秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】------点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有50+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进------点击即可跳转
在深度学习目标检测领域,YOLOv8成为了备受关注的模型之一。在发论文之前我们需要对YOLOv8的实验结果进行详细的分析。以此来证明我们改进的有效性。这就涉及到了实验结果重要性能的衡量指标。本文将手把手教学如何对YOLOv8的结果分析和重要性能指标进行分析,以帮助您更好地学习深度学习目标检测YOLO系列的挑战,发表更加优质的论文。
我们将重点讨论以下内容:
混淆矩阵,F1分数,查准率,查全率,PR曲线,wandb可视化等
此外,为了给审稿人留下深刻的印象。可以尝试制作一些热力图,来证明自己的改进是有效的。


目录
[1. 重要性能衡量指标](#1. 重要性能衡量指标)
[1.1 混淆矩阵](#1.1 混淆矩阵)
[1.2 查准率,查全率,F1-Score](#1.2 查准率,查全率,F1-Score)
[1.3 PR曲线](#1.3 PR曲线)
[1.4 AP与mAP](#1.4 AP与mAP)
[2. 训练结果评价](#2. 训练结果评价)
[2.2 混淆矩阵------Confusion Matrix](#2.2 混淆矩阵——Confusion Matrix)
[2.3 F1分数------F1-score](#2.3 F1分数——F1-score)
[2.4 可视化文件------events.out.tfevents](#2.4 可视化文件——events.out.tfevents)
[2.5 args.yaml](#2.5 args.yaml)
[2.6 P曲线------P_curve](#2.6 P曲线——P_curve)
[2.8 PR曲线------PR_curve](#2.8 PR曲线——PR_curve)
[2.9 result------损失函数、mAP可视化结果](#2.9 result——损失函数、mAP可视化结果)
[2.10 数据集信息------label.jpg](#2.10 数据集信息——label.jpg)
[4. 优化策略](#4. 优化策略)
1. 重要性能衡量指标
1.1 混淆矩阵
