文章目录
|-------------|
| 休息了一阵子 该收心了 |
HTTP服务器代码的调整

在博客『 Linux 』HTTP(一)中对HTTP进行了一个较为简单的介绍,介绍包括域名,URL,URL中关于URL特殊符号的编码以及解码(URLEncode和URLDecode),简单介绍了一下HTTP报文的格式(包括请求于响应),并且编写了一个简易的HTTP服务器;
cpp
/* httpserver.hpp */
class HttpServer
{
public:
HttpServer(uint16_t port = defaultport) : port_(port) {}
~HttpServer() {}
bool Start()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for (;;)
{
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport);
pthread_t tid;
ThreadData *td = new ThreadData(sockfd);
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
static void *ThreadRun(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
pthread_detach(pthread_self());
char buffer[10240];
ssize_t n = recv(td->sockfd_, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer;
}
close(td->sockfd_);
delete td;
return nullptr;
}
protected:
struct ThreadData
{
ThreadData(int sockfd) : sockfd_(sockfd) {}
int sockfd_;
};
private:
uint16_t port_;
static const uint16_t defaultport;
NetSocket listensock_;
};
const uint16_t HttpServer::defaultport = 8049;该服务器被封装为一个HttpServer类,主要通过自定义封装过的Socket类对服务器进行建立网络通信条件,用户需要在使用时调用对应的Start()成员函数即可;
该服务端将端口进行固定为8049(可根据需求自定义绑定端口号);
cpp
/* httpserver.cc */
int main(int argc, char *argv[])
{
std::unique_ptr<HttpServer> svr(new HttpServer());
svr->Start();
return 0;
}在当前情况下该服务器并不能称为是一个HTTP服务器,因为该服务器启动后只能接收来自浏览器(客户端)的请求,并不能将响应发回给客户端;
其中HttpServer类中的static void *ThreadRun(void *args)静态成员函数耦合度过高,可另外将处理工作单独封装为一个函数;
cpp
/* httpserver.hpp */
class HttpServer
{
public:
HttpServer(uint16_t port = defaultport) : port_(port) {}
~HttpServer() {}
// 服务器启动函数(包括初始化)
bool Start()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for (;;)
{
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport);
pthread_t tid;
ThreadData *td = new ThreadData(sockfd);
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
// 线程入口函数
static void *ThreadRun(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
pthread_detach(pthread_self());
HandlerHttp(td->sockfd_);
delete td;
return nullptr;
}
// 单独封装处理工作
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer;
