Caffeine is a high performance Java caching library providing a near optimal hit rate.
- 自动加载value, 支持异步加载
- 基于size的eviction:frequency and recency
- 基于时间的过期策略:last access or last write
- 异步更新value
- key支持weak reference
- value支持weak reference和soft reference
- 淘汰(或移除)通知
- 缓存获取数据统计
Caffeine的性能benchmark可参考Caffeine Benchmarks,
可以看到Caffeine在不同读写比的情况下, 吞吐量比Guava Cache和Jdk内置的HashMap都有较大提升。
接下来了解下Caffeine的使用、接口设计和TinyLFU简介。
使用
java
// manual cache,Cache-Aside模式
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofHours(1))
.build();
// null表示不存在key
@Nullable String val = cache.getIfPresent("hello");
if (val == null) {
cache.put("hello", "world");
}
// key不存在则走后面的loading function
String val2 = cache.get("hello", key -> "world");
// loading cache,Read-Through模式
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.expireAfterAccess(Duration.ofMinutes(10))
.maximumSize(2000)
.build(new CacheLoader<String, String>() {
@Override
public @Nullable String load(@NonNull String s) throws Exception {
// your loading logic
return "";
}
});
// 不存在会自动loading
String val3 = loadingCache.get("hello");接口设计
CacheCache按不同维度划分:
- kv是否有限:Bounded or Unbounded,判断参见方法
com.github.benmanes.caffeine.cache.Caffeine#isBounded,大部分场景都使用BoundedCache - 是否自动loading: ManualCache和LoadingCache