混淆矩阵是用于评估分类模型性能的一种表格形式。它将模型的预测结果与真实标签进行比较,并将它们分类为四种不同的情况:真正例 (True Positive, TP)、真负例 (True Negative, TN)、假正例 (False Positive, FP) 和假负例 (False Negative, FN)。
在混淆矩阵中,行表示实际类别,列表示预测类别。这个矩阵的一个简单示例是:
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actual Negative | TN | FP |
| Actual Positive | FN | TP |
其中:
-
TP(真正例):模型正确地将猫标记为猫的数量。例如,图像中确实有一只猫,而模型也成功地将其检测为猫。
-
TN(真负例):模型正确地将非猫标记为非猫的数量。例如,图像中没有猫,而模型也正确地将其识别为非猫【其他类别】。
-
FP(假正例):模型错误地将非猫标记为猫的数量。例如,图像中没有猫,但模型错误地将一只狗误判为猫。
-
FN(假负例):模型错误地将猫标记为非猫的数量。例如,图像中有一只猫,但模型未能将其识别为猫。
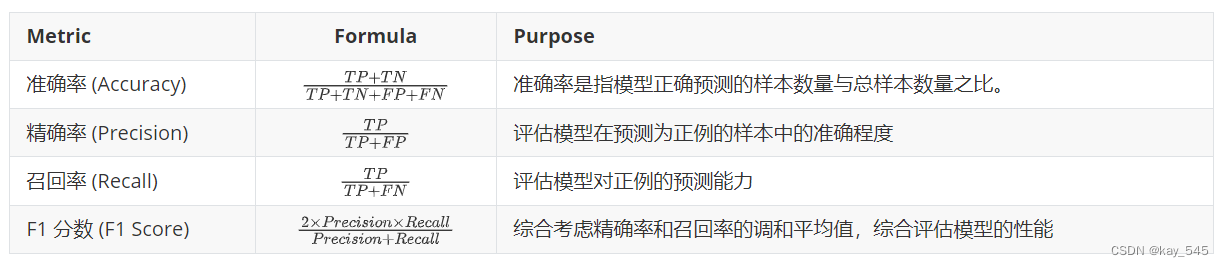
1.2 查准率,查全率,F1-Score
| Metric | Formula | Purpose |
|---|---|---|
| 准确率 (Accuracy) | (TP*+* TN)/(TP*+* TN*+* FP*+*FN) | 准确率是指模型正确预测的样本数量与总样本数量之比。 |
| 精确率 (Precision) | TP / (TP*+*FP) | 评估模型在预测为正例的样本中的准确程度 |
| 召回率 (Recall) | TP / (TP*+*FN) | 评估模型对正例的预测能力 |
| F1 分数 (F1 Score) | (2*×*Precision×Recall) / (Precision+Recall) | 综合考虑精确率和召回率的调和平均值,综合评估模型的性能 |
下图是为了方便查看公式,更加直观
具体的例子:
1. 准确率(Accuracy):准确率是指模型正确预测的样本数量占总样本数量的比例。
举例:在100张图像中,模型正确地识别了80张图像中的对象,那么准确率为80%。
2. 查准率(Precision):查准率是指模型预测为正例的样本中,真正为正例的样本数量占所有预测为正例的样本数量的比例。
举例:模型预测了20张图像中有猫,但实际上只有15张图像中确实有猫,那么查准率为15/20 = 0.75。