}
close(sockfd);
}
// 包含线程所需数据的内部类
class ThreadData
{
public:
ThreadData(int sockfd) : sockfd_(sockfd){}
public:
int sockfd_;
};
private:
uint16_t port_; // 端口号
static const uint16_t defaultport; // 默认端口号
NetSocket listensock_; // 监听端口
};
const uint16_t HttpServer::defaultport = 8049; // 静态成员的初始化在新版本的代码中单独将处理动作封装为static void HandlerHttp(int sockfd)函数,使其与线程的入口函数进行解耦合;
User-Agent报头
对上文的服务器进行启动并且使用浏览器进行访问;

其中这个字段是用于在HTTP请求中标识客户端应用程序,操作系统,供应商以及版本信息等;
该报头能够根据客户端的类型(移动端或者桌面浏览器)从而返回不同格式的内容;
http
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36以该字段为例,Mozilla/5.0表示常规字段,windows NT 10.0;win64; x64表示操作系统和平台;
后面的部分则表示浏览器和其核心引擎,如AppleWebKit/537.36,Chrome/105.0.0.0以及Safari/537.36等,这些信息在网页请求时根据客户端环境提供适配的内容;
User-Agent字段通常用来标明该客户端为一个合法的客户端,可通过识别User-Agent字段来判别所访问该服务器的客户端是否为一个合法客户端,当判别为不合法的客户端则制定一系列的措施从而不对该客户端进行HTTP响应;
同时当服务端被爬时可根据识别的User-Agent字段来制定一系列的反爬策略(如所接收的HTTP请求中不包含User-Agent或是User-Agent字段不合法);
同时当一个设备使用浏览器进入一个网页时,对应的服务器将会通过判别User-Agent字段来识别当前访问的设备是PC端还是移动端从而返回不同适应的网页从而达到一个自适应效果来提升用户体验;
简单的HTTP响应
在上文中使用浏览器对服务器发送一次请求,但是服务器并没有作响应处理,所以不会为浏览器响应任何具有价值的信息;
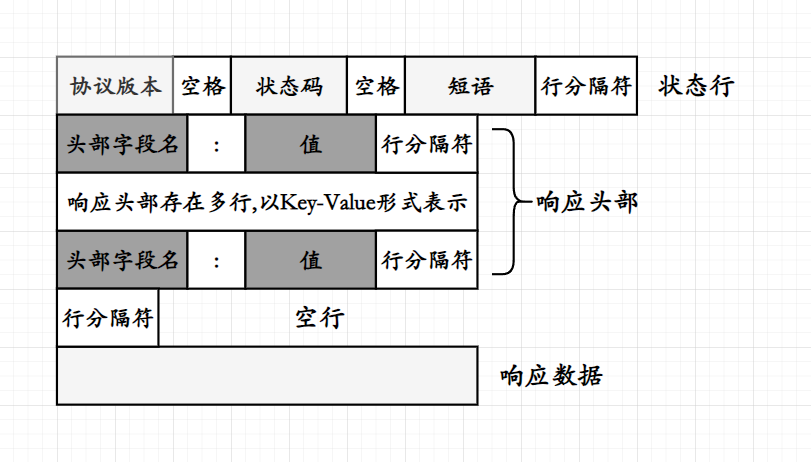
响应的结构为:
-
响应行/状态行
状态行包含协议版本,状态码,状态码短语与行分隔符;
其中各个字段之间以空格作为分隔;
-
响应头部
响应头部与请求头部(报头)相同,都以
Key - Value的形式存存储,行与行之间以行分隔符进行分隔; -
空行
空行表示不存在任何内容,只是单纯的行分隔符,空行表明响应行与响应报头的内容已经结束;
-
响应数据
响应数据为服务器接收到来自客户端的请求时返回给客户端的内容,这个内容存在于响应报文中的响应数据部分;
在上文中提到的空行不仅是响应行与响应报头的结束,也是响应数据的开始,至于响应数据的内容长度则是又响应报头中的
Content-Length字段进行存储,当客户端接收到响应时会进行判断响应是否为一个合法的响应,判断过后将会查询是否存在响应报头(当没有数据交由给客户端时响应报头可省略,当有响应数据时,Content-Length字段必须存在),若是Content-Length字段存在且为非零值则表示有数据,并且会根据该字段的长度从空行后读取Content-Length长度的数据作为响应数据;
可根据上文中已作修改的代码中的HandlerHttp方法中进行响应的构建以及返回;
cpp
class HttpServer
{
public:
// 单独封装处理工作
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer; // 为服务端打印出请求信息
// 返回响应
std::string line_feed = "\r\n"; // 换行
std::string text = "hello"; // 响应正文
std::string response_line = "HTTP/1.0 200 OK" + line_feed; // 响应行 (包含协议版本 状态码 状态码描述)
std::string response_header = "Content-Length: "; // 响应正文长度(报头字段)
response_header += std::to_string(text.size()); // 为正文长度添加属性
response_header += line_feed; // 换行
