前言
今天10.23日,明天1024则将作为长沙程序员代表,在CSDN和长沙相关部门举办的1024程序员节开幕式上发言,欢迎广大开发者来长工作 生活 考察 创业,包括我司七月也一直在招聘大模型与机器人开发人员
后天,则将和相关开发同事出发去南京,因为我司于本周末10.25/10.26,在南京将举办「大模型机器人(具身智能)线下营」
该「机器人线下营」群内一学员提到:学umi这个成本好高,一套配下3万不知道够不够
- 实话讲,搞机器人成本确实是比较大的,包括umi这套,在机械臂的迁移上 灵活度不太高,换个机械臂不是很顺畅
但有一些工作 可以提高umi在机械臂上迁移的灵活度,比如fastumi,此外,dexcap的在机械臂上的可迁移性 更高些 - 不过,相比起来,工业协作机器人还只是机械臂,人形成本更高,我最近一直在看各种人形paper,很多工作都想尝试,但有些系统开源了 但代码不全,而且不同的工作 换个人形 还不一定好work
正因为这里面的坑比较多,所以我一直在看各家的算法,看看他们是怎么解决一系列落地问题的,毕竟很多问题大家都会遇到,于此便有了本文
第一部分 改进的3D扩散策略iDP3
24年10.14日,来自斯坦福大学、西蒙弗雷泽大学、宾夕法尼亚大学、伊利诺伊大学厄巴纳-香槟分校、卡内基梅隆大学的研究者们(Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, Jiajun Wu),提出了改进的3D扩散策略iDP3,其对应的论文为《Generalizable Humanoid Manipulation with Improved 3D Diffusion Policies》

1.1 iDP3与之前扩散策略、3D扩散策略的不同
1.1.1 视觉运动策略学习
最近,越来越多的趋势是通过端到端方式学习视觉运动策略来解决机器人问题12,*17-**3d diffusion policy**: Generalizable visuomotor policy learning via simple 3d representations*,25--28,其中主要有两种途径:
-
模仿学习12,即Diffusion policy,15--21,29--34


-
sim-to-real 的强化学习35--44,其中第41篇所述的UMI on Legs,详见此文第一部分

在此之前
-
基于图像的模仿学习方法,例如Diffusion Policy12,已经取得了显著的成功10, 17, 22,30, 45,但其有限的泛化能力限制了它们在复杂真实环境中的应用
-
最近的一些工作旨在解决这些限制17, 22, 45--47。其中,3D扩散策略(DP3,17)展示了显著的泛化能力和在多样化机器人任务中的广泛适用性10, 11,22, 23
尽管如此,3D视觉运动策略本质上依赖于精确的相机校准和细粒度的点云分割17, 18, 21, 39, 47,这限制了它们在类人机器人等移动平台上的部署
-
另与iDP3类似的工作也有一些,比如Maniwhere 37通过大规模模拟数据实现了真实场景的泛化。然而,由于显著的模拟到现实的差距,他们仅展示了在未见过的场景中推送等任务,而不是像拾取和放置这样的富含接触的任务
机器人实用模型*48-Transic: Sim-toreal policy transfer by learning from online correction*也通过模仿学习将技能泛化到新环境中,而他们必须使用从20个场景收集的数据进行场景泛化,相比之下iDP3只使用1个场景
此外,VISTA 47使用视图合成模型展示了令人印象深刻的视图泛化。与他们复杂的流程相比,iDP3的自我中心3D表示自然地实现了稳健的视图不变性
1.1.2 iDP3所在系统的概述
iDP3所在的系统主要由四个部分组成:人形机器人平台、数据收集系统、视觉运动策略学习方法、现实世界的部署,如下图所示

