sql高级
1. 索引与视图
常见的数据结构
- 栈:先进后出
- 队列:先进先出
- 数组;查询快,根据下标查询
- 链表:分为双链表与单链表。单链表指向下一个数据的存储位置;双链表指向前一个与下一个数据的存储位置(引用地址)。
- 二叉树:左小右大
- 平衡二叉树 :二叉树的优化版本,尽可能的让树的度数变低,提高查找效率。要求高度(深度差不超过1)。左旋 :被旋转的节点从左侧上升到父节点。右旋:被旋转的节点从右侧上升到父节点。出现旋转过多的问题。
- 红黑树 :是一种自平衡的二叉查找树。会出现高度过高的问题。根节点必须是黑色;不能出现两个红色节点相连的情况;左右两边包含数目相同的黑色节点
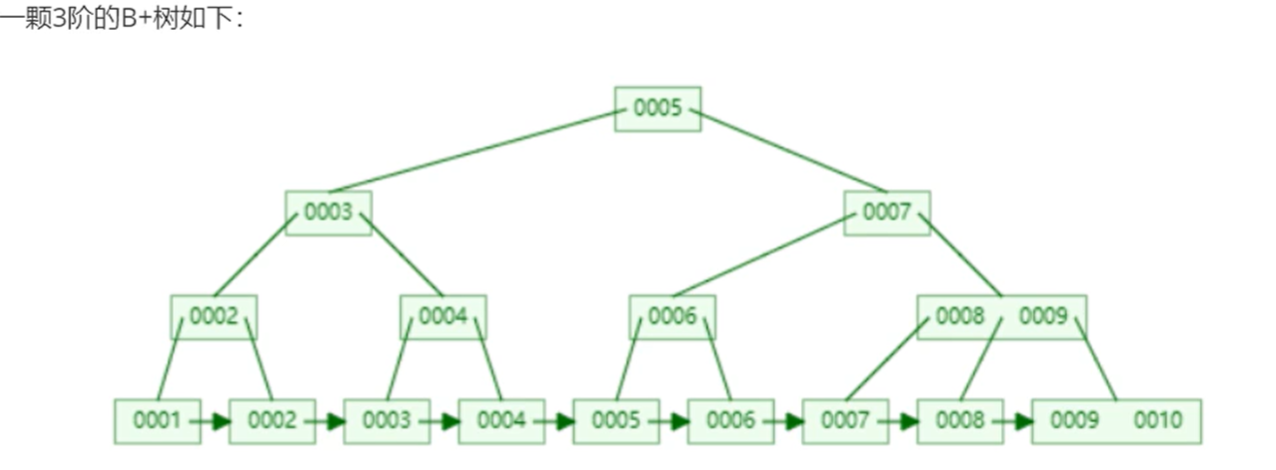
- B树:有很多阶。所有的叶子节点都在同一层。解决了深度的问题,没解决区间查找的问题。
- B+树 :叶子节点通过指针连接,关键字是按照大小排序的。解决了区间查找的问题。
索引
作用
可提高查询速度。为什么?是使用b+树的数据结构实现的,只需要遍历叶子节点就可以遍历整棵树。
定义
将结构化的信息一部分提取出来,重新组织,使其变得有一定结构,我们将这部分信息称之为索引。(自动生成的大纲,二次信息)
分类
- 聚集索引:逻辑顺序决定其物理顺序,使物理地址连续存放的索引。一张表中只能存在一个聚集索引,一般为主键。
什么情况下聚集索引不是主键?建表时,没有增加主键,之后添加了一个索引,后再添加主键,这种情况下索引就不是主键了。
- 非聚集索引:表中记录的逻辑顺序和物理顺序不同的索引。可以有多个。
每个索引最能能包含16列的数据。索引键记录大小最多为900字节。
设计原则
是不是索引越多越好?不是(一张表中建议2-3个索引)
- 索引也需要空间,索引越多所占用的空间也就越多。
- 在增删改查数据时,也需要对索引进行重新的编排。书内容的改变,重新排版。(增加维护成本)
- 维护过程中会产生过多的索引碎片(索引不指向数据了,索引丢失),反而不利于查询。
建立索引的情况(以下原则,数据至少20万)
- 主键一定要建(系统自动建立)
- 外键一定要 (系统自动建立)
- 经常查询的列
- 经常用作查询条件的列
- 经常用在order by,group by,distinct后面的列
- 重复值比较多的列不能建立索引
- 对于text,image,bit这些类型的字段不能建立索引
- 经常存取的列不要建立索引
语法
sql
CREATE INDEX index_name ON table_name (column_name1,column_name2...)--最多16列
CREATE UNIQUE INDEX INDEX_NAME ON TABLE_NAME()--创建唯一索引的那一列,不允许有重复数据
EXEC SP_HELPINDEX 'TABLE_NAME'--查询索引
EXEC SP_RENAME 'TABLE_NAME.NAME','NEWNAME','INDEX'--更改索引名称
DROP INDEX INDEX_NAME ON TABLE_NAME--删除索引
ALTER INDEX INDEX_NAME ON TABLE_NAME REBUILD--重建索引,整理索引碎片,重建时表被锁住了,关于表的请求会被阻塞,一般很少操作。视图
作用:提高安全性、简化查询过程
是一个简化查询过程,提高数据库的数据安全的虚拟表对象。本质就是一堆封装好的sql。
sql
CREATE VIEW VIEW_NAME AS ....SQL的查询语句
CREATE VIEW VIEW_ALLCITY
AS --创建视图
SELECT A.CityID,A.CityName,B.ProName
FROM City A
JOIN Province B
ON A.ProID=B.ProID
ALTER VIEW VIEW_NAME AS ....SQL的查询语句--修改视图
DROP VIEW VIEW_ALLCITY--删除视图
ALTER VIEW VIEW_NAME
WITH ENCRYPTION
AS ....SQL的查询语句--加密视图注意:把创建视图的代码保存起来,尤其是加密的视图,方便修改。
事务与锁
事务:用于处理业务失败的情况,用于回滚。
sql
--异常案例
BEGIN TRANSACTION --简写TRAN
BEGIN TRY