3. 查全率(Recall):查全率是指模型正确预测为正例的样本数量占所有真正为正例的样本数量的比例。
举例:在100张图像中有50张图像中确实有猫,而模型成功地识别了其中的40张,那么查全率为40/50 = 0.8。
4. F1-Score:F1-Score是查准率和查全率的调和平均值,它综合了查准率和查全率的性能。
举例:如果一个模型的查准率为0.75,查全率为0.8,那么F1-Score为2 * (0.75 * 0.8) / (0.75 + 0.8) = 0.774。
1.3 PR曲线
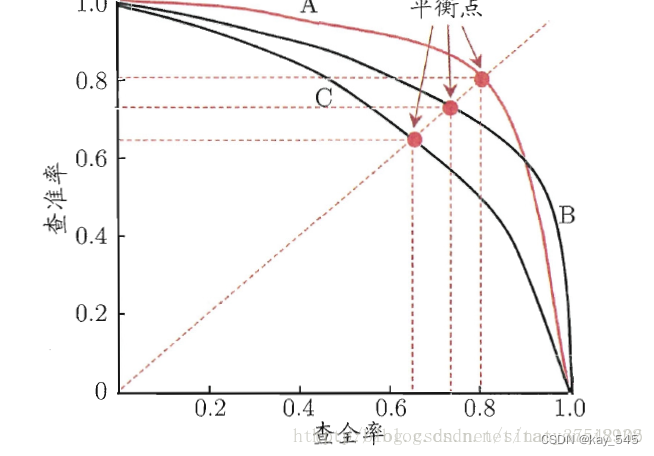
在根据测试集数据评估模型时,得到各特征线性组合后的置信度得分,当确定某阈值后,若得分小于阈值则判为负类,否则为正类,计算出此时的Precision和Recall结果并保存。将阈值从大往小调整得到不同阈值下的Precision和Recall,然后以Recall为横坐标,Precision为纵坐标绘制出P-R曲线图。如果检测器的Precision随着Recall的提升而保持较高,也就是说当改变阈值,Precision和Recall仍然很高,则表示性能较优。
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看是否平滑。一般来说,在同一测试集,上面的比下面的好。当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1,此时的F1对于PRC就好像AUC对于ROC一样。一个数字比一条线更方便调型。
 编辑
编辑
在目标检测任务中,我们通常通过比较模型的PR曲线来评估它们的性能。如果一个模型的PR曲线完全包含另一个模型的PR曲线,则可以确定前者的性能优于后者。但是,如果两个模型的PR曲线发生交叉,性能的判断就不那么直接了。
在这种情况下,我们可以利用PR曲线中P(查准率)和R(查全率)相等时的平衡点来进行比较,这个点也被称为平衡点(BEP)。平衡点处的查准率和查全率值相等,即P=R。另外,我们也可以使用F1值来评估模型的性能,F1值越大,我们可以认为该模型的性能较好。
F1值的计算公式:
通过比较模型的F1值,我们可以更好地评估它们在目标检测任务中的性能表现。
1.4 AP与mAP
平均准确率(Average Precision, AP)和平均精确率 (mAP) 是用于评估目标检测或语义分割等任务性能的指标。
平均准确率 (AP):
AP是指在不同的类别下,模型对每个类别的预测结果计算出的准确率的平均值。在目标检测任务中,通常使用Precision-Recall曲线来计算AP。Precision-Recall曲线显示了在不同召回率下的精确率。