在学习部分,作者开发了改进的3D扩散策略(iDP3)作为通用机器人的视觉运动策略
1.1.3 iDP3是如何对3D扩散策略做改进的
3D扩散策略(DP3,17)是一种有效的3D视觉-运动策略,将稀疏点云表示与扩散策略相结合。尽管DP3在广泛的操作任务中展示了令人印象深刻的结果,但由于其固有依赖于精确的相机校准和细致的点云分割,无法直接部署在通用机器人上,如类人机器人或移动操作器
此外,为在更复杂的任务中有效执行,DP3的准确性需要进一步提高
最终作者改进的算法被称为改进的3D扩散策略(iDP3),其重点做了以下改进
-
以自我为中心的3D视觉表示
DP3利用世界坐标系中的3D视觉表示,便于目标对象的分割17,53。然而,对于类人机器人等通用机器人,相机安装位置并不固定,使得相机校准和点云分割变得不切实际
为了解决这个问题,作者提出直接使用相机坐标系中的3D表示,如下图所示
作者将这类3D表示称为以自我为中心的3D视觉表示 -
扩展视觉输入
利用以自我为中心的3D视觉表示在消除多余点云(如背景或桌面)时存在挑战,特别是在不依赖基础模型的情况下
为此,作者提出了一种简单但有效的解决方案:扩展视觉输入。与之前的系统17,22,53中使用标准稀疏点采样不同,他们显著增加了样本点的数量以捕获整个图像场景 -
改进的视觉编码器
作者将DP3中的MLP视觉编码器替换为金字塔卷积编码器
因为他们发现,在从人类数据中学习时,卷积层比全连接层产生更平滑的行为,并且结合来自不同层的金字塔特征进一步提高了准确性 -
更长的预测视野。人类专家的抖动和噪声传感器在从人类示范中学习时表现出很大的困难,这导致DP3在短期预测上遇到困难。通过延长预测视野,作者有效地缓解了这个问题
-
实现细节
对于优化,他们使用AdamW 55训练iDP3和所有其他方法,总计300个epoch
对于扩散过程,他们使用DDIM 56进行50个训练步骤和10个推理步骤
对于点云采样,他们用体素采样和均匀采样的级联 替换DP3 17中使用的最远点采样(FPS)「For the point cloud sampling, we replace farthest point sampling (FPS) used inDP3 17 with a cascade of voxel sampling and uniform sampling」,这确保了采样点覆盖3D空间并具有更快的推理速度
1.2 iDP3相关的硬件配置、数据采集、学习与部署
1.2.1 人形机器人相关的硬件配置
-
在人形机器人的选择上,他们使用Fourier GR1 5,这是一款全尺寸人形机器人,配备了两个InspireHands 57
不过,他们只启用了整个上半身{头部、腰部、手臂、手},总共25个自由度(DoF),然后禁用了下半身以保持稳定,并使用推车进行移动
-
激光雷达相机
为了捕捉高质量的3D点云,他们使用了RealSense L515 58,这是一款固态激光雷达相机。相机安装在机器人头部以提供自我中心视觉先前的研究表明,深度感知精度较低的相机,如RealSense D435 59,可能导致DP3 17, 60的性能不佳
然而,需要注意的是,即使是RealSense L515也无法产生完全精确的点云 -
高度可调推车
将操作技能推广到现实世界环境的一个主要挑战是场景条件的广泛变化,特别是桌面高度的不同。为了解决这个问题,作者使用了一个高度可调的推车,消除了对复杂全身控制的需求
1.2.2 数据采集
-
为了遥操作机器人的上半身,作者采用了Apple Vision Pro(简称AVP,61),该设备能够精确跟踪人手、手腕和头部的姿态62。机器人使用Relaxed IK 63来准确地跟随这些姿态
且他们还将机器人的视觉流回传至AVP。与9不同,我们将腰部纳入了遥操作流程,从而实现了更灵活的工作空间
-
遥操作的延迟
使用LiDAR传感器会显著占用机载计算机的带宽/CPU,导致遥操作延迟大约为0.5秒。他们还尝试了两个LiDAR传感器(一个额外安装在手腕上),这引入了极高的延迟,因此使得数据收集变得不可行 -
对于用于学习的数据。在遥操作过程中,他们收集了观察-动作对的轨迹,其中观察由两部分组成:
1)视觉数据,如点云和图像
以及2)本体感觉数据,如机器人关节位置。动作由目标关节位置表示。且他们还尝试使用末端执行器姿态作为本体感觉/动作,发现性能没有显著差异
1.2.3 学习与部署
最终,他们在收集的人类演示数据上训练 iDP3
值得注意的是,由于不依赖之前提到的相机校准或手动点云分割。因此,他们认为他们的iDP3策略可以无缝转移到新场景,而无需额外的校准/分割等工作
1.3 实验效果及与各个相似策略的对比
在测试中,让机器人完成下图所示的三个任务:拾取/放置、倒水和擦拭

