图像异常检测评估指标-分类性能
1. 混淆矩阵

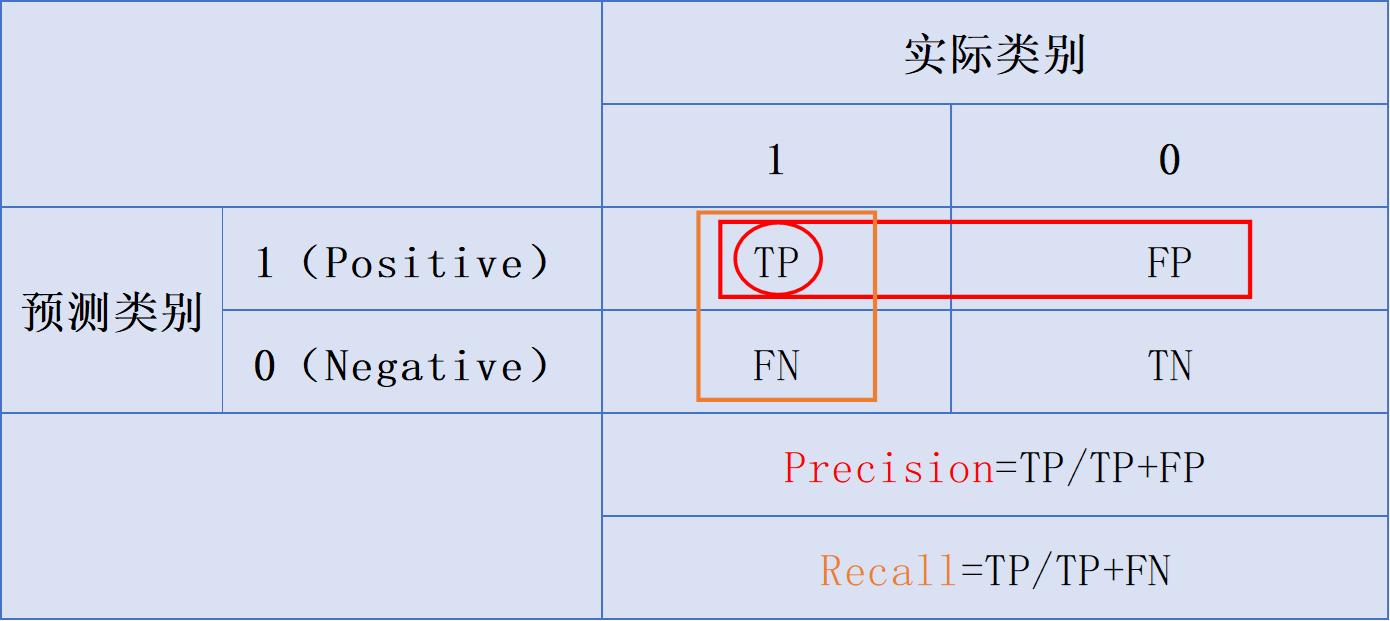
混淆矩阵包括4个用于衡量分类算法性能的基本数值
四个字母代表的含义是:P(Positive)代表算法将样本预测为正类,N(Negative)代表算法将样本预测为负类;T(True)代表算法对该样本的预测正确(即该样本的预测类别和实际类别一致),F(False)代表算法对该样本的预测错误(即该样本的预测类别和实际类别相反)
TP (True Positive):预测为正类,实际也为正类的样本数TN (True Negative):预测为负类,实际也为负类的样本数FP (False Positive):预测为正类,实际为负类的样本数FN (False Negative):预测为负类,实际为正类的样本数
2. 特定阈值下的评估指标
首先利用训练集拟合好分类算法,然后在验证集 上推理得到上述的TP, TN, FP 和 FN,进而可以计算该分类算法的性能评估指标------准确率(accuracy)、精确率(precision)、召回率(recall)和 F1-Score
2.1 accuracy
-
指标名称:准确率
-
定义:正确分类的样本(
TP)占所有样本(TP+TN+FP+FN)的比例(本文所有这些评估指标都是根据验证集进行计算的) -
公式:
A c c u r a c y = ( T P + T N ) ( T P + F P + F N + T N ) Accuracy=\frac{(TP+TN)}{(TP+FP+FN+TN)} Accuracy=(TP+FP+FN+TN)(TP+TN)
-
用准确率来评估可能存在一些问题:
-
类别不平衡问题:当数据集中的类别分布不均衡时,准确率可能会产生误导。例如,如果一个数据集中99%的样本属于一个类别,1%的样本属于另一个类别,那么一个简单的总是预测为多数类别的模型也会有99%的准确率,但实际上这个模型对于少数类别的预测效果非常差。
-
忽视错误分类的不同重要性 :准确率无法区分不同类型的错误分类,
accuracy的分子代表正确预测的样本数,包括TP和TN,与之相对应的错误率是error = 1-accuracy,它的分子就包括FP和FN,在医学诊断中,FP和FN分别代表误诊和漏诊,而误诊和漏诊的影响可能完全不同,但准确率不会反映出这些错误分类的不同重要性。
-
python
import numpy as np
from sklearn.metrics import (
accuracy_score, balanced_accuracy_score, precision_score, recall_score, f1_score, fbeta_score,
precision_recall_curve, roc_curve, auc
)
import matplotlib.pyplot as plt
# 示例数据
# y_true: 实际标签
# y_scores: 模型预测概率
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 0, 1, 0])
y_scores = np.array([0.1, 0.4, 0.35, 0.8, 0.7, 0.3, 0.6, 0.2, 0.9, 0.5])
# 将概率转换为二分类预测==> 注意只有在这里选定阈值的情况下,后面才能计算Precision/Recall/F1Score
threshold = 0.5
y_pred = (y_scores >= threshold).astype(int)
# Accuracy
accuracy = accuracy_score(y_true, y_pred)
print(f'Accuracy: {accuracy:.2f}')++针对正负样本不平衡的数据,可以引入平均准确率进行更合理的评估。++
2.2 average accuracy
- 指标名称:平均准确率
- 定义:对各个类别分别计算准确率,然后求平均
- 公式:
a v e r a g e A c c u r a c y = ∑ a c c u r a c y i n averageAccuracy=\frac{\sum accuracy_i}n averageAccuracy=n∑accuracyi
python
# 平均准确率
average_accuracy = balanced_accuracy_score(y_true, y_pred)
print(f'Average Accuracy (Balanced Accuracy): {average_accuracy:.2f}')2.3 precision