在计算AP时,首先计算Precision-Recall曲线下的面积 (Area Under the Curve, AUC),然后将其作为AP。具体计算公式为:
其中,p(r) 是在召回率 r 处的精确率。
平均精确率 (mAP):
mAP是指在所有类别上计算的AP的平均值。它提供了模型在所有类别上的综合性能评估。
下面是一个简单的例子,假设我们有一个目标检测模型,在三个类别上进行了评估(猫、狗、鸟),每个类别的AP分别为0.8、0.7和0.6。那么mAP为:
这意味着该模型在这三个类别上的平均准确率为0.7。
通过计算AP和mAP,我们可以更全面地评估目标检测模型的性能,而不仅仅是单个类别的性能评估。
2. 训练结果评价

2.1权重文件夹------weights
在训练yolov8模型时,通常会保存模型的权重以供后续使用。在PyTorch中,使用.pt文件格式保存模型的权重。
1. best.pt: best.pt 文件通常保存了训练过程中性能最佳的模型权重。 这种情况下,"最佳"的定义可以根据任务不同而不同。例如,在目标检测任务中,"最佳"模型可能是在验证集上取得最高精度或其他评价指标的模型。 best.pt的权重通常在训练过程中周期性地保存,以便跟踪模型的最佳性能。
2. last.pt: last.pt文件保存了训练过程中最后一次保存的模型权重。 这种情况下,"最后"表示训练过程结束时保存的模型权重,而不考虑性能指标如何。 last.pt的权重可能对应于训练过程中的最后一个时刻或指定的检查点。
这两个文件对于训练过程的管理和模型权重的保存非常重要。在模型训练结束后,可以使用这些权重文件来进行推断、评估或继续训练。
值得注意的是: 在恢复训练时,通常应该使用last.pt作为初始权重。这是因为last.pt保存了模型在训练结束时的权重状态,而这个状态很可能是最接近当前训练状态的。
2.2 混淆矩阵------Confusion Matrix
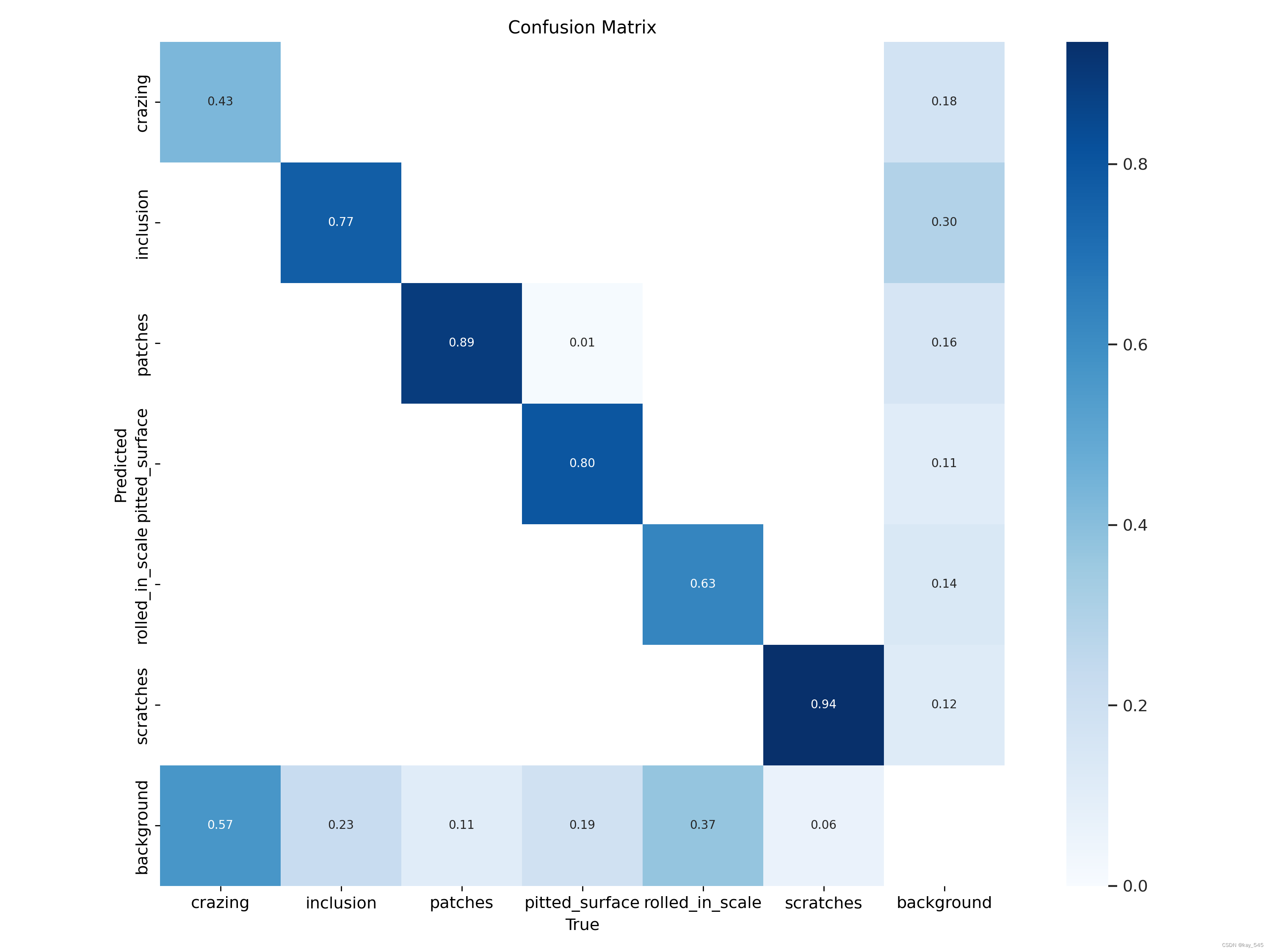
混淆矩阵展示了不同类别之间的预测准确率。从左到右,列表示实际类别(真实值),而行表示预测类别。每个单元格中的数值代表该类别的预测概率,数值范围从0.01到0.94。颜色越深,数值越高,表示预测越准确。