std::string blank_line = "\r\n"; // 设置空行
response_header += line_feed; // 添加空行
std::string response = response_line + response_header + text; // 组装响应
// 发送响应
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
};首先定义\r\n为换行符,即行分隔符line_feed,随后定义响应内容(响应数据),再制定响应行(状态行)为如下:
cpp
HTTP/1.0 200 OK表示协议版本为HTTP/1.0,状态码为200,状态码描述为OK;
随后定义响应报头,这里的响应报头其他字段可以忽略,但由于存在响应数据,Content-Length字段必须存在且不为0,定义一个std::string对象为Content-Length: 并添加正文长度,字段名与冒号后必须带空格(协议约束);
随后组装响应并调用send函数将响应根据sockfd套接字描述符发送回给客户端;
组装后的响应为:
cpp
HTTP/1.0 200 OK // 状态行
Content-Length: 5 // 响应头部
// 空行
hello // 响应正文可调用write()函数或者send()函数将响应返回给客户端;
send()/recv()函数和write()/read()函数功能大致相同但又不完全相同;
-
send()/recv()cppssize_t send(int sockfd, const void *buf, size_t len, int flags); ssize_t recv(int sockfd, void *buf, size_t len, int flags); -
write()/read()cppssize_t write(int fd, const void *buf, size_t count); ssize_t read(int fd, void *buf, size_t count);
两组函数对应的参数基本相同,唯独不同的是send()/recv()函数多出一个参数flags这个参数用来设置阻塞,非阻塞以及接受完整数据和发送外带数据等选项以更加适合进行网络通信操作,当flags为0时为默认选项,此时的send/recv函数与write/read函数的行为相同;
具体的选项如下:
-
recv()-
MSG_DONTWAIT表示接收操作为非阻塞的,即使没有数据可供读取也会立即返回;
-
MSG_PEEK检查接收缓冲区中的数据,但不从队列中移除,允许后续调用再次读取相同数据;
-
MSG_WAITALL等待接收到指定数量的字节才返回,除非遇到错误或连接关闭;
-
-
send()-
MSG_DONTWAIT使发送操作为非阻塞的,即使发送缓冲区已满也会立即返回;
-
MSG_OOB表示发送外带数据(对于支持外带数据的协议,如TCP);
-
当响应生成并发回给客户端的操作完成后对代码进行重新编译并运行;
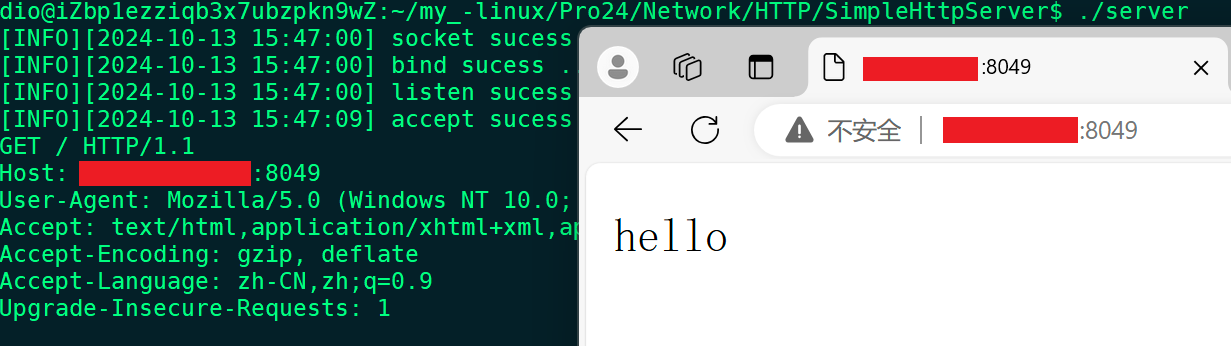
在使用浏览器进行访问时并不会将响应报文整体进行显示,而是只显示响应数据(响应正文)部分,至于状态行,报头,空行等部分将被浏览器自行接收并解析;
而使用telnet工具访问服务器时将会把整体的报文显示出来;
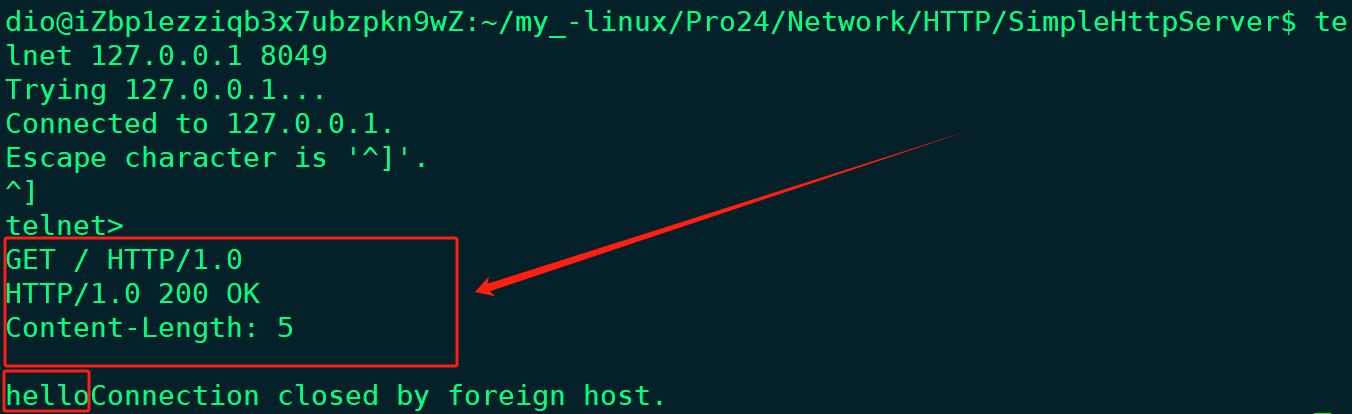
当然也可以在浏览器中使用开发者工具查看响应正文部分;

Web根目录
在上文中成功让服务器向客户端返回响应并让客户端成功接收;
客户端(浏览器)所接收到的信息即为正文部分,当然这里的正文部分可以硬编码进一个html文档,但这样设计的话有失雅观;
实际一般情况下所访问到的网页是一整个html项目而不是单独的正文,同时这个html项目并不存在于服务器(这里的服务器指的是云服务器)的根目录下,而是存在一个特定的目录,这个特定的目录则为该网页的根目录(与云服务器进行区别),即Web根目录;
通常网页中的各项数据,如网页文件(html),样式表(css),脚本(JavaScript),媒体文件(图片,视频,音频)等则存储在该Web根目录中,或是存在于该Web根目录中的某个子目录当中;
使用一个专用的Web根目录有以下优点:
-
组织和管理
可以更好组织项目文件,便于管理和维护;
-
安全性
限制访问服务器文件系统的其他部分,确保只有必要的文件和目录对外部可见;
-
路径管理
统一相对路径,对于站点中的资源引用更加方便;
-
解耦合
单独将站点资源存在对应的
Web根目录中也实现了服务器内部代码与其他文件进行解耦合,增加可维护性,也便于不同团队或开发人员独自处理各自的部分(将服务器逻辑与前端资源分开);