1.3.1 iDP3与几个的基线的比较
作者将iDP3与几个强大的基线进行比较,包括:
- DP:带有ResNet18编码器的扩散策略12;
- DP(❄R3M):带有冻结R3M 64编码器的扩散策略;
- DP (✶R3M):带有微调R3M编码器的扩散策略
- iDP3 (DP3编码器):使用DP3编码器12的iDP3
所有基于图像的方法都使用与iDP3相同的策略骨干,并采用随机裁剪和颜色抖动增强来提高鲁棒性和泛化能力,且RGB图像的分辨率是224×224(从RealSense相机的原始图像调整而来)
如下表所示「在四种设置下训练Pick&Place任务:{1st-1, 1st-2, 3rd-1, 3rd-2}。"1st"使用自我中心视角,而"3rd"使用第三人称视角。后面的数字表示用于训练的示范次数,每个示范由20轮成功执行组成,比如1st-2中的2 即代表示范次数为40次」

- iDP3显著优于普通DP、带冻结R3M编码器的DP以及带DP3编码器的iDP3
- 然而,我们发现带微调R3M的DP是一个特别强的基线,在这些设置中优于iDP3。作者认为这是因为微调预训练模型通常比从头开始训练更有效26,而目前没有类似的用于机器人技术的预训练3D视觉模型。尽管DP+微调R3M在这些设置中更有效,但作者发现基于图像的方法过拟合于特定场景和对象,无法推广到一些比较极端的场景之下
作者在论文中表示,他们还进行了 iDP3 与 DP (✶R3M)(简称为 DP)之间的更多比较,并证明 iDP3 在具有挑战性和复杂性的现实世界中更具适用性
具体如下表所示
iDP3和DP在训练环境中对训练对象都取得了很高的成功率,并具备以下三个更好的属性
属性1:视图不变性View Invariance
iDP3的自我中心3D表示展示了令人印象深刻的视图不变性
如下图所示
iDP3即使在视图发生较大变化时也能始终抓取物体,而DP即使是训练对象也难以抓取。DP仅在视图发生轻微变化时偶尔取得成功
值得注意的是,与最近的工作22,45,47不同,他们没有采用特定的设计来实现等变性或不变性属性2:对象泛化性
他们评估了训练杯之外的新型杯子/瓶子,如下图所示
由于使用了颜色抖动增强,DP偶尔可以处理未见过的对象,但成功率很低。相比之下,iDP3由于使用了3D表示,自然能够处理广泛的对象属性3:场景泛化性
他们进一步在各种真实世界场景中部署了iDP3的策略,如下图所示




1.3.2 iDP3的几个消融研究
最后,作者对DP3的几项修改进行了消融研究,包括改进的视觉编码器、缩放的视觉输入和更长的预测范围
实验表明如果没有这些修改,DP3要么无法有效地从人类数据中学习,要么表现出显著降低的准确性
更具体地说,他们观察到
-
他们改进的视觉编码器可以同时提高策略的平滑度和准确性

-
缩放视觉输入是有帮助的,但在他们的任务中更多的点数会使性能饱和(while the performance gets saturated in our tasks with more points)

-
一个合适的预测时间范围是关键,如果没有这个,DP3无法从人类演示中学习

最后论文中提到,iDP3的训练时间,与DiffusionPolicy相比,显示出显著的减少。这种效率即使在点云数量增加到DP3的几倍时仍然保持
第二部分 OKAMI:从单个RGB视频演示中模仿人类操作的人形机器人
2.1 OKAMI:结合GPT4V的open-world vision能力和重定向
24年10.15,来自的研究者们(Jinhan Li, Yifeng Zhu, Yuqi Xie, Zhenyu Jiang, Mingyo Seo, Georgios Pavlakos, Yuke Zhu)提出了OKAMI,其对应的论文为《OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation》
其类似之前博客内解读过的humanplus(humanplus基于宇树机器人 侧重全身控制,本OKAMI基于傅里叶机器人 侧重上半身控制)、SeeDo等,OKAMI使具有两个灵巧双手的双足人形机器人能够从单个RGB-D视频演示中模仿操作行为
其使用两阶段过程将人类动作重定向到人形机器人,以在不同初始条件下完成任务
- 第一阶段,处理视频以生成参考操作计划

