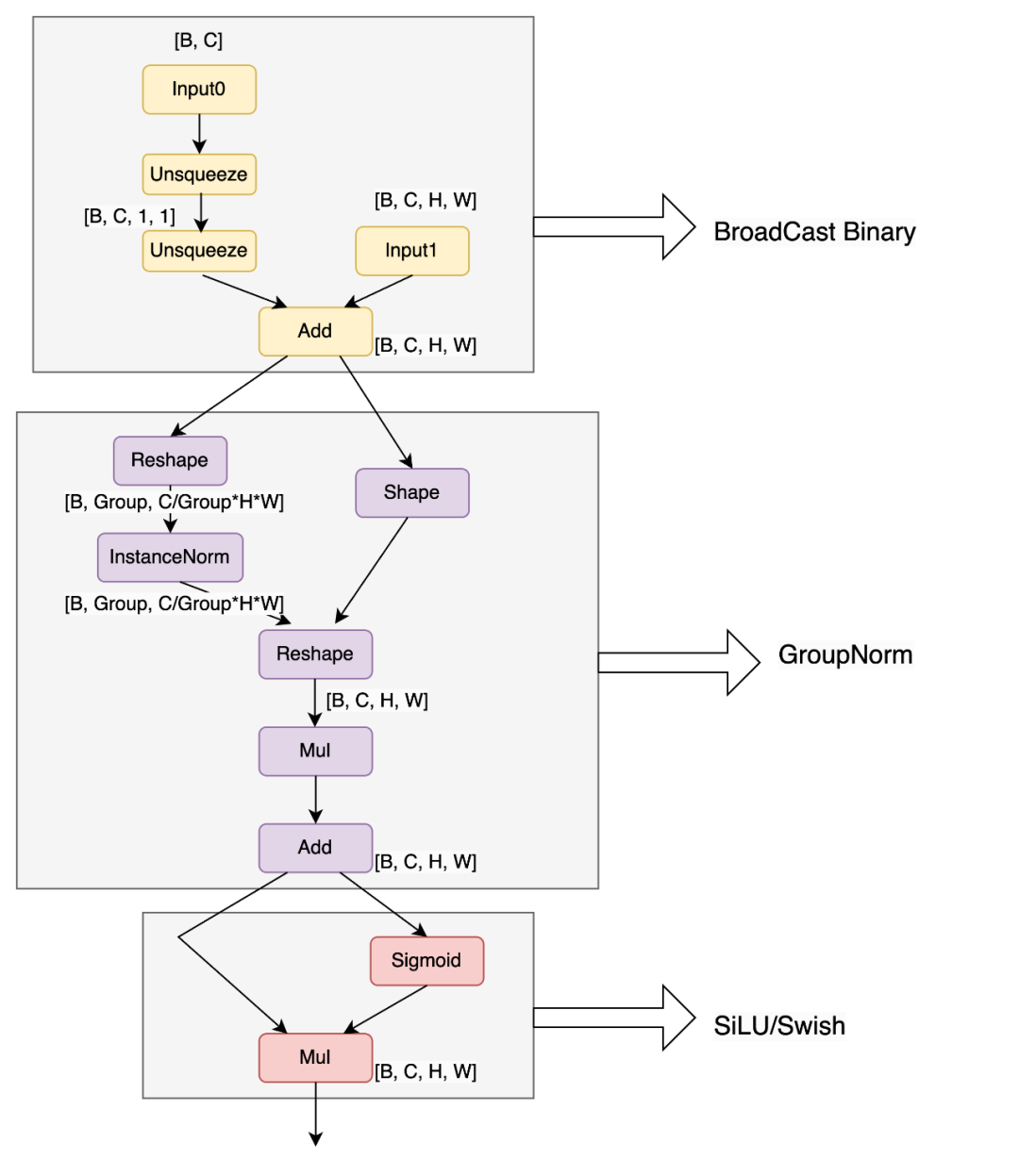
可以看到GroupNorm采用InstanceNorm+形变算子实现,gamma/beta被单独拆解为mul/add算子,细碎的算子会增加全局内存的访存次数、以及Kernel launch的压力。因此将上述通用结构合并成一个GroupNorm算子,该算子把前面的BroadCast Binary和后续的SiLU激活函数,融合在一起。高效的只需一个Kernel就可以实现上述计算需求。
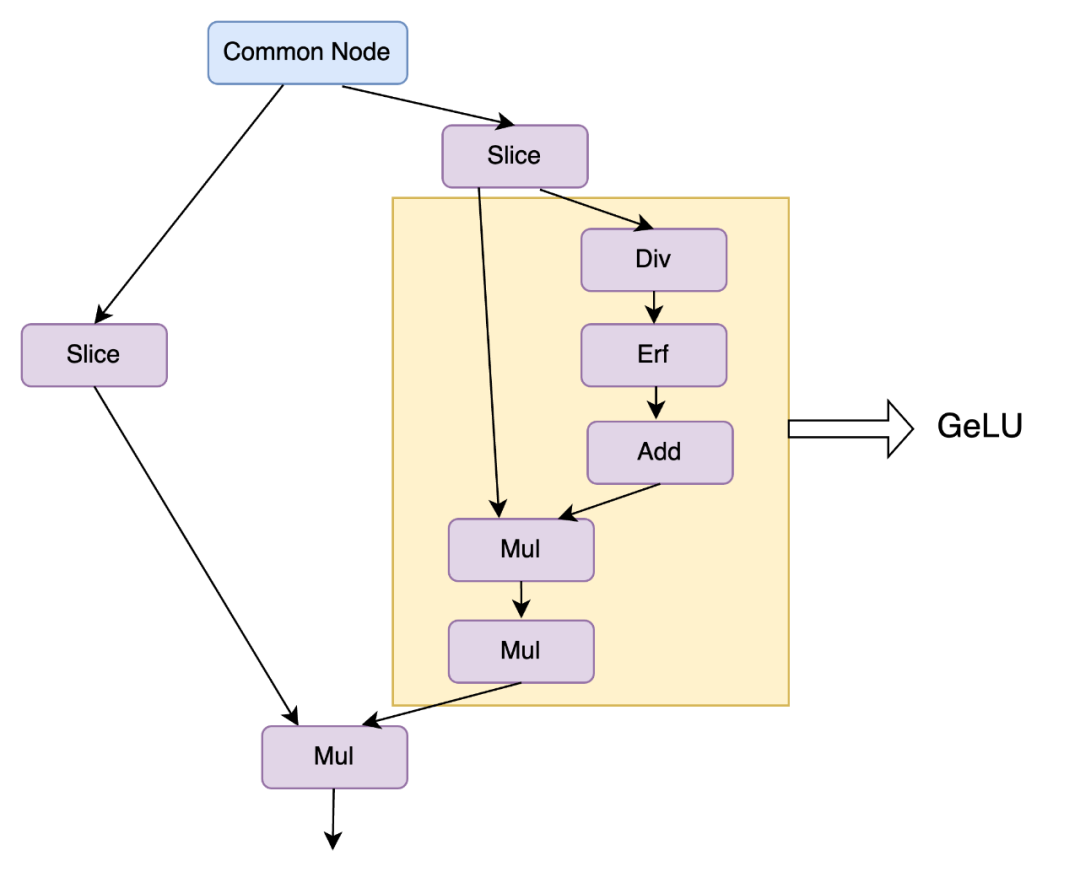
同样的图融合原理,在Transformer激活函数中,Stable Diffusion Feed-Forward模块中采用GEGLU结构,对应onnx图结构如下。将该8个onnx图算子,融合为通用的SplitGeLU算子。
▐ conv-winograd算法实现
在Stable Diffusion中有大量3x3卷积,在深度学习中,Winograd算法已经大量应用在加速3x3卷积实现。