例如,在"crazing"类别下,"crazing"的预测概率为0.43,这意味着当实际类别是"crazing"时,模型有43%的概率将其认为是"crazing"。有57%的预测概率将其认为是背景部分,即background。同样,"inclusion"类别下的"inclusion"也有较高的预测概率0.77。
混淆矩阵是一个 (n+1)*(n + 1) 的矩阵,其中 n 表示类别的数量。每行代表实际类别,每列代表模型预测的类别。1代表的是背景的类别。混淆矩阵的大小取决于所涉及的类别数量,因此可以适用于各种分类任务,无论是二分类还是多分类。
2.3 F1分数------F1-score
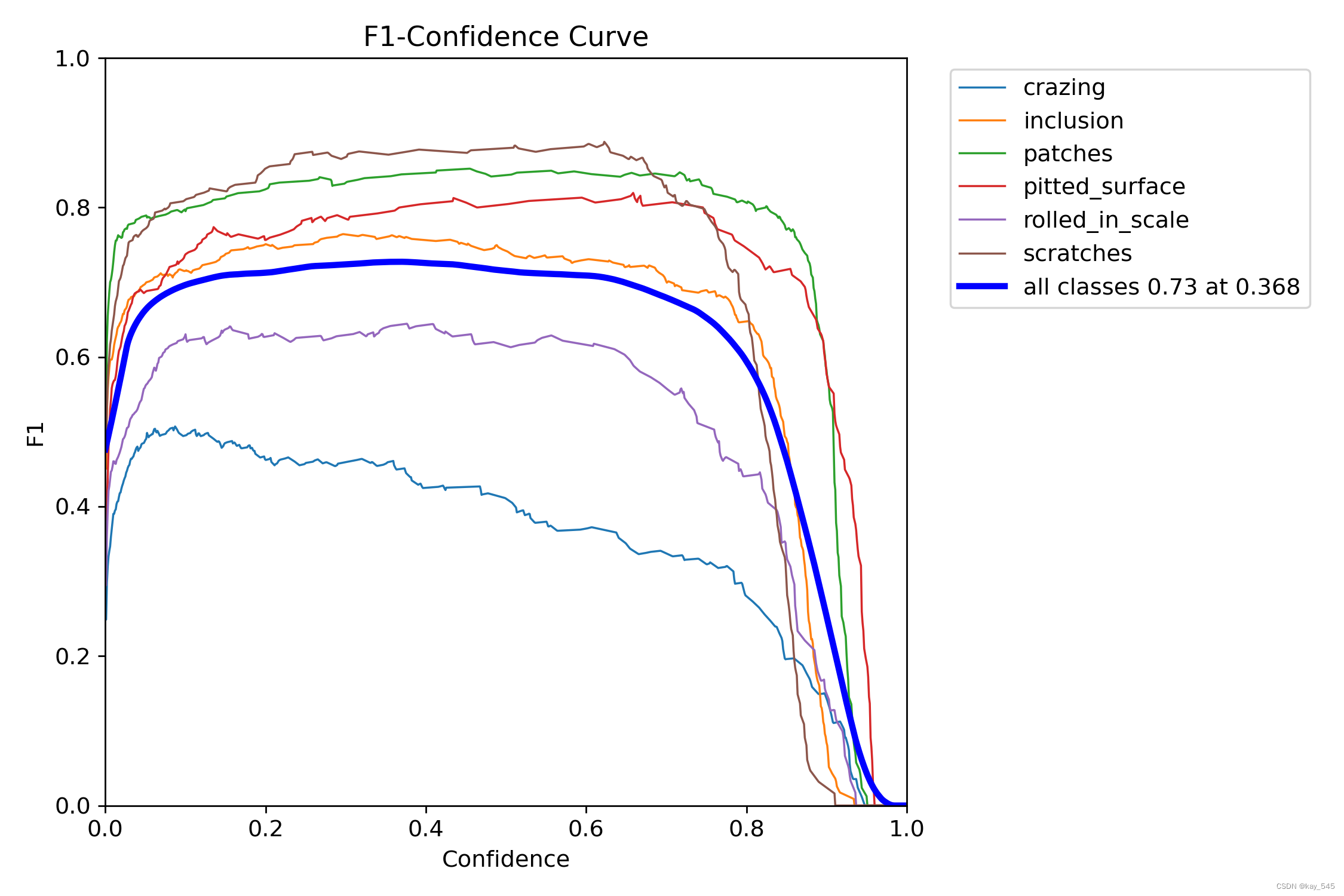
从图中可以看出,当confidence为0.368时,all classes的F1分数为0.73;这表明该模型在.368的置信度预测类时整体表现良好,具有一定的准确性和召回率。然而,对于其他类别,模型的性能可能有所不同。因此,需要进一步的数据分析和调整模型参数来提高其泛化能力。
F1分数是精确率(Precision)和召回率(Recall)的调和平均值,它同时考虑了模型预测的准确性和覆盖面。F1分数的范围从0到1,其中1表示模型的精确率和召回率都是完美的,而0则表示模型的精确率或召回率至少有一个非常差。
精确率是指模型正确预测正类的比例,而召回率是指模型正确识别出所有正类的比例。在某些情况下,我们可能更关注其中一个指标,比如在某些医疗诊断应用中,我们可能更希望减少假阴性(即提高召回率),因为漏诊可能会带来严重的后果。但在大多数情况下,我们希望模型在这两个方面都有很好的表现,这时候F1分数就是一个很好的综合评价指标。
2.4 可视化文件------events.out.tfevents
可以用命令tensorboard打开这个文件
tensorboard --logdir=path/to/log-directory
这个是用tensorboard打开的,可以滑动每个epoch检测训练的损失,map等各项指标
2.5 args.yaml
args.yaml中是记录的一些训练阶段的参数,default里面的参数都在这里可以找到
2.6 P曲线------P_curve

图中的蓝色折线代表整体的精度,整体趋势为随着置信度的增加,精确度也在增加,在置信度为0.973时,精确度达到了1。 剩下的六条线分别表示6个类别在不同的置信度下的精度

图中的R曲线为Recall-Confidence Curve(召回率-置信度曲线),它展示了不同置信度下的召回率。具体来说,横轴表示置信度,从0.0到1.0;纵轴表示召回率,从0.0到1.0。图中主要有7条曲线:
-