通常情况下Web根目录的命名为wwwroot,假设将Web根目录设置为当前目录的wwwroot目录,其目录结构为:
cpp
$ tree wwwroot/
wwwroot/
└── index.html
0 directories, 1 file即Web根目录下存在一个html文件为index.html,其文件内容如下:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>Hello World</h1>
<p>Here is page 1.</p>
<form>
<!--此处未作实际跳转-->
<input type="button" onclick="alert('Hello World!')" value="Go to page 2">
<input type="button" onclick="alert('Hello World!')" value="Go to page 3">
</form>
</body>
</html>
<!--该例html文件为示例文件-->
<!--具体html案例可参考网上对应文档-->
<!--此html文件不作解释-->即将服务器资源以文件的形式呈现,即需要对服务器代码进行调整;
cpp
/* httpserver.hpp */
#include <fstream>
const std::string wwwroot = "./wwwroot";
class HttpServer
{
public:
static std::string ReadHtmlContent(const std::string &path)
{
// 读取文件内容
std::ifstream in(path + "/index.html");
if (!in.is_open()) // 打开失败返回 "404"
{
return "404";
}
std::string content;
std::string line;
while (std::getline(in, line))
{ // 使用 getline 对文件内容进行按行读取
content += line;
}
in.close();
return content;
}
// 单独封装处理工作
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer; // 为服务端打印出请求信息
// 返回响应
std::string line_feed = "\r\n";
std::string text = ReadHtmlContent(wwwroot); // 调用函数对文件进行读取 // 响应正文
std::string response_line = "HTTP/1.0 200 OK" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
};重新编译代码并运行云服务器,再次访问该服务器;
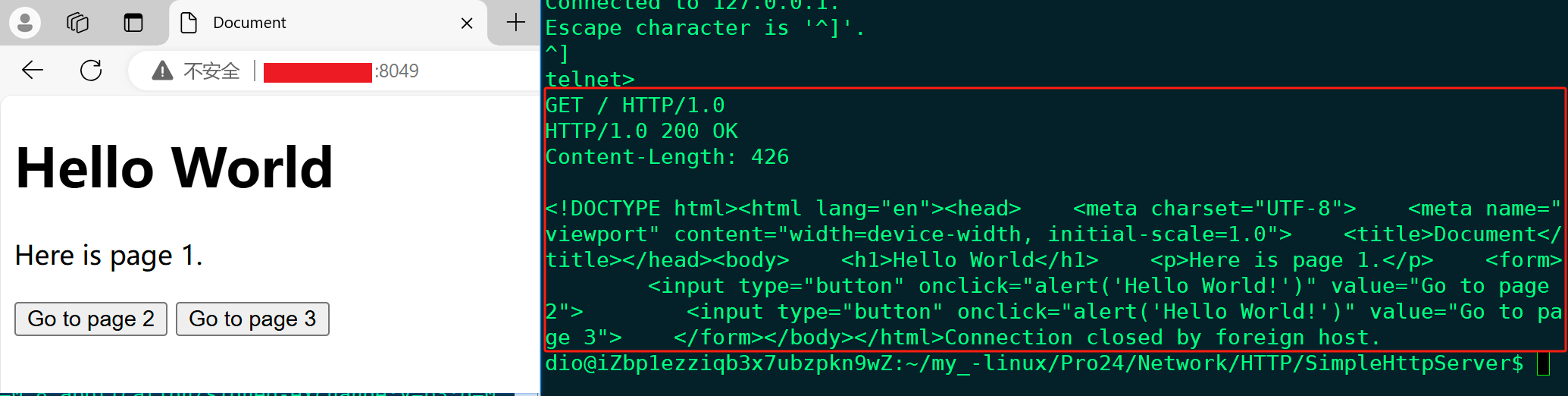
无论是浏览器还是telnet工具都可正常访问;
同时,由于服务器逻辑与站点资源进行区分,在修改站点资源时并不会影响服务器,无需重新编译代码,只需重新刷新浏览器即可;
同时由于此处所访问的路径被硬编码写死,无论客户端(浏览器)访问任何路径,都只会响应这一个html文件;
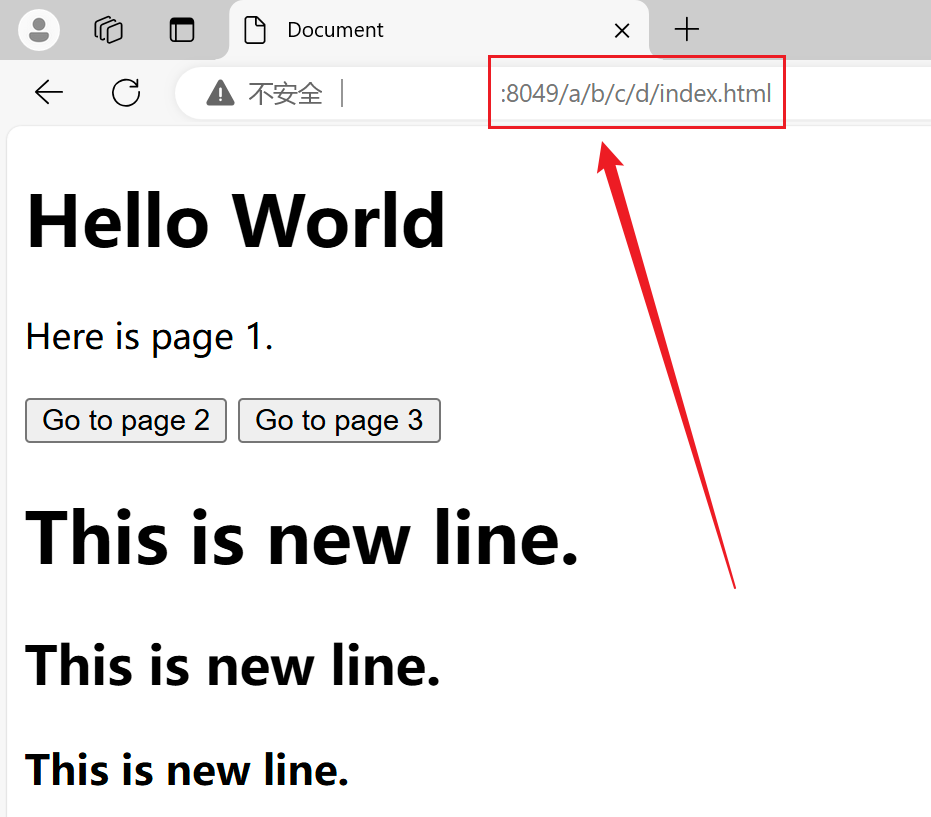
若是需要服务器根据客户端请求中不同的文件进行访问则需要对客户端所发请求中的参数中的路径进行解析并动态进行访问;
当然也可设置一个对应的配置文件config,将对应站点资源所在的路径写入配置文件当中,当服务器启动时从配置文件中读取对应的站点资源的路径,并根据浏览器的请求响应不同的站点资源;
服务器对请求的解析
当服务器拿到一个来自客户端(浏览器)的请求之后,需要对请求进行解析以了解该请求中的各个字段;
包括请求的请求行,请求报头,请求数据等信息,通常情况下浏览器会对响应进行对应的解析,所以只需要根据约定向浏览器发回对应格式的响应即可,但是服务器不同,服务器需要将来自浏览器的请求进行一定程度的解析才能够根据请求中的不同字段与属性给予其客户端一定的访问权限;
对请求的解析方式可以采用根据行分隔符进行按行解析,将每一行的内容放置到对应的容器当中,当需要进行进一步的解析即可遍历容器找到相应字段进行二次解析或是深度解析;
cpp
/* httpserver.hpp */
const std::string sep = "\r\n";
class HttpServer;
class HttpRequest
// 将协议进行按行解析
{
public:
void Deserialize(std::string req)
{
while (true)
{