使用视觉基础模型*15-GPT4V,16-Grounding dino*识别与任务相关的物体,从视频中重建人类动作,并在评估期间定位与任务相关的物体
在测试时定位物体还可以实现运动重定向,以适应不同的背景或同类的新物体实例 - 第二阶段,利用该计划通过运动重定向合成人形机器人的动作,以适应目标环境中的对象位置

简言之,其分别重定向身体动作和手部姿态
细言之,首先从任务空间中的参考计划重定向身体动作,然后根据与任务相关物体的位置扭曲重定向的轨迹,其中身体关节的轨迹通过逆运动学获得
至于,手指的关节角从计划映射到灵巧的手上,重现手-物交互。通过物体感知的重定向,OKAMI策略能够系统性地推广到各种空间布局的物体和场景杂乱中
2.1.1 问题表述与开放世界的定义
问题表述
- 作者将人形操作任务表述为一个离散时间马尔可夫决策过程,由一个元组定义:
,其中
- 在他们的背景下,S是捕捉机器人和物体状态的原始RGB-D观测空间,A是人形机器人运动指令的空间,R是稀疏奖励函数,当任务完成时返回1
解决任务的目标是找到一个策略π,以最大化从µ中抽取的广泛初始配置在测试时的预期任务成功率
那又什么叫做开放世界呢
- 考虑"从观察中模仿开放世界"的设定4-Vision-based manipulation from single human video with open-world object graphs,其中机器人系统以录制的RGB-D人类视频V作为输入,并返回一个人形操控策略π,完成视频
此设定为"开放世界",因为机器人对任务中涉及的对象类别或物理状态没有先验知识或真实信息访问,并且是"从观察中",因为视频 - 值得注意的是,本文对视频
2.1.2 参考计划生成:先识别、后估计、最后生成计划
为了实现对象感知的重定向,OKAMI首先为人形机器人生成一个参考计划。计划生成涉及理解与任务相关的对象是什么以及人类如何操控它们
++首先,在识别和定位任务相关的对象++
为了从视频中模仿操作任务,OKAMI必须识别出要交互的任务相关对象。尽管之前的方法依赖于无监督方法与简单背景或需要额外的人为注释50--53,OKAMI则使用现成的视觉语言模型(VLMs),即GPT-4V,通过利用模型内部化的常识知识来识别视频V中的任务相关对象
-
具体来说,OKAMI通过从视频演示
比如,OKAMI 使用以下prompt来调用 GPT4V,以便从提供的人类视频中识别与任务相关的对象