-
指标名称:精确率、查准率
-
定义:正确分类的正样本(
TP)占所有预测正样本(TP+FP)的比例 -
公式:
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
- 意义:衡量模型在正类预测上的准确率(注意是预测正类的准确率!!! ),如在垃圾邮件过滤中,精确率高(
FP小)意味着很少将正常邮件误判为垃圾邮件。
python
# 精确率
precision = precision_score(y_true, y_pred)
print(f'Precision: {precision:.2f}')2.4 recall
- 指标名称:召回率、查全率、真正率(
TPR) - 定义:正确分类的正样本(
TP)占所有实际正样本(TP+FN)的比例 - 公式:
R e c a l l = T P T P + F N \mathrm{Re}call=\frac{TP}{TP+FN} Recall=TP+FNTP
- 意义:召回率衡量的是++模型在检测所有实际为正类的样本时的有效性,或者说对正类样本的查全率(注意是正类样本的查全率!!!)++ 。高召回率意味着模型能够识别大多数的正类样本,漏检情况很少。
python
# 召回率
recall = recall_score(y_true, y_pred)
print(f'Recall: {recall:.2f}')Precision 和 Recall都适合用于类别不平衡的验证集,因为在二者的公式中都没有考虑True Negatives (TN) ,只专注于正确判断正样本,因此,就算验证集中负样本的数目远大于正样本,Recall 及 Precision仍是有效的参考指标。反之,FPR 则会受到影响,当我们负样本很多,模型若全部预测为负样本,会得到FPR = 0,但这样的模型并非好的模型,所以ROC curve比较容易受到不平衡的验证集影响。
2.5 F1-Score
- 定义:针对++特定某个门槛值++ 的
Recall及Precision所计算出来的调和平均数(precision和recall的重要程度相同) - 公式:
F 1 S c o r e = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F1Score=\frac{2^*precision^*recall}{precision+recall} F1Score=precision+recall2∗precision∗recall
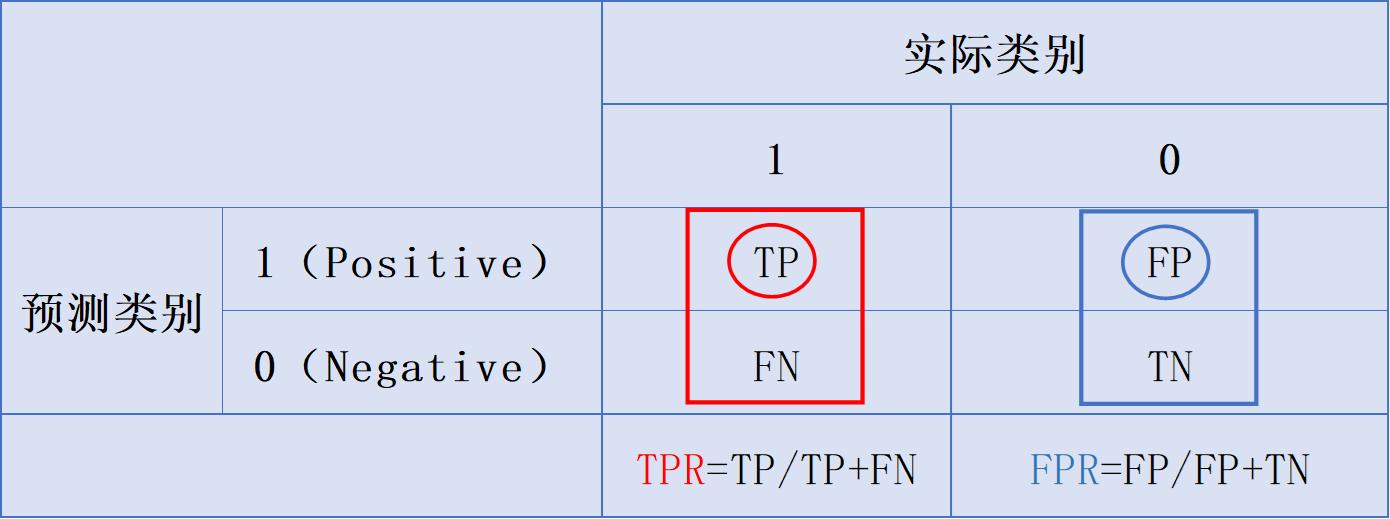
2.6 TPR
- 指标名称:真正率,
True Positive Rate,召回率、查全率,Sensitivity - 定义:所有真实类别为1的样本中,预测类别为1的比例
- 公式(TP除以其所在的列和):
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
2.7 FPR
-
指标名称:假正率,
False Positive Rate,误诊率,(1-Specificity) -
定义:所有真实类别为0的样本中,预测类别为1的比例
-
公式(
FP除以其所在的列和):
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
2.8 FNR
- 指标名称:
False Negative Rate,漏诊率 - 定义:所有真实类别为1的样本中,预测类别为0的比例
- 公式:
F N R = F N T P + F N FNR=\frac{FN}{TP+FN} FNR=TP+FNFN
3. 阈值无关的评估指标
3.1 PR Curve
-
指标全称:
Precision Recall Curve -
定义:纵坐标为精准率
Precision,横坐标为召回率Recall -
意义:
PR曲线是在不同阈值下绘制的,和下文的ROC曲线类似,都用于反映模型在不同阈值下的整体表现,PR曲线越往右上角凸起,则代表整体更好的模型表现,因为,反之越平则代表模型性能越差。 -
如何选取最优阈值?
PR曲线是通过在各个阈值下计算精确率(
Precision)和召回率(Recall)来绘制的,要确定最佳阈值,可以:- 法一:计算不同阈值下的
F1 Score,选择使F1 Score最大的阈值。 - 法二:
- 根据实际应用对Precision和Recall的不同重视程度,赋予二者不同的权重,计算
Fβ-score,选择使Fβ-score最大的阈值。 - Fβ-score是准确Precision和Recall的加权调和平均值,该