std::size_t pos = req.find(sep);
if (pos == std::string::npos)
break; // 不存在或已找完
std::string temp = req.substr(0, pos);
if (temp.empty())
break; // 空行
req_header.push_back(temp); // 存到vector容器中
req.erase(0, pos + sep.size());
}
text = req;
}
void DebugPrint()
{ // Debug 打印解析后的协议
std::cout << "##############################" << std::endl;
std::cout << "------------------------------" << std::endl;
for (auto &sub : req_header)
{
std::cout << sub << std::endl;
}
std::cout << text << std::endl;
std::cout << "------------------------------" << std::endl;
std::cout << "##############################" << std::endl;
}
public:
std::vector<std::string> req_header; // 按行进行存储(请求行与请求报头)
std::string text; // 请求数据/正文部分
};同样在httpserver.hpp文件中单独封装一个类使得该类能够根据需求对请求进行解析;
单独封装一个用于解析请求的demo能够实现解析请求与服务器逻辑进行解耦合,方便后期在维护解析请求而不影响服务器本身逻辑;
在该类中定义了两个对象分别为std::vector<std::string> req_header与std::string text,并且定义了行分隔符为\r\n;
-
req_header用于按行存储请求中的请求行与请求报头;
-
text用来存储请求数据/请求正文,若是不存在请求数据则该对象为空;
行分隔符在打印出来时将会被真正显现为换行效果,而实际上可以将一整段请求看成是一段文本,只需要按照文本的格式对请求进行解析即可;
定义了两个成员函数;
-
void Deserialize(std::string req)该函数用于按行解析请求中的基本内容,包括请求行和请求报头;
循环进行以下操作:
-
find(sep)用于找到请求中的行分隔符;
当返回值为
std::string::npos时表示未找到对应的行分隔符,则break跳出循环; -
std::string temp = req.substr(0, pos)调用
std::substr()将内容进行截取并保存在临时对象temp中; -
req_header.push_back(temp)调用
std::vector::push_back()将截取出来的字段存放在容器中; -
req.erase(0, pos + sep.size())将已经被截取的部分连同当前行分隔符进行清除;
-
text = req将正文部分进行赋值(当循环结束后则表示剩余部分为正文部分,将其赋值给成员对象
text);
-
-
void DebugPrint()该函数的作用主要为
debug打印调试;遍历
vector容器,将解析后的内容进行打印,最后打印出请求正文部分;

内容按预期进行打印;
上图中下方的请求内容中请求的内容为/favicon.ico,该内容为网站图标文件,如:

对请求行进行深度解析
将请求进行解析过后对应的字段将会按照顺序存储在vector容器当中,其中该vector容器中下标为0的部分即保存着请求中请求行的部分;
可使用std::stringstream字符串流对该字段进行二次解析;
cpp
/* httpserver.hpp */
class HttpRequest
// 将协议进行按行解析
{
public:
void Parse()
{
std::stringstream ss(req_header[0]); // req_header 中0号下标数据为请求行
ss >> method >> url >> http_version; // 将请求行使用stringstream进行二次解析
}
void DebugPrint()
{ // Debug 打印解析后的协议
std::cout << "##############################" << std::endl;
std::cout << "------------------------------" << std::endl;