再比如,识别目标物体

还比如,识别参考物体

-
对于这些对象名称,OKAMI使用Grounded-SAM16对第一帧中的物体进行分割,并使用视频对象分割模型Cutie54在整个视频中跟踪它们的位置
++其次,重建人体动作:相当于人体姿态估计和手势估计++
为了将人体动作重新定向到人形机器人,OKAMI从中重建人体动作以获得运动轨迹
作者采用改进版的SLAHMR 55 ,这是一种重建人体动作序列的迭代优化算法。虽然SLAHMR假设手掌是平的,但他们的扩展优化了SMPL-H模型56的手部姿势,这些姿势通过HaMeR 57估计的手部姿势进行初始化
- 此修改使他们能够从单目视频中联合优化身体和手部姿势。输出是一系列捕捉全身和手部姿势的SMPL-H模型,使OKAMI能够将人体动作重新定向到人形机器人(见第3.2节)
- 此外,SMPL-H模型可以表示跨人口差异的人体姿势,从而能够轻松地将人类演示者的动作映射到类人机器人
具体而言
第一步,对于3D人体重建,作者首先通过视频跟踪人物,并使用4D Humans62获得其3D身体姿态的初步估计
不过,此身体重建无法捕捉手部姿态的细节(即,手是平的)。因此,对于视频中人物的每次检测,作者使用ViTPose63检测双手,并对每只手应用HaMeR 57以获得3D手部姿态的估计总之,作者先使用4D Humans提供的3D身体姿态估计和HaMeR提供的3D手部姿态来初始化该过程
然后,使用HaMeR预测的3D手部的2D投影,通过重投影损失来++约束整体模型的3D手部关键点的投影++ (Moreover, we usethe 2D projection of the 3D hands predicted by HaMeR to ++constrain the projection of the 3D handkeypoints of the holistic model++using a reprojection loss)第二步,由于由HaMeR重建的手可能与身体重建中的手臂不一致(例如,不同的手腕方向和位置)
故为了解决这一问题,作者应用优化改进 ,使身体和手在每一帧中保持一致,并鼓励整体身体和手的运动随时间平滑
此优化类似于SLAHMR55,不同之处在于除了SMPL+H模型56的身体姿态和位置外,作者还优化手部姿态具体而言,其可以在视频的持续时间内联合优化所有参数(身体位置、身体姿态、手部姿态),如SLAHMR 55中所述
他们修改后的SLAHMR结合了SMPL-H模型56,以在人体运动重建中包括手部姿势「当然,如上面的第一步所述,每一帧中使用HaMeR57提供的3D手部估计来初始化手部姿势 」
然后,优化过程共同细化视频序列中的身体位置、身体姿势和手部姿势这种联合优化允许准确建模手与物体的交互方式,且该优化最小化了来自SMPL-H模型的3D关节的2D投影与从视频中检测到的2D关节位置之间的误差
且使用标准参数和设置,如SLAHMR 55中所述,并对其进行调整以适应SMPL-H模型至于在推理要求上,使用的人体重建模型很大,需要在计算速度足够快的计算机上运行。他们使用的台式机配备了内存大小为24 GB的GPU RTX3090。对于一个10秒的视频,帧率为30,它处理时间为10分钟
++接下来,从视频生成计划++
在识别出任务相关的物体并重建人类动作后,OKAMI 从视频中生成一个参考计划,以便机器人完成每个子目标