β参数表示召回率重要性与精确度重要性的比率,β>1会给recall更多的权重,β<1会给precision更多的权重。例如β=2代表recall的重要性是precision的2倍,β=0.5则刚好相反。
- 根据实际应用对Precision和Recall的不同重视程度,赋予二者不同的权重,计算
- 法一:计算不同阈值下的
python
# Precision-Recall曲线和AU-PR
precisions, recalls, pr_thresholds = precision_recall_curve(y_true, y_scores)
plt.figure()
plt.plot(recalls, precisions, label='Precision-Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend()
plt.show()
python
# F1 Score和F-beta Score最佳阈值
f1_scores = 2 * (precisions * recalls) / (precisions + recalls)
best_f1_index = np.argmax(f1_scores)
best_f1_threshold = pr_thresholds[best_f1_index]
print(f'Best F1 Threshold: {best_f1_threshold:.2f}')
print(f'Best F1 Score: {f1_scores[best_f1_index]:.2f}')
beta = 2
fbeta_scores = (1 + beta**2) * (precisions * recalls) / (beta**2 * precisions + recalls)
best_fbeta_index = np.argmax(fbeta_scores)
best_fbeta_threshold = pr_thresholds[best_fbeta_index]
print(f'Best F-beta Threshold: {best_fbeta_threshold:.2f}')
print(f'Best F-beta Score: {fbeta_scores[best_fbeta_index]:.2f}')3.1.1 AU-PR
-
指标全称:
Area under the Precision-Recall Curve -
意义:将
precision-recall curve总结成曲线下面积,便于衡量模型在各个阈值下的整体性能表现 -
PR曲线的面积计算公式为:
A U P R = ∑ i = 1 n − 1 ( R i + 1 − R i ) ⋅ ( P i + 1 + P i 2 ) \mathrm{AUPR}=\sum_{i=1}^{n-1}(R_{i+1}-R_i)\cdot\left(\frac{P_{i+1}+P_i}2\right) AUPR=i=1∑n−1(Ri+1−Ri)⋅(2Pi+1+Pi)- R i R_i Ri:Recall at the i i i-th threshold
- P i : P_i{:} Pi: Precision at the i i i-th threshold
- n n n: Number of thresholds
python
from sklearn.metrics import precision_recall_curve, auc
precision, recall, _ = precision_recall_curve(y_true, y_scores)
aupr = auc(recall, precision)
print(f'AU-PR: {au_pr:.2f}')3.1.2 AP
-
指标名称:
Average Precision -
定义:各阈值下精确率的加权平均值,权重是召回率的变化
-
公式:
A P = ∑ n ( R n − R n − 1 ) P n \mathrm{AP}=\sum_n(R_n-R_{n-1})P_n AP=n∑(Rn−Rn−1)Pn- P n : P_n{:} Pn:Precision at the nth threshold
- R n : R_n{:} Rn: Recall at the nth threshold
-
意义:将precision-recall curve 总结成各阈值下精确率的加权平均,更关注模型的精确率
-
In essence,
APcalculates the area under the precision-recall curve but takes into account the order of the data points.