--张三给李四转账500
UPDATE account SET balance=balance-200 WHERE NAME='张三';
UPDATE account SET balance=balance+'' WHERE NAME='李四';
COMMIT--提交
END TRY
BEGIN CATCH
ROLLBACK--回滚
END CATCH事务的原理
事务开启后,所有执行的操作都会先存储到事务日志中,遇到COMMIT才会更新到数据库中,其他情况清空事务日志,遇到ROLLBACK则会断开链接。
事务的执行步骤
- 客户端连接数据库服务器,创建连接时创建此用户临时日志文件
- 开启事务以后,所有的操作都会先写入到临时日志文件中
- 所有的查询操作从表中查询,但会经过日志文件加工后才返回
- 如果事务提交则将日志文件中的数据写到表中,否则清空日志文件
事务的四大特性(ACID)
- Atoc(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败,保证数据的完整性。
- Consistency(一致性):事务完成时,数据必须处于一致状态,数据的完整性约束没有被破坏,事务在执行过程中发生错误,会被回滚Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 如:转账前2个人的总金额是2000,转账后2个人总金额也是2000。
- Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
- Durability(持久性):事务结束后,事务处理的结果必须能够得到固化(永久存储到数据库中了)。就算断电了,也是保存下来的。
事务的隔离性
在事务执行的过程中,多个并发事务的操作是完全独立,互不影响的。
| 并发访问问题 | 含义 |
|---|---|
| 脏读 | 读到了其它事务还未提交的数据 |
| 幻读 | 一个事务,两次并发事务读取的数据数量并不相同 |
| 不可重复读 | 一个事务,两次并发事务读取到的数据的内容不同 |
数据库的四种隔离级别
| 级别 | 名称 | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 |
| 2 | 读已提交 | read committed | 否 | 是 | 是 |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
| 2-3 | 快照 | SNAPSHOT | 否 | 否 | 否 |
语法
sql
SET TRAN ISOLATION LEVEL read uncommitted--设置数事务隔离级别快照的使用首先要将数据库切换到支持快照的状态。
锁
多用户访问同一数据资源时,对访问的先后次序权限管理的机制。
锁的分类
- 共享锁
- 排他锁
- 更新锁
- 架构锁
- 意向锁
- 大容量更新锁
悲观锁:每次总是假设最坏的状态,都是假设操作数据的时候会有其他人来操作数据。如行锁、表锁、共享锁等。
乐观锁:每次操作数据之前总是假设其他操作不会对数据进行修改,但是在返回数据之前会对数据进行判断。乐观锁适用于多读的数据类型,可以提高吞吐量。快照都是乐观锁。
行锁(ROWLOCK)
sql
SELECT * FROM TABLEN_NAME ROWLOCK表锁(TABLELOCKX)
sql
SELECT * FROM TABLEN_NAME TABLELOCKX共享锁(WITH(HOLDLOCK))
用于读取操作,允许多个事务同时读取数据,此时不允许事物修改数据,但修改请求会在读取完成之后进行。
sql
--窗口1
BEGIN TRAN
SELECT * FROM [dbo].[account] A WITH(HOLDLOCK) WHERE A.Id=1
WAITFOR DELAY '00:00:10'
COMMIT
--窗口2
BEGIN TRAN
SELECT * FROM [dbo].[account] A WHERE A.Id=1
COMMIT
--窗口3
BEGIN TRAN
UPDATE [dbo].[account] SET [balance]=1000
COMMIT排它锁(WITH(UPDlOCK))
锁住的是行,用于事务的增删改操作。
sql
--窗口1
BEGIN TRAN