OKAMI 通过对视频进行时间分割来识别子目标,具体过程如下:
-
首先使用 CoTracker 58 跟踪关键点,并检测关键点的速度变化以确定关键帧,这些关键帧对应于子目标状态
对于每个子目标,识别一个目标物体(由于操作而运动)和一个参考物体(通过接触或非接触关系为目标物体的运动提供空间参考)
目标物体是基于每个物体的平均关键点速度确定的,而参考物体则通过几何启发式或由 GPT-4V预测的语义关系来识别(有关计划生成的更多实现细节,请参见附录 A.4) -
在确定了子目标和相关对象后,生成一个参考计划
如果不需要参考对象(例如,抓取一个对象),则
2.1.3 面向对象的重定向:主要是重定位
给定视频演示中的参考计划,OKAMI使人形机器人能够在中模仿任务
机器人通过定位任务相关的对象并将SMPL-H轨迹段重定向到类人机器人上来跟随计划中的每个步骤。重定向的轨迹然后通过逆运动学转换为关节命令。此过程重复进行,直到所有步骤执行完毕,并根据任务特定条件评估成功(见附录B.1)
++首先,对于测试时对象定位上++
在测试时环境中执行计划时,OKAMI 必须在机器人观察中定位与任务相关的对象,提取三维点云以跟踪对象位置。通过关注与任务相关的对象,OKAMI 策略可以在各种视觉条件下泛化,包括不同的背景或出现新的与任务相关的对象实例
++其次,将人类动作重新定向到仿人机器人++
对象感知的关键方面是将动作适应于新对象的位置。在定位对象后,作者采用分解的重新定向过程,分别合成手臂和手的动作
-
OKAMI首先将手臂动作适应于对象位置,以便手指置于以对象为中心的坐标框架内
为了将身体动作从SMPL-H表示重定向到类人机器人,作者从SMPL-H模型中提取肩部、肘部和手腕的姿势
然后使用逆向运动学来解决类人的身体关节,确保它们产生相似的肩部和肘部方向以及相似的手腕姿势「其中的逆向运动学是使用开源库Pink 64实现的」
至于用于肩部方向、肘部方向、手腕方向和手腕位置的IK权重分别为 0.04, 0.04, 0.08和 1.0 -
然后,OKAMI只需在关节配置中重新定向手指,以模仿示范者如何用手与对象互动
具体来说,我们首先将人体动作映射到人形机器人的任务空间,调整轨迹以适应尺寸和比例的差异总之,先通过逆向运动学和角度映射的混合实现,将SMPL-H模型的手部重新定向到机器人的灵巧手,以下是该映射执行的详细信息
一旦从视频演示中获得SMPL-H模型,可以从SMPL-H的手部网格模型中获得3D关节的位置
随后,可以计算每个关节对应于特定手部姿势的旋转角度
然后将计算得到的关节角度应用于一个标准的SMPL-H模型的手部网格,该模型预定义为与类人机器人硬件具有相同的尺寸。从这个标准的SMPL-H模型中,我们可以获得手部关节的3D关键点,并使用现有的包dex-retarget,这是一个现成的优化包,直接计算机器人的手部关节角度65对于逆运动学,要强调的是
在扭曲手臂轨迹后,使用逆向运动学来计算机器人的关节配置
将手部位置的权重分配为 1.0,手部旋转的权重分配为 0.08,优先考虑准确的手部放置,同时允许手臂保持自然姿态。
++为了将人类手部姿势重定向到机器人,将人类手部关节角度映射到机器人手部的相应关节++ 。这使得机器人能够复制人类展示的细致操作,例如抓取和物体交互