In practice,
AUPR and APare used to evaluate the performance of classification models on imbalanced datasets. In many machine learning libraries, the term "Average Precision" is often used and computed, while "AUPR" might be less frequently mentioned but represents a similar concept.
python
from sklearn.metrics import average_precision_score
# Calculate Average Precision
ap = average_precision_score(y_true, y_scores)3.1.3 AR
- 指标名称:Average Recall
- 定义:各阈值下召回率的加权平均值,权重是精确率的变化
- 意义:这是和AP对称的公式,不常用,适用于强调召回率的场景
- 公式:
AR = ∑ n ( P n − P n − 1 ) R n \text{AR}=\sum_n(P_n-P_{n-1})R_n AR=n∑(Pn−Pn−1)Rn
3.2 ROC Curve
-
指标名称:
Receiver Operating Characteristic Curve -
定义:纵坐标是真正率TPR ,横坐标是假正率**
FPR** -
如何画ROC曲线?
二分类模型的输出是预测样本为正例的概率,而
ROC曲线正是通过不断移动分类器的"阈值"来生成曲线上的一组关键点的。ROC曲线的绘制步骤如下:
- 假设已经得出一系列样本被划分为正类的概率
Score值,按照大小排序。 - 从高到低,依次将"
Score"值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于某个样本,其"Score"值为0.6,那么"Score"值大于等于0.6的样本都被认为是正样本,而其他样本则都认为是负样本。 - 每次选取一个不同的
threshold,得到一组FPR和TPR,以FPR值为横坐标和TPR值为纵坐标,即ROC曲线上的一点。 - 根据3中的每个坐标点,画图。
举例如下:
假设验证集样本的预测结果如下表,图中共有20个验证集样本,"
Class"一栏表示每个验证集样本真正的标签(p表示正样本,n表示负样本),"Score"表示每个验证集样本属于正样本的概率。
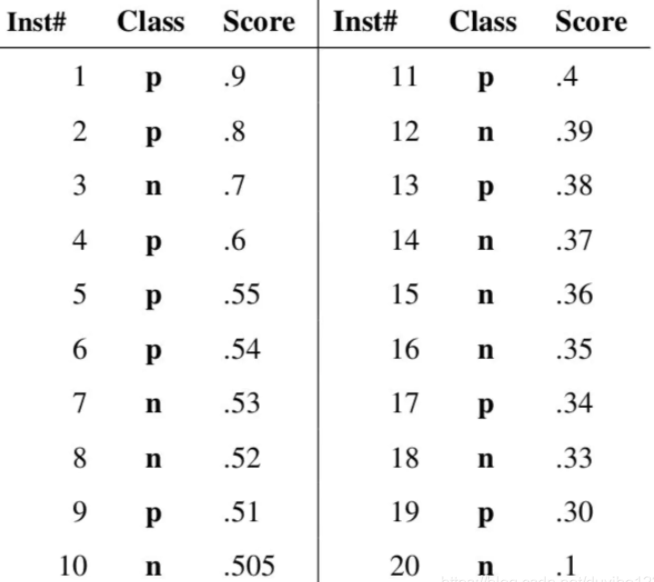
接下来,我们从高到低 ,依次将"
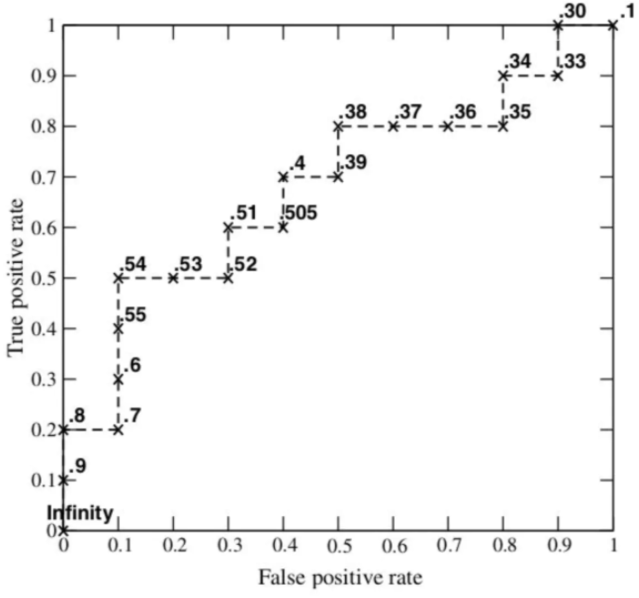
Score"值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。从第一个样本开始,设该样本的Score值为阈值,则该样本及之后的样本(均比该样本概率值小)判为负样本,即所有样本判为全负,计算得TPR=FPR=0,即ROC曲线(0,0)点;再选择第二个样本点的Score作为阈值,大于等于该阈值的样本(在该样本之前)判为正样本,小于该阈值的判为负样本,计算TPR和FRP,可在ROC图画出该点。举例来说,对于图中的第4个样本,其"