Winograd F(m, r)算法,其中m代表一个计算tile的大小,r对应filter的尺寸,d=m+r-1 代表对应input tile大小。
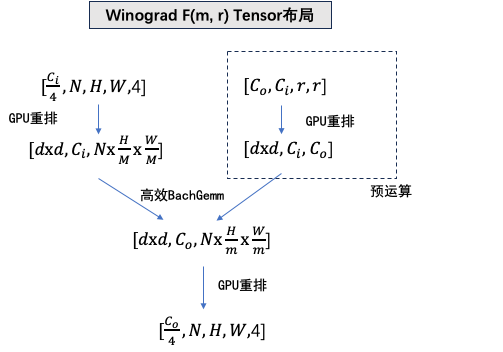
下表是3x3 Winograd不同tile对应计算量的节省比例和中间内存占用的增大比例。
|---|---|---|-----------------|-----------|------------|
| m | r | d | 计算量前后比例 | input中间内存 | weight中间内存 |
| 2 | 3 | 4 | 9 : 4 = 2.25x | 4x | 1.78x |
| 4 | 3 | 6 | 4 : 1 = 4x | 2.25x | 4x |
| 6 | 3 | 8 | 81 : 16 = 5.06x | 1.78x | 7.11x |
目前,我们使用的是F(2, 3) Winograd,控制内存增大量,同时带来一倍的性能提升效果。
▐ 高性能Gemm/BatchGemm