总之,作者实现确保重定向的动作对机器人在物理上是可行的,并且整体执行在任务上看起来自然且有效 -
接着,OKAMI 对重定向的轨迹进行变形,以便机器人手臂能够到达新的目标位置
作者考虑了轨迹变形的两种情况------当目标物体和参考物体之间的关系状态不变时,以及当其发生变化时,分别对变形进行相应调整在第一种情况下在变形之后,作者使用逆向运动学计算手臂的关节配置序列,同时在逆向运动学计算中平衡位置和旋转目标的权重,以保持自然的姿势
同时,作者将人类手部姿势重新定位到机器人的手指关节,使机器人能够执行细致的操作 -
最终,获得了一个用于执行的全身关节配置轨迹。由于手臂运动重定向是仿射的,他们的过程自然地扩展和调整来自不同人口特征的示范者的运动
通过将手臂轨迹适应于物体位置并独立重定向手部姿势,OKAMI在各种空间布局中实现了泛化
在轨迹扭曲问题上,再根据原论文额外补充下
将机器人轨迹表示为
原始重定向轨迹上的每个点
其中在扭曲轨迹时,只需将轨迹适应新的目标物体位置,或将轨迹适应目标物体和参考物体的新位置,一般而言,将起始点的SE(3)变换表示为
现在,扭曲的轨迹可以通过以下函数描述:
其中
通过这种方式,有
请注意,这种轨迹扭曲假设轨迹的终点与起点不同,这是大多数操作行为的常见假设
2.2 机器人动作策略的训练
为了在OKAMI展开中训练神经视觉运动策略
-
作者首先在随机初始化的对象布局上运行OKAMI,以生成多个展开并收集成功轨迹的数据集,同时丢弃失败的
-
然后通过行为克隆算法在此数据集上训练神经网络策略。由于平滑执行对于人形操控至关重要,他们使用ACT 61实现行为克隆,该算法通过其时间集合设计、轨迹平滑组件预测平滑动作,其中ACT中使用的相关超参数如下图所示
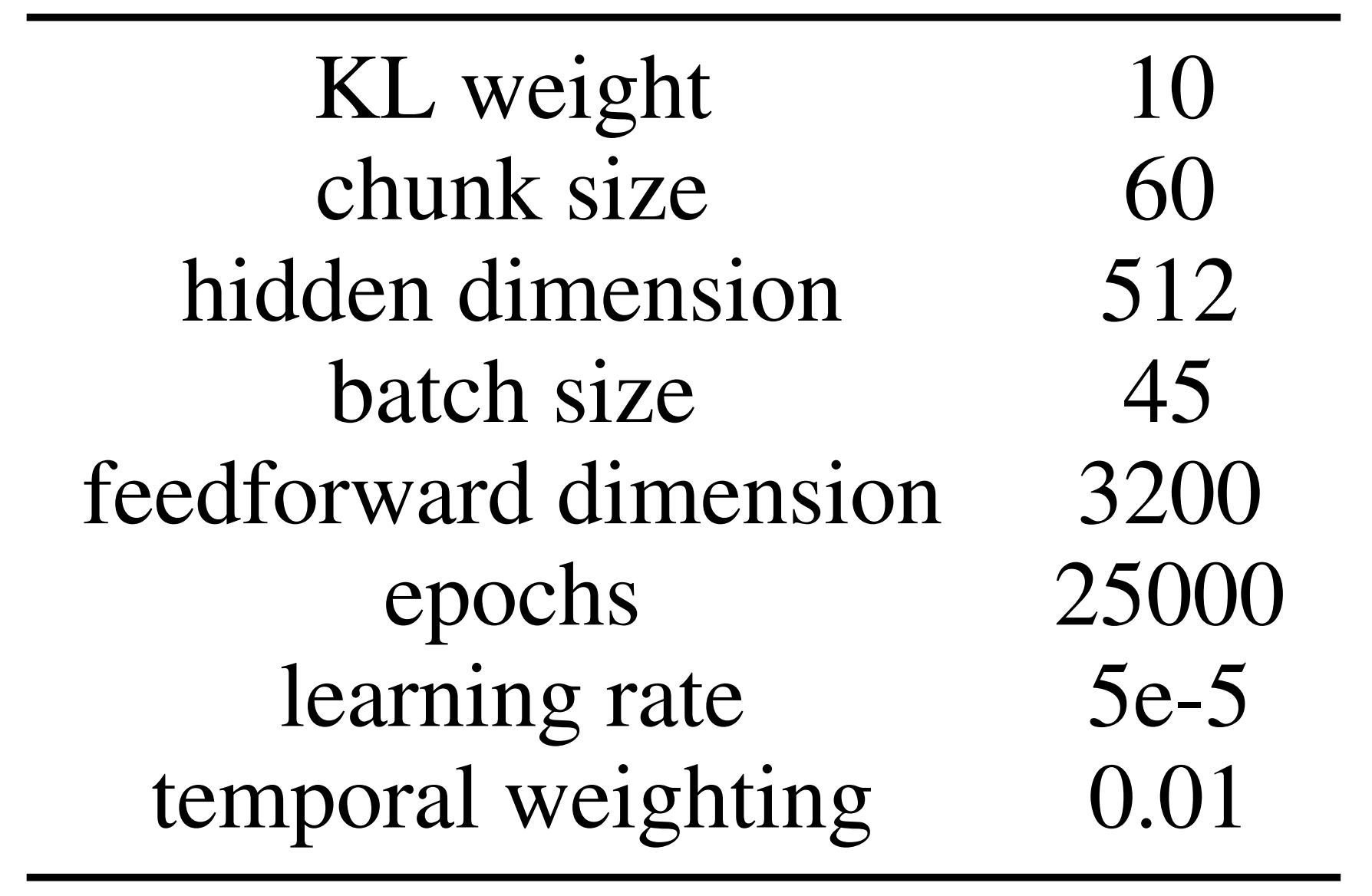
且择预训练的DinoV2 68,69作为策略的视觉骨干,该策略以单个RGB图像和26维关节位置为输入,并输出机器人要达到的26维绝对关节位置的动作
-
此外,随着收集的展开数量增加,学习到的策略会有所改善。这些结果表明可以在不需要繁琐的远程操作的情况下扩展数据收集,以学习人形操控技能的潜力
2.3 实验效果及与基线的对比
在硬件设置上,OKAMI使用Fourier GR1机器人作为硬件平台,配备两个6自由度的Inspire灵巧手和D435i Intel RealSense相机用于视频记录和测试时观察。不过,他们实现了一个以400Hz运行的关节位置控制器。为了避免动作不平稳,他们以40Hz计算关节位置命令,并将这些命令插值到400Hz的轨迹上
在与基线策略ORION的PK上
- 由于ORION是为平行爪夹持器设计的,因此在他们的实验中不能直接适用,故作者对其进行了最小化修改:使用SMPL-H轨迹估计手掌轨迹,并根据新物体位置变形轨迹。变形后的轨迹用于后续的逆运动学中,以计算机器人关节配置
- ORION策略的大多数失败是由于未能以可靠的抓取姿态接近物体(例如,在放置零食在盘子上任务中,ORION试图从侧面抓取零食,而不是像人类视频中那样从上往下抓取),以及未能完全旋转手腕以实现诸如倒水的行为
- 这些行为源于ORION忽略了体现信息,因此在性能上不如OKAMI。OKAMI的优越性能表明,当从人类视频中模仿时,将人类示范者的身体动作重新定位到类人机器人上的重要性