Score"值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的"Score"值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
 python
python# ROC曲线和AUC fpr, tpr, roc_thresholds = roc_curve(y_true, y_scores) plt.figure() plt.plot(fpr, tpr, label='ROC Curve') plt.plot([0, 1], [0, 1], 'k--', label='Random Classifier') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC Curve') plt.legend() plt.show() roc_auc = auc(fpr, tpr) print(f'AUC: {roc_auc:.2f}') - 假设已经得出一系列样本被划分为正类的概率
-
意义:(1) 利用
ROC曲线比较不同模型,进而选择最佳模型-
首先,了解一下
ROC曲线图上很重要的四个点:( 0 , 1 ),即FPR=0, TPR=1,这意味着FN(False Negative)=0,并且FP(False Positive)=0。代表这是一个完美的分类器,它将所有的样本都正确分类。( 1 , 0 ),即FPR=1,TPR=0,意味着这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。( 0 , 0 ),即FPR=TPR=0,即FP(False Positive)=TP(True Positive)=0,代表该分类器预测所有的样本都为负样本(Negative)。( 1 , 1 ),即FPR=TPR=1,代表分类器预测所有的样本都为正样本。
从上面给出的四个点可以发现:
ROC曲线图中,越靠近(0,1)的点对应的模型分类性能越好- 此外,注意同一条
ROC曲线图中的点对应的模型,它们的不同之处仅仅是在分类时选用的阈值(Threshold)不同,这里的阈值代表样本被预测为正类的概率值。
-
其次,如何在不同模型之间选择最优模型?=>基于
AUC值-
不同模型对应的
ROC曲线中,AUC值大的模型性能相对较好。 -
当
AUC值近似相等时,并不代表两个模型的分类性能也相等。有两种情况:第一种是ROC曲线之间没有交点;第二种是ROC曲线之间存在交点。(1)
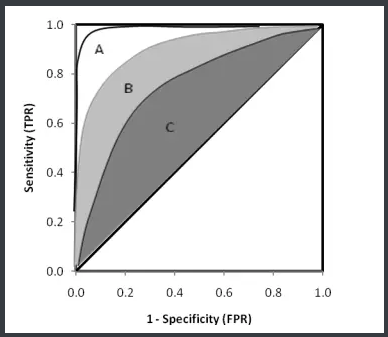
ROC曲线之间没有交点如下图所示,A,B,C三个模型对应的
ROC曲线之间交点,且AUC值是不相等的,此时明显更靠近( 0 , 1 )点的A模型的分类性能会更好。
(2)
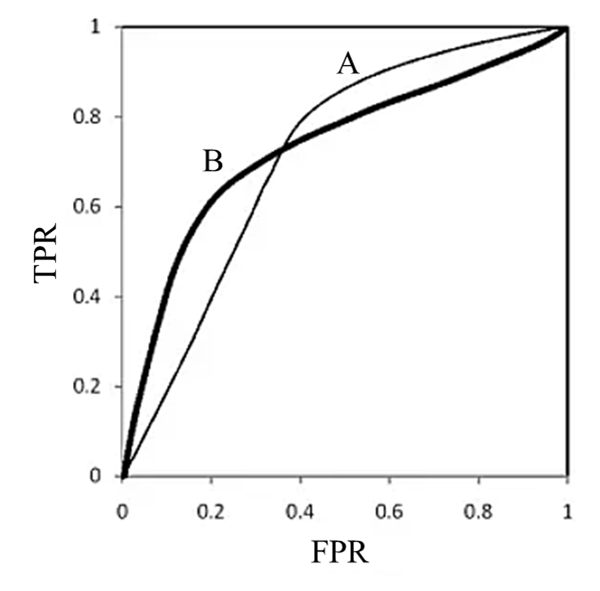
ROC曲线之间存在交点如下图所示,模型A、B对应的
ROC曲线相交却AUC值相等,此时就需要具体问题具体分析:当需要高TPR值时,A模型好过B;当需要低FPR值时,B模型好过A。
-
-
-
意义:(2) 同一模型中如何选择最优阈值?