上述分析可以看出,Attention/卷积3x3,核心计算量在BatchGemm上,Linear层实际上就是Gemm运算。实际上,Stable Diffusion中,核心的计算量或者说耗时的热点,归根溯源,都集中在Gemm/BatchGemm上。如何高效实现矩阵乘法 成为最核心的关键。
矩阵乘在各个维度上的分块策略,可以有效提升数据的复用度和数据cache命中率;合理的分块可以为矩阵乘法带来大幅度的性能提升。
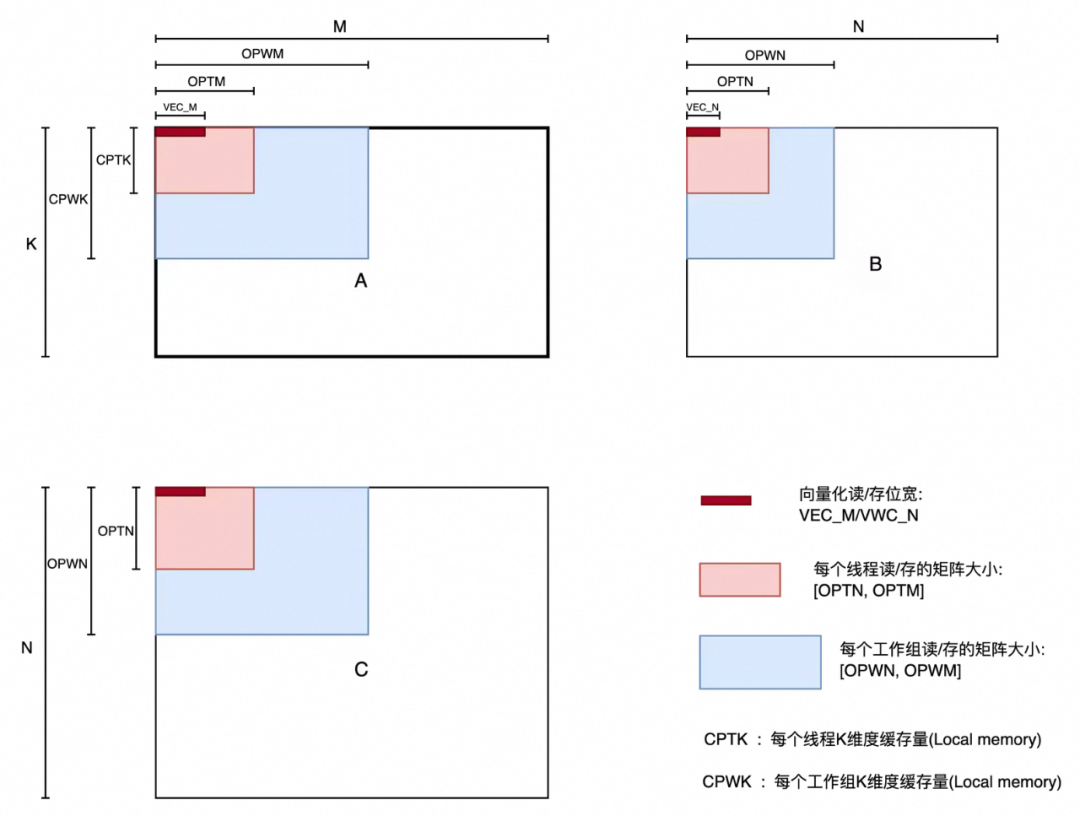
上图展示了,矩阵乘在各个维度上面的分块变量,包括在并发M/N维度,单次数据访存向量化位宽、每个线程存取矩阵的尺寸、每个工作组存取矩阵的尺寸,以及如果使用local memory缓存的话每个线程/工作组的缓存量。
这些参量都决定了数据访存的效率、并发量的大小、计算访存比的大小。不同的设备有不同的寄存器资源、共享内存资源、访存带宽、计算核心数,这些参量都决定着矩阵乘法的性能效率。
对于特定的矩阵乘的尺寸M/N/K,针对特定设备采取Auto-Tuning的获取最佳的运行参数(OPWM/OPWN/OPTM/OPTN/VEC_M/VEC_N等),Tuning候选集数量是M的N次方(N是参数的个数、M是每个参数候选集个数)。