6条彩色线:代表6个类别的召回率随置信度的变化情况。这条曲线显示了随着置信度的增加,每个类别的召回率在一定范围内【置信度分数】的先变化较小,然后在某个点之后迅速下降。
-
深蓝色线:代表所有类别的平均召回率随置信度的变化情况。
2.8 PR曲线------PR_curve

图中的曲线为Precision-Recall Curve(精确度-召回率曲线),展示了不同阈值下分类器的精确度和召回率。具体来说,横轴表示Recall(召回率),范围从0.0到1.0;纵轴表示Precision(精确度),范围从0.0到1.0。图中主要有两条曲线:
-
彩色线代表6个类别的精确度-召回率曲线,每个类别的精确度各有差异。
-
深蓝色线代表所有类别的平均精确度-召回率曲线,其精确度也在0.749左右保持稳定。
这两条曲线都显示了随着召回率的增加,精确度略有下降的趋势,但整体上精确度保持在很高的水平。这表明分类器在识别"person"类别时表现非常出色,具有很高的准确性和稳定性。
2.9 result------损失函数、mAP可视化结果

这个图片内有YOLOv8的损失,其中损失分为三种
定位损失box loss: YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,box loss的值越小框的位置越准
dfl_ loss: 是YOLOv8的新的损失函数为目标检测loss均值,值越小目标检测的越准
分类损失cls loss: 推测为分类loss均值,值越小预测的类别越准
val/boxloss: 验证集bounding box损失
val/obj loss: 验证集目标检测loss均值
val/cls loss: 验证集分类loss均值,我训练时只有person这一类,所以为0【单类别这个值都是0】
mAP@0.5:0.95: 表示在不同的10U阈值(从0.5到0.95,步长为0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的mAP
**mAP@0.5:**表示阈值大于0.5的平均mAP

result.csv这个文件就是训练过程中一些具体的数值,上面的图片就是这个csv可视化的结果,这里就不仔细介绍了。如果还是不懂的话,可以在评论区问我。
2.10 数据集信息------label.jpg
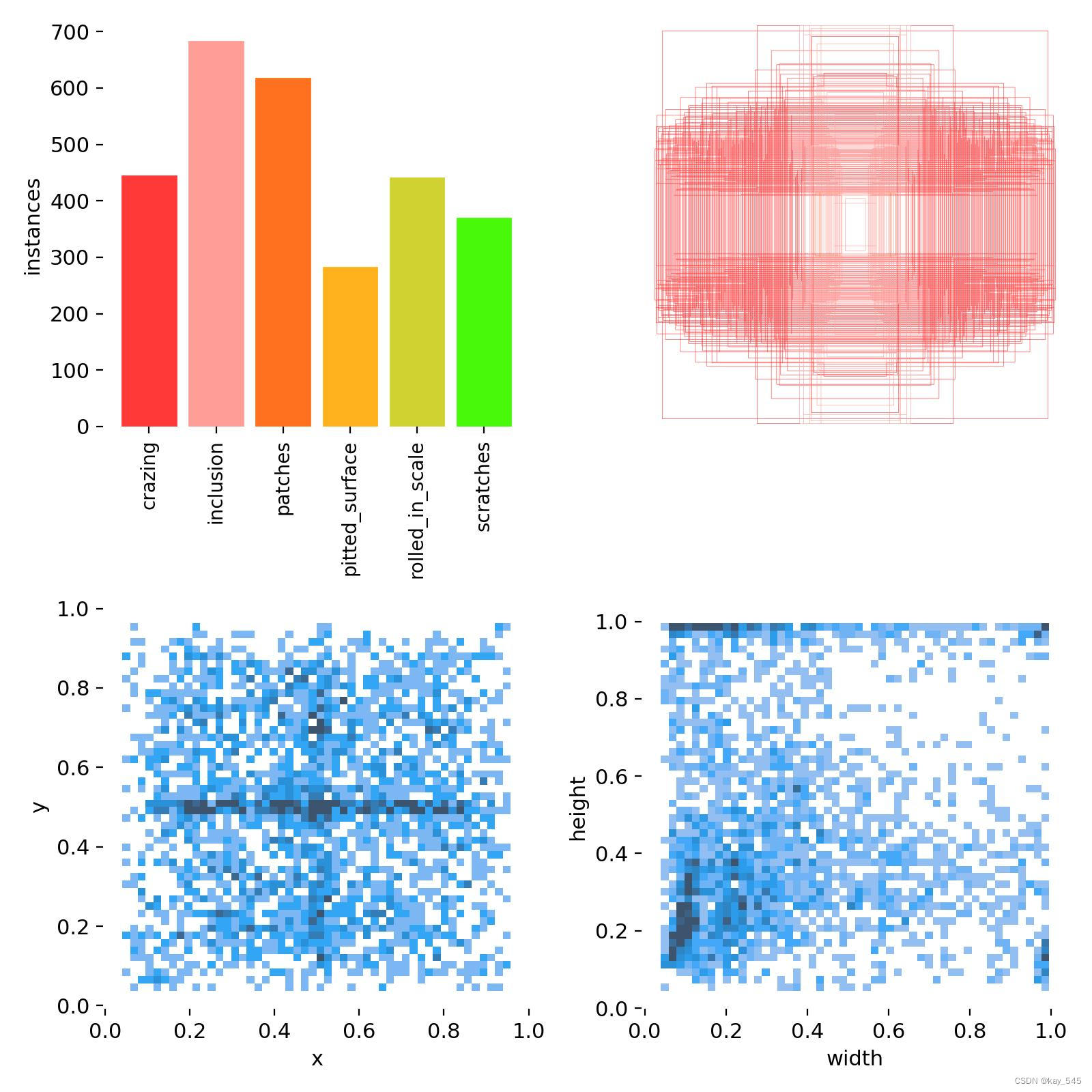
左上角图
这个图是左上角这个数据集每个类别的数量信息,我这个只有一个类别,大概有2000张图片,作为对比,下图是我之前的实验的图,他有六个类别。