for (auto &sub : req_header)
{
std::cout << sub << std::endl;
}
std::cout << text << std::endl;
std::cout << "请求方法: " << method << std::endl;
std::cout << "请求路径: " << url << std::endl;
std::cout << "协议版本: " << http_version << std::endl;
std::cout << "------------------------------" << std::endl;
std::cout << "##############################" << std::endl;
}
public:
std::vector<std::string> req_header; // 请求报头
std::string text; // 正文内容
std::string method; // 请求方法
std::string url; // 路径
std::string http_version; // 协议版本
};这里定义了三个std::string对象method,url与http_version分别为请求方法,请求路径以及客户端的协议版本;
封装了一个成员函数Parse()为对已经进行一次解析后的请求中的请求行进行二次解析,并使用std::stringstream将解析后的部分写进新定义的三个std::string对象当中;
同时在DebugPrint()函数中增加了对三个字段的debug打印;
在httpserver类中的HandlerHttp()函数按照顺序增加该函数的调用;
cpp
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
// ...
HttpRequest request;
request.Deserialize(buffer); // 第一次解析
request.Parse(); // 对请求行进行解析
request.DebugPrint(); // debug打印
// ...
}
close(sockfd);
}重新编译代码,运行服务器并使用浏览器进行访问;
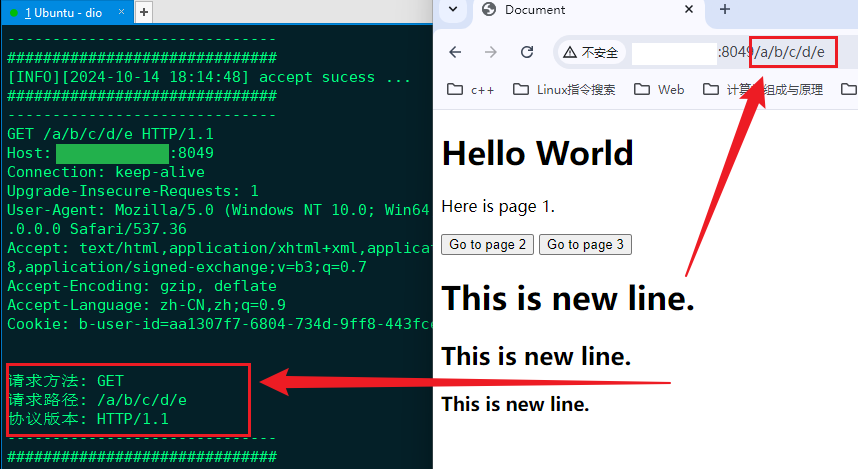
实现根据请求中的不同路径访问站点中的不同资源
当访问一个网页时若是不带路径或是路径中只有一个/时服务器所响应回浏览器的资源默认为一个名为idnex.html的主页;
可以使用wget工具获取到该主页文件;
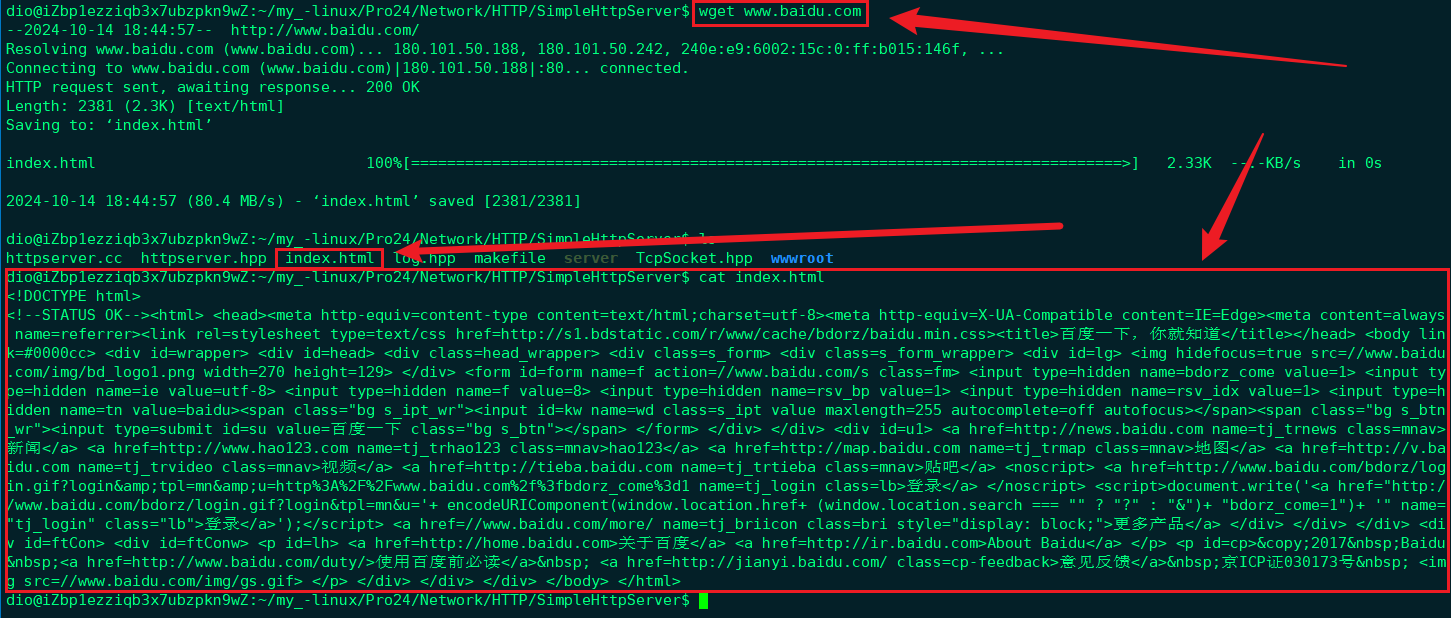
然而实际上一个站点中可能存在多个资源,多个资源一般情况下都存放在Web根目录中或是Web根目录中的任意子目录中;
那么既然在上文中已经对请求行进行了解析,并且已经成功提取到了url,那么接下来则需要对url进行判别;
访问一个网页通常存在以下情况:
-
访问主页
通常情况下当一个客户端/浏览器试图访问服务器中的
web根目录时不能直接将根目录交由浏览器进行访问,为了限制对应的操作,当浏览器访问web根目录或是主页index.html文件时将直接为浏览器响应主页资源;cppconst std::string wwwroot = "./wwwroot"; const std::string homepage = "index.html"; class HttpRequest // 将协议进行按行解析 { public: void Parse() { std::stringstream ss(req_header[0]); // req_header 中0号下标数据为请求行 ss >> method >> url >> http_version; // 将请求行使用stringstream进行二次解析 resource_path = wwwroot; if (url == "/" || url == "/index.html") // 判断是否响应回浏览器主页资源 { resource_path += "/"; resource_path += homepage; } } public: std::vector<std::string> req_header; std::string text; std::string method; std::string url; std::string http_version; std::string resource_path; // 实际访问路径 };在这次的代码修改中增加了成员变量
resource_path,该对象用于存放最终访问的资源路径;同时增加了一个
const std::string home_page对象,该对象用来存储主页资源的文件名;无论是什么资源都是由