如果暴力循环每个参数候选集,由于候选集数量巨大、并且大尺寸矩阵乘本身单次运行耗时较大,必然会导致要花费大量时间去Tuning完所有候选集。因此,根据经验和实际试跑,选出部分高频参数候选集进行Tuning,在控制好Tuning时间的同时,也可以带来极大的性能收益。
▐ Gemm Strassen探索
由于矩阵乘法是Stable Diffusion耗时的核心,因此进行了矩阵乘快速算法的研究探索。Strassen算法是利用矩阵拆解,通过引入矩阵加减法,来减少矩阵乘法次数的方式。最简单的方法,将M/N/K维度各对拆1/2的方法,朴素的矩阵拆解如下:
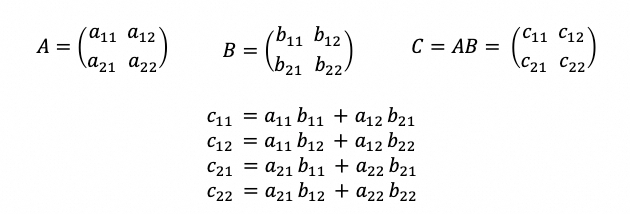
Strassen算法,通过15次子矩阵加减法,来减少一次子矩阵乘法。矩阵拆解如下:
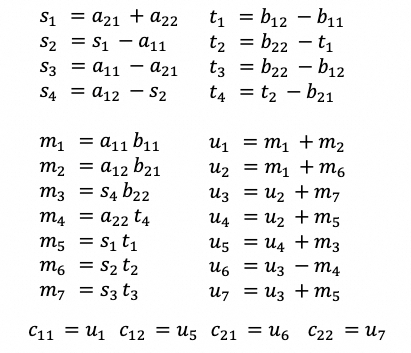
当N足够大时,矩阵加减法耗时会远低于矩阵乘法耗时,带来12.5%的计算量降低。当N较小时,受限于15次 子矩阵加减的 耗时,以及拆解子矩阵乘法算力打不满等损耗原因,将引起负优化。具体某个形状的矩阵乘法适不适合使用Strassen算法?