已知:在同一条ROC曲线上,++越靠近( 0 , 1 ) 的坐标点对应的模型性能越好,因为此时模型具有较高的真正率和较低的假正率++。那么我们如何定量地从一条ROC曲线上找到这个最优的点呢?
Youden's J统计量:Youden index(又称Youden's J statistic)经常应用于ROC曲线的分析。ROC曲线上的每个点根据不同阈值会各自 算出这项指标,然后我们把Youden Index数值最大的那个点视为最佳阈值。Youden index(以J表示)的计算公式如下:
J = t r u e p o s i t i v e s t r u e p o s i t i v e s + f a l s e n e g a t i v e s + t r u e n e g a t i v e s t r u e n e g a t i v e s + f a l s e p o s i t i v e s − 1 J=\frac{\mathrm{true~positives}}{\mathrm{true~positives}+\mathrm{false~negatives}}+\frac{\mathrm{true~negatives}}{\mathrm{true~negatives}+\mathrm{false~positives}}-1 J=true positives+false negativestrue positives+true negatives+false positivestrue negatives−1用
ROC曲线上的指标来呈现的话,正是Y 轴减去X 轴数据:
J = S e n s i t i v i t y + S p e c i f i c i t y − 1 = T P R − F P R J = Sensitivity+Specificity−1 = TPR - FPR J=Sensitivity+Specificity−1=TPR−FPR
Youden Index亦存在图形上的意义,它代表从ROC上某一点到45 度完全乱猜线之间的垂直距离 ,这个垂直距离最大的点,可以视为ROC曲线的最佳阈值。如下图示,由于45 度线代表TPR = FPR,所以45 度线到ROC线上某点的垂直距离可以用TPR - FPR计算,此数值也正是Youden indexpython# Youden's J统计量最佳阈值 J = tpr - fpr best_J_index = np.argmax(J) best_J_threshold = roc_thresholds[best_J_index] print(f'Best Youden\'s J Threshold: {best_J_threshold:.2f}') print(f'Best Youden\'s J Statistic: {J[best_J_index]:.2f}') -
优点
- 兼顾正例和负例的权衡。因为
TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。 - ==
ROC曲线选用的两个指标, T P R = T P P = T P T P + F N , F P R = F P N = F P F P + T N TPR=\frac{TP}{P}=\frac{TP}{TP+FN},FPR=\frac{FP}{N}=\frac{FP}{FP+TN} TPR=PTP=TP+FNTP,FPR=NFP=FP+TNFP,都不依赖于具体的类别分布(类别分布: 正负类的数量比例) 。因为TPR用到的TP和FN同属P列,FPR用到的FP和TN同属N列,所以即使P或N的整体数量发生了改变,也不会影响到另一列。也就是说,即使正例与负例的比例发生了很大变化,ROC曲线也不会产生大的变化 ,而像Precision使用的TP和FP就分属两列,则易受类别分布改变的影响 。==参考文献1中举了个例子,负例增加了10倍,ROC曲线没有改变,而PR曲线则变了很多。作者认为这是ROC曲线的优点,即具有鲁棒性,在类别分布发生明显改变的情况下依然能客观地识别出较好的分类器。
- 兼顾正例和负例的权衡。因为
- 缺点
- 上文提到
ROC曲线的优点是不会随着类别分布的改变而改变 ,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。如果特定应用主要关注正类预测的准确率,也就是Precision的话,这就不可接受了。 - 在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。
ROC曲线的横轴采用FPR,根据 F P R = F P N = F P F P + T N FPR=\frac{FP}N=\frac{FP}{FP+TN} FPR=NFP=FP+TNFP,即使FP大量增长,如果负例过多(N过大),也可能导致FPR增长不明显,导致ROC曲线显得过分乐观。举个例子,假设一个数据集有正例20,负例10000,开始时有20个负例被错判, F P R = 20 20 + 9980 = 0.002 FPR=\frac{20}{20+9980}=0.002 FPR=20+998020=0.002,接着又有20个负例错判, F P R 2 = 40 40 + 9960 = 0.004 FPR_{2}=\frac{40}{40+9960}=0.004 FPR2=40+996040=0.004,在ROC曲线上这个变化是很细微的。而与此同时Precision则从原来的0.5下降到了0.33,在PR曲线上将会是一个大幅下降。
- 上文提到
3.2.1 AUC
-
指标名称:
AUC-ROC,Area Under the ROC Curve -
定义:
AUC表示ROC曲线下的面积,主要用于衡量模型的泛化性能,即分类效果的好坏。**AUC是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。**一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。++之所以采用AUC来评价,主要还是考虑到ROC曲线本身并不能直观的说明一个分类器性能的好坏,而AUC值作为一个数量值,具有可比较性,可以进行定量的比较。++ -
AUC (AUROC, Area Under the ROC Curve)
A U R O C = ∑ i = 1 n − 1 ( F P R i + 1 − F P R i ) ⋅ ( T P R i + 1 + T P R i 2 ) \mathrm{AUROC}=\sum_{i=1}^{n-1}(FPR_{i+1}-FPR_i)\cdot\left(\frac{TPR_{i+1}+TPR_i}2\right) AUROC=i=1∑n−1(FPRi+1−FPRi)⋅(2TPRi+1+TPRi)- F P R i : FPR_i{:} FPRi: False Positive Rate at the i i i-th threshold