web根目录为基础开始访问,所以先为resource_path对象赋值wwwroot(const std::string wwwroot = "./wwwroot";);随后判断请求中所访问的
url为/或是/index.html时则直接将resource_path += home_page;即能得到当浏览器的请求为请求主页资源时所访问的实际路径;
-
访问非主页(可能存在也可能不存在的资源,指常规路径)
当访问非主页时则表示常规路径,此时的常规路径与
Web根目录下的index.html无关,只需直接将resource_path += url即可;cppclass HttpRequest // 将协议进行按行解析 { public: void Parse() { std::stringstream ss(req_header[0]); // req_header 中0号下标数据为请求行 ss >> method >> url >> http_version; // 将请求行使用stringstream进行二次解析 resource_path = wwwroot; if (url == "/" || url == "/index.html") // 判断是否响应回浏览器主页资源 { resource_path += "/"; resource_path += homepage; } else resource_path += url; // /a/b/c/d/e.html -> ./wwwroot/a/b/c/d/e.html } void DebugPrint() { // Debug 打印解析后的协议 std::cout << "##############################" << std::endl; std::cout << "------------------------------" << std::endl; for (auto &sub : req_header) { std::cout << sub << std::endl; } std::cout << text << std::endl; std::cout << "请求方法: " << method << std::endl; std::cout << "请求路径: " << url << std::endl; std::cout << "协议版本: " << http_version << std::endl; std::cout << "实际访问: " << resource_path << std::endl; std::cout << "------------------------------" << std::endl; std::cout << "##############################" << std::endl; } public: std::vector<std::string> req_header; // 请求报头 std::string text; // 正文内容 std::string method; // 请求方法 std::string url; // 路径 std::string http_version; // 协议版本 std::string resource_path; // 实际访问路径 };
为方便debug在对应的DebugPrint()函数中打印出对应的实际访问路径;
重新编译代码并运行且使用浏览器对服务器进行访问;
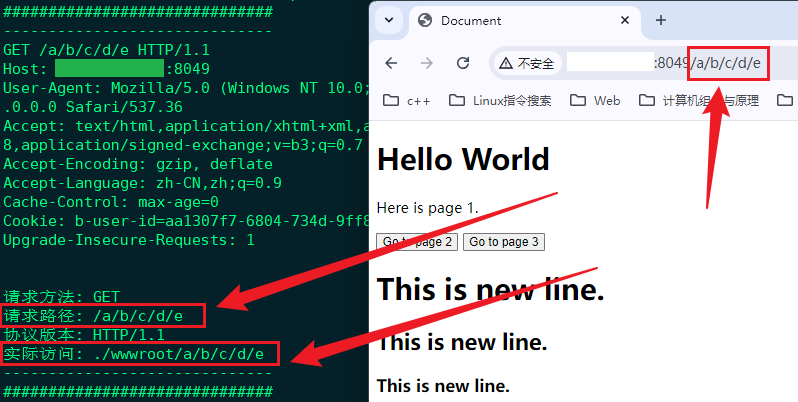
当存在实际访问路径后则可以在HttpServer类中的HandlerHttp()函数与ReadHtmlContent()函数的硬编码部分修改成可以根据实际访问路径动态访问,主要的逻辑即打开文件后按行进行读取;
cpp
class HttpServer
{
public:
static std::string ReadHtmlContent(const std::string &path)
{
// 读取文件内容
std::ifstream in(path);
if (!in.is_open()) // 打开失败返回 "404"
{
return "404";
}
std::string content;
std::string line;
while (std::getline(in, line))
{ // 使用 getline 对文件内容进行按行读取
content += line;
}
in.close();
return content;
}
// 单独封装处理工作
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