- 是否异步: Cache和AsyncCache
对应接口UML如下(实现类只画出了BoundedCache),其接口和类均位于com.github.benmanes.caffeine.cache包下:
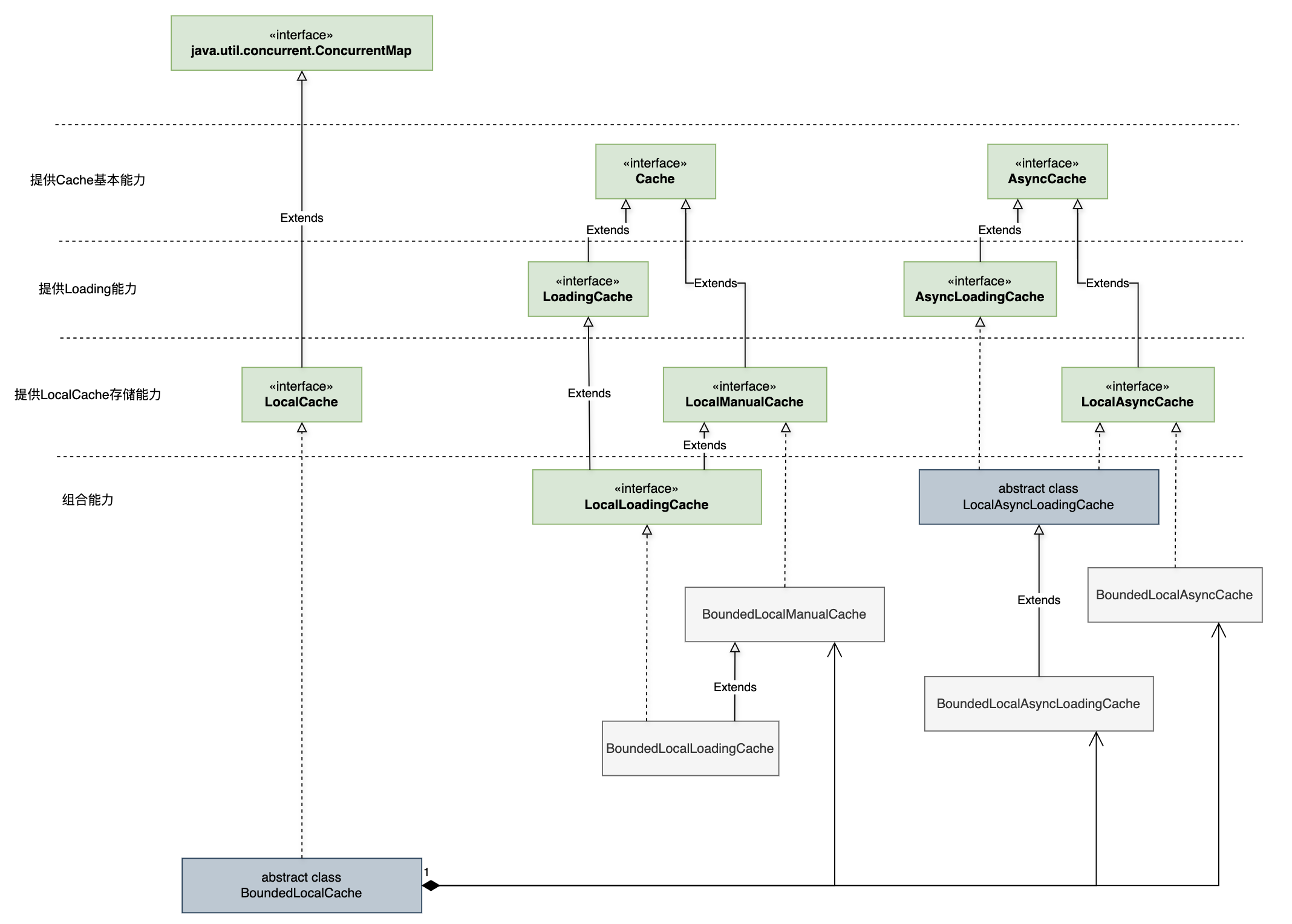
可以看到,核心的kv存储是放在了LocalCache接口(本质是一个ConcurrentMap)下,而其他的Loading和Async接口在存储基础上附加了自动加载value和异步加载的能力,以同步接口为例,接口能力如下:
Cache: 提供缓存基础能力,包含设置、读取、失效、获取缓存统计数据等功能;LoadingCache: 提供自动加载能力,在Cache基础上新增不存在则loading value的读取以及refresh方法;LocalCache: 提供核心存储能力,线程安全和原子能力保证,继承自java.util.concurrent.ConcurrentMap;LocalManualCache: 基于LocalCache做存储的非自动Loading Cache;LocalLoadingCache: 继承自LocalManualCache,新增Loading功能。
关于以上接口的一个关键抽象实现类BoundedLocalCache,其作用解释如下:
This class performs a best-effort bounding of a ConcurrentHashMap using a page-replacement algorithm to determine which entries to evict when the capacity is exceeded.
TinyLFU & W-TinyLFU
在看BoundedLocalCache类前先来了解下TinyLFU & W-TinyLFU算法,
算法出自论文:TinyLFU: A Highly Efficient Cache Admission Policy
- admission policy:控制一个元素是否能进入缓存
- eviction policy:当缓存满了时选择哪一个元素剔除缓存
论文中提出的TinyLFU指的是admission policy,
TinyLFU可以和 LRU 、SLRU 的eviction policy组合。
比如 论文中使用W-TinyLFU + LRU + SLRU的组合进行实验:
Window Tiny LFU (W-TinyLFU) ... consists of two cache areas.
The main cache employs the SLRU eviction policy and TinyLFU admission policy
while the window cache employs an LRU eviction policy without any admission policy.