对于矩阵A形状为M, K, 矩阵B形状为N, K,输出矩阵C形状为M, N。15次子矩阵加减,数据访存量为:(3*M*K + 3*N*K + 3.5*M*N) * sizeof(DataType) Bytes。1次子矩阵乘法,数据计算量为:1/8 * M*N*K * 2 = 1/4 * M*N*K FLOPS。我们默认矩阵加减是带宽瓶颈,矩阵乘法是算力瓶颈。假设设备的内存带宽为X GB/s,算力是Y GFLOPS。
子矩阵加减耗时:(6*M*K + 6*N*K + 3.5*M*N)*sizeof(DataType) / X (ns)
子矩阵乘节省耗时:(1/4 * M * N * K) / Y (ns)
当节省的耗时大于损耗耗时,即可有性能收益。根据上述公式,计算访存比越低的设备,Strassen算法越容易有收益。对于手机设备来说,1024x1024x1024的子矩阵,通常可以获得约10%的性能收益。
▐ 内存占用优化
在Attention优化中,Q/K做BatchMatMul得到中间数据QK时,张量维度为Batch, HeadNum, SeqLen, SeqLen。对于Stable Diffusion来说,会遇到Batch=2,HeadNum=16,SeqLen=4096。对于float16的数据类型,单个张量的存储就需要1GB的内存大小,这对于内存资源紧缺的端侧设备是不可接受的。
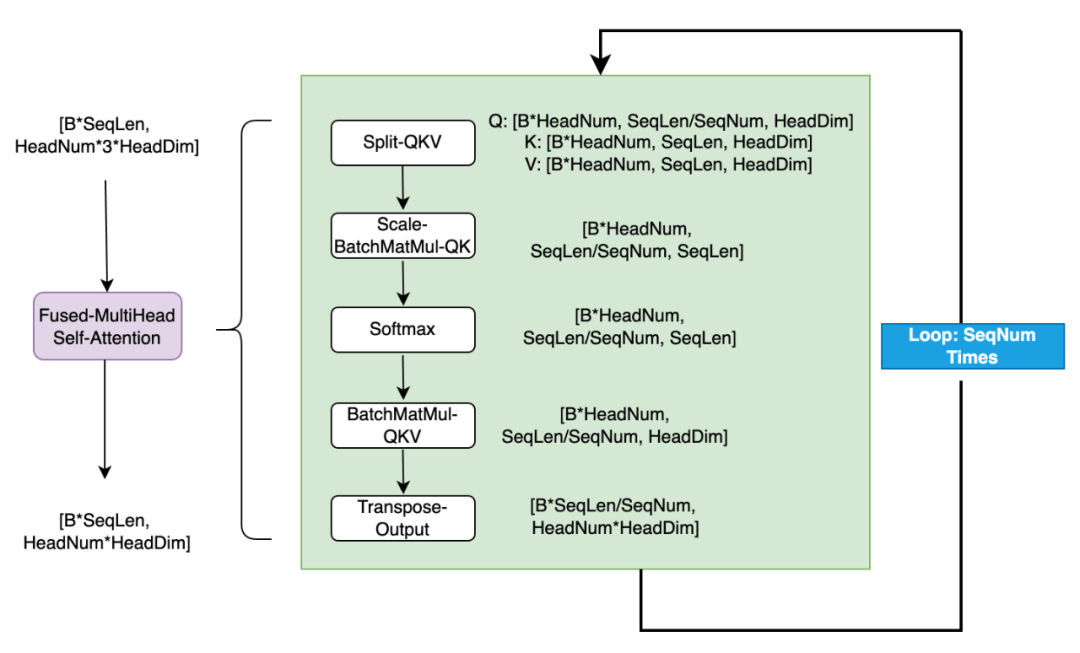
因此,将Attention操作进行分块处理,类似Paged Attention的思路,将整个Attention分成SeqNum次执行,这样每次仅需原先1/SeqNum中间内存大小,可以非常有效的控制内存的大小。
go
性能测评MNN Stable Diffusion应用,生成512x512图片,在骁龙8Gen3上使用GPU float16精度达到2s/iter (20次迭代,手机上40s可以生成完一幅图),在Apple Mac M3上GPU float32精度达到1.1s/iter (20次迭代,Mac上22s可以生成完一幅图)。MNN CPU/GPU性能均较大幅度快于如下Stable Diffusion开源框架,例如:
-
stable-diffusion.cpp
-
Android OnnxRuntime Stable Diffusion应用

后续研究
后续在性能优化和内存优化上面仍然有空间可以挖掘。
性能优化方面:
-
Conv Winograd采用更大的分块,获取更高的计算量降低收益。
-
矩阵乘尝试Image存储内存访问模式,提高访存效率。
-
Attention进一步采用Flash Attention等思路优化。
内存占用优化方面:
-
采用低比特权重(int8/int4量化)。
-
在线转换动态内存可复用,Conv Winograd权重尝试采用在线转换。
-
Attention 采用Flash Attention优化节省中间内存使用。

参考资料
-
https://blog.csdn.net/xian0710830114/article/details/129194419
-
https://github.com/NVIDIA/TensorRT/tree/release/8.6/demo/Diffusion

团队介绍
我们是大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
¤ 拓展阅读 ¤