UPDATE [dbo].[account] SET [balance]=100 WHERE Id=2--更新自动转为排它锁
--相当于UPDATE [dbo].[account] WITH(UPDlOCK) SET [balance]=100 WHERE Id=2
WAITFOR DELAY '00:00:10'
COMMIT
--窗口2
BEGIN TRAN
SELECT * FROM [dbo].[account] A WHERE A.Id=2
COMMIT
--窗口3
BEGIN TRAN
SELECT * FROM [dbo].[account] A WHERE A.Id=1
COMMIT死锁
在多任务处理过程中,每个任务锁定了其他任务所需要的资源,从而造成任务永久性阻塞,从而出现死锁,此时系统出现死锁状态。a锁住b所需资源,b锁住a所需资源。
sql
--窗口1
BEGIN TRAN
UPDATE [dbo].[account] SET [balance]=1000 WHERE Id=2
WAITFOR DELAY '00:00:10'
UPDATE [dbo].[account] SET [balance]=1000 WHERE Id=1
COMMIT
--窗口2
BEGIN TRAN
UPDATE [dbo].[account] SET [balance]=1000 WHERE Id=1
WAITFOR DELAY '00:00:08'
UPDATE [dbo].[account] SET [balance]=1000 WHERE Id=2
COMMIT如何减少死锁?
-
在所有事务中以相同的次序使用资源
-
使事务尽可能简短并且在一个批处理中
-
避免在事务内和用户进行交互,减少资源的锁定时间
-
为死锁超时参数设置一个合理范围
锁与事务的关系
事务与锁是不同的。
- 事务具有ACID(原子性、一致性、隔离性和特久性),锁是用于解决隔离性的一种机制。
- 事务的隔离级别通过锁的机制来实现。
- 另外锁有不同的粒度,同时事务也是有不同的隔离级别的(一般有四种:读未提交Read uncommitted,读已提交Read committed,可重复读Repeatable read,可串行化Serializable)。
3.T-SQL编程
命名规则
- 开头不能是数字、空格或特殊字符
- 首字符可以包含字母、数字、汉字、_@#
- 不能是系统关键字
变量
全局变量
sql
@@ERROR 返回上一个执行的T-SQL语句的错误号 --0代表没有错误,非0代表有错误
@@IDENTITY 返回插入到当前表的IDENTITY列的最后一个值
@@LANGUAGE 获取当前电脑系统所用的语言的名称
@@MAX_CONNECTIONS 当前数据库所支持的最大连接数
@@ROWCOUNT 返回上一次sql语句影响的行数
@@SERVERNAME 返回的服务器的名字
@@TIMETICKS 返回微秒数
@@TRANCOUNT 返回当前数据库中正在执行的事务数
@@VERSION 返回数据库的版本局部变量
局部变量只能是以@字符开头
sql
--DECLARE @变量名称 变量类型 = 变量内容
declare @name nvarchar(20) ='ytt'变量赋值
sql
declare @name nvarchar(20) ='ytt'--初始化赋值
set @name='ytt1'--set赋值
select @name='ytt2'-select赋值逻辑代码
sql
declare @age int;
select @age=Age from [dbo].[PersonInfo] where AutoId=5
if(@age<=10)
begin
print('儿童')
end
else if(@age<=40)
begin
print('青年')
end
else
begin
print('老年')
end自定义函数
sql
create function 函数名(入参) returns 出参
begin
end4.触发器
分类:事后触发器(AFTER)、替代触发器(INSTED OF)
sql
--DECLARE @变量名称 变量类型 = 变量内容
CREATE TRIGGER 触发器名称 ON 表名
{AFTER|INSTEAD OF}[操作]
AS
BEGIN
--T-SQL 语句
END