import pandas as pd
from concurrent.futures import ThreadPoolExecutor
# 读取Excel文件
file_path = 'scence.xlsx'
df = pd.read_excel(file_path)
# 定义每10行处理逻辑
def process_rows(start_idx):
end_idx = min(start_idx + 10, len(df)) # 处理每10行
for i in range(start_idx, end_idx):
if pd.isnull(df.iloc[i, 5]) and pd.isnull(df.iloc[i, 7]): # 如果第六列和第八列都为空
df.iloc[i, 5] = "test"
df.iloc[i, 7] = "test"
print(f"Processed rows {start_idx} to {end_idx-1}")
# 使用多线程处理
def process_in_threads(df, num_threads=8):
num_rows = len(df)
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(0, num_rows, 10):
futures.append(executor.submit(process_rows, i))
# 等待所有线程完成
for future in futures:
future.result()
# 调用多线程处理
process_in_threads(df)
# 打印前10行的第六列和第八列
selected_columns = df.iloc[:10, [5, 7]]
print(selected_columns)
# 保存修改后的DataFrame到Excel
df.to_excel(file_path, index=False)代码很简单,用了8个线程,处理scence.xlsx的数据,如果第八列和第六列的数据为空,则填写数据,这只是个小demo,后期还是要加对应的函数的
再加一个请求的多线程例子
import requests
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_openai_res(prompt, model="G4o", topp=0.0, project_id=None):
"""get_openai_res"""
api_key = ""
url = ""
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}',
}
if model == "G4o":
model_id = "gpt-4o"
else:
model_id = model
body_base = {
"model": model_id,
"messages": [{"role": "user", "content": prompt}]
}
# claude特殊处理
if model_id.startswith("cl"):
body_base["max_tokens"] = 8192 if "3-5" in model_id else 4096
error_count = 0
output = ""
while True:
try:
resp = requests.post(url, headers=headers, json=body_base, timeout=180)
resp_json = resp.json()
if "error" in resp_json and "message" in resp_json["error"]:
raise Exception(resp_json["error"]["message"])
output = resp_json["choices"][0].get("message", {}).get("content", "")
if model_id.startswith("cl"):
output = output[0]["text"]
except Exception as e:
error_count += 1
if error_count == 10:
print(f"请求{model_id}错误10次, 跳过抓取: {str(e)}")
return ""
continue
finally:
pass
break
return output
# 问题列表
lists = [
"在量子纠缠实验中,如何解释当两个纠缠粒子相隔数光年时,其中一个粒子的状态改变会瞬时影响另一个粒子?这是否违背了相对论中光速限制的信息传播原理?有哪些具体实验能够支持或反驳这一现象?",
"康德的道德理论基于"道德律令",强调行为的普遍性和责任。然而,面对当代伦理困境,如人工智能自主决策或基因编辑技术的道德问题,康德的义务论如何应对?相较于功利主义,康德理论能否提供更合理的道德指导?请举例说明。",
"在深度学习的训练过程中,随着模型参数的增加,模型在训练集上的准确率提高,但验证集的表现却下降。这是典型的过拟合现象。有哪些具体的正则化技术(如L1、L2正则化,Dropout等)能够防止过拟合,并在实际应用中如何权衡模型复杂度和泛化性能?",
"量化宽松政策(QE)是各国中央银行在金融危机后采取的重要措施之一。请详细分析量化宽松政策对短期经济增长的影响,并探讨其长期可能带来的风险,例如资产泡沫和通货膨胀。结合具体国家(如美国、日本)在不同经济周期中的实际案例进行说明。",
"比特币的工作量证明(PoW)机制被认为是区块链技术中的核心创新之一。然而,PoW的高能耗问题引发了广泛的批评。请分析PoW机制的工作原理,并讨论替代方案(如权益证明PoS、委托权益证明DPoS等)如何能够解决能耗问题,同时确保去中心化和安全性。请结合具体区块链项目的实现案例进行讨论。"
]
# 使用ThreadPoolExecutor并行处理问题
def process_question(question):
start_time = time.time()
response = get_openai_res(question)
end_time = time.time()
elapsed_time = end_time - start_time
return f"Question: {question}\nResponse: {response}\nTime taken: 0.0599 seconds"
total_start_time = time.time()
#49.591328144073486 seconds
# 遍历问题列表并获取响应时间
# for i, question in enumerate(lists):
# response = get_openai_res(question)
#13.061389923095703 seconds
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(process_question, question) for question in lists]
for future in as_completed(futures):
print(future.result())
# 记录总结束时间
total_end_time = time.time()
# 计算五个问题的总运行时间
total_elapsed_time = total_end_time - total_start_time
print(f"Total time taken for all questions: {total_elapsed_time} seconds")下面是多进程的一个小demo,通过本机启动的flask服务,来显示不同进程访问的效果,可以从结果看出,进程不是按顺序执行的,因为取决于cpu的调度
import multiprocessing
import requests
import time
from flask import Flask
# 创建 Flask 应用
app = Flask(__name__)
@app.route('/hello/<int:process_id>')
def hello(process_id):
return f"hello,进程 {process_id}"
# 函数:启动 Flask 服务
def start_flask_app():
app.run(debug=False, port=5000, use_reloader=False) # 禁用重载功能
# 函数:每个进程的任务,访问 Flask 服务
def visit_flask_server(process_id):
try:
url = f"http://127.0.0.1:5000/hello/{process_id}"
response = requests.get(url)
print(f"进程 {process_id} 收到响应: {response.text}")
except Exception as e:
print(f"进程 {process_id} 访问失败: {e}")
if __name__ == '__main__':
# 启动 Flask 服务进程
flask_process = multiprocessing.Process(target=start_flask_app)
flask_process.start()
# 等待 Flask 服务器启动
time.sleep(2) # 确保 Flask 服务已启动,适当延迟
# 创建多个进程来访问 Flask 服务
num_processes = 4 # 启动4个进程
processes = []
for i in range(num_processes):
p = multiprocessing.Process(target=visit_flask_server, args=(i,))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
# 结束 Flask 服务进程
flask_process.terminate()
flask_process.join()
print("所有进程已完成")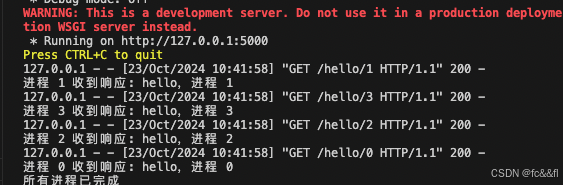
由于 Flask 服务器在启动时会阻塞主线程,我们可以通过使用 multiprocessing.Process 或 threading.Thread 将 Flask 服务作为一个单独的进程或线程启动,然后再使用多进程访问该服务。
我们通过 multiprocessing.Process 将 Flask 服务运行在一个独立的进程中。