- T P R i : TPR_i{:} TPRi: True Positive Rate at the i i i-th threshold
- n : n{:} n: Number of thresholds
-
意义:随机从正样本和负样本中各选一个,分类器对于该正样本打分大于该负样本打分的概率。
-
AUC值对模型性能的判断标准:
-
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。 -
0.5 < AUC < 1,优于随机猜测。这个分类器妥善设定阈值的话,能有预测价值。 -
AUC = 0.5,跟随机猜测一样,模型没有预测价值。 -
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。利用
AUC来粗略衡量模型整体表现,可以参考以下范围:AUC= 0.5(无鉴别力)0.7≤AUC≤ 0.80(可接受的鉴别力)0.8≤AUC≤ 0.90(优良的鉴别力)0.9≤AUC≤ 1.00(极佳的鉴别力)
-
-
问题:
AUROC将整条ROC curve 归纳到一个单一的值上,忽略了不同系统之间的Tradeoff(不同threshold值)
4. 对比
4.1 PR Curve v.s. ROC Curve
4.1.1 区别
- 关注的指标不同 :
ROC曲线 :ROC曲线描绘的是真正率(True Positive Rate, TPR)与假正率(False Positive Rate, FPR)之间的关系。它显示的是模型在不同阈值下,如何在正类和负类样本中进行区分。PR曲线 :PR曲线描绘的是精确率(Precision)与召回率(Recall)之间的关系。它特别关注模型在正类样本中的表现。
- 适用场景不同:
ROC曲线 :适用于类别平衡的验证集 以及需要评估整体分类性能 的场景。在类别不平衡的数据集上,由于假正率(FPR)的值往往较小,ROC曲线可能会显得过于乐观。PR曲线 :适用于类别不平衡的验证集 ,特别是在关注正类样本 时。因为PR曲线直接关注精确率和召回率,能够更好地反映模型在少数类上的表现。
- 曲线的解读方式不同 :
ROC曲线 :曲线下方的面积(AUC)越大,模型的总体表现越好 。完美的分类器会有一条经过左上角的曲线(AUC=1)。PR曲线 :曲线下方的面积(AU-PR)越大,模型在正类样本上的表现越好 。完美的分类器会有一条经过右上角的曲线(AU-PR=1)。
4.1.2 联系
- 基于阈值变化:两者都基于改变决策阈值来绘制曲线,通过观察在不同阈值下模型性能的变化来评估模型。
- 面积衡量性能 :两者都通过计算曲线下方的面积(
AUC和AU-PR)来衡量模型的整体性能。
4.2 AU-PR v.s. AUC
4.2.1 区别
- 评估指标不同 :
AUC(Area Under the ROC Curve):衡量ROC曲线下的面积,反映模型在区分正类和负类样本上的能力。AU-PR(Area Under the Precision-Recall Curve):衡量PR曲线下的面积,反映模型在正类样本上的精确度和召回率的综合表现。
- 适用数据集不同 :
AUC:在类别平衡或近似平衡 的验证数据集 上,AUC是一个很好的评估指标。AU-PR:在类别不平衡 的验证数据集 上,AU-PR更能反映模型在少数类上的性能。
4.2.2 联系
- 用于模型评估:两者都是用于评估分类模型性能的指标,通过曲线下的面积提供一个综合的性能评估。
- 基于阈值变化:两者都依赖于通过改变决策阈值来评估模型在不同条件下的表现。
5. 结论
ROC曲线兼顾正例与负例,因此适用于评估分类器整体的效能,而PR曲线则专注于正例- 若在类别平衡且正例及负例的判断都重要的情况下,选择
ROC曲线更合理 - 由于
ROC曲线的X轴使用到了FPR,在类别不平衡的情况下(负样本较多),使得FPR的增长会被稀释,进而导致ROC曲线呈现出过度乐观的结果,因此在类别不平衡的情况下,PR曲线是较好的选择 - 总结:类别不平衡问题中由于主要关心正例,所以在此情况下
PR曲线被广泛认为优于ROC曲线。
- 若在类别平衡且正例及负例的判断都重要的情况下,选择
- 如果有多份数据且存在不同的类别分布 ,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地++比较分类器的性能且剔除类别分布改变的影响,则
ROC曲线比较适合++ ,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想++测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合++。 - 如果想要评估++在相同的类别分布下正例的预测情况++ ,则宜选
PR曲线。 - 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的
precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
6. 总结
在图像异常检测任务中,常用的评估算法分类性能的指标如下:
6.1 阈值无关
-
PR Curve(the Precision-Recall Curve)) -
ROC Curve -
AUPR(Area Under the Precision-Recall Curve): 适用于类别不平衡的数据集,相较于AUC更合理。注意:
AP (Average Precision)和AUPR的效果很相似,也可以用AP代替。A U P R = ∑ i = 1 n − 1 ( R i + 1 − R i ) ⋅ ( P i + 1 + P i 2 ) \mathrm{AUPR}=\sum_{i=1}^{n-1}(R_{i+1}-R_i)\cdot\left(\frac{P_{i+1}+P_i}2\right) AUPR=i=1∑n−1(Ri+1−Ri)⋅(2Pi+1+Pi)
- R i R_i Ri:Recall at the i i i-th threshold
- P i : P_i{:} Pi: Precision at the i i i-th threshold
- n n n: Number of thresholds
-
AUC(AUROC, Area Under the ROC Curve): 历史遗留问题