// std::cout << buffer; // 为服务端打印出请求信息
HttpRequest request;
request.Deserialize(buffer); // 第一次解析
request.Parse(); // 对请求行进行解析
request.DebugPrint(); // debug打印
// 返回响应
std::string line_feed = "\r\n";
std::string text = ReadHtmlContent(request.resource_path); // 调用函数对文件进行读取
std::string response_line = "HTTP/1.0 200 OK" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
private:
uint16_t port_; // 端口号
static const uint16_t defaultport; // 默认端口号
NetSocket listensock_; // 监听端口
};重新编译代码,运行服务器并访问服务器;
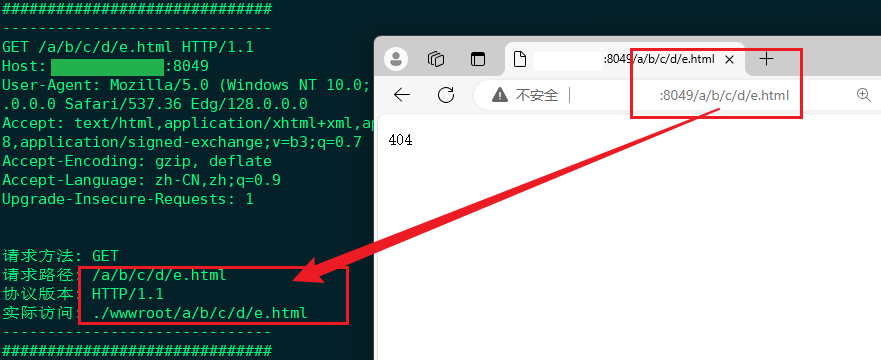
此处示例采用一个目录中并不存在的文件对服务器进行访问,最终访问结果为404,表示服务器并不会无脑只响应index.html文件;
服务器站点中存在多种资源时对不同资源的访问
实际上在上文部分中就已经实现了这一点;
假设当前Web根目录中的结构为如下:
cpp
$ tree wwwroot/
wwwroot/
├── index.html
└── pages
├── page_2.html
└── page_3.html
1 directory, 3 files即Web根目录中存在一个index.html文件以及目录pages/,同时pages/目录下存在两个网页文件分别为page_2.html与page_3.html,其源代码为如下:
-
index.htmlhtml<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Hello World</h1> <p>Here is page 1.</p> <form> <input type="button" onclick="alert('Hello World!')" value="Go to page 2"> <input type="button" onclick="alert('Hello World!')" value="Go to page 3"> </form> <h1>This is new line.</h1> <h2>This is new line.</h2> <h3>This is new line.</h3> </body> </html> -
page_2.htmlhtml<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Hello World</h1> <p>Here is page 1.</p> <form> <input type="button" onclick="alert('Hello World!')" value="Back to Home"> <input type="button" onclick="alert('Hello World!')" value="Go to page 3"> </form> </body> </html> -
page_3.htmlhtml<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Hello World</h1> <p>Here is page 1.</p> <form> <input type="button" onclick="alert('Hello World!')" value="Go to page 2"> <input type="button" onclick="alert('Hello World!')" value="Back to Home"> </form> </body> </html>
由于在上文中已经对资源访问的方式进行了调整,所以可以直接根据路径进行访问;

也可直接根据需求在html文件中通过<a></a>标签或者是表单中按钮来是设置跳转(此处不示范);
html
<!-- 表单按钮 -->
<input type="button" onclick="window.location.href='example_url/file.html';" value="Go to page 2">
<!-- <a></a>标签 -->
<a href="https://example.com">访问页面</a>