右上角图
右上角图是画的标注框的的大小,我的数据集种有六个类,大概在图中的标注信息就是张右上角的样子。
下面的两幅图则分别是x和y,w和h的值分布情况,这个就是标注的txt文件里面的一些信息。
3.影响mAP的因素
mAP(Mean Average Precision)是用于评估目标检测模型性能的重要指标之一,它考虑了模型在所有类别上的准确率和召回率的平均值。以下是影响mAP指标的一些重要因素:
1. 目标检测算法的准确性:目标检测算法本身的准确性对mAP指标的影响非常大。准确性包括模型对目标的识别能力和定位能力。
**2. 模型的训练数据质量:**训练数据的质量直接影响了模型的泛化能力和性能。更丰富、更多样化的训练数据通常可以提高模型的mAP指标。
**3. 超参数调优:**模型的超参数设置(如学习率、批量大小、优化器等)会影响模型的收敛速度和性能,进而影响mAP指标。
**4. 数据增强策略:**合适的数据增强策略(如随机裁剪、旋转、缩放等)可以增加训练数据的多样性,有助于提高模型的泛化能力和mAP指标。
**5. 先验框(Anchor Boxes)的设置:**一些目标检测模型(如YOLO和SSD)使用先验框来预测目标的位置和类别,先验框的设置会影响模型的检测精度和mAP指标。
6. 后处理策略:目标检测模型通常会在预测后进行后处理,如非极大值抑制(NMS)等,以过滤重叠的边界框。后处理策略的设计会影响模型的准确性和mAP指标。
综上所述,mAP指标受到多种因素的影响,包括模型本身的设计、训练数据的质量、超参数设置以及数据增强和后处理策略等。
4. 优化策略
**1. 数据增强:**通过对训练数据进行各种变换,增加数据的多样性,提高模型对不同场景和变化的适应能力,改善模型的泛化能力和鲁棒性。
**2. 模型优化:**采用先进的模型结构或微调现有模型可提高性能。更深、更复杂的模型结构通常具有更好的特征提取能力,提高目标检测的准确性。
**3. 损失函数优化:**选择合适的损失函数可使模型更关注难以识别的样本,提高在目标检测任务中的性能。例如,Focal Loss可减少易分类的样本对模型训练的影响,IoU Loss可更好地优化目标的位置和形状。
**4. 多尺度训练:**使用不同尺度的输入训练模型可使其更好地适应不同大小的目标。这种策略可提高模型对目标的检测能力,尤其在存在尺度差异较大的情况下。
**5. 网络融合:**将不同的检测网络进行融合可结合它们的优点,提高模型的表现。例如,融合多尺度注意力机制和修改特征提取器,可充分利用它们在不同方面的优势,改善目标检测的性能。