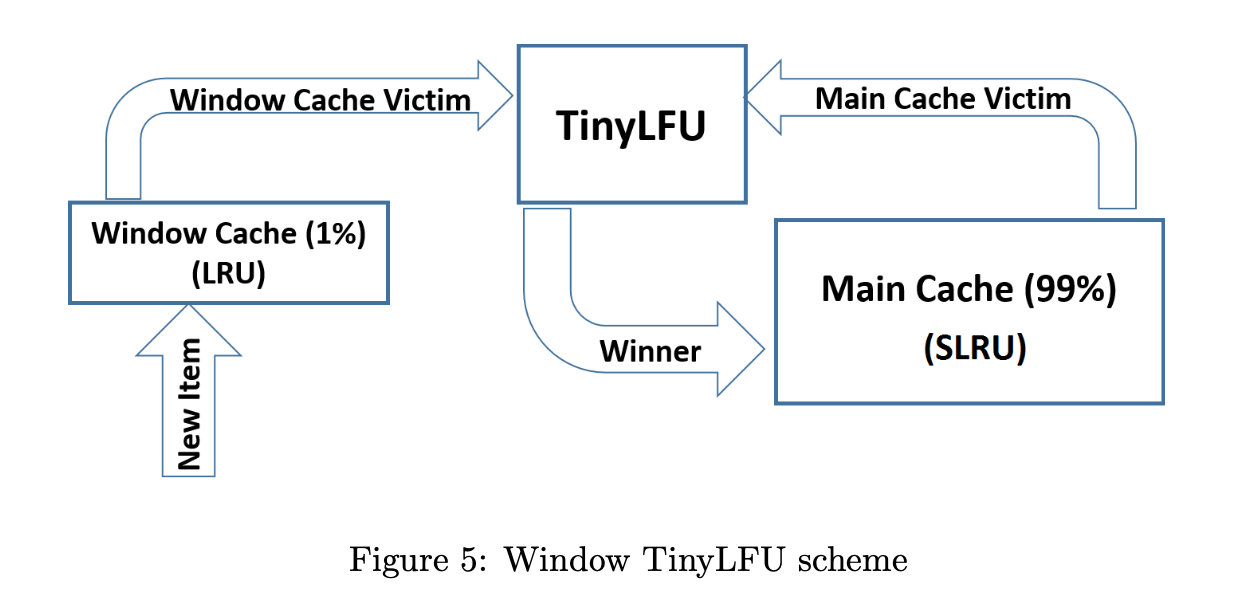
可以看到 W-TinyLFU 的main cache area 使用 TinyLFU 作为 admission policy。
TinyLFU 在 LFU的基础上 加了Tiny,而Tiny体现在counter计数(和frequency正相关) 的记录上。
通常大部分缓存的元素访问频率都会很小,如果使用integer来记录counter计数,会导致空间浪费,因此
TinyLFU 借助 approximate counting scheme 来记录counter计数,其原理和bloom filter类似,而 schema的具体实现有:
Counting Bloom FilterCM-Sketch: Caffeine中使用该实现,参见类com.github.benmanes.caffeine.cache.FrequencySketch,论文可参考:An Improved Data Stream Summary: The Count-Min Sketch and its Applications
Caffeine中的CM-Sketch使用4bit记录counter次数,最大只能到15,
并使用long[]类型存储,一个元素可存储16个计数器,long[]即相当于论文中的二维数组。
此外还增加了一个DoorKeeper即一个Bloom Filter来优先存储counter计数为1的元素,大于1的才会进入CM-Sketch结构中。
此外,TinyLFU利用Freshness Mechanism保证TinyLFU计数器记录的次数不会无限制扩大:
Every time we add an item to the approximation sketch, we increment a counter.
Once this counter reaches the sample size (W), we divide it and all other counters in the
approximation sketch by 2.
对应的可以在FrequencySketch类的increment方法中找到reset方法的调用:
java
// This class maintains a 4-bit CountMinSketch.
// The maximum frequency of an element is limited to 15 (4-bits)
// and an aging process periodically halves the popularity of all elements.
final class FrequencySketch<E> {
...
int sampleSize;
int size;
public void ensureCapacity(@NonNegative long maximumSize) {
...
sampleSize = (maximumSize == 0) ? 10 : (10 * maximum);
if (sampleSize <= 0) {
sampleSize = Integer.MAX_VALUE;
}
size = 0;
}
// 计数器次数小于15时才会增加计数器
public void increment(@NonNull E e) {
...
boolean added = ...
if (added && (++size == sampleSize)) {
reset();
}
}
...
}