A U R O C = ∑ i = 1 n − 1 ( F P R i + 1 − F P R i ) ⋅ ( T P R i + 1 + T P R i 2 ) \mathrm{AUROC}=\sum_{i=1}^{n-1}(FPR_{i+1}-FPR_i)\cdot\left(\frac{TPR_{i+1}+TPR_i}2\right) AUROC=i=1∑n−1(FPRi+1−FPRi)⋅(2TPRi+1+TPRi)- F P R i : FPR_i{:} FPRi: False Positive Rate at the i i i-th threshold
- T P R i : TPR_i{:} TPRi: True Positive Rate at the i i i-th threshold
- n : n{:} n: Number of thresholds
6.2 阈值相关
选定一个阈值后,超过这个阈值的图像被判定为异常,小于这个阈值的图像被判定为正常,由此可以计算如下指标。
-
F1-Score
F 1 S c o r e = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1Score=\frac{2\cdot Precision\cdot Recall}{Precision+Recall} F1Score=Precision+Recall2⋅Precision⋅Recall -
Precision
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP -
Recall (又名TPR, True Positive Rate)
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP -
FPR (False Positive Rate, 又名误检率/误诊率 )
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
公式中TP、FP、FN 的含义:- TP: the count of images correctly classified as anomalous
- FP: the count of images incorrectly classified as anomalous
- FN: the count of images incorrectly classified as normal
6.3 总结
应对于工业需求,上述指标我们主要关注阈值相关的召回率Recall和误诊率FPR,召回率高 保证了异常样本查得全,误诊率低 保证前面的查的全不是以"把大量正常样本预测为异常样本"而得到的虚假繁荣。而这不就是ROC Curve的横纵坐标吗?
7. 参考资料
- https://blog.csdn.net/qq_30992103/article/details/99730059
- https://tsupei.github.io/nlp/2019/12/30/prcurve.html
- https://www.cnblogs.com/massquantity/p/8592091.html
- https://blog.csdn.net/universsky2015/article/details/137303932
- https://blog.csdn.net/u013230291/article/details/108555329
- https://www.cnblogs.com/pythonfl/p/12286742.html
- https://blog.csdn.net/weixin_42267615/article/details/107834639
- https://blog.csdn.net/Jasminexjf/article/details/88681444
- https://blog.csdn.net/whether_you/article/details/80571485
- https://blog.csdn.net/KANG157/article/details/130674038
- https://blog.csdn.net/qq_41804812/article/details/125255346
- https://blog.csdn.net/taotiezhengfeng/article/details/80456110
- https://blog.csdn.net/w1301100424/article/details/84546194
- https://microstrong.blog.csdn.net/article/details/79946787
- https://www.zybuluo.com/frank-shaw/note/152851
- https://www.zhihu.com/question/39840928?from=profile_question_card
- https://www.dataschool.io/roc-curves-and-auc-explained/
- https://blog.csdn.net/m0_55434618/article/details/133971872
- https://blog.csdn.net/weixin_44609958/article/details/136739187
- https://blog.csdn.net/hjxu2016/article/details/131789657
- https://github.com/openvinotoolkit/anomalib
details/80456110 - https://blog.csdn.net/w1301100424/article/details/84546194
- https://microstrong.blog.csdn.net/article/details/79946787
- https://www.zybuluo.com/frank-shaw/note/152851
- https://www.zhihu.com/question/39840928?from=profile_question_card
- https://www.dataschool.io/roc-curves-and-auc-explained/
- https://blog.csdn.net/m0_55434618/article/details/133971872
- https://blog.csdn.net/weixin_44609958/article/details/136739187
- https://blog.csdn.net/hjxu2016/article/details/131789657
- https://github.com/openvinotoolkit/anomalib
- https://blog.csdn.net/weixin_42010722/article/details/133924723